LODsyndesis: Global Scale Knowledge Services



Abstract
:1. Introduction
- We describe in brief the process of constructing semantic indexes and performing connectivity measurements for any subset of datasets.
- We introduce specific use cases and services, we mention how they can also be important in cultural domain by showing specific examples, whereas we show ways to exploit them (e.g., programmatically through a REST API or through an HTML page).
- We report connectivity analytics for hundreds of LOD Cloud datasets, by focusing on publications (and cultural heritage) domain, and we show measurements for datasets that use CIDOC CRM model, such as British Museum.
2. Context and Related Work
2.1. RDF and Linked Data
2.2. Related Work
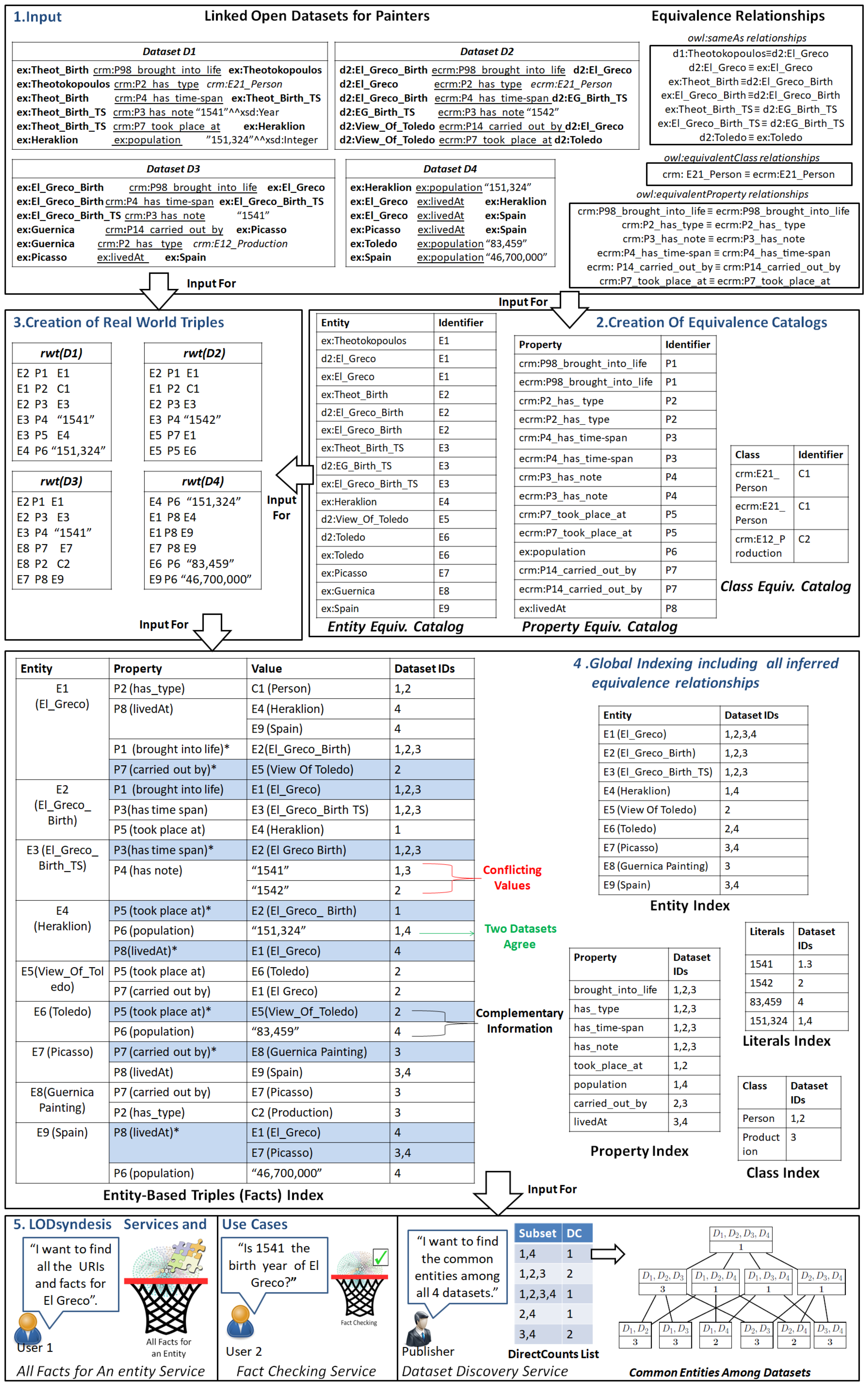
3. The Process for Performing Semantic Indexing and Connectivity Analytics
3.1. Semantic Indexing Process
3.2. Performing Connectivity Analytics
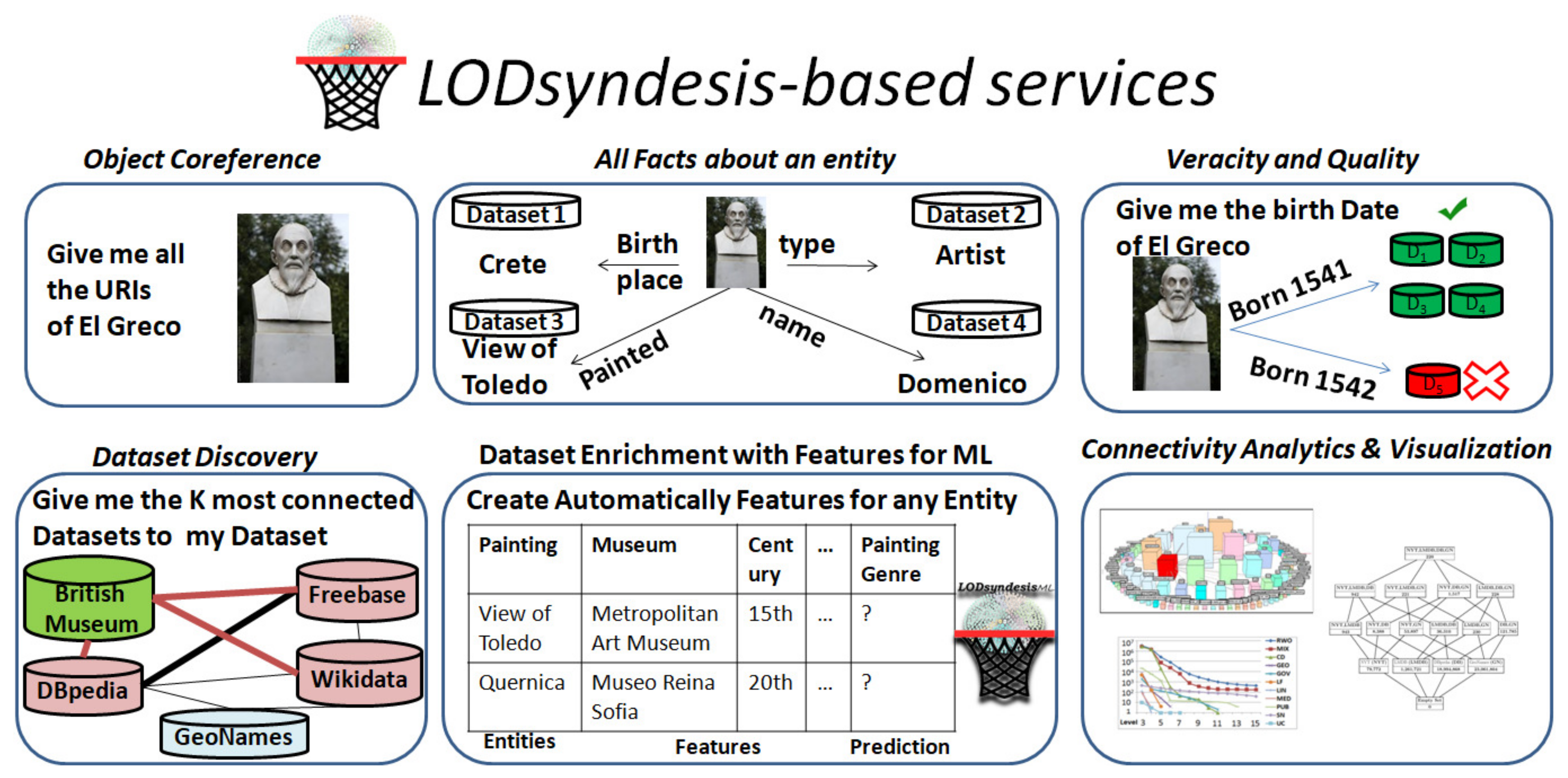
4. LODsyndesis Services and Use Cases
4.1. How to Find the URI of an Entity
4.2. UC1. Object Coreference and All Facts for an Entity Service
4.3. UC2. Fact Checking Service
4.4. UC3. Dataset Discovery and Selection Services
