


Road Condition Monitoring Using Vehicle Built-in Cameras and GPS Sensors: A Deep Learning Approach



Abstract
:1. Introduction
2. Literature Review
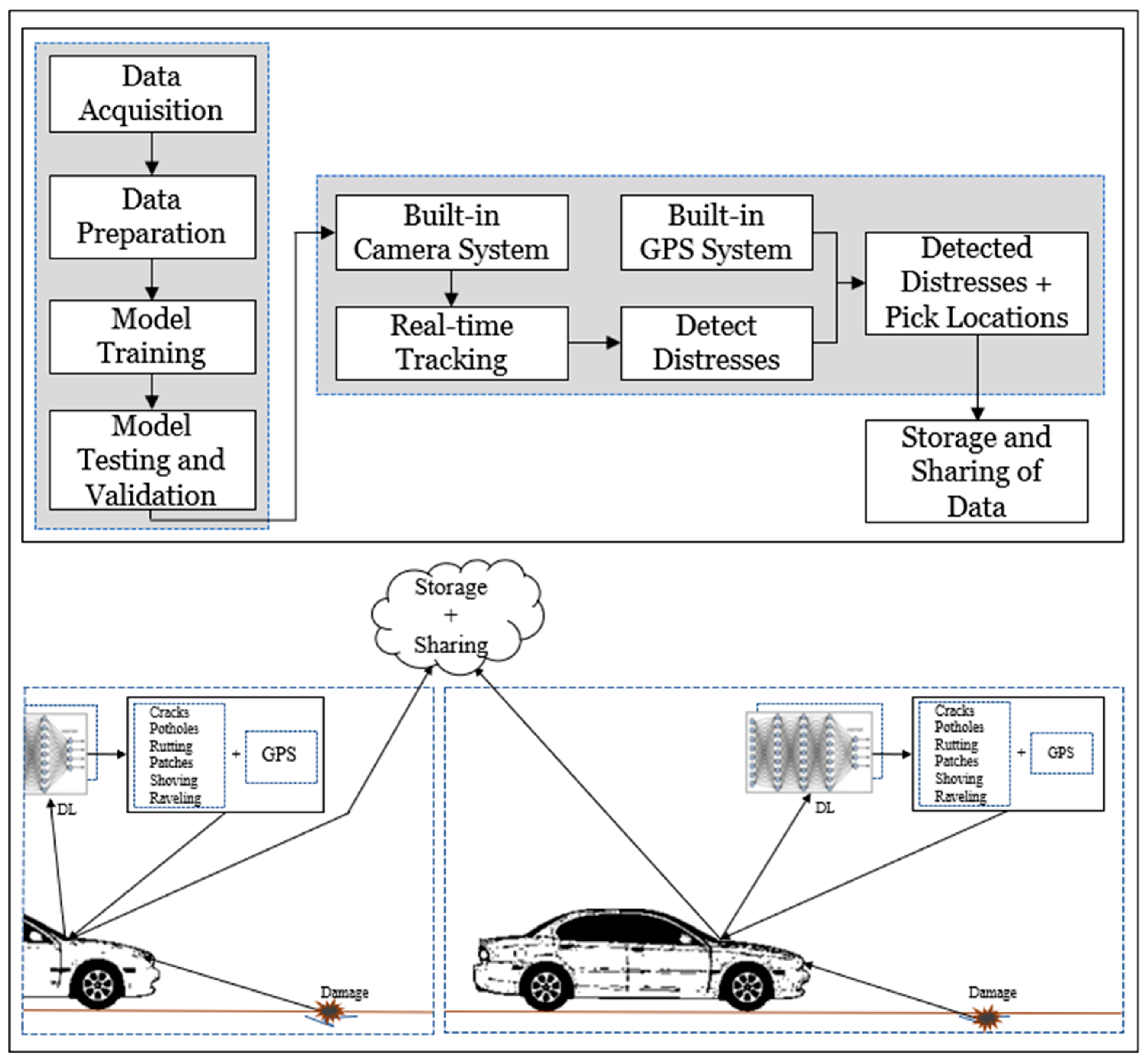
3. Methodology
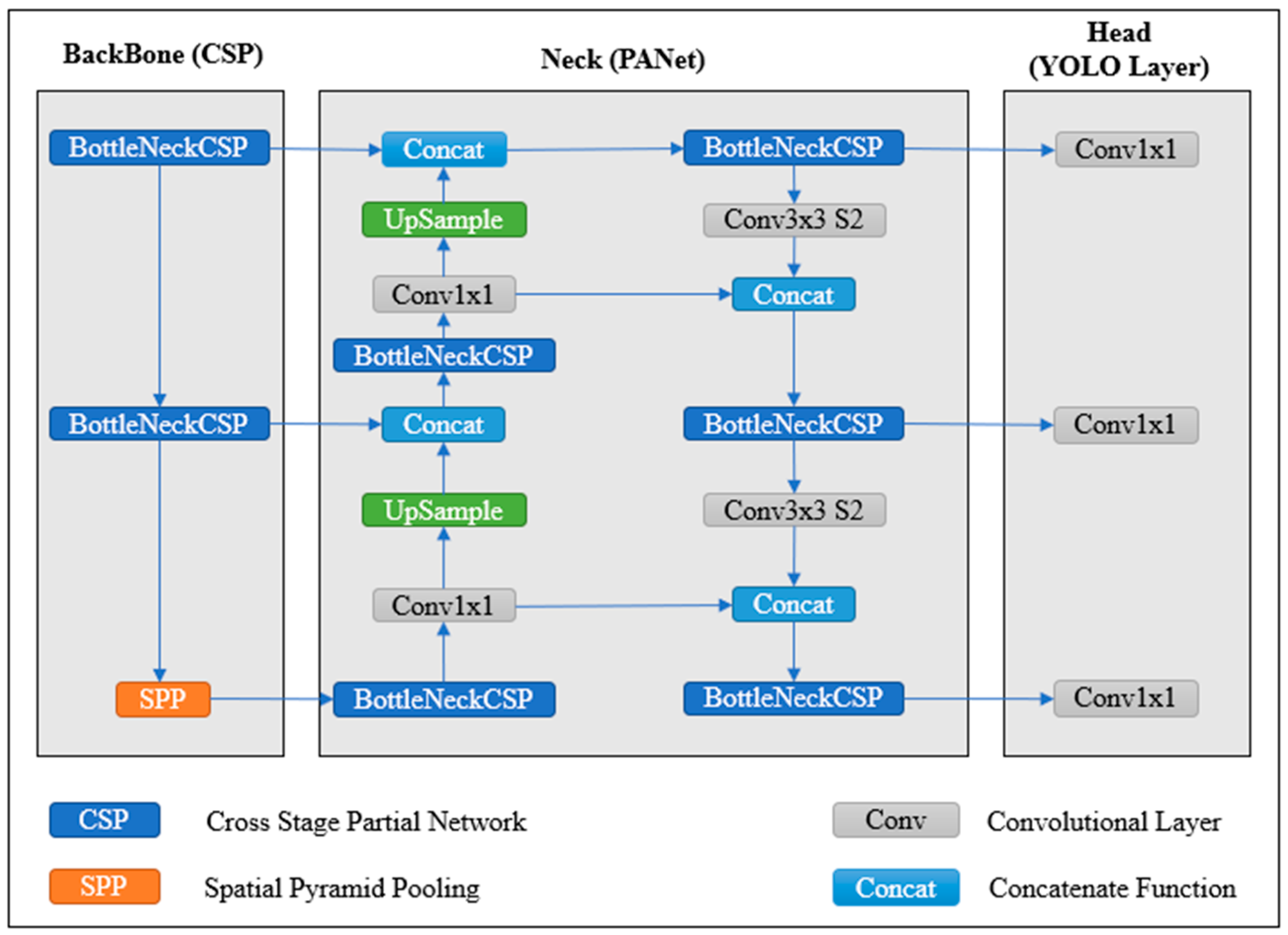
3.1. Model Selection
3.2. Model Structure
3.3. Data Collection
3.4. Dataset Selection
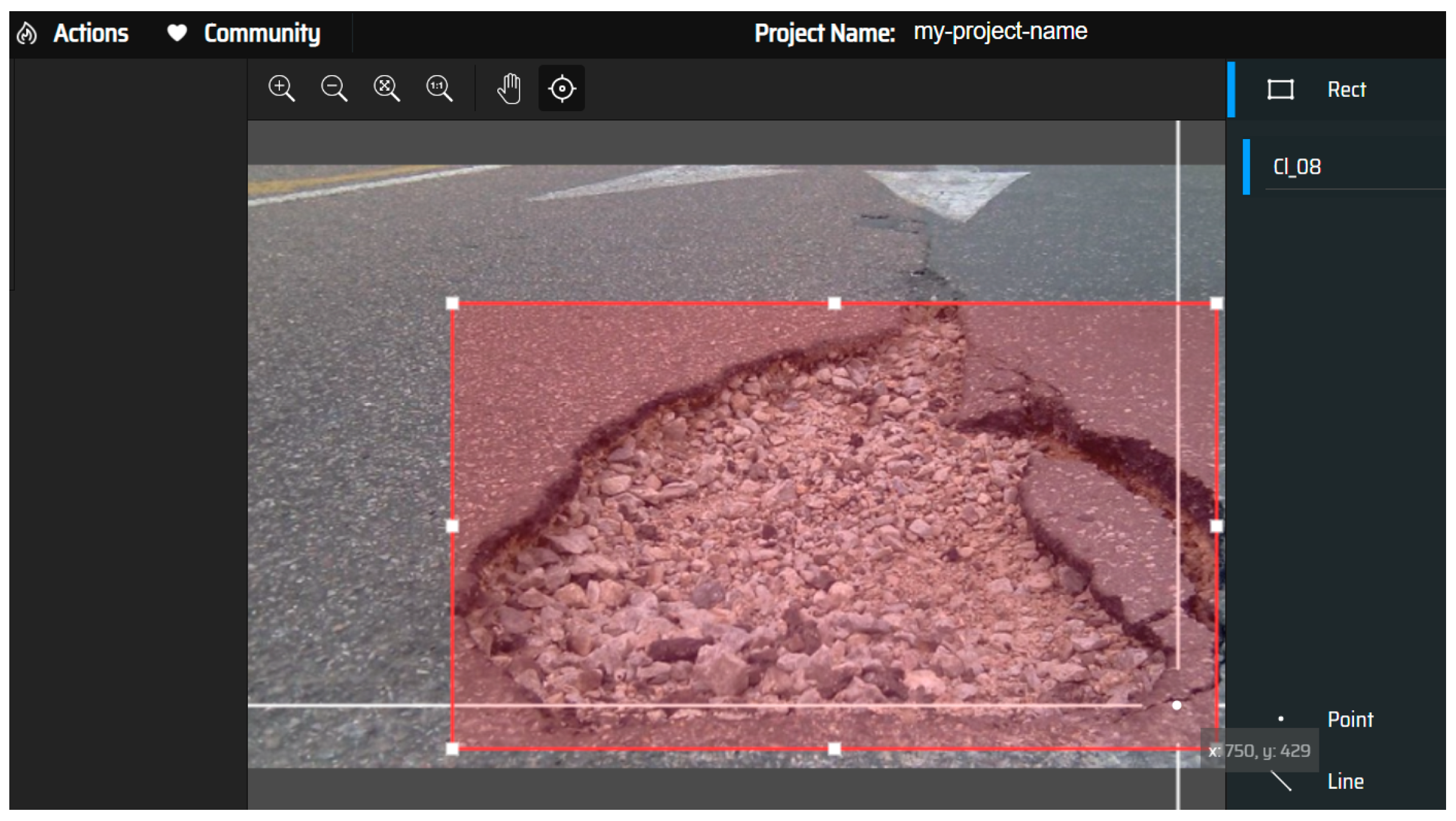
3.5. Dataset Preparation (Annotations)
3.6. Data Augmentation
3.6.1. Rescaling
3.6.2. Color Adjustments
3.6.3. Rotation
3.6.4. Mosaic Augmentation
3.7. Model Training
3.8. Training Parameters
