
TabFairGAN: Fair Tabular Data Generation with Generative Adversarial Networks


Abstract
:1. Introduction
2. Discrimination Score
3. Model Description
3.1. Tabular Dataset Representation and Transformation
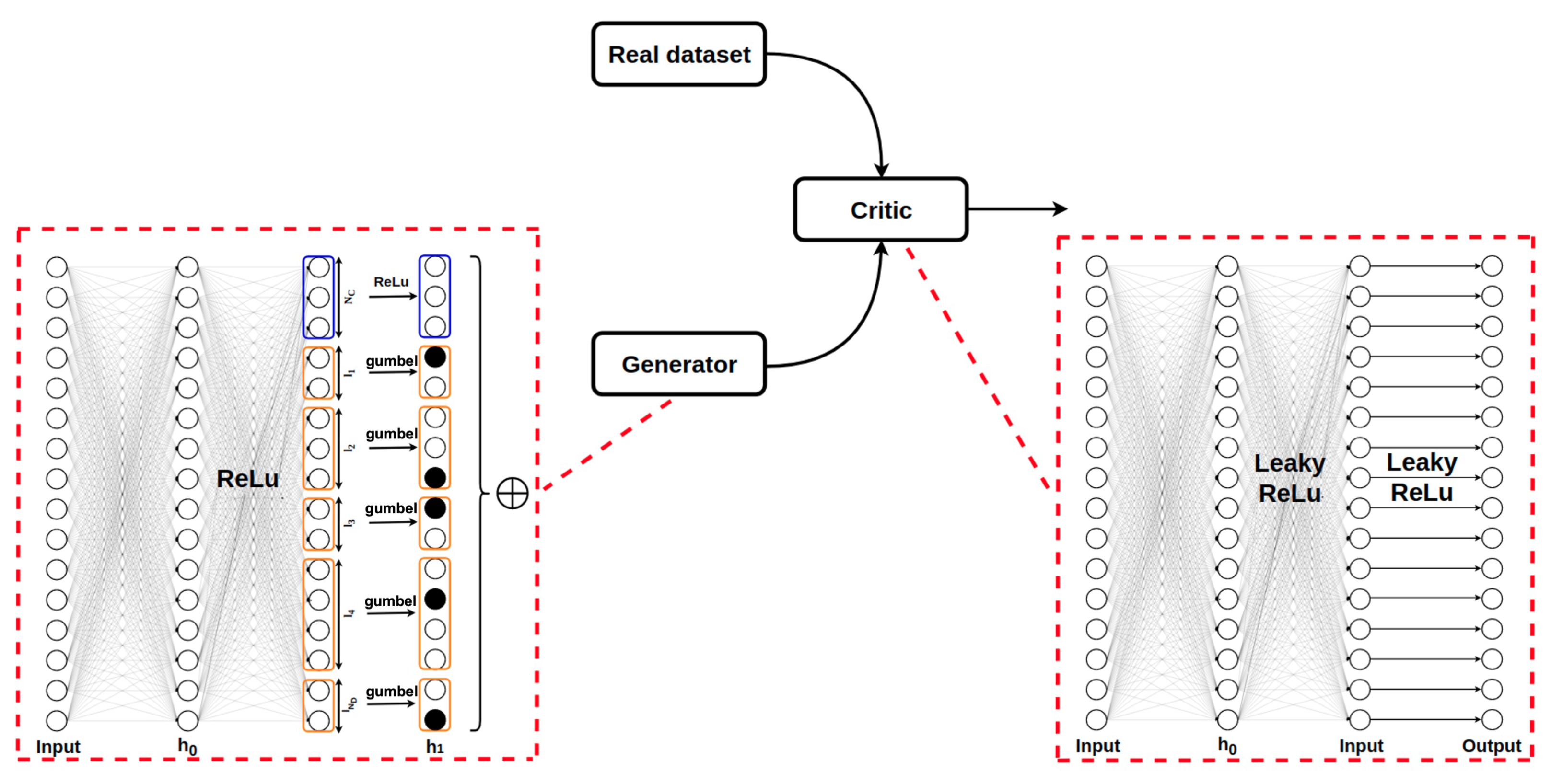
3.2. Network Structure
3.3. Training
3.3.1. Phase I: Training for Accuracy
3.3.2. Phase II: Training for Fairness and Accuracy
| Algorithm 1 training algorithm for the proposed WGAN. We use , batch size of 256, , Adam optimizer with , , and . |
|
4. Experiment: Only Phase I (No Fairness)
5. Experiments: Fair Data Generation and Data Utility (Training with Both Phase I and Phase II)
5.1. Datasets
5.2. Baseline Model: Certifying and Removing Disparate Impact
5.3. Results
5.4. Utility and Fairness Trade-Off
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| TabFairGAN | CRDI | |||
|---|---|---|---|---|
| Adult | 170 | 30 | 0.5 | 0.999 |
| Bank | 195 | 5 | 0.75 | 0.9 |
| COMPAS | c40 | 30 | 2.2 | 0.999 |
| Law School | 180 | 20 | 2.5 | 0.999 |
References
- Chouldechova, A. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments. Big Data 2017, 5, 153–163. [Google Scholar] [CrossRef] [PubMed]
- Lambrecht, A.; Tucker, C. Algorithmic bias? An empirical study of apparent gender-based discrimination in the display of stem career ads. Manag. Sci. 2019, 65, 2966–2981. [Google Scholar] [CrossRef]
- Pessach, D.; Shmueli, E. Algorithmic fairness. arXiv 2020, arXiv:2001.09784. [Google Scholar]
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2012, 33, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Feldman, M.; Friedler, S.A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 259–268. [Google Scholar]
- Kamishima, T.; Akaho, S.; Asoh, H.; Sakuma, J. Fairness-aware classifier with prejudice remover regularizer. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2012; pp. 35–50. [Google Scholar]
- Hardt, M.; Price, E.; Srebro, N. Equality of opportunity in supervised learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3315–3323. [Google Scholar]
- Oussidi, A.; Elhassouny, A. Deep generative models: Survey. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–8. [Google Scholar]
- Fahlman, S.E.; Hinton, G.E.; Sejnowski, T.J. Massively parallel architectures for Al: NETL, Thistle, and Boltzmann machines. In Proceedings of the National Conference on Artificial Intelligence, AAAI, Washington, DC, USA, 22–26 August 1983. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Generating videos with scene dynamics. Adv. Neural Inf. Process. Syst. 2016, 29, 613–621. [Google Scholar]
- Menéndez, M.; Pardo, J.; Pardo, L.; Pardo, M. The jensen-shannon divergence. J. Frankl. Inst. 1997, 334, 307–318. [Google Scholar] [CrossRef]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Edwards, H.; Storkey, A. Censoring representations with an adversary. arXiv 2015, arXiv:1511.05897. [Google Scholar]
- Madras, D.; Creager, E.; Pitassi, T.; Zemel, R. Learning adversarially fair and transferable representations. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3384–3393. [Google Scholar]
- Zhang, B.H.; Lemoine, B.; Mitchell, M. Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 335–340. [Google Scholar]
- Sattigeri, P.; Hoffman, S.C.; Chenthamarakshan, V.; Varshney, K.R. Fairness GAN: Generating datasets with fairness properties using a generative adversarial network. IBM J. Res. Dev. 2019, 63, 3:1–3:9. [Google Scholar] [CrossRef]
- Xu, D.; Yuan, S.; Zhang, L.; Wu, X. Fairgan: Fairness-aware generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 570–575. [Google Scholar]
