
Predicting Road Traffic Collisions Using a Two-Layer Ensemble Machine Learning Algorithm

Abstract
:1. Introduction
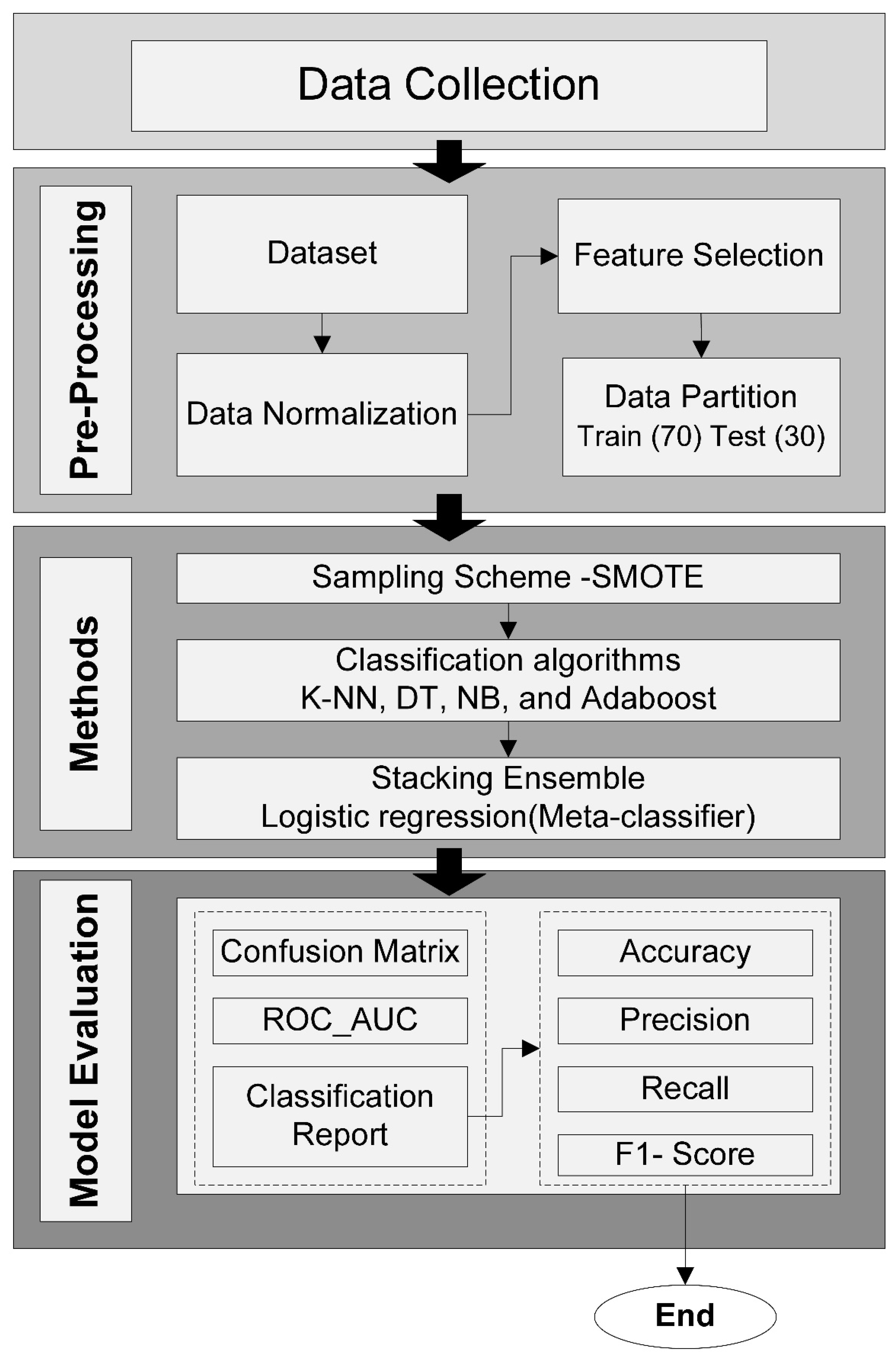
2. Materials and Methods
2.1. Study Population and Data Description
2.2. Data Preprocessing
Feature Selection
- Particle swarm optimization (PSO) algorithm: This technique works by searching for the optimal subset of features. It locates the minimum of a function by creating several ‘particles’. These particles store their best position, as well as the global position. It is this combination of local and global information that gives rise to ‘swarm intelligence’ [21]. In our study, we implemented XGBoost and linear regression algorithms to select the best features.
- Recursive feature elimination: This technique works by selecting the optimal subset of features for estimation by iteratively reducing 0 to N features [22]. The best subset is then chosen based on the model’s accuracy, cross-validation score, or Roc-Auc curve.
- Univariate feature selection: This approach works by selecting the optimal features using univariate statistical tests. It might be considered a stage in the estimator’s preprocessing process [23]. In our study, we implemented the chi-squared statistical test using the SelectKBest method.
- Feature importance: This works by classifying and evaluating each attribute to create splits. Decision tree models that are developed on ensembles; for example, extra trees and random forests can be used to rank the relevance of certain features [24]. In our study, we employed the extra trees classifier for feature selection.
