
Approximate Invariance Testing in Diagnostic Classification Models in the Presence of Attribute Hierarchies: A Bayesian Network Approach


Abstract
:1. Introduction
Test developers are responsible for developing tests that measure the intended construct and for minimizing the potential for tests being affected by construct-irrelevant characteristics, such as linguistic, communicative, cognitive, cultural, physical, or other characteristics. (p. 64)
2. Diagnostic Classification Models
2.1. Q-Matrix and Attribute Profiles
2.2. The Log-linear Cognitive Diagnosis Model
2.2.1. LCDM Measurement Model
2.2.2. LCDM Structural Model and Attribute Hierarchies
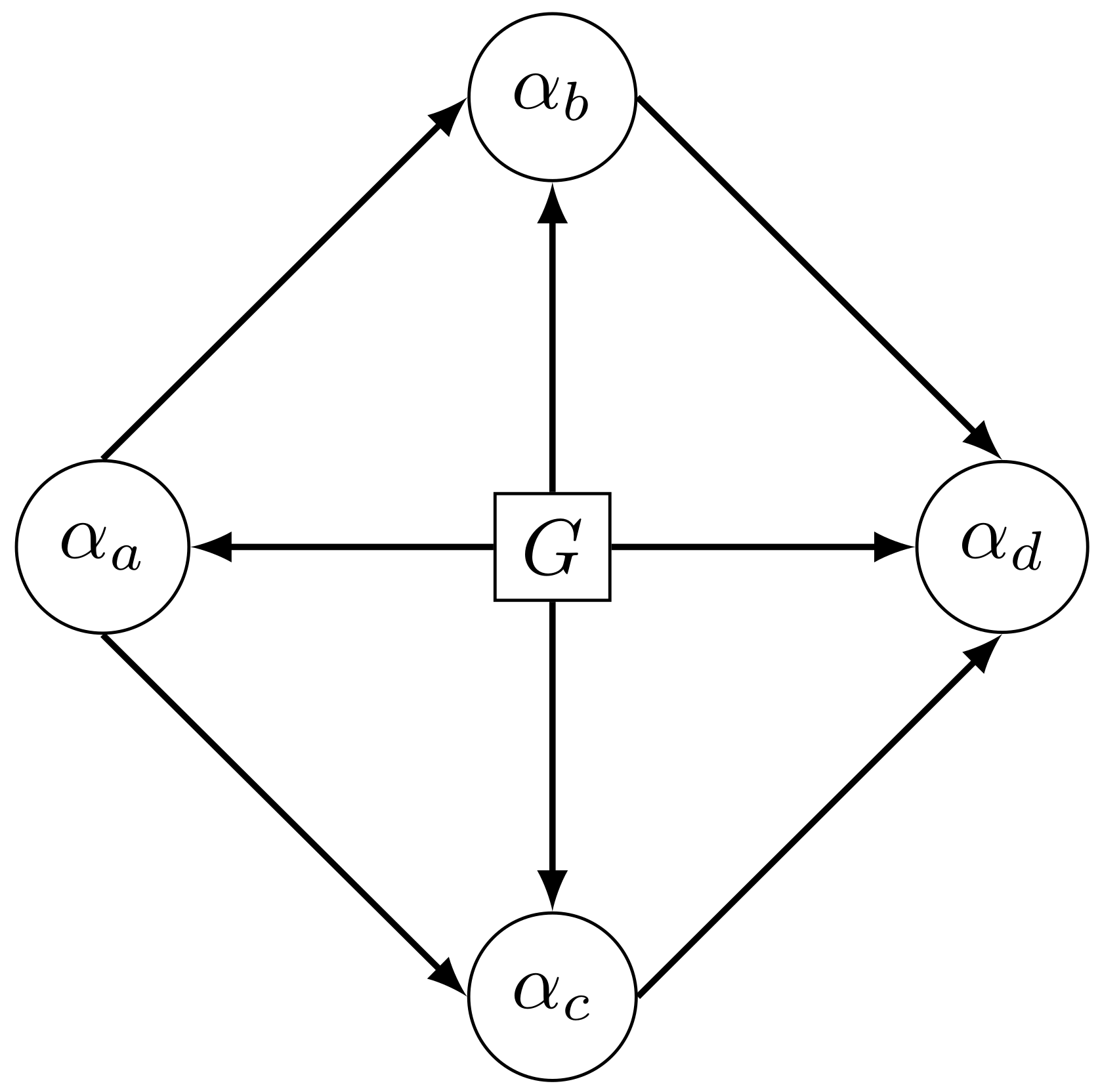
3. Parameterization of the LCDM Structural Model as a Bayesian Network
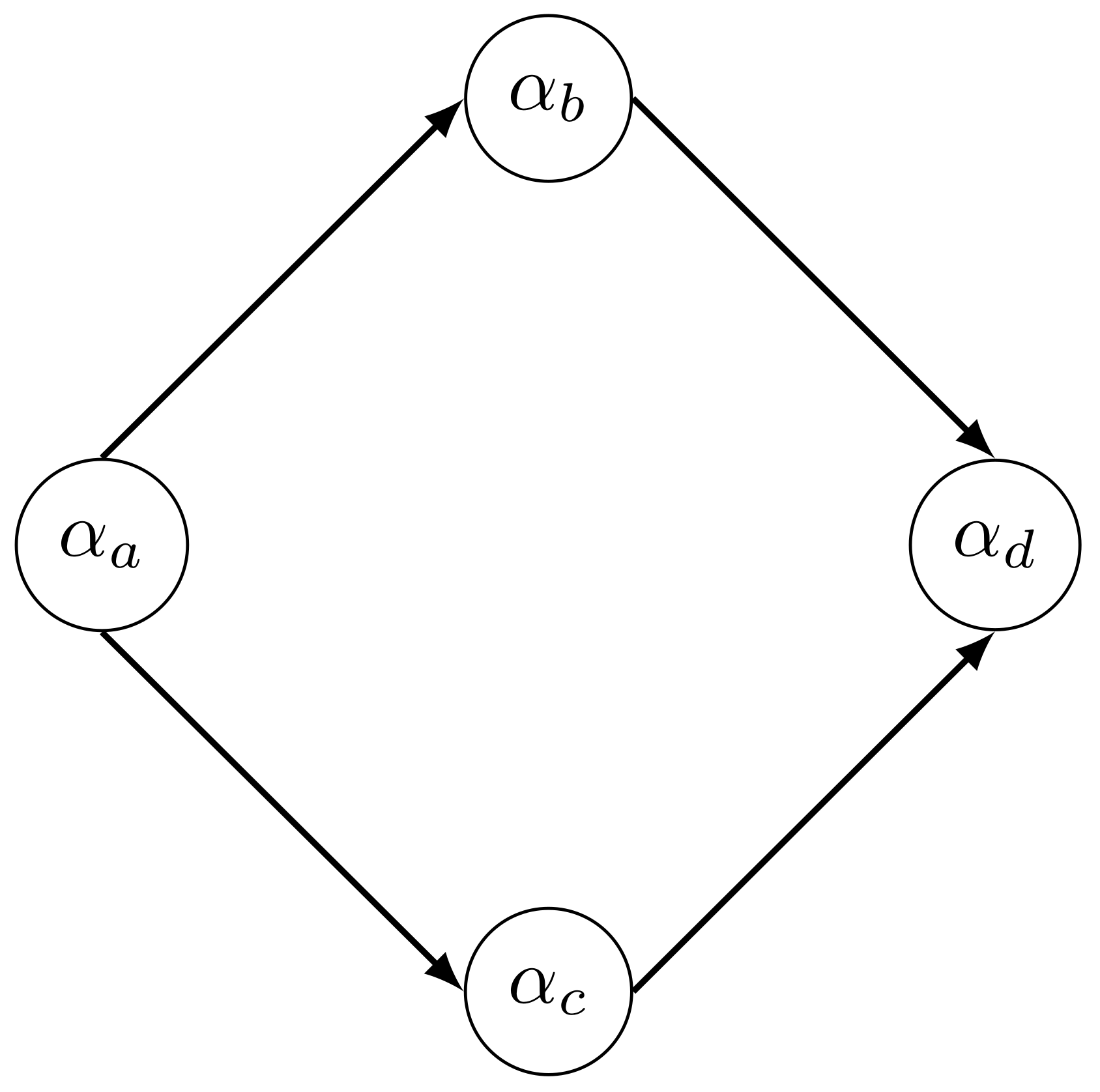
Illustrative Example with a Diamond Attribute Hierarchy
4. Measurement Invariance in DCMs
5. Modifying the LCDM for Invariance Testing
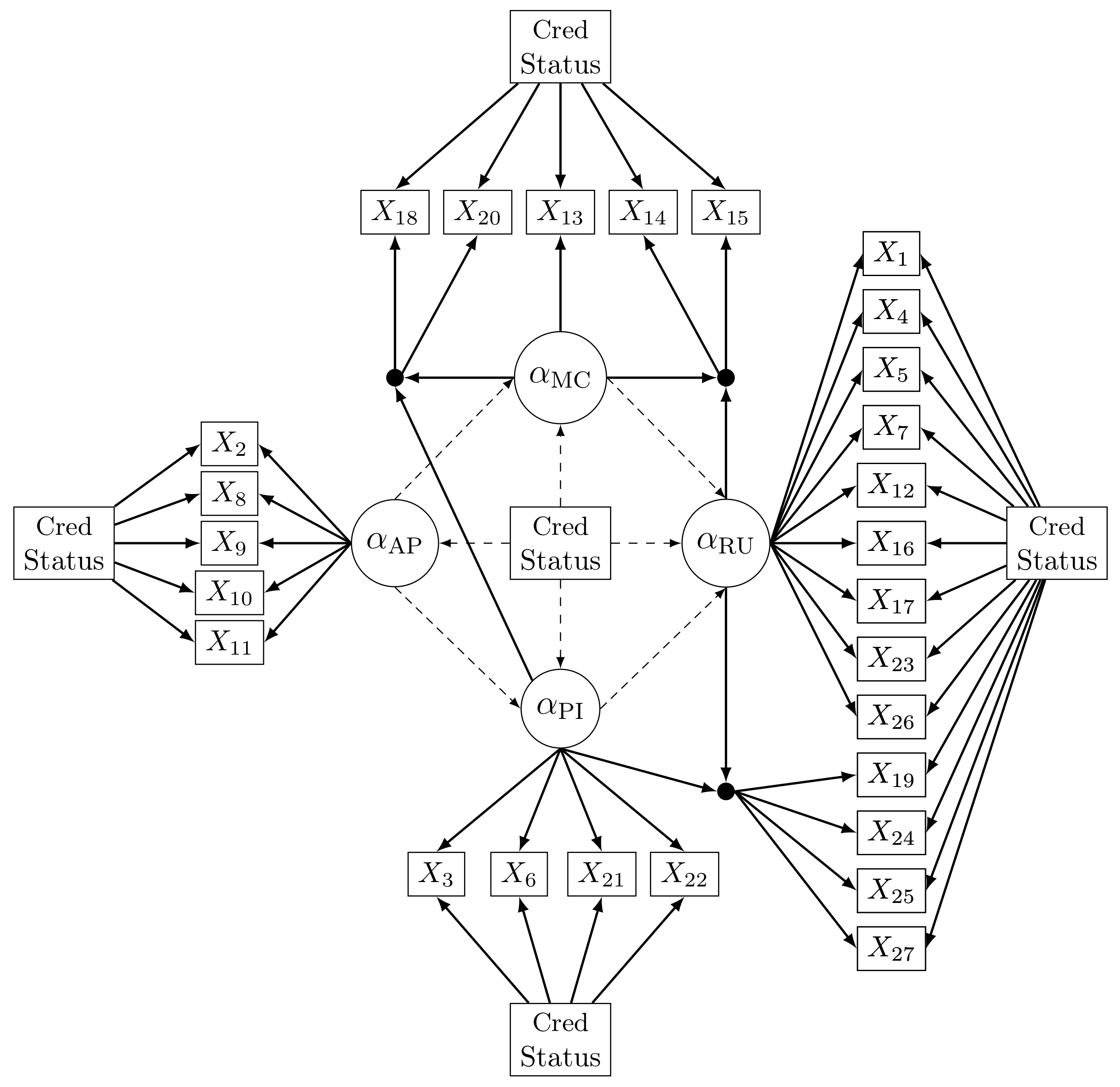
5.1. Specification of the MI-LCDM Measurement Model
5.2. Specification of the MI-BN Structural Model
6. Case Study: Diagnosing Teachers’ Multiplicative Reasoning Skills
7. Bayesian Estimation in JAGS
7.1. Posterior Inference for Teachers with Missing Credential Status
7.2. Priors for the Item and Structural Model Parameters
7.3. JAGS Syntax for the MI-LCDM Measurement Model
| Listing 1. JAGS syntax for the MI-LCDM measurement model. |
 |
 |
7.4. JAGS Syntax for the MI-BN Structural Model
| Listing 2. JAGS syntax for the MI-BN structural model. |
 |
 |
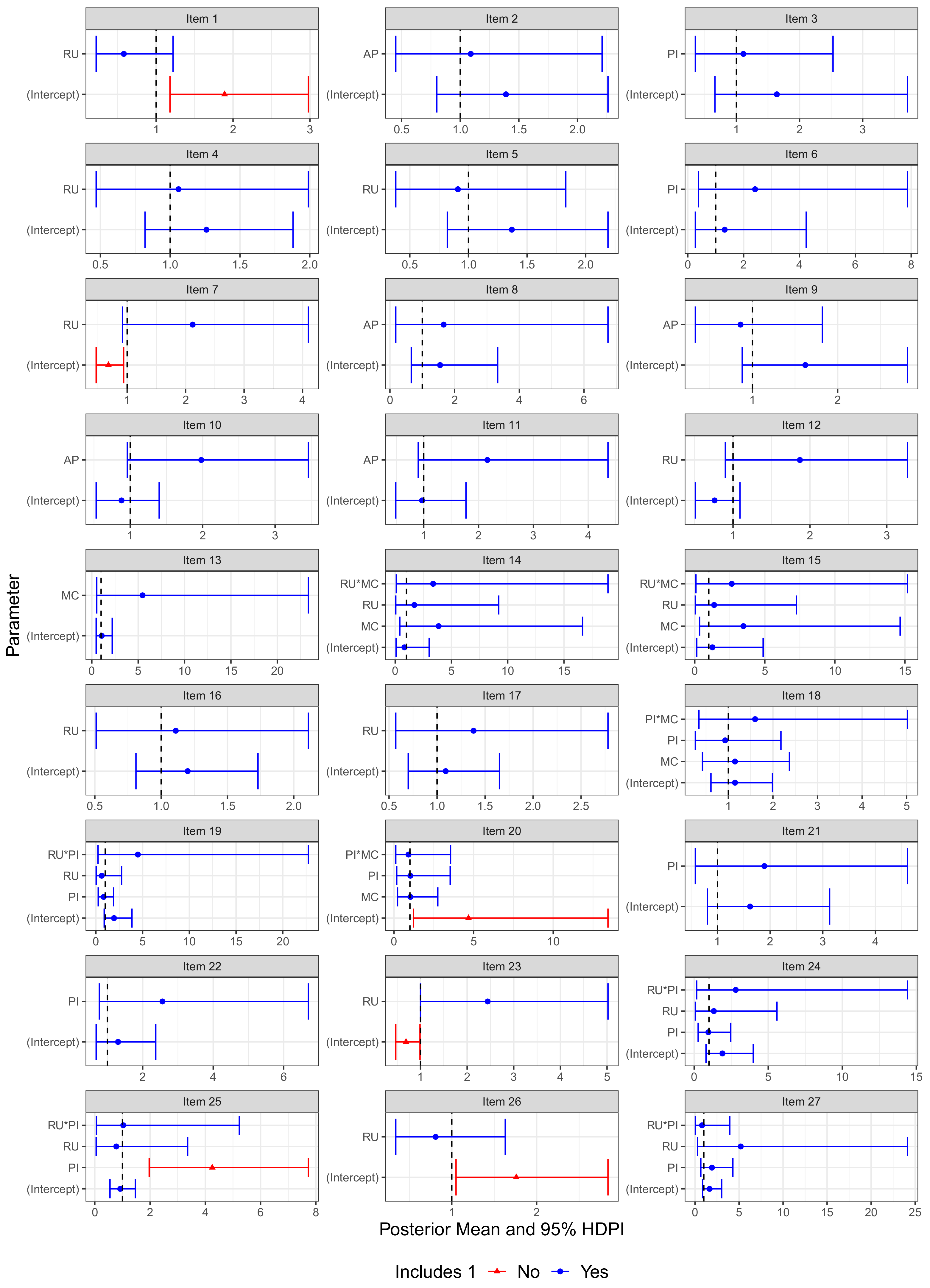
8. Approximate Invariance Testing of the Invariance Parameters
9. Results and Interpretation
9.1. Analysis of Markov Chains
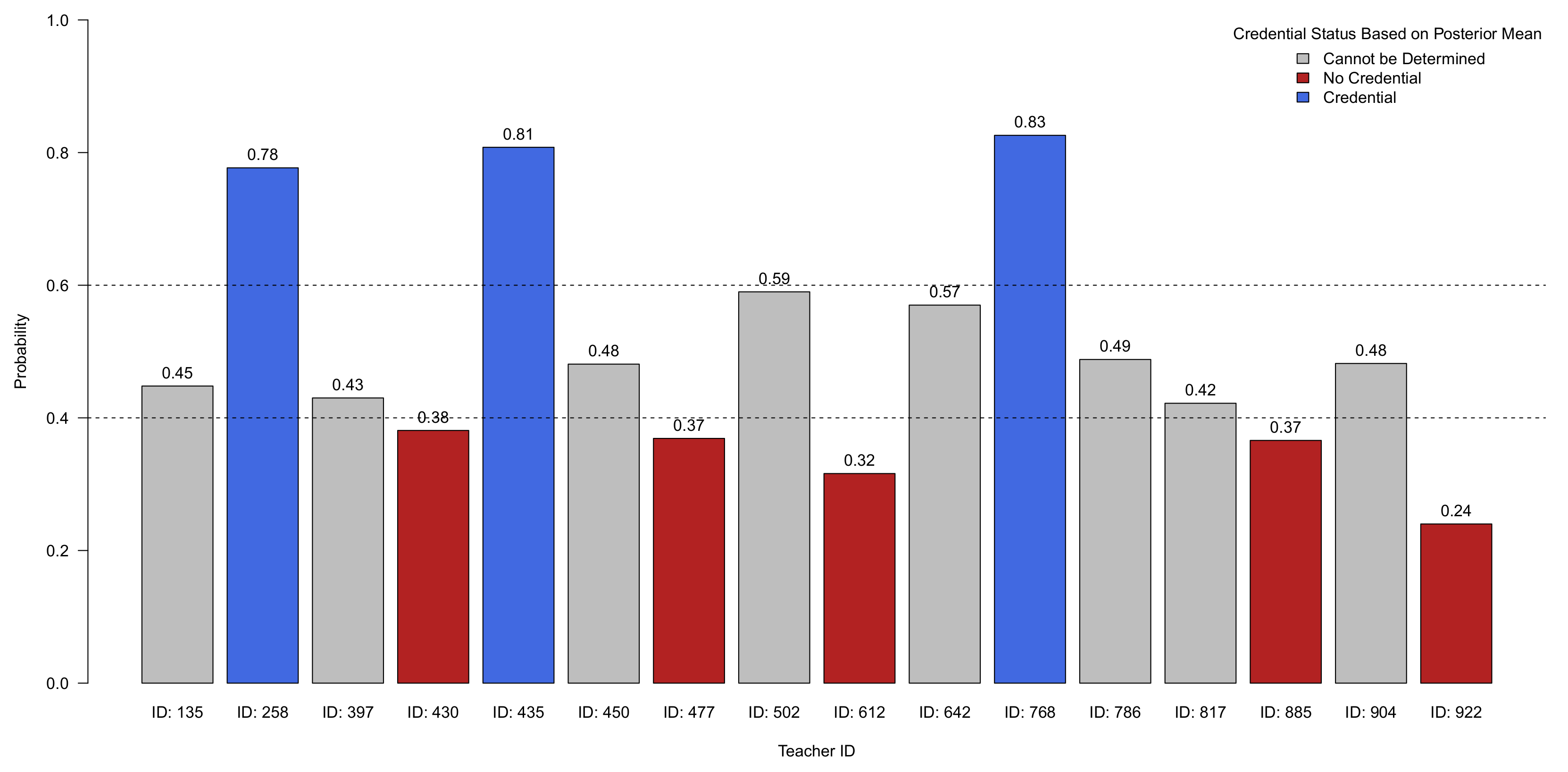
9.2. Analysis of Credential Status
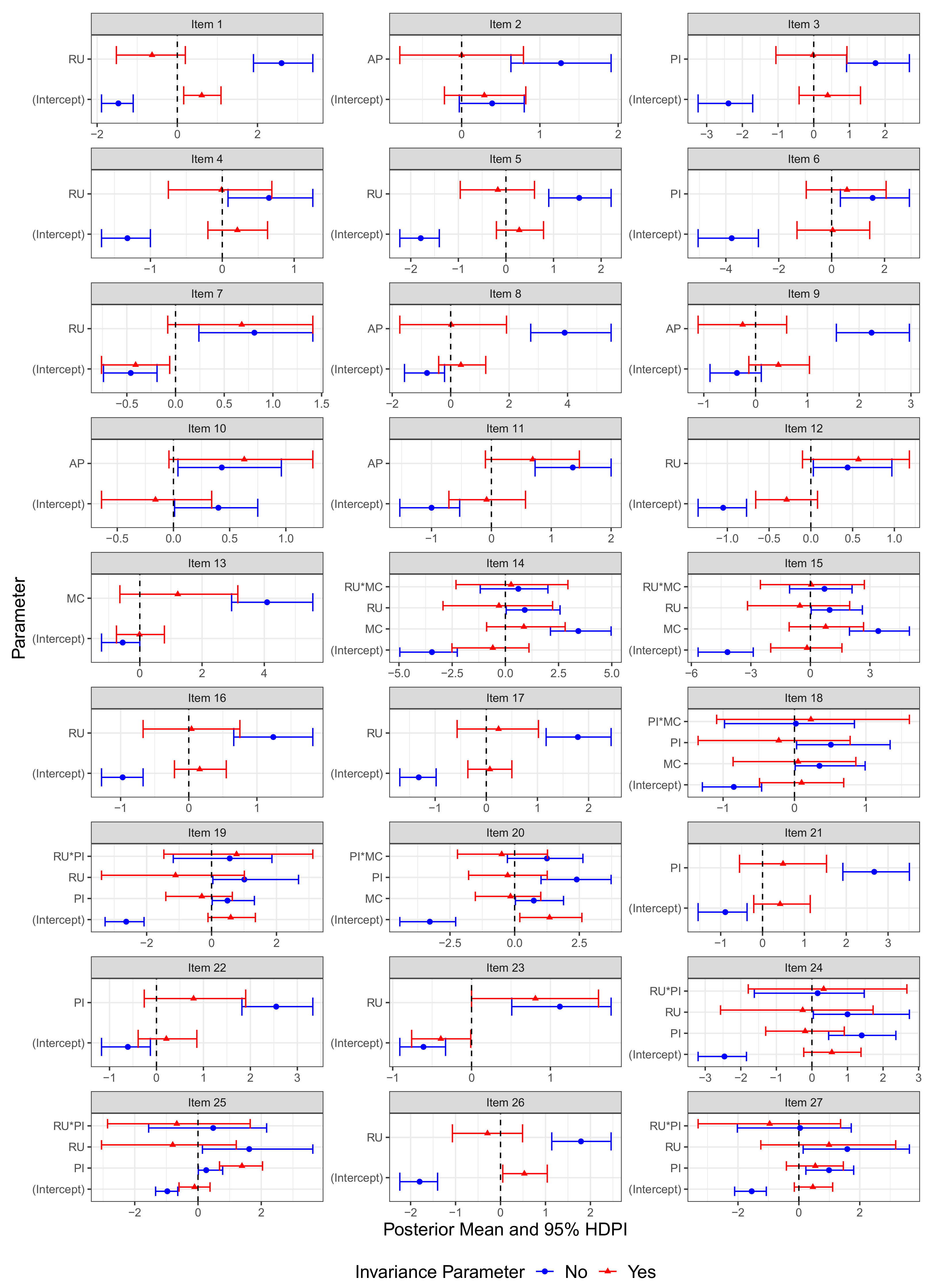
9.3. Analysis of Measurement Model (Item) Parameters
9.4. Analysis of Structural Model Parameters
9.5. Model Comparisons
9.6. Intermediate Summary of Results
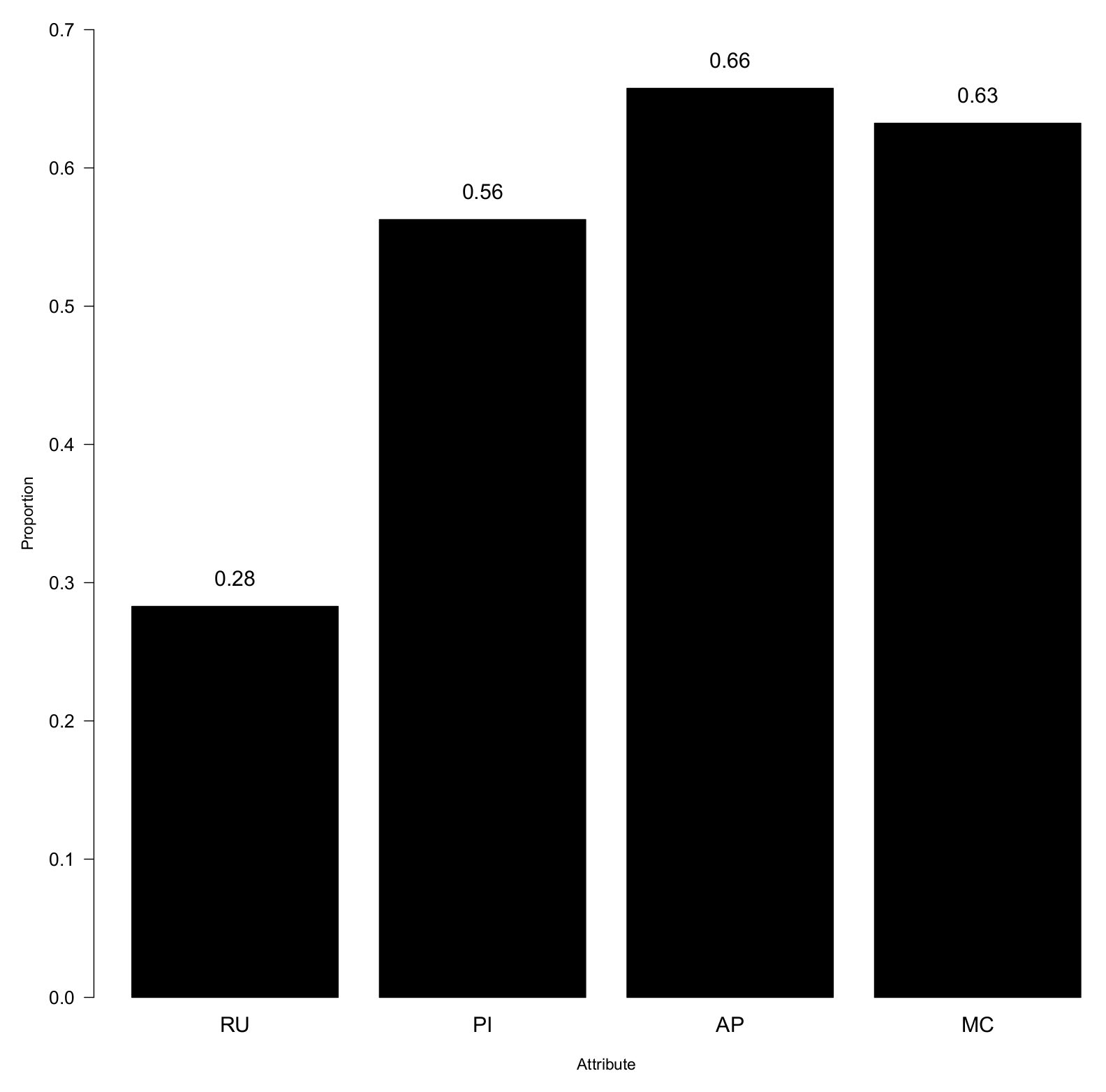
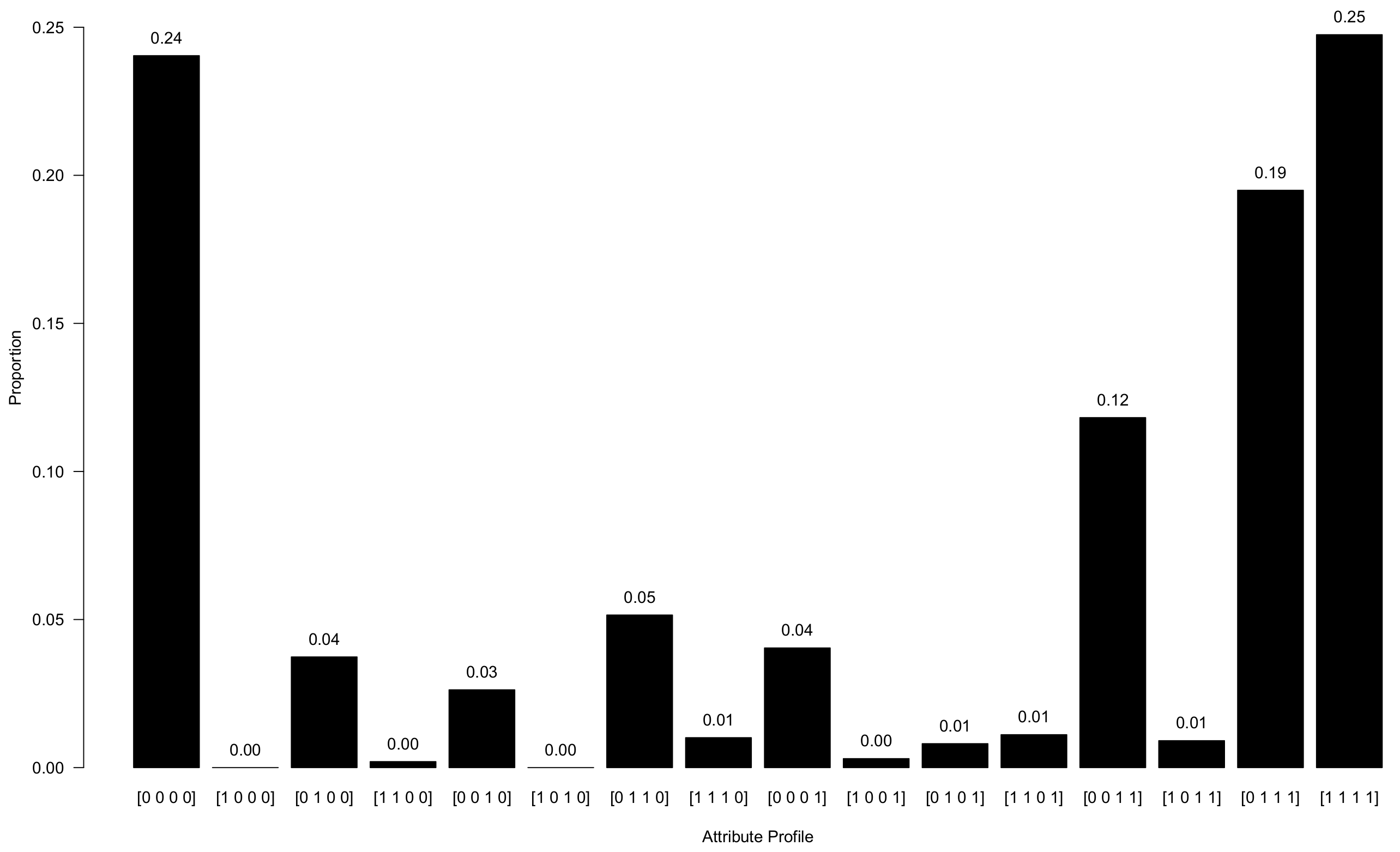
9.7. Analysis of Attribute Profiles
