1. Introduction
Due to the issue of increasing numbers of aged people in recent years, there is a trend toward home-care systems. While there are some safety protection devices, such as cameras and phones, on the market today [
1,
2], they cannot protect a person’s privacy, so they cannot be used in bathrooms, toilets, and changing rooms, nor can they be used in dark places without lighting. The elderly are more likely to need assistance in these private spaces and times. For the above reasons, Wi-Fi waves, up to 5 GHz, have been used for gesture recognition with AI computing models to detect human behaviors [
3,
4,
5]. Due to factors of lower frequency, the effects of electromagnetic interference seriously hinder the recognition rate and then affect the promotion of its application [
6]. Increasing the application frequency will help to improve this phenomenon.
Millimeter wave (mmWave), above 20 GHz, is a special radar technology that uses short-wave electromagnetic waves [
7]. A study proposes an integration of the Car-to-Car Network-Hierarchical deep neural network (CtCNET-HDRNN) model with Fifth generation (5G) mmWave [
8]. However, this linear machine learning approach does not perform well in recognizing two-dimensional images. The integration of sensing functions is becoming a key feature of 6G Radio Access Networks (RANs) [
9], allowing the use of dense small-area infrastructure to build sensing networks. Millimeter-wave radar transmits signals with wavelengths in the millimeter range, which is one of the advantages of the technology. By capturing the reflected signals, the radar system can determine the distance, velocity, and angle of an object to create a micro-Doppler effect, which can be processed to provide a unique data set, such as distance, velocity, and angle, as well as the ability to distinguish between different targets, so that the sensor can detect the characteristics of different objects within the detection range. For example, this data allows sensors to sense echo signals, and modulation effects from tiny motions, including characteristics typical of objects such as the rotational speed of a bicycle wheel, a person’s swaying arm, or an animal’s running limbs. In this paper, we will build a sensing system that can detect the object position and gesture recognition for nursing-secure care using an AI model, which can be used in embedded systems. We take the MQTT [
10] IoT protocols to transmit our identification results to create an intelligent system on a smart embedded platform and run a test system to validate our research.
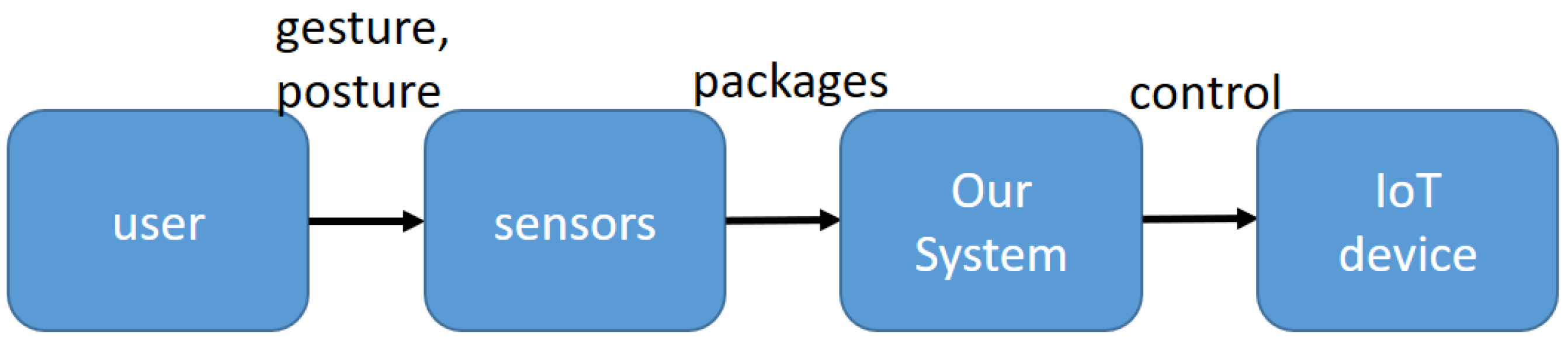
The general architecture of this paper is as shown in
Figure 1. Sensors can detect user gestures or postures, and after computation through our system, commands can be emitted to control designated IoT devices.
2. Background
2.1. ISAC
The ISAC system mainly integrates sensing and communication [
11], and is considered to be one of the most promising technologies to realize the two key requirements in 6G. With the development of networks and the evolution of wireless systems, ISAC has gradually become a hot research topic.
ISAC has recently been proposed for numerous emerging applications, including but not limited to in-vehicle networking, environmental monitoring, remote sensing, IoT, smart cities, and indoor services such as human activity and gesture recognition. More importantly, ISAC was recently identified as an enabling technology for 5G/6G and next-generation Wi-Fi systems.
An important focus in the future of ISAC development is to improve the accuracy, so as to facilitate the communication between UAVs for more complex tasks, and enable simultaneous imaging, mapping, and localization to achieve mutual performance improvements for these functions.
In addition, it is hoped that human senses can be enhanced, such as adding some features to detect things that humans cannot see with their eyes, such as information on blood vessels, organ status, or information on vital signs such as breathing, heartbeat, etc.
2.2. Widar3.0
Wireless devices often use ubiquitous commercial Wi-Fi for sensing systems, which is named DFWS (device-free wireless sensing), called Wi-Fi sensing [
5]. The research focuses on how to extract highly identifiable features from channel state information (CSI). In order to obtain more CSI identification features in cross-domain gesture recognition, a system named Widar3.0 was proposed in mid-2019. It combines the advantages of convolutional neural networks and long short-term memory networks into a joint CNN and LSTM in a model. The spatial features learned by the CNN are used as the inputs for the LSTM to simulate the temporal features. Widar3.0 can be used directly through existing equipment without retraining. However, after the actual test, it is found that after the noise information in the environment is eliminated, redundant echoes will still be generated, which will directly affect the recognition rate after passing through CNN, and this method is not suitable for subtle gesture recognition.
2.3. YOLO-v4 Machine Learning Model
In this paper, we use the YOLO-v4 machine learning model as the recognition tool for AI approaches and apply the detection methods of millimeter wave to create a secure-care system with mmWave radar. The YOLO (You Only Look Once) series, an excellent object detection model, is based on the Convolutional Neural Network (CNN) architecture, known for its high accuracy and speed. However, the YOLO [
12] series still faces significant challenges when dealing with embedded systems or resource-constrained environments. The YOLO-v4 and YOLO v4-tiny models utilize Darknet [
13] capabilities for neural network construction, weight initialization, forward propagation, and backward propagation, facilitating the processes of training and recognition.
