Maize Kernel Abortion Recognition and Classification Using Binary Classification Machine Learning Algorithms and Deep Convolutional Neural Networks

 ,
, 
 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
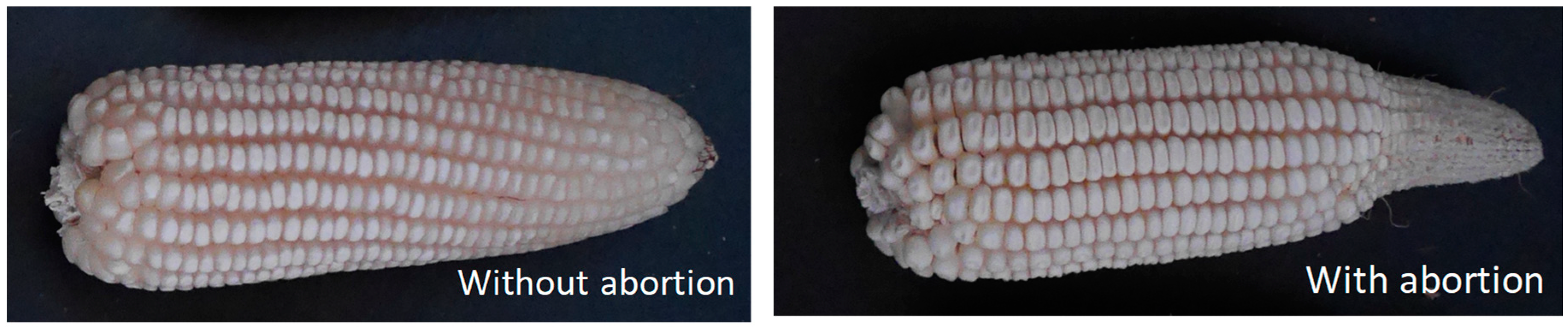
2.1. Maize Ears Photo Acquisition
