1. Introduction
In the seminal textbook of Fischer and Molenaar (1995; [
1]), Erling B. Andersen [
2]—“asked” about “What Georg Rasch Would Have Thought about this Book”—formulated:
But Rasch would have wondered about what happened to the use of graphs. And I think he would have been quite justified in this. Could it be that we have used computers in a wrong way? Since Rasch retired from active duty, have we emphasized the power of computers to do complicated calculations and solving complicated equations over the power of the computers to make nice and illustrative graphs?
In this vein, we want to introduce an extended version of the Person–Item Map (PI Map or Wright Map, cf. [
3,
4,
5]). The PI Map is a graphical depiction of both item and person parameter estimates of an item response theory (IRT; [
6]) model. It dates back to 1979 [
7] and has gained popularity by its integration in the WinSteps software [
8]. It juxtaposes the histogram of the person with the item parameter estimates based on the fact that they share a common latent scale. Wind and Hua [
9] note that the PI Map should only be interpreted if the model fits (p. 14). However, the authors also carry out that plotting of non-fitting models might as well provide valuable hints for the reasons of the misfit.
In a test application, we gain most information about a test person when item difficulty and person ability align, but also obtain unbiased person parameter estimates with items “far away” from a respondee’s location on the latent scale (however, the standard error of the estimate increases with the distance). Analogously, we gain most information about an item when its difficulty aligns with the test persons’ abilities. The PI Map fosters the detection of such a mis-alignment. Debelak et al. (2022; [
10] term this kind of analysis “sanity check” (p. 121). Refinements—like indicating the mean and standard deviation of either distribution—allow for “optimal targeting” (e.g., [
3], p. 130). Boone et al. (2014; [
3]), for example, show how PI Maps allow for detecting redundant items (referring to items with very similar difficulty parameters), which may prove useful if one is to develop a short form of a scale; or it shows “measurement gaps” (p. 129). Wind and Hua (2022; [
