
SMARTEN—A Sample-Based Approach towards Privacy-Friendly Data Refinement

 ,
,  , ,
, ,  and
and
Abstract
:
1. Introduction
- (1)
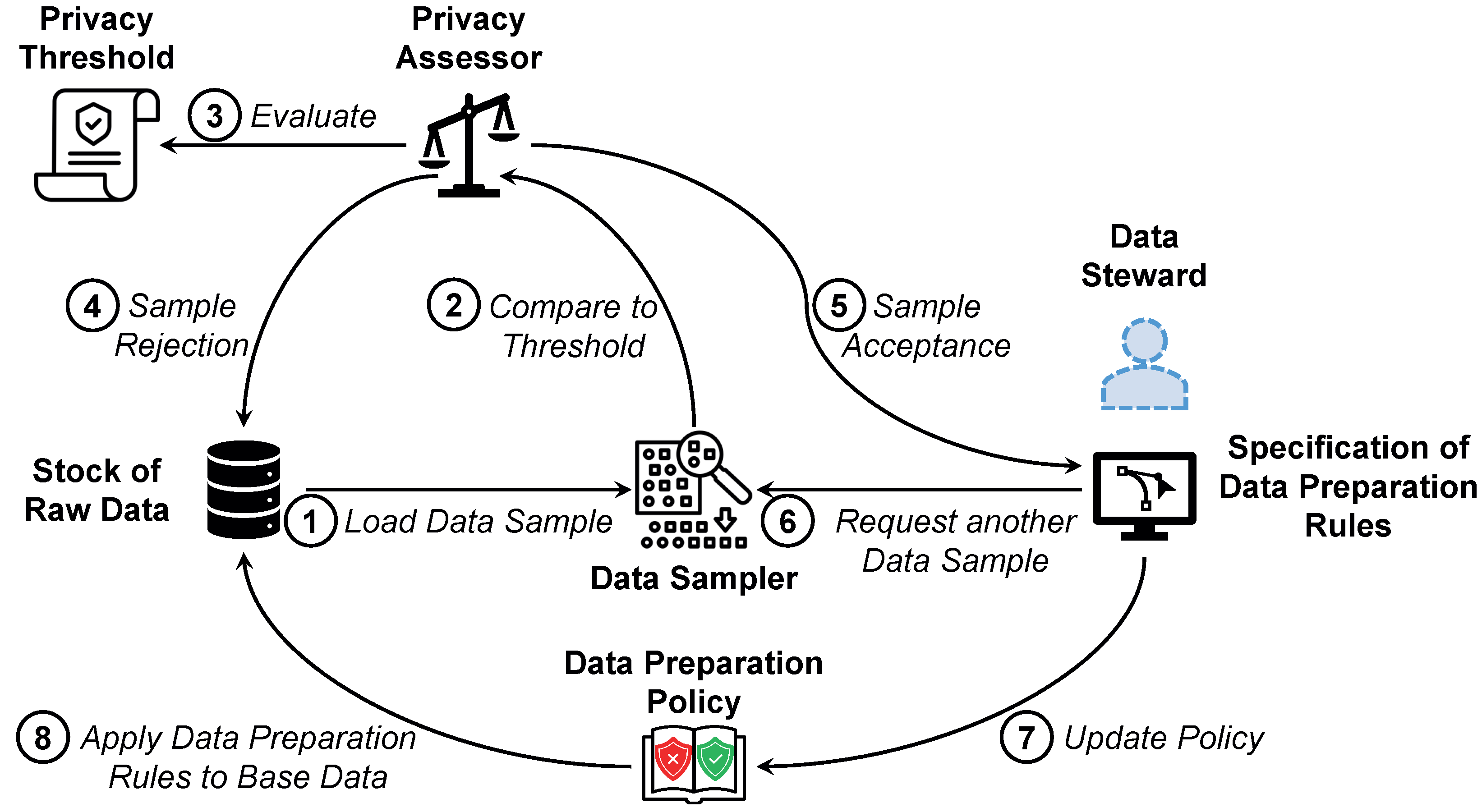
- We adapt the data preparation phase of the data refinement process. Data processors are not granted access to the full data stock, but rather to representative samples that comply with the privacy requirements. They then define data wrangling activities on these samples. These definitions are generalized as data pre-processing rules and applied to the entire data stock.
- (2)
- We adapt the data processing phase of the data refinement process. By means of privacy filters, different versions of the pre-processed data are generated. According to the privacy requirements, a specific version is used for the analysis, and the resulting insights are provided to the data consumers (e.g., smart services). As a result, each use case can be provided with the required knowledge without exposing any sensitive information.
- (3)
- We enable data owners to annotate their data with privacy requirements by means of digital signatures. These privacy requirements define how profoundly a data processor and a data consumer can inspect the data. Analogous with the data refinement process, the privacy requirements are also structured in two parts to determine in which manner access to the data are granted during pre-processing and what insights can be gained during the analysis.
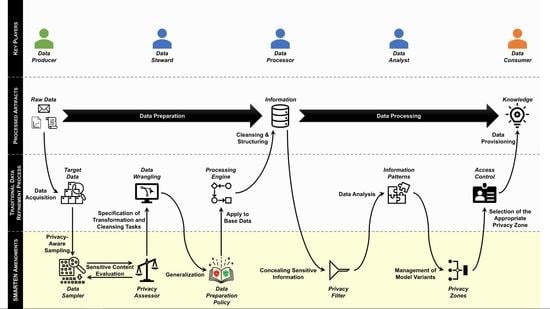
2. Data Refinement Process
- Data Preparation Phase. This part of the data refinement process deals with data wrangling. That is, a data steward selects a set of base data from the available raw data that is worth further investigation. These target data must then be cleansed, since raw data always have quality issues. For instance, missing values have to be filled in, wrong values have to be corrected, redundant data have to be removed and imbalances in the datasets have to be corrected. The cleansed data must then be converted into a uniform structure that can be processed. A data steward needs deep insight into individual datasets in order to identify the quality issues within the base data [30].
- Data Processing Phase. Based on the compiled information, a data analyst can recognize contained information patterns. Applied to the right situation, these patterns represent knowledge. Such patterns are supposed to answer questions such as “What happened?” (descriptive), “Why did it happen?” (diagnostic), “What will happen?” (predictive), and “What should I do?” (prescriptive). Thus, the base data are reflected in this knowledge only in a highly aggregated and condensed form. Therefore, a data analyst does not need an insight into individual datasets to accomplish his or her task. However, the derived knowledge reveals much more insight than a single set of raw data [31].
3. Related Work
- Withhold Data. One of the most effective ways to protect sensitive information is to avoid sharing them with third parties and not let such data be processed at all. In practice, for instance, this would mean that access to certain sensors on an IoT device—and therefore their data as well—would be completely blocked [40]. As a result, the information captured by the sensor in question is no longer available for analysis. This, however, has a significant impact on data quality and the knowledge that can be derived from them. To mitigate this to some degree, the withholding of data can be bound to certain constraints. For instance, certain time slots or locations can be defined where the disclosure of the collected data are acceptable for the data subject [41]. Likewise, only those data items that contain particularly compromising information can be withheld, e.g., if the captured values are above or below a defined threshold [42]. From a technical point of view, this approach corresponds to the application of a selection operator adopted from relational algebra. That is, all tuples that do not satisfy a specified predicate are removed from the corresponding relation, i.e., a selection represents a horizontal withholding of data [43].
