
Optimizing Sampling Strategies for Near-Surface Soil Carbon Inventory: One Size Doesn’t Fit All

 , , ,
, , ,
Abstract
:1. Introduction
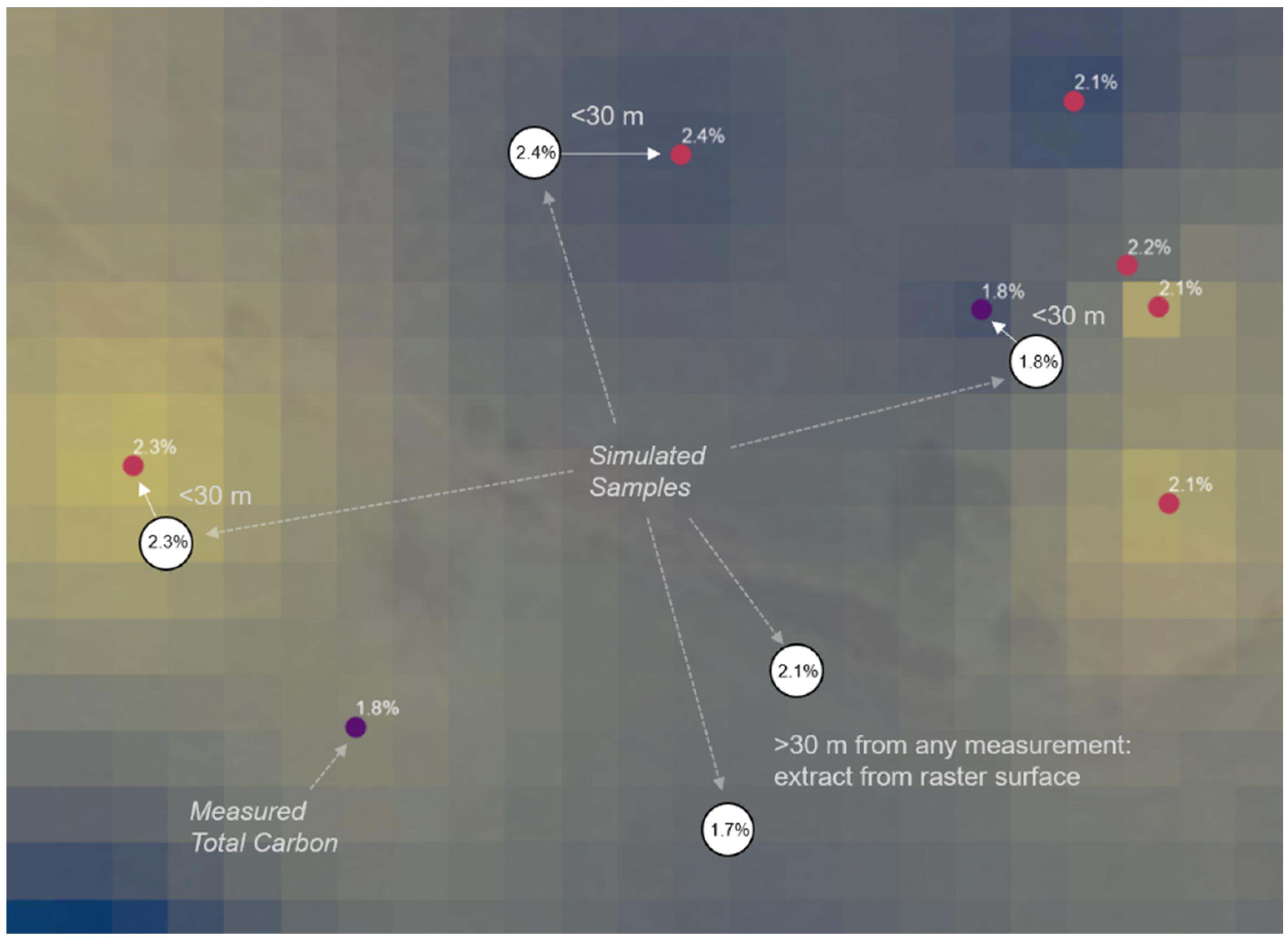
2. Materials and Methods
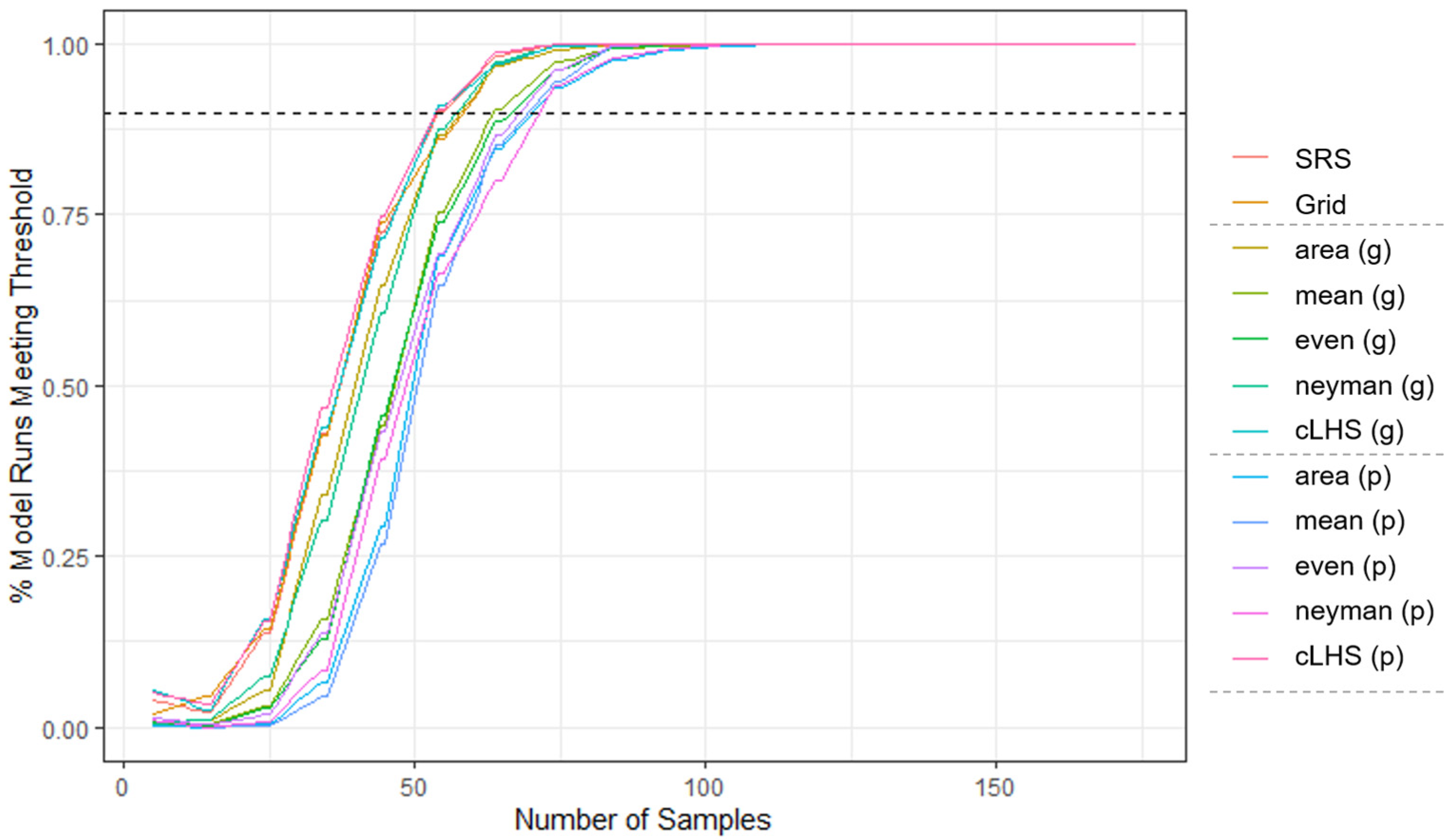
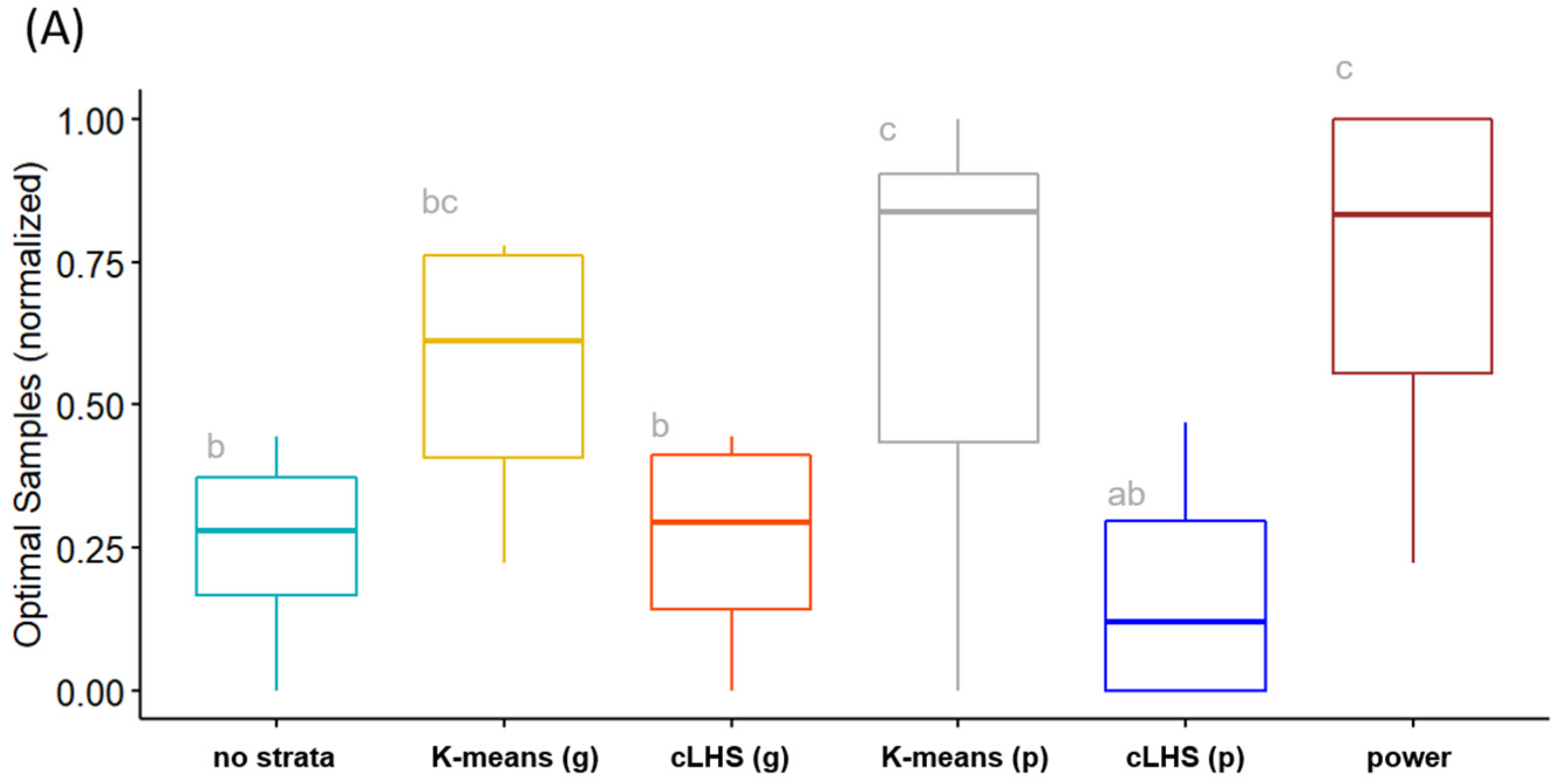
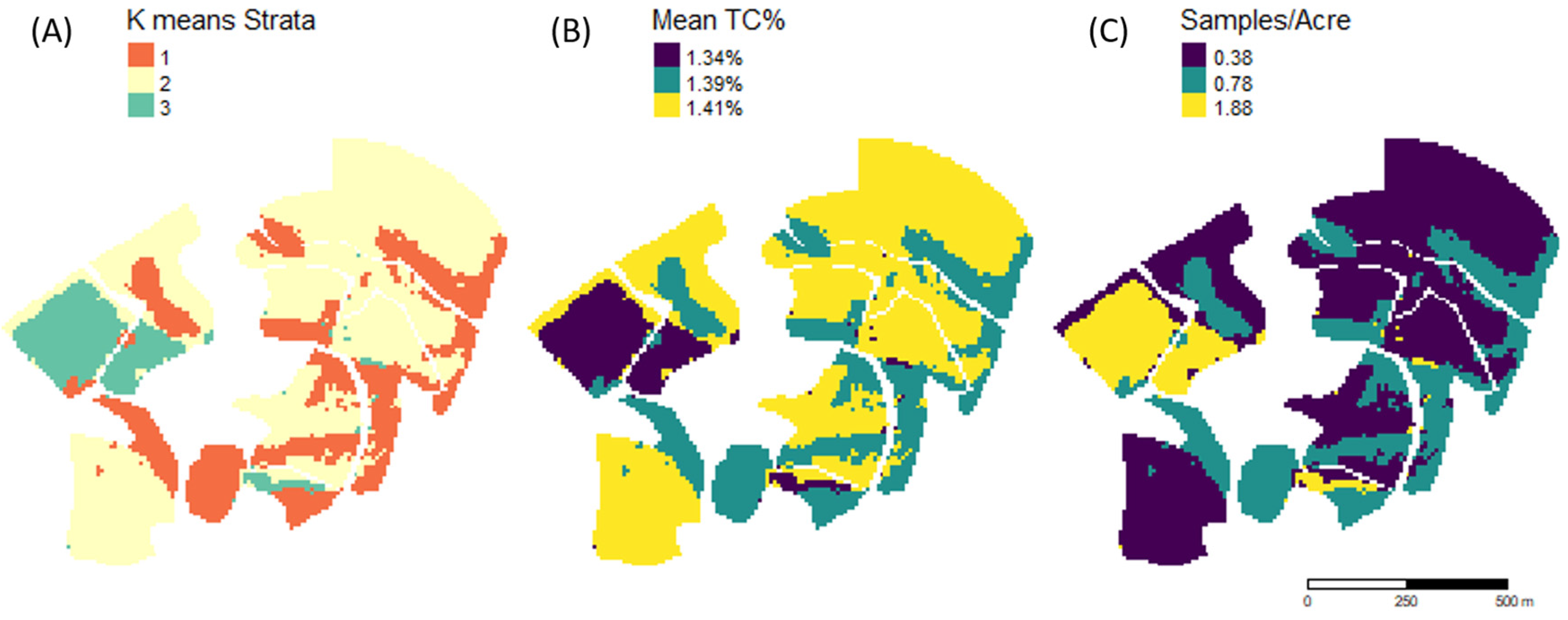
3. Results
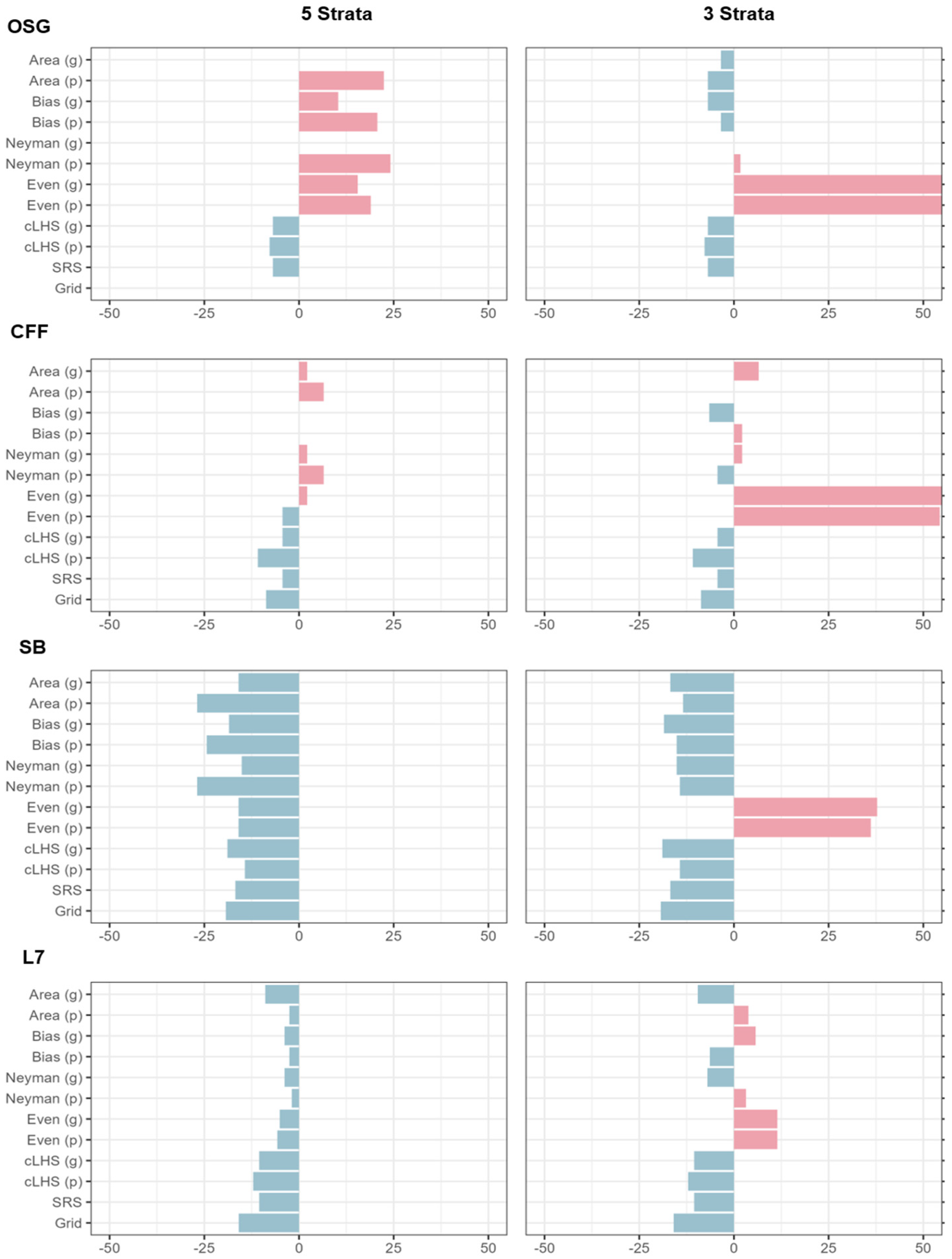
3.1. Five Strata
3.2. Three Strata
3.3. All Site Summary
4. Discussion
4.1. Grid Sampling
4.2. cLHS
4.3. Polaris vs. Open Geospatial
