
Crop Yield Estimation Using Sentinel-3 SLSTR, Soil Data, and Topographic Features Combined with Machine Learning Modeling: A Case Study of Nepal





Abstract
:1. Introduction
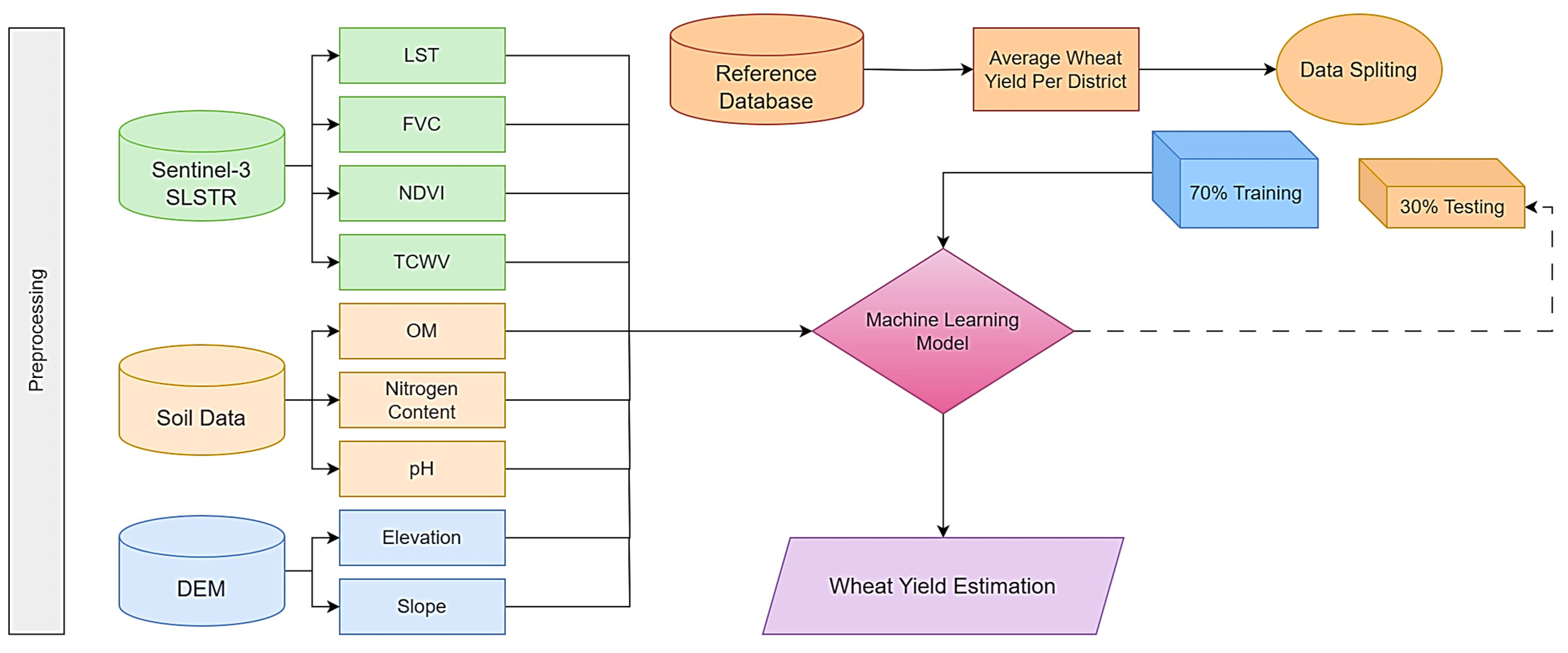
2. Materials and Methods
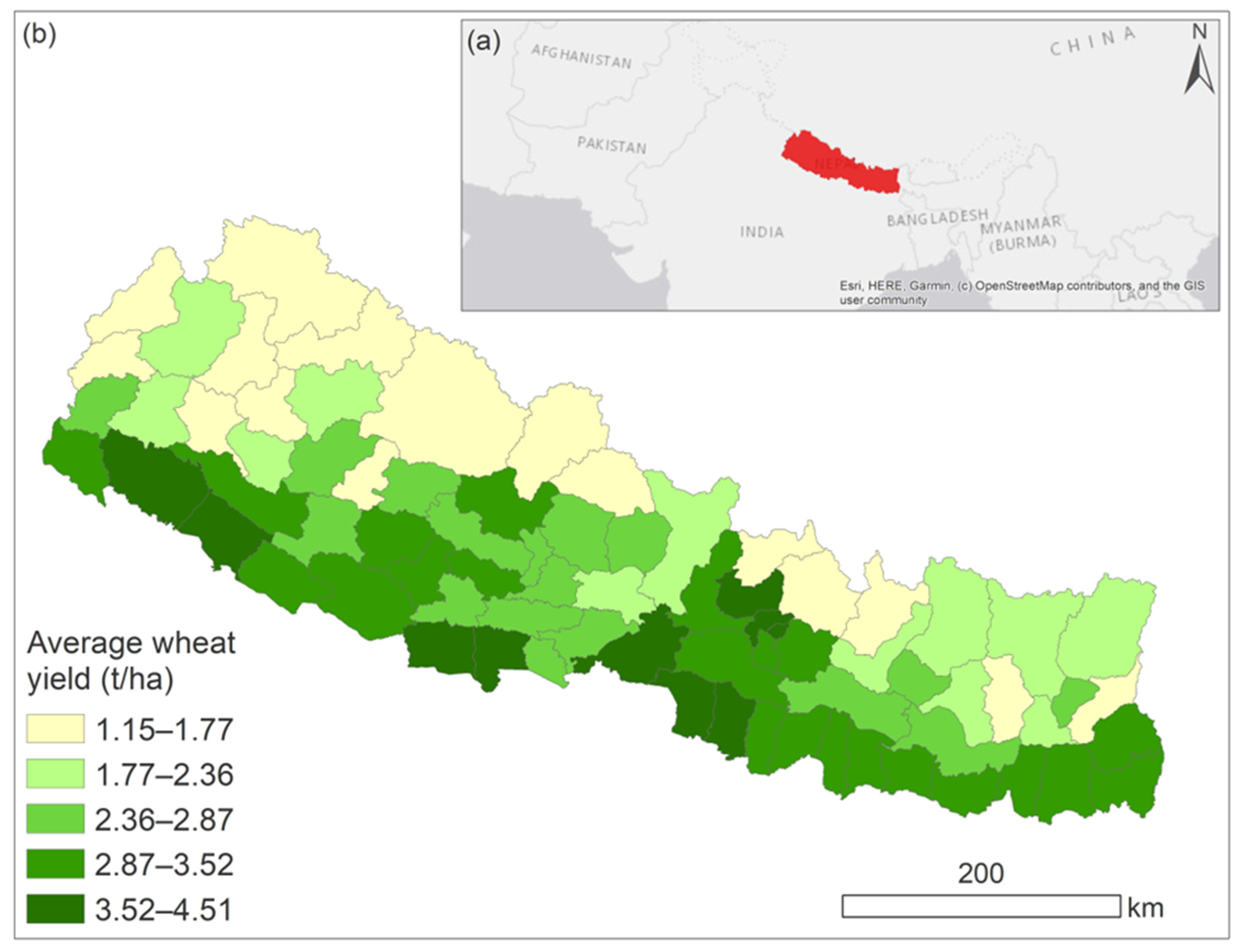
2.1. Study Area and Reference Data
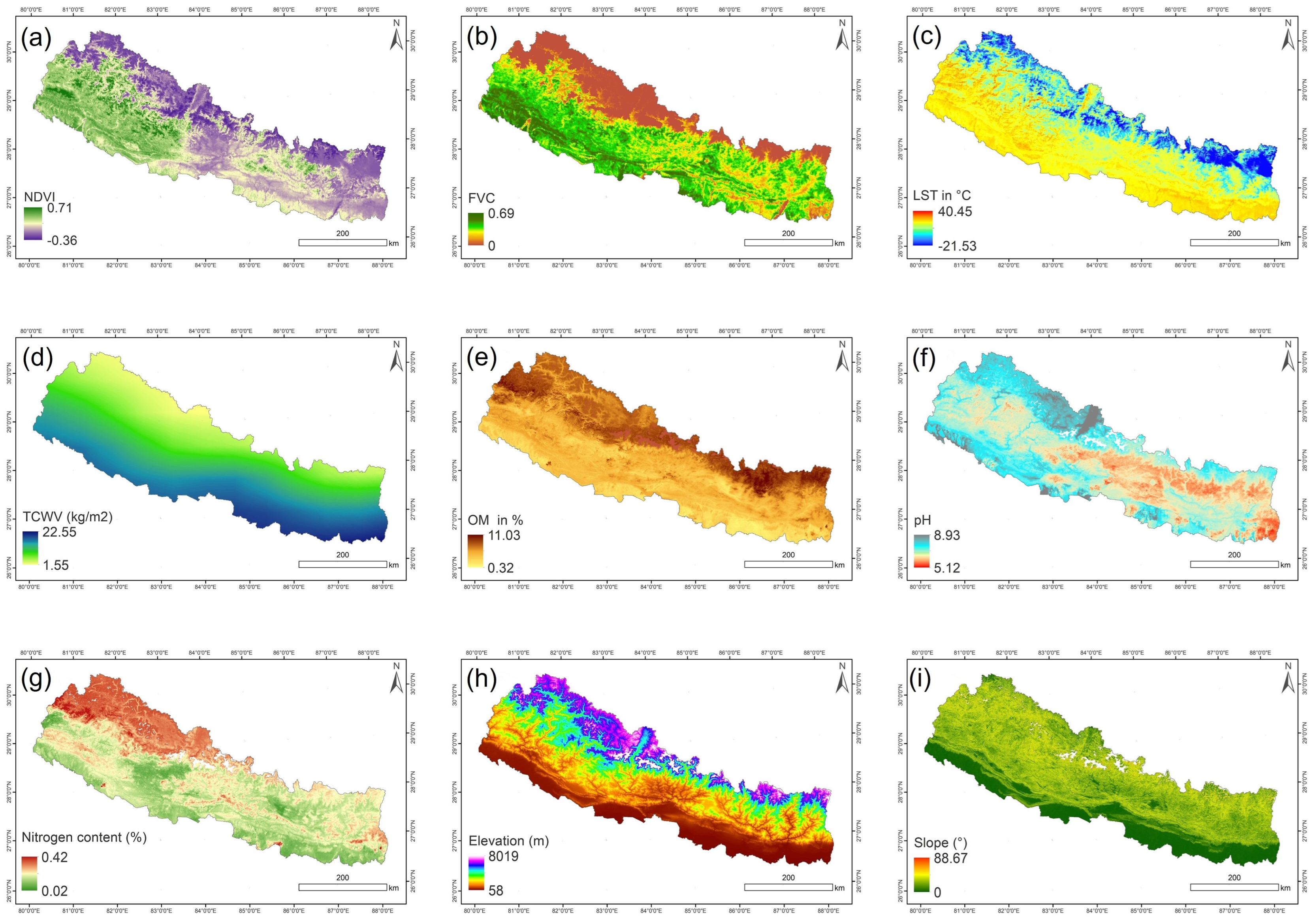
2.2. Remote Sensing Data and Other Features
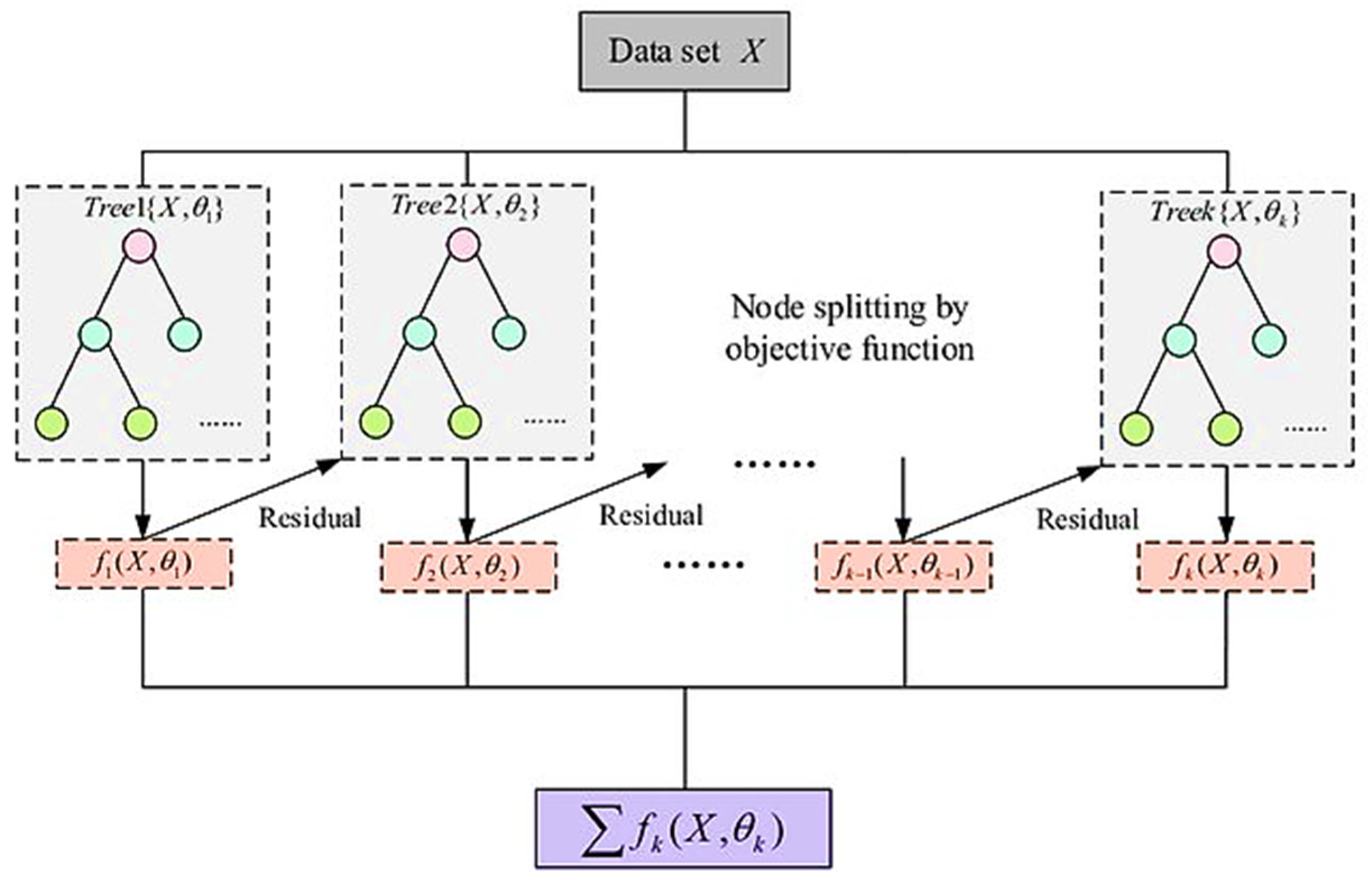
2.3. Gradient Boosting Machine (GBM) versus Extreme Gradient Boosting (XGBoost)
| Algorithm 1: Friedman’s gradient boost algorithm |
| Inputs: |
|
| Algorithm: |
|
2.4. Hyperparameter Optimization
2.5. Accuracy Assessment Metrics
3. Results and Discussion
3.1. Descriptive Analysis
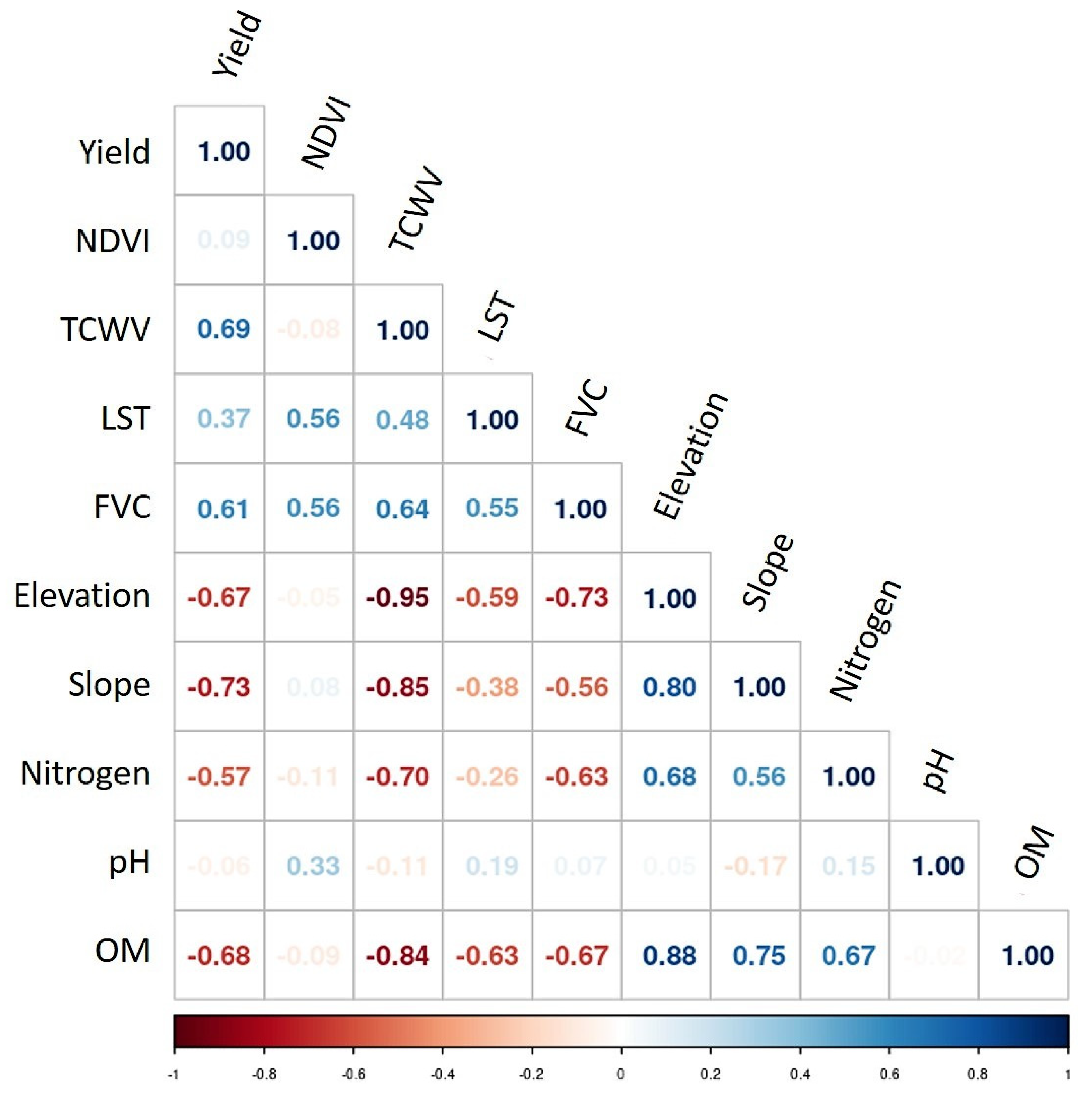
3.2. Selection of Variables and Model Calibration
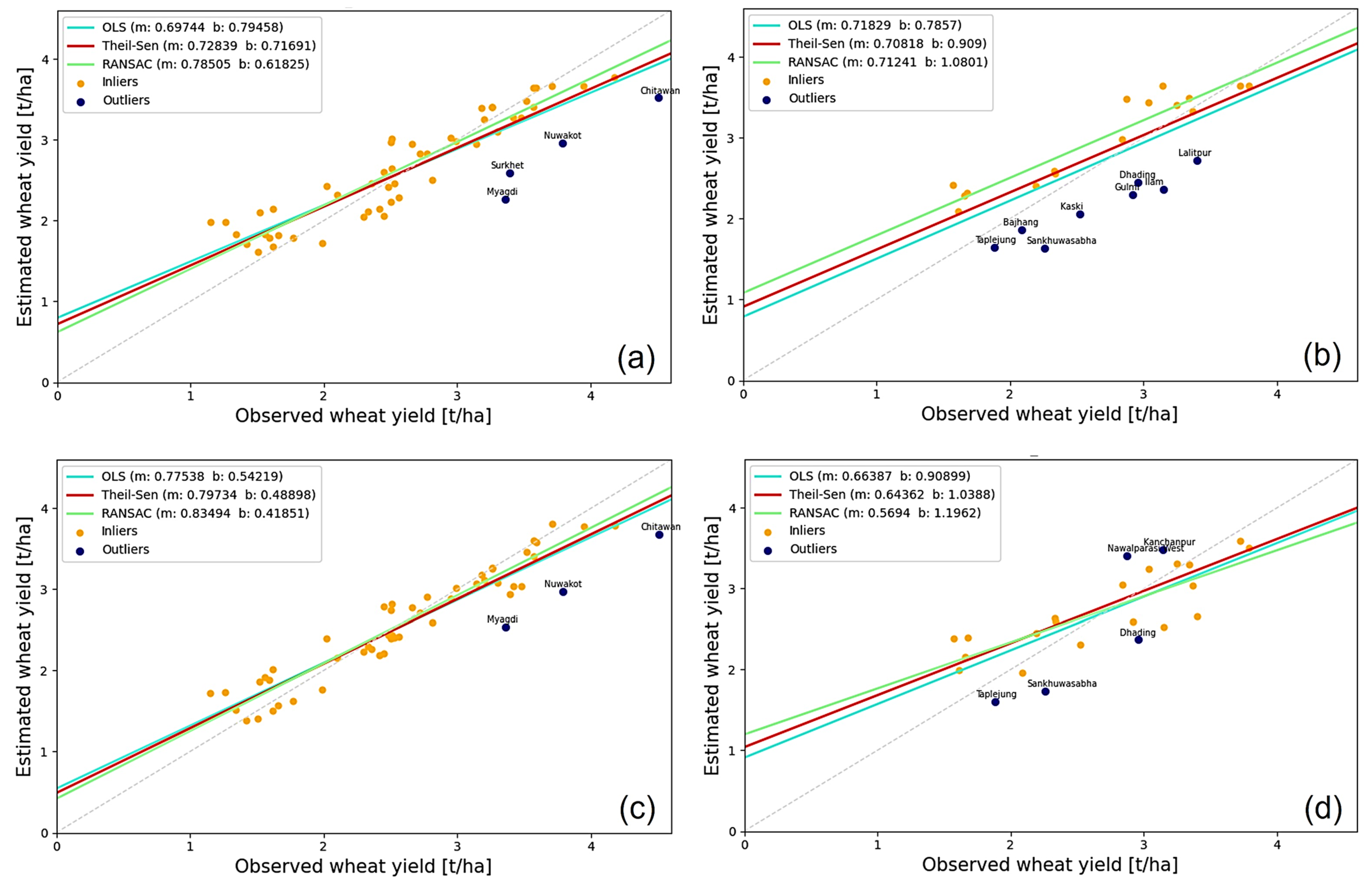
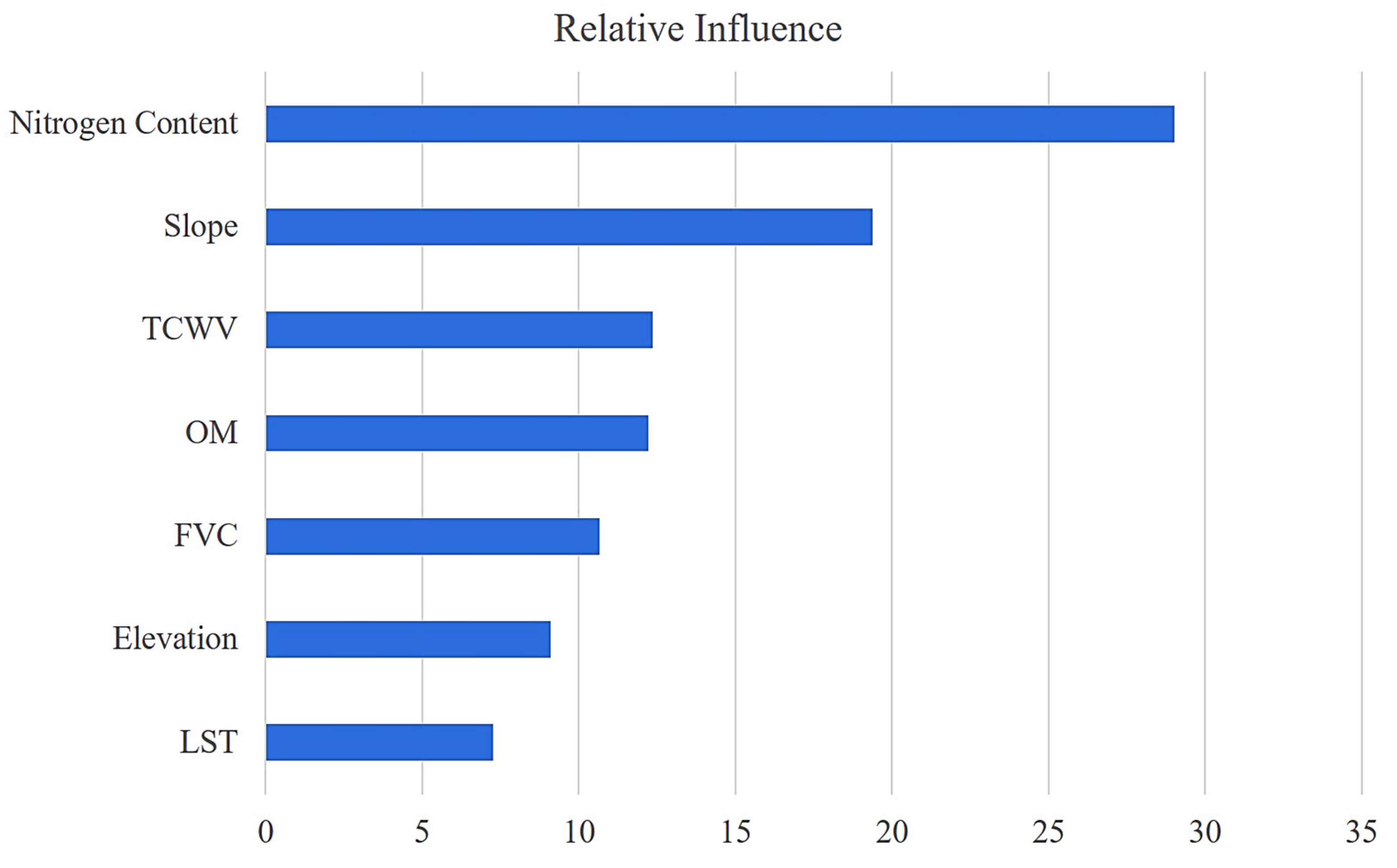
3.3. Accuracy Assessment and Influence of Features
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lobell, D.B.; Cassman, K.G.; Field, C.B. Crop yield gaps: Their importance, magnitudes, and causes. Annu. Rev. Environ. Resour. 2009, 34, 179–204. [Google Scholar] [CrossRef]
- Carletto, C.; Jolliffe, D.; Banerjee, R. From tragedy to renaissance: Improving agricultural data for better policies. J. Dev. Stud. 2015, 51, 133–148. [Google Scholar] [CrossRef]
- Dubey, S.; Dahiya, M.; Jain, S. Application of a distributed data center in logistics as cloud collaboration for handling disaster relief. In Proceedings of the IEEE 3rd International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), Bhimtal, India, 23–24 February 2018; pp. 1–11. [Google Scholar] [CrossRef]
- Mehdaoui, R.; Anane, M. Exploitation of the red-edge bands of Sentinel 2 to improve the estimation of durum wheat yield in Grombalia region (Northeastern Tunisia). Int. J. Remote Sens. 2020, 41, 8986–9008. [Google Scholar] [CrossRef]
- Adhikari, S.P.; Ghimire, Y.N.; Timsina, K.P.; Subedi, S.; Kharel, M. Technical efficiency of wheat growing farmers of Nepal. J. Agric. Nat. Resour. 2021, 4, 246–254. [Google Scholar] [CrossRef]
- Bognár, P.; Ferencz, C.; Pásztor, S.; Molnár, G.; Timár, G.; Hamar, D.; Lichtenberger, J.; Székely, B.; Steinbach, P.; Ferencz, O.E. Yield forecasting for wheat and corn in Hungary by satellite remote sensing. Int. J. Remote Sens. 2011, 32, 4759–4767. [Google Scholar] [CrossRef]