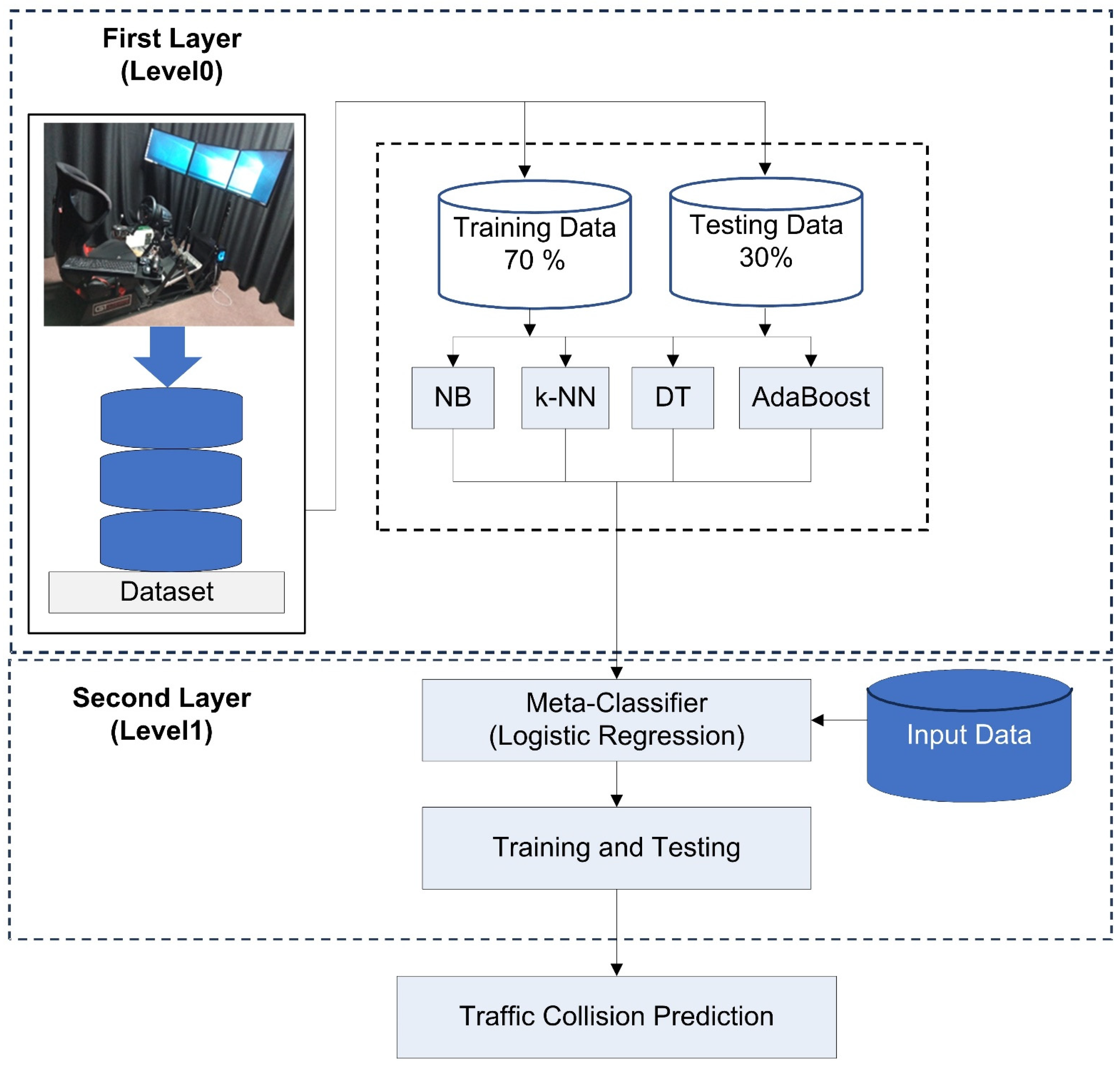
2.3. Building the Two-Layer Ensemble Model
2.4. Validation and Performance Measurement
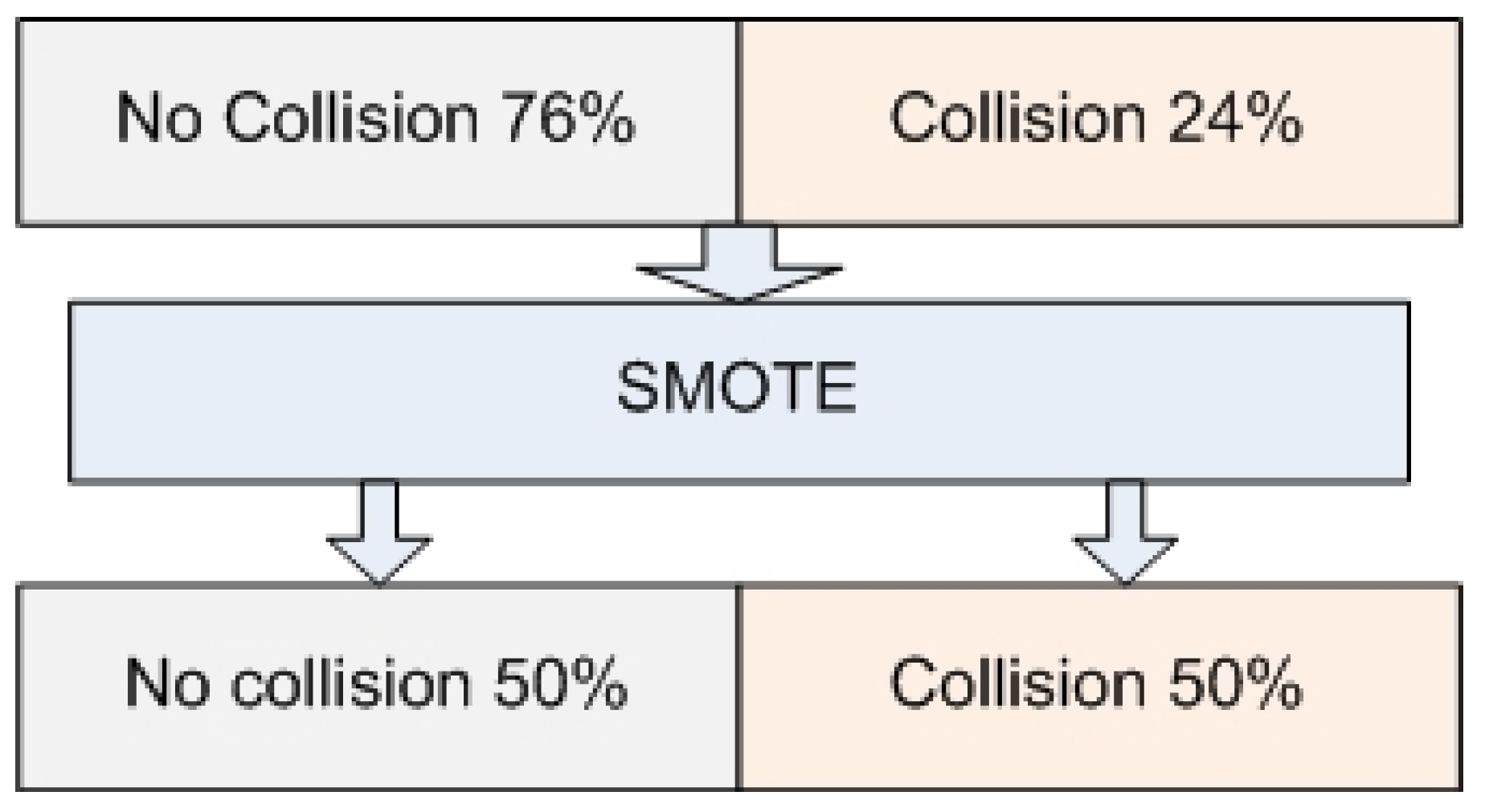
2.5. Data Oversampling
3. Results
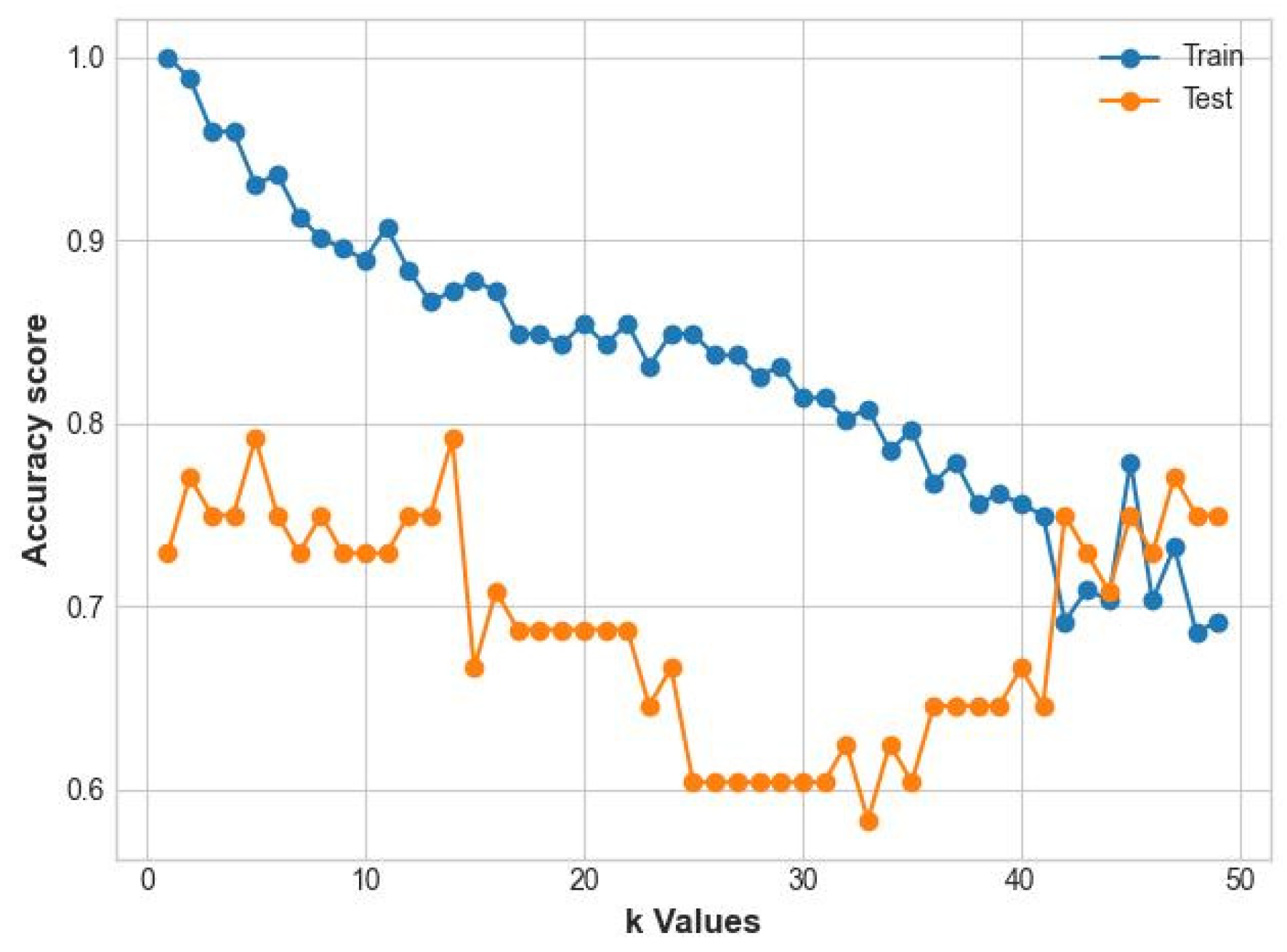
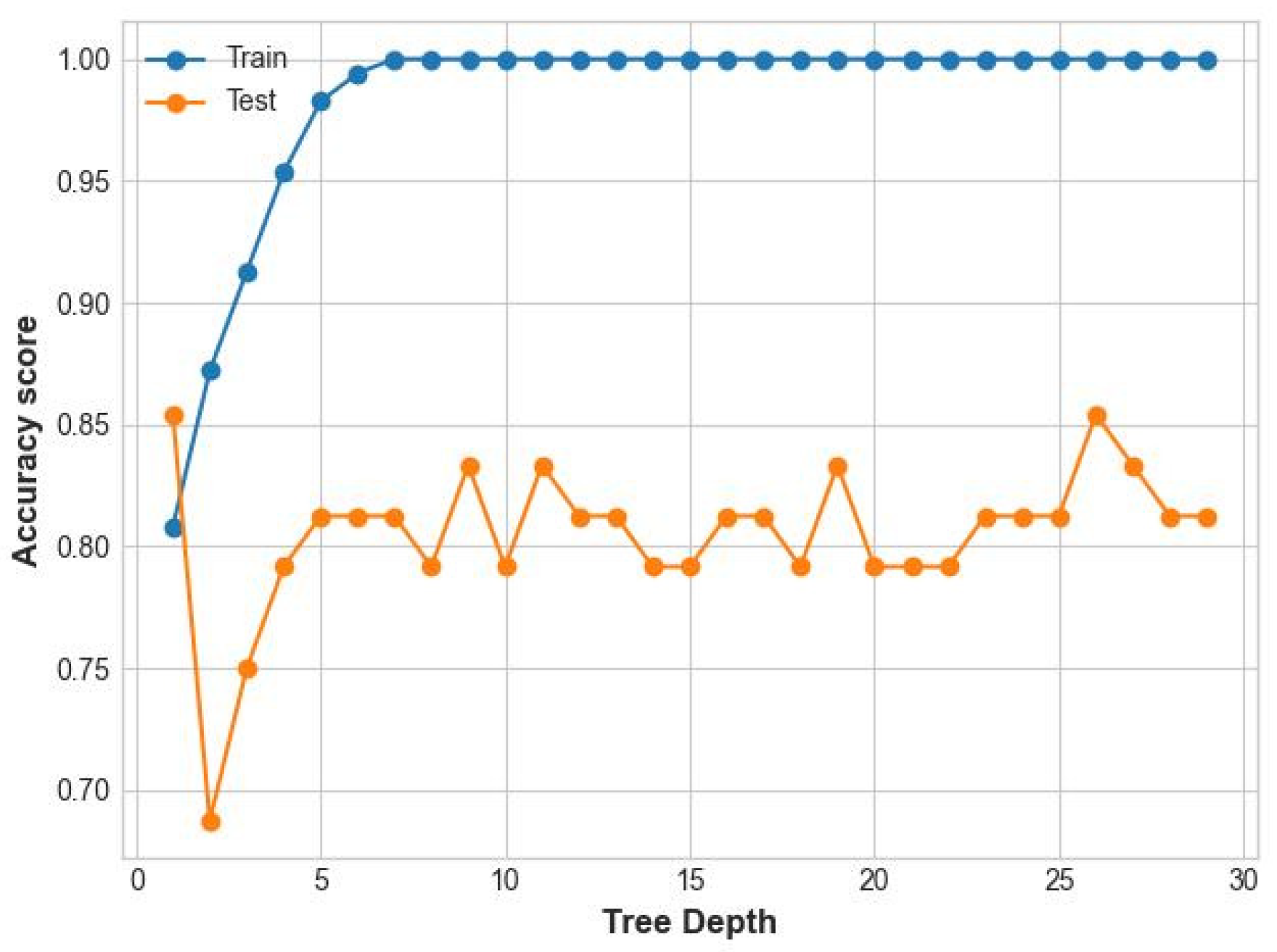
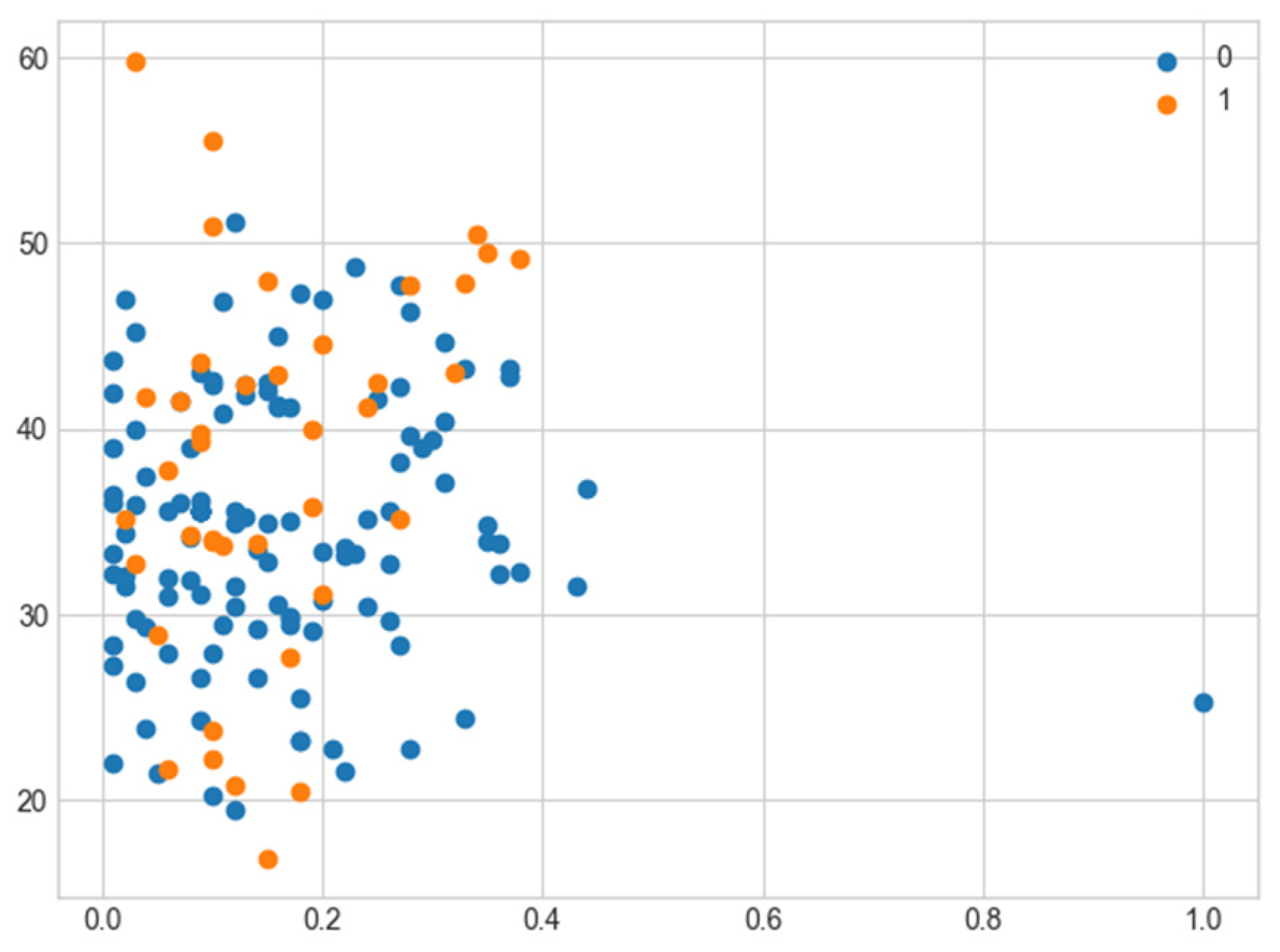
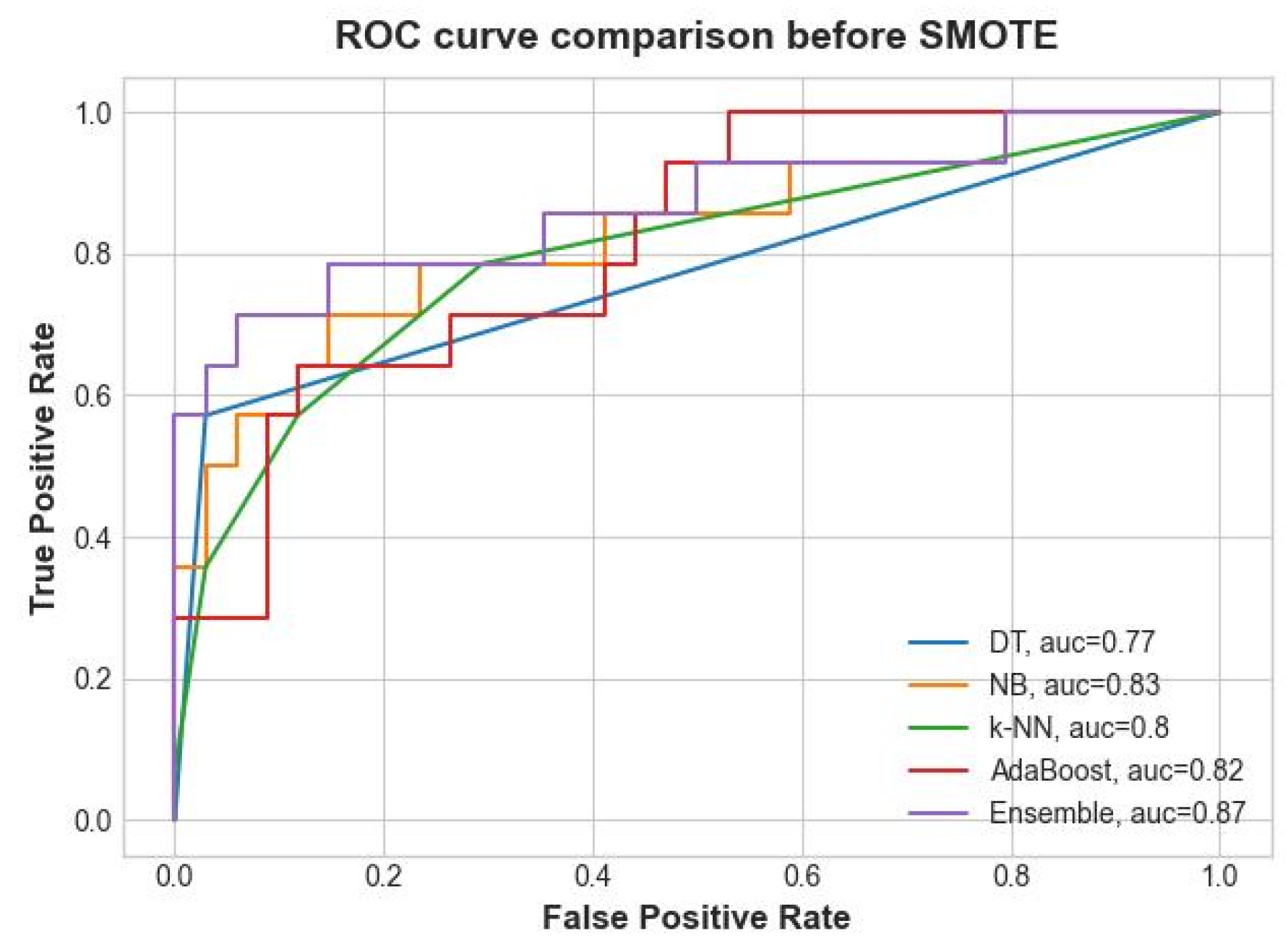
3.1. Results of the Classification before SMOTE
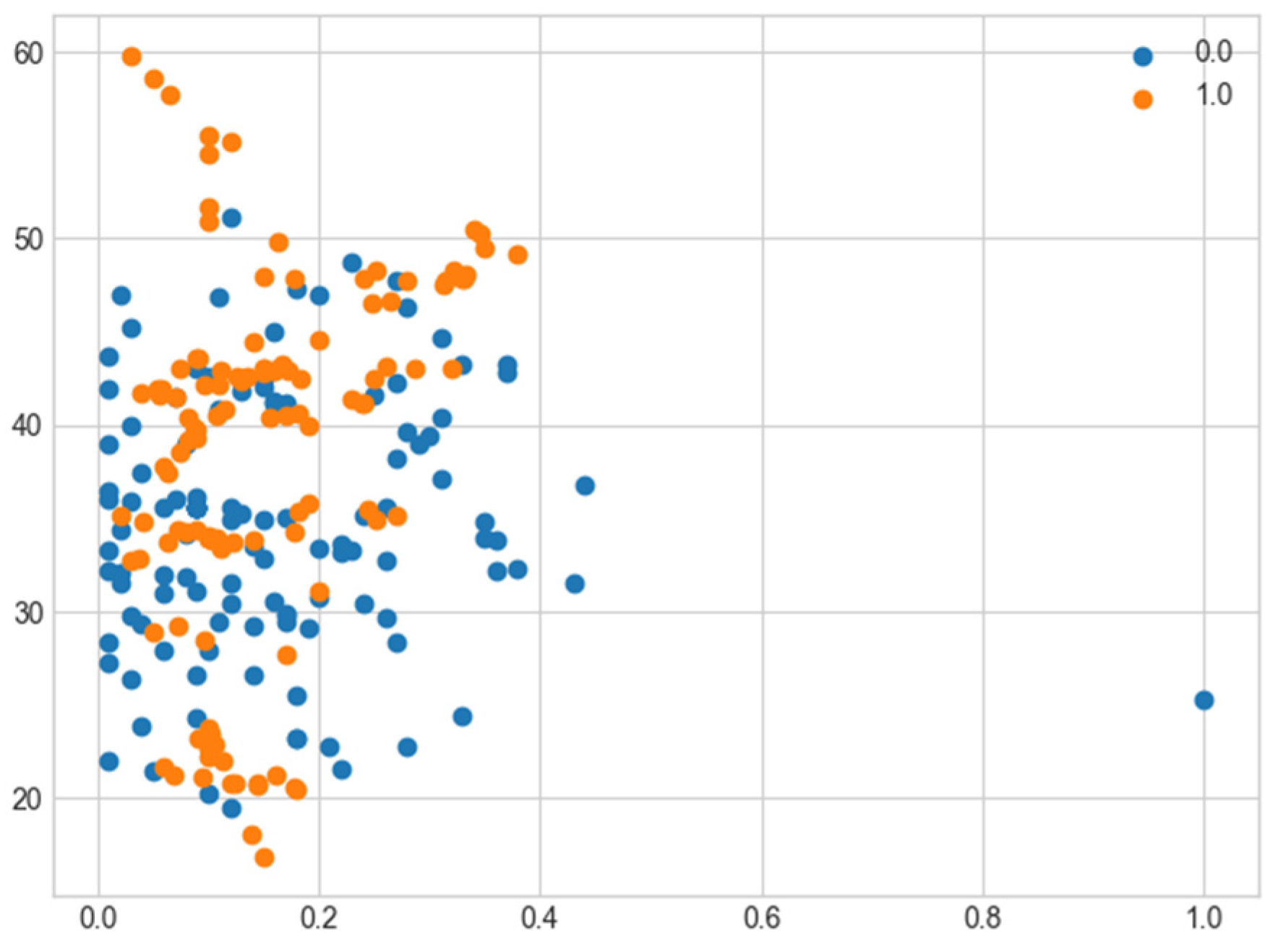
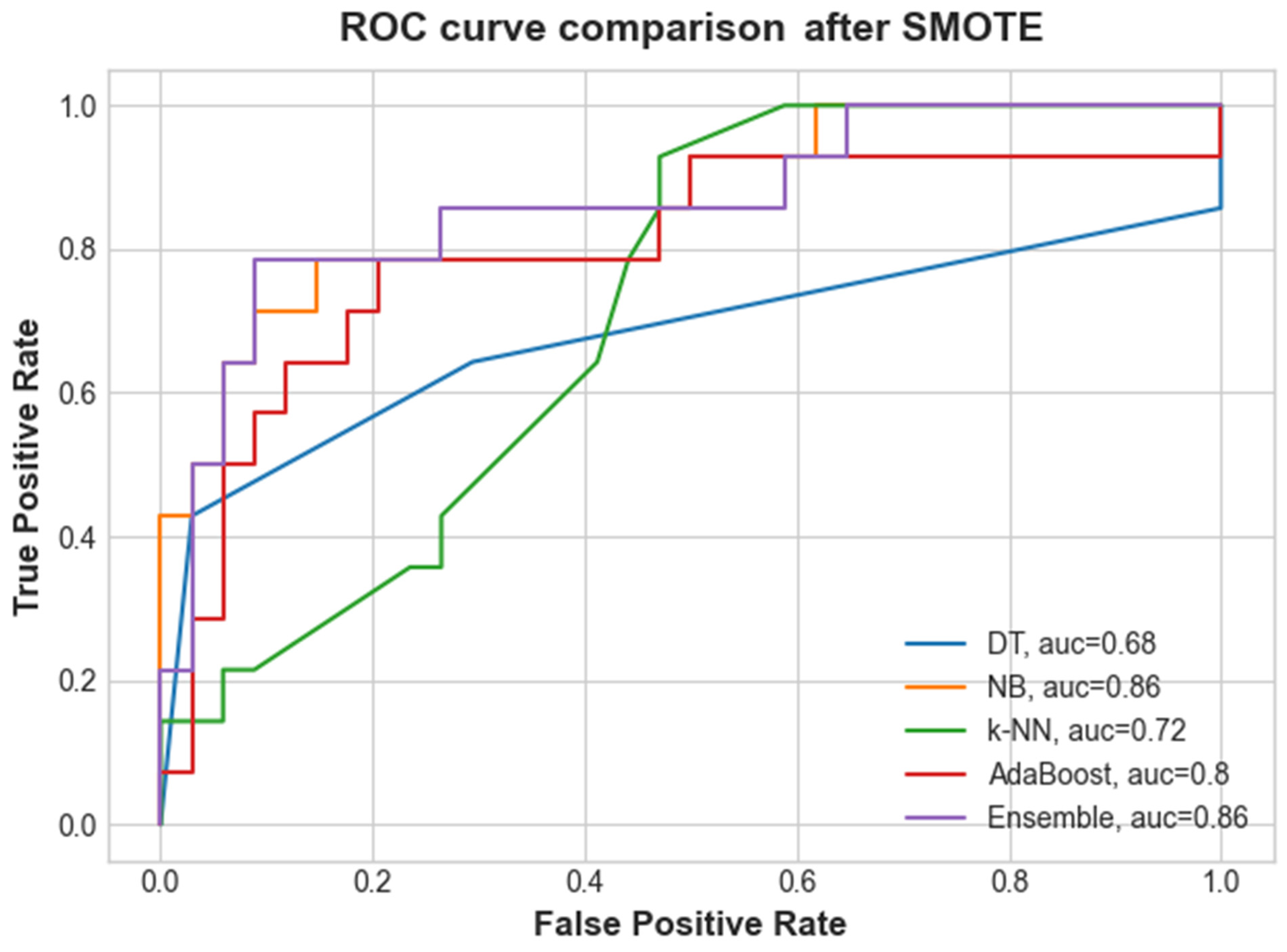
3.2. Results of the Classification after SMOTE
3.3. Results of the Proposed Ensemble Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO. Death on Roads. Available online: https://extranet.who.int/roadsafety/death-on-the-roads/#deaths/per_100k (accessed on 16 December 2023).
- Road Traffic Injuries. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 16 December 2023).
- NTSA. Report on Road Safety. 2022. Available online: https://www.the-star.co.ke/news/2023-01-18-4690-people-died-in-road-accidents-in-2022-report/ (accessed on 25 July 2023).
- Decade of Action for Road Safety. Available online: https://www.who.int/teams/social-determinants-of-health/safety-and-mobility/decade-of-action-for-road-safety-2021-2030 (accessed on 10 May 2023).
- Al Mamlook, R.E.; Ali, A.; Hasan, R.A.; Kazim, H.A.M. Machine Learning to Predict the Freeway Traffic Accidents-Based Driving Simulation. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 630–634. [Google Scholar] [CrossRef]
- Li, Z.; Liao, H.; Tang, R.; Li, G.; Li, Y.; Xu, C. Mitigating the impact of outliers in traffic crash analysis: A robust Bayesian regression approach with application to tunnel crash data. Accid. Anal. Prev. 2023, 185, 107019. [Google Scholar] [CrossRef]
- Jamal, A.; Zahid, M.; Rahman, M.T.; Al-Ahmadi, H.M.; Almoshaogeh, M.; Farooq, D.; Ahmad, M. Injury severity prediction of traffic crashes with ensemble machine learning techniques: A comparative study. Int. J. Inj. Control. Saf. Promot. 2021, 28, 408–427. [Google Scholar] [CrossRef]