9.7.1. Prevalence of Individual Attributes
9.7.2. Prevalence of Attribute Profiles
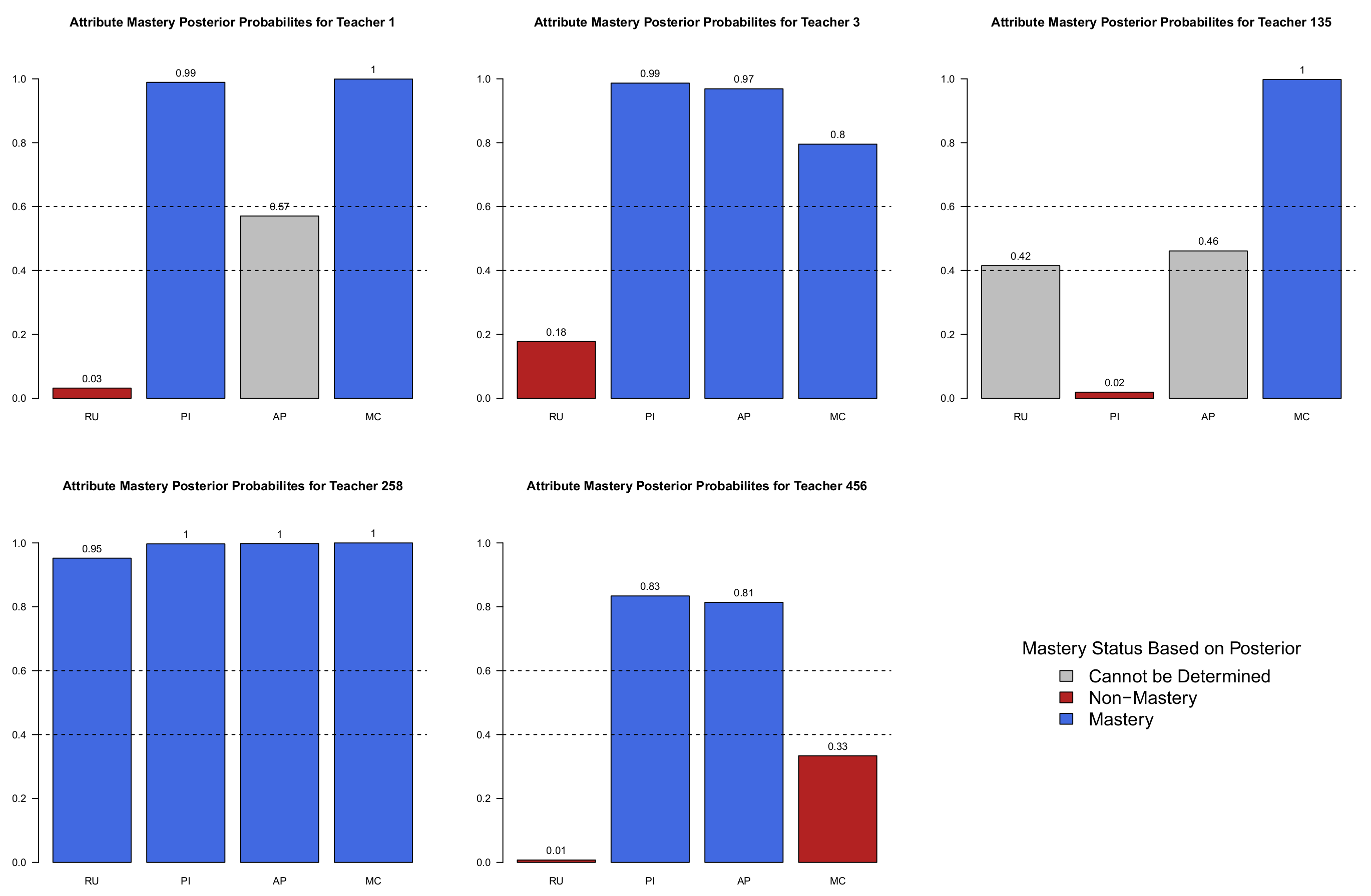
9.7.3. Analysis of Five Randomly Selected Teachers
10. Discussion
| Listing 3. JAGS syntax for the MI-LCDM measurement model with three groups. |
 |
 |
| Listing 4. JAGS syntax for a BN structural model with three-attribute linear hierarchy. |
 |
 |
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Templin, J.; Henson, R.A. Measurement of psychological disorders using cognitive diagnosis models. Psychol. Methods 2006, 11, 287–305. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Gao, X.; Cai, Y.; Tu, D. Development of a new instrument for depression with cognitive diagnosis models. Front. Psychol. 2019, 10, 1306. [Google Scholar] [CrossRef] [PubMed]
- de la Torre, J.; van der Ark, L.A.; Rossi, G. Analysis of clinical data from a cognitive diagnosis modeling framework. Meas. Eval. Couns. Dev. 2018, 51, 281–296. [Google Scholar] [CrossRef]
- Ravand, H.; Baghaei, P. Diagnostic classification models: Recent developments, practical issues, and prospects. Int. J. Test. 2020, 20, 24–56. [Google Scholar] [CrossRef]
- Leighton, J.; Gierl, M. Cognitive Diagnostic Assessment for Education: Theory and Applications; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Millsap, R.E. Statistical Approaches to Measurement Invariance; Routledge: New York, NY, USA, 2012. [Google Scholar]
- Zumbo, B.D. Three generations of DIF analyses: Considering where it has been, where it is now, and where it is going. Lang. Assess. Q. 2007, 4, 223–233. [Google Scholar] [CrossRef]
- Hansson, Å.; Gustafsson, J.E. Measurement invariance of socioeconomic status across migrational background. Scand. J. Educ. Res. 2013, 57, 148–166. [Google Scholar] [CrossRef]
- American Educational Research Association; American Psychological Association; National Council on Measurement in Education. Standards for Educational and Psychological Testing; American Educational Research Association: Philadelphia, PA, USA, 2014. [Google Scholar]