- Filter Data. However, withholding data represents a sledgehammer approach that severely impairs data quality and quantity. Filtering techniques take a more sophisticated approach. Here, only sensitive information is filtered out of the data. To this end, there are two opposing approaches: either the data are condensed, or they are enriched with synthetic data.
- Hide in the Masses. While the technical measures to conceal sensitive information described above primarily targeted data from individual users, the protection of such data can also be seen as a community task. If many individuals are willing to expose their data to a certain risk of disclosure, sensitive information can also be hidden in the masses of data. This principle can be explained very simply by means of an example: When General Crassus tried to arrest Spartacus, many followers of Spartacus claimed to be him. This way, the real Spartacus blurred with the masses and could no longer be identified as an individual. The more people thereby expose themselves to the danger of being arrested, the lower is the actual danger for each individual [60]. This fundamental idea also applies to the protection of confidential data. Often, the data themselves are not particularly sensitive as long as they cannot be linked to a data subject. Thus, instead of tampering with the data and thus degrading the quality of the data, it is often sufficient to pool the data of many individuals, so that a single record cannot be uniquely linked to any of them. It is only possible to tell that they belong to one of the k individuals that participate. In this way, it is possible to perform better analyses on the data than it would have been possible if arbitrarily filters are applied to the data of each individual [61].
- Synopsis. When looking at the related work, only the horizontal and vertical withholding of data can be applied to arbitrary raw data. However, in the context of data refinement, these measures are often too restrictive in terms of reducing not only the amount of sensitive information contained in the data but also the quality of data and thus their value. The dedicated filtering techniques can operate at a much higher level of granularity and thus better preserve data quality. To this end, however, the data must be available in the appropriate form and are afterwards only usable for their intended purpose. These measures could be applied