
Language Semantics Interpretation with an Interaction-Based Recurrent Neural Network


Abstract
:1. Introduction
1.1. Overview
1.2. Problems in RNN
1.3. Problems in Text Classification Using RNN
1.4. Performance Diagnosis Test
1.5. Remark
1.6. Contributions
1.7. Organization of Paper
2. A Novel Influence Measure: I-Score
2.1. I-Score, Confusion Table, and AUC

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Condition | ||||
|---|---|---|---|---|
| Condition Positive | Condition Negative | |||
| Actual Condition | Positive | True positive (Correct) | False negative (Incorrect) | Sensitivity/Recall Rate (RR) |
| Negative | False positive (Incorrect) | True negative (Correct) | Specificity Rate (SR) | |
| Precision/Positive Predictive Value (PPV) | Negative Predictive Value (NPV) | |||
| F1 Score | ||||
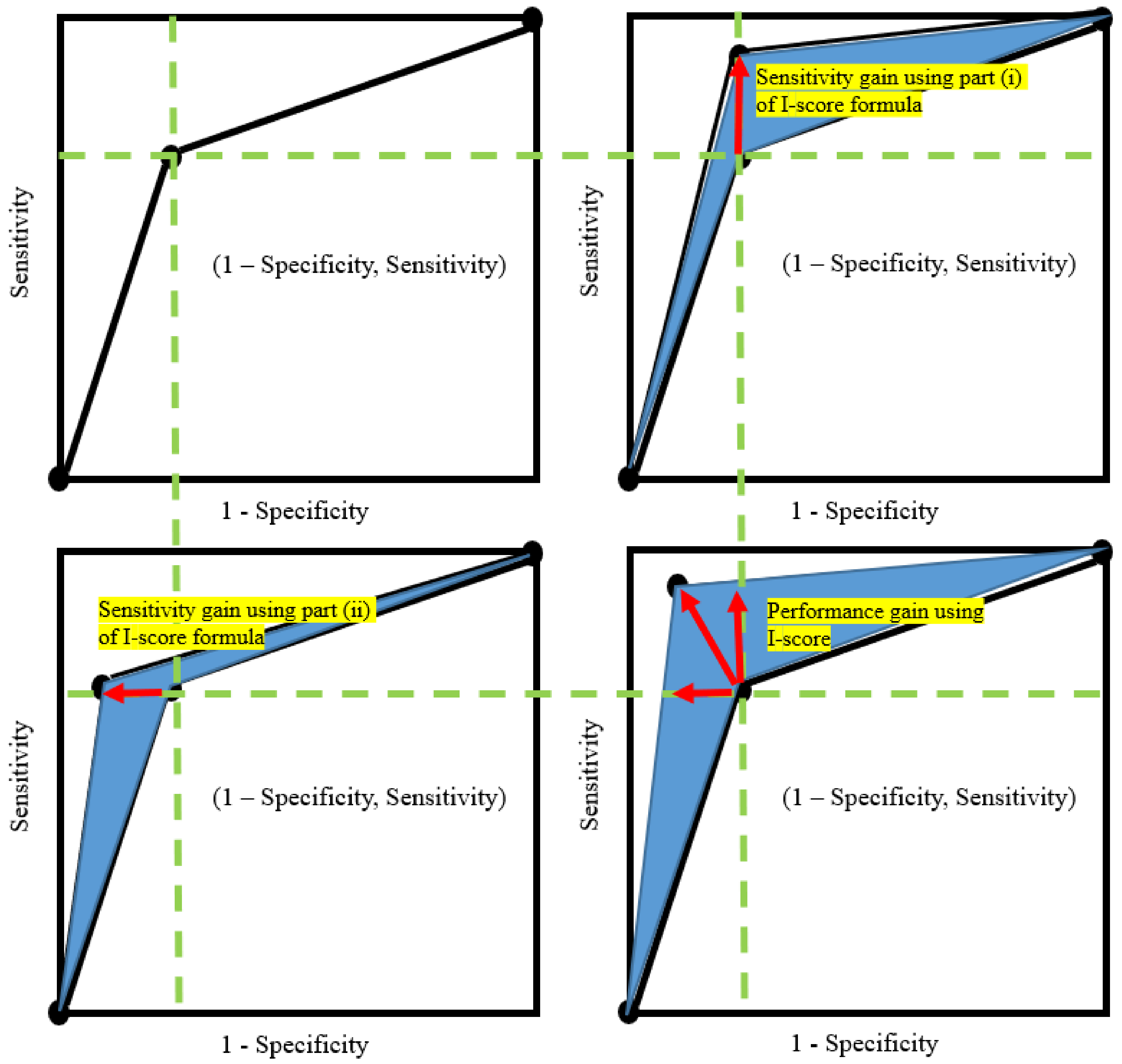
- First, part (i) is a function of sensitivity. More importantly, the I-score serves as a lower bound of sensitivity. The proposed statistics I-score is high when the sensitivity is high, which means the I-score can be used as a metric to select high sensitivity variables. A nice benefit from this phenomenon is that high sensitivity is the most important driving force to raise AUC values. This relationship is presented in the top right plot in Figure 1.