4.5. UC4. Dataset Enrichment for Machine Learning Based Tasks
4.6. UC5. Global Namespace Service
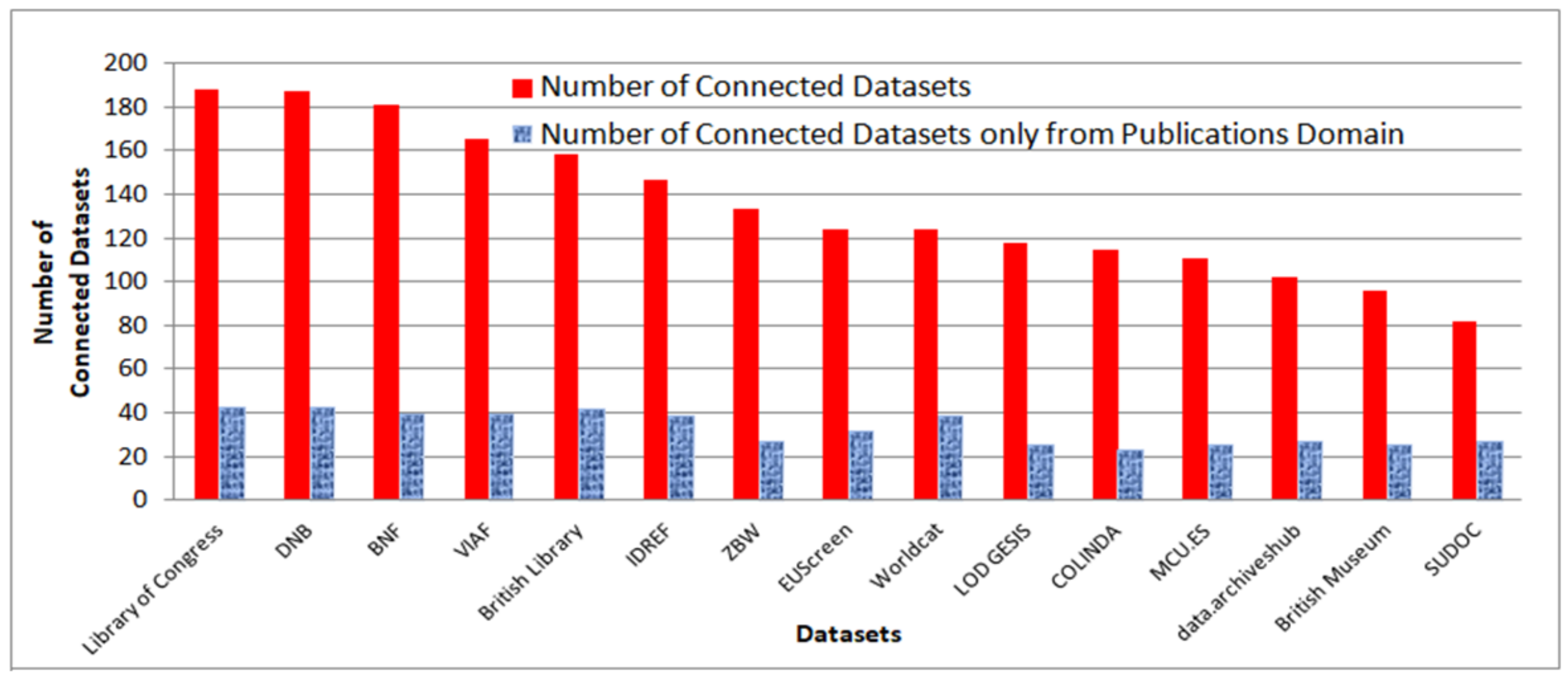
5. Connectivity Analytics over Hundreds of Linked Datasets (Focus on Datasets of Publications and Cultural Domain)
5.1. Connectivity Analytics for Publications Domain
5.2. Connectivity Analytics for British Museum
5.3. Conclusions about Connectivity of the LOD Cloud
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ermilov, I.; Lehmann, J.; Martin, M.; Auer, S. LODStats: The data web census dataset. In Proceedings of the International Semantic Web Conference, Kobe, Japan, 17–21 October 2016; Springer: Berlin, Germany, 2016; pp. 38–46. [Google Scholar]
- Doerr, M. The CIDOC conceptual reference module: An ontological approach to semantic interoperability of metadata. AI Mag. 2003, 24, 75. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia: A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. On Measuring the Lattice of Commonalities Among Several Linked Datasets. Proc. VLDB Endow. 2016, 9, 1101–1112. [Google Scholar] [CrossRef]