- Zhu, B.; Chen, S.; Cao, Y.; Xu, Z.; Yu, Y.; Han, C. A Regional Maize Yield Hierarchical Linear Model Combining Landsat 8 Vegetative Indices and Meteorological Data: Case Study in Jilin Province. Remote Sens. 2021, 13, 356. [Google Scholar] [CrossRef]
- Johnson, D.M.; Rosales, A.; Mueller, R.; Reynolds, C.; Frantz, R.; Anyamba, A.; Pak, E.; Tucker, C. USA Crop Yield Estimation with MODIS NDVI: Are Remotely Sensed Models Better than Simple Trend Analyses? Remote Sens. 2021, 13, 4227. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop Yield Prediction Using Deep Neural Networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef]
- Muruganantham, P.; Wibowo, S.; Grandhi, S.; Samrat, N.H.; Islam, N. A Systematic Literature Review on Crop Yield Prediction with Deep Learning and Remote Sensing. Remote Sens. 2022, 14, 1990. [Google Scholar] [CrossRef]
- Abdul-Jabbar, T.S.; Ziboon, A.T.; Albayati, M.M. Crop yield estimation using different remote sensing data: Literature review. IOP Conf. Ser. Earth Environ. Sci. 2023, 1129, 012004. [Google Scholar] [CrossRef]
- Ang, Y.; Shafri, H.Z.M.; Lee, Y.P.; Bakar, S.A.; Abidin, H.; Junaidi, M.U.U.M.; Samad, M.N.A. Oil Palm Yield Prediction Across Blocks Using Multi-Source Data and Machine Learning. Earth Sci. Inform. 2022, 15, 2349–2367. [Google Scholar] [CrossRef]
- Yli-Heikkilä, M.; Wittke, S.; Luotamo, M.; Puttonen, E.; Sulkava, M.; Pellikka, P.; Heiskanen, J.; Klami, A. Scalable Crop Yield Prediction with Sentinel-2 Time Series and Temporal Convolutional Network. Remote Sens. 2022, 14, 4193. [Google Scholar] [CrossRef]
- Saad El Imanni, H.; El Harti, A.; El Iysaouy, L. Wheat Yield Estimation Using Remote Sensing Indices Derived from Sentinel-2 Time Series and Google Earth Engine in a Highly Fragmented and Heterogeneous Agricultural Region. Agronomy 2022, 12, 2853. [Google Scholar] [CrossRef]
- Bognár, P.; Kern, A.; Pásztor, S.; Lichtenberger, J.; Koronczay, D.; Ferencz, C.S. Yield estimation and forecasting for winter wheat in Hungary using time series of MODIS data. Int. J. Remote Sens. 2017, 38, 3394–3414. [Google Scholar] [CrossRef]
- Hosseini, M.; Becker-Reshef, I.; Sahajpal, R.; Fontana, L.; Lafluf, P.; Leale, G.; Puricelli, E.; Varela, M.; Justice, C.J. Crop yield prediction using integration of polarimetric synthetic aperture radar and optical data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2020), Waikoloa, HI, USA, 26 September–2 October 2020; pp. 17–20. [Google Scholar] [CrossRef]
