1. Introduction
Underground utility tunnels (UUTs) are important infrastructure facilities required for modern urban life. The infrastructure typically accommodates two or more types of underground facilities, including electricity, gas, water supply, communication, and sewage facilities. UUTs overcome the topographical constraints of urban areas by using underground spaces. They are essential infrastructure facilities established for daily applications, such as communication, power, heating, and cooling amenities [
1]. UUTs are known for easy maintenance, effective control of underground facilities, and reduced occupied space. Despite the high initial construction investment, these facilities continue to be installed in new cities as they are economically efficient in the long term [
2]. In Korea, UUTs are installed in 30 regions to provide integrated services, such as electricity, water, and communication. Among them, facilities that have been in use for more than 30 and 20 years account for 25 and 43%, respectively. Numerous individual facilities are expected to age, and the management of aging UUTs is crucial because of increasing fire safety-related disasters [
3].
Therefore, to ensure the safety and efficient maintenance of underground facilities that involve frequent accidents and warrant prompt response to disasters, smart technology-based systems have been proposed. A system [
4] has been proposed to check the state of UUTs for abnormalities in facilities and installed equipment based on the data collected from closed-circuit television (CCTV) and various sensors, such as accelerometers and optical sensors. With the development of graphics processing units (GPUs) and the presentation of various image classification methods based on convolutional neural networks (CNNs), deep learning techniques applied to artificial neural networks are rapidly advancing, exhibiting outstanding performance in the field of image recognition [
5]. The integration of novel detection technologies and data-based algorithms is essential for constructing reliable and intelligent fire detection systems.
However, the fundamental operational problems of UUTs are the frequent occurrence of condensation, corrosion, and other issues owing to inadequate waterproofing, dehumidification, and ventilation facilities, which adversely affect the durability of underground structures and internal facilities. As depicted in