- Mountantonakis, M.; Tzitzikas, Y. Scalable Methods for Measuring the Connectivity and Quality of Large Numbers of Linked Datasets. J. Data Inf. Q. (JDIQ) 2018, 9. [Google Scholar] [CrossRef]
- Mountantonakis, M.; Tzitzikas, Y. High Performance Methods for Linked Open Data Connectivity Analytics. Information 2018, 9, 134. [Google Scholar] [CrossRef]
- Antoniou, G.; Van Harmelen, F. A Semantic Web Primer; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- W3C RDF Specification. RDF 1.1 Concepts and Abstract Syntax. Available online: http://www.w3.org/TR/rdf11-concepts/ (accessed on 12 November 2018).
- Antoniou, G.; Van Harmelen, F. Europeana linked open data–data.europeana.eu. Semant. Web. 2013, 4, 291–297. [Google Scholar]
- Doerr, M.; Gradmann, S.; Hennicke, S.; Isaac, A.; Meghini, C.; Van de Sompel, H. The Europeana Data Model (EDM). In Proceedings of the World Library and Information Congress: 76th IFLA General Conference and Assembly, Gothenburg, Sweden, 10–15 August 2010; pp. 10–15. [Google Scholar]
- Rietveld, L.; Beek, W.; Schlobach, S. LOD lab: Experiments at LOD scale. In Proceedings of the International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; Springer: Berlin, Germany, 2015; pp. 339–355. [Google Scholar]
- Fernández, J.D.; Beek, W.; Martínez-Prieto, M.A.; Arias, M. LOD-a-lot. In Proceedings of the International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; pp. 75–83. [Google Scholar]
- Vandenbussche, P.Y.; Atemezing, G.A.; Poveda-Villalón, M.; Vatant, B. Linked Open Vocabularies (LOV): A gateway to reusable semantic vocabularies on the Web. Semant. Web 2017, 8, 437–452. [Google Scholar] [CrossRef]
- Richardson, L.; Ruby, S. RESTful Web Services; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008. [Google Scholar]
- Common Format and MIME Type for Comma-Separated Values (CSV) Files. Available online: http://tools.ietf.org/html/rfc4180 (accessed on 12 November 2018).
- The JavaScript Object Notation (JSON) Data Interchange Format. Available online: http://buildbot.tools.ietf.org/html/rfc7158 (accessed on 12 November 2018).
- Extensible Markup Language (XML). Available online: http://www.w3.org/XML/ (accessed on 12 November 2018).
- RDF 1.1 N-Triples. Available online: http://www.w3.org/TR/n-triples/ (accessed on 12 November 2018).
- RDF 1.1 N-Quads. Available online: http://www.w3.org/TR/n-quads/ (accessed on 12 November 2018).
