


Cloud-Based Reinforcement Learning in Automotive Control Function Development



Abstract
:1. Introduction
2. Methodology
2.1. Reinforcement Learning
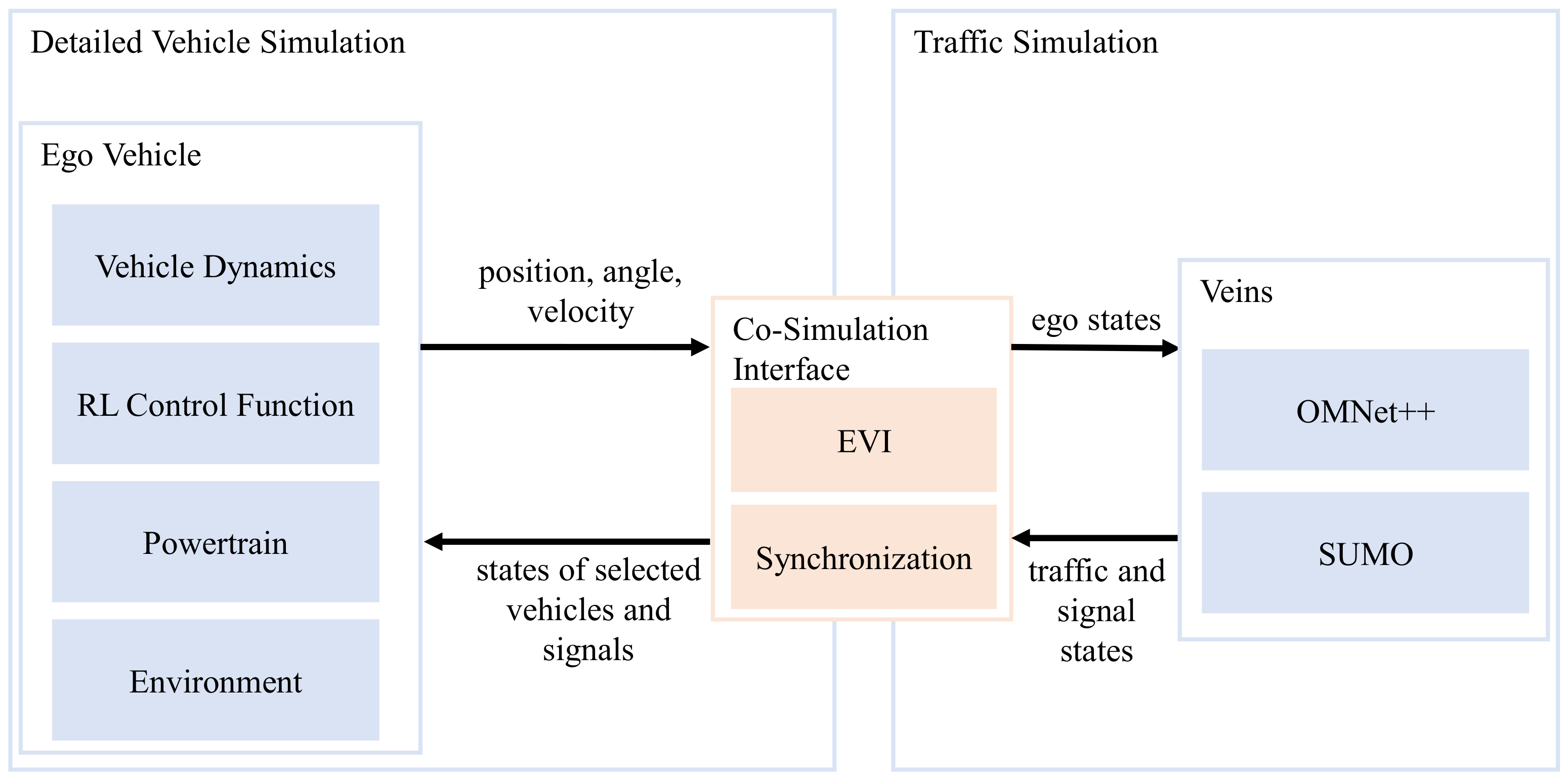
2.2. Simulation Environment
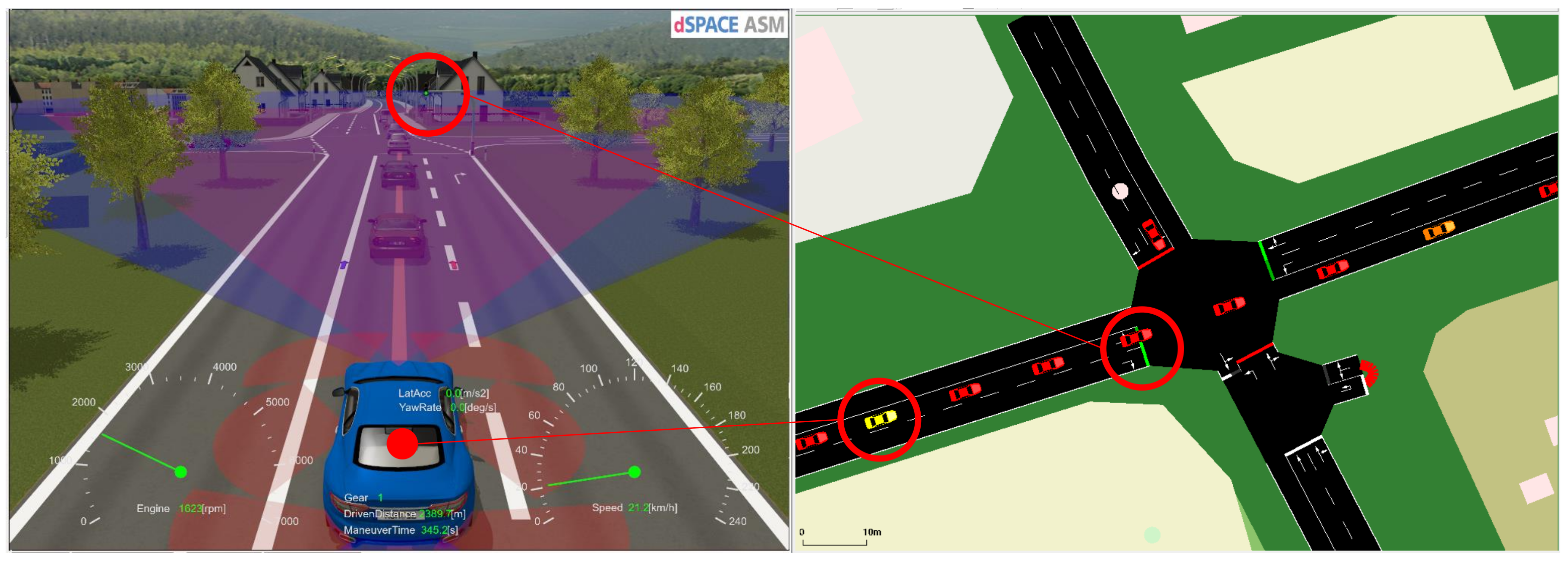
2.2.1. Physical Simulation
2.2.2. Microscopic Traffic Simulation
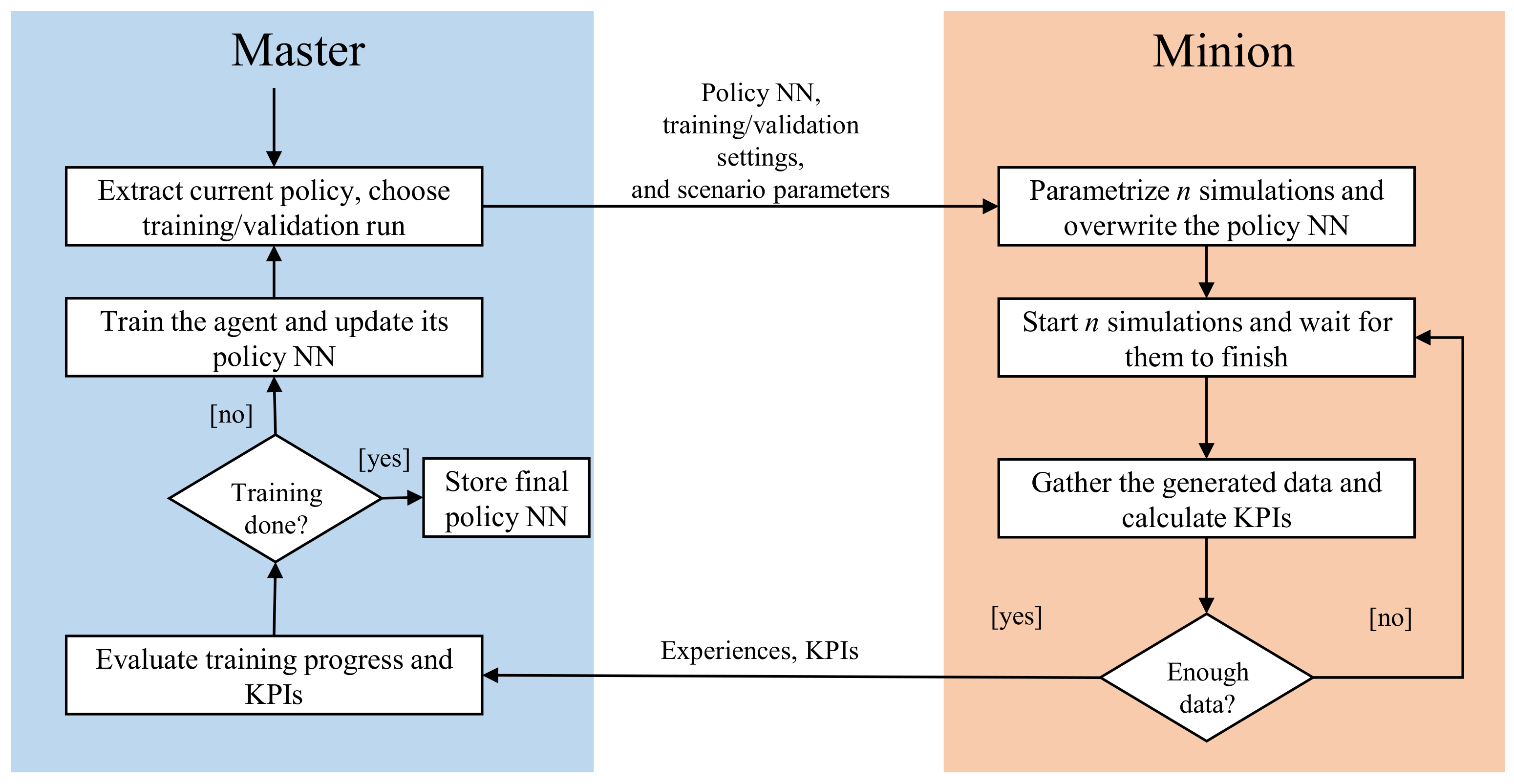
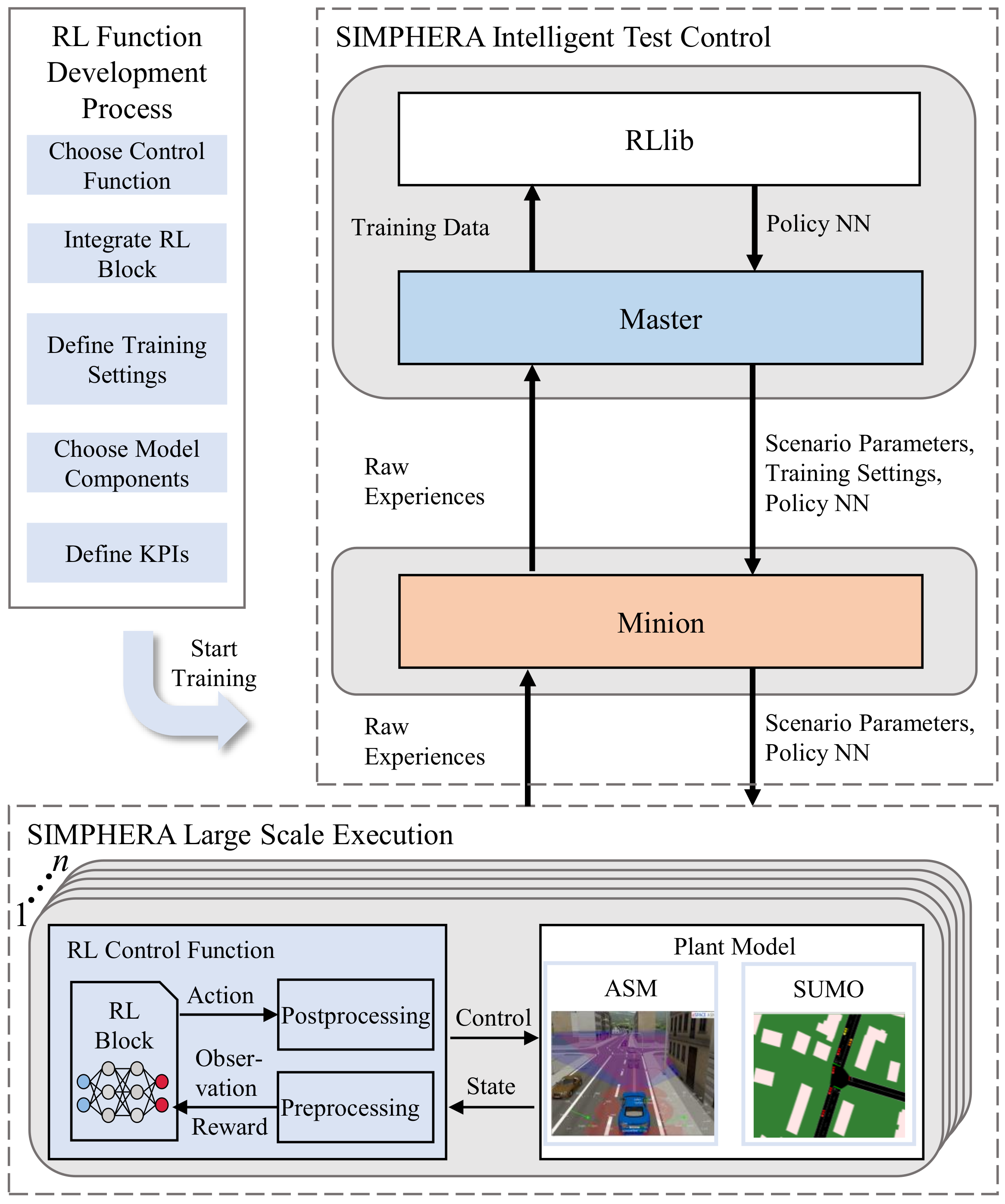
2.3. Distributed Learning Framework
3. Feasibility Study
3.1. Scenario
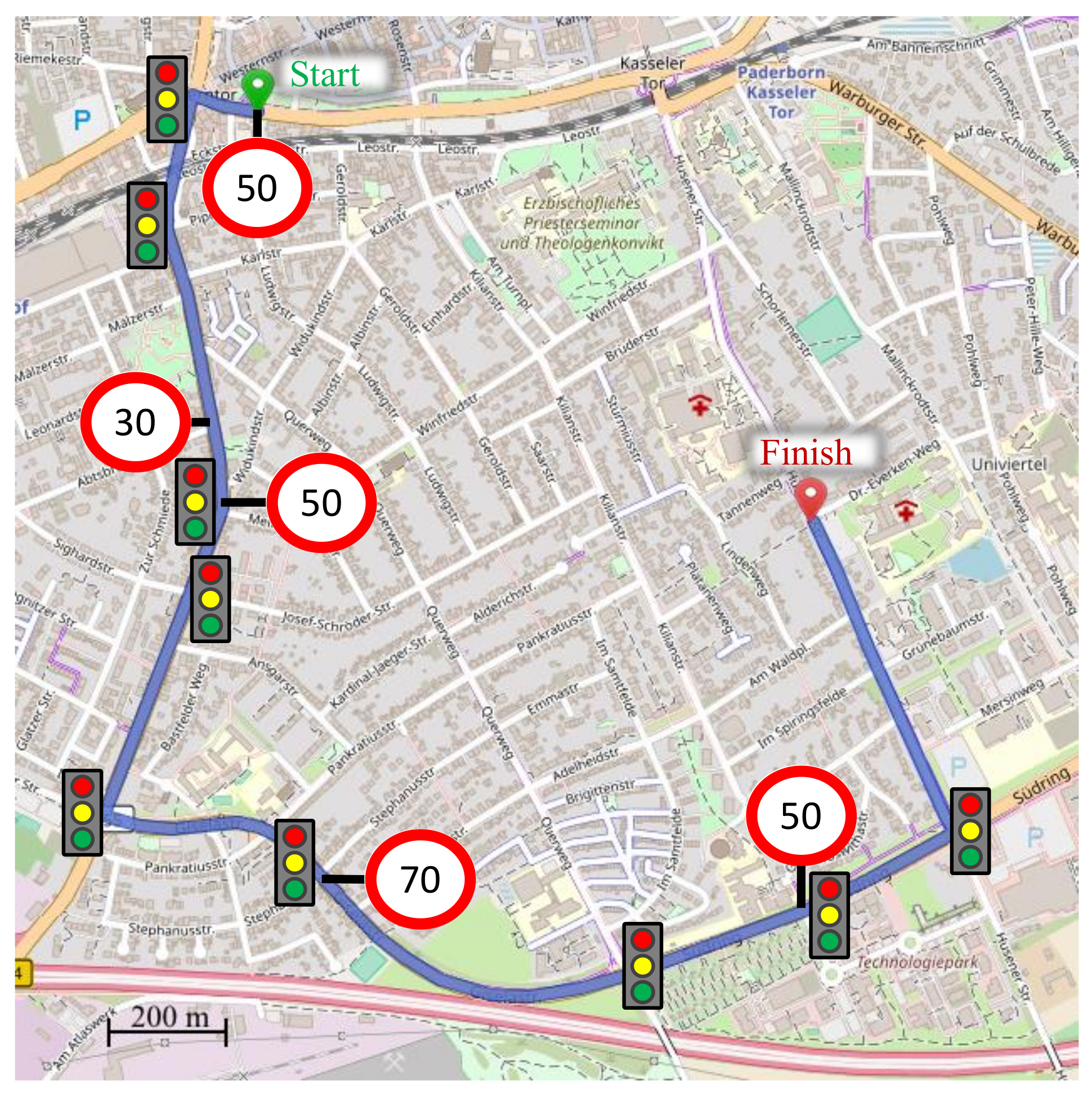
3.1.1. Route
3.1.2. Ego Vehicle
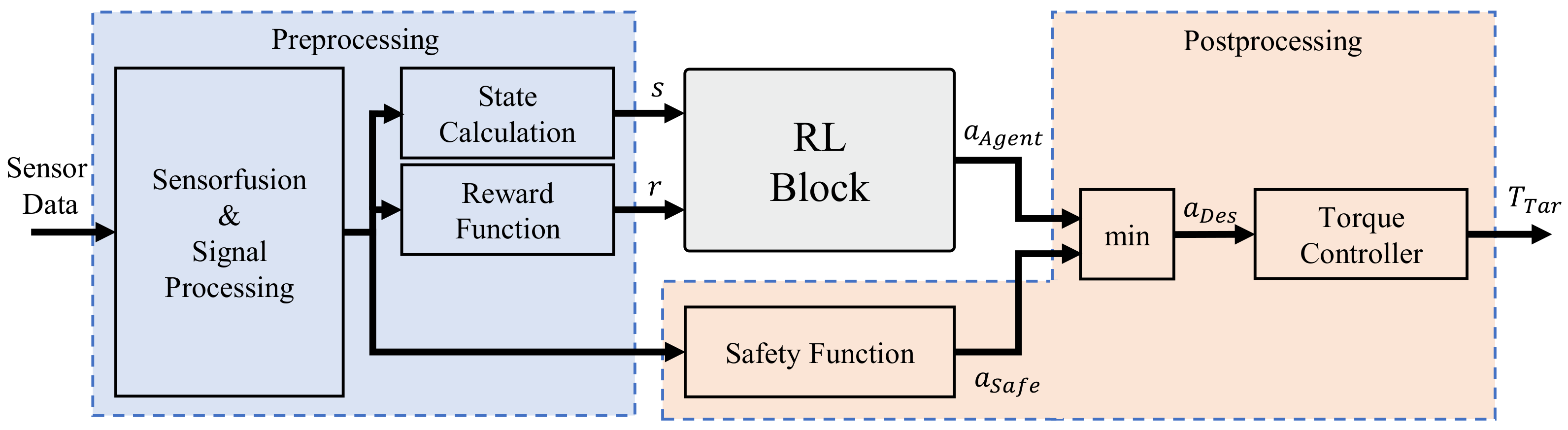
3.1.3. RL Control Function
- Collision: safety time gap (1 ) and distance (1 ) to the preceding vehicle are assured.
- Speed limit: compliance with legal speed limits is guaranteed.
- Curvature: the curve speed is limited to ensure that a lateral acceleration of 3 is not exceeded.
- Traffic light: red-light violations are prevented.
3.2. Problem Formulation
3.3. Results
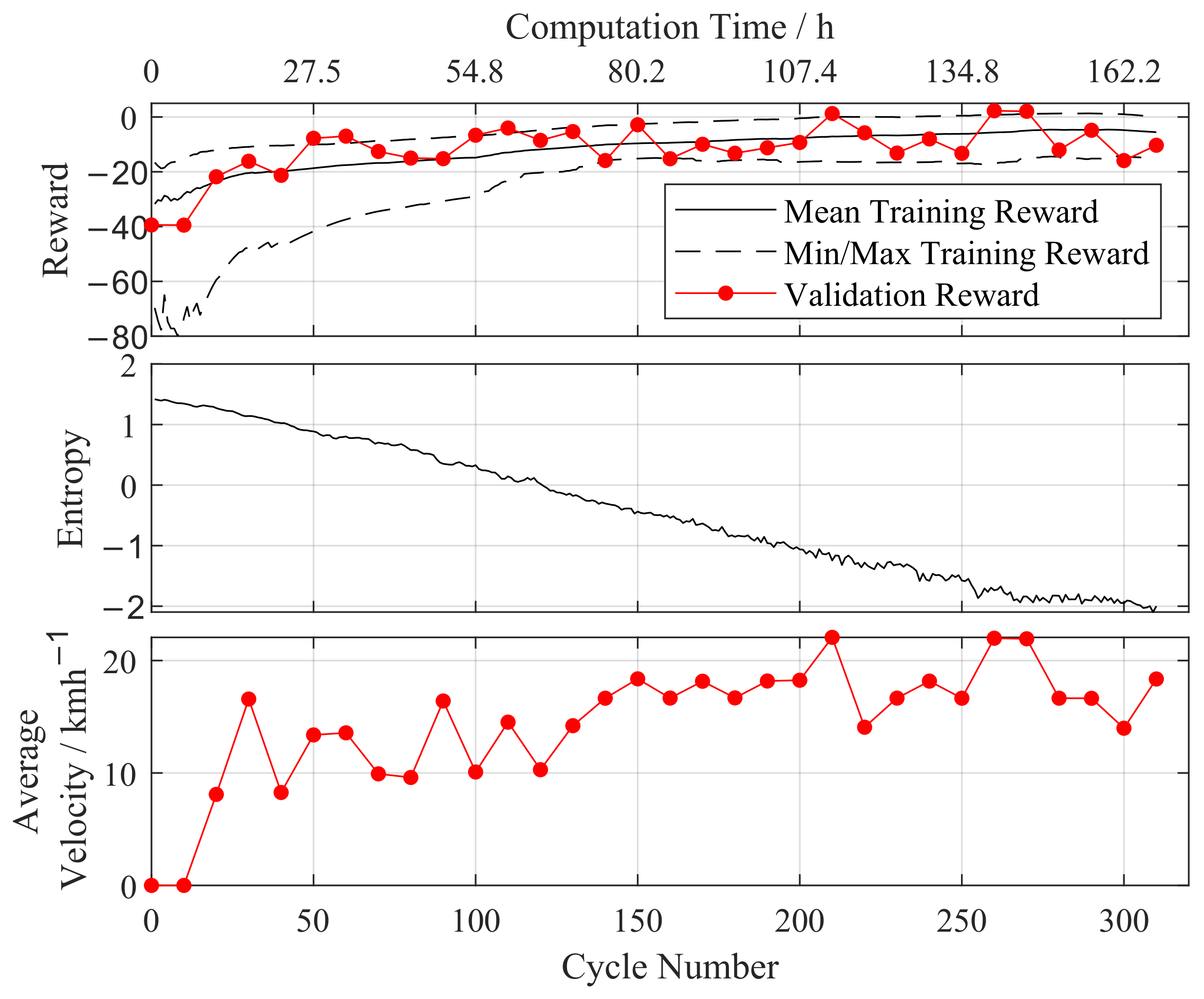
3.3.1. Training Results
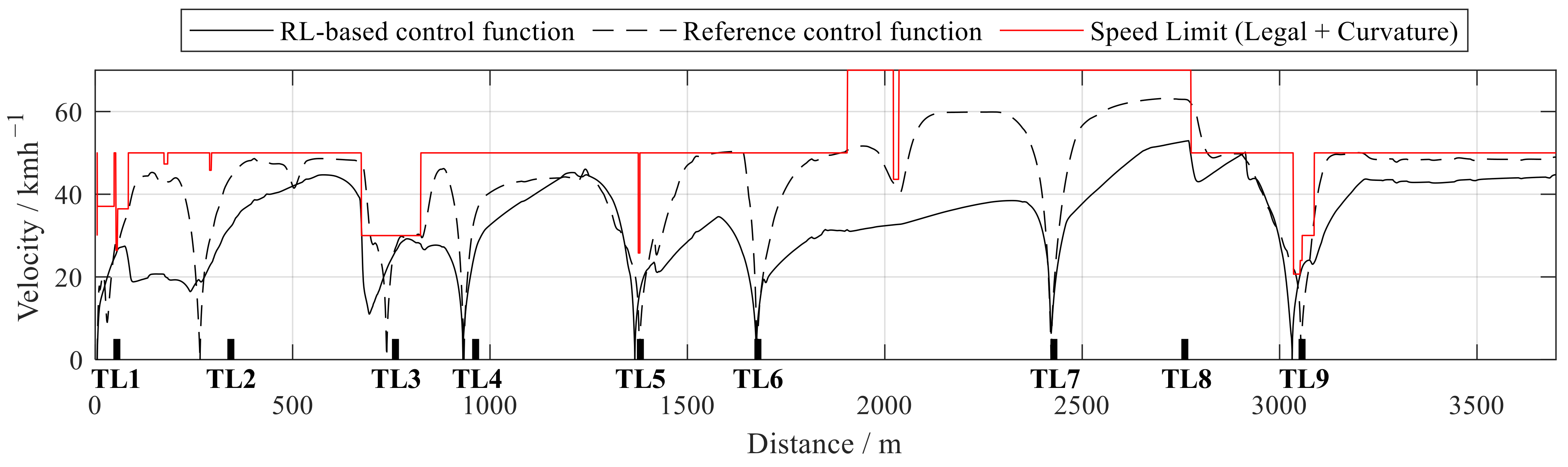
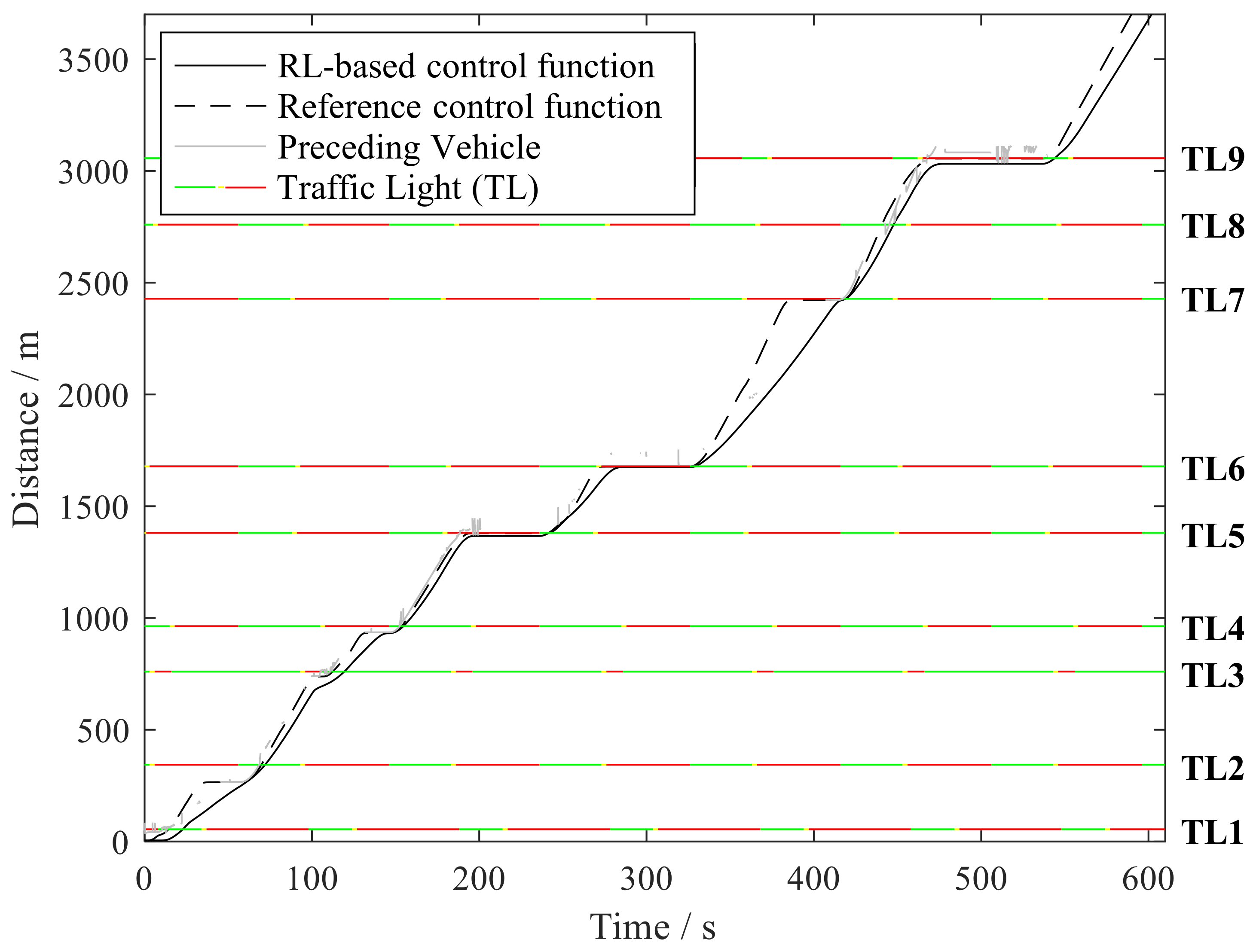
3.3.2. Validation Results
4. Discussion and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Ego Vehicle Specification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Data | Value |
|---|---|---|
| Vehicle Dynamics | cW-value | 0.27 |
| Frontal area | 2.38 | |
| Unladen weight | 1345 | |
| Acceleration 0 to 60 | 3.5 | |
| Top speed | 150 | |
| Powertrain | Motor power (rated/peak) | 75/125 |
| Motor torque | 250 | |