Figure 1, condensation occurring inside utility tunnels damages the finishing materials owing to rust or various types of fungi, causing electrical leakage because of corroded cables [
6,
7,
8,
9]. The installation of various smart devices increases the number of cables to be managed, whose insulation may be damaged when retained in a condensed environment for long periods. Short circuits may occur if the cable with damaged insulation comes into contact with an aged cable, leading to a fire. In most fire incidents that have occurred thus far in domestic and international underground facilities, cable short circuits and thermal contact caused by combustible cables have been the primary causes of fire [
10,
11]. Although forced ventilation is executed by running fans to prevent condensation inside the UUTs, the aging of the facility and insufficient fan capacity often result in inadequate ventilation. Additionally, on rainy days during summer, the ventilation system often shuts down, leading to poor ventilation within underground structures [
12].
Conventional CCTV-based technology cannot cover an entire area because of blind spots, and existing spark detectors or infrared flame detectors are extremely large and expensive to be installed in UUTs. Therefore, an acoustic sensing-based anomaly detection system is developed in this study to prevent fires in the condensation environment of UUTs by detecting electric sparks. The proposed system with no visual limitations ensures relatively flexible installation and wide-range monitoring. Furthermore, the developed system is not a contact-type sensor, such as a temperature sensor; therefore, it can be installed in vulnerable areas where condensation occurs for a more efficient operation. It can be safely managed without interaction or interference with the equipment and devices installed inside the underground complex. As sound is affected by the surrounding noise, the proposed system measures and analyzes the sounds generated in the underground complex environment, uses a deep learning technique to improve the monitoring performance of detecting initial signs of overheating, such as electric sparks, and recommends a suitable methodology for training the datasets.