- Second, part (ii) is a function of , which approximates to zero value when the variable is highly predictive. This leaves the second part to be largely determined by the global average of the response variable Y but scaled up in proportion with the number of observations that fall in the second partition (), which is the sum . An interesting benefit from this phenomenon is that the near-zero value, jointly with part (i), implies that the specificity is high, which is another important driving force to raise AUC values. In other words, when the predictor has all the information to make a good prediction, the value of is expected to be approximately zero. In addition, the global mean of the true condition can be written as . Hence, this means that part (ii) can be rewritten as , where positively affect specificity because specificity is . Thus, part (ii) is a function of specificity.
- Third, the I-score is capable of measuring the variable set as a whole without making any assumption of the underlying model. However, AUC is defined between a response variable Y and a predictor . If a variable set has more than one variable, some underlying assumptions of the model need to be made—we would need —in order to compute the AUC value.
Remark
2.2. An Interaction-Based Feature: Dagger Technique
2.3. Discretization
| Algorithm 1:Discretization. Procedure of Discretization for an Explanatory Variable |
 |
2.4. Backward Dropping Algorithm
| Algorithm 2:BDA. Procedure of the Backward Dropping Algorithm (BDA) |
 |
2.5. A Toy Example
- In the scenario when the data set has many noisy variables and each variable observed does not have any marginal signal, the common practice AUC value will miss the information. This is because AUC still relies on the marginal signal. In addition, AUC is defined under the response variable Y and its predictor , which requires us to make assumptions on the underlying model formulation. This is problematic because the mistakes carried over in making the assumptions can largely affect the outcome of AUC. However, this challenge is not a roadblock for the proposed statistic I-score at all. In the same scenario with no marginal signal, as long as the important variables are involved in the selection, the I-score has no problem signaling us the high predictive power disregarding whether the correct form of the underlying model can be found or not.
- The proposed I-score is defined using the partition of the variable set. This variable set can have multiple variables in it, and the computation of the I-score does not require any assumption of the underlying model. This means the proposed I-score iss not subject to the mistakes carried over in the assumption or searching of the true model. Hence, the I-score is a non-parametric measure.
- The construction of the I-score can also be used to create a new variable that is based on the partition of any variable set. We call this new variable , hence the name “dagger technique”. It is an engineering technique that combines a variable set to form a new variable that contains all the predictive power that the entire variable set can provide. This is a very powerful technique due to its high flexibility. In addition, it can be constructed using the variables with a high I-score value after using the Backward Dropping Algorithm.