- Zheng, L.; Sayed, T.; Mannering, F. Modeling traffic conflicts for use in road safety analysis: A review of analytic methods and future directions. Anal. Methods Accid. Res. 2021, 29, 100142. [Google Scholar] [CrossRef]
- Bokaba, T.; Doorsamy, W.; Paul, B.S. Comparative Study of Machine Learning Classifiers for Modelling Road Traffic Accidents. Appl. Sci. 2022, 12, 828. [Google Scholar] [CrossRef]
- AlMamlook, R.E.; Kwayu, K.M.; Alkasisbeh, M.R.; Frefer, A.A. Comparison of Machine Learning Algorithms for Predicting Traffic Accident Severity. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 272–276. [Google Scholar] [CrossRef]
- Berhanu, Y.; Alemayehu, E.; Schröder, D. Examining Car Accident Prediction Techniques and Road Traffic Congestion: A Comparative Analysis of Road Safety and Prevention of World Challenges in Low-Income and High-Income Countries. J. Adv. Transp. 2023, 2023, 6643412. [Google Scholar] [CrossRef]
- Al-Nashashibi, M.; Hadi, W.; El-Khalili, N.; Issa, G.; AlBanna, A.A. A New Two-step Ensemble Learning Model for Improving Stress Prediction of Automobile Drivers. Int. Arab. J. Inf. Technol. 2021, 18, 819–829. [Google Scholar] [CrossRef]
- Ameksa, M.; Mousannif, H.; Al Moatassime, H.; Elassad, Z.E.A. Crash Prediction using Ensemble Methods. In Proceedings of the 2nd International Conference on Big Data, Modelling and Machine Learning, Kenitra, Morocco, 5–6 June 2021; SCITEPRESS—Science and Technology Publications: Kenitra, Morocco, 2021; pp. 211–215. [Google Scholar] [CrossRef]
- Amiri, P.A.D.; Pierre, S. An Ensemble-Based Machine Learning Model for Forecasting Network Traffic in VANET. IEEE Access 2023, 11, 22855–22870. [Google Scholar] [CrossRef]
- Yang, K.; Al Haddad, C.; Yannis, G.; Antoniou, C. Classification and Evaluation of Driving Behavior Safety Levels: A Driving Simulation Study. IEEE Open J. Intell. Transp. Syst. 2022, 3, 111–125. [Google Scholar] [CrossRef]
- Zhang, X.; Yan, X. Predicting collision cases at unsignalized intersections using EEG metrics and driving simulator platform. Accid. Anal. Prev. 2023, 180, 106910. [Google Scholar] [CrossRef]
- Xiao, W.; Luo, X.; Xie, S. Feature semantic space-based sim2real decision model. Appl. Intell. 2022, 53, 4890–4906. [Google Scholar] [CrossRef]
