1. Introduction
Rotary machines have an undeniable role in industry. They are widely used in a variety of industrial applications. Under adverse conditions such as improper lubrication, overload, high temperature, and high humidity, these machines will eventually be damaged. Bearing failure is one of the most common failures in rotary machines, so the proper performance of bearings has a great impact on the efficiency of these machines. It is reported that more than 45% of all failures are due to defective bearings [
1,
2]. It is clear that early fault detection is crucial to ensure the safety and proper operation of rotating machines, so that severe faults, failures, and higher repair costs can be prevented by identifying faults in the early stages.
Fault detection methods are generally divided into three categories: (1) model-based methods or “white box”, (2) machine learning-based methods or “black box”, and (3) a combination of the above two methods or “gray box”.
In model based fault diagnosis, existence of a model for the system under study is crucial. Based on this model, residuals are generated for identifying faults. Unfortunately, this approach fails when there is uncertainty in the model or measurement data are noisy. Another promising approach is machine learning based or data-driven based fault diagnosis. This approach is very attractive where there is no model or uncertainty of the model is high. In this approach, only data are used for fault diagnosis. The main drawback of this scheme is that it is heavily depends on having a high-quality extensive training database. Currently, a hybrid approach is proposed to reduce the drawbacks of these two approaches and enhance the accuracy of the fault diagnosis process. In this new scheme, residuals generation is done by a model-based method and residual selection is applied by a machine learning-based approach [
3]. One example of such an approach can be found in [
4].
Currently, machine learning, including classical machine learning methods and deep learning methods, has provided the basis for intelligent fault diagnosis. Classical (shallow) machine learning methods only work on handicraft features (features that are manually and artificially extracted from the signal). As a consequence, these methods do not take advantage of all the features that are potentially present in the input data.
In [
5,
6], spectral analysis of a motor current is used to detect bearing faults in electric motors. Faults in the bearing result in torque fluctuations, which results in a change in the frequency spectrum of the stator current. The amplitude of the added frequencies to the stator current substantially depends on the bearing type and the load conditions. Ref. [
7] benefits from the combination of accelerometer and load cell data and the utilization of k-nearest neighbors (KNN) to detect bearing faults. Based on the results, the data obtained from the load cell are useful for detecting the fault, and the accelerometer is useful for identifying the location of the fault. Reference [
8] uses the iterative Boolean combination (IBC) technique, a strategy based on the combination of different support vector machines (SVMs), which aims to reduce the effect of noise on the fault detection system. According to the experiments, even in the presence of noise, this system can detect faults in a bearing. In [
9], higher-order spectral (HOS) and SVM were used to classify four types of bearing fault in different working conditions. Results show that it is a powerful method for detecting faults in rotary machines, but this method also requires manual feature extraction.
In deep learning-based models, features of the input data are extracted automatically, without human intervention. In [
10], an engine condition monitoring system was proposed using a one-dimensional convolutional neural network (1DCNN) that connects the two main parts of a fault detection system: the feature extraction and the classification parts. This model has good generalization and eliminates the need to manually extract the features. Generated images of vibration data in the time–frequency domain were used in [
11] to identify bearing faults. To this end, those images were analyzed by deep convolutional networks. It turned out that this architecture is resistant to noise. Ref. [
12] forms a matrix by combining multi-sensor data and considering them as the input to the convolutional network. By comparing the results of this method with the traditional ones, it was concluded that CNN has a better and more reliable diagnostic performance. In [
13], a deep recurrent neural network is ameliorated by an augmentation of recurrent hidden layers. In this method, the frequency spectrum of the vibration signal is used as input. The results confirm that this method has a better performance compared to other intelligent methods. Ref. [
14] uses the convolutional network and long short-term memory (LSTM) with the attention mechanism. In this model, the raw vibration signal was used, accompanying its frequency spectrum as the model input. Moreover, the attention mechanism was used to pay more attention to the distinguishing features. The proposed fault identification method in reference [
2] is called S-transform CNN (ST-CNN), which is presented using the ST layer and convolutional neural network. The input vibration signal in the ST layer is converted to a two-dimensional time-frequency matrix. Then, it enters the convolutional network. Finally, it classifies by the maximum softmax layer. Compared to other methods, such as short-time Fourier transform (STFT) + CNN, SVM, and KNN, the results show that the diagnostic performance of this method can be more promising and more reliable for diagnosing bearing faults. Reference [
15] proposed a deep learning method based on a combination of stacked residual dilated convolutional neural network (SRDCNN) and LSTM. The structure of LSTM can effectively eliminate the effects of noise. In [
16], a multilayer bidirectional gated recurrent unit with an attention mechanism (Att-MBiGRU) network was used. In comparison with different models, the results show that the attention mechanism helps the network to perform better in noisy conditions. Reference [
17] proposes a bidirectional recurrent neural network (RNN-WDCNN) consisting of a 5-layer convolutional neural network plus a pathway combining elements of recurrent neural networks and convolutional neural networks. The recurrent neural network used in this model is efficient for learning long-term dependencies in time-series data and eliminating high-frequency noise in the input signal. According to the authors, the inclusion of the attention mechanism in the return path of the model did not have a significant effect on noise effect reduction. In [
18], the raw data collected by the accelerometer sensor were considered as input to the CNN + LSTM algorithm and fault detection, so it can be said that, like most deep learning methods, it did not use selective data features and had a relatively good performance. Time–frequency signature matrix (T–FSM) feature sensitive to few-shot vibration signal and multi-label convolutional neural network with meta-learning (MLCML) was proposed in [
19]. Ref. [
20] proposed a pseudo-categorized maximum mean discrepancy (PCMMD) and used it to drive the multi-input multi-output convolutional network (MIMOCN) to narrow the cross-domain distribution discrepancy of the deep feature space.