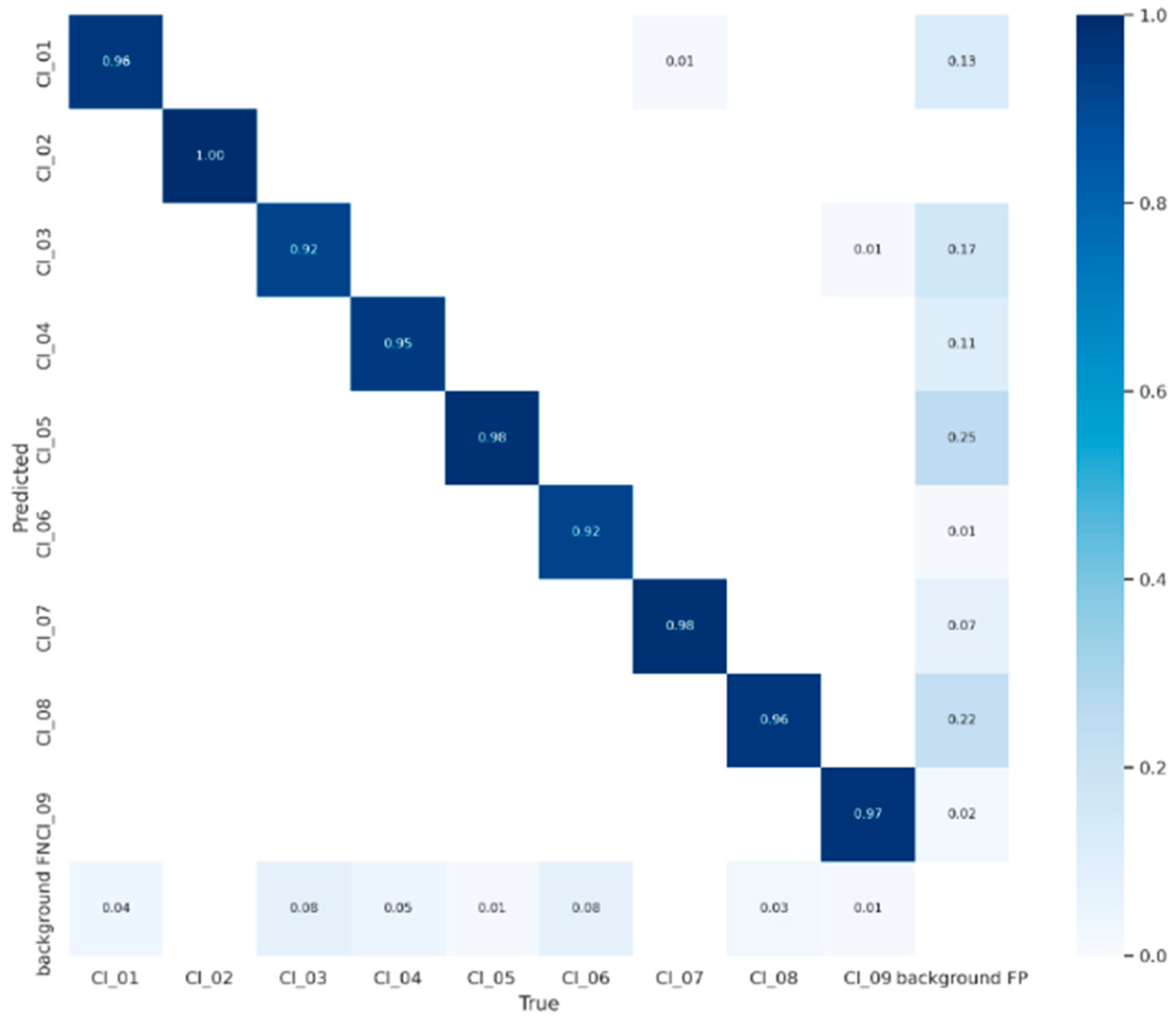
3.9. Model Analysis and Evaluation
3.10. Model Testing
3.10.1. Model Testing on Still Images
3.10.2. Model Testing on Videos at Different Driving Speeds
4. Discussion of Testing Results
4.1. Detection, Taking Photos, and Geolocations
4.2. Model Validation
5. Conclusions
6. Limitations and Future Recommendations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Majidifard, H.; Jin, P.; Adu-Gyamfi, Y.; Buttlar, W.G. Pavement Image Datasets: A New Benchmark Dataset to Classify and Densify Pavement Distresses. Transp. Res. Rec. 2020, 2674, 328–339. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Gu, X.; Ren, H. Rutting prediction of asphalt pavement with semi-rigid base: Numerical modeling on laboratory to accelerated pavement testing. Constr. Build. Mater. 2023, 375, 130903. [Google Scholar] [CrossRef]
- Stević, Ž.; Bouraima, M.B.; Subotić, M.; Qiu, Y.; Buah, P.A.; Ndiema, K.M.; Ndjegwes, C.M. Assessment of Causes of Delays in the Road Construction Projects in the Benin Republic Using Fuzzy PIPRECIA Method. Math. Probl. Eng. 2022, 2022, 5323543. [Google Scholar] [CrossRef]
- Rivera, L.; Baguec, J.H.; Yeom, C. A Study on Causes of Delay in Road Construction Projects across 25 Developing Countries. Infrastructures 2020, 5, 84. [Google Scholar] [CrossRef]
- Ghaleh, R.M.B.; Pourrostam, T.; Sharifloo, N.M.; Sardroud, J.M.; Safa, E. Delays in the Road Construction Projects from Risk Management Perspective. Infrastructures 2021, 6, 135. [Google Scholar] [CrossRef]
- USDOT. Distress Identification Manual for the Long-Term Pavement Performance Program; USDOT, Federal Highway Administration: Washington, DC, USA, 2014.