- Ouattara, B.; Forkuor, G.; Zoungrana, B.J.; Dimobe, K.; Danumah, J.; Saley, B.; Tondoh, J.E. Crops monitoring and yield estimation using sentinel products in semi-arid smallholder irrigation schemes. Int. J. Remote Sens. 2020, 41, 6527–6549. [Google Scholar] [CrossRef]
- Roznik, M.; Mishra, A.K.; Boyd, M.S. Using a Machine Learning Approach and Big Data to Augment WASDE Forecasts: Empirical Evidence from US Corn Yield. J. Forecast. 2023, 42, 1370–1384. [Google Scholar] [CrossRef]
- Bognár, P.; Kern, A.; Pásztor, S.; Steinbach, P.; Lichtenberger, J. Testing the Robust Yield Estimation Method for Winter Wheat, Corn, Rapeseed, and Sunflower with Different Vegetation Indices and Meteorological Data. Remote Sens. 2022, 14, 2860. [Google Scholar] [CrossRef]
- Srivastava, A.K.; Safaei, N.; Khaki, S.; Lopez, G.; Zeng, W.; Ewert, F.; Gaiser, T.; Rahimi, J. Winter wheat yield prediction using convolutional neural networks from environmental and phenological data. Sci. Rep. 2022, 12, 3215. [Google Scholar] [CrossRef]
- Cheng, E.; Zhang, B.; Peng, D.; Zhong, L.; Yu, L.; Liu, Y.; Xiao, C.; Li, C.; Li, X.; Chen, Y.; et al. Wheat yield estimation using remote sensing data based on machine learning approaches. Front. Plant Sci. 2022, 13, 1090970. [Google Scholar] [CrossRef]
- Ramos, A.P.; Osco, L.P.; Furuya, D.E.; Gonçalves, W.N.; Santana, D.C.; Teodoro, L.P.; Junior, C.A.; Capristo-Silva, G.F.; Li, J.; Baio, F.H.; et al. A random forest ranking approach to predict yield in maize with uav-based vegetation spectral indices. Comput. Electron. Agric. 2020, 178, 105791. [Google Scholar] [CrossRef]
- Joshi, A.; Pradhan, B.; Gite, S.; Chakraborty, S. Remote-Sensing Data and Deep-Learning Techniques in Crop Mapping and Yield Prediction: A Systematic Review. Remote Sens. 2023, 15, 2014. [Google Scholar] [CrossRef]
- Arumugam, P.; Chemura, A.; Schauberger, B.; Gornott, C. Remote Sensing Based Yield Estimation of Rice (Oryza sativa L.) Using Gradient Boosted Regression in India. Remote Sens. 2021, 13, 2379. [Google Scholar] [CrossRef]
- Pazhanivelan, S.; Geethalakshmi, V.; Tamilmounika, R.; Sudarmanian, N.S.; Kaliaperumal, R.; Ramalingam, K.; Sivamurugan, A.P.; Mrunalini, K.; Yadav, M.K.; Quicho, E.D. Spatial Rice Yield Estimation Using Multiple Linear Regression Analysis, Semi-Physical Approach and Assimilating SAR Satellite Derived Products with DSSAT Crop Simulation Model. Agronomy 2022, 12, 2008. [Google Scholar] [CrossRef]
- Ilyas, Q.M.; Ahmad, M.; Mehmood, A. Automated Estimation of Crop Yield Using Artificial Intelligence and Remote Sensing Technologies. Bioengineering 2023, 10, 125. [Google Scholar] [CrossRef]