| Average AUC | SD. of AUC | Average I-Score | SD. of I-Score | ||
|---|---|---|---|---|---|
| Important | 0.51 | 0.01 | 0.49 | 0.52 | |
| 0.51 | 0.01 | 0.52 | 0.68 | ||
| Noisy | 0.51 | 0.01 | 0.65 | 0.71 | |
| 0.5 | 0.01 | 0.41 | 0.6 | ||
| 0.51 | 0.01 | 0.61 | 0.77 | ||
| 0.5 | 0.01 | 0.27 | 0.29 | ||
| 0.51 | 0.01 | 0.42 | 0.7 | ||
| 0.5 | 0.01 | 0.33 | 0.48 | ||
| 0.51 | 0.01 | 0.49 | 0.68 | ||
| 0.51 | 0.01 | 0.39 | 0.48 | ||
| Guessed models (using ) | model (i): | 0.51 | 0.01 | 749.68 | 0.61 |
| model (ii): | 0.51 | 0.01 | 749.54 | 0.37 | |
| model (iii): | 0.49 | 0.25 | 248.2 | 18.26 | |
| model (iv): | 0.57 | 0.11 | 250.03 | 11.72 | |
| (see Equation (15)) | 1 | 0 | 999.14 | 0.54 | |
| NA | NA | 500.08 | 0.48 | ||
| True model | 1 | 0 | 999.14 | 0.54 |
2.6. Why I-Score?
2.6.1. Why Is I-Score the Best Candidate?
2.6.2. Non-Parametric Nature
2.6.3. High I-Score Produces High AUC Values
2.6.4. I-Score and the “Dagger Technique”
3. Application
3.1. Language Modeling
3.1.1. N-Gram
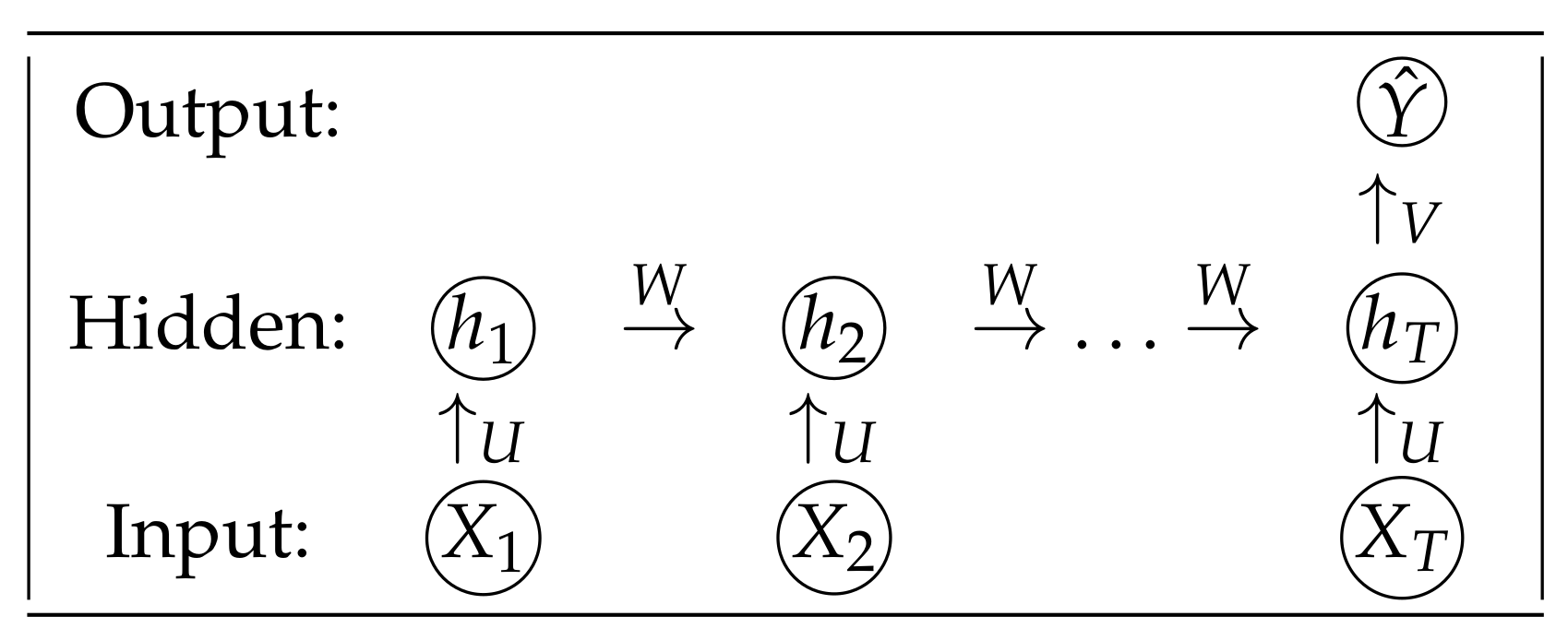
3.1.2. Recurrent Neural Network
3.1.3. Backward Propagation Using Gradient Descent
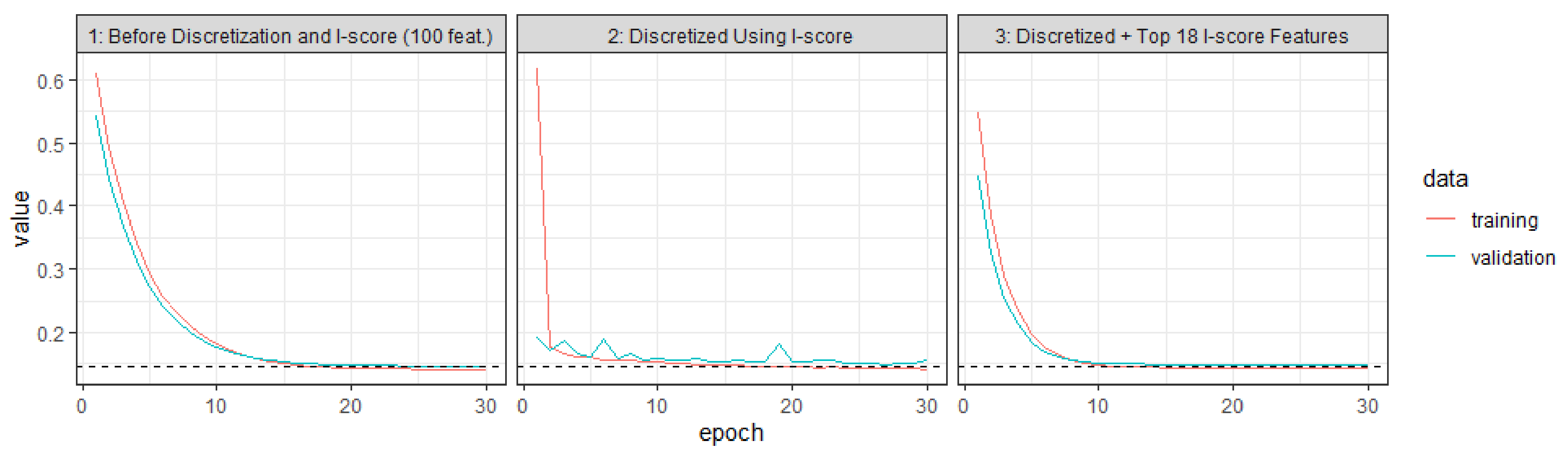
3.1.4. Implementation with I-Score
- First, we can compute the I-score for each RNN unit. For example, in Figure 3A, we can first compute the I-score on the text vectorization layer. Then we can compute the I-score on the embedding layer. With the distribution of the I-score provided from the feature matrix, we can use a particular threshold to identify the cutoff used to screen for important features that we need to feed into the RNN architecture. We denote this action by using , and it is defined as . For the input layer, each feature can be released or omitted according to its I-score values. That is, we use to determine whether this input feature is predictive and important enough to be fed into the RNN architecture. For the hidden layer, each hidden neuron can be released or omitted according to its I-score values. In other words, we can use to determine whether this hidden neuron is important enough to be inserted in the RNN architecture. If at certain t the input feature fails to meet the certain I-score threshold ( would fail if the I-score of is too low, then ), then this feature is not fed into the architecture and the next unit is defined, using Equation (19), as . This is the same for any hidden neuron as well. If a certain hidden neuron has the previously hidden neuron , it fails to meet the