- Radopoulou, S.-C.; Brilakis, I. Improving Road Asset Condition Monitoring. Transp. Res. Procedia 2016, 14, 3004–3012. [Google Scholar] [CrossRef] [Green Version]
- Nakanishi, Y.; Kaneta, T.; Nishino, S. A Review of Monitoring Construction Equipment in Support of Construction Project Management. Front. Built Environ. 2022, 7, 632593. [Google Scholar] [CrossRef]
- Khahro, S.H.; Javed, Y.; Memon, Z.A. Low-Cost Road Health Monitoring System: A Case of Flexible Pavements. Sustainability 2021, 13, 10272. [Google Scholar] [CrossRef]
- Sattar, S.; Li, S.; Chapman, M. Developing a near real-time road surface anomaly detection approach for road surface monitoring. Measurement 2021, 185, 109990. [Google Scholar] [CrossRef]
- Vavrik, S.P.S.P.W. PCR Evaluation—Considering Transition from Manual to Semi-Automated Pavement Distress Collection and Analysis; State of Ohio Department of Transportation: Columbus, OH, USA, 2013.
- Feldman, D.R.; Pyle, T.; Lee, J. Automated Pavement Condition Survey Manual; California Department of Transportation: Los Angeles, CA, USA, 2015.
- Apeagyei, A.; Ademolake, T.E.; Adom-Asamoah, M. Evaluation of deep learning models for classification of asphalt pavement distresses. Int. J. Pavement Eng. 2023, 24, 2180641. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Chen, J.; Wang, D.; Chen, Y.; Wang, L. Automatic recognition of pavement cracks from combined GPR B-scan and C-scan images using multiscale feature fusion deep neural networks. Autom. Constr. 2023, 146, 104698. [Google Scholar] [CrossRef]
- Mihoub, A.; Krichen, M.; Alswailim, M.; Mahfoudhi, S.; Salah, R.B.H. Road Scanner: A Road State Scanning Approach Based on Machine Learning Techniques. Appl. Sci. 2023, 13, 683. [Google Scholar] [CrossRef]
- Xiong, X.; Tan, Y. Pixel-Level patch detection from full-scale asphalt pavement images based on deep learning. Int. J. Pavement Eng. 2023, 24, 2180639. [Google Scholar] [CrossRef]
- Ranyal, E.; Sadhu, A.; Jain, K. Road Condition Monitoring Using Smart Sensing and Artificial Intelligence: A Review. Sensors 2022, 22, 3044. [Google Scholar] [CrossRef] [PubMed]
- Sandamal, R.M.K.; Pasindu, H.R. Applicability of smartphone-based roughness data for rural road pavement condition evaluation. Int. J. Pavement Eng. 2022, 23, 663–672. [Google Scholar] [CrossRef]
- Fares, A.; Zayed, T. Industry- and Academic-Based Trends in Pavement Roughness Inspection Technologies over the Past Five Decades: A Critical Review. Remote. Sens. 2023, 15, 2941. [Google Scholar] [CrossRef]
- Yu, Q.; Fang, Y.; Wix, R. Evaluation framework for smartphone-based road roughness index estimation systems. Int. J. Pavement Eng. 2023, 24, 2183402. [Google Scholar] [CrossRef]
- Al-Suleiman, T.I.; Alatoom, Y.I. Evaluating smartphone-based road roughness estimation systems in an urban area. J. Eng. Des. Technol. 2022, 22. [Google Scholar] [CrossRef]
- Sam Ansari. Building a Realtime Pothole Detection System Using Machine Learning and Computer Vision. 5 March 2022. Available online: https://towardsdatascience.com/building-a-realtime-pothole-detection-system-using-machine-learning-and-computer-vision-2e5fb2e5e746 (accessed on 18 June 2022).