- Kim, E.S.; Yoon, M. Testing measurement invariance: A comparison of multiple-group categorical CFA and IRT. Struct. Equ. Model. 2011, 18, 212–228. [Google Scholar] [CrossRef]
- Meredith, W. Measurement invariance, factor analysis and factorial invariance. Psychometrika 1993, 58, 525–543. [Google Scholar] [CrossRef]
- Stark, S.; Chernyshenko, O.S.; Drasgow, F. Detecting differential item functioning with confirmatory factor analysis and item response theory: Toward a unified strategy. J. Appl. Psychol. 2006, 91, 1292. [Google Scholar] [CrossRef]
- Reise, S.P.; Widaman, K.F.; Pugh, R.H. Confirmatory factor analysis and item response theory: Two approaches for exploring measurement invariance. Psychol. Bull. 1993, 114, 552. [Google Scholar] [CrossRef]
- Byrne, B.M.; Shavelson, R.J.; Muthén, B. Testing for the Equivalence of Factor Covariance and Mean Structures: The Issue of Partial Measurement Invariance. Psychol. Bull. 1989, 105, 456–466. [Google Scholar] [CrossRef]
- Rupp, A.A.; Templin, J.; Henson, R.A. Diagnostic Measurement: Theory, Methods, and Applications; Guilford Press: New York, NY, USA, 2010. [Google Scholar]
- Templin, J.; Bradshaw, L. Hierarchical diagnostic classification models: A family of models for estimating and testing attribute hierarchies. Psychometrika 2014, 79, 317–339. [Google Scholar] [CrossRef] [PubMed]
- Almond, R.G.; DiBello, L.V.; Moulder, B.; Zapata-Rivera, J.D. Modeling diagnostic assessments with Bayesian networks. J. Educ. Meas. 2007, 44, 341–359. [Google Scholar] [CrossRef]
- Plummer, M. JAGS: A program for analysis of Bayesian graphical models using Gibbs sampling. In Proceedings of the 3rd International Workshop on Distributed Statistical Computing, Vienna, Austria, 20–22 March 2003; Volume 124, pp. 1–10. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Bradshaw, L.; Izsak, A.; Templin, J.; Jacobson, E. Diagnosing teachers’ understandings of rational numbers: Building a multidimensional test within the diagnostic classification framework. Educ. Meas. Issues Pract. 2014, 33, 2–14. [Google Scholar] [CrossRef]
