
Use Cases and Methods of Virtual ADAS/ADS Calibration in Simulation



Abstract
:1. Introduction and Related Work
2. Modular Virtual Testing Framework

2.1. Scenario and Calibration Parameters
2.2. Evaluation Parameters

2.3. Test Case Definition and Sampling
| Algorithm 1: PSO Calibration Test Case Sampling |
  |
| Algorithm 2: Particle Processing |
  |
3. Use Cases and Methods of Virtual Calibration
3.1. Use Case 1: Calibration for Optimal Behavior in a Large Set of Scenarios

3.2. Use Case 2: Calibration for Different System Modes

3.3. Use Case 3: Calibration for Different Customer Groups and Markets

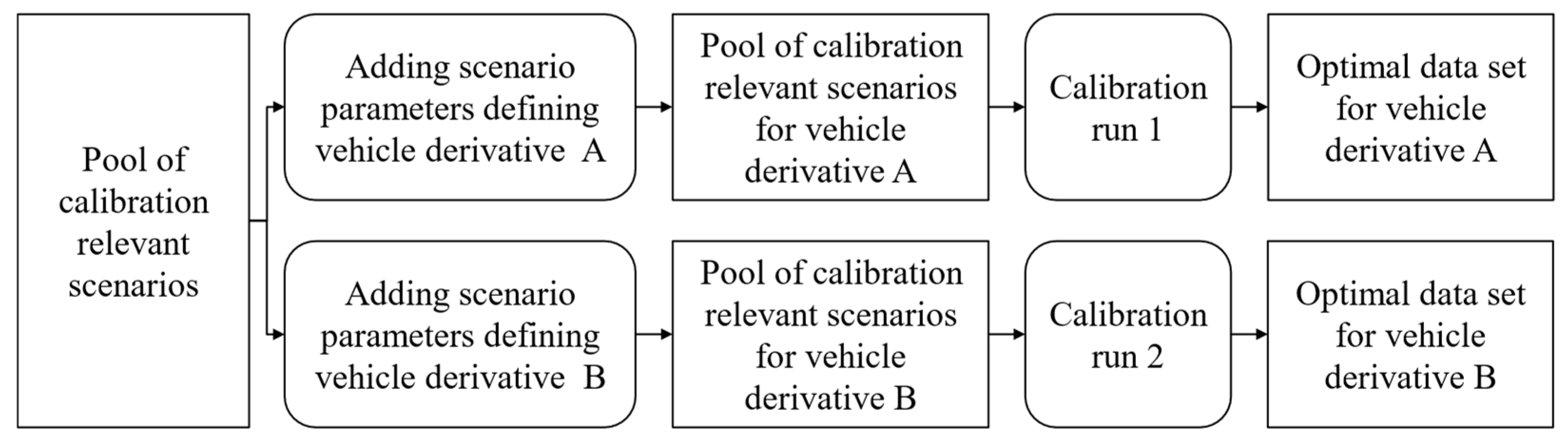
3.4. Use Case 4: Calibration for Different Vehicle Derivatives

3.5. Use Case 5: Calibration for Different Sub-Areas of the ODD

4. Implementation and Evaluation

4.1. Implementation and Evaluation of Multi-Scenario-Level Method for Use Case 1
- Distance in m between the target vehicle and the ego vehicle when cut-in is performed by the target vehicle (driving environment cluster)
- Relative velocity in km/h between target velocity and ego velocity during and after target cut-in (driving environment cluster)
- Lane change duration in s of the target vehicle (driving environment cluster)
- Desired velocity in km/h set up by the driver (driver cluster)
- Desired time gap in s set up by driver (driver cluster)
- Delay in s of perception hardware and software of the ego vehicle (ego vehicle cluster)