- Siddiquie, B.; Vitaladevuni, S.; Davis, L. Combining multiple kernels for efficient image classification. In Proceedings of the Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–8. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. How Linked Data can Aid Machine Learning-Based Tasks. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Thessaloniki, Greece, 18–21 September 2017; Springer: Berlin, Germany, 2017; pp. 155–168. [Google Scholar]
- Ristoski, P.; de Vries, G.K.D.; Paulheim, H. A collection of benchmark datasets for systematic evaluations of machine learning on the semantic web. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2016; pp. 186–194. [Google Scholar]
- Nentwig, M.; Hartung, M.; Ngonga Ngomo, A.; Rahm, E. A survey of current link discovery Semant. Web 2017, 8, 419–436. [Google Scholar]
- Okeanos Cloud Computing Service. Available online: http://okeanos.grnet.gr (accessed on 12 November 2018).
- British Museum Collection. Available online: http://collection.britishmuseum.org/ (accessed on 12 November 2018).
- Datos Artium. Available online: http://biblioteca.artium.org (accessed on 12 November 2018).
- Sandrart. Available online: http://ta.sandrart.net/en/ (accessed on 12 November 2018).
- Szépművészeti Múzeum. Available online: http://www.szepmuveszeti.hu/ (accessed on 12 November 2018).
- Data Archives Hub. Available online: http://data.archiveshub.ac.uk/ (accessed on 12 November 2018).
- Library of Congress Linked Data Service. Available online: http://id.loc.gov/ (accessed on 12 November 2018).
- The Virtual International Authority File. Available online: http://viaf.org (accessed on 12 November 2018).
- Deutschen National Bibliothek. Available online: http://www.dnb.de (accessed on 12 November 2018).
- The British Library. Available online: http://bl.uk (accessed on 12 November 2018).
- Bibliothèque Nationale de France. Available online: http://www.bnf.fr (accessed on 12 November 2018).
- IdRef-Identifiants et référentiels. Available online: http://www.idref.fr (accessed on 12 November 2018).
- German National Library of Economics. Available online: www.zbw.eu/en/ (accessed on 12 November 2018).
- EUscreen. Available online: http://www.euscreen.eu/ (accessed on 12 November 2018).
- WorldCat.org: The World’s Largest Library Catalog. Available online: http://www.worldcat.org/ (accessed on 12 November 2018).
- LOD Gesis. Available online: http://lod.gesis.org (accessed on 12 November 2018).
- Conference Linked Data. Available online: http://colinda.org (accessed on 12 November 2018).
- Lista de Encabezamientos de Materia para las Bibliotecas Públicas en SKOS. Available online: http://id.sgcb.mcu.es (accessed on 12 November 2018).
- SUDOC Catalogue. Available online: http://punktokomo.abes.fr/2011/07/04/le-sudoc-sur-le-web-de-donnees/ (accessed on 12 November 2018).
- Freebase. Available online: http://developers.google.com/freebase/ (accessed on 12 November 2018).
- Wikidata. Available online: http://www.wikidata.org (accessed on 12 November 2018).
- Yago. Available online: http://yago-knowledge.org (accessed on 12 November 2018).