- Tatsuoka, K.K. Rule space: An approach for dealing with misconceptions based on item response theory. J. Educ. Meas. 1983, 20, 345–354. [Google Scholar] [CrossRef]
- Templin, J.; Hoffman, L. Obtaining diagnostic classification model estimates using Mplus. Educ. Meas. Issues Pract. 2013, 32, 37–50. [Google Scholar] [CrossRef]
- Chung, M. Estimating the Q-Matrix for Cognitive Diagnosis Models in a Bayesian Framework. Ph.D. Thesis, Columbia University, New York, NY, USA, 2014. [Google Scholar]
- Chen, Y.; Liu, Y.; Culpepper, S.A.; Chen, Y. Inferring the number of attributes for the exploratory DINA model. Psychometrika 2021, 86, 30–64. [Google Scholar] [CrossRef]
- Culpepper, S.A. Estimating the Cognitive Diagnosis Q Matrix with Expert Knowledge: Application to the Fraction-Subtraction Dataset. Psychometrika 2019, 84, 333–357. [Google Scholar] [CrossRef]
- Chung, M. A Gibbs sampling algorithm that estimates the Q-matrix for the DINA model. J. Math. Psychol. 2019, 93, 102275. [Google Scholar] [CrossRef]
- Junker, B.W.; Sijtsma, K. Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Appl. Psychol. Meas. 2001, 25, 258–272. [Google Scholar] [CrossRef]
- Hartz, S.M. A Bayesian Framework for the Unified Model for Assessing Cognitive Abilities: Blending Theory with Practicality; University of Illinois at Urbana-Champaign: Urbana-Champaign, IL, USA, 2002. [Google Scholar]
- Henson, R.A.; Templin, J.L.; Willse, J.T. Defining a family of cognitive diagnosis models using log-linear models with latent variables. Psychometrika 2009, 74, 191. [Google Scholar] [CrossRef]
- de La Torre, J. The generalized DINA model framework. Psychometrika 2011, 76, 179–199. [Google Scholar] [CrossRef]
- Sessoms, J.; Henson, R.A. Applications of diagnostic classification models: A literature review and critical commentary. Meas. Interdiscip. Res. Perspect. 2018, 16, 1–17. [Google Scholar] [CrossRef]
- Tabatabaee-Yazdi, M. Hierarchical diagnostic classification modeling of reading comprehension. SAGE Open 2020, 10, 2158244020931068. [Google Scholar] [CrossRef]
