
A Bagged Ensemble Convolutional Neural Networks Approach to Recognize Insurance Claim Frauds



Abstract
:1. Introduction
2. Related Work
- We used an analysis technique for cleaning and improving the quality of the chosen dataset.
- We proposed a 1D Convolutional Neural Network along with the use of pre-trained CNN models.
- We used a bagged ensemble learning based architecture to boost the model performance.
- We assessed the performance of our proposed model using different paradigms and performance ratios.
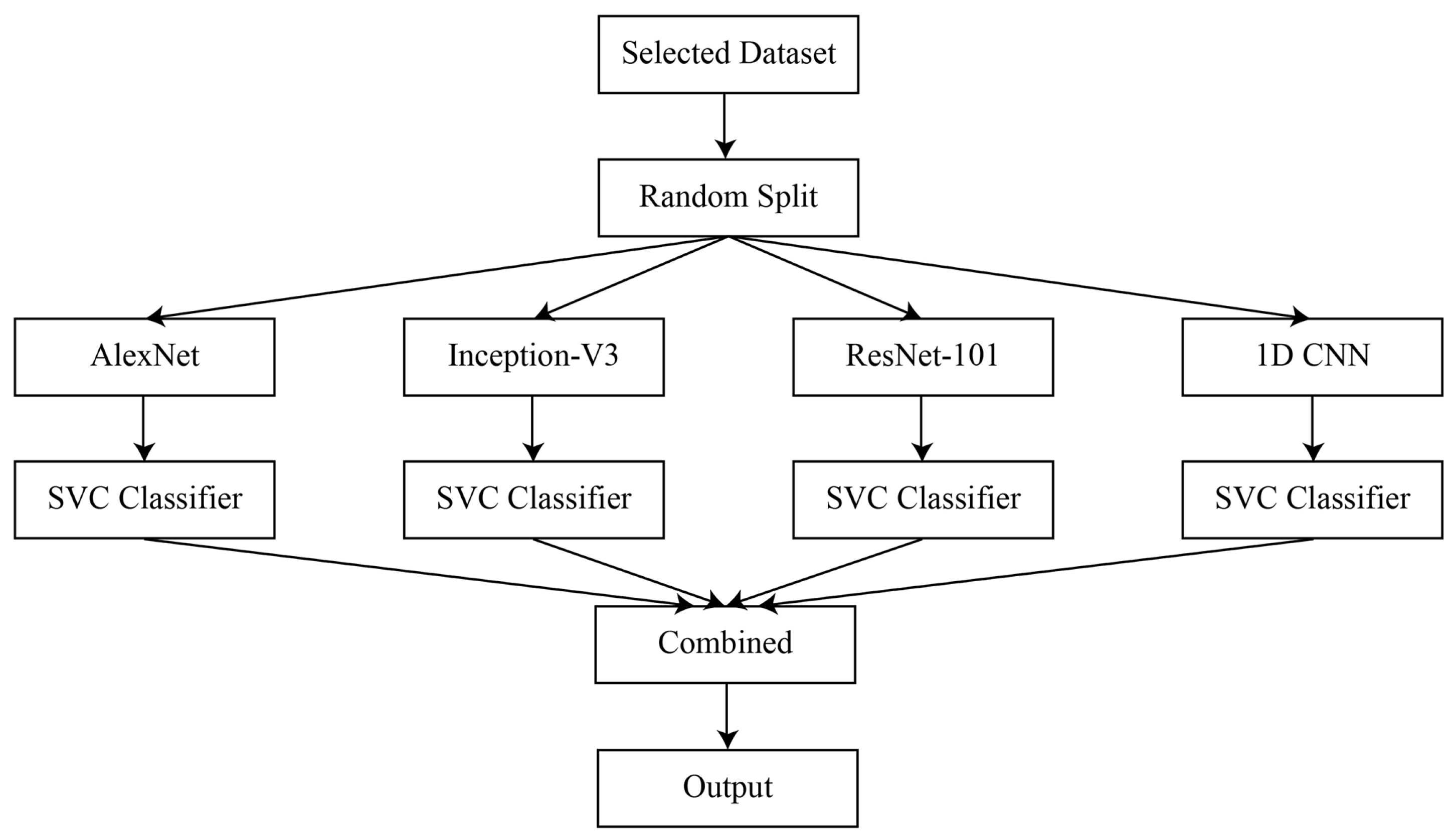
3. Materials and Methods
3.1. Deep Convolutional Neural Network
3.1.1. InceptionV3
3.1.2. ResNet-101
3.1.3. AlexNet
3.1.4. Minimized 1D CNN
3.2. Bagged Ensemble Learning
3.3. Performance Metrics
3.4. Comparaison Paradigms
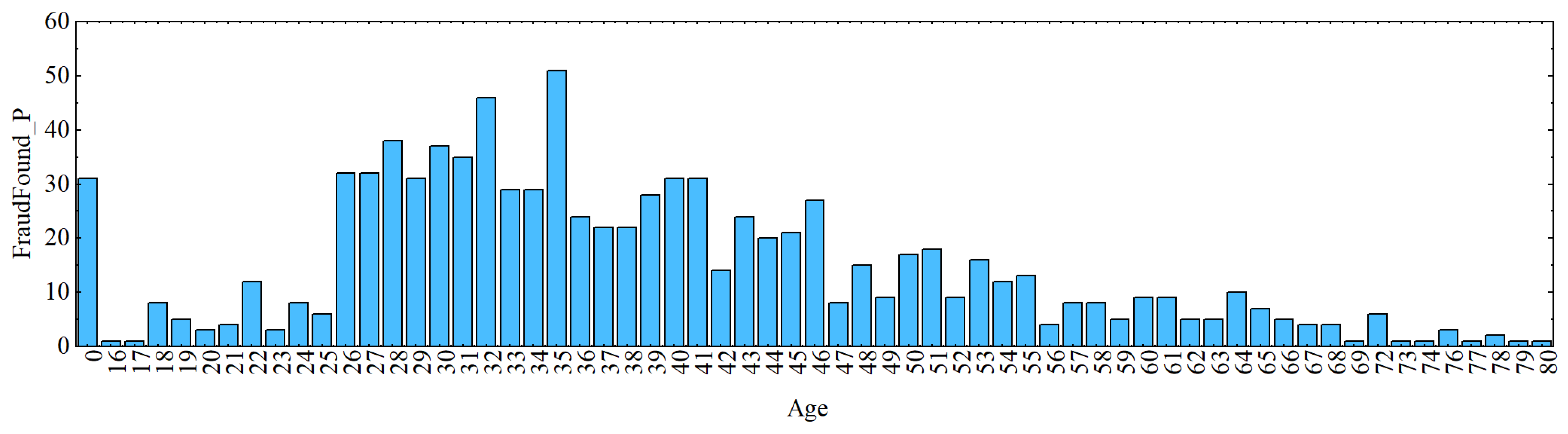
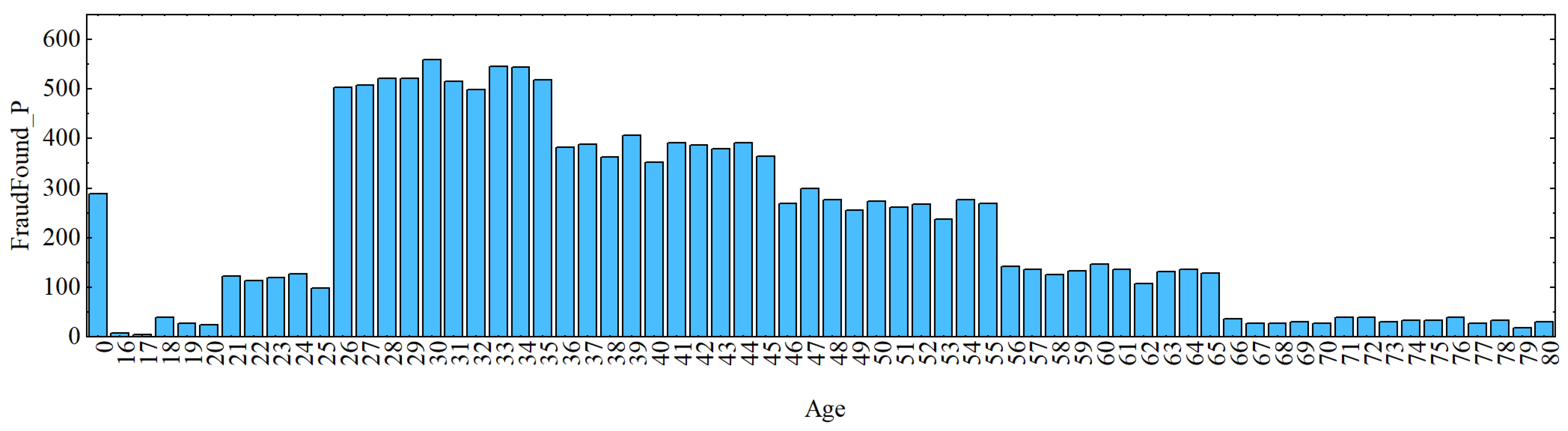
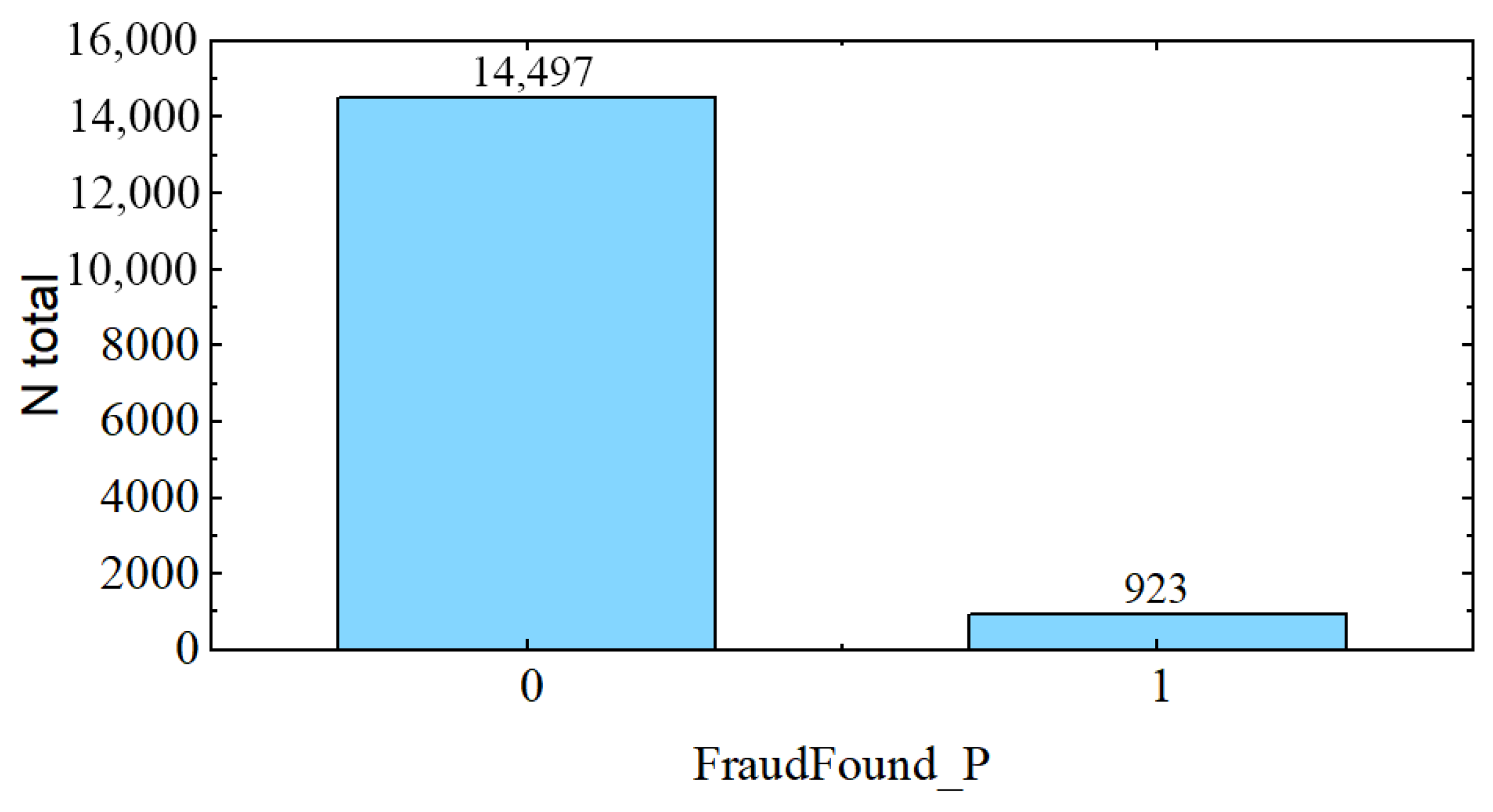
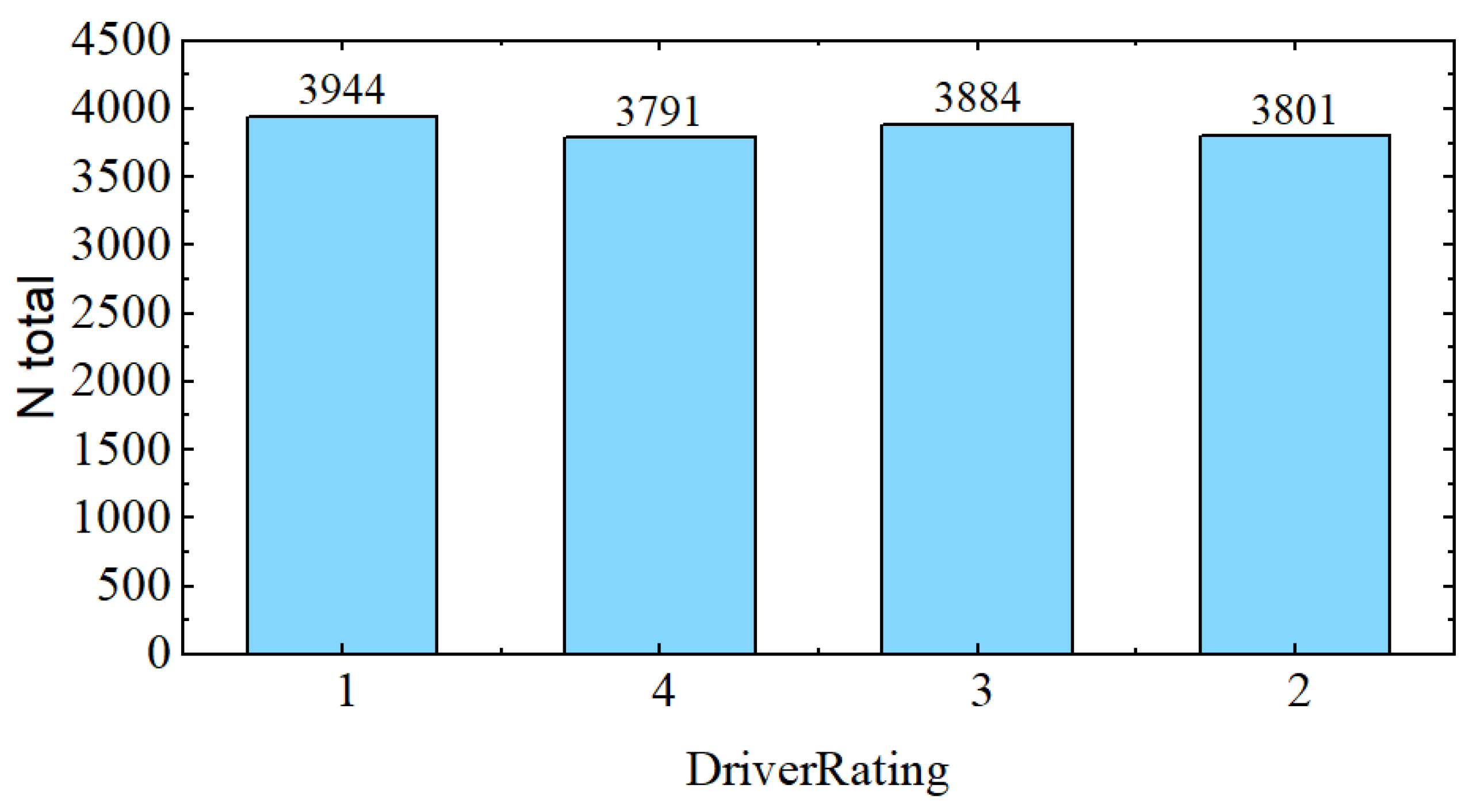
3.5. Dataset
3.6. Experimental Setup
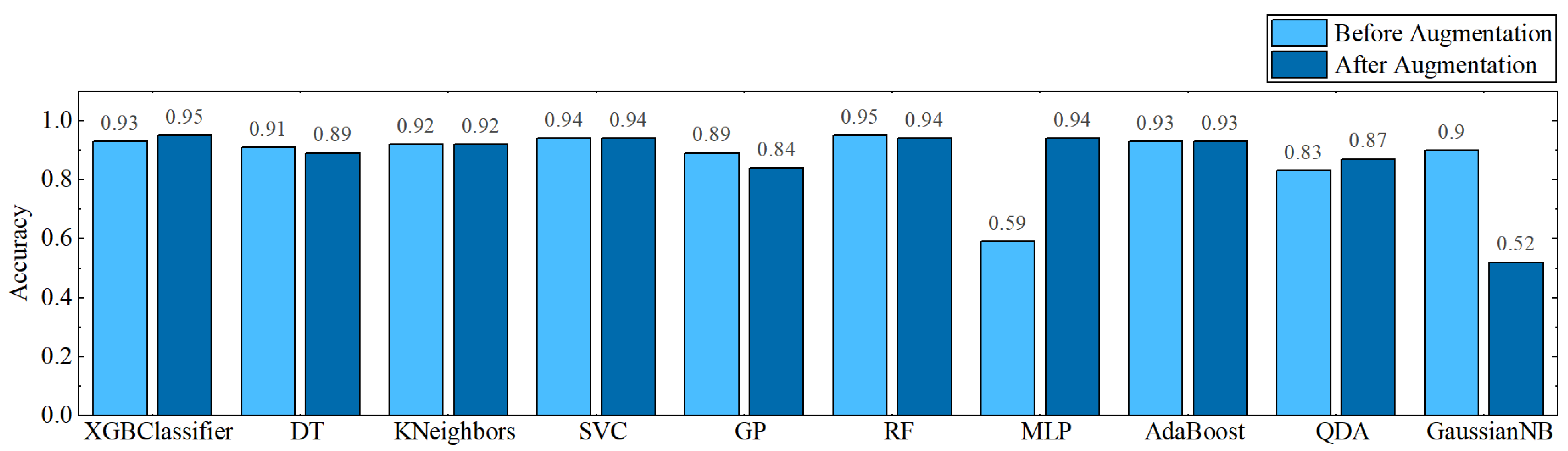
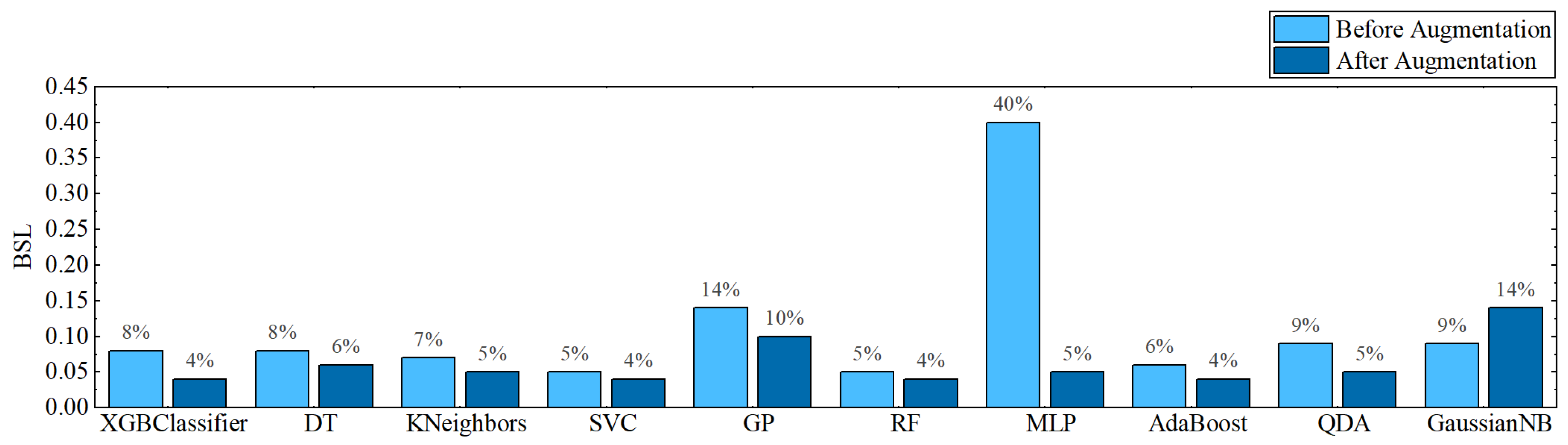
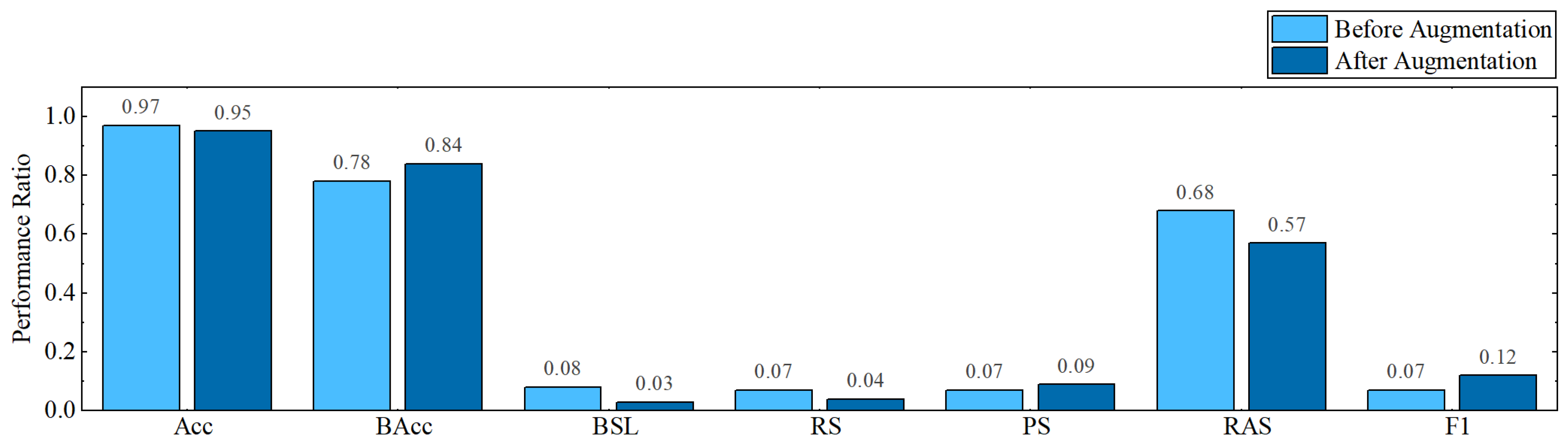
4. Experiments and Analysis
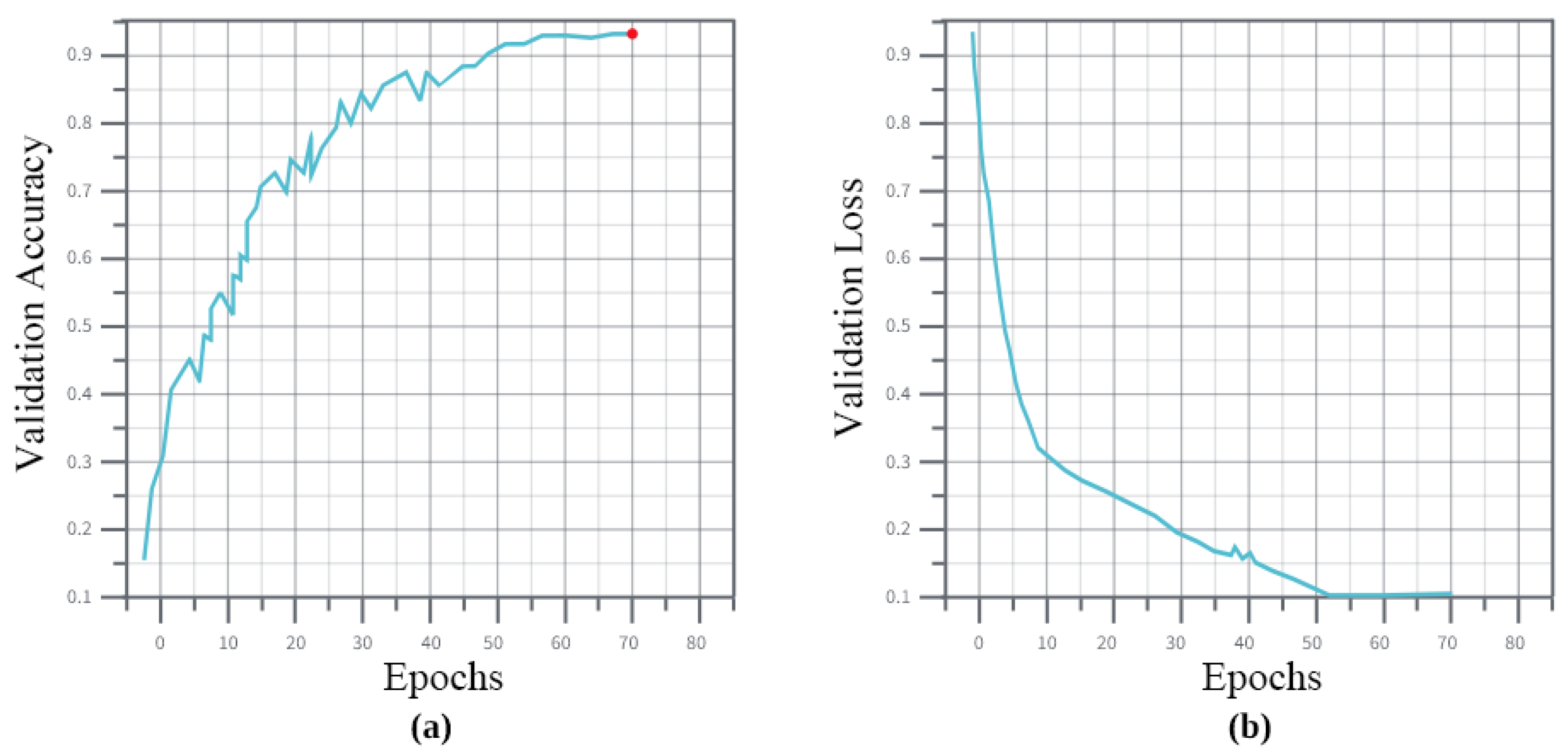
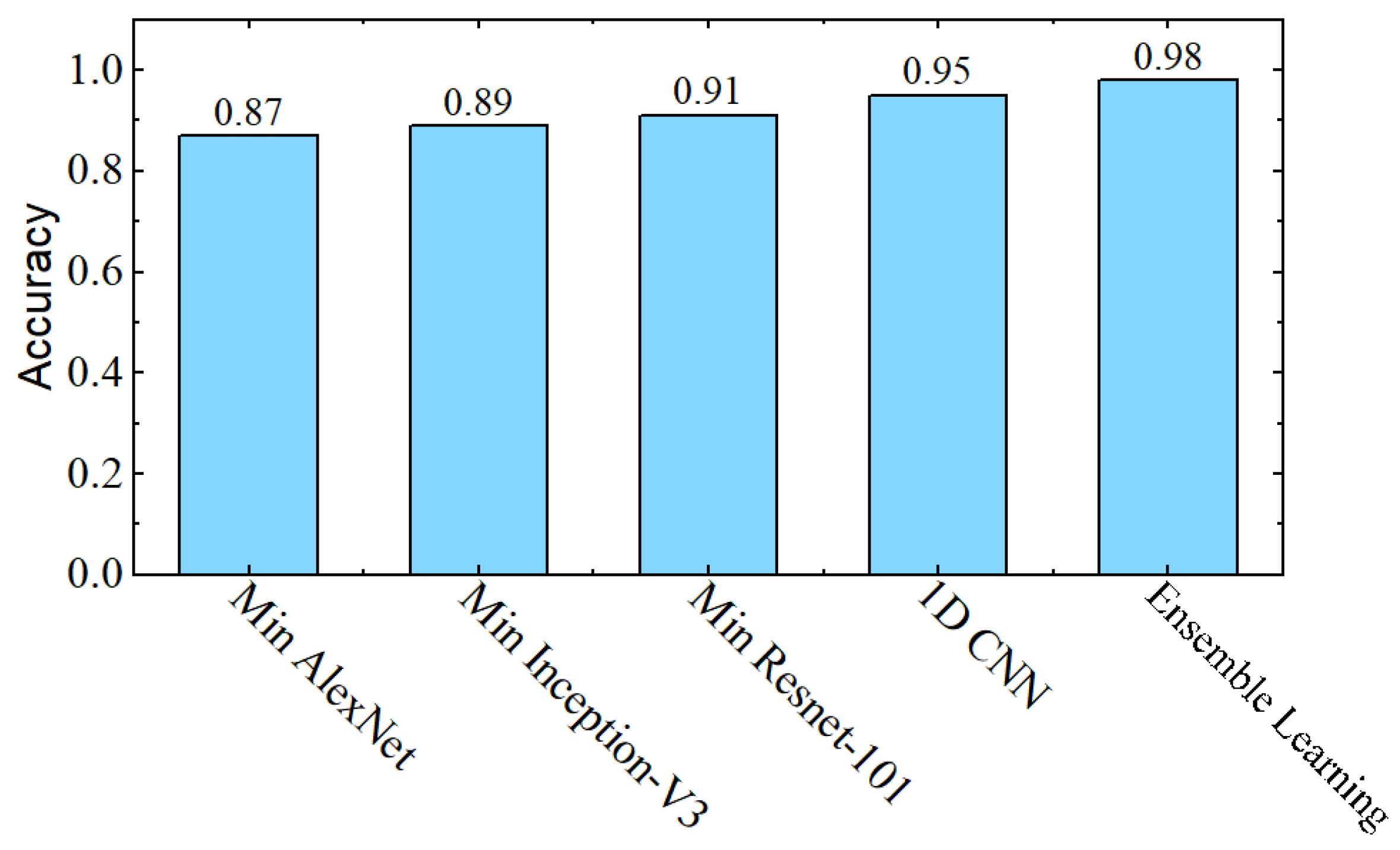
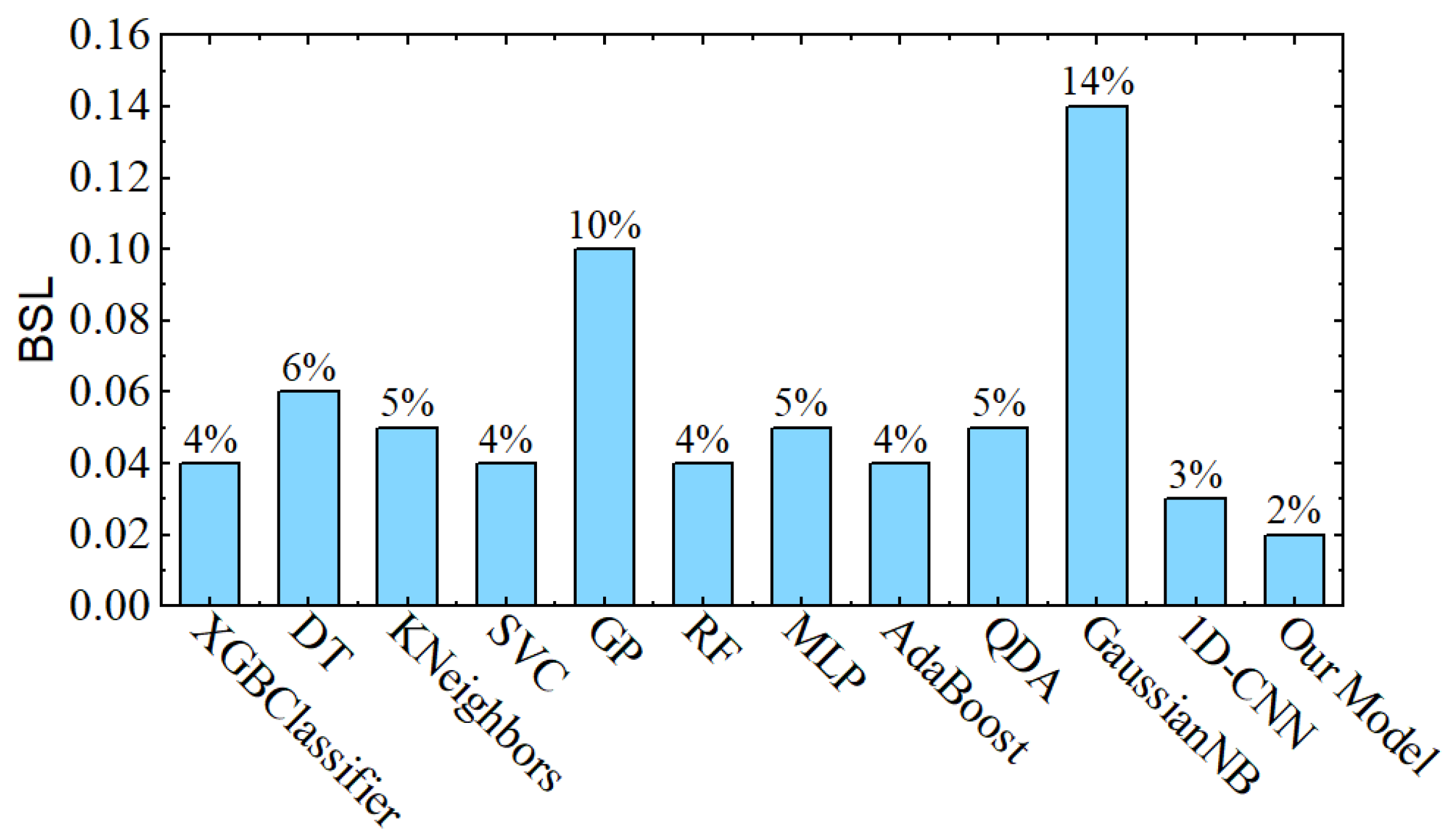
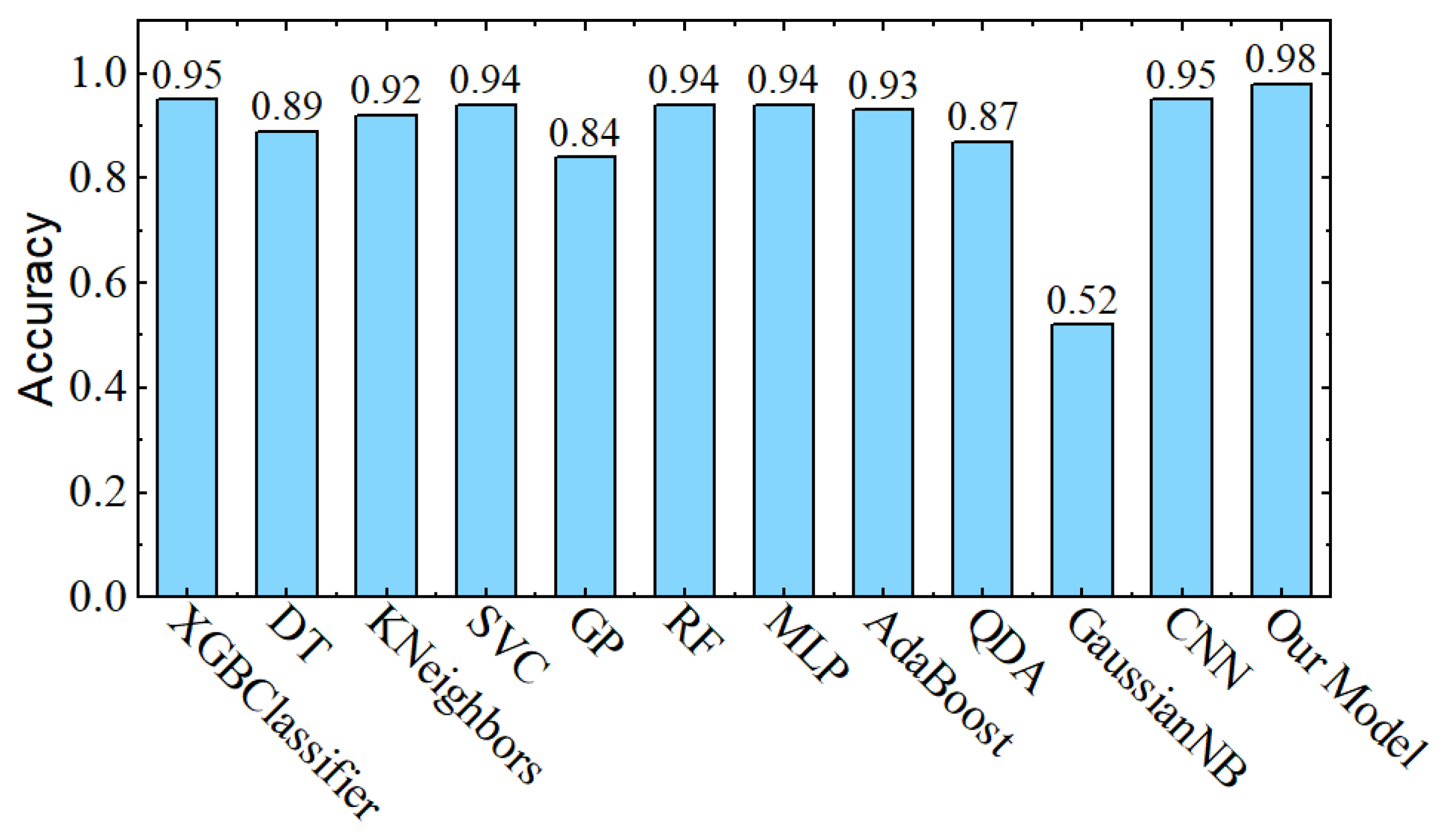
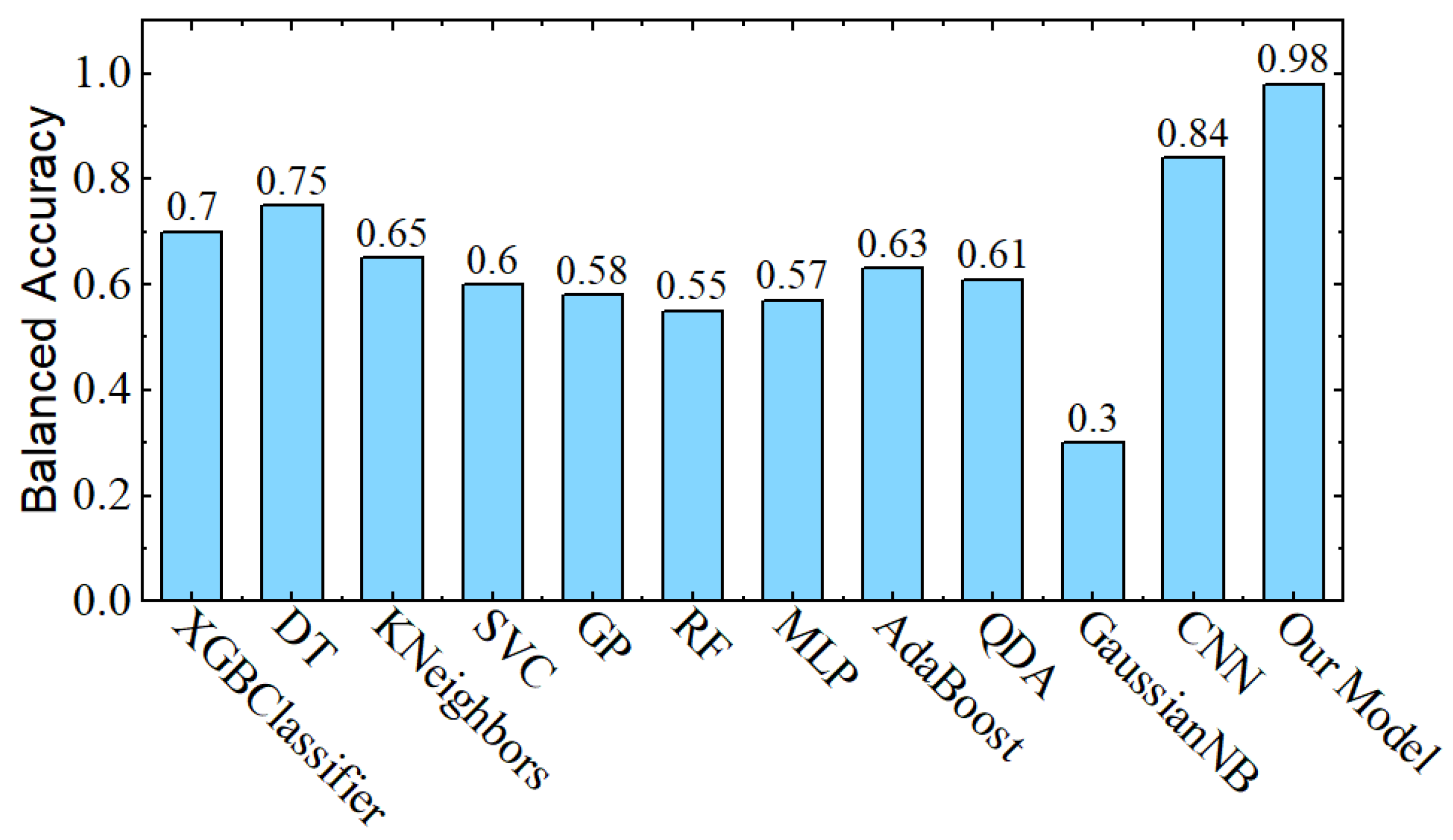
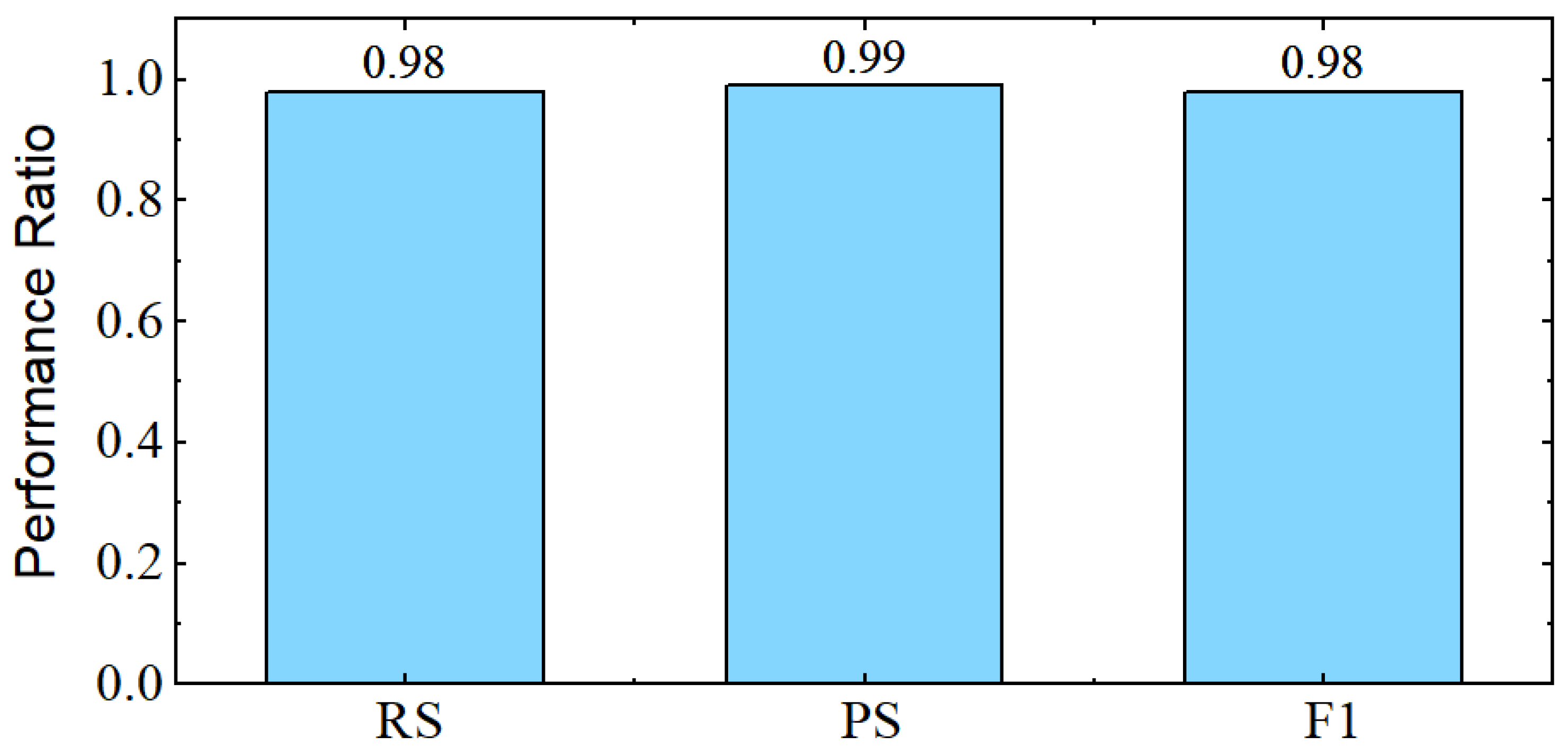
4.1. Experiments
4.2. Ablation Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.H.; Liao, Y.L.; Tsai, T.M.; Hung, G. Technology-based financial frauds in Taiwan: Issues and approaches. In Proceedings of the 2006 IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; pp. 1120–1124. [Google Scholar]