4.4. Avoiding Small Strata K-Means
4.5. Cost Penalties
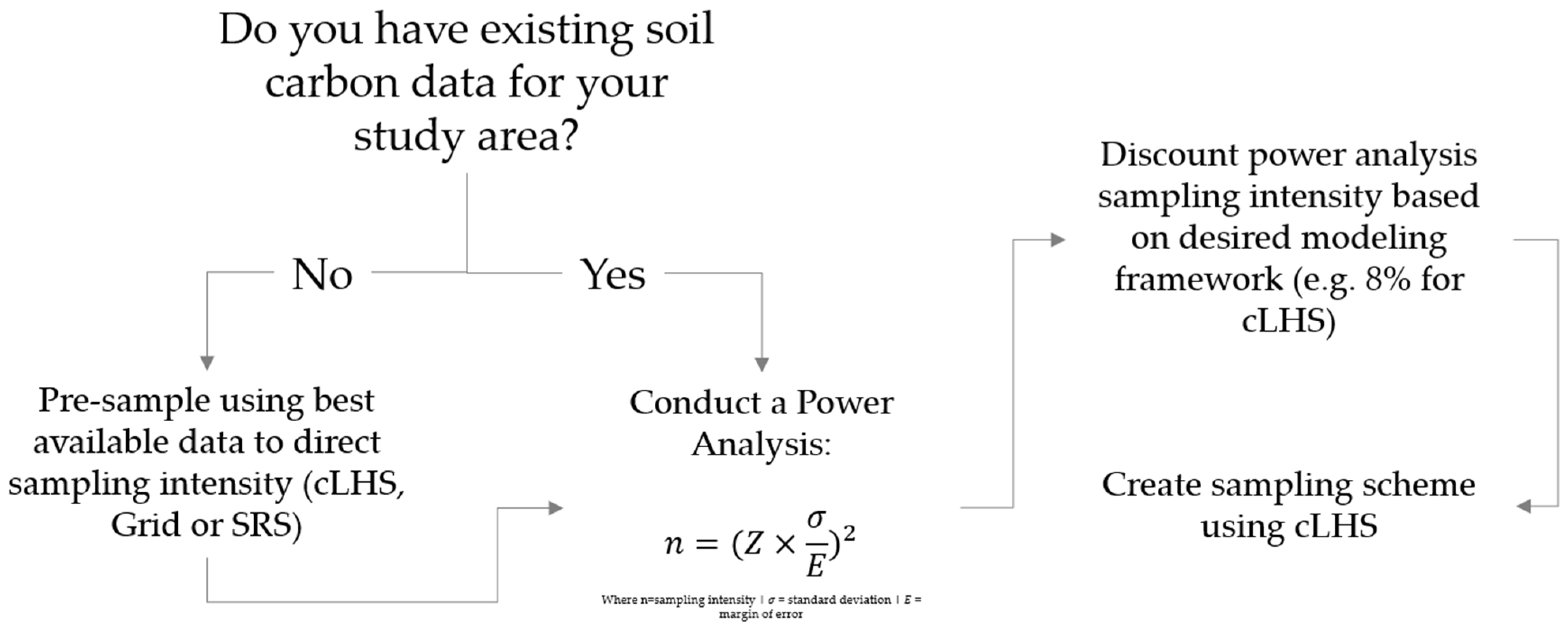
4.6. Adaptive Framework
4.7. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lal, R. Soil Carbon Sequestration Impacts on Global Climate Change and Food Security. Science 2004, 304, 1623–1627. [Google Scholar] [CrossRef] [Green Version]
- Sanderman, J.; Hengl, T.; Fiske, G.J. Soil carbon debt of 12,000 years of human land use. Proc. Natl. Acad. Sci. USA 2017, 114, 9575–9580. [Google Scholar] [CrossRef] [Green Version]
