
A Novel Feature Representation for Prediction of Global Horizontal Irradiance Using a Bidirectional Model

 ,
,
Abstract
:1. Introduction
- Bidirectional GRU is applied for the first time to solar energy forecasting, and it is shown to be better performing than other common sequence models, such as unidirectional LSTM, Bidirectional-LSTM (BLSTM), and Unidirectional GRU.
- A new feature representation with a bidirectional nature is proposed, which further augments the performance of BGRU. The model shows improved performance compared to two state-of-the-art models.
- The performance of the model is validated on real-life data from six solar stations from three climatic zones and in two seasons in India.
2. Forecasting Models for Renewable Energy
2.1. Machine Learning Based Models
2.2. Deep-Learning-Based Models
3. Detailed Working of the Deep-Learning-Based Models
3.1. Sequential Deep Learning Models
- The GRU model, rather than any sequential model, is trained by selecting a continuous portion or window from the input data. Instead of taking all such windows for training, it is often broken into batches.
- If the batches are considered dependent on each other, then it is called a stateful model.
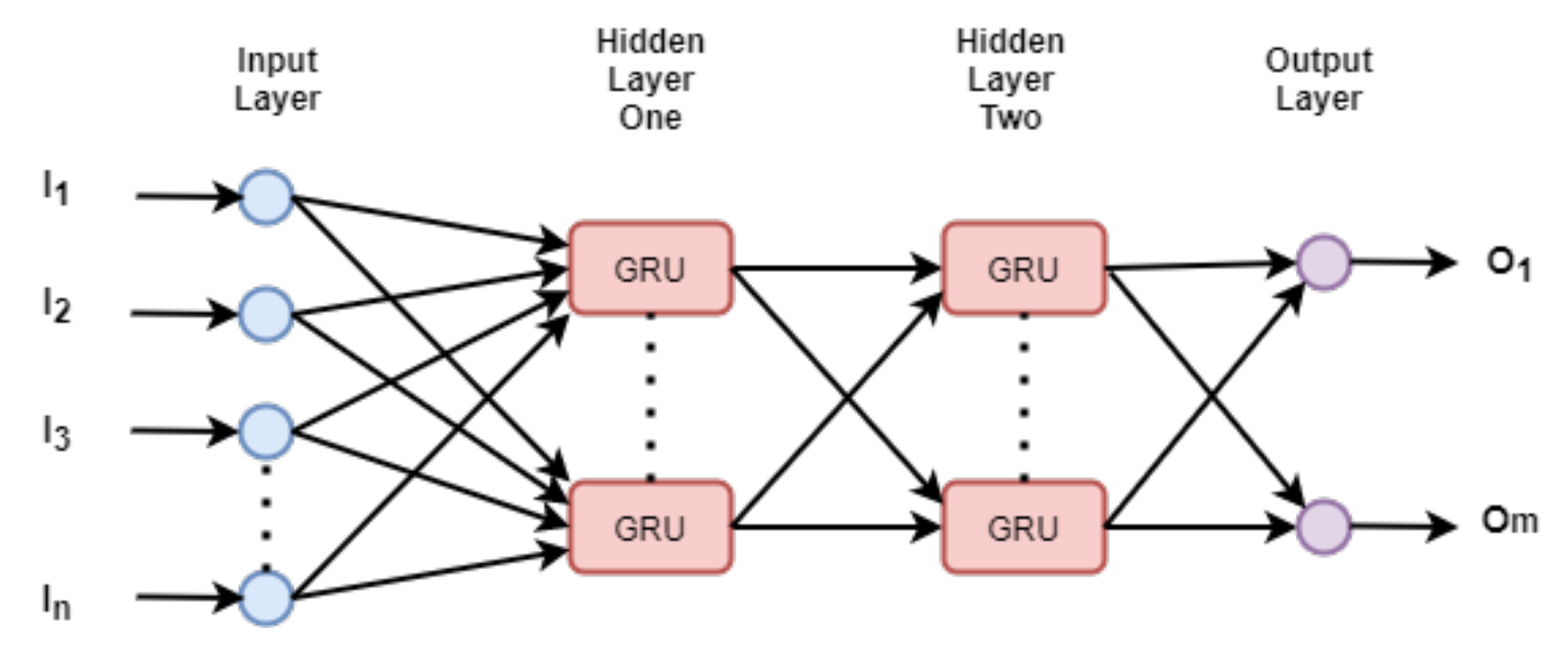
- Typically, when dealing with the sequence data, the hidden layer nodes are any sequential cells. In Figure 1, a simple schematic diagram of a deep neural network is shown, whereas a basic building block in the hidden layers, the GRU cells are used. The inputs and the outputs are denoted as [, , , …, ], and [, …, ] respectively.
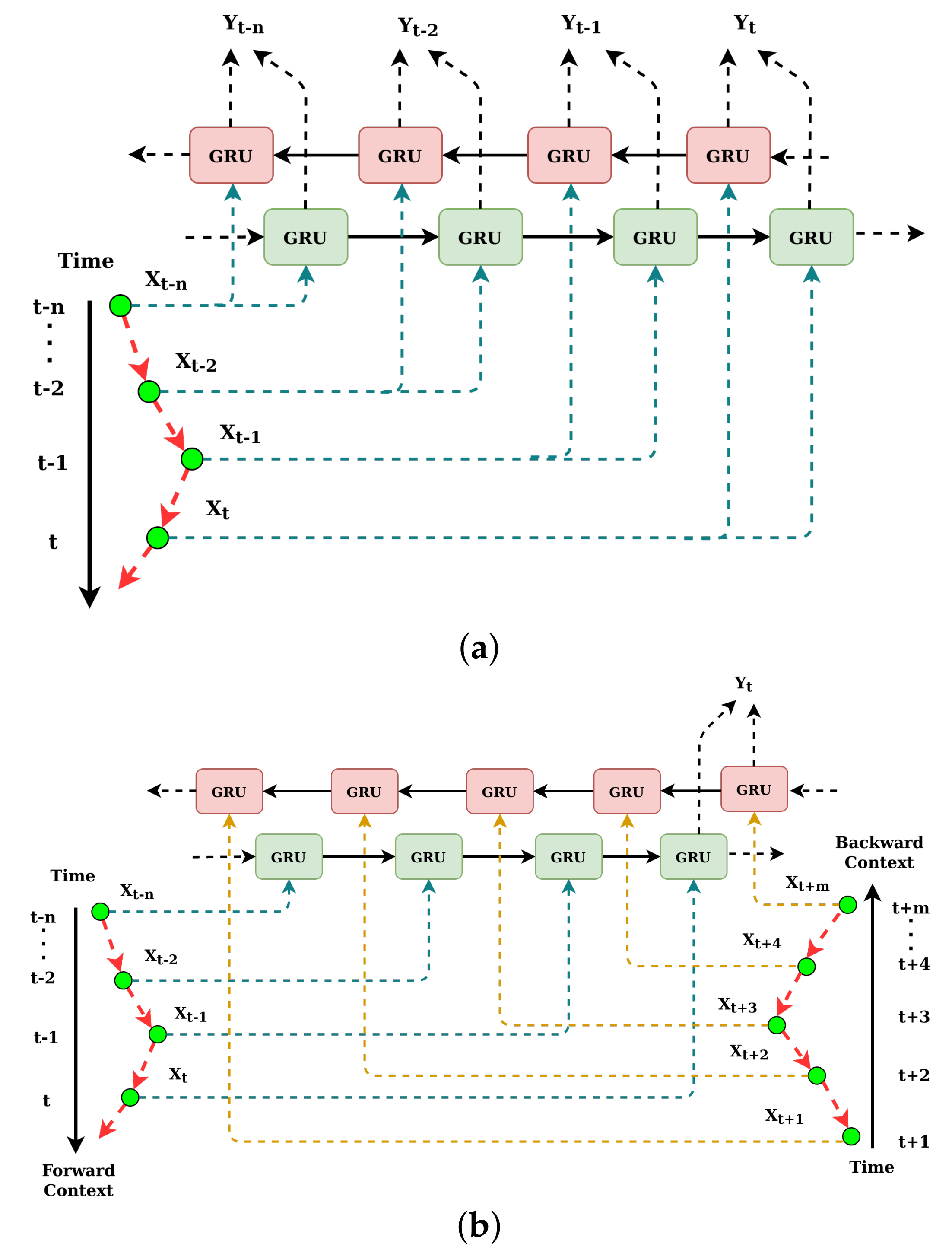
- BGRU is a fusion of two independent unidirectional GRU layers when one layer maintains the forward hidden states whereas the other maintains the backward hidden states. In the forward pass, BGRU processes inputs sequence as …, , , , for the time steps …, , , , t, and, in the backward pass, BGRU processes the input sequence for the time steps t, , , , …in the reverse direction.