9]) further point out that the spread of both the item and the person parameters also provides important information.
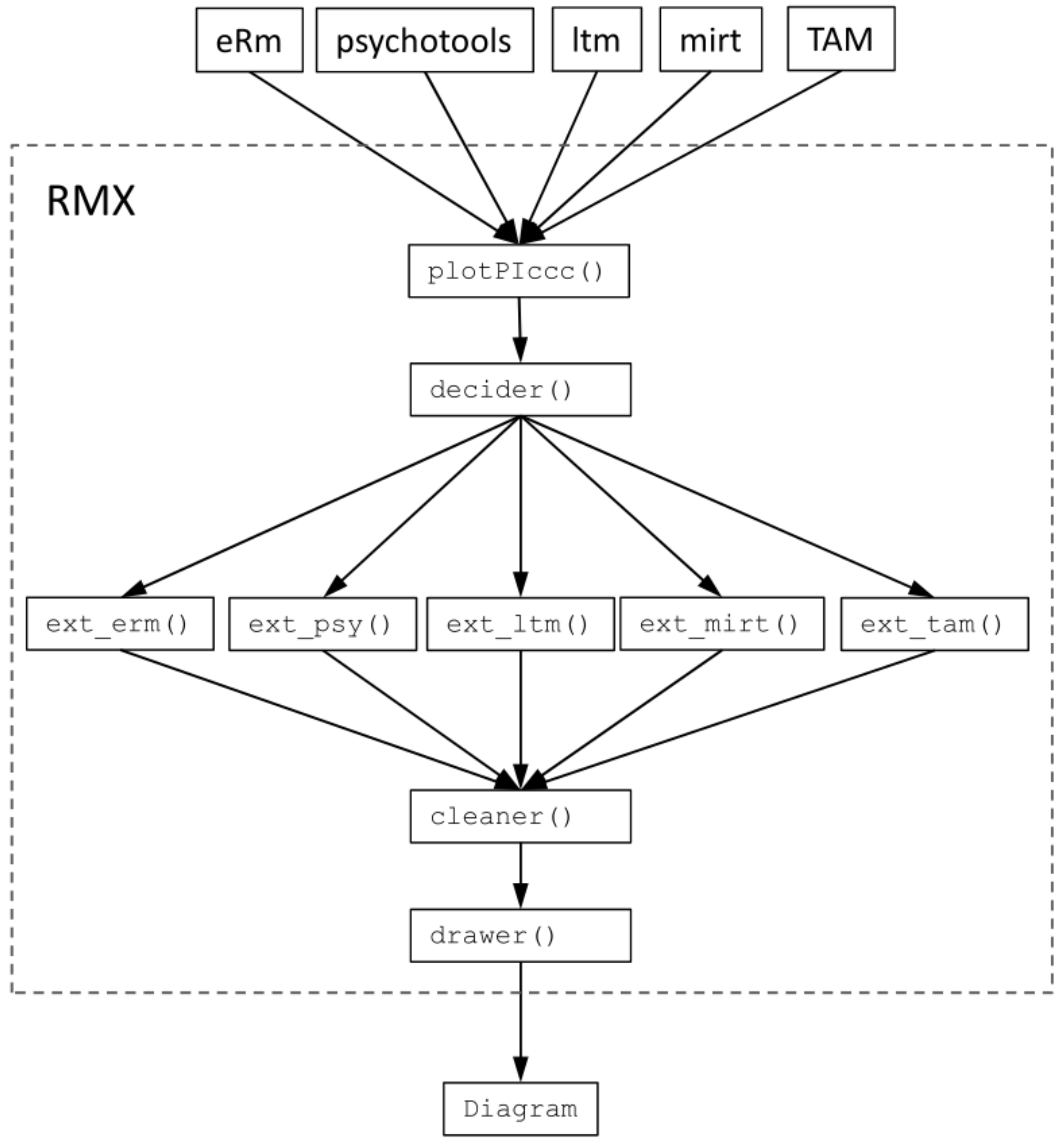
The WrightMap package [
11] of R [
12] is specialized in drawing PI Maps, supporting the output of the (non-R) program ConQuest [
13]. Some of the major R packages for IRT also support the PI Map in one form or another, for example, eRm [
14] with the
plotPImap() function, psychotools [
15] with the
piplot() function (
Figure 1), or TAM [
16] with the
IRT.WrightMap() wrapper to the WrightMap package.
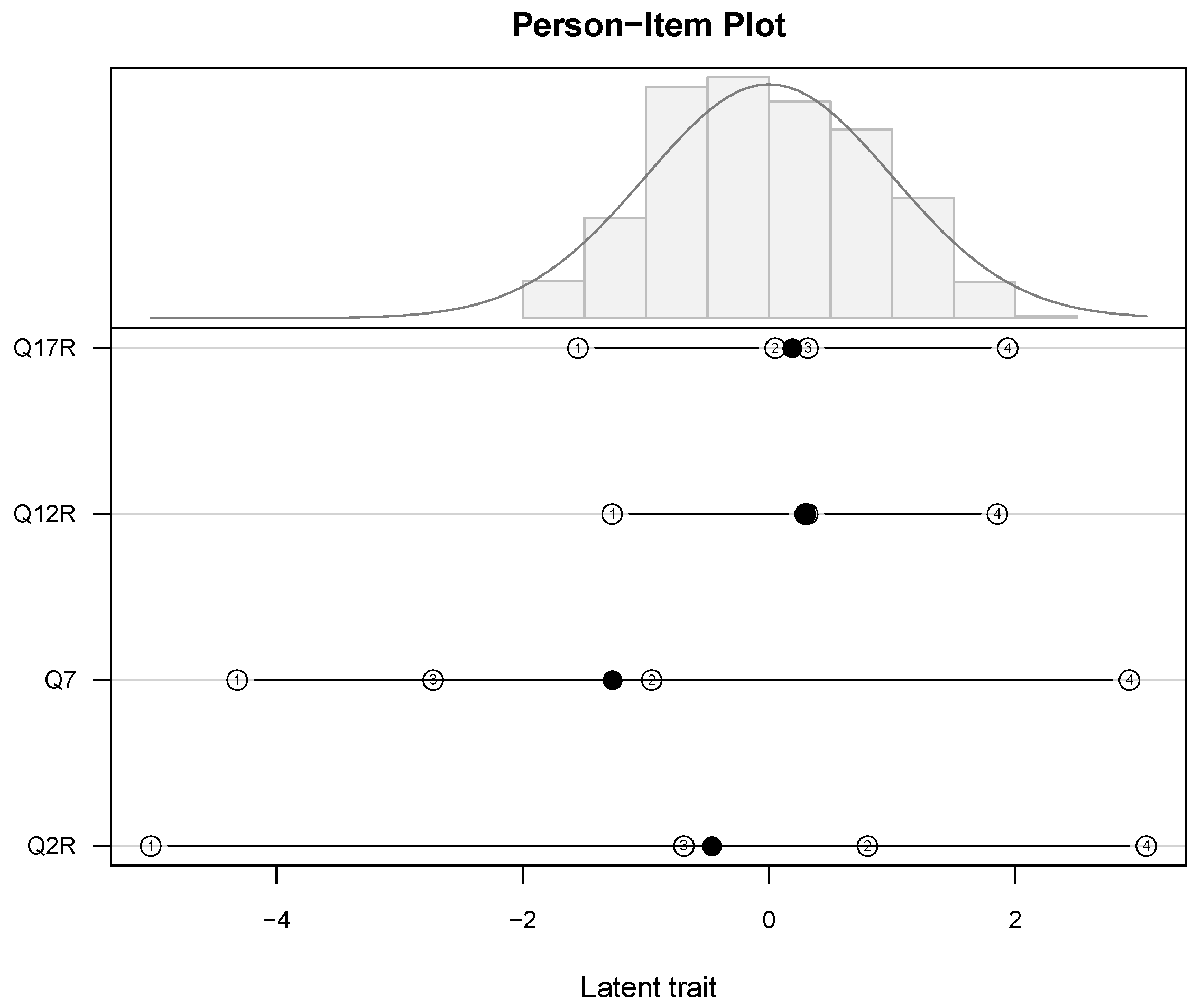
In this diagram, we find in the upper part a histogram of the person parameter estimates with the normal curve (using the mean and the standard deviation of the person parameter estimates) superimposed and in the lower part the threshold locations (numbered) along with their averages (bullets).
The diagram shows the results of a GPCM applied to the four items of the Agreeableness sub-scale of the Big Five inventory (see
Section 3 for details regarding the data). The person parameter distribution is slightly right-skewed, ranging from
to +2. Compared to the majority of the persons’ locations, the items Q17R and Q12R appear optimally placed, with the first and the last threshold covering the range of the person parameter estimates. However, the two middle thresholds of these two items are very close to each other, indicating possible problems with the middle category. In contrast, we find a much larger range of the thresholds of items Q7 and Q2R, with both items’ first thresholds below
. This could indicate that the lowest response categories were “easy” in a psychometric sense and therefore seldom used. Moreover, we find for the latter two items the middle thresholds’ positions exchanged, which might be due to problems with the middle category of the five-categorical response format.
Although this “classical” PI Map conveys important information regarding the locations of item and person parameters relative to each other, it withholds other important features of the items. For example:
- −
Only the item difficulty/category threshold parameters are drawn, which is only partial information for models involving discrimination, guessing, or laziness parameters.
- −
Although the threshold parameters are drawn for polytomous items, it is difficult to recognize which categories are likely to be chosen across the latent scale. Especially, the effects of threshold disorder are difficult to deduce.
- −
Beyond item/threshold difficulty parameters, we may also learn a lot about our items in terms of information. The category and item information curves may tell us a lot if set into relation to the person parameter distribution.
- −
Current implementations do not easily support flexibly arranging the items according to their characteristics (beyond difficulty) or, in the multidimensional case, dimensions.
- −
Current implementations do not allow for varying the area proportions used for the person parameter histogram and the item parameter part. In
Figure 1, it would be advantageous if we could increase the upper part at the expense of the item part.
In this article, we want to introduce the R package RMX (Rasch models—eXtended). It currently provides the function
RMX::plotPIccc(), which overcomes the restrictions of the “classical” PI Map in several respects. We term this modified diagram “PIccc” for it shows the Person–Item confrontation using category characteristic curves CCCs) and many other functions. Note that, although the package carries “Rasch” in its name, it does not only refer to the “Rasch Family of Models” (cf. [
1]) but also to extensions covered by the term “Item Response Theory” (which is indicated by the “X”).
3. Worked Examples
For demonstrating some of the capabilities of
RMX::plotPIccc(), we use the example dataset
big5 delivered with the RMX package. Mimicking a students’ survey, it comprises 21 items covering the Big Five (i.e., Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism; [
40]) and 1076 simulated respondents. The response format of all items was Likert-type, with the categories “very inapplicable”, “rather inapplicable”, “neither-nor”, “rather true”, and “very true” (translated from the German original).