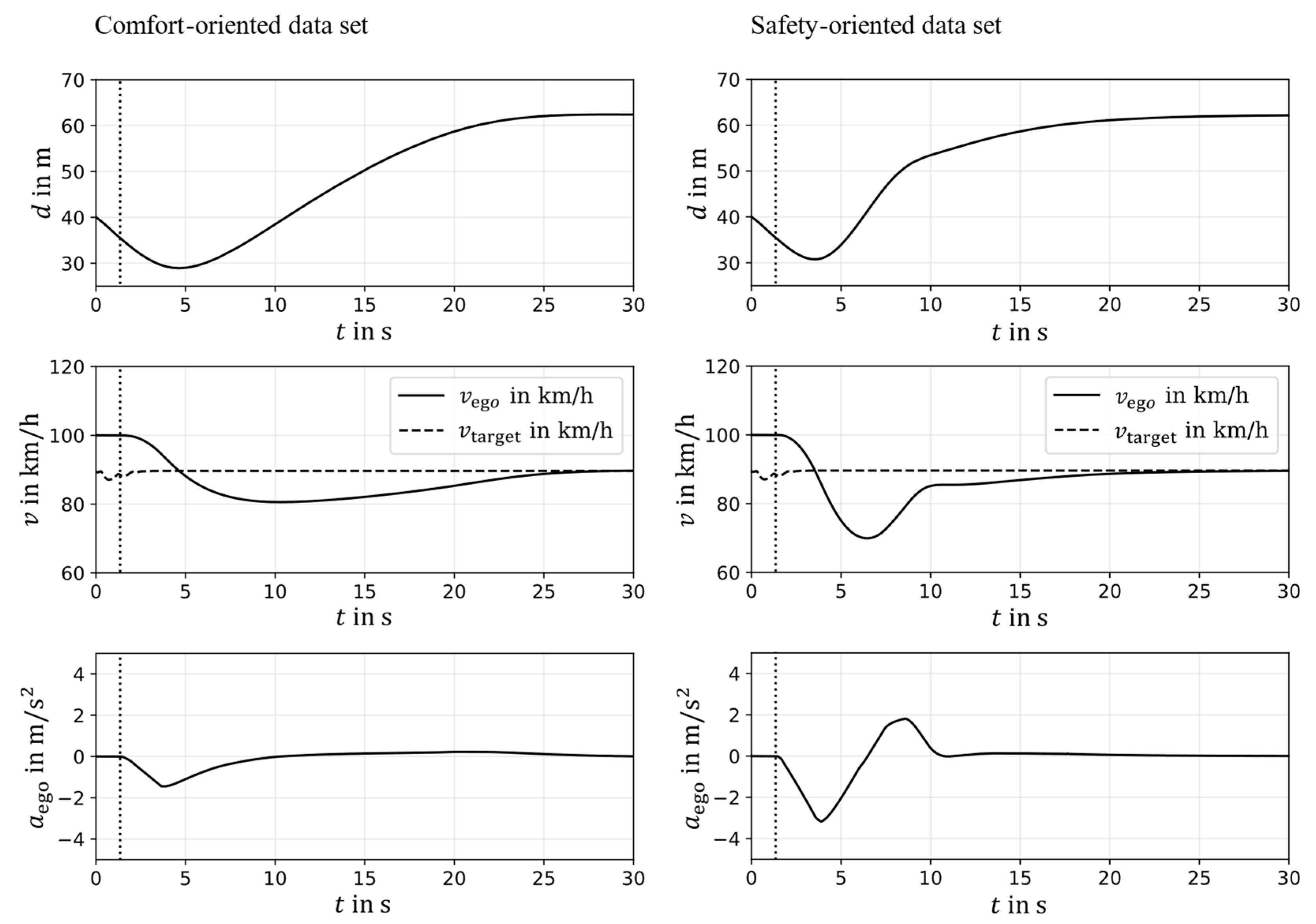
4.2. Implementation and Evaluation of Different Performance Rating Metrics for Use Cases 2 and 3
- Mean longitudinal braking deceleration in of ego vehicle during cut-in
- Maximal longitudinal braking deceleration in of ego vehicle during cut-in
- Minimal longitudinal jerk in of ego vehicle during cut-in
- Maximal longitudinal jerk in of ego vehicle during cut-in
- Minimal time to collision in s between ego vehicle and target vehicle during cut-in ( with being the distance and being the relative velocity between the two vehicles)
- Risk time in s, which is the duration of the ego vehicle violating the legislative minimum distance to the target vehicle
- Velocity immersion in , which is the relative velocity at which the ego vehicle immerses below the velocity of the target vehicle during braking
- Minimal time gap in s between ego vehicle and target vehicle during cut-in ( with being the distance between the two vehicles and being the velocity of the ego vehicle)