Single-scale convolutional neural network-based models use only a certain scale of the signal in the first layer, whereas the mechanical vibration signal has different frequencies and different potential features at different time scales. Unfortunately, single-scale convolution may lead to the loss of this potential information. Therefore, multi-scale convolutional networks were proposed. In [
21], a shallow convolutional neural network, multi scales CNN combined with a multiple attention model called MA-MSCNN, was proposed. According to the results, 99.86% accuracy was achieved with this method. In [
22], in order to automatically extract the frequency features, two convolutional neural networks with different kernel sizes were used, and LSTM was used to identify the type of fault. In [
23], a multi-scale deep convolutional neural networks (MS-DCNN) model was presented. Based on the results, the MS-DCNN model could achieve higher accuracy compared to 1D-CNN and 2D-CNN. In this study, an improved multi-scale convolutional neural network integrated with a feature attention mechanism has been developed to overcome the weaknesses of CNN-based models under noisy environments.
The proposed method in this paper tries to overcome the aforementioned weaknesses. The contributions of this paper can be summarized as follows:
The proposed method employs a multi-scale structure and bidirectional recurrent network to extract and combine spatial and temporal features available at different frequencies of the input vibration signal.
Despite extensive filters and pooling in the convolutional network, the model achieves high generalizability.
In this method, the adaptive gradient optimization algorithm is used, so the performance of the model is independent of the selection of the optimal learning rate, and there is no need to find the best learning rate value.
With batch normalization + exponential linear unit (BN + ELU), the convergence speed of the model will be very fast and needs fewer iterations to converge.
In comparison to other schemes, the proposed method has an excellent performance in classifying the types of faults and shows robustness to noise.
The structure of the paper is as follows:
Section 2 is devoted to the basic concepts.
Section 3 introduces the proposed model architecture. In
Section 4, the performance of the proposed model is evaluated through the Case Western Reserve University (CWRU) bearning dataset. Finally, the paper is concluded in
Section 5.
2. Definitions
In this section, some essential definitions that are employed in the proposed method are introduced.
2.1. Convolutional Neural Network (CNN)
Convolutional neural networks were developed in 1990 with inspiration from the visual cortex [
24]. A convolutional neural network is a feedforward neural network capable of processing data with grid-like topology (e.g., imagery data).
In fully connected neural networks (FCs), each neuron in each layer connects to all neurons in the next layer, and each connection between neurons (weights) will be a parameter in the network, so these networks will have too many training parameters for high-dimensional input data.
In contrast to fully connected networks, convolutional networks create local connections between neurons, i.e., each neuron connects only to the nearby neuron in the next layer. Moreover, the connections between the input and the neurons use a set of common weights called the convolution kernel. These two properties in convolutional networks have made it possible to process high-dimensional data. Supremely, local connectivity and weight sharing lead to local network input feature extraction.
A convolutional layer has at least one filter that performs convolutional operations. The result of these calculations is called the feature map. Hence, each “feature map” includes features extracted by different filters. Each filter in the convolutional network extracts unique features out of the training data. The number and size of these filters are defined in the network hyperparameters.
Here, a one-dimensional convolutional neural network (1DCNN) is introduced, as the input data of this study are mechanical vibration signals. If the input time series data are considered as
X, then:
where
N is the length of the data entry window. In this case, the time series sequence will be as in Equation (
2).
The convolution could be assumed as a multiplication between the filter kernel
W and the input data
, where
is the length of the convolution filter. The feature map obtained from the input data by convolution is in vector form and is called
. Feature vectors eventually pass the nonlinear activation function, as introduced in Equation (
3):
where
b and
are bias and nonlinear activation function, respectively. Finally, the feature map is obtained by putting these feature vectors together.
Then, maxpooling [
14] is applied to the feature map to reduce feature dimensions and prevent overfitting;
is the output of the maxpooling layer applied to the feature map extracted by the
jth filter.
where
s is the number of remaining features after maxpooling. By expanding each
, the maxpooling relation is as in Equation (
6):
where
, where
length of feature vector,
g is the length of the pooling, and
is the pooling layer output applied to the
jth feature map.
2.2. Gated Recurrent Unit
A recurrent neural network (RNN) is suitable for processing time series and sequential data. Recurrent neural networks have an internal memory and can store previous information in their cells. To train RNNs at each time step, the error gradient is obtained using the backpropagation through time (BPTT) algorithm, and the network parameters are adjusted accordingly.
If the length of the input sequence or the network depth in a typical RNN increases, then the gradient vanishing/exploding problem will occur and stops the training process. Thus, RNNs are not capable of learning long data dependencies. Therefore, long short-term memory (LSTM) was introduced to overcome this problem [
25].
LSTM solved simple RNN problems because it had a forget gate. The gated recurrent unit (GRU), which is based on LSTM, was proposed in [
26]. The only difference is that it has fewer gates and uses fewer training parameters, so it has a faster training process. The training speed is 29.29% faster than with LSTM, and the ratio of accuracy to computational cost is 23.45% more than LSTM [
27], and it has performed better than LSTM to maintain long-term dependencies [
28].
An important distinguishing feature between typical RNN and GRU is the ability to control the hidden information that solves gradient issues. This is possible in GRU through two gates. For instance, if the input is very important in a time step, the GRU will learn not to forget its information and keep it in a hidden status. Likewise, if the input is irrelevant and insignificant, GRU learns to ignore it.