directly at the data source’s side. However, studies show that the effectiveness of such dedicated filtering techniques is higher when they are applied at the data processor’s side, where a complete overview of all existing data are available [66]. Since data processors in the service domain are commonly assumed to be semi-honest-but-curious, i.e., they will not expose any sensitive information about a user deliberately, it is reasonable to entrust them with the task of data protection [67].
4. SMARTEN
4.1. Data Preparation Phase
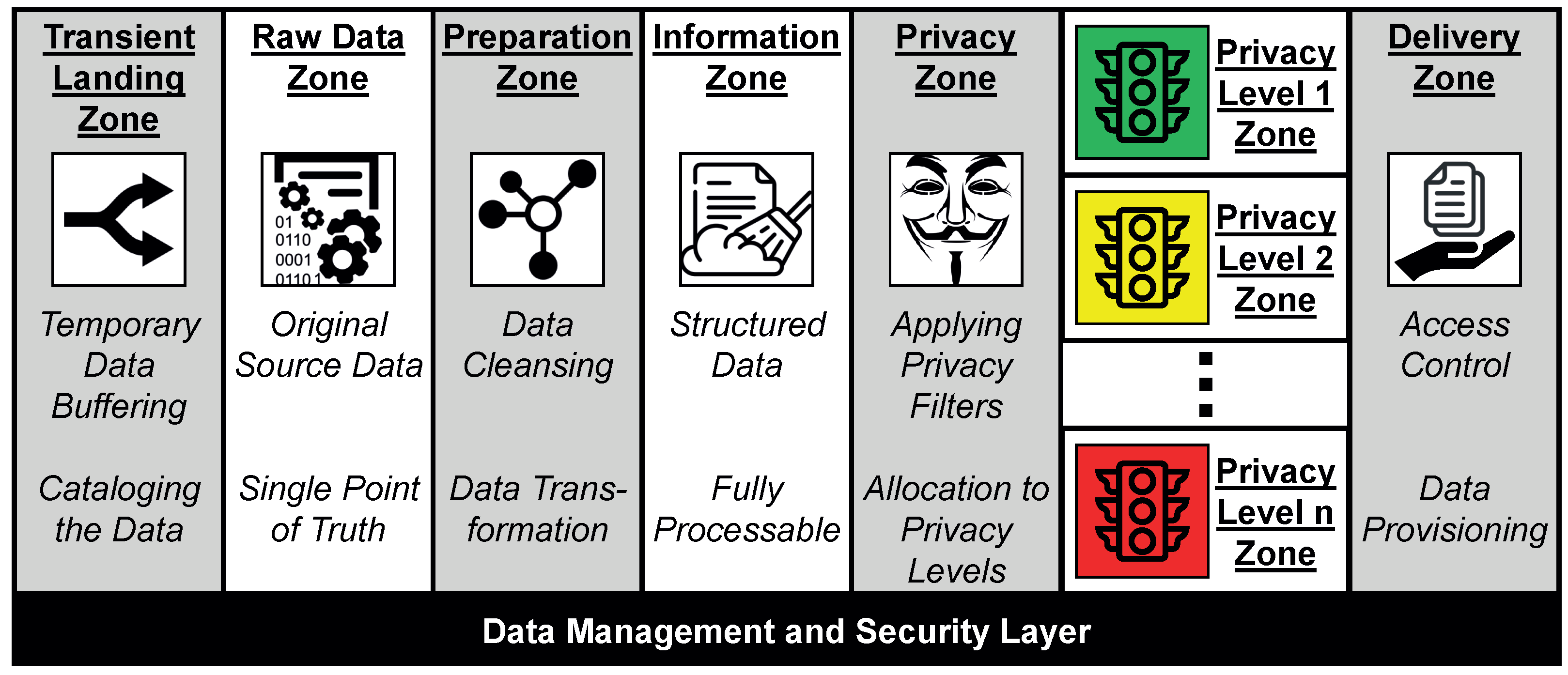
4.2. Data Processing Phase
4.3. Elicitation of Non-Disclosure Requirements
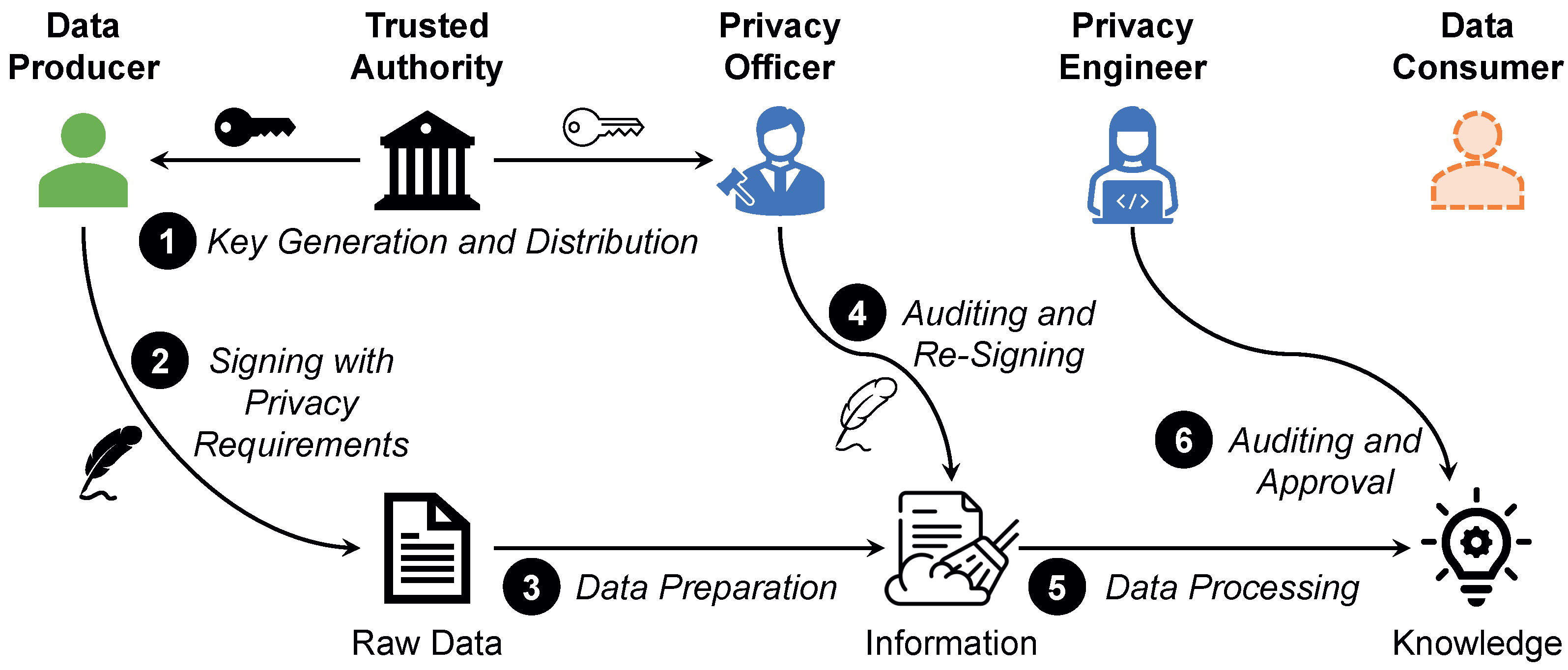
- Key Generation and Deployment. Initially, a data producer announces his or her non-disclosure requirements to a trusted authority. When dealing with sensitive data, regulations such as the GDPR mandate that there has to be an independent supervisory authority (Art. 51 and Art. 52). This can, for instance, serve as the trusted authority. ➊ This authority then generates two key pairs for the signature. Let be the set of privacy thresholds and be the set of requested privacy levels for the knowledge gained from processing the data. Then, full keys (depicted in black) reflect the union of these two sets , while delegated keys (depicted in white) reflect only , i.e., a true subset of . The full keys are provided to the data producer, while the delegated keys are provided to the data processor.
- Full Authentication. ➋ To ensure that the data are not tampered with and that the non-disclosure requirements are not lost during transmission, the data producer signs the raw data with his or her full key. ➌ In the data preparation phase, the data processor verifies the signature against his or her privacy policy . This policy describes which privacy thresholds are applied by the privacy assessor. Only if the requirements in are satisfied by is the applied privacy policy valid and the raw data in question can be preprocessed. ➍ This is monitored on behalf of the data processors by their privacy officer. A privacy officer requires no technical knowledge, as the privacy thresholds sufficiently specify how the data may be processed. If the data preparation is executed in compliance with the non-disclosure requirements, the privacy officer re-signs the data with the delegated key, i.e., is removed from the signature. In the data processing phase, the thresholds contained in are no longer relevant. However, non-disclosure requirements might indicate what a data producer wants to conceal. Thus, this filtering is necessary due to data minimization [92].