- Supraja, K.; Saritha, S. Robust fuzzy rule based technique to detect frauds in vehicle insurance. In Proceedings of the 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing (ICECDS), Chennai, India, 1–2 August 2017; pp. 3734–3739. [Google Scholar]
- Subudhi, S.; Panigrahi, S. Use of optimized Fuzzy C-Means clustering and supervised classifiers for automobile insurance fraud detection. J. King Saud-Univ.-Comput. Inf. Sci. 2020, 32, 568–575. [Google Scholar] [CrossRef]
- Itri, B.; Mohamed, Y.; Mohammed, Q.; Omar, B. Performance comparative study of machine learning algorithms for automobile insurance fraud detection. In Proceedings of the 2019 Third International Conference on Intelligent Computing in Data Sciences (ICDS), Marrakech, Morocco, 28–30 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Ngai, E.W.; Hu, Y.; Wong, Y.H.; Chen, Y.; Sun, X. The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decis. Support Syst. 2011, 50, 559–569. [Google Scholar] [CrossRef]
- Šubelj, L.; Furlan, Š.; Bajec, M. An expert system for detecting automobile insurance fraud using social network analysis. Expert Syst. Appl. 2011, 38, 1039–1052. [Google Scholar] [CrossRef] [Green Version]
- Ghezzi, S.G. A private network of social control: Insurance investigation units. Soc. Probl. 1983, 30, 521–531. [Google Scholar] [CrossRef] [Green Version]
- Clarke, M. The control of insurance fraud: A comparative view. Br. J. Criminol. 1990, 30, 1–23. [Google Scholar] [CrossRef]