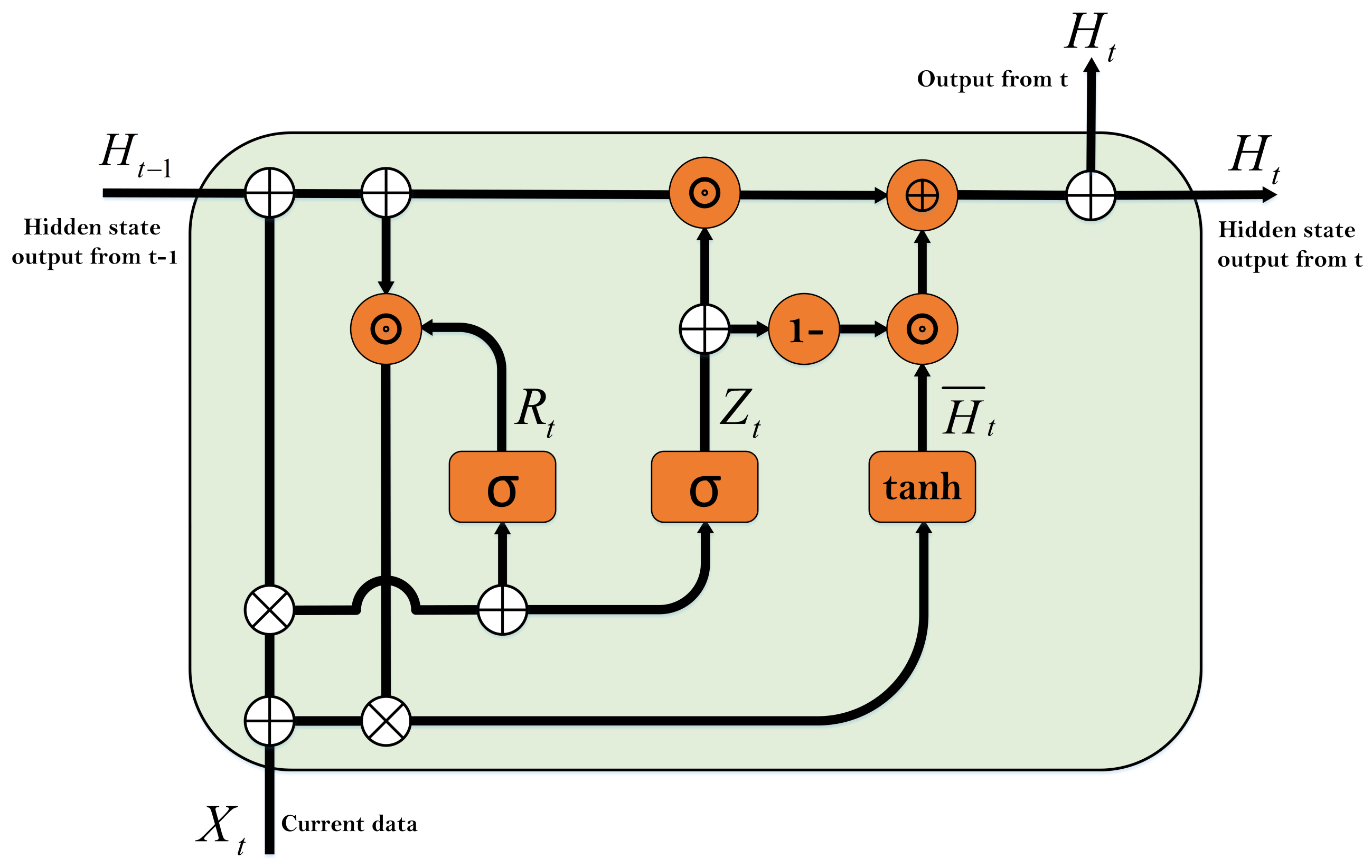
Figure 1 depicts the block diagram of one cell in the GRU network.
The reset gate determines how much of the previous hidden state is maintained, and the update gate controls how much of the previous time step of hidden mode is selected as the next time step of the hidden state and how much of the current time step knowledge is added to the hidden state. These gates make their decisions based on two criteria: the current input and the hidden state of the previous time step. These two criteria are fed to a fully connected neural network with a sigmoid activation function. The sigmoid activation function maps the input values to the range between 0 and 1 and creates the concept of a gate.
The relationships used in these gates are as in Equation (
7):
where
is the reset gate,
is the update gate,
and
are the weights connected to the input vector,
and
are the weights connected to the previously hidden status, and ⊗, ⊕, and ⊙ are concatenate, copy, and product, respectively.
Next, the candidate’s hidden state is obtained to be present in the final time step, based on the information generated in the current time step and the previous hidden state, as in Equation (
8):
where
is the weights attached to the input vector,
g is a candidate for the hidden state, and the tanh activation function is used to keep the values in the hidden state between
and 1. The generated
g is only one candidate and depends on the performance of the update gate. Finally, it is the update gate
that determines how much of the candidate’s hidden state is used and how much of the previous hidden state remains in the current hidden state. The final hidden state is updated in time step
t according to Equation (
9):
If is close to zero, the hidden state will be kept and the candidate’s hidden state will be ignored. Conversely, if is close to one, the newly generated hidden state will be approximately the same as the candidate’s hidden state. Therefore, the factors that overcome the gradient issues and keep long-term dependencies in the recurrent neural networks are the gates.