- Ma, W.; Wang, C.; Xiao, J. A Testlet Diagnostic Classification Model with Attribute Hierarchies. Appl. Psychol. Meas. 2023, 47, 183–199. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Wang, J. On the sequential hierarchical cognitive diagnostic model. Front. Psychol. 2020, 11, 579018. [Google Scholar] [CrossRef]
- Wang, C.; Lu, J. Learning attribute hierarchies from data: Two exploratory approaches. J. Educ. Behav. Stat. 2021, 46, 58–84. [Google Scholar] [CrossRef]
- Hu, B.; Templin, J. Using diagnostic classification models to validate attribute hierarchies and evaluate model fit in Bayesian networks. Multivar. Behav. Res. 2020, 55, 300–311. [Google Scholar] [CrossRef]
- Ma, C.; Ouyang, J.; Xu, G. Learning latent and hierarchical structures in cognitive diagnosis models. Psychometrika 2023, 88, 175–207. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning, and Inference; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Culbertson, M.J. Bayesian networks in educational assessment: The state of the field. Appl. Psychol. Meas. 2016, 40, 3–21. [Google Scholar] [CrossRef]
- Almond, R.G.; Mislevy, R.J.; Steinberg, L.S.; Yan, D.; Williamson, D.M. Bayesian Networks in Educational Assessment; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Liu, Y.; Yin, H.; Xin, T.; Shao, L.; Yuan, L. A comparison of differential item functioning detection methods in cognitive diagnostic models. Front. Psychol. 2019, 10, 1137. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.C. Assessment of differential item functioning under cognitive diagnosis models: The DINA model example. J. Educ. Meas. 2015, 52, 28–54. [Google Scholar] [CrossRef]
- George, A.C.; Robitzsch, A. Multiple group cognitive diagnosis models, with an emphasis on differential item functioning. Psychol. Test Assess. Model. 2014, 56, 405. [Google Scholar]
- de La Torre, J.; Lee, Y.S. A note on the invariance of the DINA model parameters. J. Educ. Meas. 2010, 47, 115–127. [Google Scholar] [CrossRef]
- Paulsen, J.; Svetina, D.; Feng, Y.; Valdivia, M. Examining the impact of differential item functioning on classification accuracy in cognitive diagnostic models. Appl. Psychol. Meas. 2020, 44, 267–281. [Google Scholar] [CrossRef] [PubMed]