The remainder of this paper is structured as follows.
Section 2 presents the methodology, architecture, and key components of the proposed anomaly detection system based on acoustic sensing.
Section 3 describes the experimental settings, testing procedures, detailed experimental results, and evaluation of the performance of the system. Finally, the conclusions and suggestions for future work are summarized in
Section 4.
2. Methodology
2.1. Acoustic Analysis of the Condensation Section of the UUTs
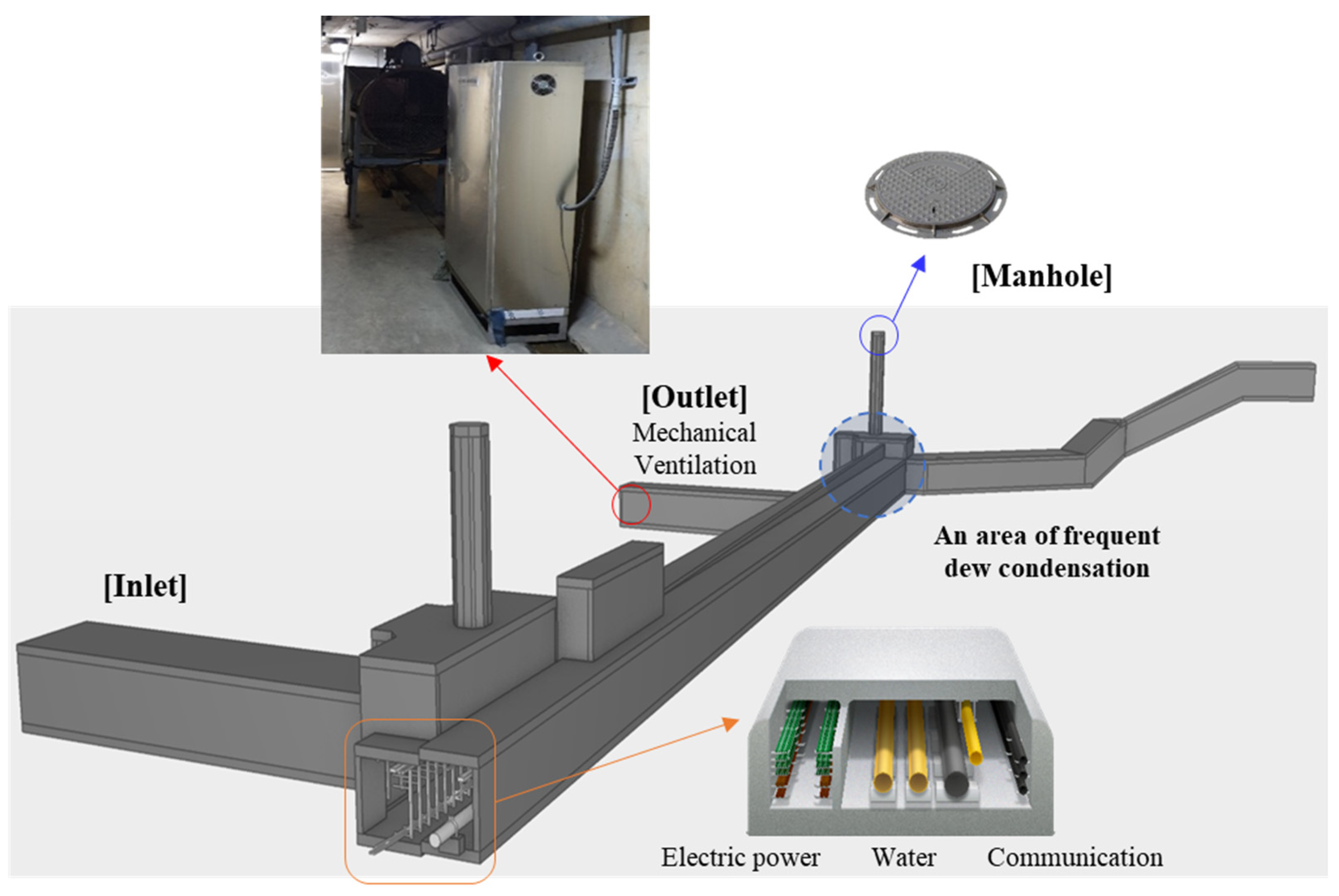
According to facility regulations, UUTs require natural and mechanical ventilation systems installed at regular intervals. Typically, UUTs experience a summer condensation problem in certain areas, as indicated in
Figure 2. This condensation is caused by insufficient resistance of exterior materials to vapor penetration, the use of materials with high humidity, inadequate insulation in the construction owing to damaged or poor adhesion of insulation materials, and poor sealing of gaps. Therefore, high humidity is generated in the air inside the structure, and condensation occurs when the surface temperature of the interior walls or surfaces of the pipes reaches the dew point. To reduce condensation in the condensation zone, a mechanical ventilation system was operated; however, this generated noise from the ventilation fan. External noise, such as traffic noise, honking of vehicles, and wind noise, also entered the natural ventilation systems. Additionally, a manhole existed in the connecting passage of the underground building, and noise was generated from the manhole cover owing to the continuous impact of vehicle traffic. Other sources of noise within UUTs included the sound of water falling into the sump pit owing to the inflow of water or condensation through the manhole, as well as the operating sounds of devices, such as CCTV or electrical equipment installed in the surrounding area.
2.2. System Architecture
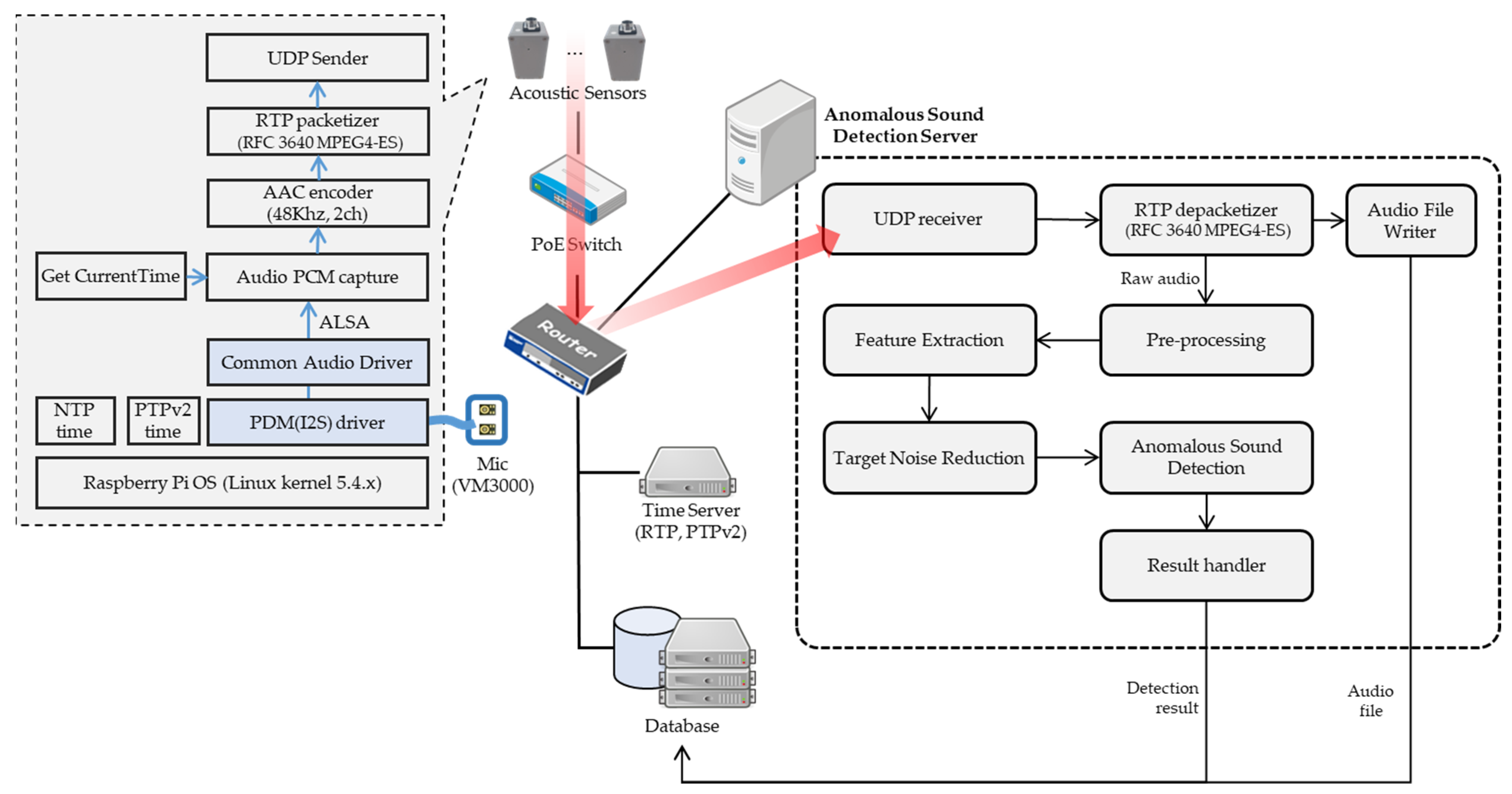
In this study, an anomaly detection system based on acoustic sensing is proposed to prevent potential fires in UUTs. As indicated in
Figure 3, the primary components of the system included acoustic sensors for collecting acoustic data and an anomalous sound detection (ASD) server. In the case of condensation in UUTs, acoustic sensors should ideally be installed in or near the corridors of UUTs where the hazard is located. The acoustic sensor [
