
The Case of Aspect in Sentiment Analysis: Seeking Attention or Co-Dependency?



Abstract
:1. Introduction
- It’s the only drug that works for my .
- A dose of 750 mg twice daily had no effect on my .
- Caused vomiting and gave me the worst .
- I find using a half a capsule seems to work fine without giving me a .
2. Related Work
3. Methodology
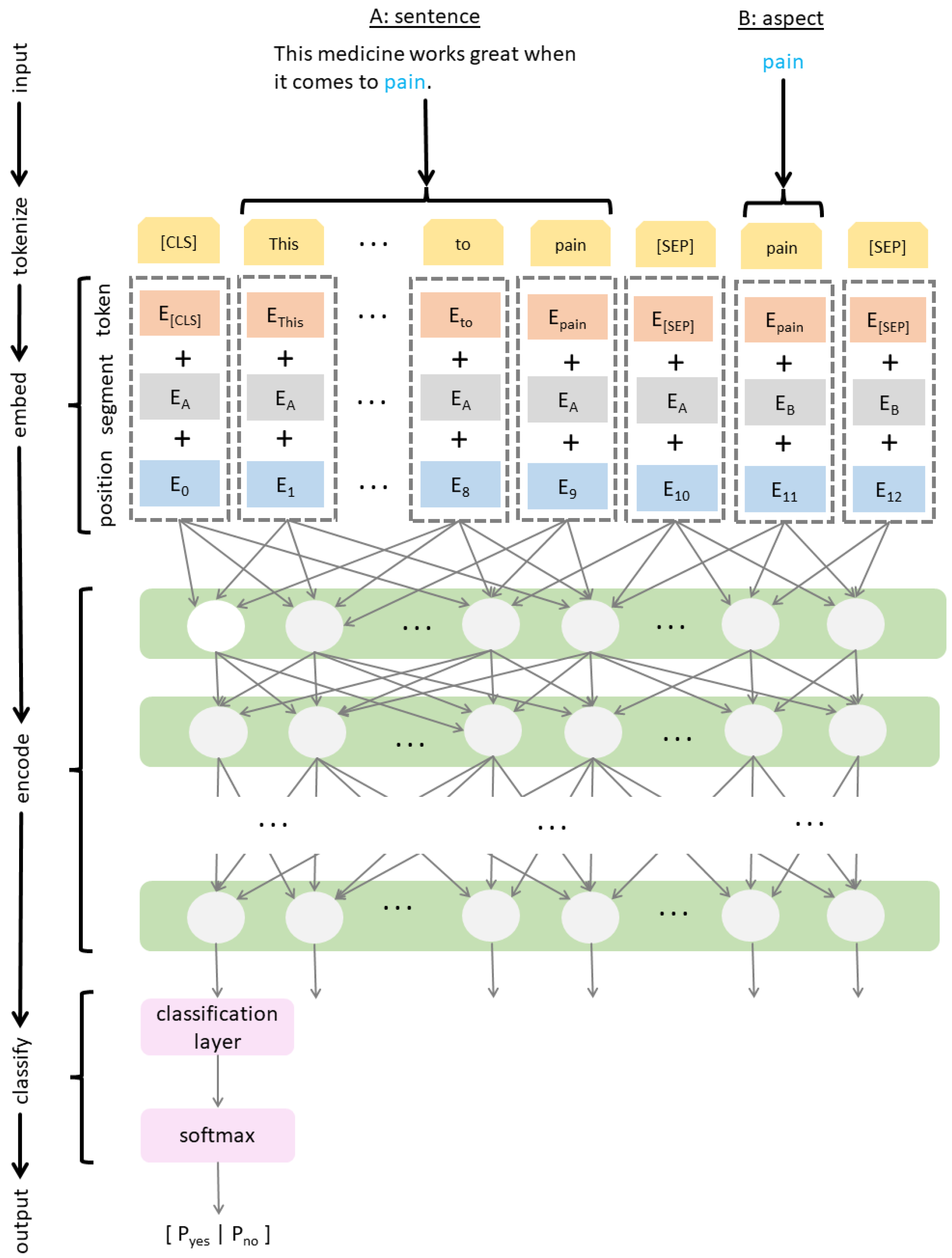
3.1. Neural Network Architecture
3.2. Implementation and Training
4. Results
4.1. Data
4.2. Evaluation
5. Discussion
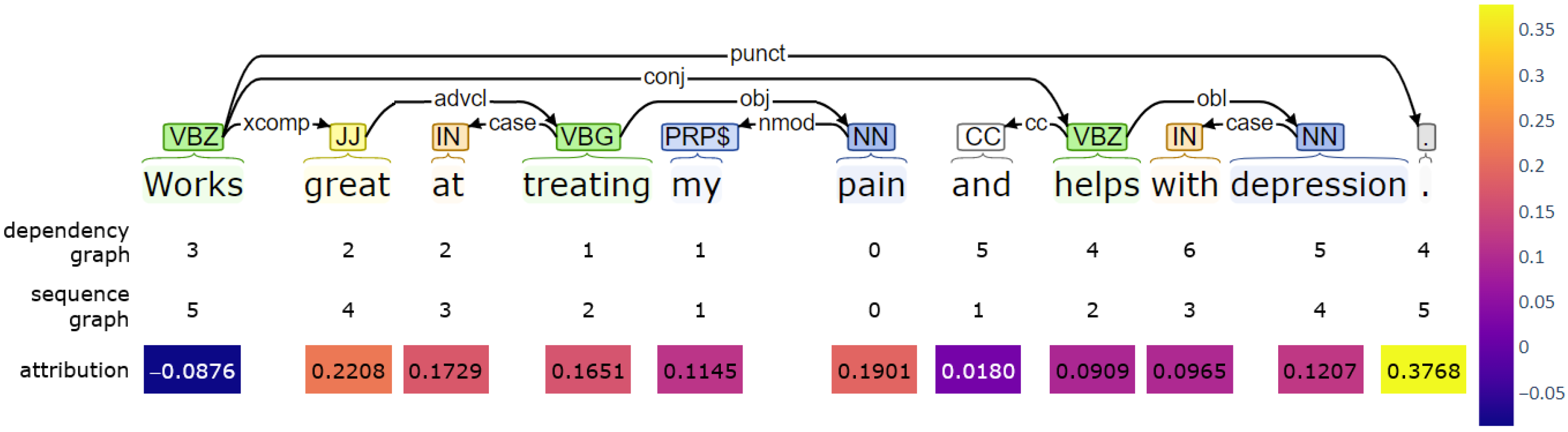
5.1. Error Analysis
5.2. Model Interpretability
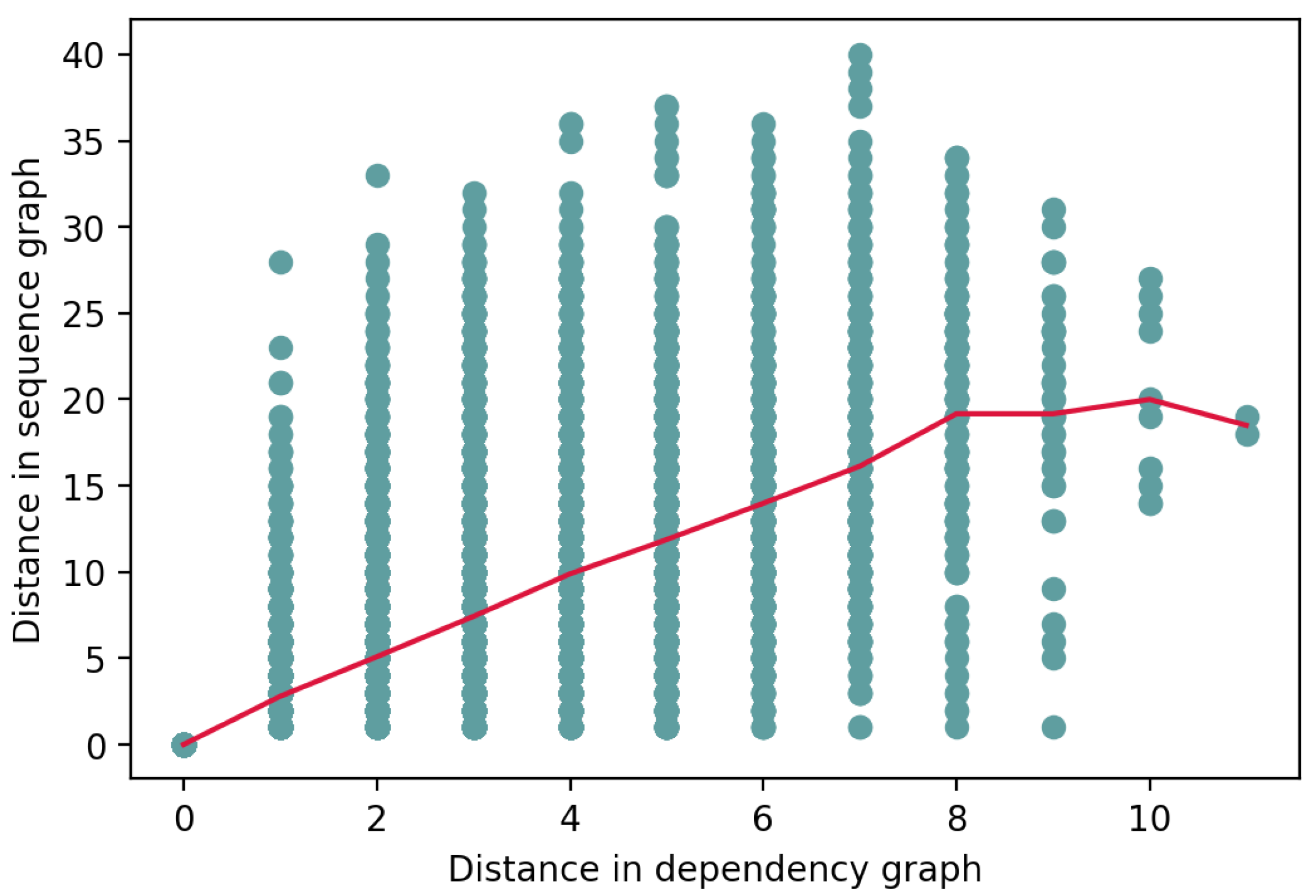
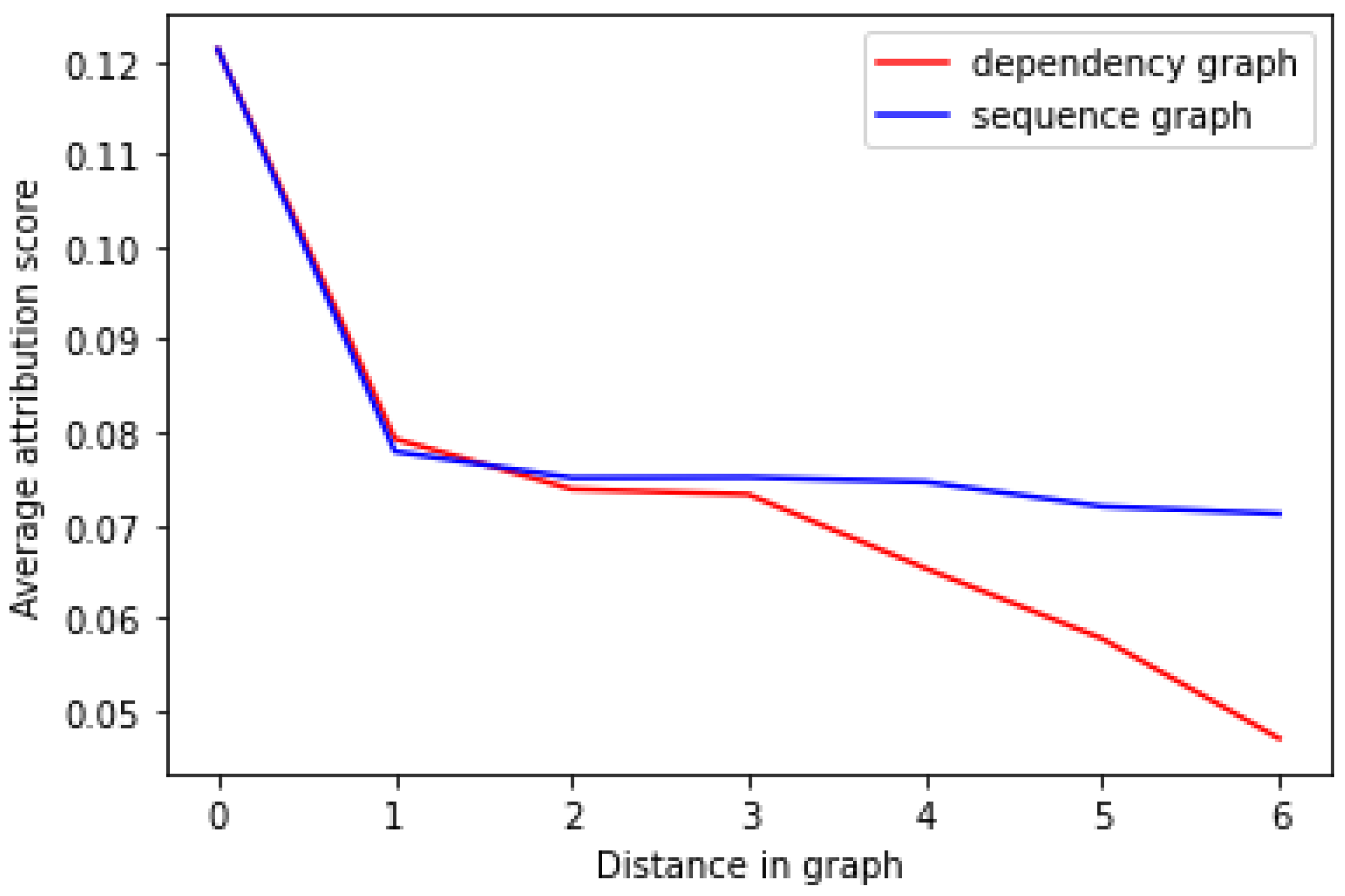
5.3. Statistical Analysis
5.4. Key Findings
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representation from Transformers |
| CNN | Convolutional neural network |
| GCN | Graph convolutional network |
| GRU | Gated recurrent unit |