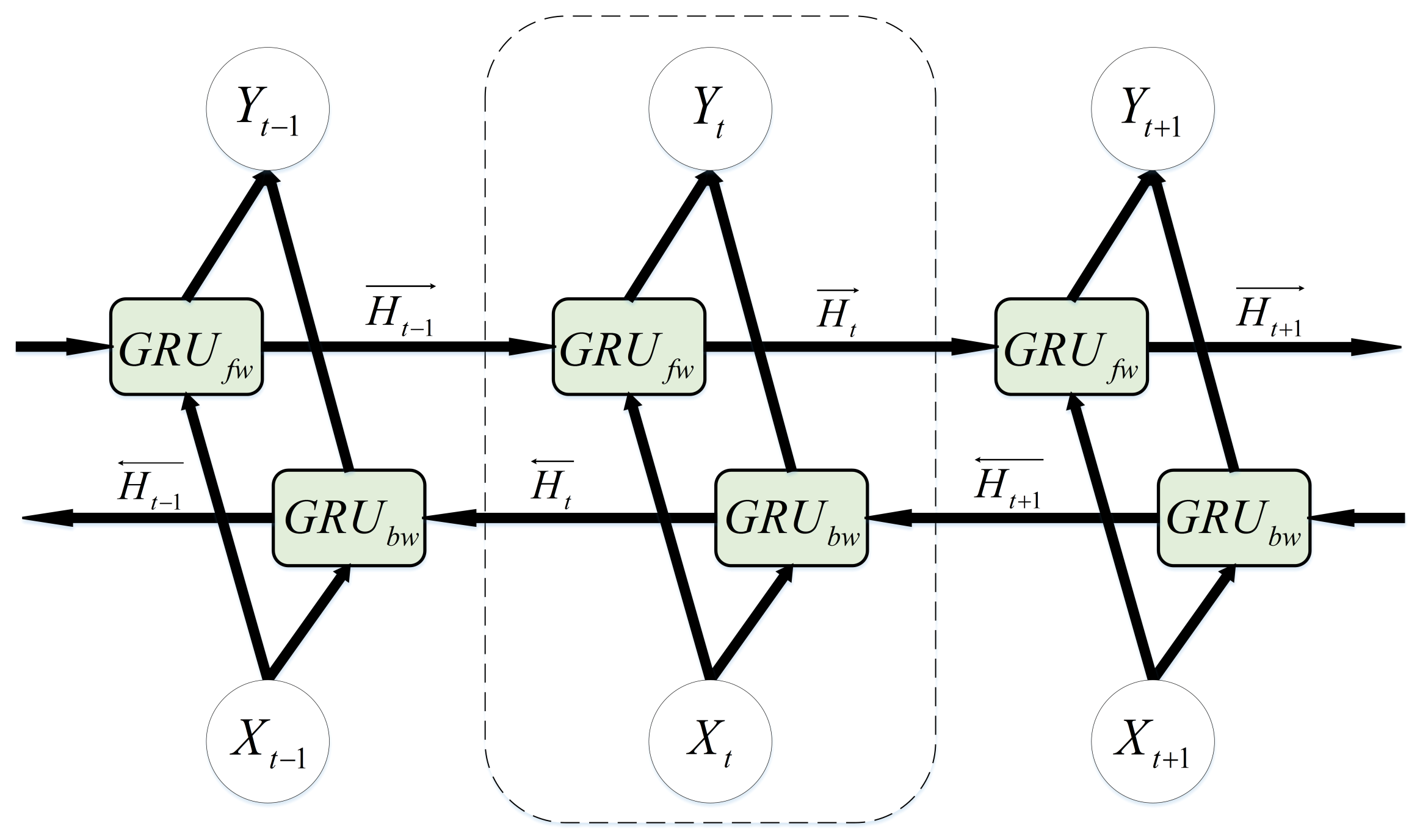
2.3. Bidirectional Gated Recurrent Unit
A typical recurrent neural network learns sequential information in one direction, i.e., the dependence of the time step
t to the previous temporal steps, but potentially available information will be lost, i.e., the dependence of the previous moments to the subsequent moments. Hence, [
30] suggests the bidirectional gated recurrent unit (BiGRU). In a BiGRU, a GRU layer is added to process the backward data, causing the
output at time
t to be based on the information of the previous time steps (
) as well as the information of the next time steps (
).
Figure 2 shows a BiGRU.
The forward hidden GRU layer (
) and the backward hidden GRU layer (
) is defined as in Equation (
10).
2.4. Batch Normalization (BN)
Training deep neural networks and convergence of the parameters is a difficult task due to the large number of layers. Data preprocessing can have a huge impact on deep network training. S. loffe [
31] proposed a preprocessing method to overcome the internal covariate shift during deep neural network training called batch normalization (BN). When the statistical distribution of input to a learning system changes, it is called the internal covariate change phenomenon of the learning system [
32]. During the training process, the layers try to adapt to the new distribution, so this phenomenon is problematic and slows down the training process, limiting the choice of a high learning rate. To deal with such problems, BN normalizes the statistical distribution of the batch at the input of each layer. In each iteration, the mean and standard deviation of training data of each batch is calculated and its data are normalized by subtracting the mean and dividing by the standard deviation. Therefore, the normalization of each input in BN is based on the statistical properties of its respective batch. if a batch with size
n is considered as a sample, the mean and standard deviation of the batch in layer
l is calculated as in Equation (
11):
The normalized value of each sample in layer l is calculated with Equation (
12):
where
is a small constant and is added to the variance just to avoid possible division by zero. Finally, BN is applied to the
ith samples in layer
l as in Equation (
13):
where a coefficient (
) and a deviation (
) are considered for that BN. These two parameters allow the learning algorithm to learn how to optimally use the BN. For example, if normalizing some features makes network performance worse, the learning algorithm will neutralize the normalization by these two parameters. Therefore, by learning the optimal
and
parameters, the learning process will determine the appropriate BN. By normalizing the distribution of input data and preventing the internal covariate shift in a network, BN will provide positive effects. BN allows using high learning rates without any possible gradient divergence [
31].
In fully connected layers, BN is usually applied before the activation function and normalizes the function input with Equation (
14):
where
is an activation function.The BN applied to each input sample will be determined by the statistical properties of the corresponding batch. BN differs from convolutional networks because the different elements of the feature map must be normalized equally to maintain the property of temporal features in the convolution. For example, if the batch has
m instances and each feature map has dimensions
, BN will be performed on all
elements based on the mean and standard deviation of batch input samples.
2.5. Exponential Linear Unit Activation Function
Clevert et al. [
33] introduced an improved version of the rectified linear unit (ReLU) activation function and its variants, i.e., parametric rectified linear unit (PReLU) and LeakyReLU, also called the exponential linear unit (ELU). This function is defined in Equation (
15).
where
is a hyperparameter and specifies the value to which the ELU converges for negative inputs. The ELU gradient is based on Equation (
16).
Like the ReLU, the ELU solves the gradient vanishing issue by having a single gradient for all positive inputs. In conjunction with accelerating the deep network learning compared to other functions of the ReLU family, the ELU provides better generalizability in the model [
33].