| Transmission ratio | 9.75 | |
| Battery capacity | 42 | |
| Battery technology | Lithium-ion | |
| Camera Sensor | Range | 50 |
| Sensor position/direction | front/front | |
| Radar Sensor | Range | 150 |
| Sensor position/direction | front/front | |
| V2I | SPaT message | |
| E-Horizon | ADASIS v2 Standard [45] | |
Appendix B. Intelligent Driver Model
| Parameter | Description | Value |
|---|---|---|
| a | Maximum Acceleration | 3.5 |
| b | Comfortable Deceleration | 2.5 |
| T | Time headway | 1 |
| Minimum distance | 2 | |
| Acceleration exponent | 3.25 |
References
- Ebert, C.; Favaro, J. Automotive software. IEEE Softw. 2017, 34, 33–39. [Google Scholar] [CrossRef]
- Vogel, M.; Knapik, P.; Cohrs, M.; Szyperrek, B.; Pueschel, W.; Etzel, H.; Fiebig, D.; Rausch, A.; Kuhrmann, M. Metrics in automotive software development: A systematic literature review. J. Softw. Evol. Process 2021, 33, e2296. [Google Scholar] [CrossRef]
- Antinyan, V. Revealing the complexity of automotive software. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual, 8–13 November 2020; pp. 1525–1528. [Google Scholar]
- Greengard, S. Automotive systems get smarter. Commun. ACM 2015, 58, 18–20. [Google Scholar] [CrossRef]
- Möhringer, S. Entwicklungsmethodik für Mechatronische Systeme; Heinz-Nixdorf Institut: Paderborn, Germany, 2004. [Google Scholar]
- Isermann, R. Automotive Control: Modeling and Control of Vehicles; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Juhnke, K.; Tichy, M.; Houdek, F. Challenges concerning test case specifications in automotive software testing: Assessment of frequency and criticality. Softw. Qual. J. 2021, 29, 39–100. [Google Scholar] [CrossRef]