| LSTM | Long short-term memory |
| NLP | Natural language processing |
| RNN | Recurrent neural network |
| SA | Sentiment analysis |
| SVM | Support vector machine |
| UMLS | Unified Medical Language System |
References
- Liu, B. Sentiment Analysis and Opinion Mining; Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2012; Volume 5, pp. 1–167. [Google Scholar]
- Cambria, E.; Poria, S.; Gelbukh, A.; Thelwall, M. Sentiment Analysis Is a Big Suitcase. IEEE Intell. Syst. 2017, 32, 74–80. [Google Scholar] [CrossRef]
- Williams, L.; Arribas-Ayllon, M.; Artemiou, A.; Spasić, I. Comparing the utility of different classification schemes for emotive language analysis. J. Classif. 2019, 36, 619–648. [Google Scholar] [CrossRef] [Green Version]
- Schouten, K.; Frasincar, F. Survey on Aspect-Level Sentiment Analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 813–830. [Google Scholar] [CrossRef]
- Korkontzelos, I.; Nikfarjam, A.; Shardlow, M.; Sarker, A.; Ananiadou, S.; Gonzalez, G.H. Analysis of the effect of sentiment analysis on extracting adverse drug reactions from tweets and forum posts. J. Biomed. Informat. 2016, 62, 148–158. [Google Scholar] [CrossRef]
- Žunić, A.; Corcoran, P.; Spasić, I. Improving the performance of sentiment analysis in health and wellbeing using domain knowledge. In Proceedings of the HealTAC 2020: Healthcare Text Analytics Conference, London, UK, 23–24 April 2020. [Google Scholar]
- Žunić, A.; Corcoran, P.; Spasić, I. Sentiment analysis in health and well-being: Systematic review. JMIR Med. Informat. 2020, 8, e16023. [Google Scholar] [CrossRef] [PubMed]
- Žunić, A.; Corcoran, P.; Spasić, I. Aspect-based sentiment analysis with graph convolution over syntactic dependencies. Artif. Intell. Med. 2021, 119, 102138. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Long Beach, CA, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Ruder, S.; Ghaffari, P.; Breslin, J.G. A Hierarchical Model of Reviews for Aspect-based Sentiment Analysis. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), Austin, TX, USA, 1–5 November 2016; pp. 999–1005. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Bao, L.; Lambert, P.; Badia, T. Attention and lexicon regularized LSTM for aspect-based sentiment analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL): Student Research Workshop, Florence, Italy, 28 July–2 August 2019; pp. 253–259. [Google Scholar]
- Han, Y.; Liu, M.; Jing, W. Aspect-level drug reviews sentiment analysis based on double BiGRU and knowledge transfer. IEEE Access 2020, 8, 21314–21325. [Google Scholar] [CrossRef]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative Study of CNN and RNN for Natural Language Processing. 2017. Available online: http://xxx.lanl.gov/abs/1702.01923 (accessed on 14 March 2022).