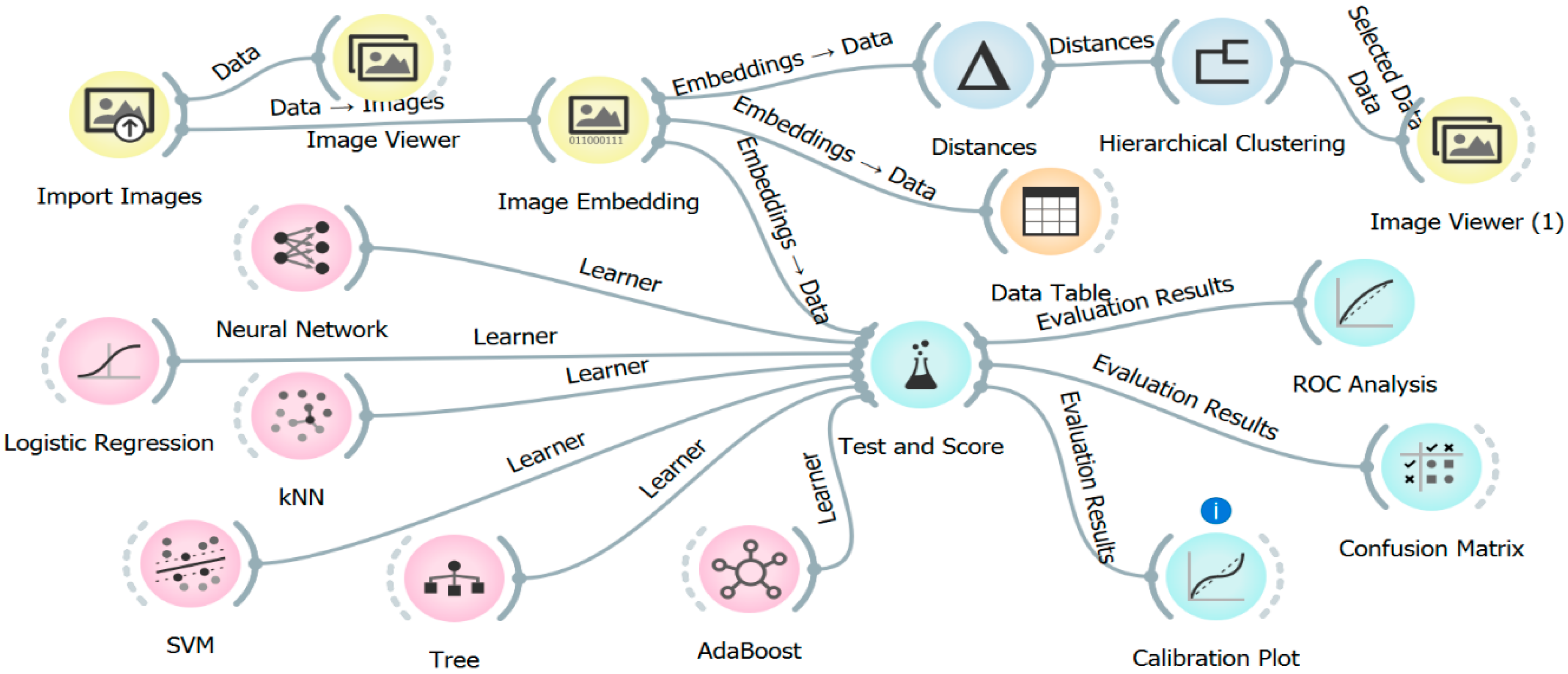
2.2. Statistical Analyses Description and Algorithms Applied
2.2.1. Image Embedding
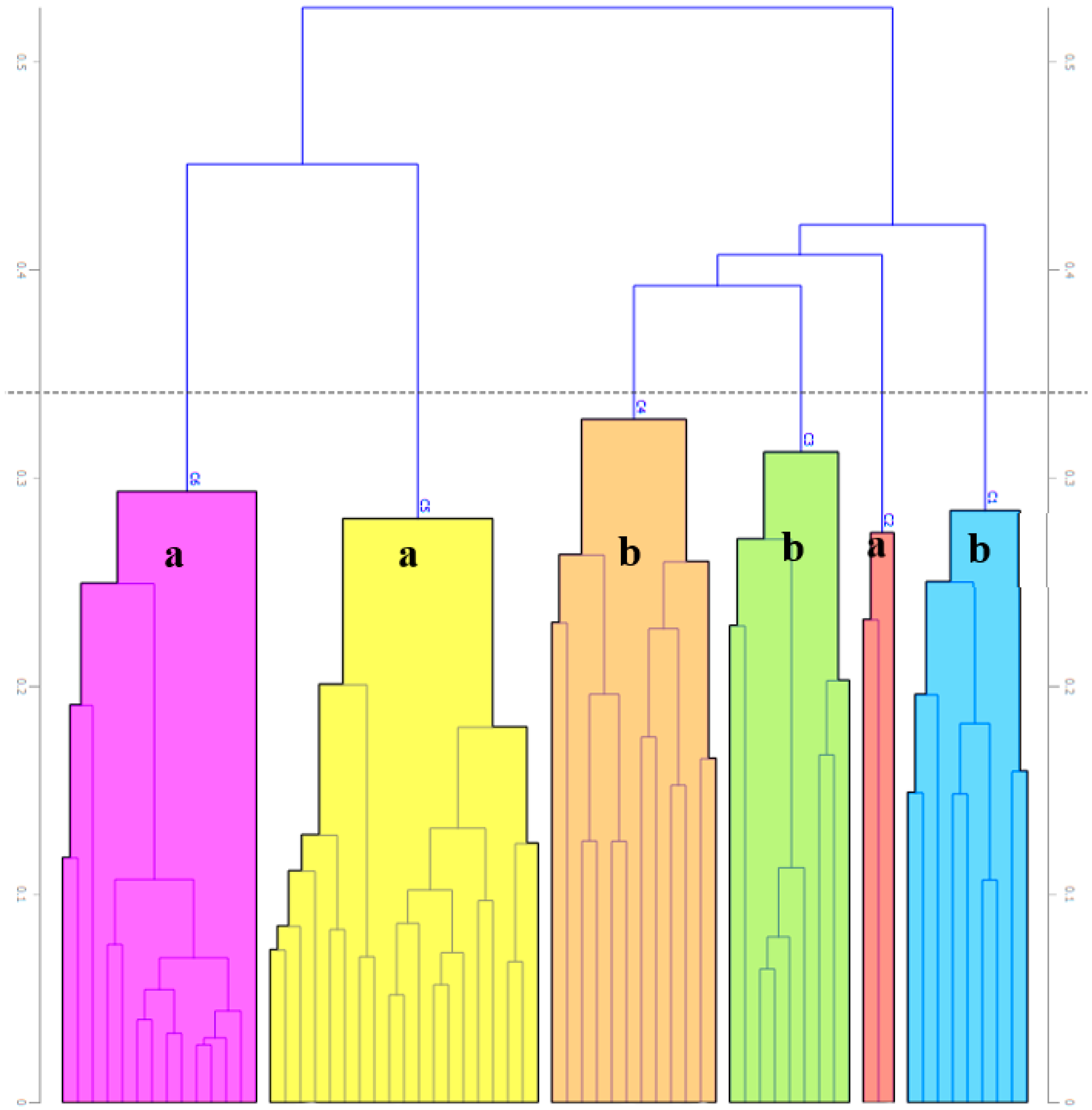
2.2.2. Image Clustering
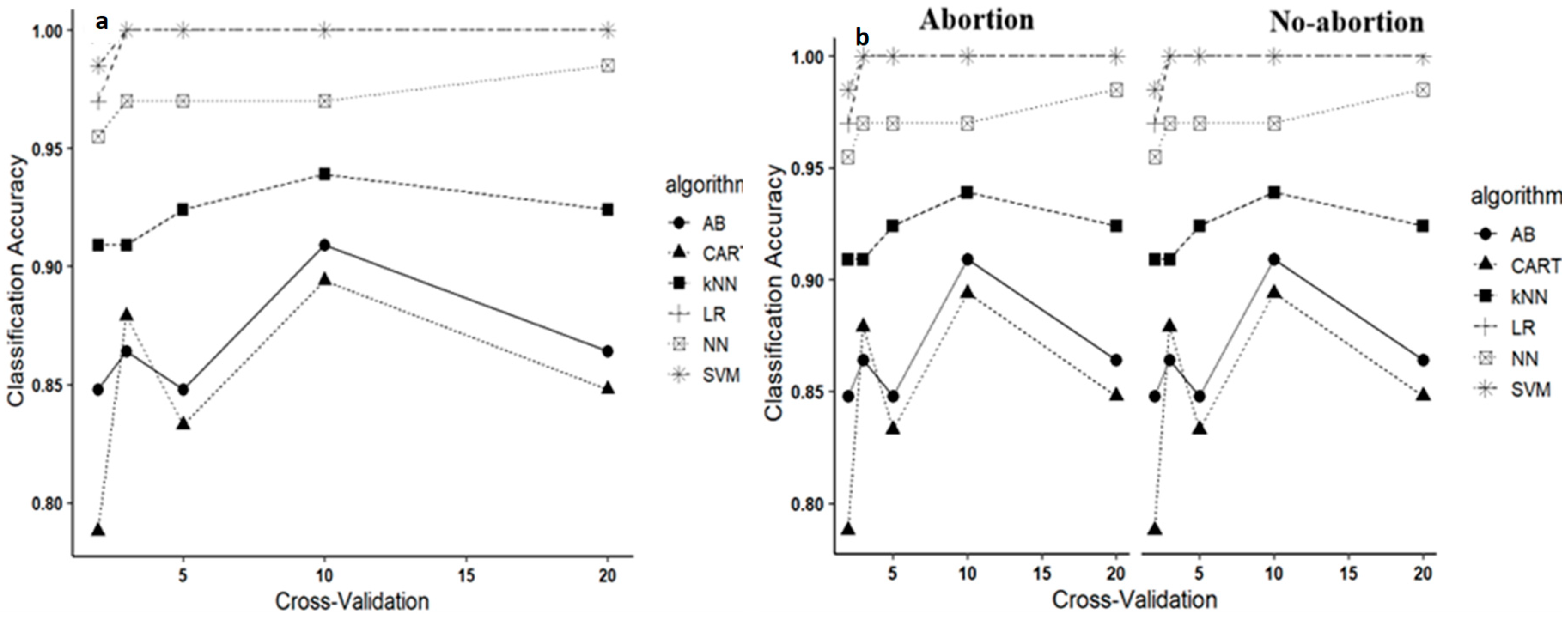
2.2.3. Training, Testing, and 10-Fold Cross-Validation