4.3. Implementation and Evaluation of Different Vehicle Models for Use Case 4

4.4. Implementation and Evaluation of Division of Scenarios in ODD Sub-Areas for Use Case 5

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country Road | City | Highway | |
|---|---|---|---|
| 0.15 | 0.46 | 0.51 | |
| 0.36 | 0.15 | 0.33 | |
| 0.7 | 0.61 | 0.72 | |
| 1.27 | 0.42 | 1.41 |
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Concrete Target Cut-in Scenarios to Be Considered in Example Use Case
| Concrete Scenario Description | ||||||
|---|---|---|---|---|---|---|
| Representative country road scenario | 40 | −10 | 4 | 100 | 2.5 | 0.1 |
| Representative city scenario | 20 | −5 | 4 | 50 | 2.5 | 0.1 |
| Representative highway scenario | 60 | −20 | 4 | 140 | 2.5 | 0.1 |
| Additional country road scenario | 30 | −5 | 4 | 100 | 2.5 | 0.1 |
| Additional city scenario | 15 | −2 | 4 | 50 | 2.5 | 0.1 |
| Additional highway scenario | 50 | −5 | 4 | 140 | 2.5 | 0.1 |
| Challenging country road scenario | 30 | −20 | 4 | 100 | 2.5 | 0.1 |
| Challenging city scenario | 15 | −10 | 4 | 50 | 2.5 | 0.1 |
| Challenging highway scenario | 50 | −30 | 4 | 140 | 2.5 | 0.1 |
Appendix B. Evaluation Metrics Used in Implementation
| Performance Rating Aspect | Direct KPI | Quality Loss Function | Parameters of Quality Loss Function | Performance Rating Aspect Weight |
|---|---|---|---|---|
| Comfort | Asymmetric target value | 4 | ||
| Asymmetric target value | ||||
| Minimizing | ||||
| Minimizing | ||||
| Safety | Asymmetric target value | 2 | ||
| Asymmetric target value | ||||
| Naturalness of driving | Asymmetric target value | 1 | ||
| Asymmetric target value |
| Performance Rating Aspect | Direct KPI | Quality Loss Function | Parameters of Quality Loss Function | Performance Rating Aspect Weight |
|---|---|---|---|---|
| Comfort | Asymmetric target value | 1 | ||
| Asymmetric target value | ||||
| Minimizing | ||||
| Minimizing | ||||
| Safety | Asymmetric target value | 2 | ||
| Asymmetric target value | ||||
| Naturalness of driving | Asymmetric target value | 1 | ||
| Asymmetric target value |
References
- SAE International. J3016_202104—Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles; SAE International: Warrendale, PA, USA, 2021. [Google Scholar] [CrossRef]
- Hakuli, S.; Krug, M. Virtuelle Integration. In Handbuch Fahrerassistenzsysteme; Springer Vieweg: Wiesbaden, Germany, 2015; pp. 125–138. ISBN 978-3-558-05733-5. [Google Scholar]
- PAS 1883:2020; Operational Design Domain (ODD) Taxonomy for an Automated Driving System (ADS)—Specification. The British Standards Institution: London, UK, 2020; ISBN 978-0-539-06735-4.
- Ulbrich, S.; Menzel, T.; Raschka, A.; Schuldt, F.; Maurer, M. Definition der Begriffe Szene, Situation und Szenario für das Automatisierte Fahren. In Fahrerassistenzworkshop; Walting, Germany, 2015. [Google Scholar]
- ISO 21448:2022-06; Road Vehicles—Safety of the Intended Functionality. ISO: Geneva, Switzerland, 2022.