- Hou, L.; de la Torre, J.; Nandakumar, R. Differential item functioning assessment in cognitive diagnostic modeling: Application of the Wald test to investigate DIF in the DINA model. J. Educ. Meas. 2014, 51, 98–125. [Google Scholar] [CrossRef]
- Svetina, D.; Feng, Y.; Paulsen, J.; Valdivia, M.; Valdivia, A.; Dai, S. Examining DIF in the context of CDMs when the Q-matrix is misspecified. Front. Psychol. 2018, 9, 696. [Google Scholar] [CrossRef]
- Zhang, W. Detecting Differential Item Functioning Using the DINA Model. Ph.D. Thesis, The University of North Carolina at Greensboro, Greensboro, NC, USA, 2006. [Google Scholar]
- Li, F. A Modified Higher-Order DINA Model for Detecting Differential Item Functioning and Differential Attribute Functioning. Ph.D. Thesis, University of Georgia, Athens, GA, USA, 2008. [Google Scholar]
- Ma, W.; Terzi, R.; de la Torre, J. Detecting differential item functioning using multiple-group cognitive diagnosis models. Appl. Psychol. Meas. 2021, 45, 37–53. [Google Scholar] [CrossRef] [PubMed]
- Bozard, J.L. Invariance Testing in Diagnostic Classification Models. Ph.D. Thesis, University of Georgia, Athens, GA, Georgia, 2010. [Google Scholar]
- Sun, X.; Wang, S.; Guo, L.; Xin, T.; Song, N. Using a Generalized Logistic Regression Method to Detect Differential Item Functioning with Multiple Groups in Cognitive Diagnostic Tests. Appl. Psychol. Meas. 2023, 47, 328–346. [Google Scholar] [CrossRef] [PubMed]
- Bramlett, S.A. A Method for Detecting Measurement Invariance in the Log-linear Cognitive Diagnosis Model. Ph.D. Thesis, University of Georgia, Athens, GA, USA, 2018. [Google Scholar]
- Yu, X.; Zhan, P.; Chen, Q. Don’t worry about the anchor-item setting in longitudinal learning diagnostic assessments. Front. Psychol. 2023, 14, 1112463. [Google Scholar] [CrossRef]
- Bartholomew, D.J.; Knott, M.; Moustaki, I. Latent Variable Models and Factor Analysis: A Unified Approach; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Zhan, P.; Jiao, H.; Man, K.; Wang, L. Using JAGS for Bayesian cognitive diagnosis modeling: A tutorial. J. Educ. Behav. Stat. 2019, 44, 473–503. [Google Scholar] [CrossRef]