2.3. Binary Classification Machine Learning Algorithms
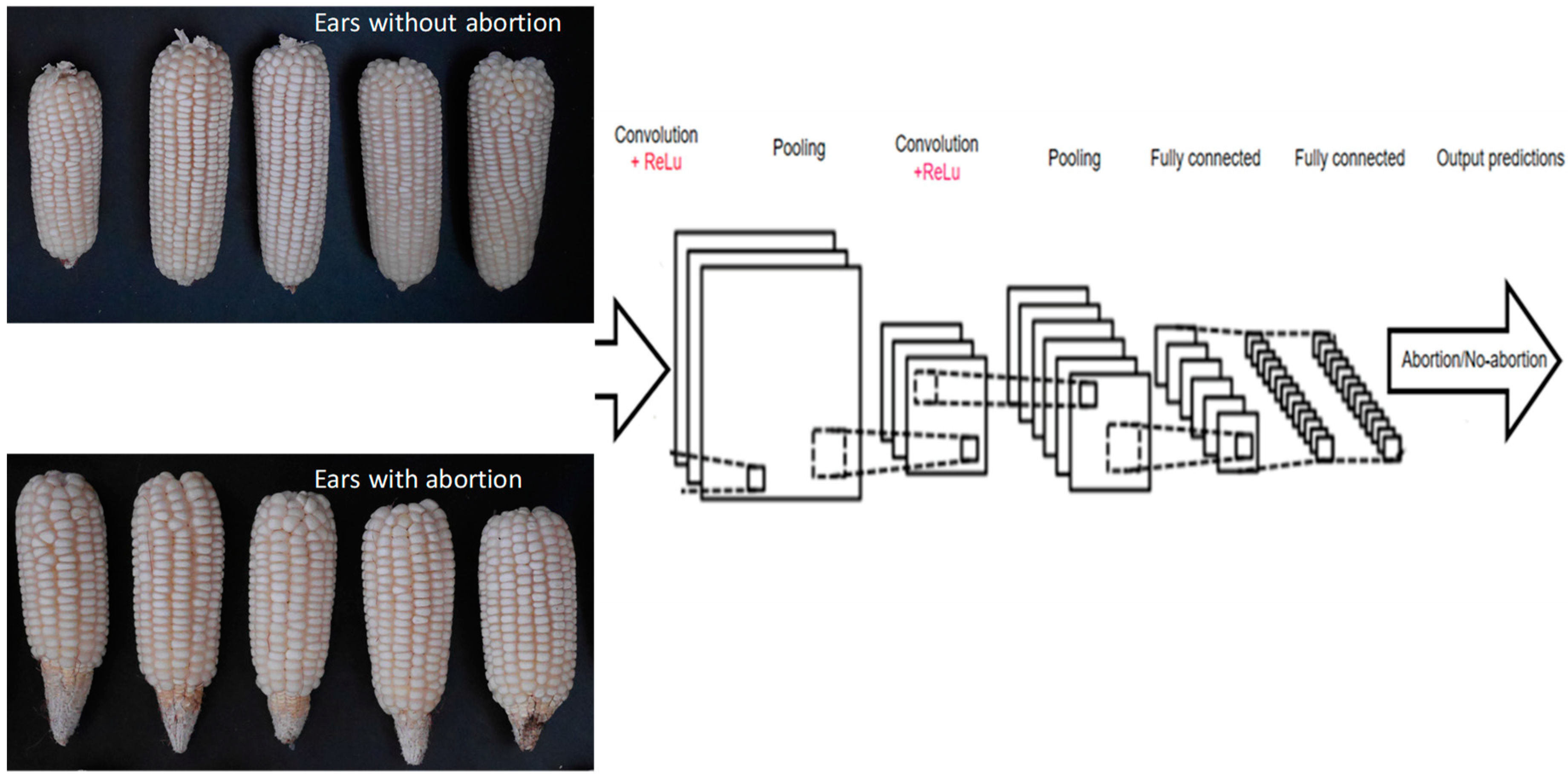
2.4. Convolutional Neural Networks
- Makes the input representations (feature dimension) smaller and more manageable;
- Reduces the number of parameters and computations in the network, therefore, controlling overfitting;
- Makes the network invariant to small transformations, distortions, and translations in the input image;
- Helps to arrive at an almost scale invariant representation of the image. This is very powerful since we can detect objects in an image no matter where they are located.