- After both forward and backward passes were completed, the hidden states are concatenated to form a final single set of hidden states.
- Then, the final hidden states go through a densely connected layer to produce the output sequence as …, , , , .
3.2. Feature Preparation for Sequential Models
- 1.
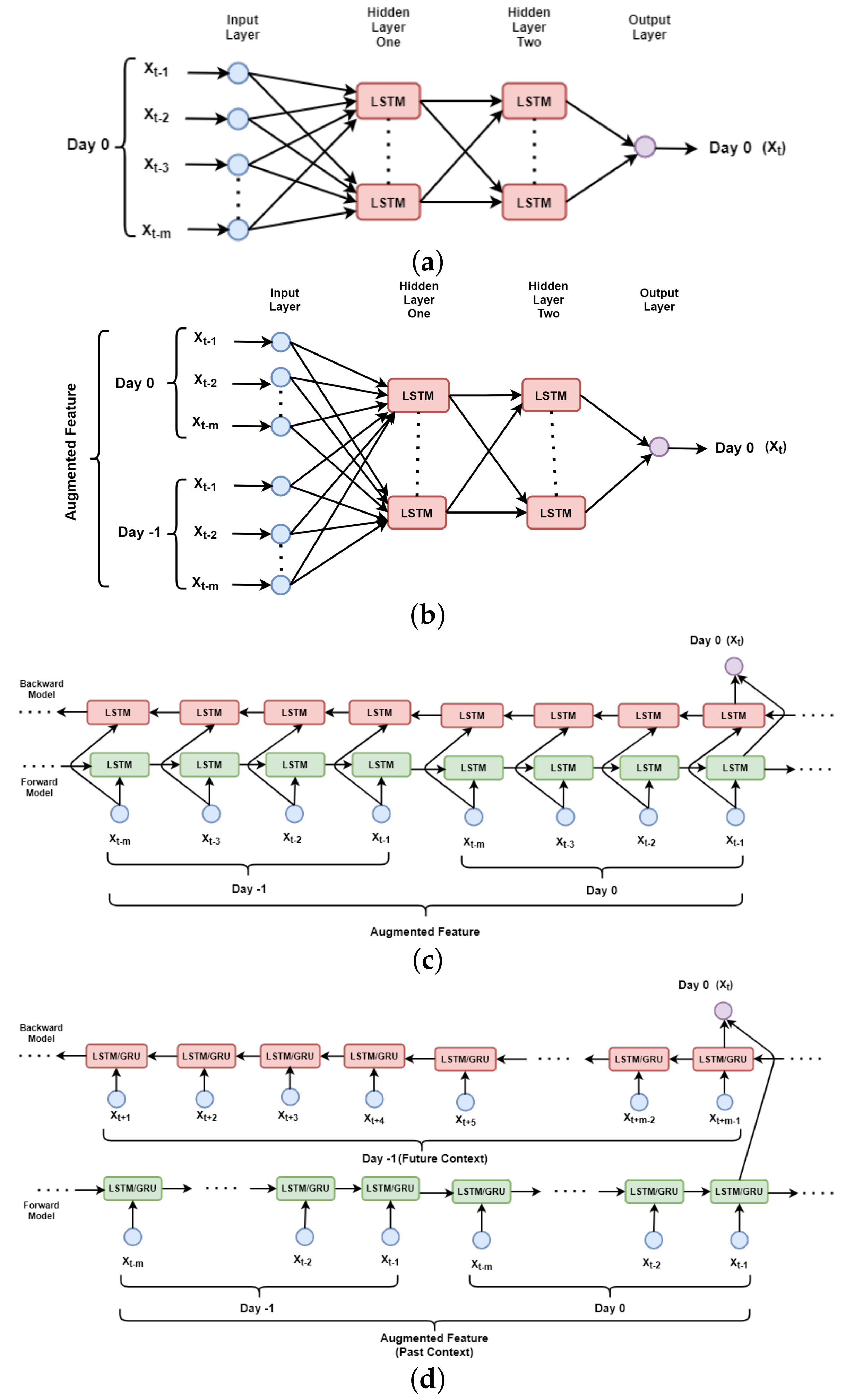
- ULSTM: In Figure 3a, the high-level block diagram of ULSTM is presented. In this case, to predict solar irradiation for the time step t as , usually, the past context of the same day is used. For example, to predict , the input sequence is defined as [,…,,]. The traditional sliding window approach was used to represent the whole feature set. The length of the window is denoted as m.
- 2.
- M-ULSTM: As with the previous feature representation, this also uses past values, and hence is a unidirectional model. However, the past context is augmented here, with the previous values, corresponding to the same time. In Figure 3b, the high-level block diagram of M-ULSTM is presented. For example, for predicting solar irradiation for the time step t as for we not only used the same day past sequence denoted as [,…,,] but also values from previous day denoted as [,…,,].
- 3.
- BLSTM: This is the traditional variant of bidirectional LSTM, where the same context is used to train the model both from forward and backward directions. Figure 3 b depicts the block diagram of BLSTM. In this architecture, the same augmented features were used in both the left and right contexts.
- 4.