- Al-Adhaileh, M.H.; Aldhyani, T.H.H. Artificial intelligence framework for modeling and predicting crop yield to enhance food security in Saudi Arabia. PeerJ. Comput. Sci. 2022, 8, e1104. [Google Scholar] [CrossRef] [PubMed]
- Wolanin, A.; Mateo-García, G.; Camps-Valls, G.; Gómez-Chova, L.; Meroni, M.; Duveiller, G.; Liangzhi, Y.; Guanter, L. Estimating and understanding crop yields with explainable deep learning in the Indian Wheat Belt. Environ. Res. Lett. 2020, 15, 024019. [Google Scholar] [CrossRef]
- Ferencz, C.; Bognár, P.; Lichtenberger, J.; Hamar, D.; Tarcsai, G.; Timár, G.; Molnár, G.; Pásztor, S.; Steinbach, P.; Székely, B.; et al. Crop yield estimation by satellite remote sensing. Int. J. Remote Sens. 2004, 25, 4113–4149. [Google Scholar] [CrossRef]
- Franch, B.; Bautista, A.S.; Fita, D.; Rubio, C.; Tarrazó-Serrano, D.; Sánchez, A.; Skakun, S.; Vermote, E.; Becker-Reshef, I.; Uris, A. Within-Field Rice Yield Estimation Based on Sentinel-2 Satellite Data. Remote Sens. 2021, 13, 4095. [Google Scholar] [CrossRef]
- Adebayo, A.D.; Sahbeni, G.; Donike, S. Integration of Sentinel-1 SAR and Sentinel-2 MSI time series DATA for crop yield prediction over agricultural areas in Kenya. In Proceedings of the AGIT2021 Conference, Salzburg, Austria, 5–9 July 2021. [Google Scholar] [CrossRef]
- Bojanowski, J.S.; Sikora, S.; Musiał, J.P.; Woźniak, E.; Dąbrowska-Zielińska, K.; Slesiński, P.; Milewski, T.; Łączyński, A. Integration of Sentinel-3 and MODIS Vegetation Indices with ERA-5 Agro-Meteorological Indicators for Operational Crop Yield Forecasting. Remote Sens. 2022, 14, 1238. [Google Scholar] [CrossRef]
- Chhetri, R.; Pandey, V.P.; Talchabhadel, R.; Thapa, B.R. How do CMIP6 models project changes in precipitation extremes over seasons and locations across the mid hills of Nepal? Theor. Appl. Climatol. 2021, 145, 1127–1144. [Google Scholar] [CrossRef]
- Sharma, S.; Khadka, N.; Hamal, K.; Baniya, B.; Luintel, N.; Joshi, B.B. Spatial and temporal analysis of precipitation and its extremities in seven provinces of Nepal (2001–2016). Appl. Ecol. Environ. Sci. 2020, 8, 64–73. [Google Scholar] [CrossRef]
- Upreti, B.N. An overview of the stratigraphy and tectonics of the Nepal Himalaya. J. Asian Earth Sci. 1999, 17, 577–606. [Google Scholar] [CrossRef]
- Bhattarai, T.N. Flood Events in Gangapur Village, Banke District: An Example of Climate Change-Induced Disaster in Nepal. J. Inst. Sci. Technol. 2014, 19, 79–85. [Google Scholar] [CrossRef]