- Ahmed, K.R. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution. Sensors 2021, 21, 8406. [Google Scholar] [CrossRef]
- Kumar, A.; Chakrapani; Kalita, D.J.; Singh, V.P. A Modern Pothole Detection technique using Deep Learning. In Proceedings of the 2nd International Conference on Data, Engineering, and Applications (IDEA), Bhopal, India, 28–29 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R. NB-CNN: Deep learning-based crack detection using convolutional neural network and Naive Bayes data fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Ranyal, E.; Sadhu, A.; Jain, K. Automated pothole condition assessment in pavement using photogrammetry-assisted convolutional neural network. Int. J. Pavement Eng. 2023, 24, 2183401. [Google Scholar] [CrossRef]
- Liu, Z.; Yeoh, J.K.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Y.; Cheng, H.D. CrackGAN: Pavement Crack Detection Using Partially Accurate Ground Truths Based on Generative Adversarial Learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1306–1319. [Google Scholar] [CrossRef]
- Zhang, K.; Cheng, H.D.; Gai, S. Efficient Dense-Dilation Network for Pavement Crack Detection with Large Input Image Size. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 884–889. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Kanaeva, I.A.; Ivanova, J.A. Road pavement crack detection using deep learning with synthetic data. IOP Conf. Series: Mater. Sci. Eng. 2021, 1019, 012036. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated Road Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar] [CrossRef]
- Du, Y.; Pan, N.; Xu, Z.; Deng, F.; Shen, Y.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2020, 22, 1659–1672. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput. Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef] [Green Version]
- JRA. Maintenance, and Repair Guidebook of the Pavement, 1st ed.; Japan Road Association: Tokyo, Japan, 2013. [Google Scholar]
- Pei, L.; Shi, L.; Sun, Z.; Li, W. Detecting potholes in asphalt pavement under small-sample conditions based on improved faster region-based convolution neural networks. Can. J. Civ. Eng. 2022, 49, 265–273. [Google Scholar] [CrossRef]
- Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote. Sens. 2022, 14, 3892. [Google Scholar] [CrossRef]
- Pomoni, M. Exploring Smart Tires as a Tool to Assist Safe Driving and Monitor Tire–Road Friction. Vehicles 2022, 4, 744–765. [Google Scholar] [CrossRef]
- Ruseruka, C.; Mwakalonge, J.; Comert, G.; Siuhi, S.; Ngeni, F.; Major, K. Pavement Distress Identification Based on Computer Vision and Controller Area Network (CAN) Sensor Models. Sustain. Sustain. Road Maint. Improv. 2023, 15, 6438. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y.; Luo, H.; Lv, G.; Guo, F.; Xie, Q. Pavement surface defect recognition method based on vehicle system vibration data and feedforward neural network. Int. J. Pavement Eng. 2023, 24, 2188594. [Google Scholar] [CrossRef]
- Lingeman, J. 70% of Buyers Want A Dash Cam in Their Next Car. AutoPacifica. 27 July 2020. Available online: https://www.autoweek.com/news/a33417902/70-of-buyers-want-a-dash-cam-in-their-next-car/ (accessed on 20 June 2023).
- Garg, A. How to Use Yolo v5 Object Detection Algorithm for Custom Object Detection. 6 January 2023. Available online: https://www.analyticsvidhya.com/blog/2021/12/how-to-use-yolo-v5-object-detection-algorithm-for-custom-object-detection-an-example-use-case/ (accessed on 25 February 2023).
- Sharma, S.; Balakrishnan, D.; Kulkarni, S.; Singh, S.; Devunuri, S.; Korlapati, S.C.R. Crackseg9k: A Collection of Crack Segmentation Datasets. In European Conference on Computer Vision; Harvard Dataverse; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Ramanishka, V.; Chen, Y.-T.; Misu, T.; Saenko, K. Toward Driving Scene Understanding: A Dataset for Learning Driver Behavior and Causal Reasoning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7699–7707. [Google Scholar] [CrossRef]
- M.S. Image Annotations. 14 March 2022. Available online: https://www.makesense.ai/ (accessed on 21 September 2022).