- BD-BLSTM and BD-BGRU: In the case of time-series prediction problems, such as text data, traditional bidirectional deep-learning models use the same past sequence for both the forward and backward context. In this paper, a simple technique is proposed, first to augment the past context and next to construct future context from previous day. The model used here is more generalized allowing the past and future context to be of unequal length. In Figure 3d, the block diagram of this proposed bidirectional feature set with BLSTM and BGRU is presented. The right or backward context is collected from the previous day denoted as [,…,,].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Input Sequence | Remarks |
|---|---|---|
| ULSTM | [,…,,] | Same day m input time steps |
| M-ULSTM | Augmented Feature {[,…,,] [,…,,]} | Same day m input time steps are augmented with previous day m time steps |
| BLSTM | = Augmented Feature {[,…,,] [,…,,]} = Augmented Feature {[,…,,] [,…,,]} | Same day m input time steps along with previous day m time steps is used as both forward and backward context |
| BD-BLSTM/ BD-BGRU | Augmented Feature {[,…,,] [,…,,]} [,…,,] | Same day m input time steps along with previous day m time steps is used as forward context and augmented with previous day m future time steps as backward context |

4. Materials and Methods
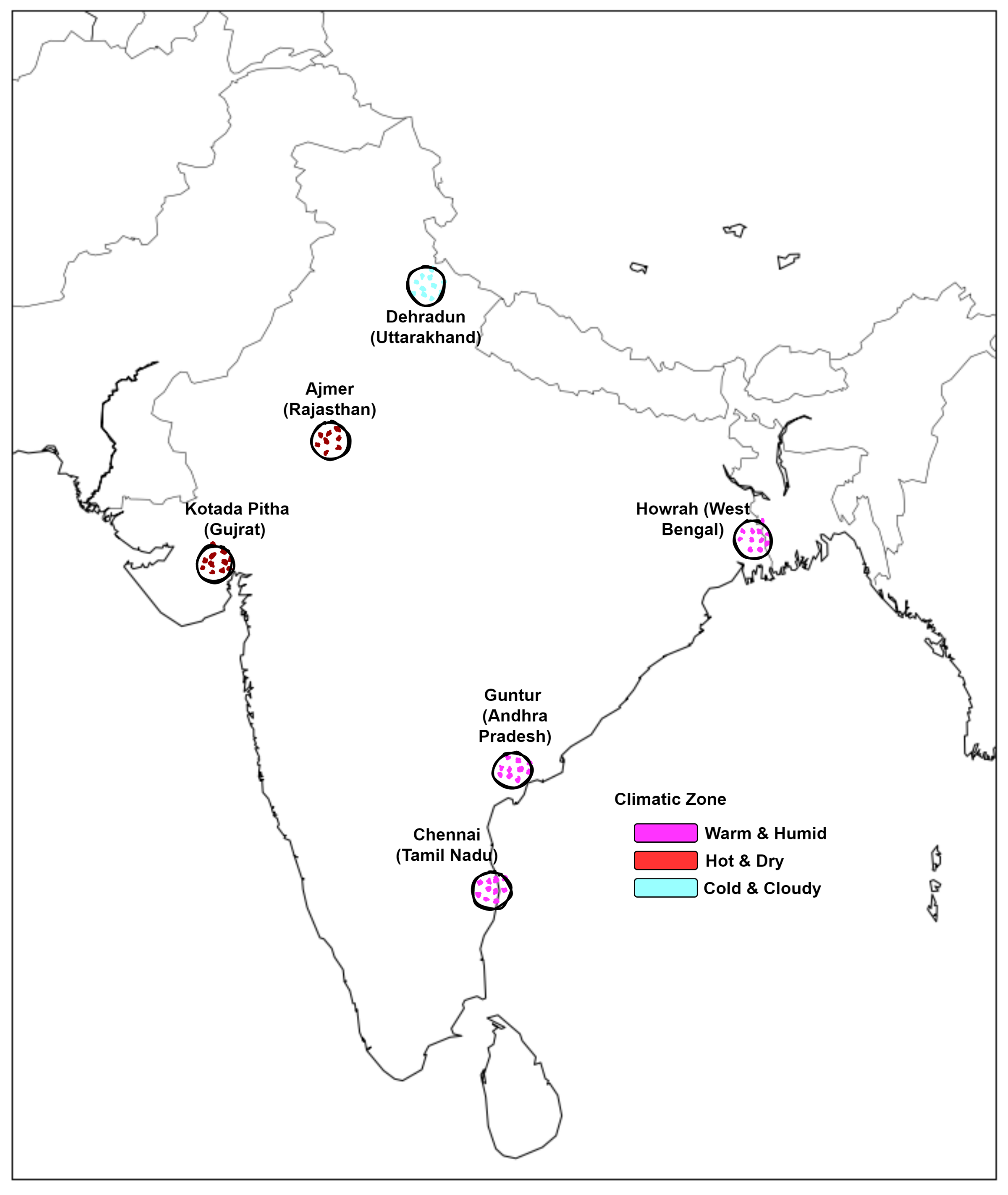
4.1. Data-Set Description
4.2. Data Pre-Processing
- 1.
- For each station–month combination, to remove night hours, only the measurements of GHI between 7 a.m. to 7 p.m. were used.
- 2.
- After that, the GHI values for each day were aggregated into five minutes, and then merged for all the days in a single time-series. The time-series should be formatted as a three-dimensional array, where the three dimensions are the size of the batch, number of time-steps (Window Size), and number of input features. In a single window, 20 time-steps of GHI were used. Batch size refers to the number of training samples used at the time of the training phase for one iteration. We used 100 training samples in a batch. During the learning process, successive batches are used to train the network.
- 3.
- Finally, GHI values were normalized in between [−1,1] using the following transformation (5).
4.3. Experimental Setup
- Different architectures of LSTM and GRU were developed using the Keras [48] API in python. For bidirectional models, three hidden layers, and for the traditional LSTM, two hidden layers were used.
- In the input layer of both LSTM and GRU, different choices of input size, i.e., sequential length were varied from 20 to 60 steps.
- In the output layer, the 20-time steps were predicted, which is 100 min in this case.
- For the bidirectional models, two sequential models were applied separately. Prediction were made from the forward direction by one model and from the backward direction by the other model. Finally, by combining both predictions, the actual decision is made.
- In the output layer, 20 neurons with linear activation were used. For traditional LSTM, the same non-linear activation tanh [49] was used, and in the output layer, linear activation was used.
- All models are trained on Adaptive Moment Estimation (Adam) [50] optimizer. For all the implemented models, different hyper-parameters [51], such as learning rate, the number of nodes in different hidden layers, batch size, and the number of epochs were optimized using Bayesian Optimization [52] approach. In this context, the Tree-structured Parzen Estimator (TPE) [53] algorithm of Hyperopt [54] package in python is used. In Table 4, the details of all the hyper-parameters were enlisted.