- Crowder, M.J.; Kimber, A.C.; Smith, R.L.; Sweeting, T.J. Statistical Analysis of Reliability Data, 1st ed.; Routledge: London, UK, 2017. [Google Scholar] [CrossRef]
- Shakil, F.A.; Hossain, S.M.; Hossain, R.; Momen, S. Prediction of Road Accidents Using Data Mining Techniques. In Algorithms for Intelligent Systems, Proceedings of International Conference on Computational Intelligence and Emerging Power System, Ajmer, India, 31 January 2021; Bansal, R.C., Zemmari, A., Sharma, K.G., Gajrani, J., Eds.; Springer: Singapore, 2022; pp. 25–35. [Google Scholar] [CrossRef]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 103375. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, G.; Sun, J.; Bavirisetti, D.P.; Xiao, G. PSO-Stacking improved ensemble model for campus building energy consumption forecasting based on priority feature selection. J. Build. Eng. 2023, 72, 106589. [Google Scholar] [CrossRef]
- Zhang, A.; Patton, E.W.; Swaney, J.M.; Zeng, T.H. A Statistical Analysis of Recent Traffic Crashes in Massachusetts. arXiv 2019, arXiv:1911.02647. [Google Scholar] [CrossRef]
- Ascensión, A.M.; Ibáñez-Solé, O.; Inza, I.; Izeta, A.; Araúzo-Bravo, M.J. Triku: A feature selection method based on nearest neighbors for single-cell data. GigaScience 2022, 11, giac017. [Google Scholar] [CrossRef] [PubMed]
- Mittal, M.; Gupta, S.; Chauhan, S.; Saraswat, L.K. Analysis on road crash severity of drivers using machine learning techniques. Int. J. Eng. Syst. Model. Simul. 2022, 13, 154. [Google Scholar] [CrossRef]
- Seraj, A.; Mohammadi-Khanaposhtani, M.; Daneshfar, R.; Naseri, M.; Esmaeili, M.; Baghban, A.; Eslamian, S. Cross-validation. In Handbook of Hydroinformatics; Elsevier: Amsterdam, The Netherlands, 2023; pp. 89–105. [Google Scholar] [CrossRef]
- Santos, D.; Saias, J.; Quaresma, P.; Nogueira, V.B. Machine Learning Approaches to Traffic Accident Analysis and Hotspot Prediction. Computers 2021, 10, 157. [Google Scholar] [CrossRef]
- Xiao, J. SVM and KNN ensemble learning for traffic incident detection. Phys. A Stat. Mech. Its Appl. 2019, 517, 29–35. [Google Scholar] [CrossRef]