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. 2018. Available online: http://xxx.lanl.gov/abs/1803.01271 (accessed on 14 March 2022).
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, J.; Zhang, J.; Wang, S. Aggregated graph convolutional networks for aspect-based sentiment classification. Inf. Sci. 2022, 600, 73–93. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, Z.; Shi, S.; Wu, Q.; Song, H. Phrase dependency relational graph attention network for Aspect-based Sentiment Analysis. Knowl.-Based Syst. 2022, 236, 107736. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Xiao, L.; Xue, Y.; Wang, H.; Hu, X.; Gu, D.; Zhu, Y. Exploring fine-grained syntactic information for aspect-based sentiment classification with dual graph neural networks. Neurocomputing 2022, 471, 48–59. [Google Scholar] [CrossRef]
- Li, W.; Shao, W.; Ji, S.; Cambria, E. BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis. Neurocomputing 2022, 467, 73–82. [Google Scholar] [CrossRef]
- Özbey, C.; Dilekoğlu, B.; Açiksöz, S. The Impact of Ensemble Learning in Sentiment Analysis under Domain Shift. In Proceedings of the 2021 Innovations in Intelligent Systems and Applications Conference (ASYU), Elazig, Turkey, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Kazmaier, J.; van Vuuren, J.H. The power of ensemble learning in sentiment analysis. Expert Syst. Appl. 2022, 187, 115819. [Google Scholar] [CrossRef]
- Luo, S.; Gu, Y.; Yao, X.; Fan, W. Research on Text Sentiment Analysis Based on Neural Network and Ensemble Learning. Rev. D’Intelligence Artif. 2021, 35, 63–70. [Google Scholar] [CrossRef]
- Sun, C.; Huang, L.; Qiu, X. Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 380–385. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Yu, P. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 2324–2335. [Google Scholar]
- Hoang, M.; Bihorac, O.A.; Rouces, J. Aspect-based sentiment analysis using bert. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 30 September–2 October 2019; Linköping University Electronic Press: Linköping, Sweden, 2019; pp. 187–196. [Google Scholar]
- Li, X.; Fu, X.; Xu, G.; Yang, Y.; Wang, J.; Jin, L.; Liu, Q.; Xiang, T. Enhancing BERT Representation With Context-Aware Embedding for Aspect-Based Sentiment Analysis. IEEE Access 2020, 8, 46868–46876. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Alsentzer, E.; Murphy, J.; Boag, W.; Weng, W.H.; Jindi, D.; Naumann, T.; McDermott, M. Publicly Available Clinical BERT Embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 72–78. [Google Scholar] [CrossRef] [Green Version]
- Aygün, İ.; Kaya, B.; Kaya, M. Aspect Based Twitter Sentiment Analysis on Vaccination and Vaccine Types in COVID-19 Pandemic with Deep Learning. IEEE J. Biomed. Health Informat. 2021, 26, 2360–2369. [Google Scholar] [CrossRef]
- Punith, N.; Raketla, K. Sentiment Analysis of Drug Reviews using Transfer Learning. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021; IEEE: Coimbatore, India, 2021; pp. 1794–1799. [Google Scholar]
- Koppel, M.; Schler, J. The importance of neutral examples for learning sentiment. Comput. Intell. 2006, 22, 100–109. [Google Scholar] [CrossRef]
- Valdivia, A.; Luzón, M.V.; Cambria, E.; Herrera, F. Consensus vote models for detecting and filtering neutrality in sentiment analysis. Inf. Fusion 2018, 44, 126–135. [Google Scholar] [CrossRef]
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, D267–D270. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP), Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 8024–8035. [Google Scholar]
- Gräßer, F.; Kallumadi, S.; Malberg, H.; Zaunseder, S. Aspect-based sentiment analysis of drug reviews applying cross-domain and cross-data learning. In Proceedings of the 2018 International Conference on Digital Health, Lyon, France, 23–26 April 2018; ACM: Lyon, France, 2018; pp. 121–125. [Google Scholar]
- Drugs.com. Available online: https://www.drugs.com/ (accessed on 2 March 2022).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2019, arXiv:1910.01108. Available online: http://xxx.lanl.gov/abs/1910.01108 (accessed on 14 March 2022).