The first example (Listing 1) shows the diagram of a GPCM evaluated with psychotools using the default options of RMX::plotPIccc():
| Listing 1. Example of a GPCM with psychotools using the Agreeableness items. |
| library(RMX) |
| library(psychotools) |
| mod1 = psychotools::gpcmodel(big5[,c(2,7,12,17)]) |
| RMX::plotPIccc(mod1) |
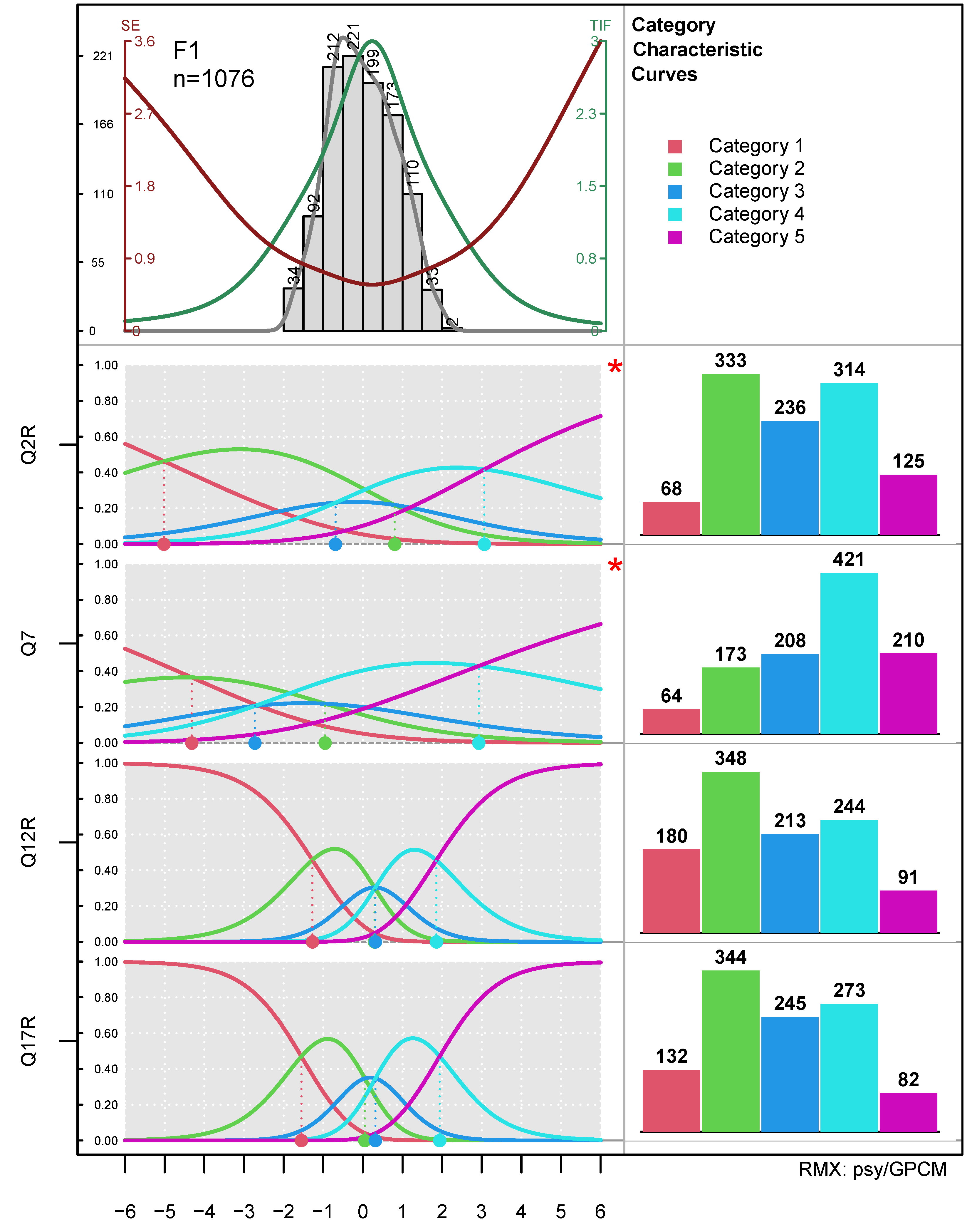
In
Figure 3, we find four areas of output: the top left segment shows the person parameter histogram, here with the default option
pplab="abs" for absolute frequencies (alternatively
pplab="rel" for percentages or
pplab="dens" for the kernel density estimates). The green line is the test information function (TIF) and the red line the standard error (SE). Additionally, if only a subset of items is used, dashed lines indicate the TIF and the SE of the selected items in the respective colors. The top right segment holds the legend for the one-function/several-items mode and the category frequency barchart for the one-item/several-functions mode (see
Figure 4 for the latter). The lower left segment shows the item-related functions, i.e., the CCCs by default in the one-function/several-items case or the selected functions in the one-item/several-functions case. The lower right segment shows the category response frequency barcharts of each item in the one-function/several-items mode and the legend of the respective function in the one-item/several-functions mode. The upper : lower and left : right proportions can be adapted with the
funhprop= and the
funwprop= option, each taking decimal values between zero and one. Values of zero or one for either option will switch on/off the entire regions so that each of the four segments can be drawn alone.