- Levy, R.; Mislevy, R.J. Bayesian Psychometric Modeling; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Depaoli, S. Bayesian Structural Equation Modeling; Guilford Publications: New York, NY, USA, 2021. [Google Scholar]
- Muthén, B.; Asparouhov, T. BSEM measurement invariance analysis. Mplus Web Notes 2013, 17, 1–48. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; Van Der Linde, A. Bayesian measures of model complexity and fit. J. R. Stat. Soc. Ser. B Stat. Methodol. 2002, 64, 583–639. [Google Scholar] [CrossRef]
- Millsap, R.E. Testing measurement invariance using item response theory in longitudinal data: An introduction. Child Dev. Perspect. 2010, 4, 5–9. [Google Scholar] [CrossRef]
- Ma, W.; de la Torre, J. GDINA: An R package for cognitive diagnosis modeling. J. Stat. Softw. 2020, 93, 1–26. [Google Scholar] [CrossRef]
- Robitzsch, A.; Kiefer, T.; George, A.C.; Uenlue, A.; Robitzsch, M.A. Package ‘CDM’. In Handbook of Diagnostic Classification Models; Springer: New York, NY, USA, 2022. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Referent Units, | Partitioning and Iterating, | Appropriateness, | Multiplicative Comparisons, |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 0 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 |
| 5 | 1 | 0 | 0 | 0 |
| 6 | 0 | 1 | 0 | 0 |
| 7 | 1 | 0 | 0 | 0 |
| 8 | 0 | 0 | 1 | 0 |
| 9 | 0 | 0 | 1 | 0 |
| 10 | 0 | 0 | 1 | 0 |
| 11 | 0 | 0 | 1 | 0 |
| 12 | 1 | 0 | 0 | 0 |
| 13 | 0 | 0 | 0 | 1 |
| 14 | 1 | 0 | 0 | 1 |
| 15 | 1 | 0 | 0 | 1 |
| 16 | 1 | 0 | 0 | 0 |
| 17 | 1 | 0 | 0 | 0 |
| 18 | 0 | 1 | 0 | 1 |
| 19 | 1 | 1 | 0 | 0 |
| 20 | 0 | 1 | 0 | 1 |
| 21 | 0 | 1 | 0 | 0 |
| 22 | 0 | 1 | 0 | 0 |
| 23 | 1 | 0 | 0 | 0 |
| 24 | 1 | 1 | 0 | 0 |
| 25 | 1 | 1 | 0 | 0 |
| 26 | 1 | 0 | 0 | 0 |
| 27 | 1 | 1 | 0 | 0 |
| Odds Ratio | ||||||
|---|---|---|---|---|---|---|
| Submodel | Effect | Notation | Mean (SD) | 95% HDPI | Mean (SD) | 95% HDPI |