- Peel, M.C.; Finlayson, B.L.; McMahon, T.A. Updated world map of the Köppen-Geiger climate classification. Hydrol. Earth Syst. Sci. 2007, 5, 1633–1644. [Google Scholar] [CrossRef]
- Dai, W.; Subedi, R.; Jin, K.; Hao, L. Spatiotemporal variation of potential evapotranspiration and meteorological drought based on multi-source data in Nepal. Nat. Hazards Res. 2023, 3, 271–279. [Google Scholar] [CrossRef]
- Karki, R.; Ul Hasson, S.; Gerlitz, L.; Talchabhadel, R.; Schickhoff, U.; Scholten, T.; Böhner, J. Rising mean and extreme near-surface air temperature across Nepal. Int. J. Climatol. 2020, 40, 2445–2463. [Google Scholar] [CrossRef]
- Ba, R.; Zech, W. Soils of the high mountain region of Eastern Nepal: Classification, distribution, and soil forming processes. Catena 1994, 22, 85–103. [Google Scholar] [CrossRef]
- Merz, J. Water Balances, Floods and Sediment Transport in the Hindu Kush-Himalayan Region; Geographical Bernensia. G72; Department of Geography, University of Bern, Bern and International Centre for Integrated Mountain Development: Kathmandu, Nepal, 2004. [Google Scholar] [CrossRef]
- Paudel, B.; Zhang, Y.L.; Li, S.C.; Liu, L.S.; Wu, X.; Khanal, N.R. Review of studies on land use and land cover change in Nepal. J. Mt. Sci. 2016, 13, 643–660. [Google Scholar] [CrossRef]
- Gairhe, S.; Shrestha, H.K.; Timsina, K. Dynamics of major cereals productivity in Nepal. J. Nepal Agric. Res. Counc. 2018, 4, 60–71. [Google Scholar] [CrossRef]
- The World Bank. Population, Total—Nepal. 2021. Available online: https://data.worldbank.org/indicator/SP.POP.TOTL?locations=NP (accessed on 30 March 2023).
- National Planning Commission. Sustainable Development Goals (Kathmandu, Nepal: Government of Nepal, National Planning Commission. 2017. Available online: https://www.npc.gov.np/images/category/SDGs_Report_Final.pdf (accessed on 30 March 2023).
- Joshi, K.D.; Conroy, C.; Witcombe, J.R. Agriculture, seed, and innovation in Nepal: Industry and policy issues for the future. Gates Open Res. 2019, 3, 232. [Google Scholar] [CrossRef]
- Ministry of Agriculture and Livestock Development, Government of Nepal. Statistical Information on Nepalese Agriculture—2020/21 (Report No. 2077/78). 2021. Available online: https://nepalindata.com/resource/STATISTICAL-INFORMATION-ON-NEPALESE-AGRICULTURE-2077-78--2020-21/ (accessed on 30 March 2023).
- ESA. User Guides. Available online: https://sentinels.copernicus.eu/web/sentinel/user-guides.2022 (accessed on 5 June 2023).