- Gavrilov, A.D.; Jordache, A.; Vasdani, M.; Deng, J. Preventing Model Overfitting and Underfitting in Convolutional Neural Networks. Int. J. Softw. Sci. Comput. Intell. 2018, 10, 19–28. [Google Scholar] [CrossRef]
- Li, J.; Liu, G.; Yang, T.; Zhou, J.; Zhao, Y. Research on Relationships among Different Distress Types of Asphalt Pavements with Semi-Rigid Bases in China Using Association Rule Mining: A Statistical Point of View. Adv. Civ. Eng. 2019, 2019, 5369532. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.; Hwang, H.; Kim, H.S. Synthetic Data Augmentation and Deep Learning for the Fault Diagnosis of Rotating Machines. Mathematics 2021, 9, 2336. [Google Scholar] [CrossRef]
- Chen, X.-W.; Lin, X. Big Data Deep Learning: Challenges and Perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
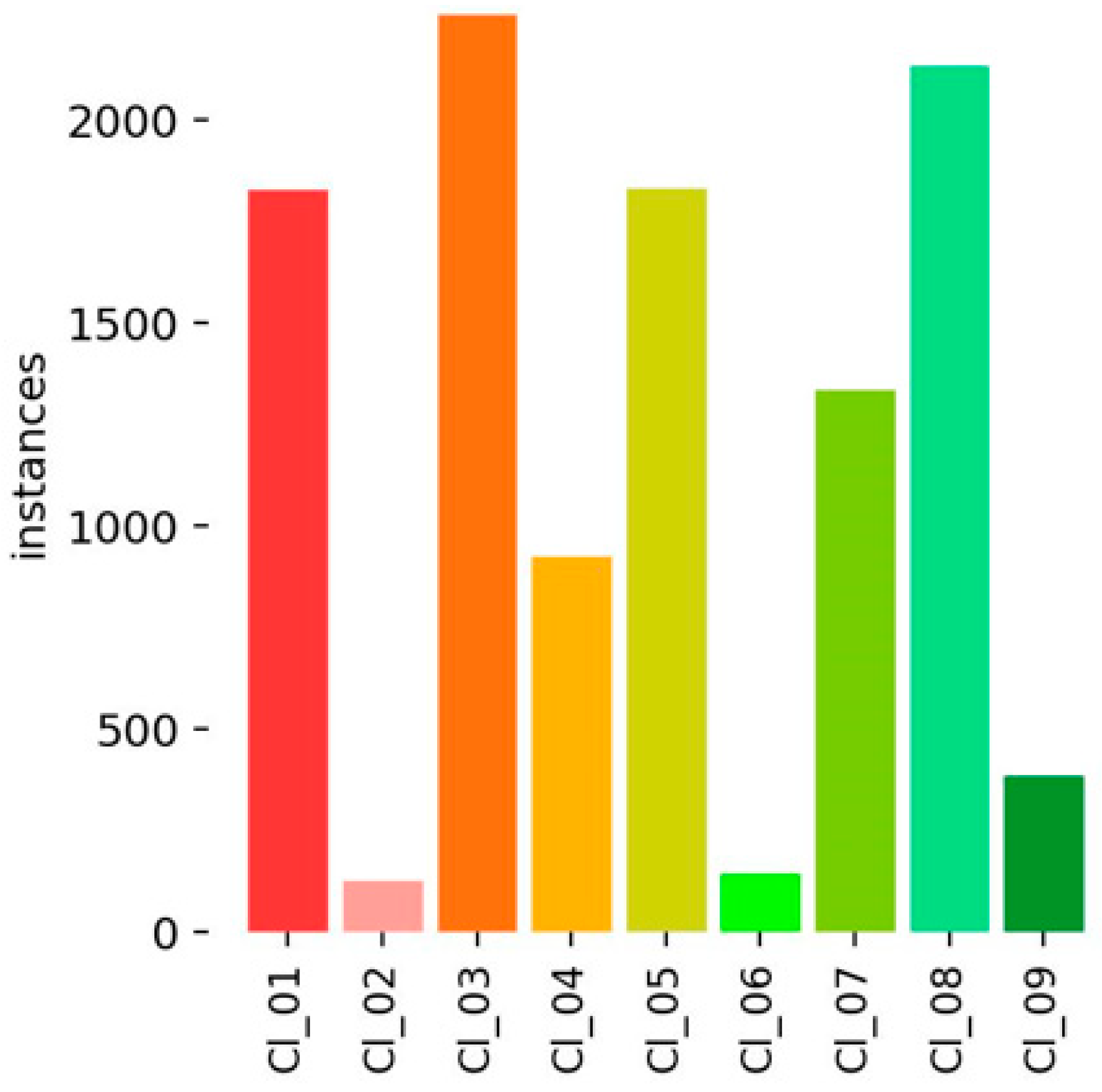
| S/N | Class | Symbol Used |
|---|---|---|
| 1 | Fatigue/Alligator Cracks | Cl_01 |
| 2 | Block Cracks | Cl_02 |
| 3 | Transverse Cracks | Cl_03 |
| 4 | Longitudinal—Wheel Path Cracks | Cl_04 |
| 5 | Longitudinal—Non-Wheel Path Cracks | Cl_05 |
| 6 | Edge, Joint, Reflective Cracks | Cl_06 |
| 7 | Patches | Cl_07 |
| 8 | Potholes | Cl_08 |
| 9 | Raveling, Shoving, Rutting | Cl_09 |
| S/N | Parameter | Value |
|---|---|---|
| 1. | Batch Size | 40 |
| 2. | Epochs | 150 |
| 3. | Learning Rate | 0.01 |
| 4. | Optimizer | SGD = 0.01 |
| 5. | Anchor Sizes | Dynamic |
| S/N | Class | Precision (%) | Recall (%) | [email protected] |
|---|---|---|---|---|
| 1 | Cl_01 | 94.9 | 93.7 | 97.6 |
| 2 | Cl_02 | 97.9 | 100.0 | 99.5 |
| 3 | Cl_03 | 94.1 | 83.5 | 93.9 |
| 4 | Cl_04 | 91.6 | 93.7 | 95.6 |
| 5 | Cl_05 | 93.1 | 94.3 | 97.4 |
| 6 | Cl_06 | 97.4 | 92.3 | 96.2 |