- Liu, L.; Özsu, M.T. (Eds.) k-Nearest Neighbor Classification. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; p. 1590. [Google Scholar] [CrossRef]
- Abdullah, P.; Sipos, T. Drivers’ Behavior and Traffic Accident Analysis Using Decision Tree Method. Sustainability 2022, 14, 11339. [Google Scholar] [CrossRef]
- Lu, Y.; Ye, T.; Zheng, J. Decision Tree Algorithm in Machine Learning. In Proceedings of the 2022 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 20–21 August 2022; pp. 1014–1017. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Zhang, X. A Study of Fatigue Driving Detection System Based on AdaBoost Algorithm. In Proceedings of the 2022 4th International Conference on Artificial Intelligence and Advanced Manufacturing (AIAM), Hamburg, Germany, 7–9 October 2022; pp. 32–35. [Google Scholar] [CrossRef]
- Zhao, H.; Yu, H.; Li, D.; Mao, T.; Zhu, H. Vehicle Accident Risk Prediction Based on AdaBoost-SO in VANETs. IEEE Access 2019, 7, 14549–14557. [Google Scholar] [CrossRef]
- Yang, L.; Zhao, Q. An aggressive driving state recognition model using EEG based on stacking ensemble learning. J. Transp. Saf. Secur. 2023. [Google Scholar] [CrossRef]
- Tang, J.; Liang, J.; Han, C.; Li, Z.; Huang, H. Crash injury severity analysis using a two-layer Stacking framework. Accid. Anal. Prev. 2019, 122, 226–238. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Meng, X.; Song, L. A novel ensemble learning method for crash prediction using road geometric alignments and traffic data. J. Transp. Saf. Secur. 2020, 12, 1128–1146. [Google Scholar] [CrossRef]
- Ishaq, A.; Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Improving the Prediction of Heart Failure Patients’ Survival Using SMOTE and Effective Data Mining Techniques. IEEE Access 2021, 9, 39707–39716. [Google Scholar] [CrossRef]
- Jiang, Z.; Yang, J.; Liu, Y. Imbalanced Learning with Oversampling based on Classification Contribution Degree. Adv. Theory Simul. 2021, 4, 2100031. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Lee, D.; Kim, K. An efficient method to determine sample size in oversampling based on classification complexity for imbalanced data. Expert Syst. Appl. 2021, 184, 115442. [Google Scholar] [CrossRef]