13] is designed to suit the environment of the UUTs. To apply the sensor to actual UUTs, it was modified to allow power and data transfer through a single Ethernet cable using a Power over Ethernet (PoE) switch as
Figure 4. The PoE is substantially safer than a typical alternating current (AC) power supply that always supplies power to the outlet. Moreover, as PoE uses low voltage, difficult requirements such as separate wire conduits or distribution panels need not be considered. The i2s (Inter IC Sound) interface on the Raspberry Pi was configured to receive PCM (Pulse Code Modulation) data directly from the MEMS microphone using PDM mode. The sound acquisition H/W device made based on this configuration is IP (Ingress Protection rating) 67 waterproof to prevent abnormalities caused by condensation during sound acquisition. For the microcontroller unit, we used a Raspberry Pi ZERO and connected it to the microphone sensor to measure the data. The acoustic sensor module consists of Common Audio Driver in the kernel driver area and Pulse Density Modulation (PDM) driver, and the application consists of PCM capture, Advanced Audio Coding (AAC) encoder, real-time transport protocol (RTP) packetizer, User Datagram Protocol (UDP) sender, etc. The PDM Driver is written by modifying the I2S module of the linux kernel, is connected to the digital microphone versper VM3000 and the PDM interface, and is responsible for receiving acoustic data with a sampling rate of 48,000 and 24 bits. The sound data were compressed using an audio codec (AAC-LC) and transmitted to an ASD server through a transmission router using the RTP.
The UDP Receiver in the anomalous sound detection server receives RTP packets sent from the acoustic sensor. RTP depacketizer parses the RTP packets to obtain audio elementary stream (ES), synchronization source (SSRC), and time information. Audio files are stored in the database through Audio File Writer. The PCM data were subjected to pre-processing, feature extraction, and target noise reduction (TNR). Subsequently, the ASD deep learning model tested whether the sound signal indicated an anomaly and transmitted the result and corresponding sound data to the database.
2.3. Data Acquisition and Pre-Processing