2.5. Algorithms Evaluation Techniques
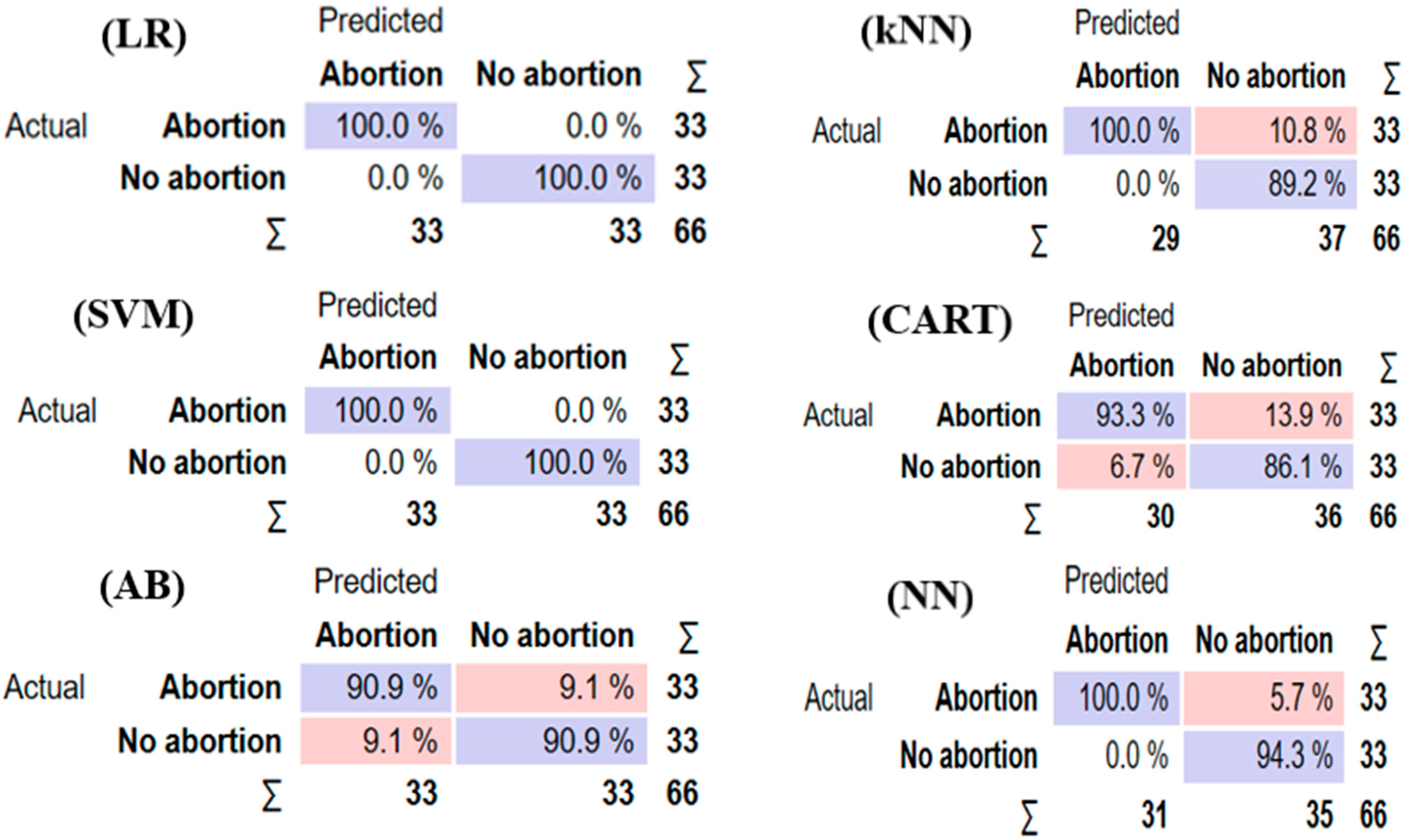