- Elassad, Z.E.A.; Mousannif, H.; Al Moatassime, H. Class-imbalanced crash prediction based on real-time traffic and weather data: A driving simulator study. Traffic Inj. Prev. 2020, 21, 201–208. [Google Scholar] [CrossRef]
- Sağlam, F.; Cengiz, M.A. A novel SMOTE-based resampling technique trough noise detection and the boosting procedure. Expert Syst. Appl. 2022, 200, 117023. [Google Scholar] [CrossRef]
- Theissler, A.; Thomas, M.; Burch, M.; Gerschner, F. ConfusionVis: Comparative evaluation and selection of multi-class classifiers based on confusion matrices. Knowl.-Based Syst. 2022, 247, 108651. [Google Scholar] [CrossRef]
- Mokoatle, M.; Vukosi Marivate, D.; Michael Esiefarienrhe Bukohwo, P. Predicting Road Traffic Accident Severity using Accident Report Data in South Africa. In Proceedings of the 20th Annual International Conference on Digital Government Research, Dubai, United Arab Emirates, 18 June 2019; ACM: Dubai, United Arab Emirates, 2019; pp. 11–17. [Google Scholar] [CrossRef]
- Mansoor, U.; Ratrout, N.T.; Rahman, S.M.; Assi, K. Crash Severity Prediction Using Two-Layer Ensemble Machine Learning Model for Proactive Emergency Management. IEEE Access 2020, 8, 210750–210762. [Google Scholar] [CrossRef]
- Aldhari, I.; Almoshaogeh, M.; Jamal, A.; Alharbi, F.; Alinizzi, M.; Haider, H. Severity Prediction of Highway Crashes in Saudi Arabia Using Machine Learning Techniques. Appl. Sci. 2022, 13, 233. [Google Scholar] [CrossRef]
- Yang, L.; Aghaabbasi, M.; Ali, M.; Jan, A.; Bouallegue, B.; Javed, M.F.; Salem, N.M. Comparative Analysis of the Optimized KNN, SVM, and Ensemble DT Models Using Bayesian Optimization for Predicting Pedestrian Fatalities: An Advance towards Realizing the Sustainable Safety of Pedestrians. Sustainability 2022, 14, 10467. [Google Scholar] [CrossRef]