4.4. Comparison with Other Models
4.5. Performance Metrics
5. Results and Discussions
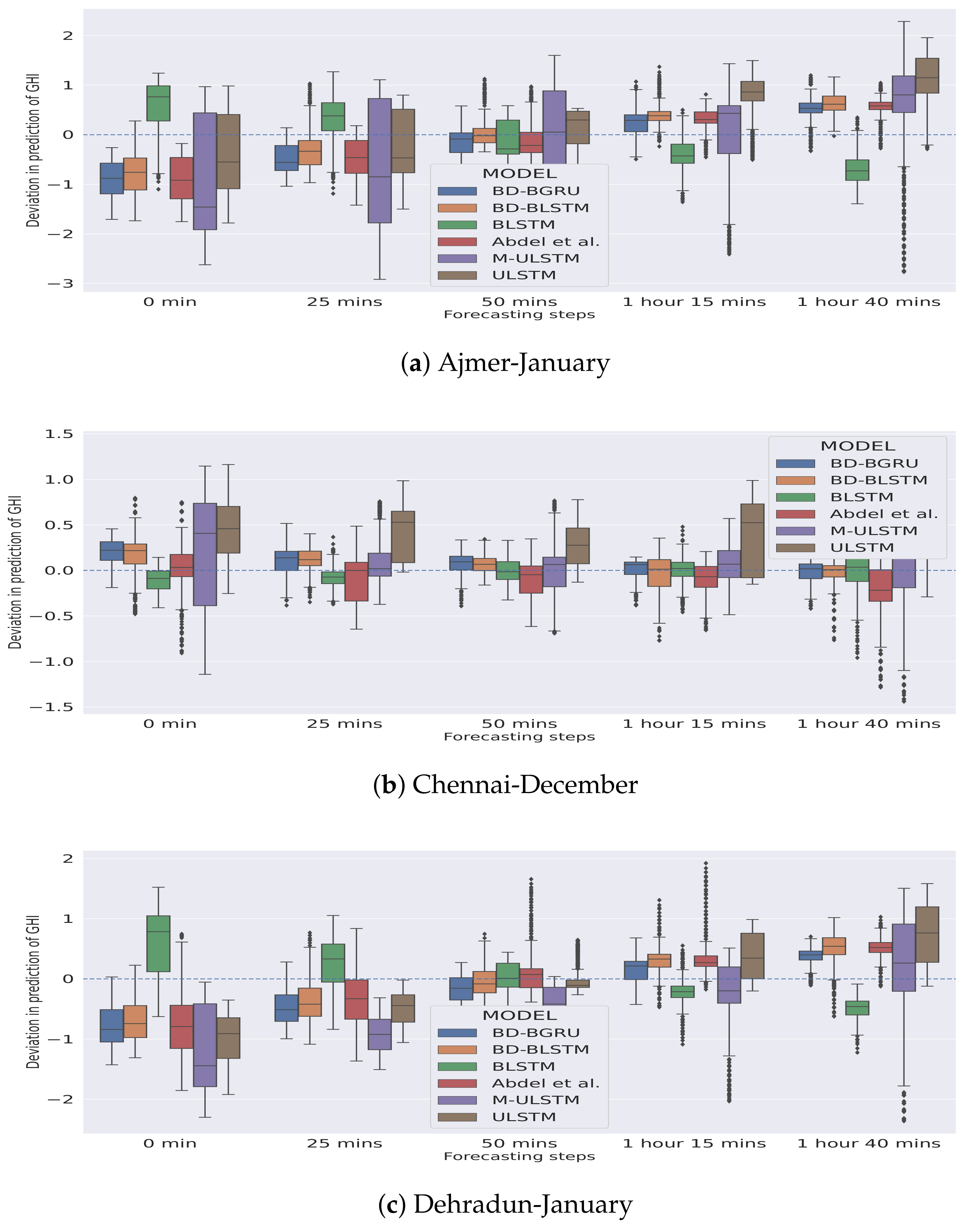
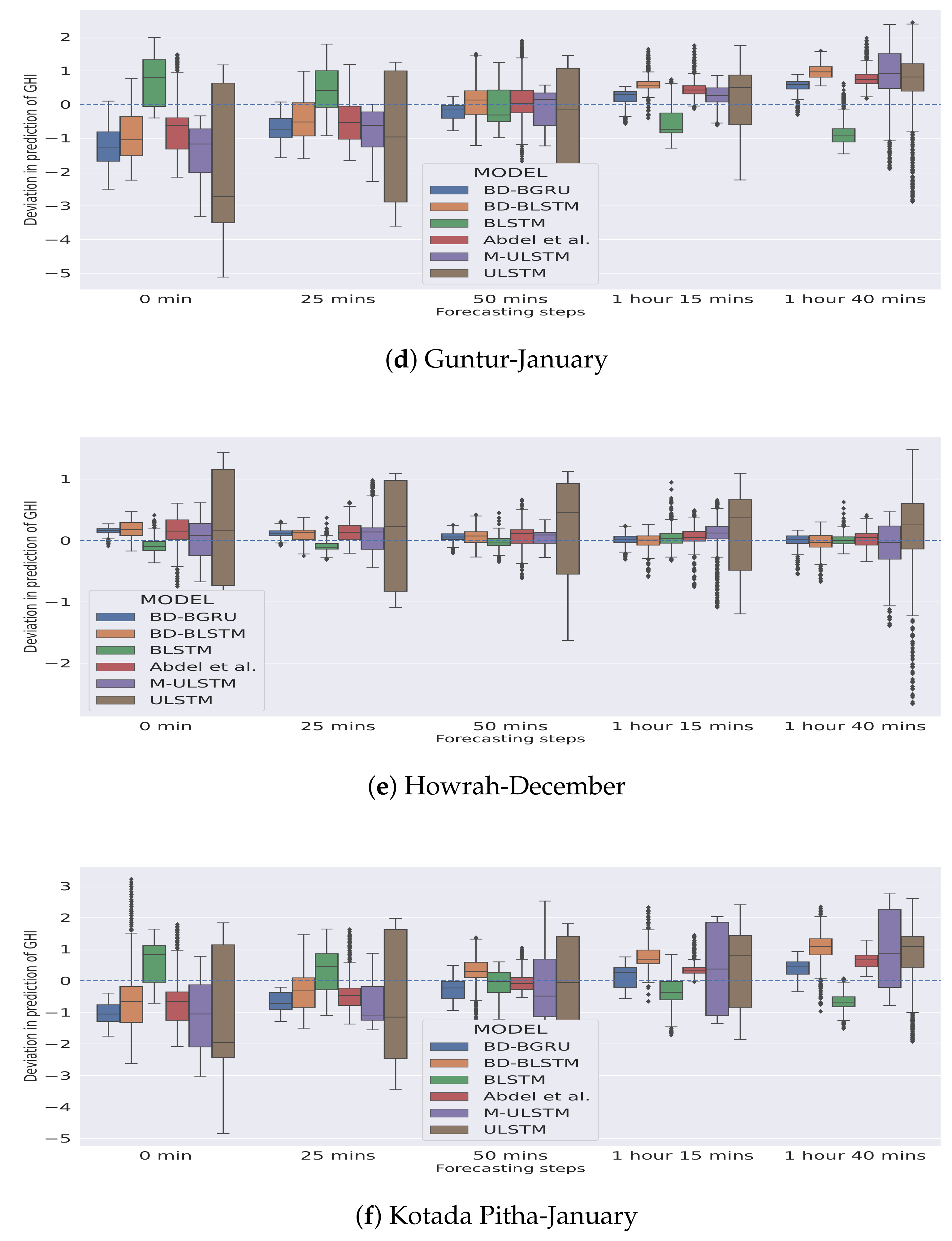
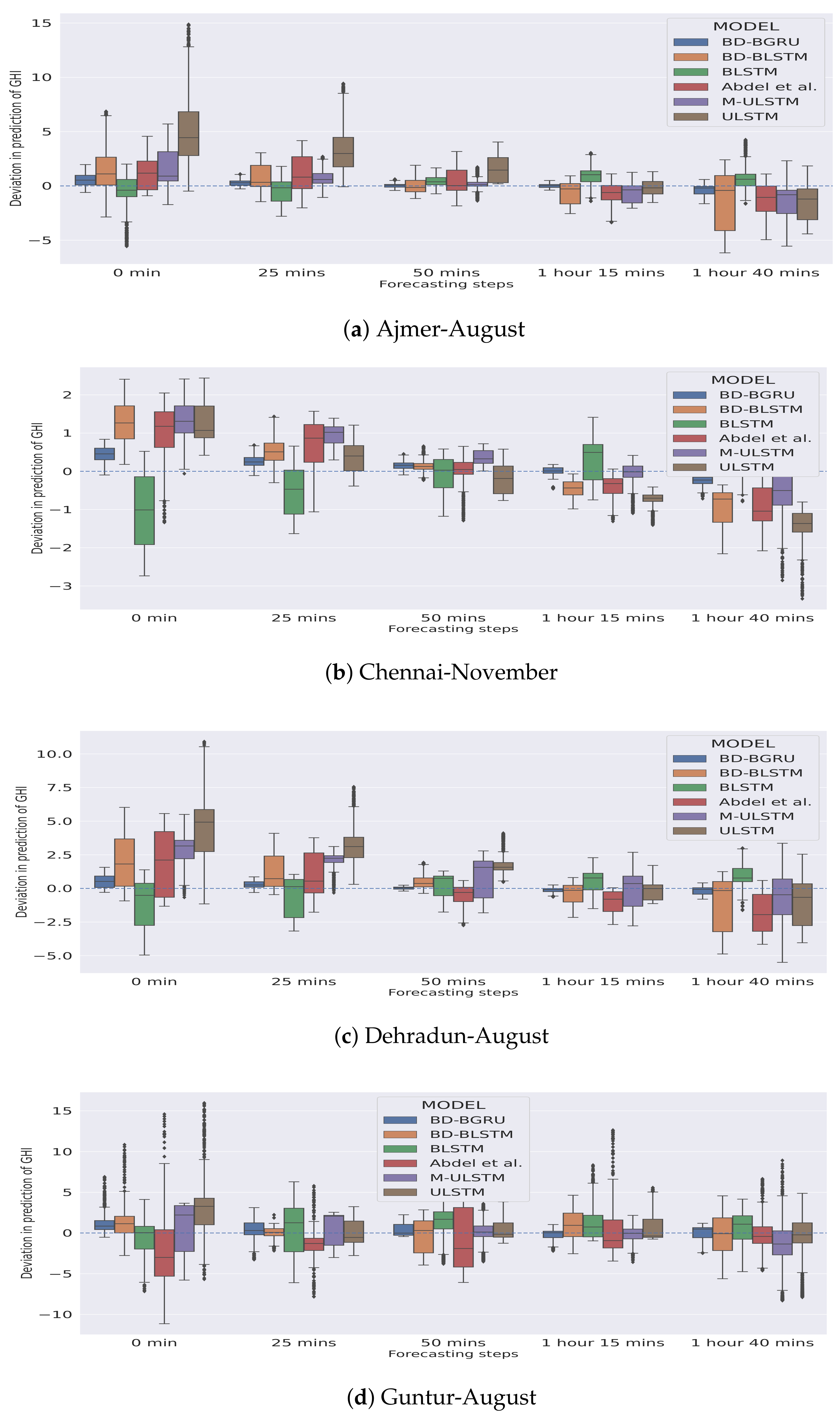
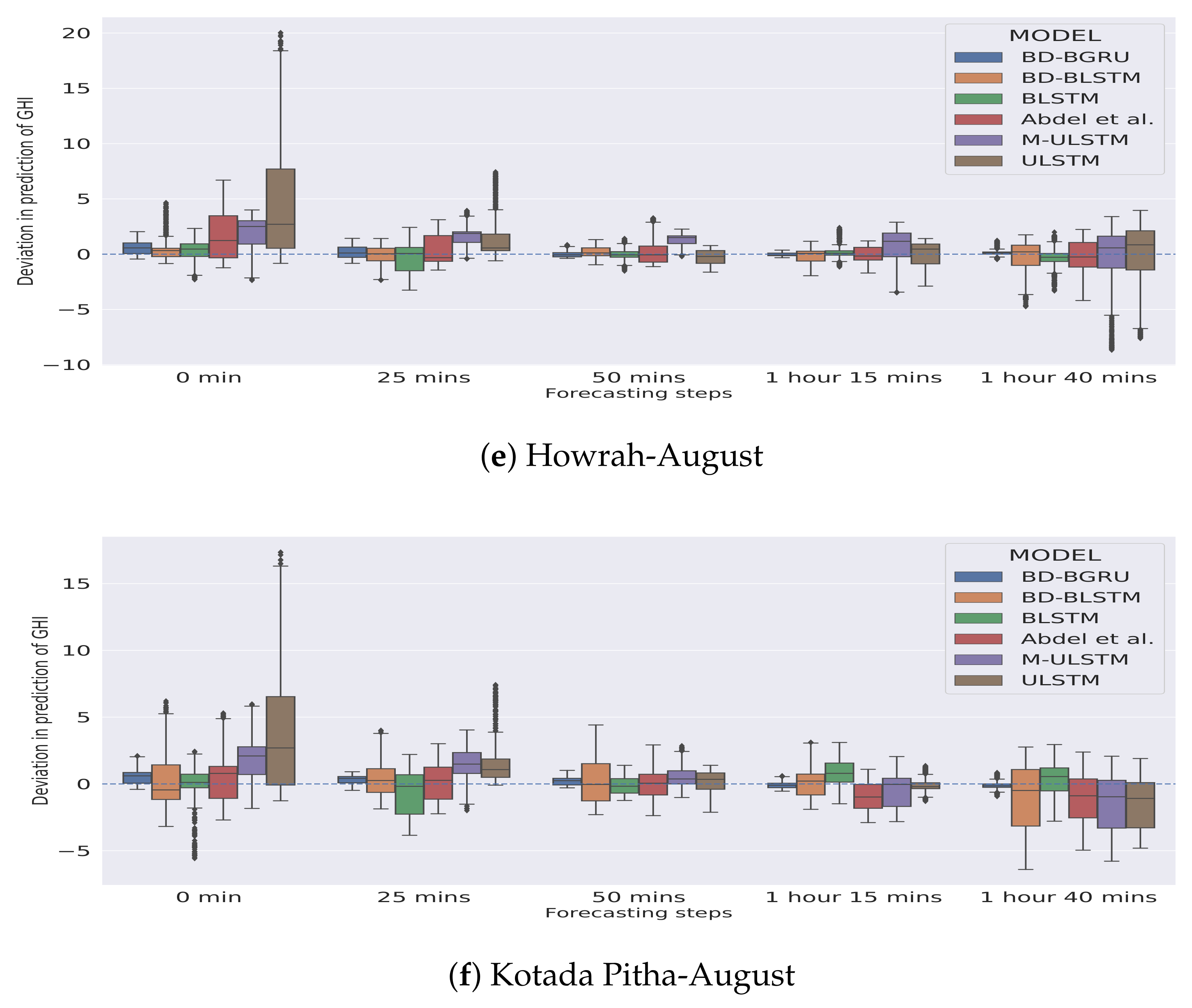
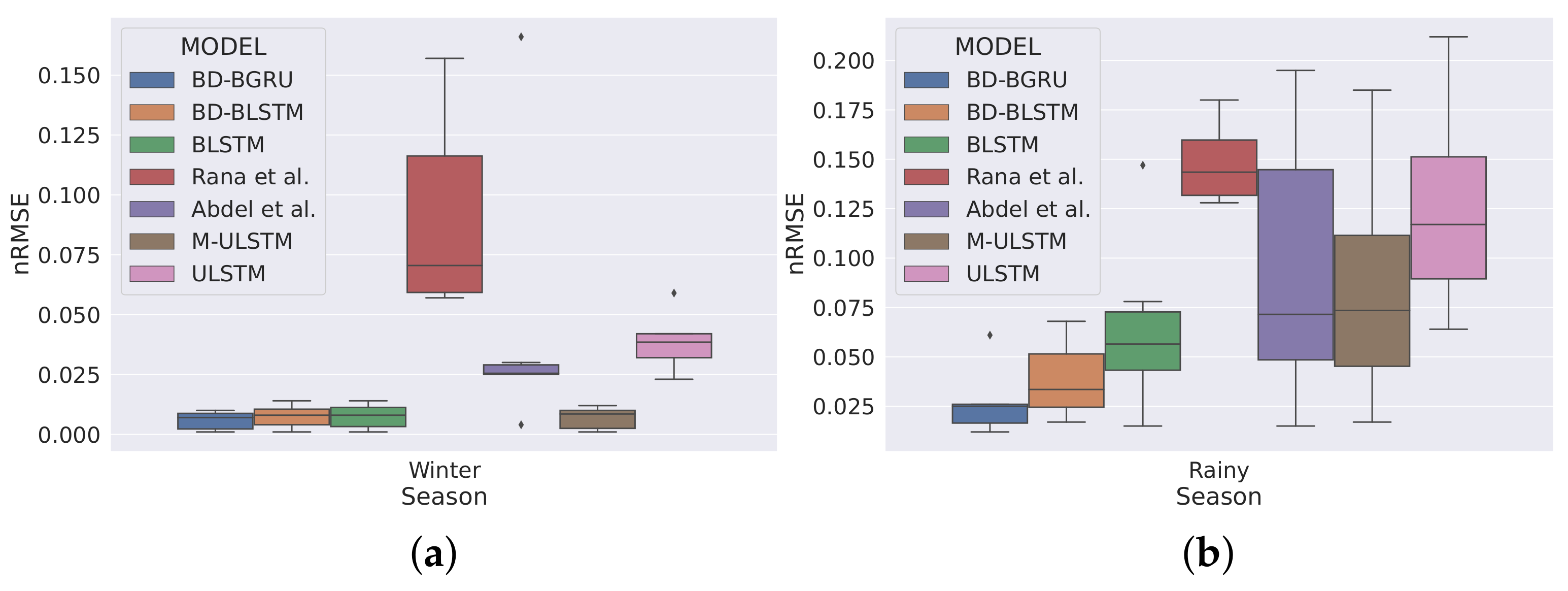
5.1. Forecasting Performance of M-ULSTM over ULSTM
5.2. Forecasting Performance of BLSTM over M-ULSTM
5.3. Forecasting Performance of BD-BLSTM and BD-BGRU over BLSTM
- BD-BLSTM:Winter: In the winter season, BD-BLSTM dominated BLSTM by 4.04%.Rainy: In the rainy season, BD-BLSTM outperformed BLSTM by 31.81%.Variability: BD-BLSTM achieved lower standard deviation compared to BLSTM.