- Smith, P. Soils and climate change. Curr. Opin. Environ. Sustain. 2012, 4, 539–544. [Google Scholar] [CrossRef]
- Tifafi, M.; Guenet, B.; Hatté, C. Large Differences in Global and Regional Total Soil Carbon Stock Estimates Based on SoilGrids, HWSD, and NCSCD: Intercomparison and Evaluation Based on Field Data from USA, England, Wales, and France. Glob. Biogeochem. Cycles 2018, 32, 42–56. [Google Scholar] [CrossRef] [Green Version]
- Scharlemann, J.P.; Tanner, E.V.; Hiederer, R.; Kapos, V. Global soil carbon: Understanding and managing the largest terrestrial carbon pool. Carbon Manag. 2014, 5, 81–91. [Google Scholar] [CrossRef]
- Ramankutty, N.; Evan, A.T.; Monfreda, C.; Foley, J.A. Farming the planet: 1. Geographic distribution of global agricultural lands in the year 2000. Glob. Biogeochem. Cycles 2008, 22, GB1022. [Google Scholar] [CrossRef]
- Bigelow, D.; Borchers, A. Major Uses of Land in the United States. 2012. Available online: https://www.ers.usda.gov/webdocs/publications/84880/eib-178.pdf?v (accessed on 8 January 2023).