- Claßen, J.; Pischinger, S.; Krysmon, S.; Sterlepper, S.; Dorscheidt, F.; Doucet, M.; Reuber, C.; Görgen, M.; Scharf, J.; Nijs, M.; et al. Statistically supported real driving emission calibration: Using cycle generation to provide vehicle-specific and statistically representative test scenarios for Euro 7. Int. J. Engine Res. 2020, 21, 1783–1799. [Google Scholar] [CrossRef]
- Mattos, D.I.; Bosch, J.; Olsson, H.H.; Korshani, A.M.; Lantz, J. Automotive A/B testing: Challenges and lessons learned from practice. In Proceedings of the 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Portoroz, Slovenia, 26–28 August 2020; pp. 101–109. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Cao, Z.; Xu, S.; Peng, H.; Yang, D.; Zidek, R. Confidence-aware reinforcement learning for self-driving cars. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7419–7430. [Google Scholar] [CrossRef]
- Gutiérrez-Moreno, R.; Barea, R.; López-Guillén, E.; Araluce, J.; Bergasa, L.M. Reinforcement learning-based autonomous driving at intersections in CARLA simulator. Sensors 2022, 22, 8373. [Google Scholar] [CrossRef]
- Li, D.; Okhrin, O. Modified DDPG car-following model with a real-world human driving experience with CARLA simulator. Transp. Res. Part C Emerg. Technol. 2023, 147, 103987. [Google Scholar] [CrossRef]