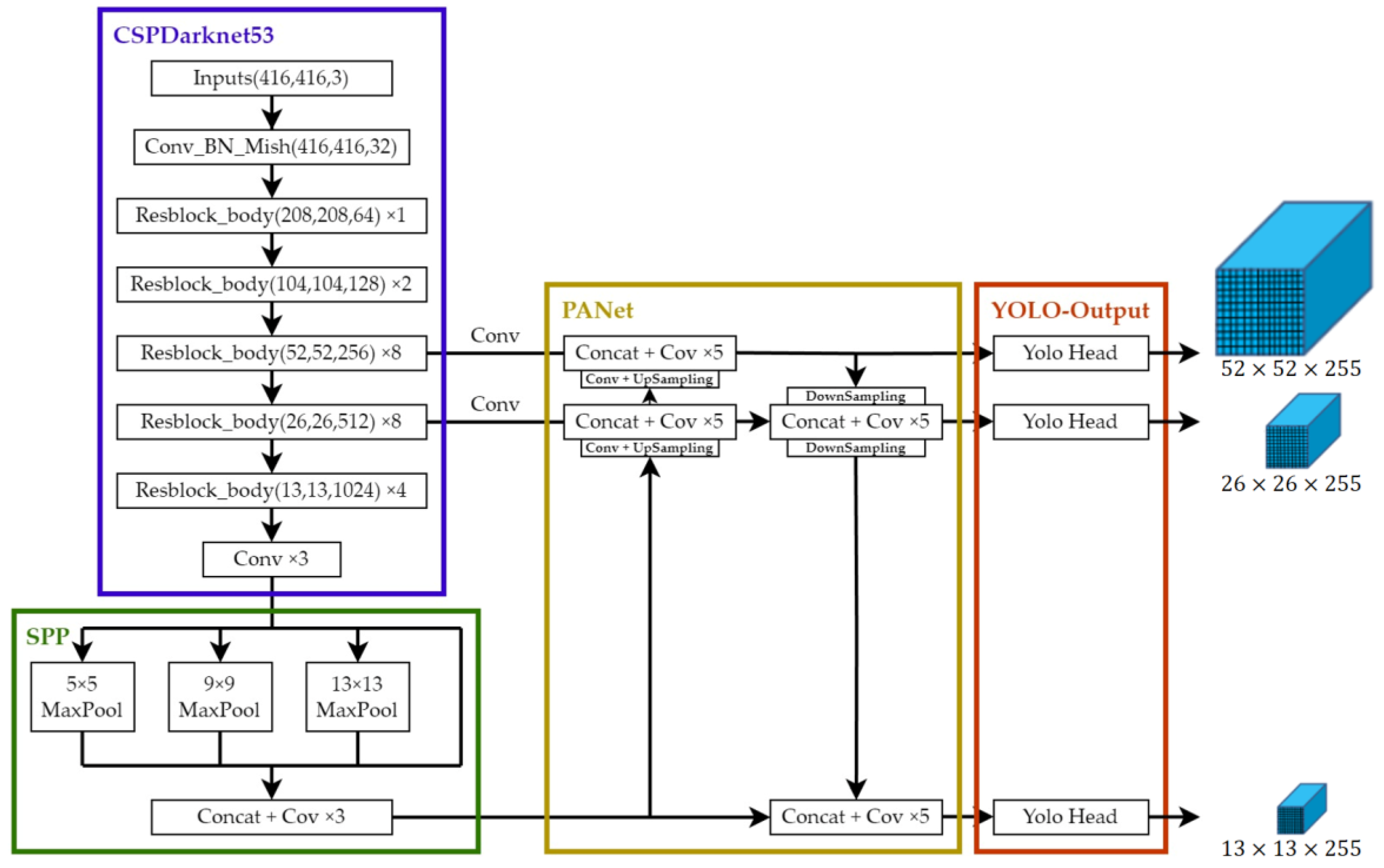
The YOLO-v4 network architecture is shown in
Figure 2. YOLO-v4 is roughly composed of four parts: Darknet, SPP, PANet, and YOLO-output, with a total of 161 layers.
CSPDarknet53: The CSPDarknet53 layer is the entrance of the whole network, as part of the Backbone. (the blue frame part)
SPP: Feature maps given before the last layer Concate of CSPDarknet53, as part of the Neck. (green frame part)
PANet: The actions of sitting down and sampling and upsampling in PANet are also used here as part of the Neck.
YOLO-Output: Finally, YOLO-Output outputs the final results, including the target position of the prediction frame and the reliability of the detection target. (Yellow frame part)
Currently, YOLO series networks are often processed using Graphics Processing Units (GPUs) or custom hardware designs, such as Field Programmable Gate Arrays (FPGAs) that enable high degrees of parallelism for computations [
14,
15]. However, in the context of embedded systems or resource-limited scenarios, CNN-based models still face challenges due to data computation latency and limited data access bandwidth. To address this, some studies have started applying hardware accelerators to CNN models to enhance computational efficiency. For specific image data, such as sensor data images with lower information content, optimizing the number of layers without sacrificing model accuracy can directly impact the model’s speed.
In deep learning, a convolutional neural network (CNN) is widely used for image recognition. To accurately identify similar images, the number of convolutional layers can be increased to obtain and abstract features of the image. However, as the number of layers increases, a large number of weight tables are generated, which increases the demand for computing resources, computing complexity, and storage space required for the weight tables, thus limiting the performance of embedded systems using CNNs. To solve related problems, many related studies have explored various methods, such as processing computing data, computing directly in memory, or designing a dedicated CNN model to retrain weight tables [
16,
17], to increase computing speed and reduce storage space. As the CNN calculation results indicate whether a feature is prominent, the classification process finds the category with the highest value among all the categories as the classification result. Based on this principle, this study demonstrates that as long as the relationships between the magnitudes of the calculation results are maintained, the accuracy can be nearly lossless.
2.4. YOLO v4-Tiny Machine Learning Model
YOLO v4-tiny [
18], as a lightweight object detection model of YOLO-v4, continues the advantages of the YOLO series and has higher accuracy and fast identification capabilities. It provides effective and accurate object detection in resource-constrained environments and is suitable for a variety of application scenarios, including embedded systems, mobile devices, and real-time vision applications.