- Caron, L.; Dionne, G. Insurance fraud estimation: More evidence from the Quebec automobile insurance industry. In Automobile Insurance: Road Safety, New Drivers, Risks, Insurance Fraud and Regulation; Springer: Boston, MA, USA, 1999; pp. 175–182. [Google Scholar]
- Viaene, S.; Derrig, R.A.; Baesens, B.; Dedene, G.A. comparison of state-of-the-art classification techniques for expert automobile insurance claim fraud detection. J. Risk Insur. 2002, 69, 373–421. [Google Scholar] [CrossRef]
- Phua, C.; Alahakoon, D.; Lee, V. Minority report in fraud detection: Classification of skewed data. ACM Sigkdd Explor. Newsl. 2004, 6, 50–59. [Google Scholar] [CrossRef]
- Šubelj, L.; Bajec, M. Robust network community detection using balanced propagation. Eur. Phys. J. B 2011, 81, 353–362. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Wang, S.; Zhang, D.; Yang, B. Random rough subspace based neural network ensemble for insurance fraud detection. In Proceedings of the 4th International Joint Conference on Computational Sciences and Optimization, Kunming, China, 15–19 April 2011; pp. 1276–1280. [Google Scholar]
- Tao, H.; Liu, Z.; Song, X. Insurance fraud identification research based on fuzzy Support Vector Machine with dual membership. In Proceedings of the 2012 International Conference on Information Management, Innovation Management and Industrial Engineering, Sanya, China, 20–21 October 2012; pp. 457–460. [Google Scholar]
- Sundarkumar, G.G.; Ravi, V. A novel hybrid undersampling method for mining imbalanced datasets in banking and insurance. Eng. Appl. Artif. Intell. 2015, 37, 368–377. [Google Scholar] [CrossRef]
- Lee, Y.J.; Yeh, Y.R.; Wang, Y.C.F. Anomaly detection via online oversampling principal component analysis. IEEE Trans. Knowl. Data Eng. 2012, 25, 1460–1470. [Google Scholar] [CrossRef]