- Coppo, P.; Ricciarelli, B.; Brandani, F.; Delderfield, J.; Ferlet, M.; Mutlow, C.; Munro, G.; Nightingale, T.; Smith, D.; Bianchi, S.; et al. SLSTR: A high accuracy dual scan temperature radiometer for sea and land surface monitoring from space. J. Mod. Opt. 2010, 57, 1815–1830. [Google Scholar] [CrossRef]
- Musyimi, P.K.; Sahbeni, G.; Timár, G.; Weidinger, T.; Székely, B. Analysis of Short-Term Drought Episodes Using Sentinel-3 SLSTR Data under a Semi-Arid Climate in Lower Eastern Kenya. Remote Sens. 2023, 15, 3041. [Google Scholar] [CrossRef]
- Hu, X.; Ren, H.; Tansey, K.; Zheng, Y.; Ghent, D.; Liu, X.; Yan, L. Agricultural drought monitoring using European Space Agency Sentinel 3A land surface temperature and normalized difference vegetation index imageries. Agric. For. Meteorol. 2019, 279, 107707. [Google Scholar] [CrossRef]
- Musyimi, P.K.; Sahbeni, G.; Timár, G.; Weidinger, T.; Székely, B. Actual Evapotranspiration Estimation Using Sentinel-1 SAR and Sentinel-3 SLSTR Data Combined with a Gradient Boosting Machine Model in Busia County, Western Kenya. Atmosphere 2022, 13, 1927. [Google Scholar] [CrossRef]
- Xu, W.; Wooster, M.J. Sentinel-3 SLSTR active fire (AF) detection and FRP daytime product—Algorithm description and global intercomparison to MODIS, VIIRS and Landsat AF data. Sci. Remote Sens. 2023, 7, 100087. [Google Scholar] [CrossRef]
- Ojha, N.; Merlin, O.; Suere, C.; Escorihuela, M.J. Extending the Spatio-Temporal Applicability of DISPATCH Soil Moisture Downscaling Algorithm: A Study Case Using SMAP, MODIS and Sentinel-3 Data. Front. Environ. Sci. 2021, 9, 555216. [Google Scholar] [CrossRef]
- IPAD. Country Summary—Nepal Production. 2023. Available online: https://ipad.fas.usda.gov/countrysummary/default.aspx?id=NP (accessed on 15 April 2023).
- Sahbeni, G.; Székely, B.; Sahajpal, R. Characterization of different crop types using biophysical indicators derived from Sentinel-2 MSI multi-temporal data in Sudurpashchim Province, Western Nepal. In Proceedings of the EGU General Assembly 2023, Vienna, Austria, 24–28 April 2023. EGU23-3884. [Google Scholar] [CrossRef]
- NASA Shuttle Radar Topography Mission (SRTM). Shuttle Radar Topography Mission (SRTM) Global. Distributed by OpenTopography 2013. Available online: https://www.fdsn.org/networks/detail/GH/ (accessed on 5 June 2023).
- Open Topography. Three New Global Topographic Datasets Available (SRTM Ellipsoidal, ALOS World 3D, GMRT). 2017. Available online: https://opentopography.org/news/three-new-global-topographic-datasets-available-srtm-ellipsoidal-alos-world-3d-gmrt (accessed on 31 March 2023).
- Arino, O.; Gross, D.; Ranera, F.; Bourg, L.; Leroy, M.; Bicheron, P.; Latham, J.; Di Gregorio, A.; Brockmann, C.; Witt, R.; et al. GlobCover: ESA Service for Global Land Cover from MERIS. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 2412–2415, JRC49403. [Google Scholar] [CrossRef]
- ESA. Copernicus Sentinel-3 SLSTR Land User Handbook. 2023. Available online: https://sentinel.esa.int/documents/247904/4598082/Sentinel-3-SLSTR-Land-Handbook.pdf (accessed on 20 February 2023).
- Kganyago, M.; Mhangara, P.; Adjorlolo, C. Estimating Crop Biophysical Parameters Using Machine Learning Algorithms and Sentinel-2 Imagery. Remote Sens. 2021, 13, 4314. [Google Scholar] [CrossRef]
- Fan, J.; Ma, X.; Wu, L.; Zhang, F.; Yu, X.; Zeng, W. Light Gradient Boosting Machine: An efficient soft computing model for estimating daily reference evapotranspiration with local and external meteorological data. Agric. Water Manag. 2019, 225, 105758. [Google Scholar] [CrossRef]
- Wang, L.; Hu, P.; Zheng, H.; Liu, Y.; Cao, X.; Hellwich, O.; Liu, T.; Luo, G.; Bao, A.; Chen, X. Integrative modeling of heterogeneous soil salinity using sparse ground samples and remote sensing images. Geoderma 2023, 430, 116321. [Google Scholar] [CrossRef]
- He, Z.; Lin, D.; Lau, T.; Wu, M. Gradient Boosting Machine: A Survey. arXiv 2019, arXiv:1908.06951. [Google Scholar] [CrossRef]
- Aworka, R.; Cedric, L.S.; Adoni, W.Y.; Zoueu, J.T.; Mutombo, F.K.; Kimpolo, C.L.; Nahhal, T.; Krichen, M. Agricultural Decision System based on Advanced Machine Learning Models for Yield Prediction: Case of East African Countries. Smart Agric. Technol. 2022, 2, 100048. [Google Scholar] [CrossRef]
- Landry, M. Machine Learning with R and H2O; H2O. ai: Mountain View, CA, USA, 2016; Available online: http://h2o-release.s3.amazonaws.com/h2o/master/5118/docs-website/h2o-docs/booklets/RBooklet.pdf (accessed on 16 April 2023).
- Lu, H.; Karimireddy, S.P.; Ponomareva, N.; Mirrokni, V.S. Accelerating Gradient Boosting Machines. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS 2020), Palermo, Italy, 26–28 August 2020; Volume 108. Available online: http://proceedings.mlr.press/v108/lu20a/lu20a.pdf (accessed on 19 April 2023).
- Candido, C.G.; Blanco, A.C.; Medina, J.M.; Gubatanga, E.; Santos, A.; Ana, R.C.; Reyes, R.B. Improving the consistency of multi-temporal land cover mapping of Laguna Lake watershed using light gradient boosting machine (LightGBM) approach, change detection analysis, and Markov chain. Remote Sens. Appl. Soc. Environ. 2021, 23, 100565. [Google Scholar] [CrossRef]
- Khoi, D.N.; Quan, N.T.; Linh, D.Q.; Nhi, P.T.T.; Thuy, N.T.D. Using Machine Learning Models for Predicting the Water Quality Index in the La Buong River, Vietnam. Water 2022, 14, 1552. [Google Scholar] [CrossRef]
- Friedman, J. Greedy boosting approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Sarijaloo, F.B.; Porta, M.; Taslimi, B.; Pardalos, P.M. Yield performance estimation of corn hybrids using machine learning algorithms. Artif. Intell. Agric. 2021, 5, 82–89. [Google Scholar] [CrossRef]
- Park, J.; Lee, Y.; Lee, J. Assessment of Machine Learning Algorithms for Land Cover Classification Using Remotely Sensed Data. Sens. Mater. 2021, 33, 3885–3902. [Google Scholar] [CrossRef]
- Tarwidi, D.; Pudjaprasetya, S.R.; Adytia, D.; Apri, M. An optimized XGBoost-based machine learning method for predicting wave run-up on a sloping beach. MethodsX 2023, 10, 102119. [Google Scholar] [CrossRef]
- Zopluoglu, C. How Does Extreme Gradient Boosting (XGBoost) Work? 2019. Available online: https://github.com/czopluoglu/website/tree/master/docs/posts/extreme-gradient-boosting/ (accessed on 11 May 2023).