- Pezzuolo, A.; Dumont, B.; Sartori, L.; Marinello, F.; De Antoni Migliorati, M.; Basso, B. Evaluating the impact of soil conservation measures on soil organic carbon at the farm scale. Comput. Electron. Agric. 2017, 135, 175–182. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Basso, B. Impacts of climate variability and adaptation strategies on crop yields and soil organic carbon in the US Midwest. PLoS ONE 2020, 15, e0225433. [Google Scholar] [CrossRef] [Green Version]
- Griscom, B.W.; Adams, J.; Ellis, P.W.; Houghton, R.A.; Lomax, G.; Miteva, D.A.; Schlesinger, W.H.; Shoch, D.; Siikamäki, J.V.; Smith, P.; et al. Natural climate solutions. Proc. Natl. Acad. Sci. USA 2017, 114, 11645–11650. [Google Scholar] [CrossRef] [Green Version]
- Zomer, R.J.; Bossio, D.A.; Sommer, R.; Verchot, L.V. Global sequestration potential of increased organic carbon in cropland soils. Sci. Rep. 2017, 7, 15554–15558. [Google Scholar] [CrossRef] [Green Version]
- FAO. Measuring and Modelling Soil Carbon Stocks and Stock Changes in Livestock Production Systems Guidelines for Assessment. Livestock Environmental Assessment and Performance (LEAP) Partnership. 2019. Available online: https://www.fao.org/publications/card/en/c/CA2934EN/ (accessed on 12 August 2021).
- Lal, R. Soil organic matter content and crop yield. J. Soil Water Conserv. 2020, 75, 27A–32A. [Google Scholar] [CrossRef] [Green Version]
- Oldfield, E.E.; Bradford, M.A.; Wood, S.A. Global meta-analysis of the relationship between soil organic matter and crop yields. SOIL 2019, 5, 15–32. [Google Scholar] [CrossRef] [Green Version]
- Libohova, Z.; Seybold, C.; Willis, S.; Schoeneberger, P.; Williams, C.; Lindbo, D.; Stott, D.; Owens, P.R. Reevaluating the effects of soil organic matter and other properties on available water-holding capacity using the National Cooperative Soil Survey Characterization Database. J. Soil Water Conserv. 2018, 73, 411–421. [Google Scholar] [CrossRef] [Green Version]
- Minasny, B.; McBratney, A.B. Limited effect of organic matter on soil available water capacity. Eur. J. Soil Sci. 2018, 69, 39–47. [Google Scholar] [CrossRef] [Green Version]
- Smith, P.; Soussana, J.F.; Angers, D.; Schipper, L.; Chenu, C.; Rasse, D.P.; Batjes, N.H.; Egmond, V.F.; McNeill, S.; Kuhnert, M.; et al. How to measure, report and verify soil carbon change to realize the potential of soil carbon sequestration for atmospheric greenhouse gas removal. Glob. Change Biol. 2020, 26, 219–241. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ward, K.J.; Chabrillat, S.; Neumann, C.; Foerster, S. A remote sensing adapted approach for soil organic carbon prediction based on the spectrally clustered LUCAS soil database. Geoderma 2019, 353, 297–307. [Google Scholar] [CrossRef]
- Conant, R.T.; Smith, G.R.; Paustian, K. Spatial Variability of Soil Carbon in Forested and Cultivated Sites. J. Environ. Qual. 2003, 32, 278–286. [Google Scholar] [CrossRef] [Green Version]
- de Gruijter, J.J.; McBratney, A.B.; Minasny, B.; Wheeler, I.; Malone, B.P.; Stockmann, U. Farm-scale soil carbon auditing. Geoderma 2016, 265, 120–130. [Google Scholar] [CrossRef]
- Mandal, A.; Majumder, A.; Dhaliwal, S.S.; Toor, A.S.; Mani, P.K.; Naresh, R.K.; Gupta, R.K.; Mitran, T. Impact of agricultural management practices on soil carbon sequestration and its monitoring through simulation models and remote sensing techniques: A review. Crit. Rev. Environ. Sci. Technol. 2020; ahead of print. [Google Scholar] [CrossRef]
- Basso, B.; Antle, J. Digital agriculture to design sustainable agricultural systems. Nat. Sustain. 2020, 3, 254–256. [Google Scholar] [CrossRef]
- Basso, B.; Dobrowolski, J.; McKay, C. From the Dust Bowl to Drones to Big Data: The Next Revolution in Agriculture. Georget. J. Int. Aff. 2017, 18, 158–165. [Google Scholar] [CrossRef]
- Paustian, K.; Larson, E.; Kent, J.; Marx, E.; Swan, A. Soil C Sequestration as a Biological Negative Emission Strategy. Front. Clim. 2019, 1, 8. [Google Scholar] [CrossRef]
- Don, A.; Schumacher, J.; Scherer-Lorenzen, M.; Scholten, T.; Schulze, E. Spatial and vertical variation of soil carbon at two grassland sites—Implications for measuring soil carbon stocks. Geoderma 2007, 141, 272–282. [Google Scholar] [CrossRef]
- Garten, C.T.; Wullschleger, S.D. Soil Carbon Inventories under a Bioenergy Crop (Switchgrass): Measurement Limitations. J. Environ. Qual. 1999, 28, 1359–1365. [Google Scholar] [CrossRef]
- Vanguelova, E.I.; Bonifacio, E.; Vos, D.B.; Hoosbeek, M.R.; Berger, T.W.; Vesterdal, L.; Armolaitis, K.; Celi, L.; Dinca, L.; Kjønaas, O.J.; et al. Sources of errors and uncertainties in the assessment of forest soil carbon stocks at different scales—Review and recommendations. Environ. Monit. Assess. 2016, 188, 630. [Google Scholar] [CrossRef]