- BD-BGRU:Winter: In the winter season, BD-BGRU outperformed BLSTM by 21.49%.Rainy: In the rainy season, BD-BGRU outperformed BLSTM by 53.45%.Variability: BD-BGRU achieved a lower standard deviation compared to BLSTM.
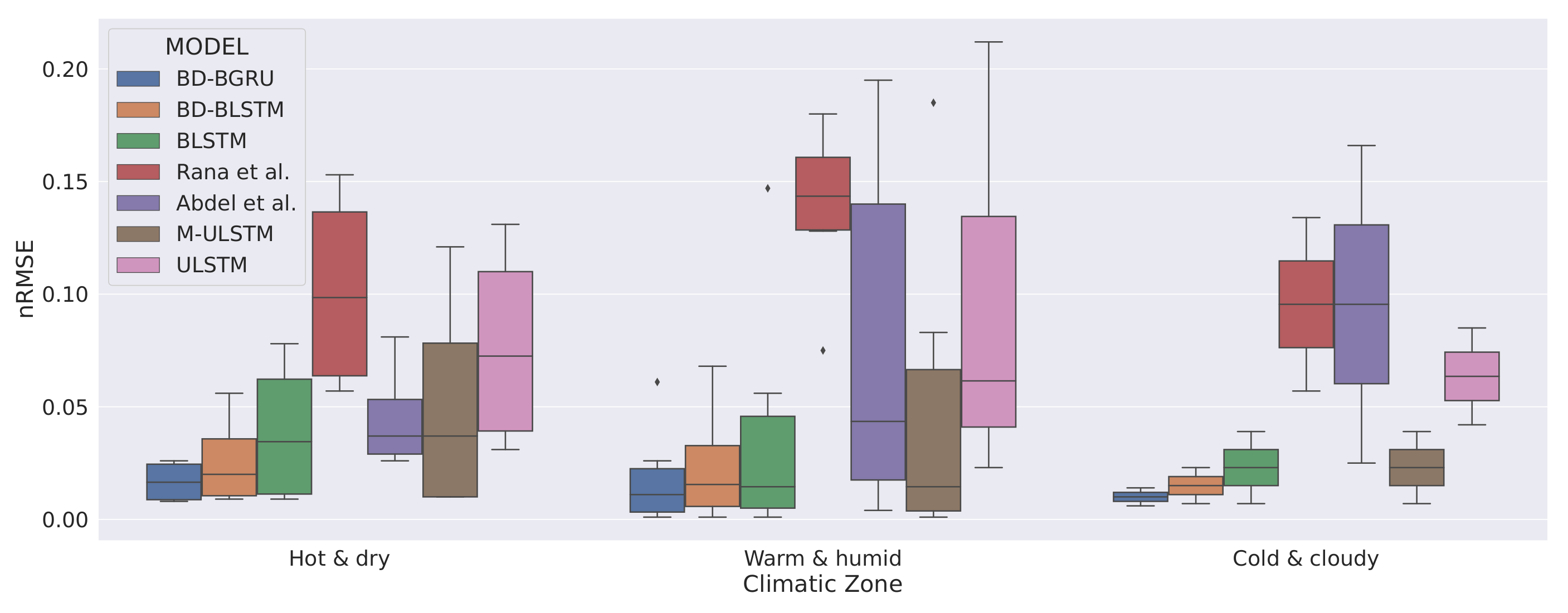
5.4. Overall Forecasting Performance of BD-BGRU
5.5. Comparison with Other Models
- We observed that BD-BGRU achieved the lowest overall nRMSE score compared to all the other models. In terms of overall forecasting accuracy, BD-BGRU dominated BD-BLSTM by 30.43%.
- BD-BGRU achieved the lowest standard deviation as 0.016. It implies that in the case of BD-BGRU the variance in predictions of GHI is minimum.
- BD-BGRU has also achieved the lowest mean rank as 1.16 compared to the other models.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Prăvălie, R.; Patriche, C.; Bandoc, G. Spatial assessment of solar energy potential at global scale. A geographical approach. J. Clean. Prod. 2019, 209, 692–721. [Google Scholar] [CrossRef]
- Dudley, B. BP statistical review of world energy. BP Stat. Rev. Lond. UK 2018, 6, 00116. [Google Scholar]
- Fliess, M.; Join, C.; Voyant, C. Prediction bands for solar energy: New short-term time series forecasting techniques. Sol. Energy 2018, 166, 519–528. [Google Scholar] [CrossRef] [Green Version]
- Pan, C.; Tan, J.; Feng, D. Prediction intervals estimation of solar generation based on gated recurrent unit and kernel density estimation. Neurocomputing 2020, 453, 552–562. [Google Scholar] [CrossRef]
- Alzahrani, A.; Shamsi, P.; Dagli, C.; Ferdowsi, M. Solar irradiance forecasting using deep neural networks. Procedia Comput. Sci. 2017, 114, 304–313. [Google Scholar] [CrossRef]
- Hejase, H.A.; Al-Shamisi, M.H.; Assi, A.H. Modeling of global horizontal irradiance in the United Arab Emirates with artificial neural networks. Energy 2014, 77, 542–552. [Google Scholar] [CrossRef]
- Lai, C.S.; Zhong, C.; Pan, K.; Ng, W.W.; Lai, L.L. A deep learning based hybrid method for hourly solar radiation forecasting. Expert Syst. Appl. 2021, 177, 114941. [Google Scholar] [CrossRef]
- Abdel-Nasser, M.; Mahmoud, K. Accurate photovoltaic power forecasting models using deep LSTM-RNN. Neural Comput. Appl. 2019, 31, 2727–2740. [Google Scholar] [CrossRef]
- Qing, X.; Niu, Y. Hourly day-ahead solar irradiance prediction using weather forecasts by LSTM. Energy 2018, 148, 461–468. [Google Scholar] [CrossRef]
- Alfadda, A.; Rahman, S.; Pipattanasomporn, M. Solar irradiance forecast using aerosols measurements: A data driven approach. Sol. Energy 2018, 170, 924–939. [Google Scholar] [CrossRef]
- Srivastava, S.; Lessmann, S. A comparative study of LSTM neural networks in forecasting day-ahead global horizontal irradiance with satellite data. Sol. Energy 2018, 162, 232–247. [Google Scholar] [CrossRef]
- Cannizzaro, D.; Aliberti, A.; Bottaccioli, L.; Macii, E.; Acquaviva, A.; Patti, E. Solar radiation forecasting based on convolutional neural network and ensemble learning. Expert Syst. Appl. 2021, 181, 115167. [Google Scholar] [CrossRef]
- Perez, R.; Lorenz, E.; Pelland, S.; Beauharnois, M.; Van Knowe, G.; Hemker, K., Jr.; Heinemann, D.; Remund, J.; Müller, S.C.; Traunmüller, W.; et al. Comparison of numerical weather prediction solar irradiance forecasts in the US, Canada and Europe. Sol. Energy 2013, 94, 305–326. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Mellit, A.; Mekki, H.; Messai, A.; Kalogirou, S.A. FPGA-based implementation of intelligent predictor for global solar irradiation, Part I: Theory and simulation. Expert Syst. Appl. 2011, 38, 2668–2685. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Extreme gradient boosting and deep neural network based ensemble learning approach to forecast hourly solar irradiance. J. Clean. Prod. 2021, 279, 123285. [Google Scholar] [CrossRef]
- Wan, H.; Guo, S.; Yin, K.; Liang, X.; Lin, Y. CTS-LSTM: LSTM-based neural networks for correlatedtime series prediction. Knowl.-Based Syst. 2020, 191, 105239. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, Z.; Kong, D.; Han, H.; Zhao, Y. EA-LSTM: Evolutionary attention-based LSTM for time series prediction. Knowl.-Based Syst. 2019, 181, 104785. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Yang, Z.; Yu, Q.; Hong, T.; Lin, X. Online reliability time series prediction via convolutional neural network and long short term memory for service-oriented systems. Knowl.-Based Syst. 2018, 159, 132–147. [Google Scholar] [CrossRef]
- Long, W.; Lu, Z.; Cui, L. Deep learning-based feature engineering for stock price movement prediction. Knowl.-Based Syst. 2019, 164, 163–173. [Google Scholar] [CrossRef]