- Delegated Authentication. ➎ The re-signing initiates the data processing phase. In this phase, the data processor verifies the modified signature against his or her privacy policy . This policy describes the privacy measures for which privacy scripts are available in the Privacy Zone. Only if the scripts comply with the requirements described in the signature can the prepared data be further processed. ➏ However, as such an auditing is by no means trivial, it has to be handled by a privacy engineer. A privacy engineer represents an intermediary between legal experts and IT experts. He or she is able to evaluate the means by which the non-disclosure requirements of the data producers can be met without rendering the quality of the processing results useless. Only if the privacy engineer approves the applied measures is the gained knowledge offered in the respective Privacy Level x Zone to data consumers. Since a semi-honest-but-curious data processor can be assumed, this approach is a reliable way to enforce the non-disclosure requirements of the data producers.
5. Evaluation
5.1. Feature Assessment
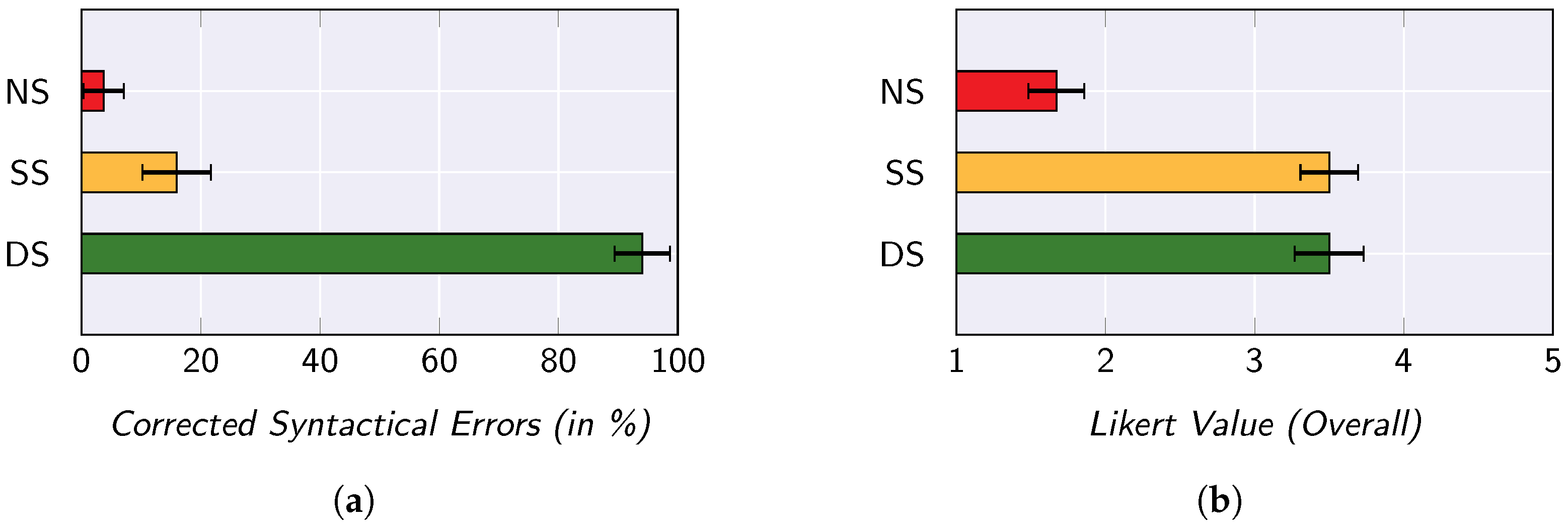
5.2. User Study
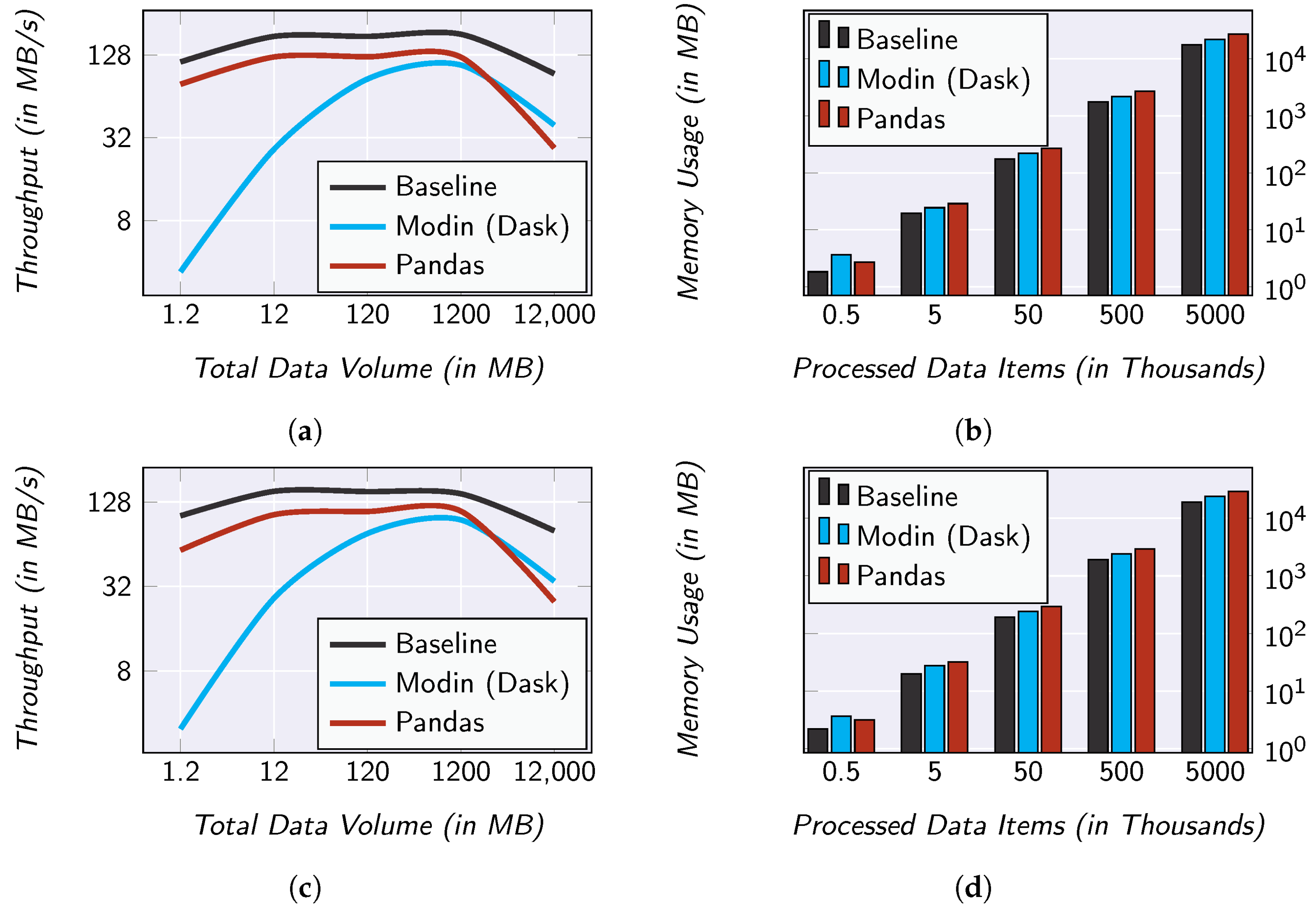
5.3. Performance Measurement
5.4. Lessons Learned
6. Conclusions
- By adapting the data preparation phase of the data refinement process, data stewards only obtain access to a representative sample of the data. The samples are compiled in such a way that they comply with given privacy constraints. A data steward operates on the sample, and these data wrangling activities can be transferred to pre-processing rules, which are then applied to the entire data stock. This way, data can be transformed into processable information without providing too many insights.
- By adapting the data processing phase of the data refinement process, different privacy filters can be applied to the acquired information before it is analyzed in order to derive knowledge. The privacy filters are designed for each type of data in such a way that specific aspects of the data can be concealed without impairing the quality of the data significantly and thus rendering smart services inoperable in the process.