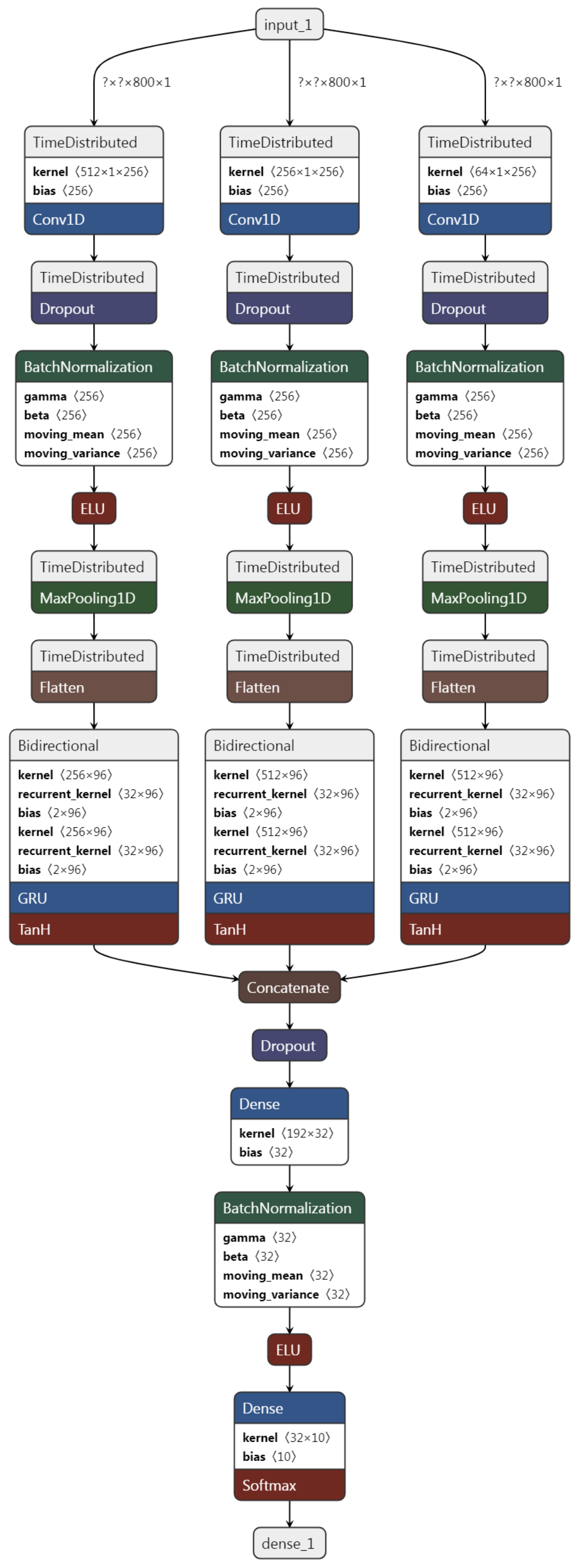
3. Proposed Model
The proposed structure consists of several different layers to establish a relationship between the raw bearing vibration signal and the output label. In the first layer, the convolutional network is used to extract the local features of the vibration signal. Each convolutional neural network contains a number of filters that extract their patterns by moving on the signal. In each layer, the size of these filters is fixed, and the convolution filter solely observes a certain range of signals in each slip.
Therefore, if multiple scales and frequencies of the vibration signal could be monitored, then more complete information about the signal could be achieved. In this regard, three parallel convolutions are used in the proposed model, each of which has a specific filter size, and each convolution has to extract features related to its scale.
All three convolutions have 256 one-dimensional filters, but the length of the filter is different. The length of the filters for the first convolution is 512, which is relatively large for an input vibration signal, and includes a signal with a length of 800, so they will be able to extract low-frequency features. The length of the second convolution filter is 256, which extracts the intermediate frequency features. In addition, in order not to lose the high-frequency features, a convolution layer with filters of length 64 is applied. Each convolution layer output will be feature maps that are the results of a specific scale of the input signal.
Dropout is applied after each layer. Dropout is a simple mechanism that turns off a number of neurons during the training process, and the weight of the connections of those neurons is not updated. The dropout rate is selected to be 0.05. This makes the network less sensitive to small changes in the input data, thus increasing the network’s generalizability and preventing overfitting.
Maxpooling is used to summarize the feature map and reduce the feature dimensions. The maxpooling output of a feature map contains the most prominent input features. The maxpooling window intended for the proposed model is equal to 256, which makes the resulting feature map small.
In each channel, after the convolutional network, a bidirectional GRU is used to extract global information and learn the sequential information of the feature map obtained by the convolution layer. A bidirectional GRU layer is used at the end of each channel to find the temporal dependencies between the spatial features obtained from the convolutional network. The bidirectional GRU extracts sequential information in both directions (dependence of before–after and post-forward moments) and learns the sequential pattern in the local features extracted by convolution. In the next step, all local and global features obtained from different signal scales are merged. In the final step, a fully connected (FC) layer with 32 neurons categorizes the extracted features. In this layer, like the convolutional network, batch normalization (BN) and ELU activation functions are applied.
The softmax function is used to find out the probability of which input data belong to a specific category. This output function converts the output of a network to a probability distribution with Equation (
17):
In the above relation,
K is the number of output neurons,
z is the input vector of the function, and
i is the index of the input vector. The neuron with the highest value of the function represents the class to which the provided input belongs. To calculate the network output error, the mean squared logarithmic error (MSLE) loss function is used, which is a type of mean squared error (MSE) loss function, and it has the advantage that small and big errors behave in a logarithmic manner. This function is defined in Equation (
18):
where
is the network output,
y is the true output, and
n is the number of data. To update the weights, an adaptive gradient algorithm (Adagrad) is used. This algorithm is defined in Equation (
19).