The diagram in
Figure 3 is based on the same data as used in
Figure 1. Note that the items are ordered from top to bottom (i.e., reversed compared to
Figure 1), thus following the ordering of the items. The CCCs of this diagram immediately show that the spread of the thresholds of items Q2R and Q7 (observed in
Figure 1) is due to the low discrimination of these two items (
and
). Again, we find thresholds 2 and 3 reversed (indicated by asterisks), and we can confirm the suspicion from
Figure 1 that the lowest categories of these two items were barely used. From the CCCs, we also see that the middle category was at no point of the latent continuum the most attractive one. Additionally, we see that the TIF of this sub-scale has a strong peak, which went undetected in the classical variant of the PI Map.
The next example demonstrates the one-item/multiple-functions mode. We estimate a GPCM for the Neuroticism subscale of the Big Five example dataset (i.e., items 4, 9, 14, and 19; Listing 2).
| Listing 2. Example of a GPCM using TAM. |
| library(TAM) |
| |
| mod2a = TAM::tam.mml( big5[,c(4,9,14,19)],verbose=FALSE) # Neuroticism |
| mod2b = TAM::tam.mml.2pl(big5[,c(4,9,14,19)],verbose=FALSE) |
| |
| RMX::plotPIccc(mod2a,type=c("CCC","TCC","BIF"),isel=2,infomax=1.05) |
| RMX::plotPIccc(mod2b,type=c("CCC","TCC","BIF"),isel=2,infomax=1.05) |
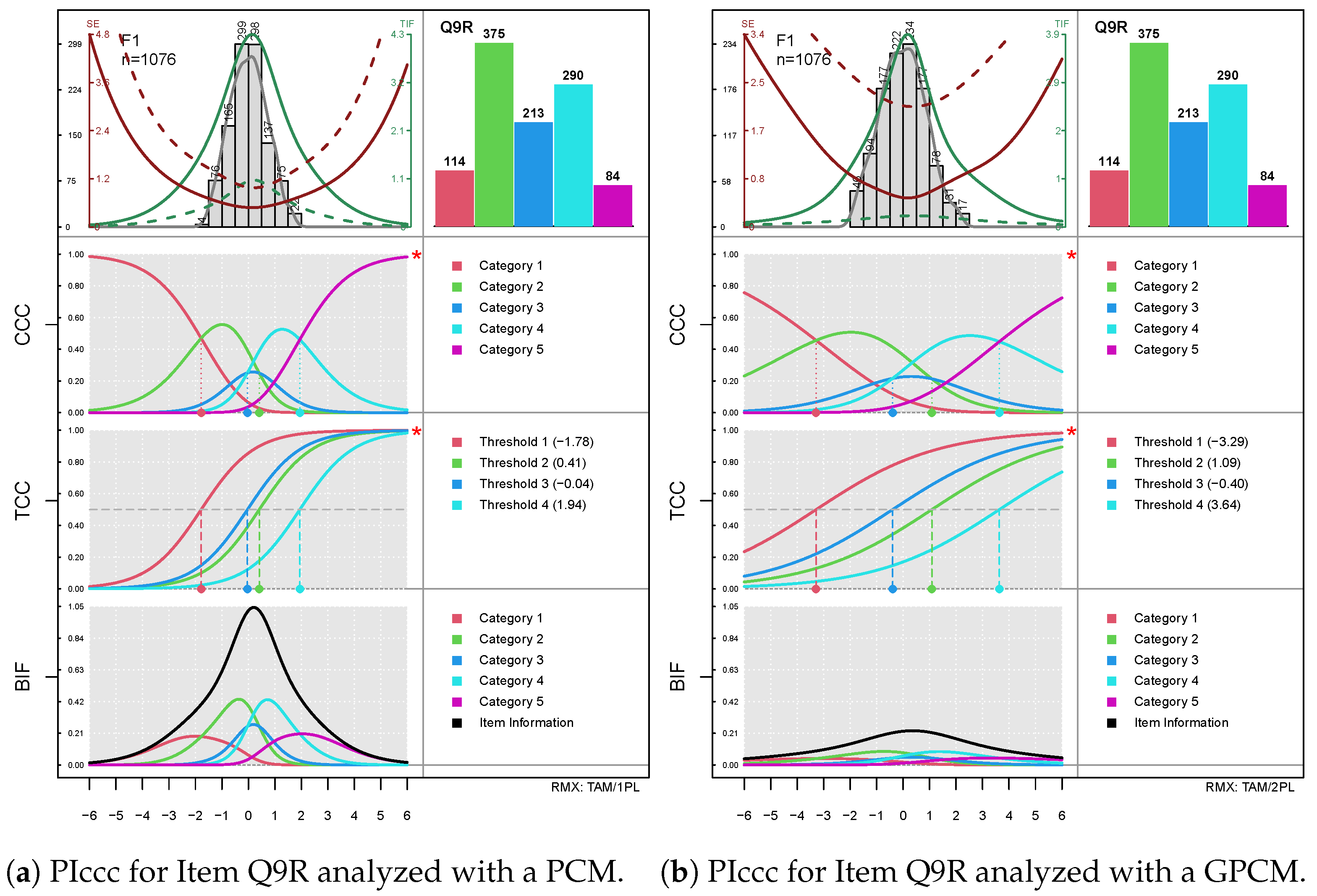
Figure 4 shows the output of the multiple-type diagram for item
Q9R of the Neuroticism subscale. In this mode, the barchart with the category frequencies is shifted to the top and the legends are now placed to the right of each diagram. In the top left area, we now see not only the TIF and SE lines (solid) but also the respective dashed lines for the selected item, as mentioned above. The latter allow for comparing the item’s contribution to the test information. Note that the arrangement of the three functions follows the ordering in the