- Minasny, B.; Malone, B.P.; McBratney, A.B.; Angers, D.A.; Arrouays, D.; Chambers, A.; Chaplot, V.; Chen, Z.; Cheng, K.; Das, B.S.; et al. Soil carbon 4 per mille. Geoderma 2017, 292, 59–86. [Google Scholar] [CrossRef]
- Gruijter, J.J.; Bierkens, M.F.P.; Brus, D.J.; Knotters, M. Sampling for Natural Resource Monitoring; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Kerry, R.; Oliver, M.A.; Frogbrook, Z.L. Sampling in Precision Agriculture. In Geostatistical Applications for Precision Agriculture; Springer: Dordrecht, The Netherlands, 2010; pp. 35–63. [Google Scholar]
- Oliver, M.A.; Webster, R. The elucidation of soil pattern in the Wyre Forest of the West Midlands, England. II. Spatial distribution. J. Soil Sci. 1987, 38, 293–307. [Google Scholar] [CrossRef]
- Wadoux, A.M.J.; Brus, D.J.; Heuvelink, G.B.M. Sampling design optimization for soil mapping with random forest. Geoderma 2019, 355, 113913. [Google Scholar] [CrossRef]
- Allen, D.E.; Pringle, M.J.; Page, K.L.; Dalal, R.C. A review of sampling designs for the measurement of soil organic carbon in Australian grazing lands. Rangel. J. 2010, 32, 227–246. [Google Scholar] [CrossRef]
- Youden, W.J.; Mehlich, A. Selection of Efficient Methods for Soil Sampling. Soil Sci. Soc. Am. J. 1938, 2, 399. [Google Scholar] [CrossRef]
- Zhang, Y.; Hartemink, A.E. Sampling designs for soil organic carbon stock assessment of soil profiles. Geoderma 2017, 307, 220–230. [Google Scholar] [CrossRef]
- Wadoux, A.M.J.C.; Marchant, B.P.; Lark, R.M. Efficient sampling for geostatistical surveys. Eur. J. Soil Sci. 2019, 70, 975–989. [Google Scholar] [CrossRef]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: New York, NY, USA, 1997. [Google Scholar]
- Wallenius, K.; Rita, H.; Mikkonen, A.; Lappi, K.; Lindström, K.; Hartikainen, H.; Raateland, A.; Niemi, R.M. Effects of land use on the level, variation and spatial structure of soil enzyme activities and bacterial communities. Soil Biol. Biochem. 2011, 43, 1464–1473. [Google Scholar] [CrossRef]
- Peltoniemi, M.; Heikkinen, J.; Mäkipää, R. Stratification of regional sampling by model-predicted changes of carbon stocks in Forested mineral soils. Silva Fenn. 2007, 41, 287. [Google Scholar] [CrossRef] [Green Version]
- Rao, P.S. Sampling Methodologies; Chapman & Hall/CRC: Boca Raton, FL, USA, 2000. [Google Scholar]
- Malone, B.P.; Odgers, N.P.; Stockmann, U.; Minasny, B.; McBratney, A.B. Digital Mapping of Soil Classes and Continuous Soil Properties. In Pedometrics; Springer International Publishing: Cham, Switzerland, 2018; pp. 373–413. [Google Scholar]
- Parton, W.J.; Schimel, D.S.; Cole, C.V.; Ojima, D.S. Analysis of Factors Controlling Soil Organic Matter Levels in Great Plains Grasslands. Soil Sci. Soc. Am. J. 1987, 51, 1173. [Google Scholar] [CrossRef]
- Peltoniemi, M.; Mäkipää, R.; Liski, J.; Tamminen, P. Changes in soil carbon with stand age-an evaluation of a modelling method with empirical data. Glob. Change Biol. 2004, 10, 2078–2091. [Google Scholar] [CrossRef]
- Spencer, S.; Ogle, S.M.; Breidt, F.J.; Goebel, J.J.; Paustian, K. Designing a national soil carbon monitoring network to support climate change policy: A case example for US agricultural lands. Greenh. Gas Meas. Manag. 2011, 1, 167–178. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Malone, B.P.; Wheeler, I. Digital Mapping of Soil Carbon. In Advances in Agronomy; Elsevier Science & Technology: Amsterdam, The Netherlands, 2013; Volume 118, pp. 1–47. [Google Scholar]
- Malone, B.P.; Minansy, B.; Brungard, C. Some methods to improve the utility of conditioned Latin hypercube sampling. PeerJ 2019, 7, e6451. [Google Scholar] [CrossRef]
- Singh, K.; Whelan, B.; Goss, M. Soil carbon change across ten New South Wales farms under different farm management regimes in Australia. Soil Use Manag. 2020, 36, 616–632. [Google Scholar] [CrossRef]
- Miller, B.A.; Koszinski, S.; Hierold, W.; Rogasik, H.; Schröder, B.; Van Oost, K.; Wehrhan, M.; Sommer, M. Towards mapping soil carbon landscapes: Issues of sampling scale and transferability. Soil Tillage Res. 2016, 156, 194. [Google Scholar] [CrossRef]
- Shao, S.; Zhang, H.; Fan, M.; Su, B.; Wu, J.; Zhang, M.; Yang, L.; Gao, C. Spatial variability-based sample size allocation for stratified sampling. CATENA 2021, 206, 105509. [Google Scholar] [CrossRef]
- Costa, C.; Dittmer, K.; Shelton, S.; Bossio, D.; Zinyengere, N.; Luu, P.; Heinz, S.; Egenolf, K.; Rowland, B.; Zuluaga, A.; et al. How Soil Carbon Accounting Can Improve to Support Investment-Oriented Actions Promoting Soil Carbon Storage. 2020. Available online: https://samples.ccafs.cgiar.org/how-soil-carbon-accounting-can-improve-to-support-investment-oriented-actions-promoting-soil-carbon-storage/ (accessed on 12 August 2021).