- Using two-tier annotations, data owners can specify their privacy requirements. The outer tier specifies which requirements must be met in the data preparation phase while the inner layer describes which privacy measures have to be applied in the data processing phase. In SMARTEN, these annotations are realized as digital signatures that can be attached directly to the source data and thus inseparably tied to them.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANOVA | analysis of variance |
| API | application programming interface |
| CRISP-DM | cross-industry standard process for data mining |
| DB | database |
| DIK | data, information, knowledge |
| DS | dynamic sampling |
| eHealth | electronic health |
| GB | gigabyte |
| GDPR | general data protection regulation |
| GPS | global positioning system |
| IoT | internet of things |
| IT | information technology |
| KDD | knowledge discovery in databases |
| MB | megabyte |
| NS | no sampling |
| SEMMA | sample, explore, modify, model, and assess |
| SMARTEN | sample-based approach towards privacy-friendly data refinement |
| SQL | structured query language |
| SS | static sampling |
| STPA-Priv | system theoretic process analysis for Privacy |
References
- Schwab, K.; Marcus, A.; Oyola, J.R.; Hoffman, W.; Luzi, M. Personal Data: The Emergence of a New Asset Class; World Economic Forum: Geneva, Switzerland, 2011. [Google Scholar]
- Toonders, J. Data is the New Oil of the Digital Economy. In WIRED; Condé Nast: New York, NY, USA, 2014. [Google Scholar]
- Quigley, E.; Holme, I.; Doyle, D.M.; Ho, A.K.; Ambrose, E.; Kirkwood, K.; Doyle, G. “Data is the new oil”: Citizen science and informed consent in an era of researchers handling of an economically valuable resource. Life Sci. Soc. Policy 2021, 17, 9. [Google Scholar] [CrossRef] [PubMed]
- Jesse, N. Data Strategy and Data Trust–Drivers for Business Development. IFAC Pap. 2021, 54, 8–12. [Google Scholar] [CrossRef]
- Bibri, S.E.; Krogstie, J. A Novel Model for Data-Driven Smart Sustainable Cities of the Future: A Strategic Roadmap to Transformational Change in the Era of Big Data. Future Cities Environ. 2021, 7, 3. [Google Scholar] [CrossRef]
- Hallur, G.G.; Prabhu, S.; Aslekar, A. Entertainment in Era of AI, Big Data & IoT. In Digital Entertainment: The Next Evolution in Service Sector; Das, S., Gochhait, S., Eds.; Springer: Singapore, 2021; pp. 87–109. [Google Scholar]
- Jossen, S. The World’s Most Valuable Resource Is No Longer Oil, But Data. Economist, 6 May 2017. [Google Scholar]
- Bello, O.; Zeadally, S. Toward efficient smartification of the Internet of Things (IoT) services. Future Gener. Comput. Syst. 2019, 92, 663–673. [Google Scholar] [CrossRef]
- Bhageshpur, K. Data is the New Oil—And That’s a Good Thing; Forbes Technololy Council: Boston, MA, USA, 2019. [Google Scholar]
- Taffel, S. Data and oil: Metaphor, materiality and metabolic rifts. New Media Soc. (OnlineFirst) 2021, 14614448211017887. [Google Scholar] [CrossRef]
- Liew, A. Understanding Data, Information, Knowledge And Their Inter-Relationships. J. Knowl. Manag. Pract. 2007, 8, 1–10. [Google Scholar]
- Rowley, J. The wisdom hierarchy: Representations of the DIKW hierarchy. J. Inf. Sci. 2007, 33, 163–180. [Google Scholar] [CrossRef]
- Hashemi, S.H.; Faghri, F.; Rausch, P.; Campbell, R.H. World of Empowered IoT Users. In Proceedings of the 2016 IEEE First International Conference on Internet-of-Things Design and Implementation (IoTDI), Berlin, Germany, 4–8 April 2016; IEEE: Manhattan, NY, USA, 2016; pp. 13–24. [Google Scholar]
- Van Meter, H.J. Revising the DIKW Pyramid and the Real Relationship between Data, Information, Knowledge and Wisdom. Law Technol. Hum. 2020, 2, 69–80. [Google Scholar] [CrossRef]
- Alasadi, S.A.; Bhaya, W.S. Review of Data Preprocessing Techniques in Data Mining. J. Eng. Appl. Sci. 2017, 12, 4102–4107. [Google Scholar]
- Elgendy, N.; Elragal, A. Big Data Analytics: A Literature Review Paper. In Proceedings of the 14th Industrial Conference on Data Mining (ICDM), St. Petersburg, Russia, 16–20 July 2014; Springer: Cham, Switzerland, 2014; pp. 214–227. [Google Scholar]
- Maletic, J.I.; Marcus, A. Data Cleansing: A Prelude to Knowledge Discovery. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2010; pp. 19–32. [Google Scholar]
- Tawalbeh, L.; Muheidat, F.; Tawalbeh, M.; Quwaider, M. IoT Privacy and Security: Challenges and Solutions. Appl. Sci. 2020, 10, 4102. [Google Scholar] [CrossRef]
- Ali, M.U.; Mishra, B.K.; Thakker, D.; Mazumdar, S.; Simpson, S. Using Citizen Science to Complement IoT Data Collection: A Survey of Motivational and Engagement Factors in Technology-Centric Citizen Science Projects. IoT 2021, 2, 275–309. [Google Scholar] [CrossRef]
- Lagoze, C.; Block, W.C.; Williams, J.; Abowd, J.; Vilhuber, L. Data Management of Confidential Data. Int. J. Digit. Curation 2013, 8, 265–278. [Google Scholar] [CrossRef]
- Ukil, A.; Bandyopadhyay, S.; Pal, A. IoT-Privacy: To be private or not to be private. In Proceedings of the 2014 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 27 April–2 May 2014; IEEE: Manhattan, NY, USA, 2014; pp. 123–124. [Google Scholar]
- Gerber, N.; Gerber, P.; Volkamer, M. Explaining the privacy paradox: A systematic review of literature investigating privacy attitude and behavior. Comput. Secur. 2018, 77, 226–261. [Google Scholar] [CrossRef]
- Sarker, I.H. Data Science and Analytics: An Overview from Data-Driven Smart Computing, Decision-Making and Applications Perspective. SN Comput. Sci. 2021, 2, 377. [Google Scholar] [CrossRef] [PubMed]
- Matignon, R. Data Mining Using SAS Enterprise Miner; Wiley: Hoboken, NJ, USA, 2007. [Google Scholar]
- Shearer, C. The CRISP-DM Model: The New Blueprint for Data Mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. The KDD Process for Extracting Useful Knowledge from Volumes of Data. Commun. ACM 1996, 39, 27–34. [Google Scholar] [CrossRef]
- Kutzias, D.; Dukino, C.; Kett, H. Towards a Continuous Process Model for Data Science Projects. In Proceedings of the 12th International Conference on Applied Human Factors and Ergonomics (AHFE), New York, NY, USA, 25–29 July 2021; Springer: Cham, Switzerland, 2021; pp. 204–210. [Google Scholar]
- Costagliola, G.; Fuccella, V.; Giordano, M.; Polese, G. Monitoring Online Tests through Data Visualization. IEEE Trans. Knowl. Data Eng. 2009, 21, 773–784. [Google Scholar] [CrossRef]
- Uttamchandani, S. The Self-Service Data Roadmap: Democratize Data and Reduce Time to Insight; O’Reilly: Sebastopol, CA, USA, 2020. [Google Scholar]
- Azeroual, O. Data Wrangling in Database Systems: Purging of Dirty Data. Data 2020, 50, 50. [Google Scholar] [CrossRef]
- Delen, D. Prescriptive Analytics: The Final Frontier for Evidence-Based Management and Optimal Decision Making; Pearson FT Press: Hoboken, NJ, USA, 2019. [Google Scholar]
- Luengo, J.; García-Gil, D.; Ramírez-Gallego, S.; García, S.; Herrera, F. Big Data Preprocessing: Enabling Smart Data; Springer: Cham, Switzerland, 2020. [Google Scholar]
- European Parliament and Council of the European Union. Regulation on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (Data Protection Directive). Legislative Acts L119. Off. J. Eur. Union 2016. Available online: https://gdpr-info.eu/ (accessed on 31 July 2022).