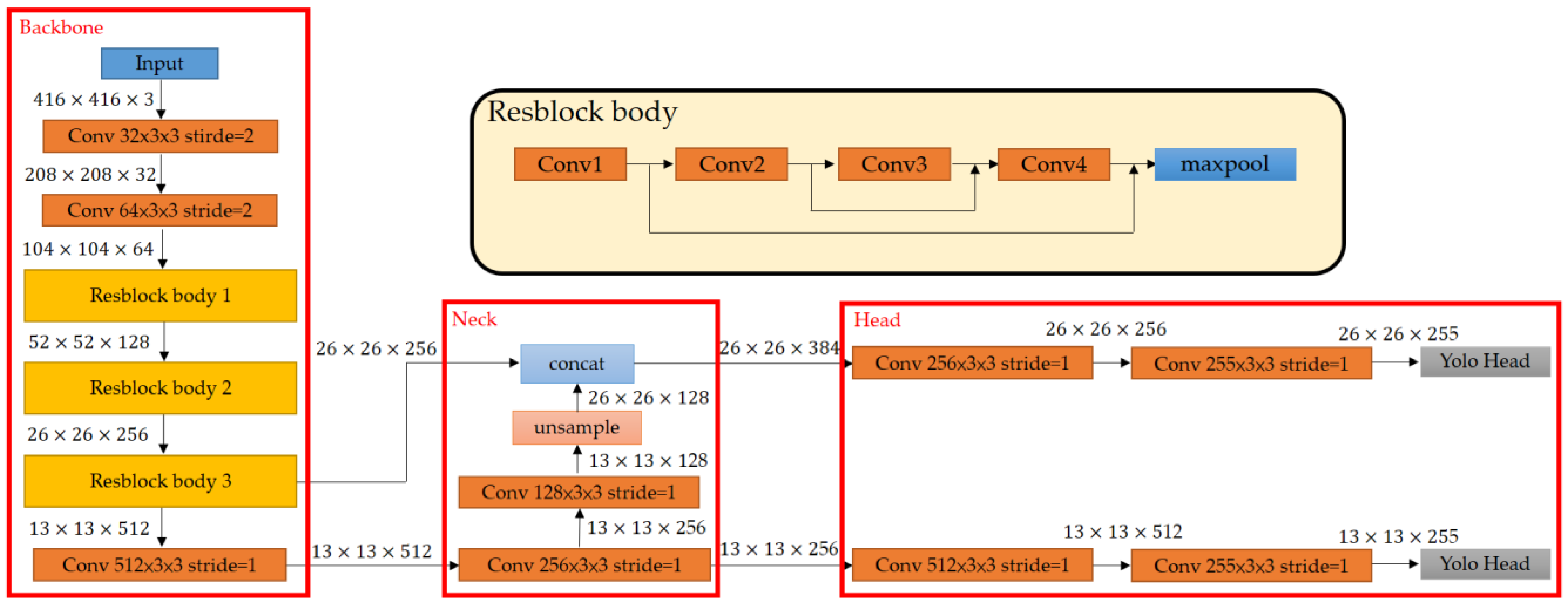
Compared with YOLO-v4, YOLO v4-tiny has only one-tenth of the weight parameter, has considerable advantages in speed and storage space, and is easier to adapt to resource-limited situations such as embedded systems. YOLO v4-tiny is an object detection model based on the convolutional neural network (CNN), with a total of 38 layers and can be divided into three parts, Backbone, Neck, and YOLO head, as shown in
Figure 3.
The backbone consists of a series of convolutional layers and a Resblock body [
19]. A Resblock body is one of the key parts of the backbone. This structure retains low-level features while extracting deeper features, effectively increasing the depth of the model and helping the convolutional layer to capture features of different scales, thereby better-capturing targets of different sizes to improve the accuracy of the model.
The features of feature maps of different scales are fused through upsampling and convolution layers to improve the detection capabilities of targets of different scales without increasing excessive calculations.
YOLO v4-tiny uses two detection layers of different scales, which are responsible for bounding boxes of three specific scales. YOLO v4-tiny converts the received feature maps into target detection results through the detection layer and predicts the corresponding bounding boxes with classified labels and confidence scores.
3. Materials and Methods
The comparison of the advantages and disadvantages of the previously introduced methods with those of our method are shown in
Table 1. To safeguard user information and offer comprehensive security protection across all time frames and areas, establishing a stable signal to enhance recognition rates is essential. Due to the increasingly complex electromagnetic environment and signals, traditional identification methods struggle to achieve desired recognition rates. This paper proposes a deep learning-based approach that analyzes the received signals to generate point cloud diagrams, enabling classification algorithms to more effectively differentiate between data points.