- Luo, T.; Wang, J.; Fu, T.; Shangguan, Q.; Fang, S. Risk prediction for cut-ins using multi-driver simulation data and machine learning algorithms: A comparison among decision tree, GBDT and LSTM. Int. J. Transp. Sci. Technol. 2023, 12, 862–877. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Univariate Feature Selection | Recursive Elimination Method | Feature Importance | Particle Swarm Optimization (PSO) |
|---|---|---|---|
| Lane gap | Lane gap | Lane gap | Lane gap |
| Speed | Speed | Speed | Speed |
| Brake | Brake | Brake | Brake |
| Education level | Education level | Education level | Driver Experience |
| Driver Experience | Driver Experience | Driver Experience | Surface condition |
| Driver Age | Driver Age | Driver Age | Gender |
| Total Instances | Predicted | ||
|---|---|---|---|
| Negative | Positive | ||
| Actual | Negative | True Negative (TN) | False Positive (FP) |
| Positive | False Negative (TN) | True Positive (TP) | |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| AdaBoost | 0.79 ± 0.11 | 0.76 ± 0.13 | 0.71 ± 0.12 | 0.72 ± 0.14 |
| k-NN | 0.79 ± 0.08 | 0.81 ± 0.41 | 0.66 ± 0.19 | 0.68 ± 0.25 |
| DT | 0.85 ± 0.12 | 0.87 ± 0.27 | 0.77 ± 0.22 | 0.80 ± 0.19 |
| NB | 0.83 ± 0.05 | 0.82 ± 0.20 | 0.76 ± 0.18 | 0.78 ± 0.10 |
| Two-layer ensemble | 0.83 ± 0.06 | 0.91 ± 0.25 | 0.75 ± 0.19 | 0.79 ± 0.11 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| AdaBoost | 0.79 ± 0.09 | 0.75 ± 0.12 | 0.73 ± 0.13 | 0.74 ± 0.08 |
| k-NN | 0.72 ± 0.13 | 0.66 ± 0.12 | 0.64 ± 0.08 | 0.65 ± 0.06 |
| DT | 0.77 ± 0.08 | 0.69 ± 0.90 | 0.68 ± 0.08 | 0.68 ± 0.10 |
| NB | 0.81 ± 0.06 | 0.72 ± 0.10 | 0.73 ± 0.12 | 0.73 ± 0.07 |
| Two-layer ensemble | 0.85 ± 0.08 | 0.86 ± 0.09 | 0.82 ± 0.09 | 0.83 ± 0.08 |
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| k-NN | 0.79 | 0.97 | 0.87 |
| Decision Trees | 0.83 | 0.86 | 0.85 |
| AdaBoost | 0.83 | 0.86 | 0.85 |
| Naïve Bayes | 0.85 | 0.94 | 0.90 |
| Two-layer ensemble | 0.87 | 0.97 | 0.92 |
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| k-NN | 0.80 | 0.31 | 0.44 |
| Decision Trees | 0.58 | 0.54 | 0.56 |
| AdaBoost | 0.58 | 0.54 | 0.56 |
| Naïve Bayes | 0.80 | 0.62 | 0.70 |
| Two-layer ensemble | 0.89 | 0.62 | 0.73 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| k-NN | 0.65 ± 0.09 | 0.56 ± 0.12 | 0.56 ± 0.10 | 0.56 ± 0.09 |