- Rhahla, M.; Allegue, S.; Abdellatif, T. Guidelines for GDPR compliance in Big Data systems. J. Inf. Secur. Appl. 2021, 61, 102896. [Google Scholar] [CrossRef]
- Rassouli, B.; Rosas, F.E.; Gündüz, D. Data Disclosure Under Perfect Sample Privacy. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2012–2025. [Google Scholar] [CrossRef]
- Al-Rubaie, M.; Chang, J.M. Privacy-Preserving Machine Learning: Threats and Solutions. IEEE Secur. Priv. 2019, 17, 49–58. [Google Scholar] [CrossRef]
- Dou, H.; Chen, Y.; Yang, Y.; Long, Y. A secure and efficient privacy-preserving data aggregation algorithm. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1495–1503. [Google Scholar] [CrossRef]
- Khwaja, A.S.; Anpalagan, A.; Naeem, M.; Venkatesh, B. Smart Meter Data Obfuscation Using Correlated Noise. IEEE Internet Things J. 2020, 7, 7250–7264. [Google Scholar] [CrossRef]
- Gangarde, R.; Sharma, A.; Pawar, A.; Joshi, R.; Gonge, S. Privacy Preservation in Online Social Networks Using Multiple-Graph-Properties-Based Clustering to Ensure k-Anonymity, l-Diversity, and t-Closeness. Electronics 2021, 10, 2877. [Google Scholar] [CrossRef]
- Stach, C. How to Deal with Third Party Apps in a Privacy System—The PMP Gatekeeper. In Proceedings of the 2015 IEEE 16th International Conference on Mobile Data Management (MDM), Pittsburgh, PA, USA, 15–18 June 2015; IEEE: Manhattan, NY, USA, 2015; pp. 167–172. [Google Scholar]
- Stach, C. How to Assure Privacy on Android Phones and Devices? In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management (MDM), Milan, Italy, 3–6 June 2013; IEEE: Manhattan, NY, USA, 2013; pp. 350–352. [Google Scholar]
- Stach, C.; Mitschang, B. Privacy Management for Mobile Platforms—A Review of Concepts and Approaches. In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management (MDM), Milan, Italy, 3–6 June 2013; IEEE: Manhattan, NY, USA, 2013; pp. 305–313. [Google Scholar]
- Hou, W.C.; Ozsoyoglu, G.; Taneja, B.K. Statistical Estimators for Relational Algebra Expressions. In Proceedings of the Seventh ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), Austin, TX, USA, 21–23 March 1988; ACM: New York, NY, USA, 1988; pp. 276–287. [Google Scholar]
- Stach, C. Fine-Grained Privacy Control for Fitness and Health Applications Using the Privacy Management Platform. In Proceedings of the Information Systems Security and Privacy: 4th International Conference, ICISSP 2018, Funchal, Portugal, 22–24 January 2018; Revised Selected Papers. Mori, P., Furnell, S., Camp, O., Eds.; Springer: Cham, Switzerland, 2019; pp. 1–25. [Google Scholar]
- McKenzie, L.E.; Snodgrass, R.T. Evaluation of Relational Algebras Incorporating the Time Dimension in Databases. ACM Comput. Surv. 1991, 23, 501–543. [Google Scholar] [CrossRef]
- Özsoyoğlu, G.; Özsoyoğlu, Z.M.; Matos, V. Extending Relational Algebra and Relational Calculus with Set-Valued Attributes and Aggregate Functions. ACM Trans. Database Syst. 1987, 12, 566–592. [Google Scholar] [CrossRef]
- Li, J.; Maier, D.; Tufte, K.; Papadimos, V.; Tucker, P.A. Semantics and Evaluation Techniques for Window Aggregates in Data Streams. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data (SIGMOD), Baltimore, MD, USA, 14–16 June 2005; ACM: New York, NY, USA, 2005; pp. 311–322. [Google Scholar]
- Olejnik, K.; Dacosta, I.; Machado, J.S.; Huguenin, K.; Khan, M.E.; Hubaux, J.P. SmarPer: Context-Aware and Automatic Runtime-Permissions for Mobile Devices. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; IEEE: Manhattan, NY, USA, 2017; pp. 1058–1076. [Google Scholar]
- Navidan, H.; Moghtadaiee, V.; Nazaran, N.; Alishahi, M. Hide me Behind the Noise: Local Differential Privacy for Indoor Location Privacy. In Proceedings of the 2022 IEEE European Symposium on Security and Privacy Workshops (EuroS & PW), Genoa, Italy, 6–10 June 2022; IEEE: Manhattan, NY, USA, 2022; pp. 514–523. [Google Scholar]
- Choi, M.J.; Kim, H.S.; Moon, Y.S. Publishing Sensitive Time-Series Data under Preservation of Privacy and Distance Orders. Int. J. Innov. Comput. Inf. Control. 2012, 8, 3619–3638. [Google Scholar]
- Liu, B.; Ding, M.; Shaham, S.; Rahayu, W.; Farokhi, F.; Lin, Z. When Machine Learning Meets Privacy: A Survey and Outlook. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Alpers, S.; Oberweis, A.; Pieper, M.; Betz, S.; Fritsch, A.; Schiefer, G.; Wagner, M. PRIVACY-AVARE: An approach to manage and distribute privacy settings. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; IEEE: Manhattan, NY, USA, 2017; pp. 1460–1468. [Google Scholar]
- Kido, H.; Yanagisawa, Y.; Satoh, T. An anonymous communication technique using dummies for location-based services. In Proceedings of the 2005 International Conference on Pervasive Services (ICPS), Santorini, Greece, 11–14 July 2005; IEEE: Manhattan, NY, USA, 2005; pp. 88–97. [Google Scholar]
- Stach, C.; Steimle, F.; Mitschang, B. How to Realize Device Interoperability and Information Security in mHealth Applications. In Proceedings of the Biomedical Engineering Systems and Technologies: 11th International Joint Conference, BIOSTEC 2018, Funchal, Portugal, 19–21 January 2018; Revised Selected Papers. Cliquet, A., Jr., Wiebe, S., Anderson, P., Saggio, G., Zwiggelaar, R., Gamboa, H., Fred, A., Bermúdez i Badia, S., Eds.; Springer: Cham, Switzerland, 2019; pp. 213–237. [Google Scholar]
- Stach, C. VAULT: A Privacy Approach towards High-Utility Time Series Data. In Proceedings of the Thirteenth International Conference on Emerging Security Information, Systems and Technologies (SECURWARE), Nice, France, 27–31 October 2019; IARIA: Wilmington, DE, USA, 2019; pp. 41–46. [Google Scholar]
- Hernández Acosta, L.; Reinhardt, D. A survey on privacy issues and solutions for Voice-controlled Digital Assistants. Pervasive Mob. Comput. 2022, 80, 101523. [Google Scholar] [CrossRef]
- Oh, S.J.; Benenson, R.; Fritz, M.; Schiele, B. Faceless Person Recognition: Privacy Implications in Social Media. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 19–35. [Google Scholar]
- Alpers, S.; Betz, S.; Fritsch, A.; Oberweis, A.; Schiefer, G.; Wagner, M. Citizen Empowerment by a Technical Approach for Privacy Enforcement. In Proceedings of the 8th International Conference on Cloud Computing and Services Science (CLOSER), Funchal, Portugal, 19–21 March 2018; SciTePress: Setúbal, Portugal, 2018; pp. 589–595. [Google Scholar]