type= option.
By comparing the two diagrams, we see clearly the differences in the item’s discrimination parameter, which is 1 for the PCM and
for the GPCM. Accordingly, the CCCs and TCCs in the right diagram (
Figure 4b) are clearly flatter than those in the left one (
Figure 4a). Interestingly, the maximum item information also differs remarkably (1.04 for the PCM vs. 0.23 for the GPCM; we used the
infomax= option to equalize the scales of the two information functions). Here, we see clearly that the improvement in fit due to varying slopes comes at the cost of information. The item shows a threshold disordering for both models, which is indicated by the red asterisks. Thus, the weaknesses of the item become visible at a glance. Moreover, the comparison of the sSE curves of this item (dotted red lines) shows that the GPCM-based standard errors are remarkably larger than those based on the PCM, which is a result of the lower discrimination parameter of this item.
Next, we demonstrate the output of a multidimensional diagram using the classical form (Listing 3).
| Listing 3. Example of a multidimensional GPCM using mirt and the Big Five example dataset. |
| |
| big5mod = "O = 5,10,15,20,21 |
| C = 3,8,13,18 |
| E = 1,6,11,16 |
| A = 2,7,12,17 |
| N = 4,9,14,19 |
| COV=O*C*E*A*N" |
| big5res = mirt::mirt(big5,big5mod,itemtype="gpcm",method="MHRM") |
| big5est = RMX::plotPIccc(big5res,classical=TRUE, lmar=3, ylas=2, |
| funhprop=0.6,dencol=NA,usedimcol=TRUE, |
| dimcol=c("#bef7ff", "#a0dcff", "#82c2ff", "#63a7ff", "#458cff"), |
| tifcol=grey(0.6), secol="dodgerblue4") |
| |
The lmar=3 and ylas=2 options allowed for printing the item labels, which have been automatically extended by the dimension labels. With the option usedimcol=TRUE, we colored the items’ dots according to their respective latent dimension. Note further that, in the classical=TRUE variant, threshold disordering is indicated with dotted lines.