- Fu, K.; Cheng, D.; Tu, Y.; Zhang, L. Credit card fraud detection using convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing, Kyoto, Japan, 16–21 October 2016; pp. 483–490. [Google Scholar]
- Zhang, Z.; Zhou, X.; Zhang, X.; Wang, L.; Wang, P. A model based on convolutional neural network for online transaction fraud detection. Secur. Commun. Netw. 2018. [Google Scholar] [CrossRef] [Green Version]
- Xia, H.; Zhou, Y.; Zhang, Z. Auto insurance fraud identification based on a CNN-LSTM fusion deep learning model. Int. J. Ad Hoc Ubiquitous Comput. 2022, 39, 37–45. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- Abdullah, S.M.S.; Abdulazeez, A.M. Facial expression recognition based on deep learning convolution neural network: A review. J. Soft Comput. Data Min. 2008, 2, 53–65. [Google Scholar]
- Anwar, S.M.; Majid, M.; Qayyum, A.; Awais, M.; Alnowami, M.; Khan, M.K. Medical image analysis using convolutional neural networks: A review. J. Med Syst. 2018, 42, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Tian, X.; Han, H. Deep convolutional neural networks with transfer learning for automobile damage image classification. J. Database Manag. (JDM) 2022, 33, 1–16. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Dong, N.; Zhao, L.; Wu, C.H.; Chang, J.F. Inception v3 based cervical cell classification combined with artificially extracted features. Appl. Soft Comput. 2020, 93, 106311. [Google Scholar] [CrossRef]