It should be noted that adaptative gradient (Adagrad) is a feature-specific learning rate optimizer. The adaptation of the learning rate is related to the frequency of update of a given feature. It assigns a higher learning rate to the infrequent features and vice versa.
where
is a diagonal matrix whose elements are the sum of gradients with respect to
to time t, and
is a fixed number to avoid dividing by a possible zero. The architecture of the proposed model is shown in
Figure 3. All hyperparameters of the proposed method are presented in
Table 1.
4. CWRU Dataset
The dataset provided by the CWRU [
34] Bearing Database is recognized as a standard benchmark for evaluating machine learning models to detect bearing faults. This dataset is available to the public and has been used by many researchers in the field. In this dataset, in addition to the location of the fault, the severity of the fault is also provided.
The dataset used to perform this experiment is the CWRU dataset. Most articles in the field of rotary machine diagnostics have used this dataset, and this will help us to be able to compare the results with other related work.
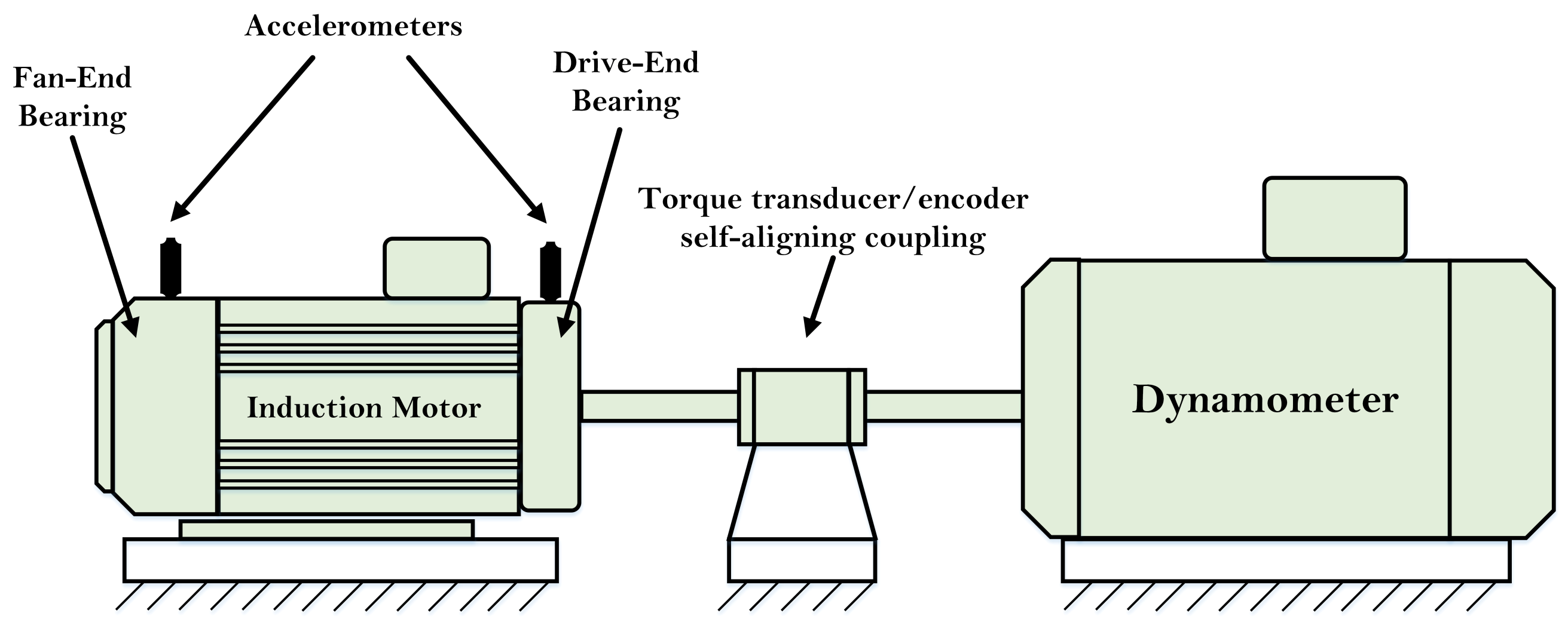
The equipment for this test, shown in
Figure 4, consists of a 2 hp motor and a dynamo meter that is used to apply the controlled torque. A torque and encoder transducer is connected to the device to measure the torque and speed, respectively. In addition, three accelerometers are used to obtain the mechanical vibration signal: one on the fan-end bearing, one on the drive-end bearing, and one on the motor holder base. The bearings under test in this dataset are SKF 6205-2RS-Jem bearings, and the data are taken at two sampling rates of 12 KHz and 48 KHz.