| Decision Trees | 0.81 ± 0.74 | 0.83 ± 0.12 | 0.70 ± 0.78 | 0.73 ± 0.72 |
| AdaBoost | 0.79 ± 0.08 | 0.76 ± 0.10 | 0.71 ± 0.10 | 0.72 ± 0.09 |
| Naïve Bayes | 0.81 ± 0.10 | 0.77 ± 0.12 | 0.76 ± 0.11 | 0.77 ± 0.09 |
| Two-layer ensemble | 0.88 ± 0.08 | 0.86 ± 0.09 | 0.83 ± 0.11 | 0.84 ± 0.79 |
| Work | Dataset Source | Method | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|---|
| Aldhari et al. [44] | Collected | Ensemble XGBoost RF LR | 94% 91% 65% | 94% 90% 65% | 94% 90% 65% | 94% 90% 65% |
| Yang et al. [45] | Australia road deaths database (ARDD) | Ensemble SVM k-NN DT | 88% 87% 88% | |||
| Luo et al. [46] | Driving Simulator | Classification DT Gradient boosting decision tree (GBDT) Long–short-term memory (LSTM) | 77% 80% 87% | |||
| Mansoor et al. [43] | Canadian Dataset | Ensemble k-NN DT AdaBoost FNN SVM Two-Layer Ensemble | 62% 68% 72% 70% 72% 73% | 70% 70% 72% 70% 69% 77% | 66% 69% 72% 70% 71% 75% | 67% 69% 71% 69% 68% 76% |
| Proposed | Driving Simulator | Ensemble k-NN DT AdaBoost NB Two-Layer Ensemble | 56% 83% 76% 83% 86% | 56% 70% 71% 76% 83% | 56% 73% 72% 77% 84% | 65% 81% 79% 81% 88% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oyoo, J.O.; Wekesa, J.S.; Ogada, K.O. Predicting Road Traffic Collisions Using a Two-Layer Ensemble Machine Learning Algorithm. Appl. Syst. Innov. 2024, 7, 25. https://doi.org/10.3390/asi7020025
Oyoo JO, Wekesa JS, Ogada KO. Predicting Road Traffic Collisions Using a Two-Layer Ensemble Machine Learning Algorithm. Applied System Innovation. 2024; 7(2):25. https://doi.org/10.3390/asi7020025
Chicago/Turabian StyleOyoo, James Oduor, Jael Sanyanda Wekesa, and Kennedy Odhiambo Ogada. 2024. "Predicting Road Traffic Collisions Using a Two-Layer Ensemble Machine Learning Algorithm" Applied System Innovation 7, no. 2: 25. https://doi.org/10.3390/asi7020025
APA StyleOyoo, J. O., Wekesa, J. S., & Ogada, K. O. (2024). Predicting Road Traffic Collisions Using a Two-Layer Ensemble Machine Learning Algorithm. Applied System Innovation, 7(2), 25. https://doi.org/10.3390/asi7020025