- Wilhelm, U.; Ebel, S.; Weitzel, A. Funktionale Sicherheit und ISO 26262—Validierung von Systemen mit funktionaler Unzulänglichkeit. In Handbuch Fahrerassistenzsysteme; Springer Vieweg: Wiesbaden, Germany, 2015; pp. 101–102. ISBN 978-3-658-05733-6. [Google Scholar]
- Langner, J.; Bauer, K.-L.; Holzäpfel, M.; Sax, E. A Process Reference Model for the Virtual Application of Predictive Control Features. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020. [Google Scholar] [CrossRef]
- Euro NCAP. “2020 Assisted Driving Tests”. Available online: www.euroncap.com/en/vehicle-safety/safety-campaigns/2020-assisted-driving-tests (accessed on 10 February 2023).
- King, C.; Ries, L.; Langner, J.; Sax, E. A Taxonomy and Survey on Validation Approaches for Automated Driving Systems. In Proceedings of the IEEE International Symposium on Systems Engineering (ISSE), Vienna, Austria, 12 October–12 November 2020. [Google Scholar] [CrossRef]
- Liesner, L. Automatisierte Funktionsoptimierung von Adaptive Cruise Control. Ph.D. Thesis, Shaker Verlag, Düren, Germany, 2017. [Google Scholar]
- Pawellek, T. Objektivierung von Abstandsregelstrategien. Ph.D. Thesis, Shaker Verlag, Düren, Germany, 2019. [Google Scholar]
- Beglerović, H.; Ravi, A.; Wikström, N.; Koegeler, H.-M.; Leitner, A.; Holzinger, J. Model-based safety validation of the automated driving functio highway pilot. In 8th International Munich Chassis Symposium; Springer Fachmedien Wiesbaden: Munich, Germany, 2017. [Google Scholar] [CrossRef]
- Bach, J.; Holzäpfel, M.; Otten, S.; Sax, E. Reactive-Replay Approach for Verification and Validation of Closed-Loop Control Systems in Early Development; WCX™ 17: SAE World Congress Experience; Detroit, MI, USA, 2017. [Google Scholar] [CrossRef]
- Markofsky, M.; Schramm, D. A modular framework for virtual calibration and validation of driver assistance systems. In 13th International Munich Chassis Symposium; Munich, Germany, 2022. [Google Scholar]
- Bagschik, G.; Menzel, T.; Reschka, A.; Maurer, M. Szenarien für Entwicklung, Absicherung und Test von automatisierten Fahrzeugen. In Workshop Fahrerassistenzsysteme und Automatisiertes Fahren; Walting, Germany, 2017. [Google Scholar]
- Bock, J.; Krajewski, R.; Eckstein, L.; Klimke, J.; Sauerbier, J.; Zlocki, A. Data Basis for Scenario-Based Validation of HAD on Highways. In Proceedings of the 27th Aachen Colloquium Automobile and Engine Technology, Aachen, Germany, 8–10 October 2018. [Google Scholar]
- PEGASUS Projekt. Schlussbericht für das Gesamtprojekt PEGASUS. Available online: www.pegasusprojekt.de (accessed on 5 August 2021).
- Pfeffer, R. Szenariobasierte Simulationsgestützte Funktionale Absicherung Hochautomatisierter Fahrfunktionen Durch Nutzung von Realdaten. Ph.D. Thesis, Karlsruher Institut für Technologie (KIT), Karlsruhe, Germany, 2020. [Google Scholar] [CrossRef]
- Feilhauer, M. Simulationsgestützte Absicherung von Fahrerassistenzsystemen; Universität Stuttgart: Stuttgart, Germany, 2018. [Google Scholar] [CrossRef]
- Pütz, A.; Zlocki, A.; Bock, J.; Eckstein, L. System validation of highly automated vehicles with a database of relevant traffic scenarios. In Proceedings of the 12th ITS European Congress, Strasbourg, France, 19–22 June 2017. [Google Scholar]