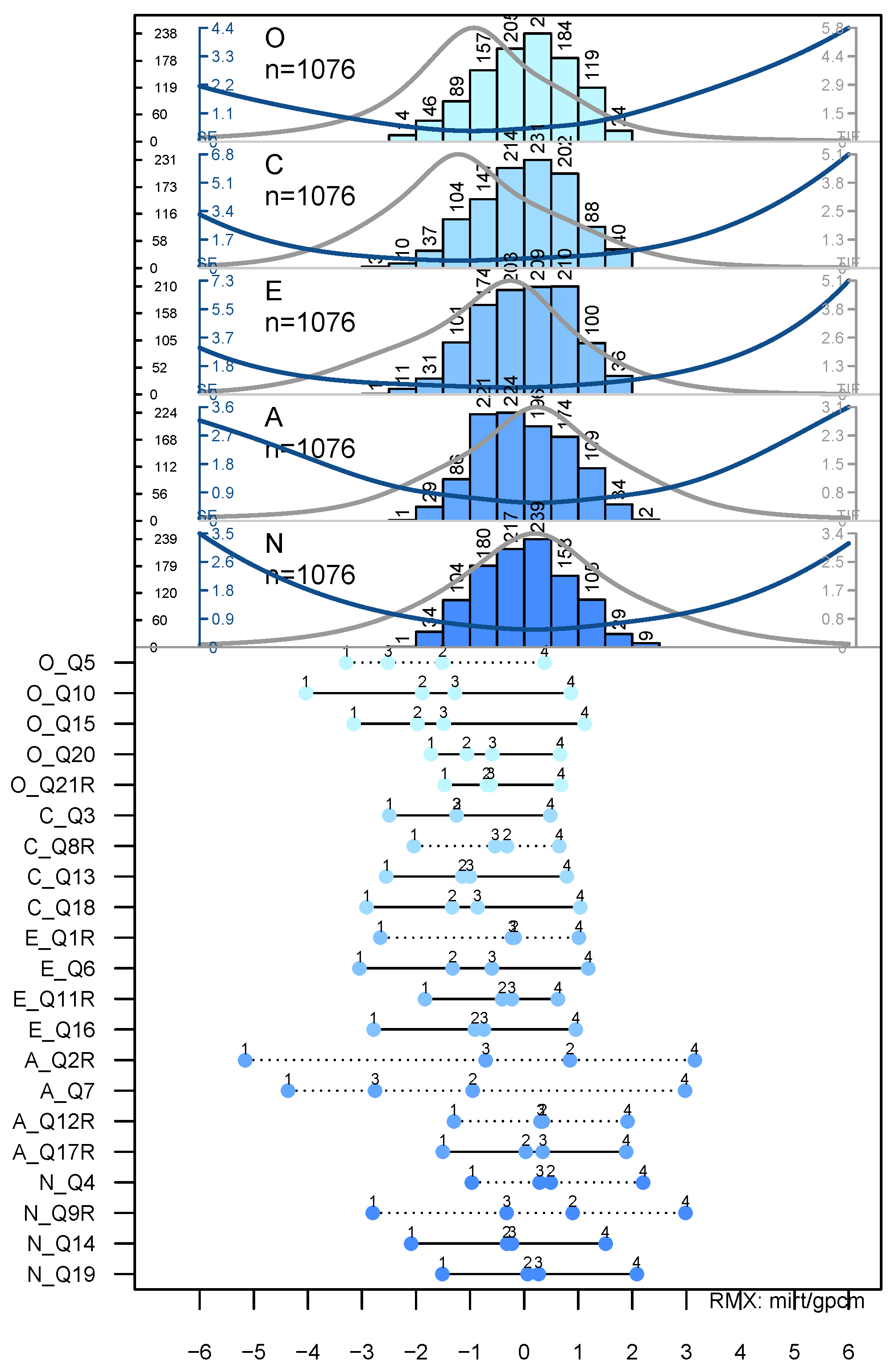
From
Figure 5, we learn that the items’ thresholds exceed the range of the person parameters and that eight items show threshold disordering. Another interesting feature becomes visible here: the combined depiction of the person parameter histogram and the TIF allows for examining whether the instrument (here, sub-scale) measures best where the respondents are located. Such a comparison could be useful for clinical applications, for example, to check whether the instrument works better for inpatients or for screening purposes in the general population.
For publishing, one could redirect the output to a suitably formatted file with the
pdf() or
png() function of R (the former yielding scalable images). That way, the user may choose the optimal window proportions (
width=,
height=), which is the reason why the plot opens by default in an external window (RStudio/posit [
41] users may set
extwin=FALSE to use the internal graphics viewer). Internally,
RMX::plotPIccc() uses for the external graphics window the generic
dev.new() function of R with the
noRStudioGD=TRUE option set. The
extwin=FALSE option is also required if one uses
RMX::plotPIccc() for compiling a markdown output, which is readily supported by RStudio/posit. Additionally, the option
resetpar= (default:
TRUE) controls, whether the graphic parameters (set with
par()) are restored after the drawing has finished. Setting to
FALSE allows for further refinements of the diagram (e.g., additional text, arrows, etc.).