- Zhou, W.; Guan, K.; Peng, B.; Margenot, A.; Lee, D.; Tang, J.; Jin, Z.; Grant, R.; DeLucia, E.; Qin, Z.; et al. How does uncertainty of soil organic carbon stock affect the calculation of carbon budgets and soil carbon credits for croplands in the U.S. Midwest? Geoderma 2023, 429, 116254. [Google Scholar] [CrossRef]
- Soil Survey Staff Web Soil Survey. Natural Resources Conservation Service, United States Department of Agriculture. Available online: https://websoilsurvey.nrcs.usda.gov/app/ (accessed on 29 August 2022).
- Stratifi. Available online: https://charliebettigole.users.earthengine.app/view/stratifi-beta-v21 (accessed on 12 June 2020).
- Natural Resources Conservation Service, United States Department Of Agriculture Gridded Soil Survey Geographic Database (gSSURGO). 2016. Available online: https://www.nrcs.usda.gov/resources/data-and-reports/gridded-soil-survey-geographic-gssurgo-database (accessed on 29 August 2022).
- Poggio, L.; De Sousa, L.M.; Batjes, N.H.; Heuvelink, G.B.M.; Kempen, B.; Ribeiro, E.; Rossiter, D. SoilGrids 2.0: Producing soil information for the globe with quantified spatial uncertainty. Soil 2021, 7, 217–240. [Google Scholar] [CrossRef]
- Chaney, N.W.; Wood, E.F.; McBratney, A.B.; Hempel, J.W.; Nauman, T.W.; Brungard, C.W.; Odgers, N.P. POLARIS: A 30-meter probabilistic soil series map of the contiguous United States. Geoderma 2016, 274, 54–67. [Google Scholar] [CrossRef] [Green Version]
- Gesch, D.; Oimoen, M.; Greenlee, S.; Nelson, C.; Steuck, M.; Tyler, D. The national elevation dataset. Photogramm. Eng. Remote Sens. 2002, 68, 5–11. [Google Scholar]
- CAR Soil Enrichment Protocol | Version 1.0|. 2020. Available online: https://www.climateactionreserve.org/how/protocols/ncs/soil-enrichment/ (accessed on 12 August 2021).
- FAO. FAO GSOC MRV Protocol. 2020. Available online: https://www.fao.org/3/cb0509en/cb0509en.pdf (accessed on 12 August 2021).
- VCS. VCS Module VMD0021 Estimation of Stocks in the Soil Carbon Pool. 2012. Available online: https://verra.org/wp-content/uploads/imported/methodologies/VMD0021-Estimation-of-Stocks-in-the-Soil-Carbon-Pool-v1.0.pdf (accessed on 12 August 2021).
- Edgar Bueno OptimStrat: Choosing the Sample Strategy. 2020. Available online: https://cran.r-project.org/web/packages/optimStrat/optimStrat.pdf (accessed on 12 August 2021).
- Minasny, B.; McBratney, A.B. A conditioned Latin hypercube method for sampling in the presence of ancillary information. Comput. Geosci. 2006, 32, 1378–1388. [Google Scholar] [CrossRef]
- Roudier, P. Clhs: A R Package for Conditioned Latin Hypercube Sampling. 2011. Available online: https://cran.r-project.org/web/packages/clhs/clhs.pdf (accessed on 29 August 2022).
- Rumpel, C.; Amiraslani, F.; Chenu, C.; Garcia Cardenas, M.; Kaonga, M.; Koutika, L.; Ladha, J.; Madari, B.; Shirato, Y.; Smith, P.; et al. The 4p1000 initiative: Opportunities, limitations and challenges for implementing soil organic carbon sequestration as a sustainable development strategy. Ambio 2020, 49, 350–360. [Google Scholar] [CrossRef] [Green Version]
- Bossio, D.A.; Cook-Patton, S.C.; Ellis, P.W.; Fargione, J.; Sanderman, J.; Smith, P.; Wood, S.; Zomer, R.J.; von Unger, M.; Emmer, I.M.; et al. The role of soil carbon in natural climate solutions. Nat. Sustain. 2020, 3, 391–398. [Google Scholar] [CrossRef]
- Maillard, É.; McConkey, B.G.; Angers, D.A. Increased uncertainty in soil carbon stock measurement with spatial scale and sampling profile depth in world grasslands: A systematic analysis. Agric. Ecosyst. Environ. 2017, 236, 268–276. [Google Scholar] [CrossRef]
- Lawrence, P.G.; Roper, W.; Morris, T.F.; Guillard, K. Guiding soil sampling strategies using classical and spatial statistics: A review. Agron. J. 2020, 112, 493–510. [Google Scholar] [CrossRef] [Green Version]
- Lamichhane, S.; Kumar, L.; Wilson, B. Digital soil mapping algorithms and covariates for soil organic carbon mapping and their implications: A review. Geoderma 2019, 352, 395–413. [Google Scholar] [CrossRef]
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Potash, E.; Guan, K.; Margenot, A.; Lee, D.; DeLucia, E.; Wang, S.; Jang, C. How to estimate soil organic carbon stocks of agricultural fields? Perspectives using ex-ante evaluation. Geoderma 2022, 411, 115693. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data; WILEY: New York, NY, USA, 2009. [Google Scholar]