- Choi, E.; Biswal, S.; Malin, B.; Duke, J.; Stewart, W.F.; Sun, J. Generating multi-label discrete patient records using generative adversarial networks. In Proceedings of the Machine Learning for Healthcare Conference, Boston, MA, USA, 18–19 August 2017; pp. 286–305. [Google Scholar]
- Xu, L.; Veeramachaneni, K. Synthesizing Tabular Data using Generative Adversarial Networks. arXiv 2018, arXiv:1811.11264. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular data using Conditional GAN. Adv. Neural Inf. Process. Syst. 2019, 32, 7333–7343. [Google Scholar]
- Xu, D.; Yuan, S.; Zhang, L.; Wu, X. Fairgan+: Achieving fair data generation and classification through generative adversarial nets. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1401–1406. [Google Scholar]
- Beasley, T.M.; Erickson, S.; Allison, D.B. Rank-based inverse normal transformations are increasingly used, but are they merited? Behav. Genet. 2009, 39, 580–595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. Adv. Neural Inf. Process. Syst. 2017, 30, 5769–5779. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Moro, S.; Cortez, P.; Rita, P. A data-driven approach to predict the success of bank telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef] [Green Version]
- Zafar, M.B.; Valera, I.; Rogriguez, M.G.; Gummadi, K.P. Fairness constraints: Mechanisms for fair classification. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 9–11 May 2017; pp. 962–970. [Google Scholar]
- Angwin, J.; Larson, J.; Mattu, S.; Kirchner, L. Machine Bias ProPublica. 2016. Available online: https://github.com/propublica/compas-analysis (accessed on 21 July 2021).
- Wightman, L.F. LSAC National Longitudinal Bar Passage Study. LSAC Research Report Series; Available online: https://eric.ed.gov/?id=ED469370 (accessed on 20 July 2021).
- Bechavod, Y.; Ligett, K. Penalizing unfairness in binary classification. arXiv 2017, arXiv:1707.00044. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]


| Classifier | DTC | LR | MLP | |||
|---|---|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | |
| Original Data | ||||||
| TabFairGan | 0.783 | 0.544 | 0.794 | 0.239 | 0.405 | |
| TGAN | ||||||
| CTGAN | 0.794 | 0.784 | ||||
| Original Data | TabFairGAN | CRDI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Orig. Acc. | F1 Orig. | DS Data | DS Gen. | Acc. Gen. | F1 Gen. | DS Classifier | DS Rep. | Acc. Rep. | F1 Rep. | DS Classifier |
| Adult | 0.009 | 0.082 | 0.793 | 0.558 | |||||||
| Bank | 0.001 | 0.854 | 0.384 | 0.050 | |||||||
| COMPAS | 0.009 | 0.893 | 0.906 | 0.205 | |||||||
| Law School | 0.024 | 0.153 | 0.892 | 0.941 | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajabi, A.; Garibay, O.O. TabFairGAN: Fair Tabular Data Generation with Generative Adversarial Networks. Mach. Learn. Knowl. Extr. 2022, 4, 488-501. https://doi.org/10.3390/make4020022
Rajabi A, Garibay OO. TabFairGAN: Fair Tabular Data Generation with Generative Adversarial Networks. Machine Learning and Knowledge Extraction. 2022; 4(2):488-501. https://doi.org/10.3390/make4020022
Chicago/Turabian StyleRajabi, Amirarsalan, and Ozlem Ozmen Garibay. 2022. "TabFairGAN: Fair Tabular Data Generation with Generative Adversarial Networks" Machine Learning and Knowledge Extraction 4, no. 2: 488-501. https://doi.org/10.3390/make4020022
APA StyleRajabi, A., & Garibay, O. O. (2022). TabFairGAN: Fair Tabular Data Generation with Generative Adversarial Networks. Machine Learning and Knowledge Extraction, 4(2), 488-501. https://doi.org/10.3390/make4020022