- Wang, C.; Chen, D.; Hao, L.; Liu, X.; Zeng, Y.; Chen, J.; Zhang, G. Pulmonary image classification based on inception-v3 transfer learning model. IEEE Access 2019, 7, 146533–146541. [Google Scholar] [CrossRef]
- Xia, X.; Xu, C.; Nan, B. Inception-v3 for flower classification. In Proceedings of the 2017 2nd International Conference on Image, Vision and COMPUTING (ICIVC), Chengdu, China, 2–4 June 2017; pp. 783–787. [Google Scholar]
- Matoušek, J.; Tihelka, D. A comparison of convolutional neural networks for glottal closure instant detection from raw speech. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6938–6942. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Microsoft/Resnet-101 · Hugging Face. Available online: https://huggingface.co/microsoft/resnet-101 (accessed on 18 January 2023).
- Ghosal, P.; Nandanwar, L.; Kanchan, S.; Bhadra, A.; Chakraborty, J.; Nandi, D. Brain tumor classification using ResNet-101 based squeeze and excitation deep neural network. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Majitar, India, 25–28 February 2019; pp. 1–6. [Google Scholar]
- Demir, A.; Yilmaz, F.; Kose, O. Early detection of skin cancer using deep learning architectures: Resnet-101 and inception-v3. In Proceedings of the 2019 Medical Technologies Congress (TIPTEKNO), Izmir, Turkey, 3–5 October 2019; pp. 1–4. [Google Scholar]
- LSVRC 2012 Results, image-net.org. Available online: https://image-net.org/challenges/LSVRC/2012/results.html (accessed on 18 January 2023).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Hancock, J.; Khoshgoftaar, T.M. Performance of catboost and xgboost in medicare fraud detection. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 572–579. [Google Scholar]