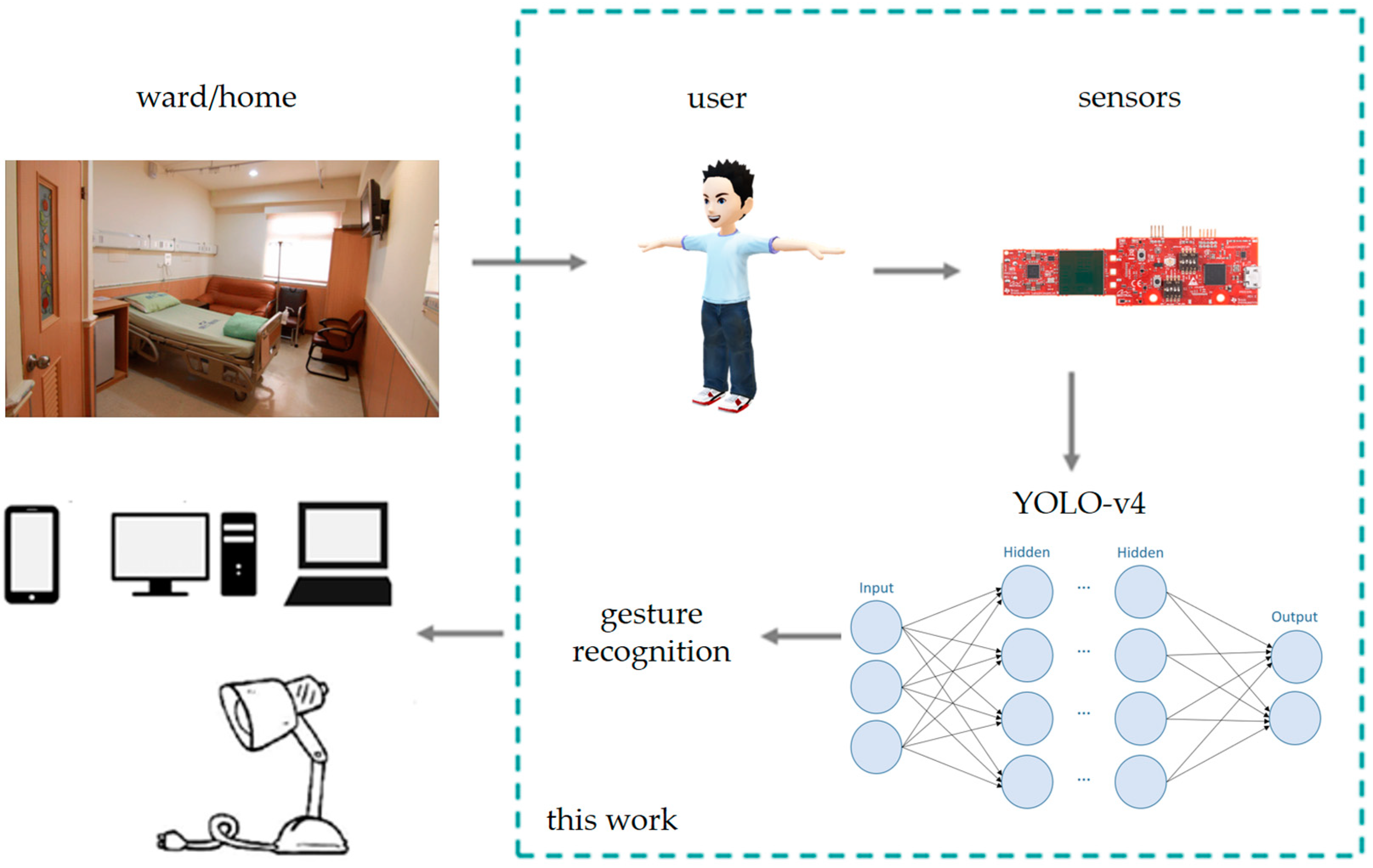
The architecture of the nursing-secure-care system is shown in
Figure 4, which is constructed by a Millimeter sensor, gesture recognition system, and IoT communication system. In this paper, we focus on how to make the point-cloud image, how to build the recognition system with YOLO, and how to make the MQTT commands to control secure devices for the embedded systems. The confirmed posture results are sent via MQTT to the Topic within the Broker, which in this case is Pi-4. Subsequently, messages are sent separately based on the subscribed content of the subscribers, enabling the rapid transmission of the current posture to users’ devices. Millimeter sensors transmit electromagnetic wave signals, which are reflected by objects, similar to radar systems. By capturing reflected signals, radar systems can determine the distance, velocity, and angle of objects for micro-Doppler effects, which can be processed to provide unique data sets such as, distance, velocity, and angle, as well as the ability to distinguish different targets, which enables the sensor to detect the characteristics of different objects within the detection range. These data, for example, allow sensors to sense the echo signals—modulation effects from tiny movements—that include the typical features of objects such as, the spinning speed of a bicycle wheel, the swaying arms of a person, or the running limbs of an animal. In this project, we will build a sensing system with an AI model that can be used in the embedded systems. To approach these goals, we will go through this project as follows. First, we will generate the pixel coordinates by calculating the echo signals of the Doppler effects in period. Second, the pixel coordinates will be used to build the pixel cloud images