UUTs are restricted in terms of access, rendering it difficult to acquire acoustic data during fire or disaster situations. Moreover, electric sparks cannot be generated in underground cavities owing to the risk of fire. As electric spark sounds are not commonly experienced in daily life, artificially created sound datasets are commonly used. Therefore, we selected the sound that was most similar to the sound of an actual spark that occurred at the location where condensation was generated in the UUTs.
Since the voltage of the UUT management cable is 110 V/220 V, the sound of electric sparks corresponding to that voltage was collected from an open-source sound database. The collected sound data and a sound file similar to the spark generated by the actual UUT were played through a speaker at the UUT location where the condensation occurred.
Additionally, based on the sound data collection device and program reported in [
13], the sound was collected from various locations in the UUTs, focusing on areas where condensation occurred.
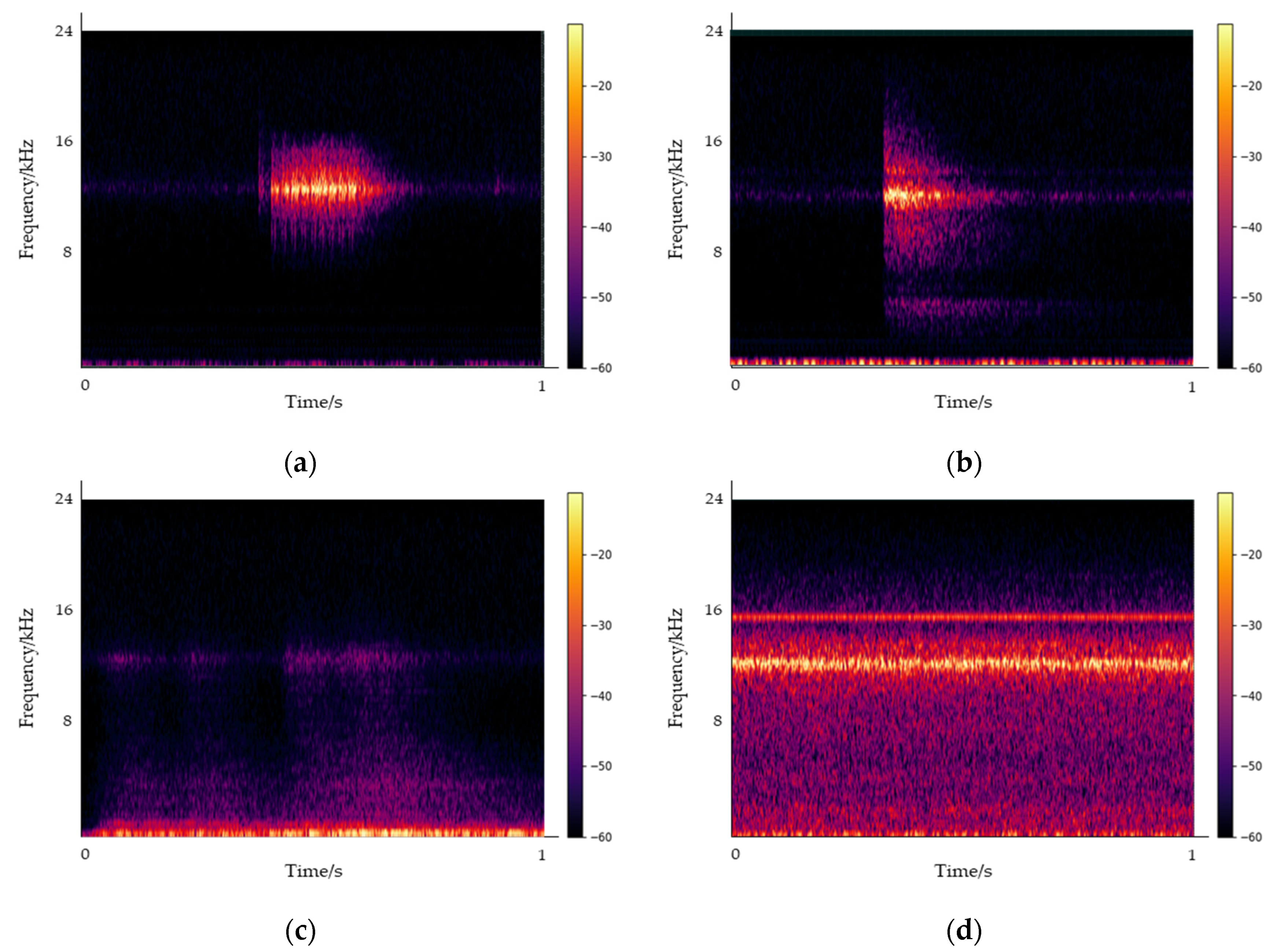
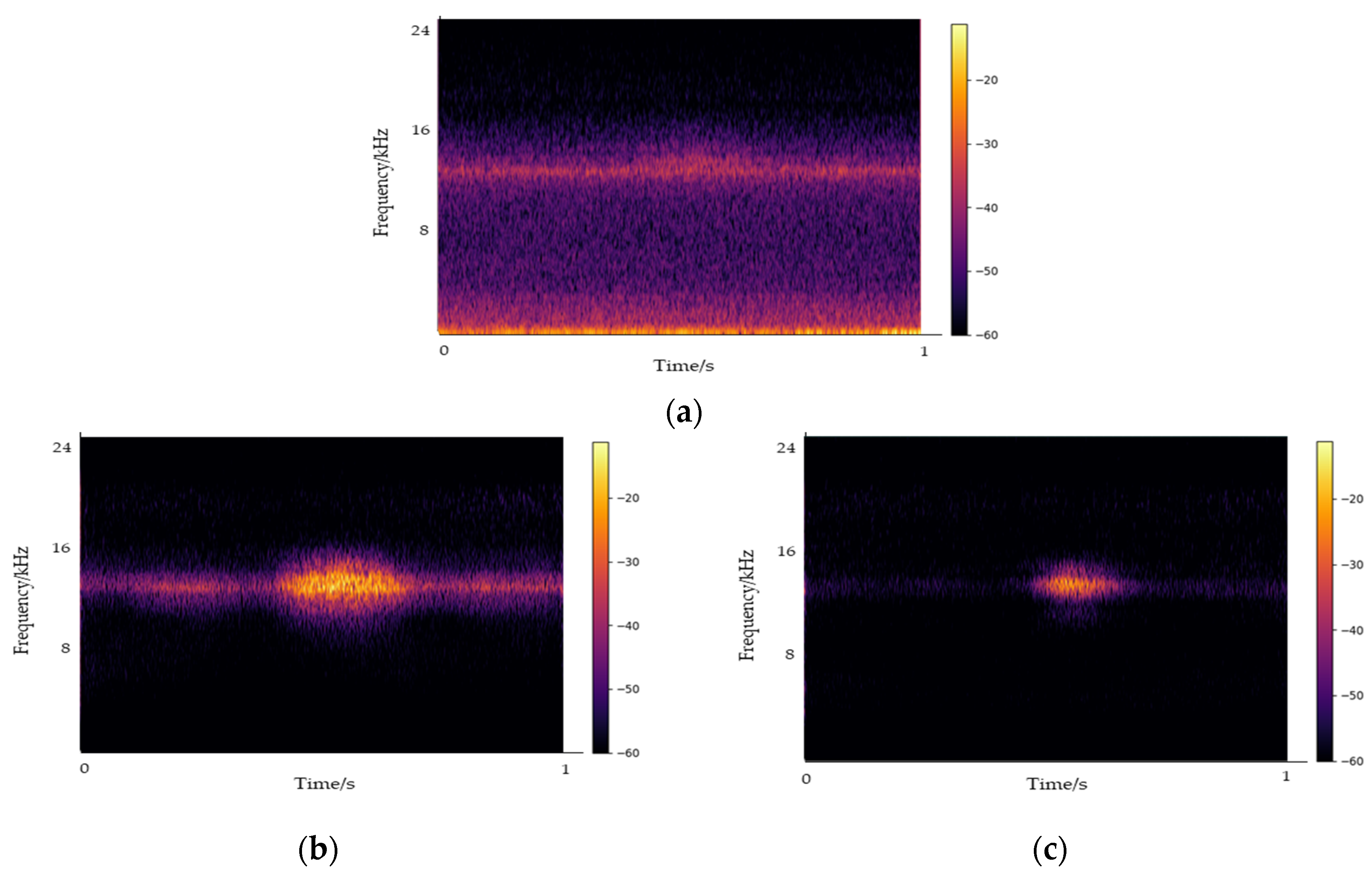
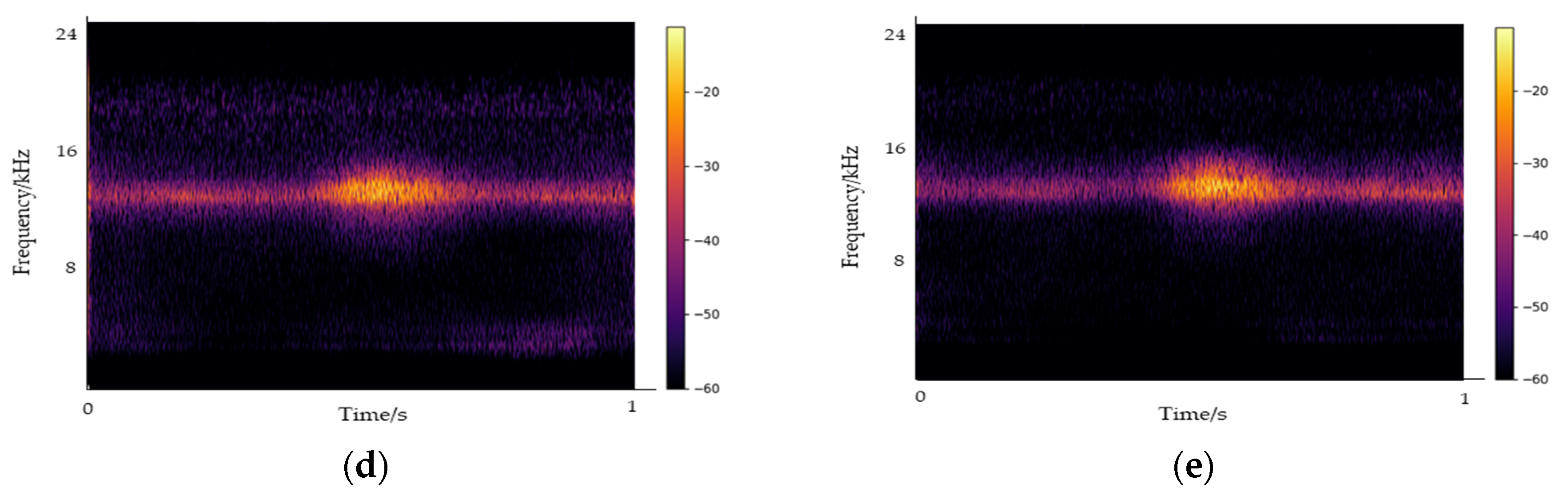
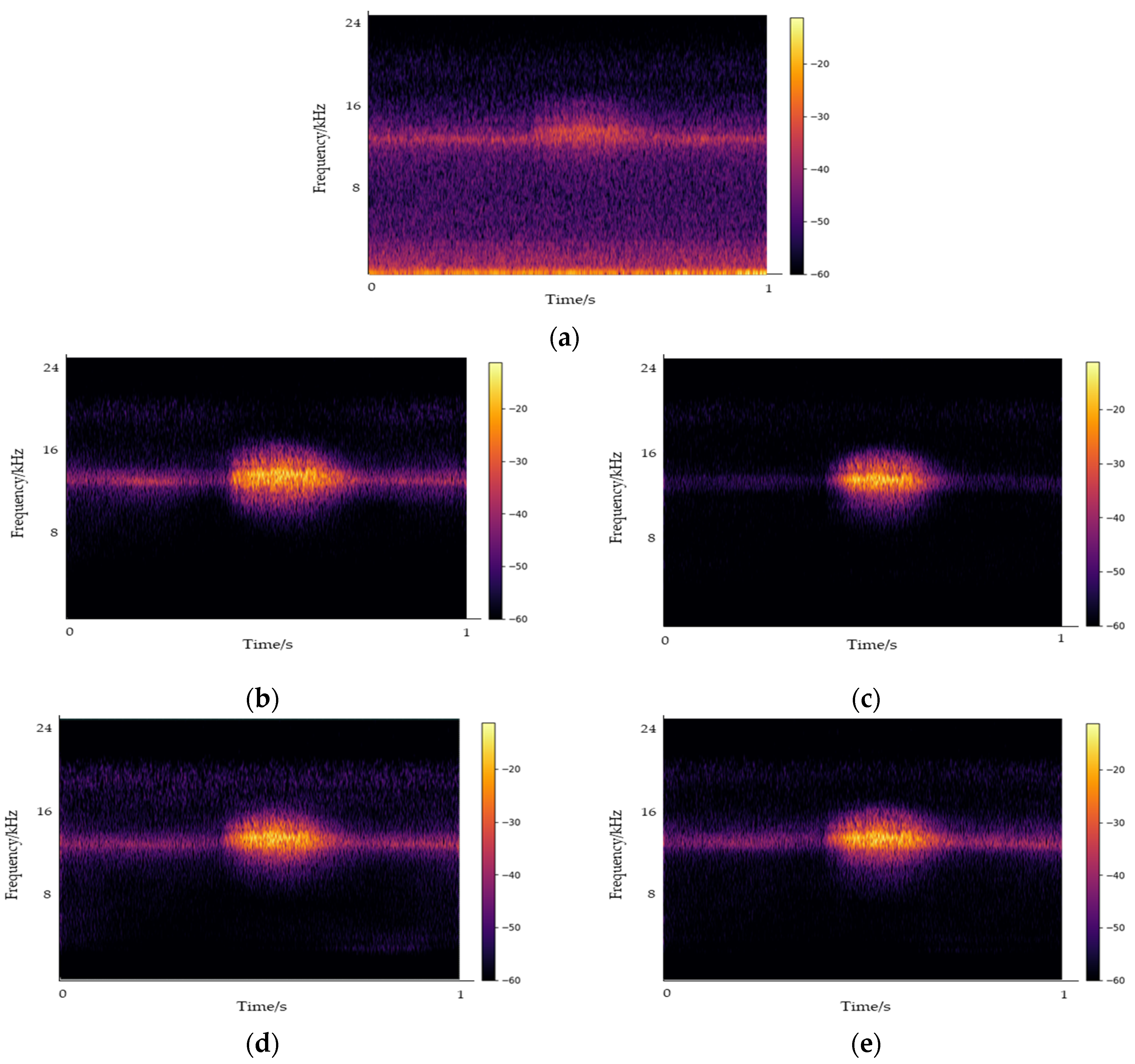
Figure 5 illustrates a representative sound generated inside the UUTs, with the spectrogram captured at 1 s intervals. Data were collected at the same location for 10 sessions from December 2021 to August 2022. We collected the sounds of noise and electric sparks in UUTs during winter and spring and the sound of the ventilation fan during the vulnerable period of summer. After data collection, inspection, labeling, and labeling inspection, 564 GB of raw data were secured. The analysis of the sound collected inside the UUTs indicated that multiple sounds were reflected owing to their characteristics, and the use of an omnidirectional VM3000 MEMS microphone resulted in the creation of reverberations. An electric spark sound occurred in less than a second with the energy distribution ranging between 8 and 18 kHz. The sound of impact on the manhole exhibited a signal length of approximately 0.5 to 2 s owing to the speed differences of passing vehicles and consecutive passing of two or more vehicles, with energy occurring up to approximately 19 kHz. Notably, the sound was strongly concentrated below 3 kHz.