I-score criteria, then is defined as . Hence, this function acts as a gate to allow the information of the neuron to pass through according to a certain I-score threshold. If is zero, that means this input feature is not important at all and hence can be omitted by replacing it with a zero value. In other words, it is as if this feature never existed. In this case, there is no need to construct . We show later in Section 3 that important long-term dependencies that are associated with language semantics can be detected using this function because I-score has the power to omit noisy and redundant features in the RNN architecture. Since I-score is compared throughout the entire length of T, the long-term dependencies between features that are far apart can be captured using high I-score values.
- Second, we can use the “dagger technique” to engineer and craft novel features using Equation (15). We can then calculate the I-score on these dagger feature values to see how important they are. We can directly use a 2-gram model, and the I-score is capable of indicating which 2-gram phrases are important. These phrases can act as two-way interactions. According to the I-score, we can then determine whether we want all the words in the 2-gram models, 3-gram models, or even higher level of N-gram models. When n is large, we recommend using the proposed Backward Dropping Algorithm to reduce dimensions within the N-word phrase before creating a new feature using the proposed “dagger technique”. For example, suppose we use the 2-gram model. A sentence such as “I love my cats” can be processed into (I, love), (love, my), (my, cats). Each feature set has two words. We can denote the original sentence “I love my cats” into four features . The “dagger technique” suggests that we can use Equation (15) with 2-gram models fed in as inputs. In other words, we can take and construct , where j is the running index tracking the partitions formed using . If we discretize and (see Section 2.3 for a detailed discussion of discretization using the I-score) and they both take values of , then there are partitions, and hence j can take values of . In this case, the novel feature can take on four values, i.e., an example can be seen in Table 2. The combination of the I-score, Backward Dropping Algorithm, and the “dagger technique” allows us to prune the useful and predictive information in a feature set so that we can achieve maximum prediction power with as few features as possible.