- Nalluri, M.; Pentela, M.; Eluri, N.R. A Scalable Tree Boosting System: XG Boost. Int. J. Res. Stud. Sci. Eng. Technol. 2020, 7, 36–51. [Google Scholar]
- Zhang, P.; Jia, Y.; Shang, Y. Research and application of XGBoost in imbalanced data. Int. J. Distrib. Sens. Netw. 2022, 18, 15501329221106935. [Google Scholar] [CrossRef]
- Guo, R.; Zhao, Z.; Wang, T.; Liu, G.; Zhao, J.; Gao, D. Degradation State Recognition of Piston Pump Based on ICEEMDAN and XGBoost. Appl. Sci. 2020, 10, 6593. [Google Scholar] [CrossRef]
- Ali, Y.A.; Awwad, E.M.; Al-Razgan, M.; Maarouf, A. Hyperparameter Search for Machine Learning Algorithms for Optimizing the Computational Complexity. Processes 2023, 11, 349. [Google Scholar] [CrossRef]
- Liashchynskyi, P.; Liashchynskyi, P. Grid search, random search, genetic algorithm: A big comparison for NAS. arXiv 2019, arXiv:1912.06059. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Larochelle, H.; Erhan, D.; Courville, A.; Bergstra, J.; Bengio, Y. An empirical evaluation of deep architectures on problem with many factors of variation. In Proceedings of the Twenty-Fourth International Conference on Machine Learning (ICML’07), Corvallis, OR, USA, 20–24 June 2007; pp. 473–480. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Boehmke, B.; Greenwell, B.M. Chapter 12. In Gradient Boosting, Hands-On Machine Learning with R, 1st ed.; Chapman and Hall, CRC: London, UK, 2019. [Google Scholar]
- Arif Ali, Z.; Abduljabbar, Z.H.; Taher, H.A.; Bibo Sallow, A.; Almufti, S.M. Exploring the Power of eXtreme Gradient Boosting Algorithm in Machine Learning: A Review. Acad. J. Nawroz Univ. 2023, 12, 320–334. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Pham, H.T.; Awange, J.; Kuhn, M.; Nguyen, B.V.; Bui, L.K. Enhancing Crop Yield Prediction Utilizing Machine Learning on Satellite-Based Vegetation Health Indices. Sensors 2022, 22, 719. [Google Scholar] [CrossRef]
- Ali, R.; Kuriqi, A.; Abubaker, S.; Kisi, O. Long-Term Trends and Seasonality Detection of the Observed Flow in Yangtze River Using Mann-Kendall and Sen’s Innovative Trend Method. Water 2019, 11, 1855. [Google Scholar] [CrossRef]
- Ferrara, R.M.; Trevisiol, P.; Acutis, M.; Rana, G.; Richter, G.M.; Baggaley, N. Topographic impacts on wheat yields under climate change: Two contrasted case studies in Europe. Theor. Appl. Climatol. 2010, 99, 53–65. [Google Scholar] [CrossRef]
- Heil, K.; Heinemann, P.; Schmidhalter, U. Modeling the Effects of Soil Variability, Topography, and Management on the Yield of Barley. Front. Environ. Sci. 2018, 6, 146. [Google Scholar] [CrossRef]
- Hsiao, J.; Swann, A.L.; Kim, S. Maize yield under a changing climate: The hidden role of vapor pressure deficit. Agric. For. Meteorol. 2018, 297, 107692. [Google Scholar] [CrossRef]
- King, A.E.; Ali, G.A.; Gillespie, A.W.; Wagner-Riddle, C. Soil Organic Matter as Catalyst of Crop Resource Capture. Front. Environ. Sci. 2020, 8, 50. [Google Scholar] [CrossRef]
- Oldfield, E.E.; Bradford, M.A.; Augarten, A.J.; Cooley, E.T.; Radatz, A.M.; Radatz, T.; Ruark, M.D. Positive associations of soil organic matter and crop yields across a regional network of working farms. Soil Sci. Soc. Am. J. 2021, 86, 384–397. [Google Scholar] [CrossRef]
- Vonk, W.J.; van Ittersum, M.K.; Reidsma, P.; Zavattaro, L.; Bechini, L.; Guzmán, G.; Pronk, A.; Spiegel, H.; Steinmann, H.H.; Ruysschaert, G.; et al. European survey shows poor association between soil organic matter and crop yields. Nutr. Cycl. Agroecosyst. 2020, 118, 325–334. [Google Scholar] [CrossRef]
- Wood, S.A.; Sokol, N.; Bell, C.W.; Bradford, M.A.; Naeem, S.; Wallenstein, M.D.; Palm, C.A. Opposing effects of different soil organic matter fractions on crop yields. Ecol. Appl. A Publ. Ecol. Soc. Am. 2016, 26, 2072–2085. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, S.; Li, X.; Geng, H.; Xie, Y.; He, Y. Estimating Maize Yield in the Black Soil Region of Northeast China Using Land Surface Data Assimilation: Integrating a Crop Model and Remote Sensing. Front. Plant Sci. 2022, 13, 915109. [Google Scholar] [CrossRef]
- Martin, A.J. Parry and others, Raising yield potential of wheat. II. Increasing photosynthetic capacity and efficiency. J. Exp. Bot. 2011, 62, 453–467. [Google Scholar] [CrossRef]
- Anas, M.; Liao, F.; Verma, K.K.; Sarwar, M.A.; Mahmood, A.; Chen, Z.L.; Li, Q.; Zeng, X.P.; Liu, Y.; Li, Y.R. Fate of nitrogen in agriculture and environment: Agronomic, eco-physiological and molecular approaches to improve nitrogen use efficiency. Biol. Res. 2020, 53, 47. [Google Scholar] [CrossRef]
- Boulelouah, N.; Berbache, M.R.; Bedjaoui, H.; Selama, N.; Rebouh, N.Y. Influence of Nitrogen Fertilizer Rate on Yield, Grain Quality and Nitrogen Use Efficiency of Durum Wheat (Triticum durum Desf) under Algerian Semiarid Conditions. Agriculture 2022, 12, 1937. [Google Scholar] [CrossRef]
- Sun, J.; Li, W.; Li, C.; Chang, W.; Zhang, S.; Zeng, Y.; Zeng, C.; Peng, M. Effect of Different Rates of Nitrogen Fertilization on Crop Yield, Soil Properties and Leaf Physiological Attributes in Banana Under Subtropical Regions of China. Front. Plant Sci. 2020, 11, 613760. [Google Scholar] [CrossRef]
- Belete, F.; Dechassa, N.; Molla, A.; Tana, T. Effect of nitrogen fertilizer rates on grain yield and nitrogen uptake and use efficiency of bread wheat (Triticum aestivum L.) varieties on the Vertisols of central highlands of Ethiopia. Agric. Food Secur. 2018, 7, 78. [Google Scholar] [CrossRef]
- Ma, G.; Liu, W.; Li, S.; Zhang, P.; Wang, C.; Lu, H.; Wang, L.; Xie, Y.; Ma, D.; Kang, G. Determining the Optimal N Input to Improve Grain Yield and Quality in Winter Wheat with Reduced Apparent N Loss in the North China Plain. Front. Plant Sci. 2019, 10, 181. [Google Scholar] [CrossRef] [PubMed]
- Luitel, D.R.; Jha, P.K.; Siwakoti, M.; Shrestha, M.L.; Munniappan, R. Climatic Trends in Different Bioclimatic Zones in the Chitwan Annapurna Landscape, Nepal. Climate 2020, 8, 136. [Google Scholar] [CrossRef]
- Dawadi, B.; Shrestha, A.; Acharya, R.; Dhital, Y.P.; Devkota, R. Impact of climate change on agricultural production: A case of Rasuwa District, Nepal. Reg. Sustain. 2022, 3, 122–132. [Google Scholar] [CrossRef]
- Acevedo, E.; Silva, P.; Silva, H. Wheat growth and physiology. In FAO Corporate Repository; FAO: Rome, Italy, 2009; pp. 1–24. [Google Scholar]
- Kern, A.; Barcza, Z.; Marjanović, H.; Árendás, T.; Fodor, N.; Bónis, P.; Bognár, P.; Lichtenberger, J. Statistical modelling of crop yield in Central Europe using climate data and remote sensing vegetation indices. Agric. For. Meteorol. 2018, 260, 300–320. [Google Scholar] [CrossRef]
- Musa, A.I.; Tsubo, M.; Ali-Babiker, I.E.A.; Iizumi, T.; Kurosaki, Y.; Ibaraki, Y.; El-Hag, F.M.; Tahir, I.S.; Tsujimoto, H. Relationship of irrigated wheat yield with temperature in hot environments of Sudan. Theor. Appl. Climatol. 2021, 145, 1113–1125. [Google Scholar] [CrossRef]
- Cabrera-Bosquet, L.; Molero, G.; Stellacci, A.; Bort, J.; Nogués, S.; Araus, J. NDVI as a potential tool for predicting biomass, plant nitrogen content and growth in wheat genotypes subjected to different water and nitrogen conditions. Cereal Res. Commun. 2011, 39, 147–159. [Google Scholar] [CrossRef]
- Panek, E.; Gozdowski, D. Analysis of relationship between cereal yield and NDVI for selected regions of Central Europe based on MODIS satellite data. Remote Sens. Appl. Soc. Environ. 2020, 17, 100286. [Google Scholar] [CrossRef]
- Roznik, M.; Boyd, M.; Porth, L. Improving crop yield estimation by applying higher resolution satellite NDVI imagery and high-resolution cropland masks. Remote Sens. Appl. Soc. Environ. 2022, 25, 100693. [Google Scholar] [CrossRef]
- Barrow, N.J.; Hartemink, A.E. The effects of pH on nutrient availability depend on both soils and plants. Plant Soil 2023, 487, 21–37. [Google Scholar] [CrossRef]