The most significant noise in the underground spaces was the sound of the ventilation fan. The energy was generated up to the 24 kHz frequency band, with a strong concentration below 18 kHz. This overlapped with the frequency band of the electric spark sounds.
The collected PCM data were transformed into magnitude spectrograms every 1 s using short-time Fourier transform (STFT). Therefore, the pre-processed one-dimensional (1D) fast Fourier transform (FFT) numerical data contained 48,000 points.
where
denotes the Hamming window function, and
indicates the function of
and
. If
, N represents the number of FFTs. Here, each signal was subjected to FFT, and the corresponding STFT was obtained as
The short-time power spectrum
was calculated as
where
denotes the short-time autocorrelation of
;
indicates the Fourier transform of
, and n and ω represent the horizontal and vertical coordinates, respectively. STFT with a window size of 512 was performed using a Hamming window and 63% overlap to maintain the time resolution less than 0.01 s. As the sound of electric sparks was short, the time resolution had to be increased. Additionally, we set a minimum frequency resolution of approximately 100 Hz to satisfy the requirements of the high frequency range of the sound. Consequently, the 1D time-domain data of 1 s were converted into 1D STFT data using 256 times FFT. The size of each STFT dataset with 48,000 points was reduced to create a dataset of size 256 × 256. This was used as a feature of the deep learning model. In the spectrogram, the range of variation of the harmonics was (0, 24,000) Hz. The Butterworth bandpass filter was designed to pass the signal through the band at 4000 and 20,000 Hz. This was a combination of high-pass and low-pass filters with cutoff frequencies of 4000 and 20,000 Hz, respectively. This range was filtered because it comprised most of the primary information of the spark signal.
2.4. Deep Learning Models
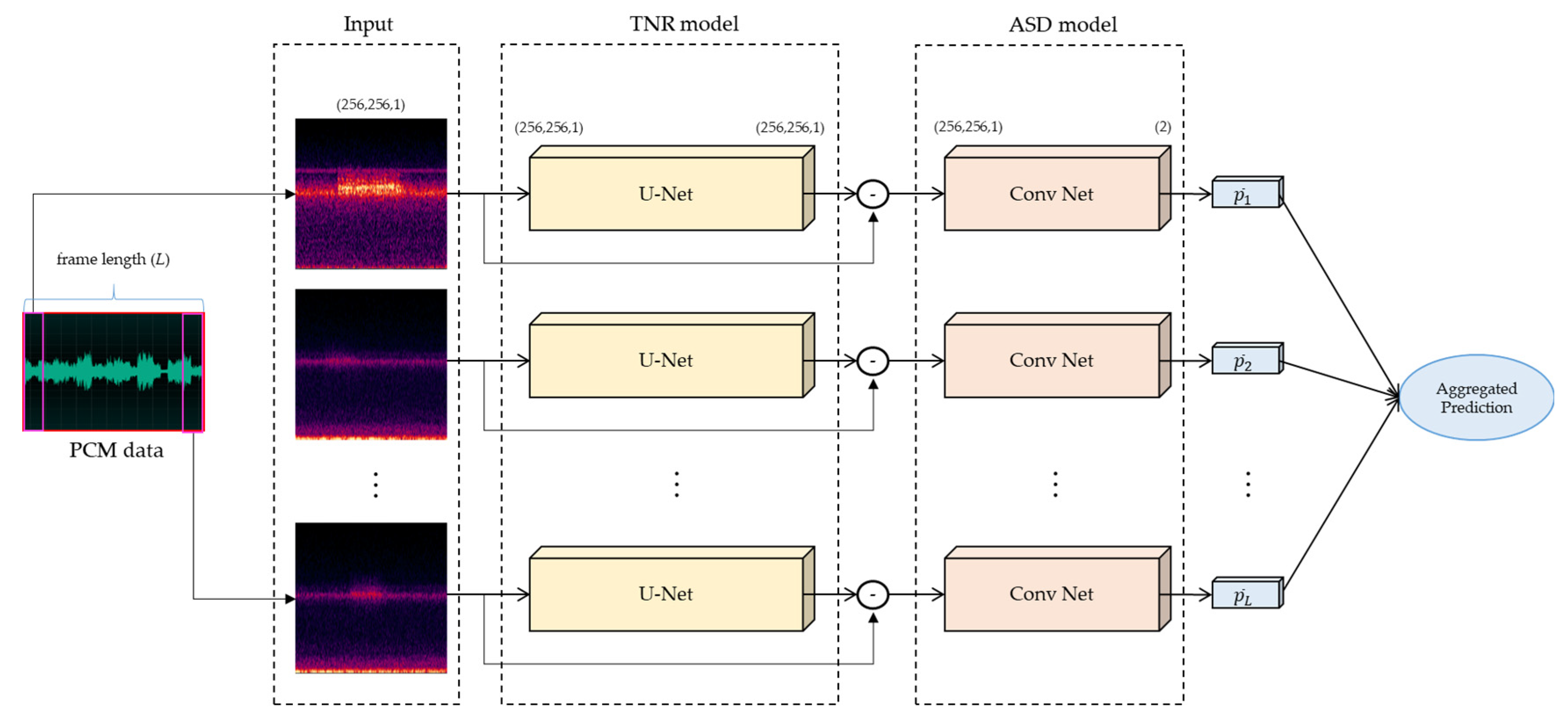
As illustrated in
Figure 6, two different deep learning models were considered, each with two different training datasets. Typically, the systems operating in the spectrogram domain use the mixed-signal phase when restoring the signal in the time domain. However, errors may occur in the estimated signal because of using the mixed-signal phase. To overcome this drawback, the desired signal was directly estimated in the frequency domain without being transformed into the time domain.