with layer-coloring methods. Noise can be filtered with mathematical morphologies, such as erosion and dilation methods,. Third, we classify the pixel cloud images and train them with machine learning models, such as YOLO-v4, to obtain weight tables for sensing event recognition. Fourth, we simplify the machine learning models and build up the performance-oriented programs to ensure that we can run the mmWave sensing system in the embedded systems.
This paper employs the TI IWR6843AOP single-chip mmWave sensor as shown in
Figure 5. This chip operates within the frequency range of 60 GHz to 64 GHz and functions adequately in general environments ranging from −40 degrees to 105 degrees Celsius. It consists of 4 receiver (RX) and 3 transmitter (TX) antenna modules. The receiver operates at a Baud rate of 115,200 while the transmitter can reach up to 921,600, facilitating high-speed and precise data transmission. It offers a transmission speed of 50 ms/frame. In this study, we utilize the UART interface to connect with a computer. The received data is analyzed by the computer and plotted on the canvas (Mat window) within the program, enabling our observation.
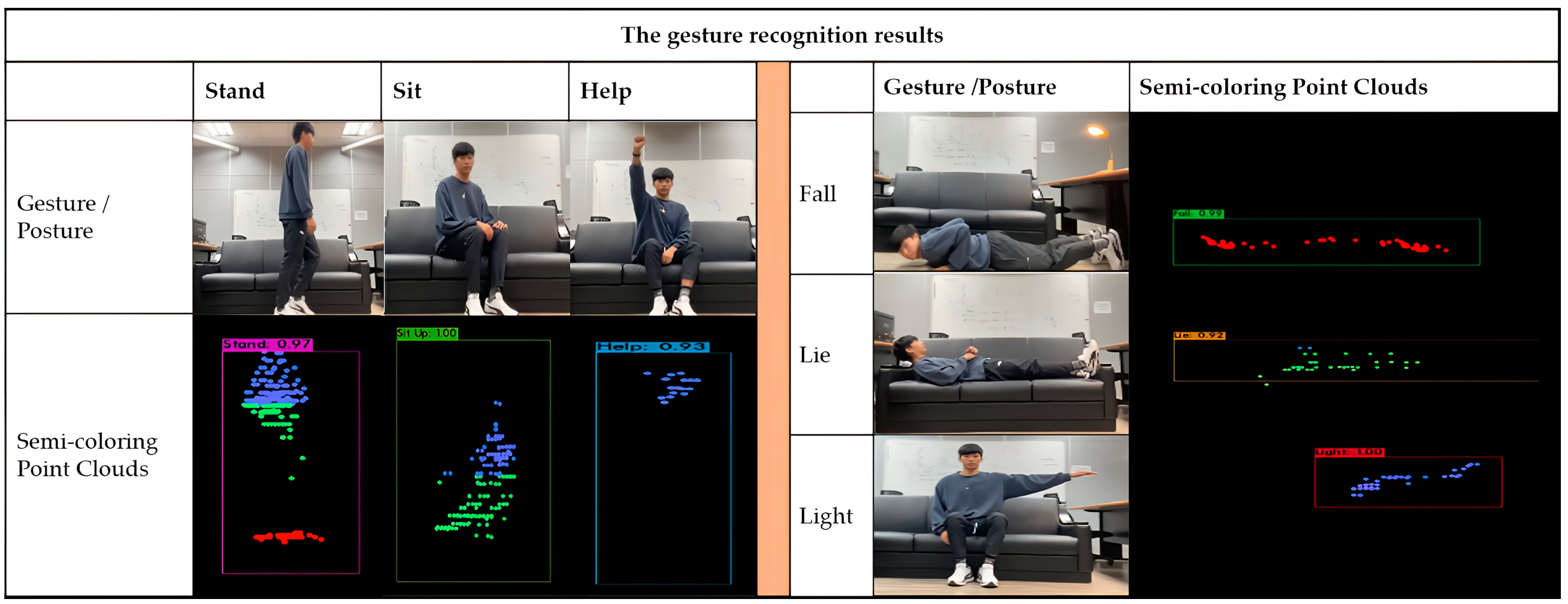
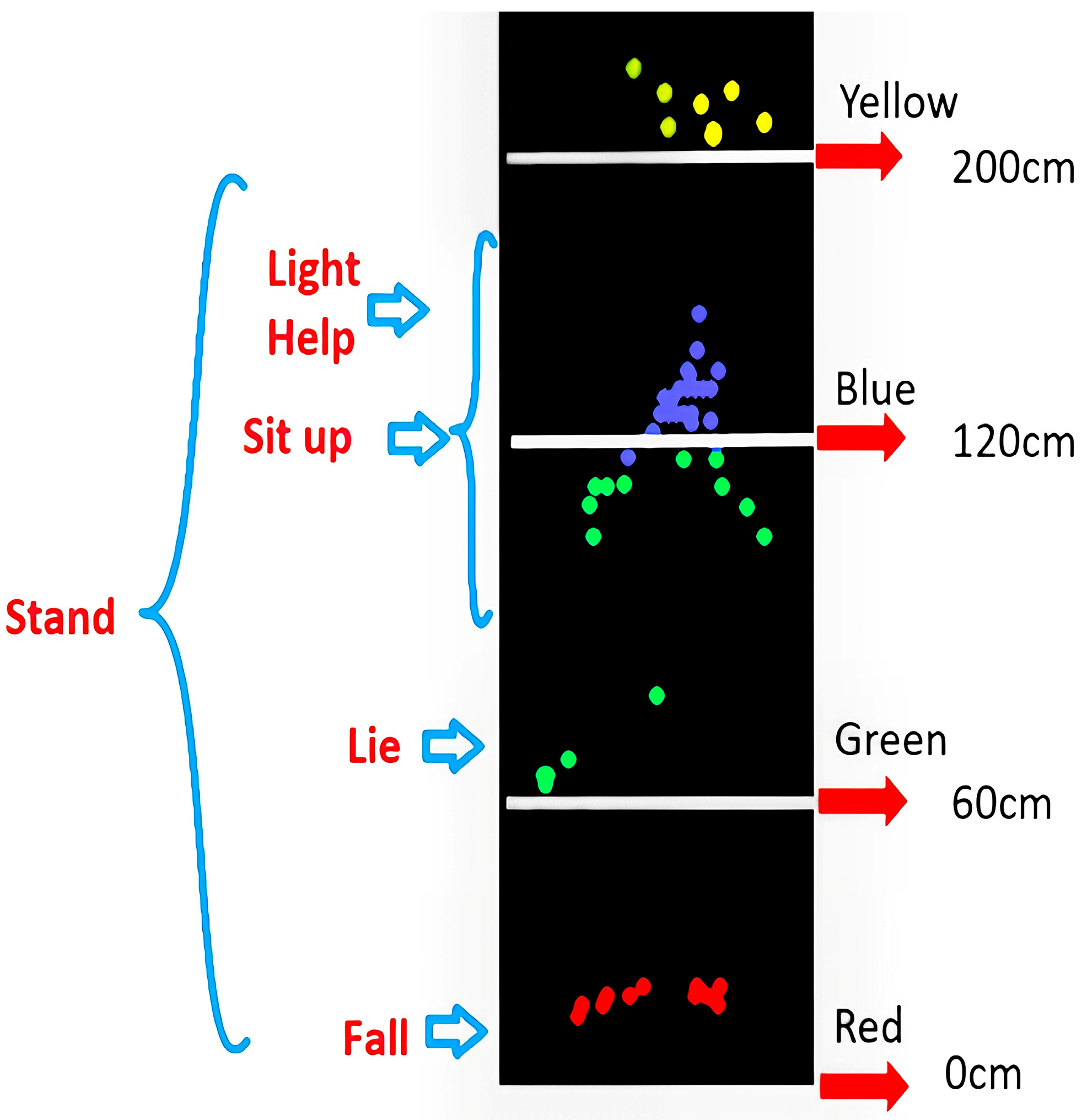
To make it easier for users to use our entire system, we assign colors to the point cloud according to the distance. When the position is far away from what we need to identify, we will lighten the color. In this way, we will tell the user where the setting needs to be adjusted. to find the best distance for attitude recognition. Through the results, it is found that this method has the following advantages. From walking (Stand), sitting (Sit), lying down (for sleep time: Lie), falling (abnormal motion detection: Fall), switching lights (Light), and help (distress: Help) gestures, such as those shown in
Figure 6, all can be completed within the complete set of safety protection behavior system in our designs.