- Zhang, Y.; Tong, J.; Wang, Z.; Gao, F. Customer transaction fraud detection using xgboost model. In Proceedings of the 2020 International Conference on Computer Engineering and Application (ICCEA), Guangzhou, China, 18–20 March 2020; pp. 554–558. [Google Scholar]
- Hassan, A.K.I.; Abraham, A. Modeling insurance fraud detection using imbalanced data classification. In Advances in Nature and Biologically Inspired Computing; Springer: Cham, Switzerland, 2016; pp. 117–127. [Google Scholar]
- Awoyemi, J.O.; Adetunmbi, A.O.; Oluwadare, S.A. Credit card fraud detection using machine learning techniques: A comparative analysis. In Proceedings of the International Conference on Computing Networking and Informatics (ICCNI), Ota, Nigeria, 29–31 October 2017; pp. 1–9. [Google Scholar]
- Al-Hashedi, K.G.; Magalingam, P. Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, Q.; Zhu, J.; Zhang, M.; Yang, Z.; Cao, H. Robust deep auto-encoding Gaussian process regression for unsupervised anomaly detection. Neurocomputing 2020, 376, 180–190. [Google Scholar] [CrossRef]
- Li, Y.; Yan, C.; Liu, W.; Li, M. Research and application of Random Forest model in mining automobile insurance fraud. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; pp. 1756–1761. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Randhawa, K.; Loo, C.K.; Seera, M.; Lim, C.P.; Nandi, A.K. Credit card fraud detection using adaboost and majority voting. IEEE Access 2018, 6, 14277–14284. [Google Scholar] [CrossRef]
- Fraud Stats, InsuranceFraud.org. 2022. Available online: https://insurancefraud.org/fraud-stats/ (accessed on 18 January 2023).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Layer | Parameters | Input | Output |