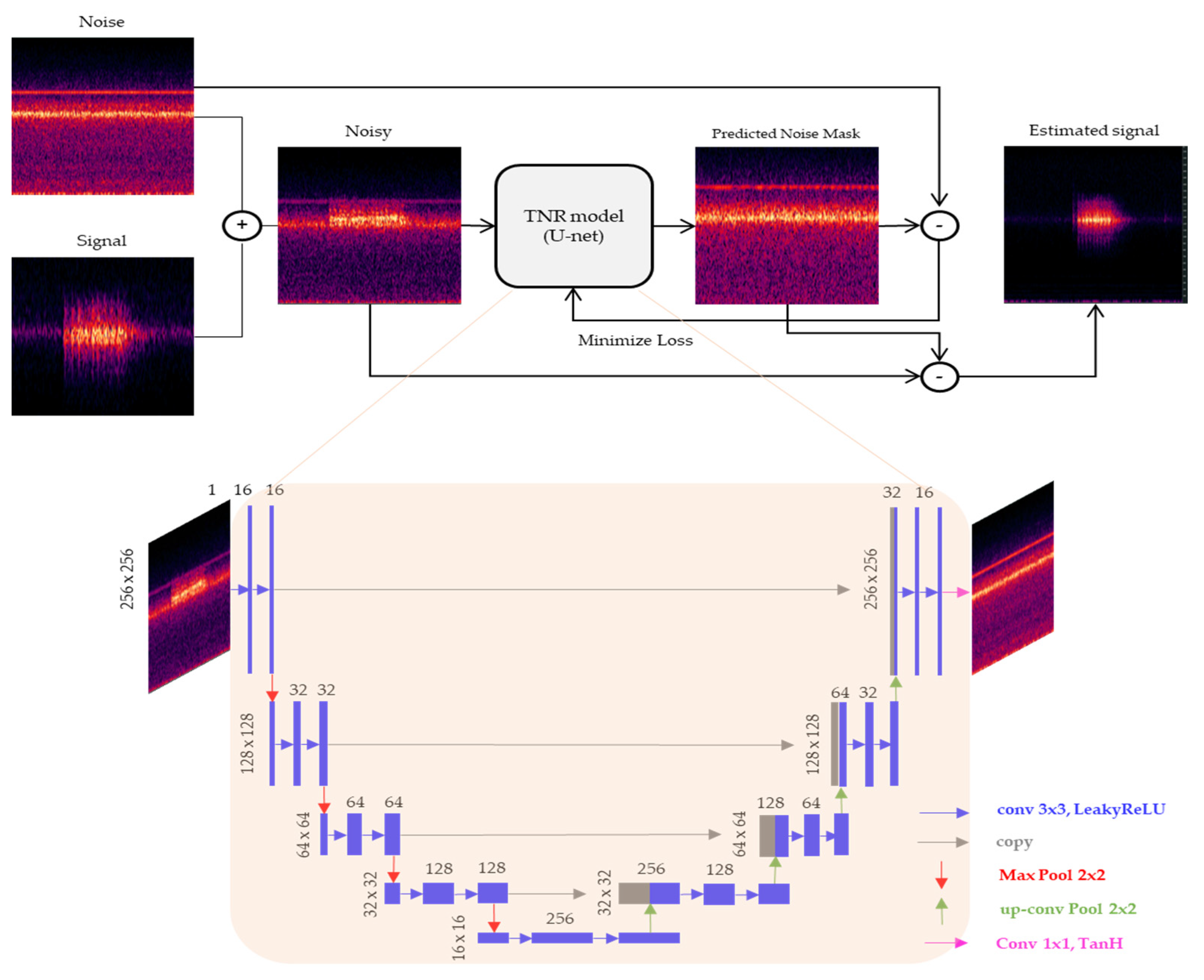
2.4.1. U-Net-Based TNR Model
The U-Net model was used for training, which is a deep convolutional autoencoder originally developed for image segmentation in the medical field [
14]. U-Net utilizes features with both overall contextual information and precise localization; in this study, U-Net was adapted to remove noise spectra.
Figure 7 illustrates the network architecture used for training. The network input was the mixing spectrum of sparks and ventilation fans with dimensions of 256 × 256. Both the input and output matrices were globally scaled and mapped to a normalized distribution between −1 and 1. The encoder comprised 10 convolutional layers with the leaky rectified linear unit (LeakyReLU), max pooling, and dropout layers. The decoder was a symmetrically expanding path with skipped connections. The final activation layer was a hyperbolic tangent (tanh) with an output distribution between −1 and 1. The model was compiled using the Adam optimizer, and the loss functions were used as a trade-off between
and
. Furthermore, the Huber loss and log-cosh loss were compared and analyzed. Here,
denotes the
ith entry of
;
indicates the actual value, and
represents the value predicted by the TNR model. Owing to the strong noise characteristics of the ventilation fan, several outliers existed in the signal. Therefore, a robust loss function resistant to outliers was used to compensate for this.
The Huber loss function addressed the drawbacks of non-differentiable L1 loss by applying L2 loss when the value was less than 1 and L1 loss when the error was greater than 1, thus combining the strengths of the two types of loss functions [
15]. The use of the Huber loss function during the training of the TNR model ensured rapid learning even when large errors occurred. Using the robust L1 loss at the beginning of the training process when the TNR model could not converge was effective. As the training progressed and the loss function reduced to a value less than one, stable learning was achieved by using the differentiable L2 loss.
The log-cosh loss function is another loss function applied to regression problems that are smoother than the mean squared error (MSE). This function combines the advantages of the MSE and mean absolute error (MAE), reduces the sensitivity to outliers, and improves the robustness of the neural network model to outliers.
A mask was generated to predict noise using this process, and the noise-free signal was estimated by directly subtracting the noisy input signal from the output of the model.