- Stach, C.; Dürr, F.; Mindermann, K.; Palanisamy, S.M.; Wagner, S. How a Pattern-based Privacy System Contributes to Improve Context Recognition. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; IEEE: Manhattan, NY, USA, 2018; pp. 238–243. [Google Scholar]
- Kwecka, Z.; Buchanan, W.; Schafer, B.; Rauhofer, J. “I am Spartacus”: Privacy enhancing technologies, collaborative obfuscation and privacy as a public good. Artif. Intell. Law 2014, 22, 113–139. [Google Scholar] [CrossRef]
- Slijepčeviá, D.; Henzl, M.; Klausner, L.D.; Dam, T.; Kieseberg, P.; Zeppelzauer, M. k-Anonymity in practice: How generalisation and suppression affect machine learning classifiers. Comput. Secur. 2021, 111, 102488. [Google Scholar] [CrossRef]
- Dwork, C. Differential Privacy. In Proceedings of the 33rd International Colloquium on Automata, Languages, and Programming (ICALP), Venice, Italy,, 10–14 July 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Jain, P.; Gyanchandani, M.; Khare, N. Differential privacy: Its technological prescriptive using big data. J. Big Data 2018, 5, 15. [Google Scholar] [CrossRef]
- Zhu, T.; Li, G.; Zhou, W.; Yu, P.S. Differentially Private Recommender System. In Differential Privacy and Applications; Springer: Cham, Switzerland, 2017; pp. 107–129. [Google Scholar]
- Machanavajjhala, A.; He, X.; Hay, M. Differential Privacy in the Wild: A Tutorial on Current Practices & Open Challenges. In Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD), Chicago, IL, USA, 14–19 May 2017; ACM: New York, NY, USA, 2017; pp. 1727–1730. [Google Scholar]
- Stach, C.; Alpers, S.; Betz, S.; Dürr, F.; Fritsch, A.; Mindermann, K.; Palanisamy, S.M.; Schiefer, G.; Wagner, M.; Mitschang, B.; et al. The AVARE PATRON—A Holistic Privacy Approach for the Internet of Things. In Proceedings of the 15th International Joint Conference on e-Business and Telecommunications (SECRYPT), Porto, Portugal, 26–28 July 2018; SciTePress: Setúbal, Portugal, 2018; pp. 372–379. [Google Scholar]
- Chai, Q.; Gong, G. Verifiable symmetric searchable encryption for semi-honest-but-curious cloud servers. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; IEEE: Manhattan, NY, USA, 2012; pp. 917–922. [Google Scholar]
- Zagalsky, A.; Te’eni, D.; Yahav, I.; Schwartz, D.G.; Silverman, G.; Cohen, D.; Mann, Y.; Lewinsky, D. The Design of Reciprocal Learning Between Human and Artificial Intelligence. Proc. ACM Hum.-Comput. Interact. 2021, 5, 443. [Google Scholar] [CrossRef]
- Arcolezi, H.H.; Couchot, J.F.; Al Bouna, B.; Xiao, X. Random Sampling Plus Fake Data: Multidimensional Frequency Estimates With Local Differential Privacy. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM), Gold Coast, QLD, Australia, 1–5 November 2021; ACM: New York, NY, USA, 2021; pp. 47–57. [Google Scholar]
- Wagner, I.; Eckhoff, D. Technical Privacy Metrics: A Systematic Survey. ACM Comput. Surv. 2018, 51, 57. [Google Scholar] [CrossRef]
- Oppold, S.; Herschel, M. A System Framework for Personalized and Transparent Data-Driven Decisions. In Proceedings of the 32nd International Conference on Advanced Information Systems Engineering (CAiSE), Grenoble, France, 8–12 June 2020; Springer: Cham, Switzerland, 2020; pp. 153–168. [Google Scholar]
- Lässig, N.; Oppold, S.; Herschel, M. Metrics and Algorithms for Locally Fair and Accurate Classifications using Ensembles. Datenbank Spektrum 2022, 22, 23–43. [Google Scholar] [CrossRef]
- Gemp, I.; Theocharous, G.; Ghavamzadeh, M. Automated Data Cleansing through Meta-Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 4760–4761. [Google Scholar]
- Dutta, A.; Deb, T.; Pathak, S. Automated Data Harmonization (ADH) using Artificial Intelligence (AI). OPSEARCH 2021, 58, 257–275. [Google Scholar] [CrossRef]
- Behringer, M.; Hirmer, P.; Mitschang, B. A Human-Centered Approach for Interactive Data Processing and Analytics. In Proceedings of the Enterprise Information Systems: 19th International Conference, ICEIS 2017, Porto, Portugal, 26–29 April 2017; Revised Selected Papers. Hammoudi, S., Śmiałek, M., Camp, O., Filipe, J., Eds.; Springer: Cham, Switzerland, 2018; pp. 498–514. [Google Scholar]
- Stöger, K.; Schneeberger, D.; Kieseberg, P.; Holzinger, A. Legal aspects of data cleansing in medical AI. Comput. Law Secur. Rev. 2021, 42, 105587. [Google Scholar] [CrossRef]
- El Emam, K.; Mosquera, L.; Hoptroff, R. Practical Synthetic Data Generation; O’Reilly: Sebastopol, CA, USA, 2020. [Google Scholar]
- Stach, C.; Bräcker, J.; Eichler, R.; Giebler, C.; Mitschang, B. Demand-Driven Data Provisioning in Data Lakes: BARENTS—A Tailorable Data Preparation Zone. In Proceedings of the 23rd International Conference on Information Integration and Web Intelligence (iiWAS), Linz, Austria, 29 November–1 December 2021; ACM: New York, NY, USA, 2021; pp. 187–198. [Google Scholar]
- Hosseinzadeh, M.; Azhir, E.; Ahmed, O.H.; Ghafour, M.Y.; Ahmed, S.H.; Rahmani, A.M.; Vo, B. Data cleansing mechanisms and approaches for big data analytics: A systematic study. J. Ambient. Intell. Humaniz. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Sharma, B. Architecting Data Lakes: Data Management Architectures for Advanced Business Use Cases, 2nd ed.; O’Reilly: Sebastopol, CA, USA, 2018. [Google Scholar]
- Stach, C.; Bräcker, J.; Eichler, R.; Giebler, C.; Gritti, C. How to Provide High-Utility Time Series Data in a Privacy-Aware Manner: A VAULT to Manage Time Series Data. Int. J. Adv. Secur. 2020, 13, 88–108. [Google Scholar]
- Stach, C.; Giebler, C.; Wagner, M.; Weber, C.; Mitschang, B. AMNESIA: A Technical Solution towards GDPR-compliant Machine Learning. In Proceedings of the 6th International Conference on Information Systems Security and Privacy (ICISSP), Valletta, Malta, 25–27 February 2020; SciTePress: Setúbal, Portugal, 2020; pp. 21–32. [Google Scholar]