- Kruse, S.; Papotti, P.; Naumann, F. Estimating Data Integration and Cleaning Effort. In Proceedings of the International Conference on Extending Database Technology, Brussels, Belgium, 23–27 March 2015; pp. 61–72. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| ID | Service URL | Description | Parameters | Response Types |
|---|---|---|---|---|
| 1 | LODsyndesis/rest-api/ keywordEntity | Finds all the URIs, containing one or more keywords. | keyword: Put one or more keywords. | text/csv, application/json, application/xml |
| 2 | LODsyndesis/rest-api/ objectCoreference | Finds all the equivalent entities of a given URI or the datasets where it occurs. | uri: Put any URI (Entity or Schema Element). provenance: It is an optional parameter. Put true for showing the datasets where the selected entity occurs. | application/n-triples, application/json, application/xml |
| 3 | LODsyndesis/rest-api/ allFacts | Finds all the facts (and their provenance) for a given URI (or an equivalent one). | uri: Put a URI that represents an entity. | application/n-quads, application/json, application/xml |
| 4 | LODsyndesis/rest-api/ factChecking | Checks a specific fact for a given entity. | uri: Put a URI that represents a single entity. fact: Put a fact, separate words by using space. threshold: Ratio of how many words of the fact should exist in the triple (optional). | application/n-triples, application/json, application/xml |
| 5 | LODsyndesis/rest-api/ datasetDiscovery | Finds the most connected datasets to a given one for several measurement types. | dataset: Put a URI of an RDF Dataset. connections_number: It is optional. It can be any integer greater than zero, i.e., for showing the top-k connected datasets. subset_size: It can be any of the following: [pairs, triads, quads] (e.g., select pairs for finding the most connected pairs of datasets). measurement_type: It can be any of the following: [Entities, Literals, Properties, Triples, Classes, SubjectObject]. | application/n-triples, application/json, application/xml |
| 6 | LODsyndesis/rest-api/ namespaceLookup | Finds all the datasets where a namespace occurs. | namespace: Put any namespace. | text/csv, application/json, application/xml |
| Category | % of Connected Pairs in Publications Domain (Average Connectivity of All the Datasets) | % of Connected Triads in Publications Domain (Average Connectivity of All the Datasets) |
|---|---|---|
| Entities | 14.3% (11%) | 2% (1.24%) |
| Literals | 88.7% (78%) | 68.2% (46.44%) |
| Properties | 44.8% (24.45%) | 16.87% (5.38%) |
| Classes | 11.1% (5.42%) | 2.1% (0.5%) |
| Triples | 8.2% (10%) | 0.5% (1%) |
| Position | Subset of Datasets | # of Common Entities |
|---|---|---|
| 1 | {DNB, Library of Congress ,VIAF} | 1,333,836 |
| 2 | {British Library, Library of Congress ,VIAF} | 1,040,862 |
| 3 | {BNF, Library of Congress, VIAF} | 1,007,312 |
| 4 | {DNB, BNF, VIAF} | 592,367 |
| 5 | {DNB, BNF, Library of Congress} | 516,323 |
| Measurement Type | Number of Connected Datasets | Datasets with at Least 10 Commonalities | Datasets with at Least 100 Commonalities | Datasets with at Least 1000 Commonalities | Most Connected Dataset to British Museum for Each Measurement Type |
|---|---|---|---|---|---|
| Entities | 95 | 44 | 27 | 13 | Wikidata |
| Literals | 393 | 359 | 263 | 132 | YAGO |
| Classes | 4 | 2 | 0 | 0 | Szepmuveszeti Muzeum |
| Properties | 143 | 2 | 0 | 0 | Datos ARTIUM |
| Triples | 48 | 26 | 14 | 8 | Library of Congress |
| Position | Subset of Datasets | # of Common Entities |
|---|---|---|
| 1 | {British Museum, VIAF, Wikidata} | 18,865 |
| 2 | {British Museum, DBpedia, Wikidata} | 17,172 |
| 3 | {British Museum, DBpedia, Yago} | 16,039 |
| 4 | {British Museum, Yago, Wikidata} | 16,036 |
| 5 | {British Museum, Library of Congress, VIAF} | 15,317 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mountantonakis, M.; Tzitzikas, Y. LODsyndesis: Global Scale Knowledge Services. Heritage 2018, 1, 335-348. https://doi.org/10.3390/heritage1020023
Mountantonakis M, Tzitzikas Y. LODsyndesis: Global Scale Knowledge Services. Heritage. 2018; 1(2):335-348. https://doi.org/10.3390/heritage1020023
Chicago/Turabian StyleMountantonakis, Michalis, and Yannis Tzitzikas. 2018. "LODsyndesis: Global Scale Knowledge Services" Heritage 1, no. 2: 335-348. https://doi.org/10.3390/heritage1020023
APA StyleMountantonakis, M., & Tzitzikas, Y. (2018). LODsyndesis: Global Scale Knowledge Services. Heritage, 1(2), 335-348. https://doi.org/10.3390/heritage1020023