| AP | Intercept | 0.47 (0.23) | (0.04, 0.93) | |||
| 0.16 (0.27) | (−0.38, 0.69) | 1.22 (0.34) | (0.68, 2.00) | |||
| PI | Intercept | −1.37 (0.50) | (−2.47, −0.53) | |||
| −0.07 (0.59) | (−1.16, 1.14) | 1.12 (0.89) | (0.31, 3.11) | |||
| AP Main Effect | 2.54 (0.54) | (1.59, 3.69) | ||||
| 0.21 (0.63) | (−1.06, 1.43) | 1.51 (1.04) | (0.35, 4.18) | |||
| MC | Intercept | −1.31 (0.47) | (−2.31, −0.46) | |||
| 0.43 (0.54) | (−0.57, 1.52) | 1.79 (1.18) | (0.57, 4.59) | |||
| AP Main Effect | 2.72 (0.53) | (1.77, 3.80) | ||||
| −0.11 (0.61) | (−1.33, 1.04) | 1.08 (0.69) | (0.26, 2.83) | |||
| RU | Intercept | −3.75 (0.75) | (−5.35, −2.46) | |||
| −0.87 (1.06) | (−3.03, 1.14) | 0.71 (0.91) | (0.05, 3.13) | |||
| PI Main Effect | 2.08 (0.87) | (0.41, 3.85) | ||||
| −0.13 (1.20) | (−2.59, 2.14) | 1.76 (3.22) | (0.07, 8.47) | |||
| MC Main Effect | 0.97 (0.62) | (0.06, 2.33) | ||||
| 1.31 (1.10) | (−0.85, 3.52) | 6.90 (11.66) | (0.43, 33.88) | |||
| PI × MC Interaction | 1.07 (0.83) | (−0.54, 2.73) | ||||
| −0.33 (1.26) | (−2.74, 2.24) | 1.80 (6.79) | (0.06, 9.42) | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez, A.J.; Templin, J. Approximate Invariance Testing in Diagnostic Classification Models in the Presence of Attribute Hierarchies: A Bayesian Network Approach. Psych 2023, 5, 688-714. https://doi.org/10.3390/psych5030045
Martinez AJ, Templin J. Approximate Invariance Testing in Diagnostic Classification Models in the Presence of Attribute Hierarchies: A Bayesian Network Approach. Psych. 2023; 5(3):688-714. https://doi.org/10.3390/psych5030045
Chicago/Turabian StyleMartinez, Alfonso J., and Jonathan Templin. 2023. "Approximate Invariance Testing in Diagnostic Classification Models in the Presence of Attribute Hierarchies: A Bayesian Network Approach" Psych 5, no. 3: 688-714. https://doi.org/10.3390/psych5030045
APA StyleMartinez, A. J., & Templin, J. (2023). Approximate Invariance Testing in Diagnostic Classification Models in the Presence of Attribute Hierarchies: A Bayesian Network Approach. Psych, 5(3), 688-714. https://doi.org/10.3390/psych5030045