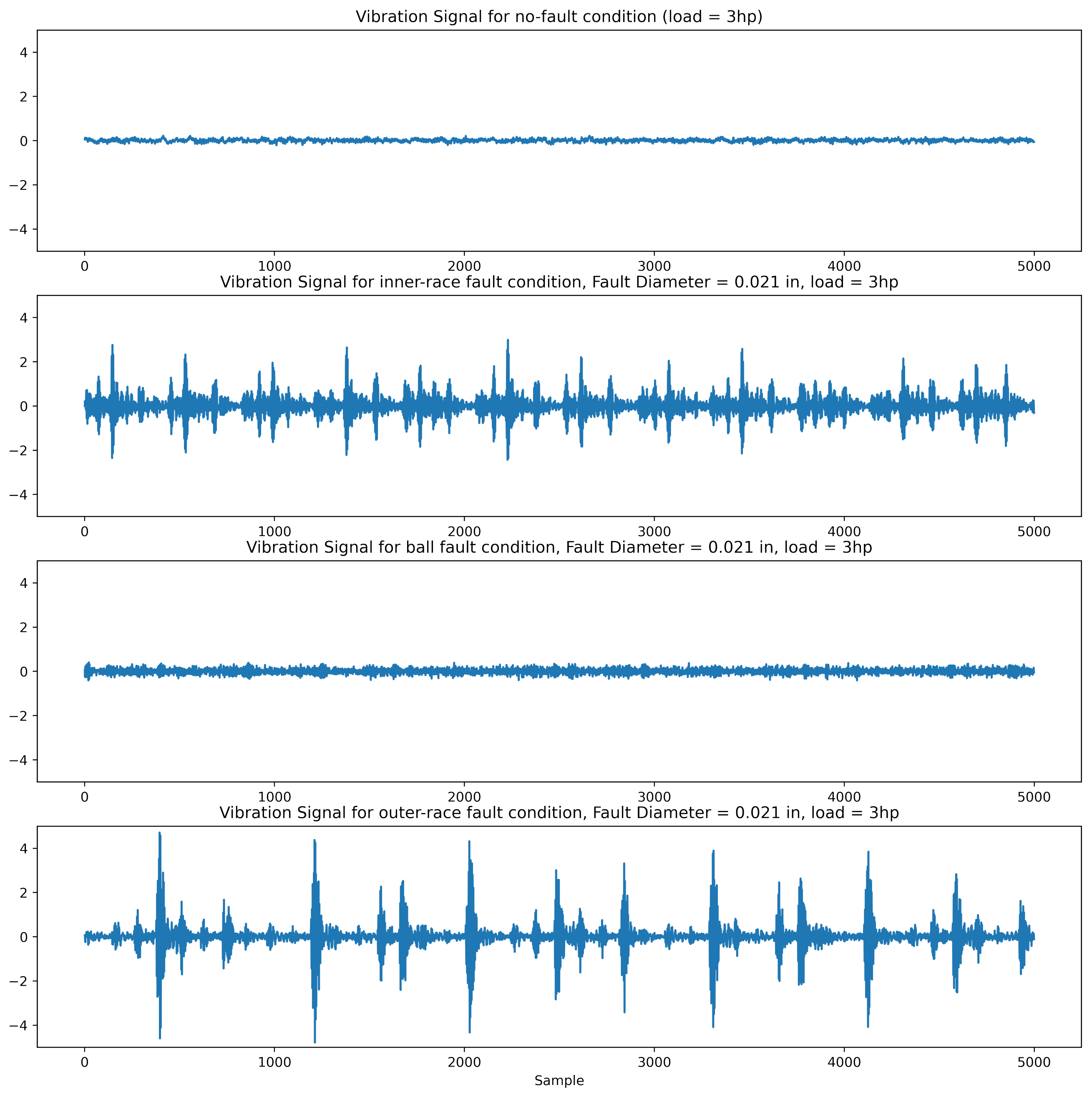
The data used in this study are the vibration signal obtained by an accelerometer mounted on the drive end (close to the fault) with a sampling rate of 12 KHz. In this test, the motor rotation speed is changed from 1730 RPM to 1797 RPM and the motor load is changed from 0 and 3 hp to create normal bearing operating conditions. This dataset includes three types of fault that were laboratory-induced by electrical discharge machining (EDM) with a depth of 0.011 inches in different parts of the bearing: the inner raceway, outer raceway, and balls (rolling element). In addition, each fault has three levels, with diameters of 0.007, 0.014, and 0.021 inches.
Figure 5 shows a snapshot of these signals.
Considering the healthy state, there are 10 types of data in this dataset in total. The dateset summary is reported in
Table 2. The time window considered in this study includes two complete rotations of the motor shaft. The amount of data in each cycle is obtained by
, where
is the sampling frequency (Hz),
is the motor shaft speed (rpm), and
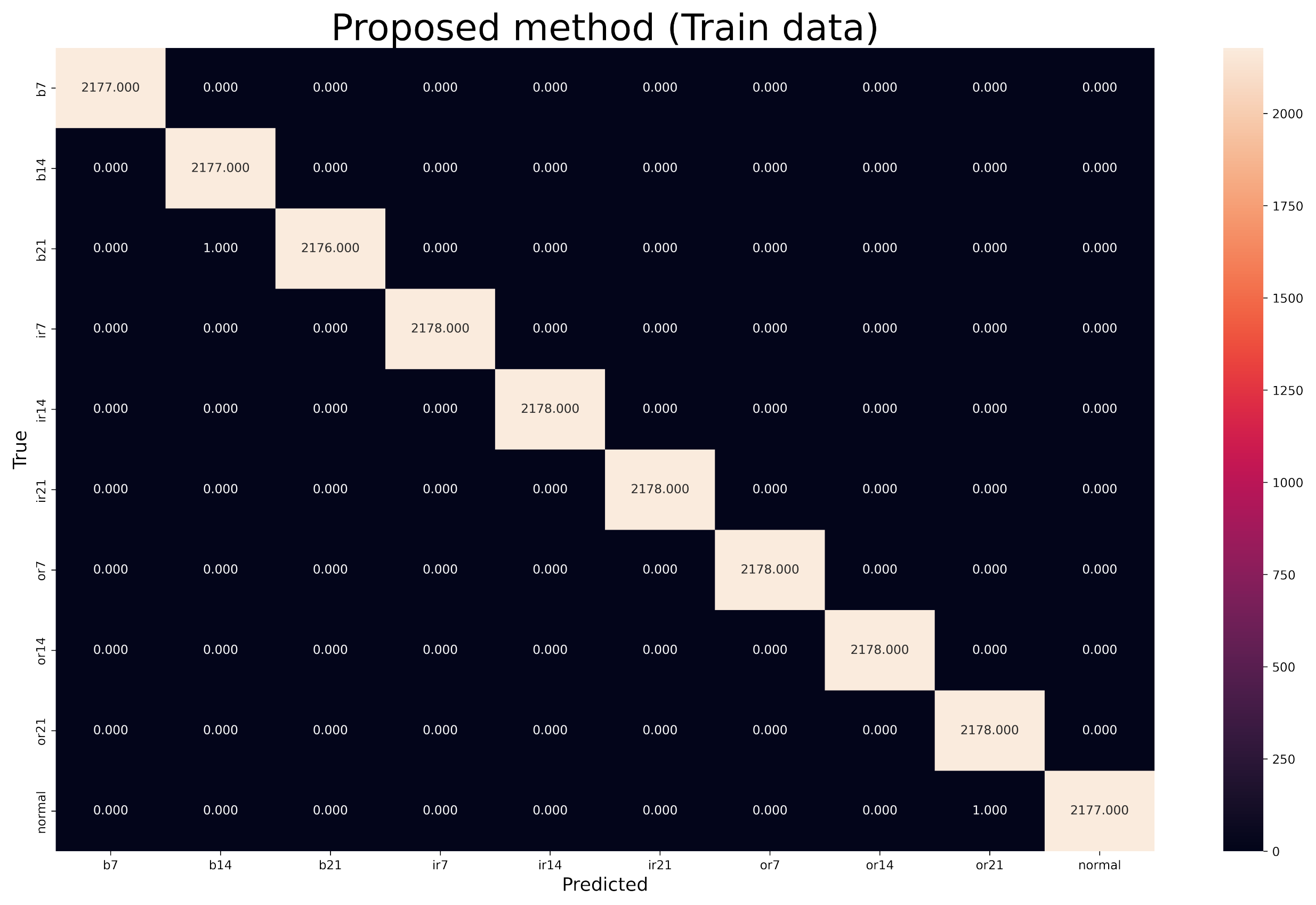