- Cao, Z.; Bıyık, E.; Wang, W.Z.; Raventos, A.; Gaidon, A.; Rosman, G.; Sadigh, D. Reinforcement learning based control of imitative policies for near-accident driving. arXiv 2020, arXiv:2007.00178. [Google Scholar]
- Li, G.; Yang, Y.; Li, S.; Qu, X.; Lyu, N.; Li, S.E. Decision making of autonomous vehicles in lane change scenarios: Deep reinforcement learning approaches with risk awareness. Transp. Res. Part C Emerg. Technol. 2022, 134, 103452. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, L.; Gao, B.; Qu, T.; Chen, H. Deterministic promotion reinforcement learning applied to longitudinal velocity control for automated vehicles. IEEE Trans. Veh. Technol. 2019, 69, 338–348. [Google Scholar] [CrossRef]
- Tian, Y.; Cao, X.; Huang, K.; Fei, C.; Zheng, Z.; Ji, X. Learning to drive like human beings: A method based on deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6357–6367. [Google Scholar] [CrossRef]
- Song, S.; Chen, H.; Sun, H.; Liu, M. Data efficient reinforcement learning for integrated lateral planning and control in automated parking system. Sensors 2020, 20, 7297. [Google Scholar] [CrossRef]
- Zhao, J.; Cheng, S.; Li, L.; Li, M.; Zhang, Z. A model free controller based on reinforcement learning for active steering system with uncertainties. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2021, 235, 2470–2483. [Google Scholar] [CrossRef]
- Deng, H.; Zhao, Y.; Nguyen, A.T.; Huang, C. Fault-Tolerant Predictive Control With Deep-Reinforcement-Learning-Based Torque Distribution for Four In-Wheel Motor Drive Electric Vehicles. IEEE/ASME Trans. Mechatron. 2023, 28, 668–680. [Google Scholar] [CrossRef]