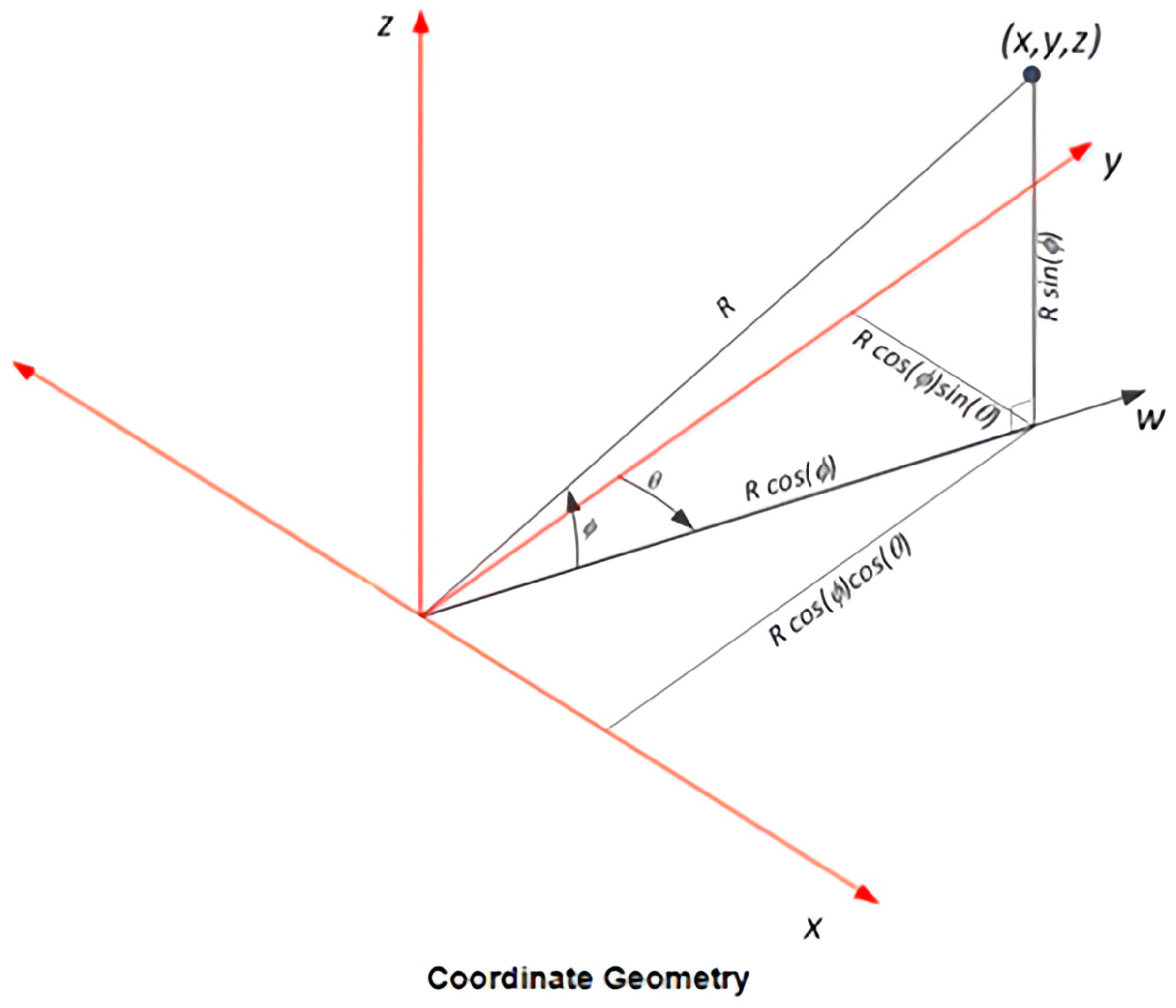
When the mmWave detects objects by the micro-Doppler effect, the parameters of elevation, azimuth, and Doppler velocity, will be obtained. We will utilize Equations (1)–(3) to compute coordinates, thereby converting the mmWave spherical coordinates into Cartesian coordinates, as shown in
Figure 7, as follows:
To increase the gesture recognition rate, we propose the layer-coloring method. These points will be made as semi-coloring pixel cloud images according to the height, distance, and direction. The coloring mapped table for height is shown in
Table 2. We use pixel cloud images, as illustrated in
Figure 8, to create classifying and labelling as training target objects for the machine learning model. After training is complete, we can use the weight tables to make an event recognition system. To obtain the time sequence of the scenario, we grab the pixel cloud images of each frame and overlap them by an adaptive time paragraph, such as 0.2 s. The semi-coloring pixel cloud images become the input source data of the mmWave sensing system.
From
Table 3, the recognition rates without semi-coloring illustrate that misjudgments are serious, such that the gesture Fall can be recognized as the gesture Lie, the gesture Light, and the gesture Fall, making it impossible to accurately identify the correct one.
From
Table 4, the recognition rates with semi-coloring illustrate that the error rate decreases and approaches 0%, which means that the correct posture can be accurately identified. Therefore, the semi-coloring method is an excellent approach to recognizing the gestures.
In deep learning, the convolutional neural network (CNN) is a type of deep neural network, which is the most common mode in current applications and is best at image processing. It is inspired by the human visual nervous system and is designed using a variant of multilayer perceptron that requires minimal preprocessing, based on their shared weight architecture and translation-invariant features.
The CNN method has two major characteristics:
It can effectively reduce the dimensionality of pictures with large amounts of data into small amounts of data.
It can effectively retain image features and conform to the principles of image processing.
The first problem solved by CNN is to simplify complex problems. It reduces the dimension of a large number of parameters into a small number of parameters and then processes them. It retains the characteristics of the image in a visual-like way, and when the image is flipped, rotated, or positionally changed, it can also effectively identify similar images. The YOLO-v4 model is a machine learning operation model with an optimization strategy in the CNN field. The YOLO v4-tiny model is often used in embedded environments due to its large number of layers. We will deeply survey and implement the mmWave sensing system in theYOLO-v4 model in the embedded platform. To speed the edge computing, three target problems will be studied in depth:
Domain Quantization for saving storage and improving computing performance.
CNN layers to be reduced, based on the YOLO v4-tiny model as the specific light CNN model to speed up object recognition computing.
Data Parallelism programming method to be used for coding the CNN model to approach power-efficient computing in embedded systems.
In this paper, we will focus on four objective tasks: (1) Preparation of precise pixel cloud images. (2) Build a mmWave sensing system on an embedded system to detect object location, recognize gesture and posture, distinguish life signs, and track movement of objects. (3) Simplify the machine learning models and create performance-oriented programs to enable the running of a mmWave sensing system in the embedded systems. (4) Test and verify our design. When this project is completed, the effective mmWave sensing system will be created on a smart embedded platform and a demon system will be run to verify our studies.
5. Discussion
Although the integration of sensing tools and communication systems has been recognized as a pivotal area, there is a deficiency in comprehensive exploration aimed at simplifying these models to achieve heightened efficiency and reduced resource consumption. There are limited comprehensive studies showcasing the effective amalgamation of these components.
This paper aims to integrate sensing tools with communication systems to facilitate efficient data transmission and processing. It addresses the challenge of simplifying intricate machine learning models, specifically the YOLO v4-tiny model, in order to improve performance, while minimizing resource utilization. Additionally, the research focuses on the development of hardware-based quantization techniques designed to convert data from floating-point to fixed-point number formats. This endeavor is intended to expedite computation processes and reduce storage requirements.
Simplified machine learning models and hardware-based quantization techniques can benefit scientists and researchers by providing efficient methods for processing data and reducing computational resources, thereby accelerating the pace of research in machine learning and related fields. Moreover, for society, these advancements can lead to the creation of more efficient and accurate systems for healthcare, security, and surveillance, contributing to improved safety measures, healthcare monitoring, and technological advancements that benefit society at large.