- Mindermann, K.; Riedel, F.; Abdulkhaleq, A.; Stach, C.; Wagner, S. Exploratory Study of the Privacy Extension for System Theoretic Process Analysis (STPA-Priv) to elicit Privacy Risks in eHealth. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops, 4th International Workshop on Evolving Security & Privacy Requirements Engineering (REW/ESPRE), Lisbon, Portugal, 4–8 September 2017; IEEE: Manhattan, NY, USA, 2017; pp. 90–96. [Google Scholar]
- Shapiro, S.S. Privacy Risk Analysis Based on System Control Structures: Adapting System-Theoretic Process Analysis for Privacy Engineering. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; IEEE: Manhattan, NY, USA, 2016; pp. 17–24. [Google Scholar]
- Stach, C.; Mitschang, B. ACCESSORS: A Data-Centric Permission Model for the Internet of Things. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), Funchal, Portugal, 22–24 January 2018; SciTePress: Setúbal, Portugal, 2018; pp. 30–40. [Google Scholar]
- Stach, C.; Steimle, F. Recommender-based Privacy Requirements Elicitation—EPICUREAN: An Approach to Simplify Privacy Settings in IoT Applications with Respect to the GDPR. In Proceedings of the 34th ACM/SIGAPP Symposium On Applied Computing (SAC), Limassol, Cyprus, 8–12 April 2019; ACM: New York, NY, USA, 2019; pp. 1500–1507. [Google Scholar]
- Stach, C.; Mitschang, B. Elicitation of Privacy Requirements for the Internet of Things Using ACCESSORS. In Proceedings of the Information Systems Security and Privacy: 4th International Conference, ICISSP 2018, Funchal, Portugal, 22–24 January 2018; Revised Selected Papers. Mori, P., Furnell, S., Camp, O., Eds.; Springer: Cham, Switzerland, 2019; pp. 40–65. [Google Scholar]
- Gritti, C.; Chen, R.; Susilo, W.; Plantard, T. Dynamic Provable Data Possession Protocols with Public Verifiability and Data Privacy. In Proceedings of the 13th International Conference on Information Security Practice and Experience (ISPEC), Melbourne, VIC, Australia, 13–15 December 2017; Springer: Cham, Switzerland, 2017; pp. 485–505. [Google Scholar]
- Gritti, C. Publicly Verifiable Proofs of Data Replication and Retrievability for Cloud Storage. In Proceedings of the 2020 International Computer Symposium (ICS), Tainan, Taiwan, 17–19 December 2020; IEEE: Manhattan, NY, USA, 2020; pp. 431–436. [Google Scholar]
- Stach, C.; Gritti, C.; Mitschang, B. Bringing Privacy Control Back to Citizens: DISPEL—A Distributed Privacy Management Platform for the Internet of Things. In Proceedings of the 35th ACM/SIGAPP Symposium on Applied Computing (SAC), Brno, Czech Republic, 30 March–3 April 2020; ACM: New York, NY, USA, 2020; pp. 1272–1279. [Google Scholar]
- Gritti, C.; Önen, M.; Molva, R. CHARIOT: Cloud-Assisted Access Control for the Internet of Things. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, Ireland, 28–30 August 2018; IEEE: Manhattan, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Gritti, C.; Önen, M.; Molva, R. Privacy-Preserving Delegable Authentication in the Internet of Things. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing (SAC), Limassol, Cyprus, 8–12 April 2019; ACM: New York, NY, USA, 2019; pp. 861–869. [Google Scholar]
- Chaum, D.; Damgård, I.B.; van de Graaf, J. Multiparty Computations Ensuring Privacy of Each Party’s Input and Correctness of the Result. In Proceedings of the 7th Annual International Cryptology Conference (CRYPTO), Santa Barbara, CA, USA, 16–20 August 1988; Springer: Berlin/Heidelberg, Germany, 1988; pp. 87–119. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Barker, E. Recommendation for Key Management: Part 1—General; NIST Special Publication 800-57 Part 1, Revision 5; National Institute of Standards and Technology, Technology Administration: Gaithersburg, MD, USA, 2020; pp. 1–158.
- Mavroeidis, V.; Vishi, K.; Zych, M.D.; Jøsang, A. The Impact of Quantum Computing on Present Cryptography. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 405–414. [Google Scholar] [CrossRef]
- Borges, F.; Reis, P.R.; Pereira, D. A Comparison of Security and its Performance for Key Agreements in Post-Quantum Cryptography. IEEE Access 2020, 8, 142413–142422. [Google Scholar] [CrossRef]
- Behringer, M.; Hirmer, P.; Fritz, M.; Mitschang, B. Empowering Domain Experts to Preprocess Massive Distributed Datasets. In Proceedings of the 23rd International Conference on Business Information Systems (BIS), Colorado Springs, CO, USA, 8–10 June 2020; Springer: Cham, Switzerland, 2020; pp. 61–75. [Google Scholar]
- Stach, C.; Brodt, A. vHike—A Dynamic Ride-Sharing Service for Smartphones. In Proceedings of the 2011 IEEE 12th International Conference on Mobile Data Management (MDM), Luleå, Sweden, 6–9 June 2011; IEEE: Manhattan, NY, USA, 2011; pp. 333–336. [Google Scholar]
- Stach, C. Secure Candy Castle—A Prototype for Privacy-Aware mHealth Apps. In Proceedings of the 2016 IEEE 17th International Conference on Mobile Data Management (MDM), Porto, Portugal, 13–16 June 2016; IEEE: Manhattan, NY, USA, 2016; pp. 361–364. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CRISP-DM | KDD | SEMMA |
|---|---|---|
| Business Understanding | Preceding the KDD Process | - |
| Data Understanding | Selection | Sample |
| Pre-Processing | Explore | |
| Data Preparation | Transformation | Modify |
| Modeling | Data Mining | Model |
| Evaluation | Interpretation/Evaluation | Assess |
| Deployment | Succeeding the KDD Process | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stach, C.; Behringer, M.; Bräcker, J.; Gritti, C.; Mitschang, B. SMARTEN—A Sample-Based Approach towards Privacy-Friendly Data Refinement. J. Cybersecur. Priv. 2022, 2, 606-628. https://doi.org/10.3390/jcp2030031
Stach C, Behringer M, Bräcker J, Gritti C, Mitschang B. SMARTEN—A Sample-Based Approach towards Privacy-Friendly Data Refinement. Journal of Cybersecurity and Privacy. 2022; 2(3):606-628. https://doi.org/10.3390/jcp2030031
Chicago/Turabian StyleStach, Christoph, Michael Behringer, Julia Bräcker, Clémentine Gritti, and Bernhard Mitschang. 2022. "SMARTEN—A Sample-Based Approach towards Privacy-Friendly Data Refinement" Journal of Cybersecurity and Privacy 2, no. 3: 606-628. https://doi.org/10.3390/jcp2030031
APA StyleStach, C., Behringer, M., Bräcker, J., Gritti, C., & Mitschang, B. (2022). SMARTEN—A Sample-Based Approach towards Privacy-Friendly Data Refinement. Journal of Cybersecurity and Privacy, 2(3), 606-628. https://doi.org/10.3390/jcp2030031