- Fuchs, F.; Song, Y.; Kaufmann, E.; Scaramuzza, D.; Dürr, P. Super-human performance in gran turismo sport using deep reinforcement learning. IEEE Robot. Autom. Lett. 2021, 6, 4257–4264. [Google Scholar] [CrossRef]
- Wurman, P.R.; Barrett, S.; Kawamoto, K.; MacGlashan, J.; Subramanian, K.; Walsh, T.J.; Capobianco, R.; Devlic, A.; Eckert, F.; Fuchs, F.; et al. Outracing champion Gran Turismo drivers with deep reinforcement learning. Nature 2022, 602, 223–228. [Google Scholar] [CrossRef]
- Min, K.; Kim, H.; Huh, K. Deep distributional reinforcement learning based high-level driving policy determination. IEEE Trans. Intell. Veh. 2019, 4, 416–424. [Google Scholar] [CrossRef]
- Bai, Z.; Hao, P.; Shangguan, W.; Cai, B.; Barth, M.J. Hybrid reinforcement learning-based eco-driving strategy for connected and automated vehicles at signalized intersections. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15850–15863. [Google Scholar] [CrossRef]
- Kreidieh, A.R.; Wu, C.; Bayen, A.M. Dissipating stop-and-go waves in closed and open networks via deep reinforcement learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1475–1480. [Google Scholar]
- Feng, S.; Sun, H.; Yan, X.; Zhu, H.; Zou, Z.; Shen, S.; Liu, H.X. Dense reinforcement learning for safety validation of autonomous vehicles. Nature 2023, 615, 620–627. [Google Scholar] [CrossRef]
- Wang, P.; Chan, C.Y. Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Guo, Q.; Angah, O.; Liu, Z.; Ban, X.J. Hybrid deep reinforcement learning based eco-driving for low-level connected and automated vehicles along signalized corridors. Transp. Res. Part C Emerg. Technol. 2021, 124, 102980. [Google Scholar] [CrossRef]