The
RMX::plotPIccc() function returns (invisibly) a list with all values used for plotting, which may be useful for publishing the results. Listing 4 shows, exemplarily, how to build a table for
LATEX using the
xtable package [
42] of R using the return object
big5est from Listing 3:
| Listing 4. Processing the return object of the analysis of Listing 3. |
| |
| xtable::xtable(big5est$N$thresholds) |
| \begin{table}[H] |
| \centering |
| \begin{tabular}{rrrrr}\hline |
| & Q4 & Q9R & Q14 & Q19 \\\hline |
| 1 & -0.97 & -2.79 & -2.09 & -1.51 \\ |
| 2 & 0.49 & 0.90 & -0.32 & 0.07 \\ |
| 3 & 0.29 & -0.32 & -0.22 & 0.27 \\ |
| 4 & 2.20 & 2.99 & 1.51 & 2.09 \\\hline |
| \end{tabular} |
| \end{table} |
| |
This code yields the following
Table 5 (kept in its original format, improvements ad lib):
Non-
LATEX users may as well use different packages (e.g., knitr [
43,
44], pandoc [
45], sjplot [
46], R2wd [
47], etc.) to transform the output into a form compatible with one’s favorite text processing software.
4. Discussion
In this article, we introduced the RMX package, which provides the PIccc, an extended Person–Item Map. In addition to plotting the estimated difficulty and threshold parameters, it also supports a set of item-related functions, like the CCC, the TCC, and various information functions. This allows for a more efficient assessment of the items’ functioning and the alignment of person and item parameters.
Aside from the multi-purpose PIccc, the RMX::plotPIccc() function may also be used to draw simple diagrams of a single item’s CCC, TCC, CIF, IIF, or the category frequencies barplot only by using the isel=, funhprop=, and funwprop= options. Thus, the package offers enormous flexibility by covering functionality, which may require more programming effort in the other packages, if supported at all. It further improves some of the other packages’ functions in terms of graphical options.
In contrast to the classical PI Map, the new PIccc diagram works best with only a few items (except, of course, for classical=TRUE). This may require to split items across multiple diagrams, e.g., according to sub-scales or other substantive criteria. However, the alternative (so far) was to plot each, say, CCC separately per item (possibly gathering them in a plot matrix), which makes comparisons more difficult, not to mention the limited comparability to the person parameter distribution. Therefore, the presented solution seems to be a major step forward in this respect.
4.1. Threshold (Dis)Ordering in the NRM
When analyzing items with the NRM, threshold disordering is indicated by the CBDs rather than the intersection points like in the (G)PCM ([
48], but opposed by [
49]). This is exactly what the PIccc diagram draws with the option
type="TCC", thus allowing for easily detecting threshold disordering. Importantly, the
type="CCC" will
not allow for detecting threshold disordering for the NRM as a category could indeed lack a range on the latent continuum, along which it has a larger probability to be chosen than any other category, although thresholds are ordered. This is in contrast to the (G)PCM, where threshold disordering is always associated with categories “vanishing” behind others. To our knowledge,
RMX::plotPIccc() is the first program directly implementing a graphical disorder detection feature for the NRM.
4.2. Sorting Items in the NRM
The
RMX::plotPIccc() function allows for sorting polytomous items according to several criteria, including the discrimination parameters. For the NRM, this is not possible in a straightforward manner because it estimates a discrimination parameter for each category of an item. Therefore, we use the mean of the discrimination parameters per item for sorting. Alternatively, sorting could also be achieved by using the item-wise (i.e., single-indexed) discrimination parameter as defined by Thissen et al. (2010; [
34]), which is planned for a further release of RMX.
4.3. Estimating the Person Parameters
Regarding the person parameters, we have to distinguish the CML- and the MML-based methods ([
50]), with eRm and psychotools supporting the former and ltm, mirt, and TAM the latter. In the CML context, no person parameter estimates can be obtained for perfect and zero scores as they tend to add or subtract infinity, respectively (The same applies to the item parameter estimation; i.e., items with zero or perfect scores will also require special treatment, but this is already handled in the originating packages). However, making certain additional assumptions allows for generating surrogate values. The eRm package applies a spline interpolation to the score-
function and extrapolates estimates for zero and maximum possible score using the
extrapolate=TRUE option in the
coef() function. In contrast, the psychotools package will just return
NA for respondents with zero or perfect scores.
We encounter a similar situation for datasets containing missing values. The eRm routines evaluate each missing pattern separately and return a vector with the respective estimates for all respondents. In contrast, psychotools also return NA if a response vector contains missing values. Therefore, the N= shown in the person parameter distribution area may differ from the actual sample size if the originating package was psychotools. In contrast, the MML-based packages can handle zero and perfect scores.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}