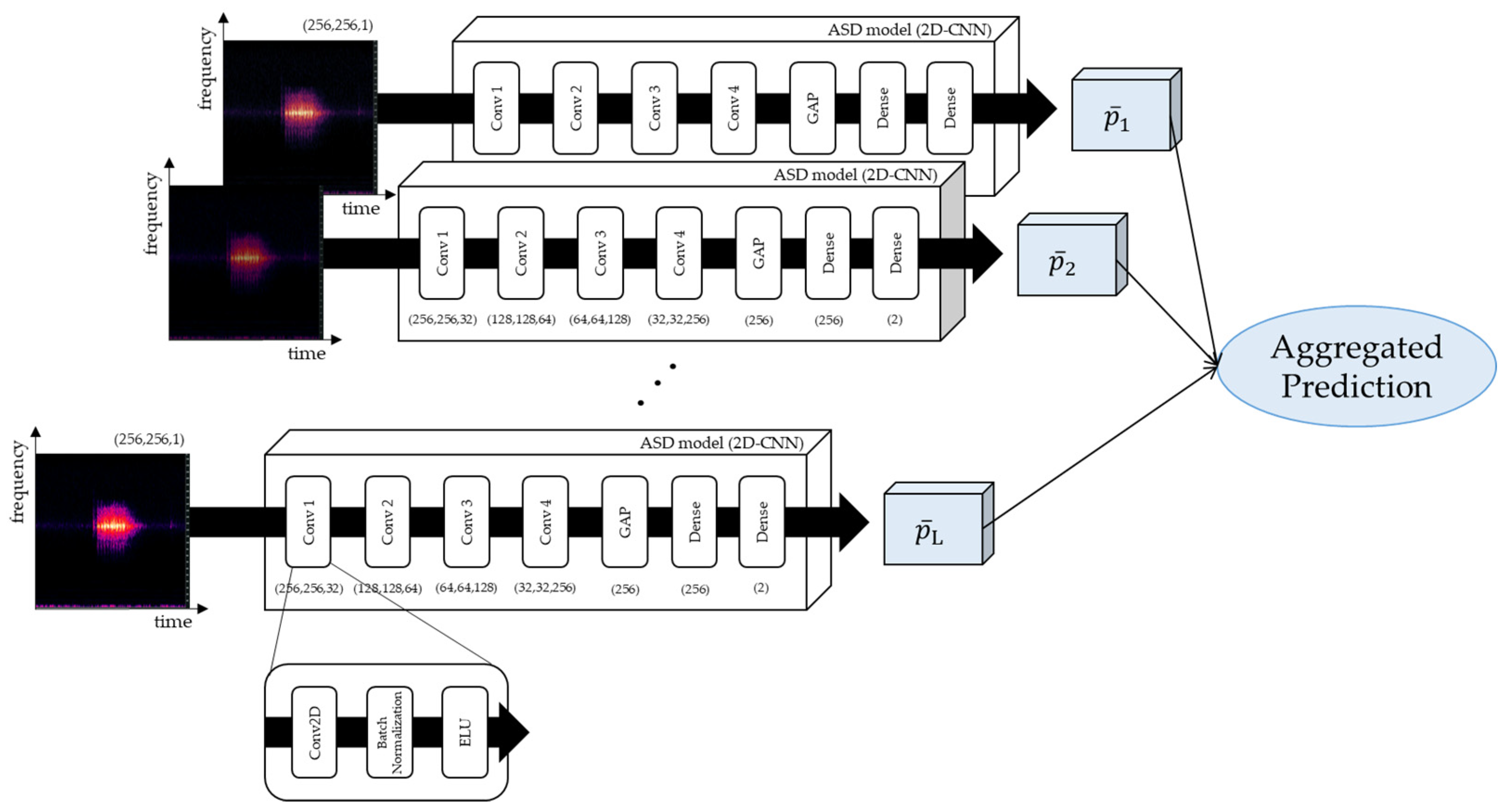
2.4.2. Two-Dimensional (2D) CNN-Based ASD Model
A 2D-CNN structure was used to detect anomalous sounds with magnitude spectrograms of size [256 × 256 × 1] as input.
Figure 8 illustrates the detailed structure of the 2D CNN used for ASD. The Conv Net comprised four 2D convolutional layers, one global average pooling (GAP) layer, and two dense layers. The kernel size of the 2D convolutional layers was [3,3], with padding set to “same” and strides set to 1 only for Conv1 and 2 for Conv2–Conv4. Batch normalization was applied to each layer (Conv), and the exponential linear unit (ELU) was used as the activation function. After the fourth convolutional layer (Conv1–Conv4), the model was lightweight, and overfitting was prevented using GAP. In general, GAP is used for extracting features from each sample by repeatedly performing average pooling to reduce the sample size and extract representative values of [1,1] filter size from each sample. Therefore, a sample size of [32 × 32, 256] in Conv4 was represented using a [256] layer with 256 representative values. Subsequently, the model was passed through two dense layers, and the prediction probability was calculated using the SoftMax activation function.
Next, the fusion of predicted probabilities obtained from the ASD model based on the frame length was used for the analysis. The fusion result
was obtained as follows:
where
denotes the predicted probability of 1D time-domain data of 1 s;
indicates the category number (C = 2), and
was evaluated considering L frames. The aggregated predicted label
was determined as
4. Conclusions
This study focused on detecting electric sparks in the condensation environment of UUTs to prevent fires caused by electrical leakages that occur from condensation and corrosion owing to inadequate waterproofing, dehumidification, and ventilation facilities. The results indicate that a microphone sensor can analyze the sound generated in UUTs and detect electric sparks, thereby contributing to the implementation of an intelligent fire detection system. The experimental results verify that the proposed method can stably detect electric spark sounds by eliminating the ventilation fan noise, which can have a significant impact on the UUTs. The proposed method can potentially address the limitations of traditional CCTV fire-detection technology. This can reduce the inefficiency of manual inspection and maintenance while increasing the efficiency of the system in managing UUTs. However, in the future, various pieces of equipment may be introduced to manage UUTs, and the diversity of sounds generated by such equipment can be a decisive factor in developing data-based anomaly detection. Therefore, further research is required to detect anomalies considering different types of sound data.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}