- Wegener, M.; Koch, L.; Eisenbarth, M.; Andert, J. Automated eco-driving in urban scenarios using deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2021, 126, 102967. [Google Scholar] [CrossRef]
- Norouzi, A.; Shahpouri, S.; Gordon, D.; Shahbakhti, M.; Koch, C.R. Safe deep reinforcement learning in diesel engine emission control. Proc. Inst. Mech. Eng. Part J. Syst. Control. Eng. 2023, 09596518231153445. [Google Scholar] [CrossRef]
- Lai, C.; Wu, C.; Wang, S.; Li, J.; Hu, B. EGR Intelligent Control of Diesel Engine Based on Deep Reinforcement Learning. In Proceedings of the International Conference of Fluid Power and Mechatronic Control Engineering (ICFPMCE 2022), Kunming, China, 22–24 March 2022; Atlantis Press: Amsterdam, The Netherlands, 2022; pp. 151–161. [Google Scholar]
- Hu, B.; Yang, J.; Li, J.; Li, S.; Bai, H. Intelligent control strategy for transient response of a variable geometry turbocharger system based on deep reinforcement learning. Processes 2019, 7, 601. [Google Scholar] [CrossRef] [Green Version]
- Koch, L.; Picerno, M.; Badalian, K.; Lee, S.Y.; Andert, J. Automated function development for emission control with deep reinforcement learning. Eng. Appl. Artif. Intell. 2023, 117, 105477. [Google Scholar] [CrossRef]
- Book, G.; Traue, A.; Balakrishna, P.; Brosch, A.; Schenke, M.; Hanke, S.; Kirchgässner, W.; Wallscheid, O. Transferring online reinforcement learning for electric motor control from simulation to real-world experiments. IEEE Open J. Power Electron. 2021, 2, 187–201. [Google Scholar] [CrossRef]