- Third, we can concatenate many N-gram models with different n values. For example, we can carry out N-gram modeling using , , and . This way, we can combine more high-order interactions. In order to avoid overfitting, we can use the I-score to select the important interactions and then use these selected phrases (which can be two-word, three-word, or four-word) to build RNN models.
3.2. IMDB Dataset
| No. | Samples | I-Score Features | Label | |
|---|---|---|---|---|
| Uni–Gram | 2-Gram, 3-Gram | |||
| 1 | this film was just brilliant casting location scenery story direction everyone’s really suited the part they played and you could just imagine being there robert is an amazing actor and now the same being director father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for retail and … | {congratulations, lovely, true} | {amazing actor, really suited} | 1 |
| 2 | big hair big boobs bad music and a giant safety pin these are the words to best describe this terrible movie i love cheesy horror movies and i’ve seen hundreds but this had got to be on of the worst ever made the plot is paper thin and ridiculous the acting is an abomination the script is completely laughable the best is the end showdown with the cop and how he worked out who the killer is it’s just so damn terribly written … | {bad, ridiculous} | {bad music, terribly written}, {damn terribly written} | 0 |
| No. | Samples (Original Paragraphs) | I-Score Features (Using Different Thresholds) | Label | |
|---|---|---|---|---|
| Top 7.5% I-Score | Top 25% I-Score | |||
| 1 | this film was just brilliant casting location scenery story direction everyone’s really suited the part they played and you could just imagine being there robert is an amazing actor and now the same being director father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for retail and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also congratulations to the two little boy’s that played the of … | {congratulations often the play them all a are and should have done you think the lovely because it was true and someone’s life after all that was shared with us all} | {for it really at the so sad you what they at a must good this was also congratulations to two little boy’s that played the <UNK> of norman and paul they were just brilliant children are often left out the praising list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done do not you think the whole story was so lovely because it was true and was someone’s life after all that was shared with us all} | 1 |
| 400 words | 31 words | 101 words | ||
| 2 | big hair big boobs bad music and a giant safety pin these are the words to best describe this terrible movie i love cheesy horror movies and i’ve seen hundreds but this had got to be on of the worst ever made the plot is paper thin and ridiculous the acting is an abomination the script is completely laughable the best is the end showdown with the cop and how he worked out who the killer is it’s just so damn terribly written the clothes are sickening and funny in equal measures the hair is big lots of boobs bounce men wear those cut tee shirts that show off their sickening that men