- Nesensohn, J.; Lefevre, S.; Allgeier, D.; Schick, B.; Fuhr, F. An Efficient Evaluation Method for Longitudinal Driver Assistance System within a Consistent KPI based Development Process. In 11th International Munich Chassis Symposium 2020: Chassis. Tech Plus; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Schick, B.; Fuhr, F.; Höfer, M.; Pfeffer, P.E. Eigenschaftsbasierte Entwicklung von Fahrerassistenzsystemen. ATZ-Automob. Z. 2019, 121, 70–75. [Google Scholar] [CrossRef]
- Oschlies, H.; Saust, F.; Schmidt, S. Methodik zur Analyse, Auslegung und Bewertung einer automatisierten Querführung. In Magdeburger Maschinenbau-Tage; 2017. [Google Scholar]
- Schmitt, B.I. Konvergenzanalyse für die Partikelschwarmoptimierung. In Ausgezeichnete Informatikdissertationen 2015; Gesellschaft für Informatik: Bonn, Germany, 2015; pp. 259–268. ISBN 978-3-88579-975-7. [Google Scholar]
- Zhang, W.-J.; Xie, X.-F.; Bi, D.-C. Handling Boundary Constraints for Numerical Optimization by Particle Swarm Flying in Periodic Search Space. In Proceedings of the 2004 Congress on Evolutionary Computation (IEEE Cat. No. 04TH8753), Portland, OR, USA, 19–23 June 2004. [Google Scholar] [CrossRef]
- Schäuffele, J.; Zurawka, T. Automotive Software Engineering; Vieweg + Teubner Verlag: Wiesbaden, Germany, 2010; ISBN 978-3-8348-9368-0. [Google Scholar]
- Filev, D.P.; Stevens, G.; Lu, J.; Prakah-Asante, K.O.; Kolmanovsky, I.; Szwabowski, S.J.; Di Cairano, S. System and Method for Integrated Control of Vehicle Control Systems. U.S. Patent 8,600,614 B2, 3 December 2013. [Google Scholar]
- ISO 22179:2009-09; Intelligent Transport Systems—Full Speed Range Adaptive Cruise Control (FSRA) Systems—Performance Requirements and Test Procedures. ISO: Geneva, Switzerland, 2009.
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; López, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017. [Google Scholar] [CrossRef]
- Storey, K. Using PhysX for Vehicle Simulations in Games. In Proceedings of the Game Developer Conference San Francisco, San Francisco, CA, USA, 18–22 March 2019. [Google Scholar]
- Taguchi, G.; Chowdhury, S.; Wu, Y.; Taguchi, S.; Yano, H. Taguchi’s Quality Engineering Handbook; John Wiley & Sons: Hoboken, NJ, USA, 2004; ISBN 0471413348. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Markofsky, M.; Schäfer, M.; Schramm, D. Use Cases and Methods of Virtual ADAS/ADS Calibration in Simulation. Vehicles 2023, 5, 802-829. https://doi.org/10.3390/vehicles5030044
Markofsky M, Schäfer M, Schramm D. Use Cases and Methods of Virtual ADAS/ADS Calibration in Simulation. Vehicles. 2023; 5(3):802-829. https://doi.org/10.3390/vehicles5030044
Chicago/Turabian StyleMarkofsky, Moritz, Max Schäfer, and Dieter Schramm. 2023. "Use Cases and Methods of Virtual ADAS/ADS Calibration in Simulation" Vehicles 5, no. 3: 802-829. https://doi.org/10.3390/vehicles5030044
APA StyleMarkofsky, M., Schäfer, M., & Schramm, D. (2023). Use Cases and Methods of Virtual ADAS/ADS Calibration in Simulation. Vehicles, 5(3), 802-829. https://doi.org/10.3390/vehicles5030044