|---|---|---|---|---|
| 1 | Convolution1D_1 | Channels = 32 Kernels = 14 Pooling = 0.32 | 64 × 1 × 32 × 480 | 64 × 32 × 32 × 480 |
| 2 | Batch_Normalization_1 | Channels = 32 | 64 × 32 × 32 × 480 | 64 × 64 × 32 × 480 |
| 3 | Convolution1D_2 | Channels = 64 Kernels = (28,1) Pooling = 0.0 | 64 × 64 × 32 × 480 | 64 × 64 × 1 × 480 |
| 4 | Batch_Normalization_2 | Channels = 64 | 64 × 64 × 1 × 480 | 64 × 64 × 1 × 480 |
| 5 | ReLU_1 | - | 64 × 64 × 1 × 480 | 64 × 64 × 1 × 480 |
| 6 | Max-Pooling_1 | [1,2] | 64 × 64 × 1 × 480 | 64 × 64 × 1 × 228 |
| 7 | Dropout | 0.5 | 64 × 64 × 1 × 228 | 32 × 32 × 1 × 114 |
| 8 | Convolution1D_3 | Channels = 16 Kernels = 7 Pooling = 0.64 | 32 × 32 × 1 × 114 | 64 × 16 × 32 × 114 |
| 9 | Batch_Normalization_3 | Channels = 32 | 64 × 16 × 32 × 114 | 64 × 32 × 32 × 114 |
| 10 | Convolution1D_4 | Channels = 64 Kernels = (28,1) Pooling = 0.0 | 64 × 32 × 32 × 114 | 64 × 32 × 1 × 114 |
| 11 | Batch_Normalization_4 | Channels = 32 | 64 × 32 × 1 × 114 | 64 × 32 × 1 × 114 |
| 12 | ReLU_2 | - | 64 × 32 × 1 × 114 | 64 × 32 × 1 × 114 |
| 13 | Max-Pooling_2 | [1,1] | 64 × 32 × 1 × 114 | 64 × 32 × 1 × 57 |
| 14 | Dropout | 0.5 | 64 × 32 × 1 × 57 | 32 × 16 × 1 × 27 |
| 15 | Fully_Connected_1 | Input = 32 Output = 32 | 32 × 16 × 1 × 27 | 32 × 16 × 32 |
| 16 | ReLU_3 | - | 32 × 16 × 32 | 32 × 16 × 32 |
| 17 | Fully_Connected_2 | Input = 16 Output = 16 | 32 × 16 × 32 | 32 × 16 × 16 |
| 18 | ReLU_4 | - | 32 × 16 × 32 | 32 × 16 × 32 |
| 19 | Label Output | - | - | - |
| Split Ratio | Accuracy |
|---|---|
| 40–30–30 | 0.87 |
| 50–25–25 | 0.90 |