- Iwana, B.K.; Frinken, V.; Uchida, S. DTW-NN: A novel neural network for time series recognition using dynamic alignment between inputs and weights. Knowl.-Based Syst. 2020, 188, 104971. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Aslam, M.; Lee, J.M.; Kim, H.S.; Lee, S.J.; Hong, S. Deep Learning Models for Long-Term Solar Radiation Forecasting Considering Microgrid Installation: A Comparative Study. Energies 2019, 13, 147. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, A.; Ain, A.; Dasgupta, P. Solar Irradiance Prediction from Historical Trends Using Deep Neural Networks. In Proceedings of the 2018 IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–15 August 2018; pp. 356–361. [Google Scholar] [CrossRef]
- Castangia, M.; Aliberti, A.; Bottaccioli, L.; Macii, E.; Patti, E. A compound of feature selection techniques to improve solar radiation forecasting. Expert Syst. Appl. 2021, 178, 114979. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, J. SolarNet: A sky image-based deep convolutional neural network for intra-hour solar forecasting. Sol. Energy 2020, 204, 71–78. [Google Scholar] [CrossRef]
- Sharadga, H.; Hajimirza, S.; Balog, R.S. Time series forecasting of solar power generation for large-scale photovoltaic plants. Renew. Energy 2019. [Google Scholar] [CrossRef]
- Zheng, J.; Zhang, H.; Dai, Y.; Wang, B.; Zheng, T.; Liao, Q.; Liang, Y.; Zhang, F.; Song, X. Time series prediction for output of multi-region solar power plants. Appl. Energy 2020, 257, 114001. [Google Scholar] [CrossRef]
- Rana, M.; Rahman, A. Multiple steps ahead solar photovoltaic power forecasting based on univariate machine-learning models and data re-sampling. Sustain. Energy Grids Netw. 2020, 21, 100286. [Google Scholar] [CrossRef]
- Benali, L.; Notton, G.; Fouilloy, A.; Voyant, C.; Dizene, R. Solar radiation forecasting using artificial neural network and random forest methods: Application to normal beam, horizontal diffuse and global components. Renew. Energy 2019, 132, 871–884. [Google Scholar] [CrossRef]
- Yang, Z.; Mourshed, M.; Liu, K.; Xu, X.; Feng, S. A novel competitive swarm optimized RBF neural network model for short-term solar power generation forecasting. Neurocomputing 2020, 397, 415–421. [Google Scholar] [CrossRef]
- Torres-Barrán, A.; Alonso, Á.; Dorronsoro, J.R. Regression tree ensembles for wind energy and solar radiation prediction. Neurocomputing 2019, 326, 151–160. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H. Photovoltaic power forecasting based LSTM-Convolutional Network. Energy 2019, 189, 116225. [Google Scholar] [CrossRef]
- Malakar, S.; Goswami, S.; Ganguli, B.; Chakrabarti, A.; Roy, S.S.; Boopathi, K.; Rangaraj, A. Designing a long short-term network for short-term forecasting of global horizontal irradiance. SN Appl. Sci. 2021, 3, 477. [Google Scholar] [CrossRef]
- Wang, K.; Li, K.; Zhou, L.; Hu, Y.; Cheng, Z.; Liu, J.; Chen, C. Multiple convolutional neural networks for multivariate time series prediction. Neurocomputing 2019, 360, 107–119. [Google Scholar] [CrossRef]
- Ghimire, S.; Deo, R.C.; Raj, N.; Mi, J. Deep solar radiation forecasting with convolutional neural network and long short-term memory network algorithms. Appl. Energy 2019, 253, 113541. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Pascanu, R.; Mikolov, T.; Bengio, Y. Understanding the exploding gradient problem. arXiv 2012, arXiv:1211.5063. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Wichrowska, O.; Maheswaranathan, N.; Hoffman, M.W.; Colmenarejo, S.G.; Denil, M.; Freitas, N.; Sohl-Dickstein, J. Learned optimizers that scale and generalize. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3751–3760. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, M. An Introduction to Solar Radiation; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Wazwaz, A.M. The tanh method for traveling wave solutions of nonlinear equations. Appl. Math. Comput. 2004, 154, 713–723. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yoo, Y. Hyperparameter optimization of deep neural network using univariate dynamic encoding algorithm for searches. Knowl.-Based Syst. 2019, 178, 74–83. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. Advances in Neural Information Processing Systems. 2012, pp. 2951–2959. Available online: https://proceedings.neurips.cc/paper/2012/file/05311655a15b75fab86956663e1819cd-Paper.pdf (accessed on 20 November 2021).
- Bergstra, J.S.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. Advances in Neural Information Processing Systems. 2011, pp. 2546–2554. Available online: https://hal.inria.fr/hal-00642998 (accessed on 20 November 2021).