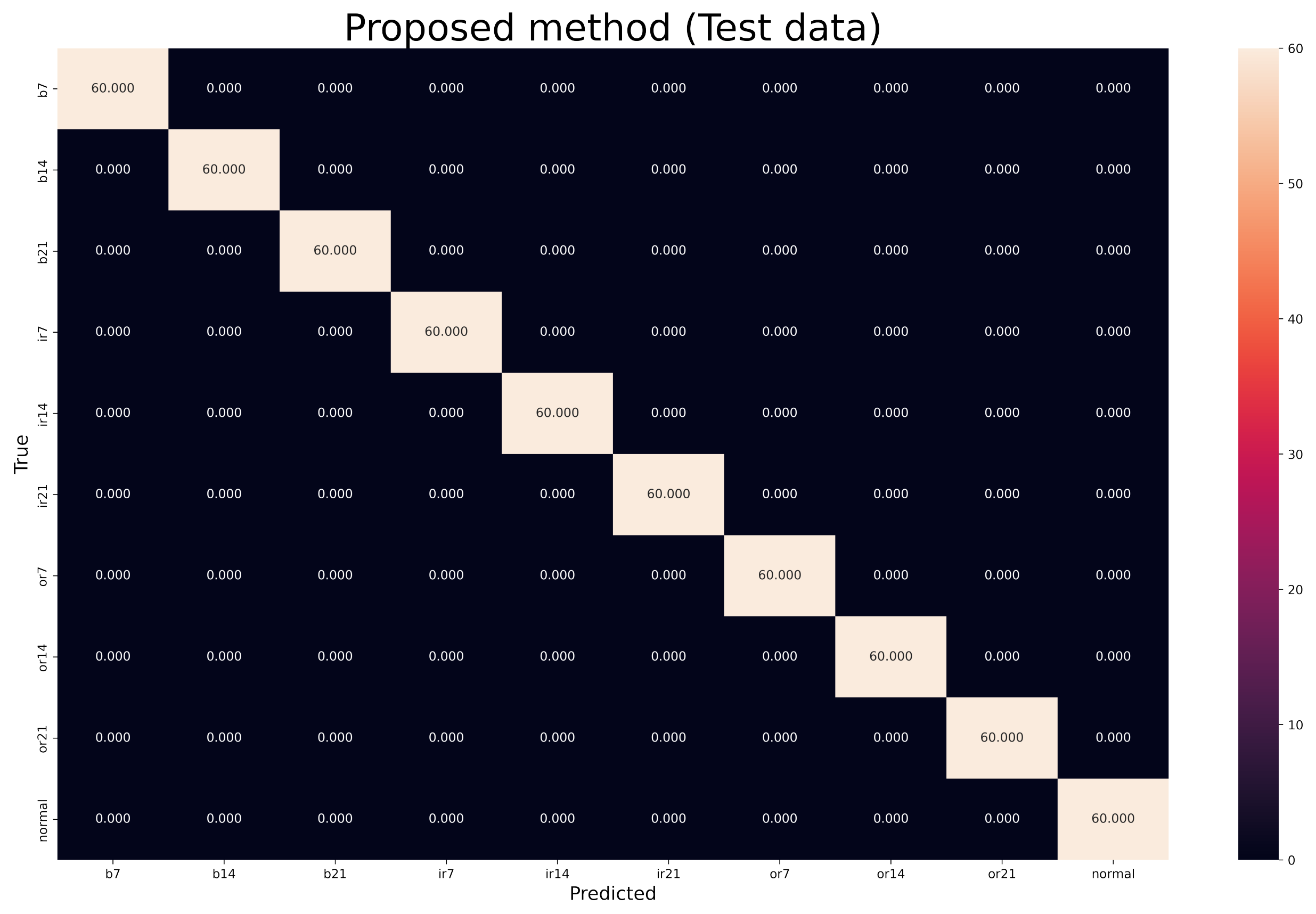
N is the amount of data. The average rotation speed of 1730, 1750, 1772, and 1797 rpm is approximately 1762 and, according to the sampling rate of 12 KHz, there are approximately 400 samples per cycle; two rotations of the motor shaft will give us 800 samples. Therefore, the selected time window will be 800 samples. Seventy-two percent of the data were selected as training, 18% as validation, and 10% as test.
Data Augmentation
Due to the large number of training parameters, deep learning models require large amounts of data for training, but such a dataset is not available. In this study, a data augmentation method called sliding window was used for training data. In this method, instead of creating training data with the size of a time window, the training window is shifted with n time-steps. Therefore, n samples from the previous data are removed and n new samples are added in, where n is the sliding parameter. In this study, was selected and the amount of training data was increased from 5440 to 21,770 samples.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}