| 60–20–20 | 0.93 |
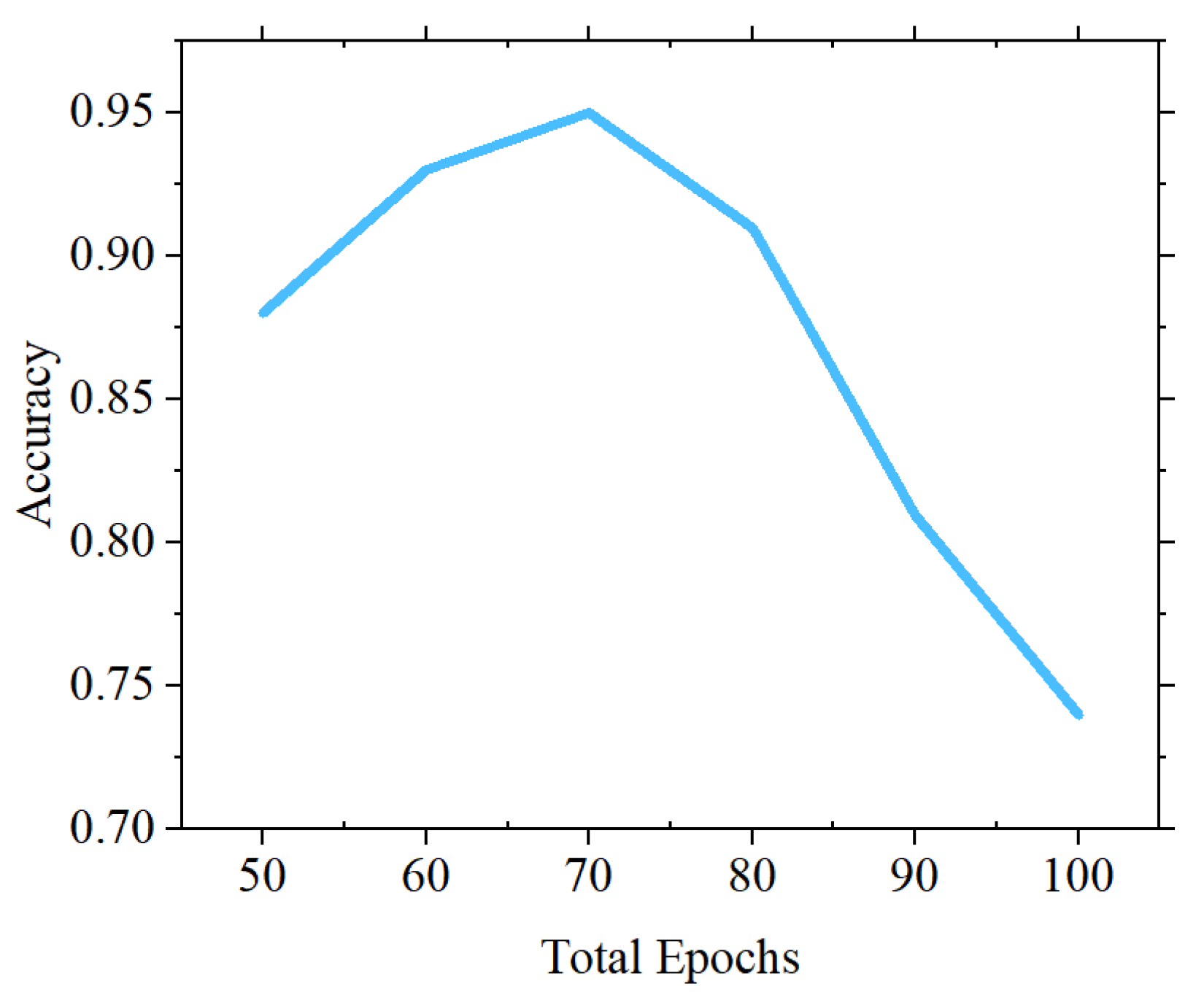
| 70–15–15 | 0.95 |
| 80–10–10 | 0.94 |
| 90–5–5 | 0.94 |
| Initial Learning Rate | Accuracy |
|---|---|
| 0.01 | 0.78 |
| 0.02 | 0.87 |
| 0.001 | 0.92 |
| 0.002 | 0.95 |
| 0.0001 | 0.92 |
| 0.0002 | 0.86 |
| Model | AlexNet | Inception-V3 | Resnet-101 | |||
|---|---|---|---|---|---|---|
| Selected Blocks | Acc | Selected Blocks | Acc | Selected Blocks | Acc | |
| Original | -all- | 0.83 | -all- | 0.84 | -all- | 0.87 |
| Minimized | 1 | 0.81 | 1 | 0.8 | 1 | 0.74 |
| 2 | 0.87 | 2 | 0.83 | 2 | 0.81 | |
| - | - | 3 | 0.89 | 3 | 0.88 | |
| - | - | 4 | 0.85 | 4 | 0.91 | |
| - | - | 5 | 0.82 | 5 | 0.86 | |
| - | - | 6 | 0.83 | 6 | 0.85 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abakarim, Y.; Lahby, M.; Attioui, A. A Bagged Ensemble Convolutional Neural Networks Approach to Recognize Insurance Claim Frauds. Appl. Syst. Innov. 2023, 6, 20. https://doi.org/10.3390/asi6010020
Abakarim Y, Lahby M, Attioui A. A Bagged Ensemble Convolutional Neural Networks Approach to Recognize Insurance Claim Frauds. Applied System Innovation. 2023; 6(1):20. https://doi.org/10.3390/asi6010020
Chicago/Turabian StyleAbakarim, Youness, Mohamed Lahby, and Abdelbaki Attioui. 2023. "A Bagged Ensemble Convolutional Neural Networks Approach to Recognize Insurance Claim Frauds" Applied System Innovation 6, no. 1: 20. https://doi.org/10.3390/asi6010020
APA StyleAbakarim, Y., Lahby, M., & Attioui, A. (2023). A Bagged Ensemble Convolutional Neural Networks Approach to Recognize Insurance Claim Frauds. Applied System Innovation, 6(1), 20. https://doi.org/10.3390/asi6010020