actually wore them and the music is just trash that plays over and over again in almost every scene there is trashy music boobs and … | {those every is trashy music away all aside this whose only is to look that was the 80’s and have good old laugh at how bad everything was back then} | {script best worked who the just so terribly the clothes in equal hair lots boobs men wear those cut shirts that show off their sickening that men actually wore them and the music is just trash that over and over again in almost every scene there is trashy music boobs and taking away bodies and the gym still does not close for all joking aside this is a truly bad film whose only charm is to look back on the disaster that was the 80’s and have a good old laugh at how bad everything was back then} | 0 |
| 400 words | 31 words | 101 words | ||
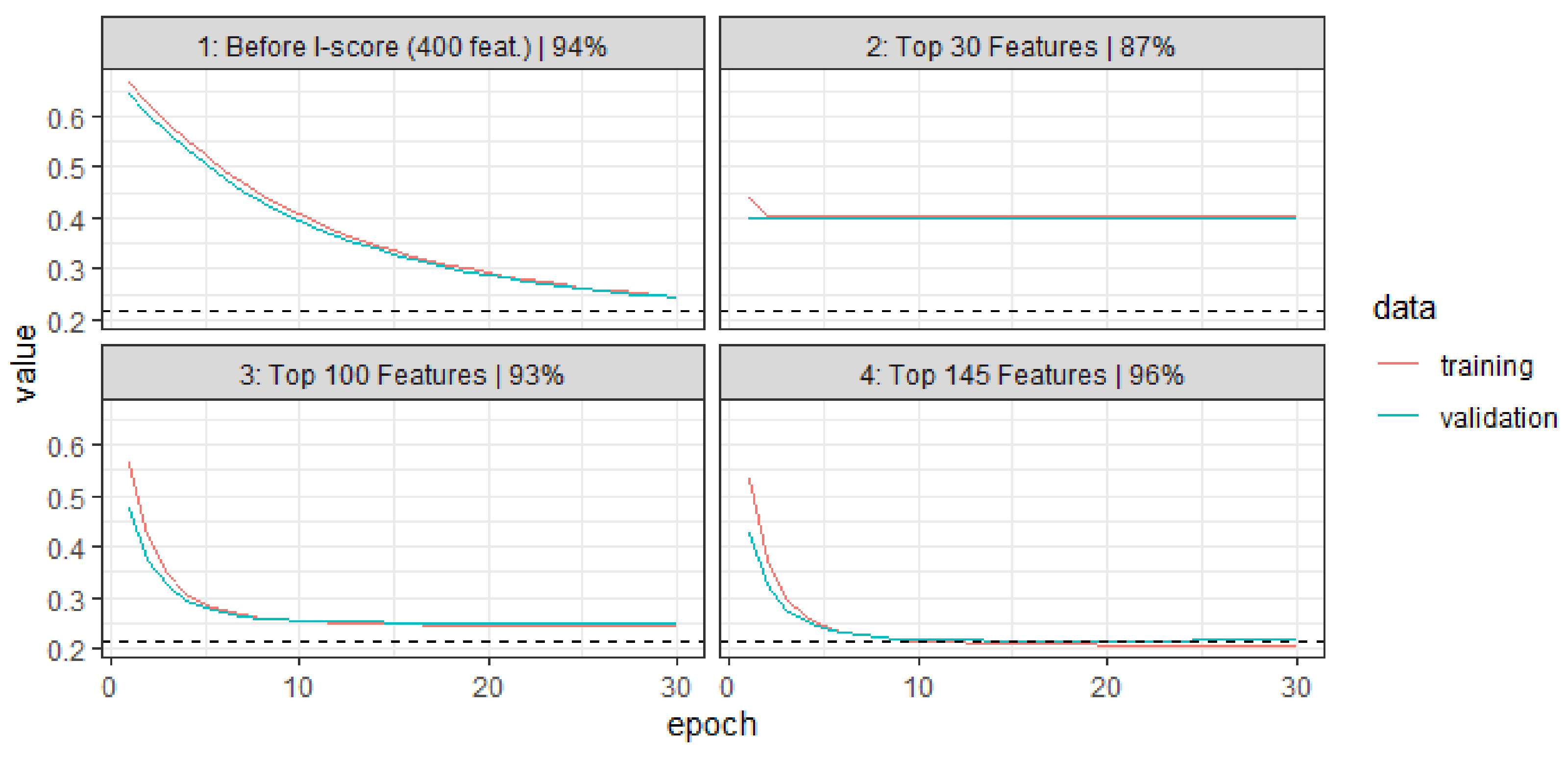
3.3. Results
| Model | IMDB (Test Set) |
|---|---|
| CNN [33] | 37.5% |
| RNN | 85.7% |
| LSTM | 86.6% |
| GRU | 86.7% |
| 2-gram | 92.2% |
| 2-gram + 3-gram | 91.1% |
| 2-gram + 3-gram + 4-gram | 90.2% |
| Average: | 81% |
| Proposed: | |
| 2-gram: use high I-score features | 96.5% |
| 2-gram + 3-gram: use high I-score features | 96.7% |
| 2-gram + 3-gram + 4-gram: use high I-score features | 97.2% |
| 2-gram + 3-gram + 4-gram: use novel “dagger” features (based on Equation (15)) | 97.2% |
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Salehinejad, H.; Sankar, S.; Barfett, J.; Colak, E.; Valaee, S. Recent advances in recurrent neural networks. arXiv 2017, arXiv:1801.01078. [Google Scholar]
- Bengio, Y.; Boulanger-Lewandowski, N.; Pascanu, R. Advances in optimizing recurrent networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8624–8628. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, M.A.; Popescu, A.C.; Oane, M.; Channa, A.; Mihai, S.; Ristoscu, C.; Mihailescu, I.N. Bridging the analytical and artificial neural network models for keyhole formation with experimental verification in laser-melting deposition: A novel approach. Results Phys. 2021, 26, 104440. [Google Scholar] [CrossRef]
- Mahmood, M.A.; Visan, A.I.; Ristoscu, C.; Mihailescu, I.N. Artificial neural network algorithms for 3d printing. Materials 2021, 14, 163. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Networks 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Hinton, G.E. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Spirovski, K.; Stevanoska, E.; Kulakov, A.; Popeska, Z.; Velinov, G. Comparison of different model’s performances in task of document classification. In Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics, Novi Sad, Serbia, 25–27 June 2018; pp. 1–12. [Google Scholar]
- Jayawant, N. Mandrekar. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 2010, 5, 1315–1316. [Google Scholar]
- Halligan, S.; Altman, D.G.; Mallett, S. Disadvantages of using the area under the receiver operating characteristic curve to assess imaging tests: A discussion and proposal for an alternative approach. Eur. Radiol. 2015, 25, 932–939. [Google Scholar] [CrossRef] [Green Version]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef]