- Aynekulu, E.; Vagen, T.; Shephard, K.; Winowiecki, L. A Protocol for Modeling, Measurement and Monitoring Soil Carbon Stocks in Agricultural Landscapes; World Agroforestry Centre: Nairobi, Kenya, 2011. [Google Scholar]
- Bradford, M.A.; Carey, C.J.; Atwood, L.; Bossio, D.; Fenichel, E.P.; Gennet, S.; Fargione, J.; Fisher, J.R.B.; Fuller, E.; Kane, D.A.; et al. Soil carbon science for policy and practice. Nat. Sustain. 2019, 2, 1070–1072. [Google Scholar] [CrossRef]
- Davies, L.L.; Uchitel, K.; Ruple, J. Understanding barriers to commercial-scale carbon capture and sequestration in the United States: An empirical assessment. Energy Policy 2013, 59, 745–761. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Sub-Model Labels | Geospatial Inputs | Number of Strata |
|---|---|---|---|
| Simple Random Sample | SRS | Study Area Boundary | - |
| Grid Sample | Grid | Study Area Boundary | - |
| cLHS | cLHS (p), cLHS (g) | p: Polaris Mean OM 5–15 cm g: NDVI (Sentinel 2 L1c), Slope, Northness, Soil C (GSSURGO) | - |
| K-means | area (p), even (p), bias (p), neyman (p), area (g), even (g), bias (g), neyman (g) | p: Polaris Mean OM 5–15 cm g: NDVI (Sentinel 2 L1c), Slope, Northness, Soil C (GSSURGO) | 3/5 |
| Farm | N-Samp | Ha | Samples ha−1 | Power ha−1 | Dominant Soil Type | Mean Total C | SD Total C | Range/Psill | EBK RMSE |
|---|---|---|---|---|---|---|---|---|---|
| OSG | 569 | 234.0 | 2.43 | 0.25 | Purcellville silty clay loam | 1.43% | 0.33 | 240.2/0.02 | 0.283 |
| CFF | 344 | 61.3 | 5.61 | 0.75 | Armour Silt Loam | 1.4% | 0.29 | 44.6/0.02 | 0.247 |
| SB | 207 | 104.1 | 1.99 | 1.14 | Charleton Fine Sandy Loam | 2.49% | 0.82 | 146.3/0.04 | 0.758 |
| L7 | 245 | 70.7 | 3.47 | 2.22 | Holston Loam | 0.89% | 0.34 | 252.0/0.13 | 0.256 |
| Three Strata | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Power Analysis | Best Model | Worst Model | Cost Diff Per 1000 ha | |||||||
| Farm | N × ha−1 | Pwr N | Name | N × ha−1 | N | Name | N × ha−1 | N | Best v Power | Best v Worse |
| OSG | 0.25 | 58 | cLHS (p) | 0.229 | 53 | Even (p) | 0.397 | 93 | $385 | $3376 |
| CFF | 0.75 | 46 | cLHS (p) | 0.669 | 41 | Even (g) | 1.191 | 73 | $1632 | $10,442 |
| SB | 1.14 | 119 | Grid | 0.922 | 96 | Even (g) | 1.576 | 164 | $4420 | $13,067 |
| L7 | 2.22 | 157 | Grid | 1.868 | 132 | Even (p) | 2.476 | 175 | $7074 | $12,167 |
| Five Strata | ||||||||||
| OSG | 0.25 | 58 | cLHS (p) | 0.229 | 53 | Neyman (p) | 0.308 | 72 | $342 | $1538 |
| CFF | 0.75 | 46 | cLHS (p) | 0.669 | 41 | Neyman (p) | 0.799 | 49 | $1632 | $2611 |
| SB | 1.14 | 119 | Area (p) | 0.836 | 87 | cLHS (p) | 0.980 | 102 | $6149 | $2882 |
| L7 | 2.22 | 157 | Grid | 1.868 | 132 | Neyman (p) | 2.179 | 154 | $7074 | $6225 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bettigole, C.; Hanle, J.; Kane, D.A.; Pagliaro, Z.; Kolodney, S.; Szuhay, S.; Chandler, M.; Hersh, E.; Wood, S.A.; Basso, B.; et al. Optimizing Sampling Strategies for Near-Surface Soil Carbon Inventory: One Size Doesn’t Fit All. Soil Syst. 2023, 7, 27. https://doi.org/10.3390/soilsystems7010027
Bettigole C, Hanle J, Kane DA, Pagliaro Z, Kolodney S, Szuhay S, Chandler M, Hersh E, Wood SA, Basso B, et al. Optimizing Sampling Strategies for Near-Surface Soil Carbon Inventory: One Size Doesn’t Fit All. Soil Systems. 2023; 7(1):27. https://doi.org/10.3390/soilsystems7010027
Chicago/Turabian StyleBettigole, Charles, Juliana Hanle, Daniel A. Kane, Zoe Pagliaro, Shaylan Kolodney, Sylvana Szuhay, Miles Chandler, Eli Hersh, Stephen A. Wood, Bruno Basso, and et al. 2023. "Optimizing Sampling Strategies for Near-Surface Soil Carbon Inventory: One Size Doesn’t Fit All" Soil Systems 7, no. 1: 27. https://doi.org/10.3390/soilsystems7010027
APA StyleBettigole, C., Hanle, J., Kane, D. A., Pagliaro, Z., Kolodney, S., Szuhay, S., Chandler, M., Hersh, E., Wood, S. A., Basso, B., Goodwin, D. J., Hardy, S., Wolf, Z., & Covey, K. R. (2023). Optimizing Sampling Strategies for Near-Surface Soil Carbon Inventory: One Size Doesn’t Fit All. Soil Systems, 7(1), 27. https://doi.org/10.3390/soilsystems7010027