- Ofek, N.; Rokach, L.; Caragea, C.; Yen, J. The Importance of Pronouns to Sentiment Analysis: Online Cancer Survivor Network Case Study. In Proceedings of the 24th International Conference on World Wide Web (WWW), Florence, Italy, 18–22 May 2015; pp. 83–84. [Google Scholar]
- Kokhlikyan, N.; Miglani, V.; Martin, M.; Wang, E.; Alsallakh, B.; Reynolds, J.; Melnikov, A.; Kliushkina, N.; Araya, C.; Yan, S.; et al. Captum: A Unified and Generic Model Interpretability Library for PyTorch. 2020. Available online: http://xxx.lanl.gov/abs/2009.07896 (accessed on 11 May 2022).
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3319–3328. [Google Scholar]
- Htut, P.M.; Phang, J.; Bordia, S.; Bowman, S.R. Do Attention Heads in BERT Track Syntactic Dependencies? arXiv 2019, arXiv:1911.12246. Available online: http://xxx.lanl.gov/abs/1911.12246 (accessed on 14 March 2022).
- Ravishankar, V.; Kulmizev, A.; Abdou, M.; Søgaard, A.; Nivre, J. Attention Can Reflect Syntactic Structure (If You Let It). In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume (EACL), Online, 19–23 April 2021; pp. 3031–3045. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; pp. 276–286. [Google Scholar]
- Spasić, I.; Uzuner, Ö.; Zhou, L. Emerging clinical applications of text analytics. Int. J. Med Informat. 2020, 134, 103974. [Google Scholar] [CrossRef] [PubMed]
- Berg, O. Health and quality of life. Acta Sociol. 1975, 18, 3–22. [Google Scholar] [CrossRef]
- Spasić, I.; Owen, D.; Smith, A.; Button, K. KLOSURE: Closing in on open–ended patient questionnaires with text mining. J. Biomed. Semant. 2019, 10, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive | Negative | Total | |
|---|---|---|---|
| Train | 410 | 378 | 788 |
| Validation | 99 | 98 | 197 |
| Test | 130 | 117 | 247 |
| Total | 639 | 593 | 1232 |
| Method | Accuracy | Loss | |
|---|---|---|---|
| Baseline | 81.78% | 0.4570 | |
| BERTbase | uncased | 78.14% | 0.5270 |
| cased | 94.33% | 0.3641 | |
| DistilBERTbase | uncased | 73.28% | 0.5688 |
| cased | 94.74% | 0.3660 |
| ID | Sentence | Label | Uncased | Cased |
|---|---|---|---|---|
| 1 | Excellent headache reliever! | + | − | + |
| 2 | Good medicine, it gets rid of your pain without that drowsy sick feeling. | + | − | + |
| 3 | Love this medicine, no headache. | + | − | + |
| 4 | Sadly no effect on my pain. | − | + | − |
| 5 | Made my symptom worse-so much for 24 h relief. | − | + | − |
| 6 | No pain relief whatsoever. | − | + | − |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Žunić, A.; Corcoran, P.; Spasić, I. The Case of Aspect in Sentiment Analysis: Seeking Attention or Co-Dependency? Mach. Learn. Knowl. Extr. 2022, 4, 474-487. https://doi.org/10.3390/make4020021
Žunić A, Corcoran P, Spasić I. The Case of Aspect in Sentiment Analysis: Seeking Attention or Co-Dependency? Machine Learning and Knowledge Extraction. 2022; 4(2):474-487. https://doi.org/10.3390/make4020021
Chicago/Turabian StyleŽunić, Anastazia, Padraig Corcoran, and Irena Spasić. 2022. "The Case of Aspect in Sentiment Analysis: Seeking Attention or Co-Dependency?" Machine Learning and Knowledge Extraction 4, no. 2: 474-487. https://doi.org/10.3390/make4020021
APA StyleŽunić, A., Corcoran, P., & Spasić, I. (2022). The Case of Aspect in Sentiment Analysis: Seeking Attention or Co-Dependency? Machine Learning and Knowledge Extraction, 4(2), 474-487. https://doi.org/10.3390/make4020021