- Bergstra, J.; Yamins, D.; Cox, D.D. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in Science Conference; Citeseer: University Park, PA, USA, 2013; pp. 13–20. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]









| Citation | Data | Model Name | ForecastingWindow | Country | Correctness | A/D |
|---|---|---|---|---|---|---|
| [8] | Time Series | LSTM (Unidirectional) | Hourly | Egypt | The claimed forecasting error is 82.15, and 136.87 in terms of RMSE | Perfromed better compared to MLR, BRT, and NN |
| [27] | Time Series | Bi-LSTM (Bidirectional) | Hourly | China | BI-LSTM produced correlation coefficient of 98%, and RMSE of 0.791 | Same past context used for both the forward and the backward mode |
| [28] | Time Series | PSO-LSTM(Bidirectional) | Multiple days | China | PSO-LSTM achieved the lowest MAE, and RMSE as 8.14, and 19.41 | Same past context used for both the forward and the backward mode |
| [36] | Time Series | CNN-LSTM(Unidirectional) | 1-Day, 1-Week, 2-Week and 1-Month | Australia | It achieved lower MAPE < 11%, and RRMSE < 15% compared to benchmark models | This study islimited to one solar station |
| [33] | Time Series | LSTM-CNN (Unidirectional) | Multiple days | China | LSTM-CNN achieved the best MAE, RMSE, and MAPE as 0.221, 0.621, and 0.042 | This study islimited to onesolar station |
| [6] | Time Series | MLP (Unidirectional) | Monthly | UAE | MLP has shown the best MBE, ans RMSE as 0.0003, and 0.179 | The model is validated for three solar stations |
| [30] | Time Series | RF | 1 h to 6 h | France | RF achieved the lowest forecasting error as 19.65% to 27.78% in terms of RMSE | This study is restricted to one solar station |
| [10] | Aerosol Optical Depth (AOD) and the Angstrom Exponent data | MLP (Unidirectional) | 1 h | Saudi Arabia | MLP achieved lower RMSE under 4% and forecast skill of over 42% | The study is restricted to one solar site |
| [29] | Time Series | RF | 5 min to 3 h | Australia | RF achieved the lowest overall MAE, and MRE as 110.46, and 10.5% | The proposed model is univariate, and restricted to one solar site |
| City with Month | Longitude | Latitude | Standard Deviation | Climatic Zone |
|---|---|---|---|---|
| Ajmer (January) | E | N | 47.64 | Hot and dry |
| Chennai (December) | E | N | 48.26 | Warm and humid |
| Dehradun (January) | E | N | 46.94 | Cold and cloudy |
| Guntur (January) | E | N | 49.46 | Warm and humid |
| Howrah (December) | E | N | 45.16 | Warm and humid |
| Kotada Pitha (January) | E | N | 48.55 | Hot and dry |
| Ajmer (August) | E | N | 78.33 | Hot and dry |
| Chennai (November) | E | N | 51.88 | Warm and humid |
| Dehradun (August) | E | N | 74.78 | Cold and cloudy |
| Guntur (August) | E | N | 90.36 | Warm and humid |
| Howrah (August) | E | N | 80.22 | Warm and humid |
| Kotada Pitha (August) | E | N | 82.91 | Hot and dry |
| Models | Hyper-Parameters | Values |
|---|---|---|
| Number of hidden layers | 1, 2, 3 | |
| Nodes in hidden layer | 25, 50, 100 | |
| BLSTM/BD-BLSTM/BD-BGRU/ULSTM/M-ULSTM | Learning rate | 0.1, 0.01, 0.001 |
| Batch size | 1, 10, 20, 50, 100 | |
| Epoch | 20, 40, 60, 60, 80, 100 |
| Model Attributes | [29] | [8] | BD-BLSTM/BD-BGRU * |
|---|---|---|---|
| Similarities | |||
| Domain: | Solar prediction | Solar prediction | Solar prediction |
| Input data: | Time series | Time series | Time series |
| Prediction type: | Uni-variate | Uni-variate | Uni-variate |
| Series type: | Non-stationary | Non-stationary | Non-stationary |
| Dissimilarities | |||
| Model type: | Random Forest | Neural Network | Neural Network |
| Sequential model: | × | ✓ | ✓ |
| Memory: | × | ✓ | ✓ |
| Stateful: | × | × | ✓ |
| Activation: | × | Default | tanh |
| Bidirectional: | × | × | ✓ |
| Bidirectional feature: | × | × | ✓ |
| Stateful: | × | × | ✓ |
| Ajmer | Chennai | Dehradun | Guntur | Howrah | Kotada Pitha | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | |
| ULSTM | 0.042 | 0.103 | 0.035 | 0.064 | 0.042 | 0.056 | 0.059 | 0.212 | 0.023 | 0.158 | 0.031 | 0.131 | 0.0581 |
| M-ULSTM * | 0.010 | 0.064 | 0.001 | 0.017 | 0.007 | 0.039 | 0.012 | 0.185 | 0.001 | 0.083 | 0.010 | 0.121 | 0.038 |
| Ajmer | Chennai | Dehradun | Guntur | Howrah | Kotada Pitha | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | |
| M-ULSTM | 0.010 | 0.064 | 0.001 | 0.017 | 0.007 | 0.039 | 0.012 | 0.018 | 0.001 | 0.083 | 0.010 | 0.121 | 0.038 |
| BLSTM * | 0.009 | 0.057 | 0.002 | 0.015 | 0.007 | 0.039 | 0.014 | 0.147 | 0.001 | 0.056 | 0.012 | 0.078 | 0.025 |
| Ajmer | Chennai | Dehradun | Guntur | Howrah | Kotada Pitha | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | |
| BLSTM | 0.009 | 0.057 | 0.002 | 0.015 | 0.007 | 0.039 | 0.014 | 0.147 | 0.001 | 0.056 | 0.012 | 0.078 | 0.025 |
| BD-BLSTM | 0.009 | 0.0029 | 0.003 | 0.0017 | 0.007 | 0.023 | 0.014 | 0.068 | 0.001 | 0.038 | 0.011 | 0.056 | 0.021 |
| BD-BGRU * | 0.008 | 0.024 | 0.001 | 0.012 | 0.006 | 0.014 | 0.010 | 0.061 | 0.001 | 0.026 | 0.009 | 0.026 | 0.016 |
| Ajmer | Chennai | Dehradun | Guntur | Howrah | Kotada Pitha | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | Winter | Rainy | |
| [29] | 0.057 | 0.131 | 0.130 | 0.128 | 0.057 | 0.134 | 0.075 | 0.180 | 0.157 | 0.162 | 0.066 | 0.153 | 0.043 |
| [8] | 0.026 | 0.044 | 0.166 | 0.015 | 0.025 | 0.166 | 0.025 | 0.195 | 0.004 | 0.062 | 0.030 | 0.081 | 0.067 |
| BD-BGRU * | 0.008 | 0.024 | 0.001 | 0.012 | 0.006 | 0.014 | 0.010 | 0.061 | 0.001 | 0.026 | 0.009 | 0.026 | 0.016 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malakar, S.; Goswami, S.; Ganguli, B.; Chakrabarti, A.; Roy, S.S.; Boopathi, K.; Rangaraj, A.G. A Novel Feature Representation for Prediction of Global Horizontal Irradiance Using a Bidirectional Model. Mach. Learn. Knowl. Extr. 2021, 3, 946-965. https://doi.org/10.3390/make3040047
Malakar S, Goswami S, Ganguli B, Chakrabarti A, Roy SS, Boopathi K, Rangaraj AG. A Novel Feature Representation for Prediction of Global Horizontal Irradiance Using a Bidirectional Model. Machine Learning and Knowledge Extraction. 2021; 3(4):946-965. https://doi.org/10.3390/make3040047
Chicago/Turabian StyleMalakar, Sourav, Saptarsi Goswami, Bhaswati Ganguli, Amlan Chakrabarti, Sugata Sen Roy, K. Boopathi, and A. G. Rangaraj. 2021. "A Novel Feature Representation for Prediction of Global Horizontal Irradiance Using a Bidirectional Model" Machine Learning and Knowledge Extraction 3, no. 4: 946-965. https://doi.org/10.3390/make3040047
APA StyleMalakar, S., Goswami, S., Ganguli, B., Chakrabarti, A., Roy, S. S., Boopathi, K., & Rangaraj, A. G. (2021). A Novel Feature Representation for Prediction of Global Horizontal Irradiance Using a Bidirectional Model. Machine Learning and Knowledge Extraction, 3(4), 946-965. https://doi.org/10.3390/make3040047