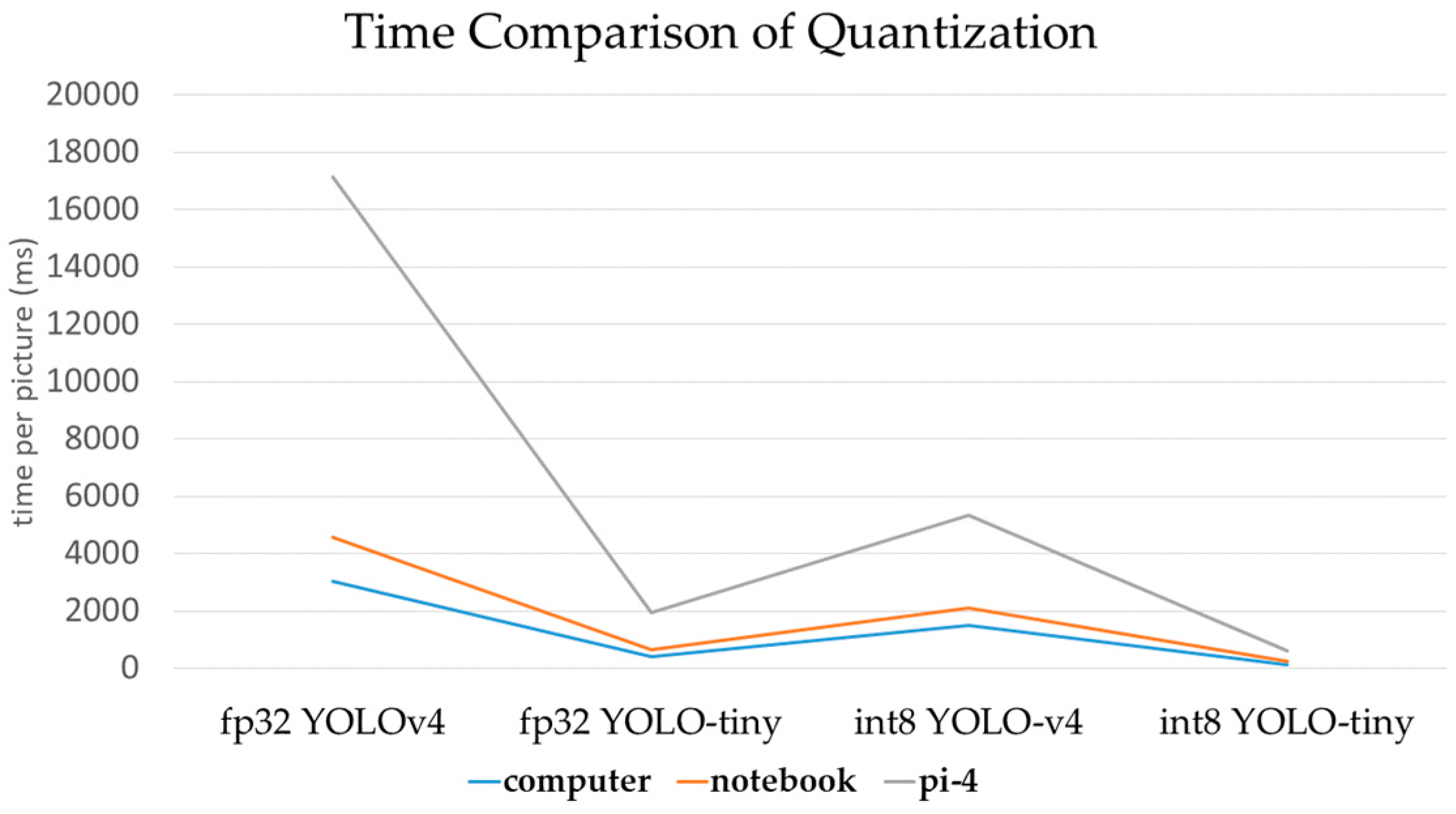
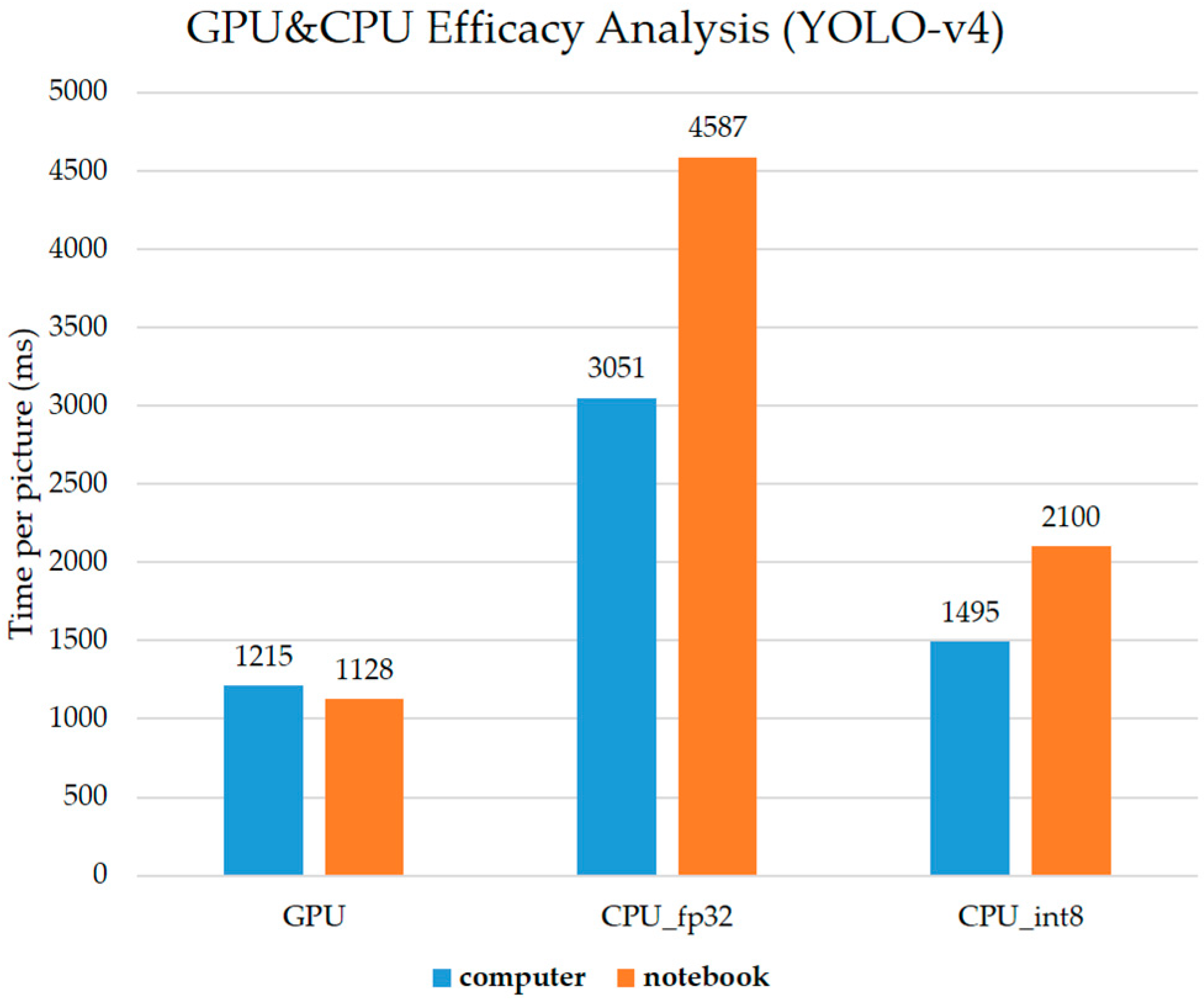
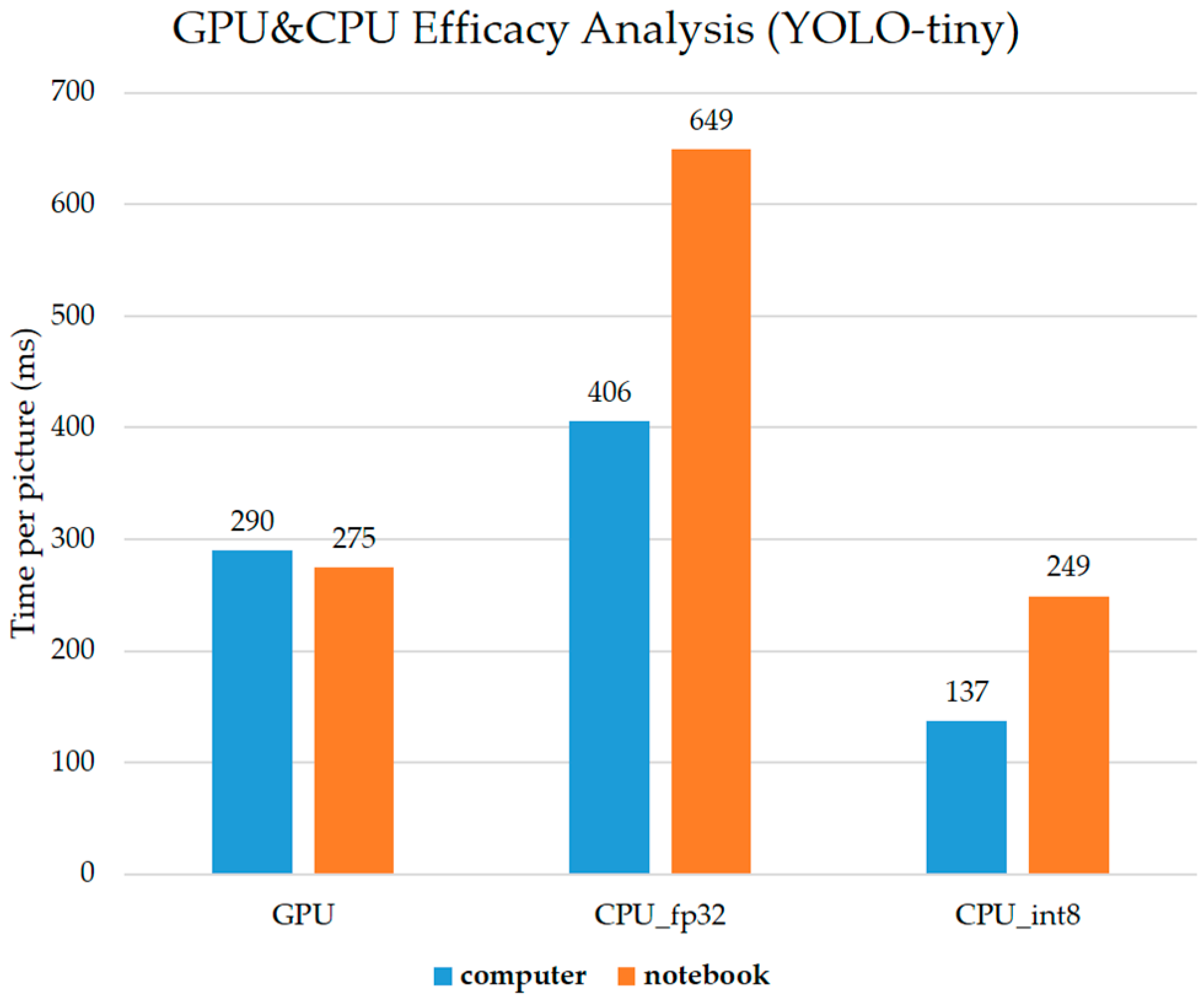
We analyze the effects of the proposed quantization method to be used in YOLO models, which are computed on PC CPU-only (tagged as CPU) stations and CPU + GPU (tagged as GPU) stations.
Figure 9 illustrates that computing performance with the proposed quantization method on CPU is lower by a time difference of 280 ms compared with GPU in YOLO-v4 models.
Figure 10 shows that computing performance with the proposed quantization method on CPU is higher by a time difference of 153 ms compared with GPU in YOLO v4-tiny models. Following the above results, the proposed quantization method is an important mechanism for the computing of the YOLO-v4 model. In particular, the YOLO v4-tiny model with the proposed quantization method on CPU has excellent performance compared with GPU. This result proves that the proposed quantization method is suitable for use on the YOLO v4-tiny model in the embedded systems to create a smart IOT system. According to the evaluation results, we can replace Resblock body 2 and Resblock body 3 with convolutional layers to simplify the number of layers. In this way, the total reduced convolution operations are 5 layers and the computing performance of the YOLO v4-tiny model will be improved by up to 20%.
Currently, performance testing relies primarily on C language for estimating the prediction time of images. In the future, the aim is to implement the entire framework onto a chip and establish a complete computing architecture. Regarding the utilization of YOLO-v4 in this paper, there is a hope to adjust the architecture to design a learning model that better suits the goals of this research with enhanced performance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}