- Han, S.Y.; Liang, T. Reinforcement-learning-based vibration control for a vehicle semi-active suspension system via the PPO approach. Appl. Sci. 2022, 12, 3078. [Google Scholar] [CrossRef]
- Hu, Y.; Li, W.; Xu, K.; Zahid, T.; Qin, F.; Li, C. Energy management strategy for a hybrid electric vehicle based on deep reinforcement learning. Appl. Sci. 2018, 8, 187. [Google Scholar] [CrossRef] [Green Version]
- Sun, M.; Zhao, P.; Lin, X. Power management in hybrid electric vehicles using deep recurrent reinforcement learning. Electr. Eng. 2022, 104, 1459–1471. [Google Scholar] [CrossRef]
- Liu, T.; Hu, X.; Li, S.E.; Cao, D. Reinforcement learning optimized look-ahead energy management of a parallel hybrid electric vehicle. IEEE/ASME Trans. Mechatron. 2017, 22, 1497–1507. [Google Scholar] [CrossRef]
- Choi, W.; Kim, J.W.; Ahn, C.; Gim, J. Reinforcement Learning-based Controller for Thermal Management System of Electric Vehicles. In Proceedings of the 2022 IEEE Vehicle Power and Propulsion Conference (VPPC), Merced, CA, USA, 1–4 November 2022; pp. 1–5. [Google Scholar]
- Gu, S.; Yang, L.; Du, Y.; Chen, G.; Walter, F.; Wang, J.; Yang, Y.; Knoll, A. A review of safe reinforcement learning: Methods, theory and applications. arXiv 2022, arXiv:2205.10330. [Google Scholar]
- VDI/VDE 2206; Development of Mechatronic and Cyber-Physical Systems. The Association of German Engineers: Alexisbad, Germany, 2021.