- Bengio, Y.; LeCun, Y. Scaling learning algorithms towards ai. Large-Scale Kernel Mach. 2007, 34, 1–41. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machine. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2017. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1989, 2, 396–404. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Chernoff, H.; Lo, S.H.; Zheng, T. Discovering influential variables: A method of partitions. Ann. Appl. Stat. 2009, 3, 1335–1369. [Google Scholar] [CrossRef] [Green Version]
- Lo, A.; Chernoff, H.; Zheng, T.; Lo, S.H. Why significant variables aren’t automatically good predictors. Proc. Natl. Acad. Sci. USA 2015, 112, 13892–13897. [Google Scholar] [CrossRef] [Green Version]
- Lo, A.; Chernoff, H.; Zheng, T.; Lo, S.H. Framework for making better predictions by directly estimating variables’ predictivity. Proc. Natl. Acad. Sci. USA 2016, 113, 14277–14282. [Google Scholar] [CrossRef] [Green Version]
- Lo, S.H.; Yin, Y. An interaction-based convolutional neural network (icnn) towards better understanding of COVID-19 x-ray images. arXiv 2021, arXiv:2106.06911. [Google Scholar]
- Lo, S.H.; Yin, Y. A novel interaction-based methodology towards explainable ai with better understanding of pneumonia chest x-ray images. arXiv 2021, arXiv:2104.12672. [Google Scholar]
- Lo, S.H.; Zheng, T. Backward haplotype transmission association algorithm—A fast multiple-marker screening method. Hum. Hered. 2002, 53, 197–215. [Google Scholar] [CrossRef] [Green Version]
- Carrington, A.M.; Fieguth, P.W.; Qazi, H.; Holzinger, A.; Chen, H.H.; Mayr, F.; Manuel, D.G. A new concordant partial auc and partial c statistic for imbalanced data in the evaluation of machine learning algorithms. BMC Med. Inform. Decis. Mak. 2020, 20, 4. [Google Scholar] [CrossRef] [PubMed]
- Baker, S.G. The central role of receiver operating characteristic (roc) curves in evaluating tests for the early detection of cancer. J. Natl. Cancer Inst. 2003, 95, 511–515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, Y.; Levy, O. word2vec explained: Deriving mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective lstms for target-dependent sentiment classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]





| Name | Function | Figure | Derivative |
|---|---|---|---|
| Sigmoid |  | ||
| tanh |  | ||
| ReLU |  |

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo, S.-H.; Yin, Y. Language Semantics Interpretation with an Interaction-Based Recurrent Neural Network. Mach. Learn. Knowl. Extr. 2021, 3, 922-945. https://doi.org/10.3390/make3040046
Lo S-H, Yin Y. Language Semantics Interpretation with an Interaction-Based Recurrent Neural Network. Machine Learning and Knowledge Extraction. 2021; 3(4):922-945. https://doi.org/10.3390/make3040046
Chicago/Turabian StyleLo, Shaw-Hwa, and Yiqiao Yin. 2021. "Language Semantics Interpretation with an Interaction-Based Recurrent Neural Network" Machine Learning and Knowledge Extraction 3, no. 4: 922-945. https://doi.org/10.3390/make3040046
APA StyleLo, S. -H., & Yin, Y. (2021). Language Semantics Interpretation with an Interaction-Based Recurrent Neural Network. Machine Learning and Knowledge Extraction, 3(4), 922-945. https://doi.org/10.3390/make3040046