- Chen, J.; Manevski, K.; Lærke, P.E.; Jørgensen, U. Biomass yield, yield stability and soil carbon and nitrogen content under cropping systems destined for biorefineries. Soil Tillage Res. 2022, 221, 105397. [Google Scholar] [CrossRef]
- McLachlan, B.A.; van Kooten, G.C.; Zheng, Z. Country-level climate-crop yield relationships and the impacts of climate change on food security. SN Appl. Sci. 2020, 2, 1650. [Google Scholar] [CrossRef]
- Mariadass, D.A.L.; Moung, E.G.; Sufian, M.M.; Farzamnia, A. EXtreme gradient boosting (XGBoost) regressor and shapley additive explanation for crop yield prediction in agriculture. In Proceedings of the 12th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 17–18 November 2022; pp. 219–224. [Google Scholar] [CrossRef]
- Kulpanich, N.; Worachairungreung, M.; Thanakunwutthirot, K.; Chaiboonrueang, P. The Application of Unmanned Aerial Vehicles (UAVs) and Extreme Gradient Boosting (XGBoost) to Crop Yield Estimation: A Case Study of Don Tum District, Nakhon Pathom, Thailand. Int. J. Geoinformat. 2023, 19, 65–77. [Google Scholar] [CrossRef]
- Noorunnahar, M.; Chowdhury, A.H.; Mila, F.A. A tree based eXtreme Gradient Boosting (XGBoost) machine learning model to forecast the annual rice production in Bangladesh. PLoS ONE 2023, 18, e0283452. [Google Scholar] [CrossRef] [PubMed]
- Huber, F.; Yushchenko, A.; Stratmann, B.; Steinhage, V. Extreme Gradient Boosting for Yield Estimation compared with Deep Learning Approaches. Comput. Electron. Agric. 2022, 202, 107346. [Google Scholar] [CrossRef]
- Oikonomidis, A.; Catal, C.; Kassahun, A. Hybrid deep learning-based models for crop yield prediction. Appl. Artif. Intell. 2022, 36, 2031822. [Google Scholar] [CrossRef]
- Khan, R.; Mishra, P.; Baranidharan, B. Crop Yield Prediction using Gradient Boosting Regression. Int. J. Innov. Technol. Explor. Eng. 2020, 9, 2293. [Google Scholar] [CrossRef]
- Ahmed, S. A Software Framework for Predicting the Maize Yield Using Modified Multi-Layer Perceptron. Sustainability 2023, 15, 3017. [Google Scholar] [CrossRef]
- Wilhelm, F. Theil-Sen Regression: Python Code Computing a Theil-Sen Regression on a Synthetic Dataset. Available online: https://scikit-learn.org/stable/auto_examples/linear_model/plot_theilsen.html (accessed on 2 December 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Theil, H. A rank-invariant method of linear and polynomial regression analysis. In Henri Theil’s Contributions to Economics and Econometrics; Springer Science and Business Media LLC: Dordrecht, The Netherlands, 1992; Volume 53, pp. 345–381. [Google Scholar] [CrossRef]
- Sen, P.K. Estimates of the regression coefficient based on Kendall’s Tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Paradigm for Model Consensus: Applications to Image Fitting with Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Vörös, F.; van Wyk de Vries, B.; Karátson, D.; Székely, B. DTM-Based Morphometric Analysis of Scoria Cones of the Chaîne des Puys (France)—The Classic and a New Approach. Remote Sens. 2021, 13, 1983. [Google Scholar] [CrossRef]
- Karki, R.; Talchabhadel, R.; Aalto, J.; Baidya, S.K. New climatic classification of Nepal. Theor. Appl. Climatol. 2016, 125, 799–808. [Google Scholar] [CrossRef]
- Paudel, B.; Zhang, Y.; Li, S.; Liu, L. Spatiotemporal changes in agricultural land cover in Nepal over the last 100 years. J. Geogr. Sci. 2018, 28, 1519–1537. [Google Scholar] [CrossRef]
- Molnar, C. “Permutation Feature Importance”. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable (2nd ed.). 2022. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 15 June 2023).
- Karimli, N.; Selbeso Glu, M.O. Remote Sensing-Based Yield Estimation of Winter Wheat Using Vegetation and Soil Indices in Jalilabad, Azerbaijan. ISPRS Int. J. Geo-Inf. 2023, 12, 124. [Google Scholar] [CrossRef]
- Ben-Asher, J.; Garcia, Y.; Garcia, A.; Flitcroft, I.; Hoogenboom, G. Effect of atmospheric water vapor on photosynthesis, transpiration, and canopy conductance: A case study in corn. Plant Soil Environ. 2013, 59, 549–555. [Google Scholar] [CrossRef]
- Lal, R. Soil organic matter content and crop yield. J. Soil Water Conserv. 2020, 75, 27A–32A. [Google Scholar] [CrossRef]
- Huzsvai, L.; Zsembeli, J.; Kovács, E.; Juhász, C. Response of Winter Wheat (Triticum aestivum L.) Yield to the Increasing Weather Fluctuations in a Continental Region of Four-Season Climate. Agronomy 2022, 12, 314. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| LST (°C) | Measurement of surface temperature inland |
| TCWV (kg/m2) | Quantification of the total water vapor in the atmosphere |
| NDVI | Indicator of vegetation density and health |
| FVC | Estimation of the proportion of land covered by vegetation |
| OM (%) | Percentage of organic matter in the soil |
| pH | Measurement of the acidity or alkalinity of the soil |
| Total nitrogen content (%) | Proportion of nitrogen content in the soil |
| Elevation (m) | Altitude above sea level at a specific location |
| Slope (degrees) | Inclination or gradient of the land surface |
| Hyperparameter | Objective | Value |
|---|---|---|
| nrounds or n_estimators | Determines the number of boosting rounds, allowing for a substantial ensemble of trees. | 100 |
| max_depth | Controls the maximum depth of each tree, enabling the model to capture complex interactions between features without excessive depth. | 3 |
| Learning rate eta | Selected to balance the contribution of each tree to the final prediction and facilitate convergence during the gradient descent process. | 0.1 |
| gamma | Imposes a minimum loss reduction threshold for further splits in the tree structure, promoting regularization and mitigating overfitting. | 0.01 |
| colsample_bytree | Randomly samples a fraction of features at each tree construction, introducing diversity and reducing overfitting. | 0.3 |
| min_child_weight | Determines the minimum sum of instance weights required to create a new child node in the tree. | 1 |
| subsample | Randomly selects a fraction of training instances to train each tree to reduce overfitting. | 0.3 |
| Minimum | 1st Qu. | Median | Mean | 3rd Qu. | Maximum | Skewness |
|---|---|---|---|---|---|---|
| 1.15 | 2.09 | 2.56 | 2.65 | 3.26 | 4.51 | −0.009 |
| Model | Training | Testing | ||
|---|---|---|---|---|
| R2 | RMSE (t/ha) | R2 | RMSE (t/ha) | |
| GBM | 0.79 | 0.38 | 0.56 | 0.47 |
| XGBoost | 0.89 | 0.30 | 0.61 | 0.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sahbeni, G.; Székely, B.; Musyimi, P.K.; Timár, G.; Sahajpal, R. Crop Yield Estimation Using Sentinel-3 SLSTR, Soil Data, and Topographic Features Combined with Machine Learning Modeling: A Case Study of Nepal. AgriEngineering 2023, 5, 1766-1788. https://doi.org/10.3390/agriengineering5040109
Sahbeni G, Székely B, Musyimi PK, Timár G, Sahajpal R. Crop Yield Estimation Using Sentinel-3 SLSTR, Soil Data, and Topographic Features Combined with Machine Learning Modeling: A Case Study of Nepal. AgriEngineering. 2023; 5(4):1766-1788. https://doi.org/10.3390/agriengineering5040109
Chicago/Turabian StyleSahbeni, Ghada, Balázs Székely, Peter K. Musyimi, Gábor Timár, and Ritvik Sahajpal. 2023. "Crop Yield Estimation Using Sentinel-3 SLSTR, Soil Data, and Topographic Features Combined with Machine Learning Modeling: A Case Study of Nepal" AgriEngineering 5, no. 4: 1766-1788. https://doi.org/10.3390/agriengineering5040109
APA StyleSahbeni, G., Székely, B., Musyimi, P. K., Timár, G., & Sahajpal, R. (2023). Crop Yield Estimation Using Sentinel-3 SLSTR, Soil Data, and Topographic Features Combined with Machine Learning Modeling: A Case Study of Nepal. AgriEngineering, 5(4), 1766-1788. https://doi.org/10.3390/agriengineering5040109