- Jacobson, I.; Booch, G.; Rumbaugh, J. The unified process. IEEE Softw. 1999, 16, 96. [Google Scholar]
- ISO 26262; Road Vehicles—Functional Safety. International Organization for Standardization: Geneva, Switzerland, 2011.
- Eisenbarth, M.; Wegener, M.; Scheer, R.; Andert, J.; Buse, D.S.; Klingler, F.; Sommer, C.; Dressler, F.; Reinold, P.; Gries, R. Toward smart vehicle-to-everything-connected powertrains: Driving real component test benches in a fully interactive virtual smart city. IEEE Veh. Technol. Mag. 2020, 16, 75–82. [Google Scholar] [CrossRef]
- Forum, A. ADASIS v2 Standard. 2010. Available online: https://adasis.org/ (accessed on 28 May 2023).
- dSPACE GmbH. SIMPHERA, the Cloud-Based, Highly Scalable Solution for the Simulation and Validation of Functions for Autonomous Driving. 2023. Available online: https://www.dspace.com/en/pub/home/products/sw/simulation_software/simphera.cfm (accessed on 29 May 2023).
- Liang, E.; Liaw, R.; Nishihara, R.; Moritz, P.; Fox, R.; Gonzalez, J.; Goldberg, K.; Stoica, I. Ray RLLib: A Composable and Scalable Reinforcement Learning Library. arXiv 2017, arXiv:1712.09381. [Google Scholar]
- David, R.; Duke, J.; Jain, A.; Janapa Reddi, V.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Wang, T.; et al. Tensorflow lite micro: Embedded machine learning for tinyml systems. Proc. Mach. Learn. Syst. 2021, 3, 800–811. [Google Scholar]
- Buse, D.S. Paderborn Traffic Scenario, version 0.1; CERN: Meyrin, Switzerland, 2021. [Google Scholar] [CrossRef]
- OpenStreetMap Contributors. OpenStreetMap. 2022. Available online: https://www.openstreetmap.org (accessed on 21 May 2023).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Kesting, A.; Treiber, M.; Helbing, D. Enhanced intelligent driver model to access the impact of driving strategies on traffic capacity. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2010, 368, 4585–4605. [Google Scholar] [CrossRef] [Green Version]









| Simulation Software | Automated Driving | Actuator Control | Energy & Thermal Management |
|---|---|---|---|
| CARLA | [11,12,13,14,15] | ||
| CarSim | [16,17,18] * | [19] * | [20] |
| Gaming Engines | [21,22,23,24] | ||
| SUMO | [12,25,26,27,28] | ||
| MATLAB/Simulink | [18] *, [29] | [19,30,31,32] *, [33,34,35] | [36,37,38,39] |
| GT-Power | [30,31,32] * |
| Type | Quantity | Range |
|---|---|---|
| State | Ego velocity | 0 to 75 |
| Ego longitudinal acceleration | −4 to 3 | |
| Ego lateral acceleration | −3 to 3 | |
| Fellow distance | 0 to 150 | |
| Fellow relative velocity | −70 to 70 | |
| Traffic-light status | 0 or 1 | |
| Traffic-light switching time | 0 to 70 | |
| Traffic-light distance | 0 to 300 | |
| Current legal speed limit | 0 to 70 | |
| Distance to upcoming legal speed limit | 0 to 150 | |
| Upcoming legal speed limit | 0 to 70 | |
| Distance to velocity curvature limit | 0 to 150 | |
| Curvature speed limit | 0 to 70 | |
| Safe acceleration () | −4 –3 | |
| Velocity band lower limit | 0 to 70 | |
| Velocity band upper limit | 0 to 70 | |
| Road slope | −30% to 30% | |
| Action | Desired acceleration () | −2 to 3.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koch, L.; Roeser, D.; Badalian, K.; Lieb, A.; Andert, J. Cloud-Based Reinforcement Learning in Automotive Control Function Development. Vehicles 2023, 5, 914-930. https://doi.org/10.3390/vehicles5030050
Koch L, Roeser D, Badalian K, Lieb A, Andert J. Cloud-Based Reinforcement Learning in Automotive Control Function Development. Vehicles. 2023; 5(3):914-930. https://doi.org/10.3390/vehicles5030050
Chicago/Turabian StyleKoch, Lucas, Dennis Roeser, Kevin Badalian, Alexander Lieb, and Jakob Andert. 2023. "Cloud-Based Reinforcement Learning in Automotive Control Function Development" Vehicles 5, no. 3: 914-930. https://doi.org/10.3390/vehicles5030050
APA StyleKoch, L., Roeser, D., Badalian, K., Lieb, A., & Andert, J. (2023). Cloud-Based Reinforcement Learning in Automotive Control Function Development. Vehicles, 5(3), 914-930. https://doi.org/10.3390/vehicles5030050