| 7 | Cl_07 | 95.6 | 98.3 | 99.3 |
| 8 | Cl_08 | 93.0 | 91.6 | 96.3 |
| 9 | Cl_09 | 97.2 | 93.3 | 98.7 |
| S/N | Speed (Mph) | Precision (%) | Recall (%) |
|---|---|---|---|
| 1. | 0–20 | 67 | 90 |
| 2. | 20–40 | 57 | 86 |
| 3. | 40–60 | 59 | 62 |
| 4. | 60–80 | 54 | 88 |
| 5. | 80–100 | 65 | 76 |
| 6. | 100–120 | 66 | 87 |
| S/N | Speed (Mph) | Precision (%) | % Improvement in Precision | Recall (%) | % Improvement in Recall |
|---|---|---|---|---|---|
| 1. | 0–20 | 78 | 11 | 95 | 5 |
| 2. | 20–40 | 81 | 24 | 94 | 8 |
| 3. | 40–60 | 76 | 17 | 92 | 30 |
| 4. | 60–80 | 85 | 31 | 93 | 5 |
| 5. | 80–100 | 79 | 14 | 86 | 10 |
| 6. | 100–120 | 82 | 16 | 91 | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruseruka, C.; Mwakalonge, J.; Comert, G.; Siuhi, S.; Perkins, J. Road Condition Monitoring Using Vehicle Built-in Cameras and GPS Sensors: A Deep Learning Approach. Vehicles 2023, 5, 931-948. https://doi.org/10.3390/vehicles5030051
Ruseruka C, Mwakalonge J, Comert G, Siuhi S, Perkins J. Road Condition Monitoring Using Vehicle Built-in Cameras and GPS Sensors: A Deep Learning Approach. Vehicles. 2023; 5(3):931-948. https://doi.org/10.3390/vehicles5030051
Chicago/Turabian StyleRuseruka, Cuthbert, Judith Mwakalonge, Gurcan Comert, Saidi Siuhi, and Judy Perkins. 2023. "Road Condition Monitoring Using Vehicle Built-in Cameras and GPS Sensors: A Deep Learning Approach" Vehicles 5, no. 3: 931-948. https://doi.org/10.3390/vehicles5030051
APA StyleRuseruka, C., Mwakalonge, J., Comert, G., Siuhi, S., & Perkins, J. (2023). Road Condition Monitoring Using Vehicle Built-in Cameras and GPS Sensors: A Deep Learning Approach. Vehicles, 5(3), 931-948. https://doi.org/10.3390/vehicles5030051