2.5.1. Confusion Matrix
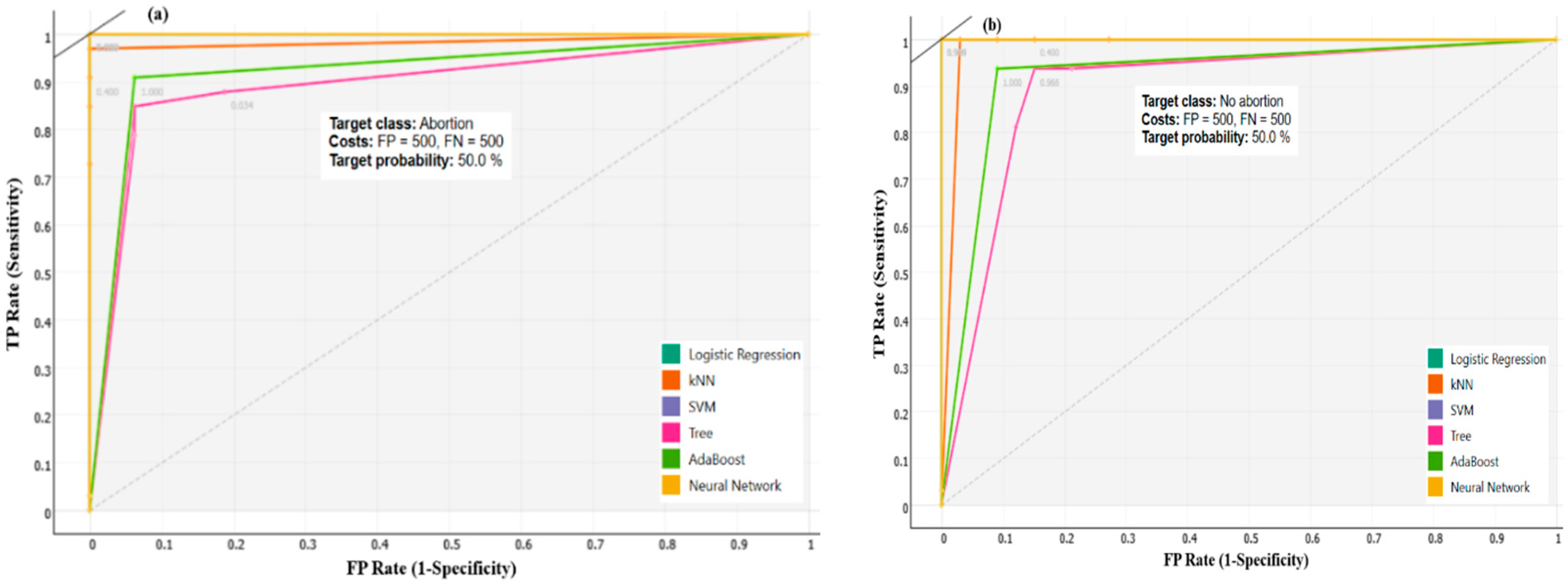
2.5.2. ROC Analysis
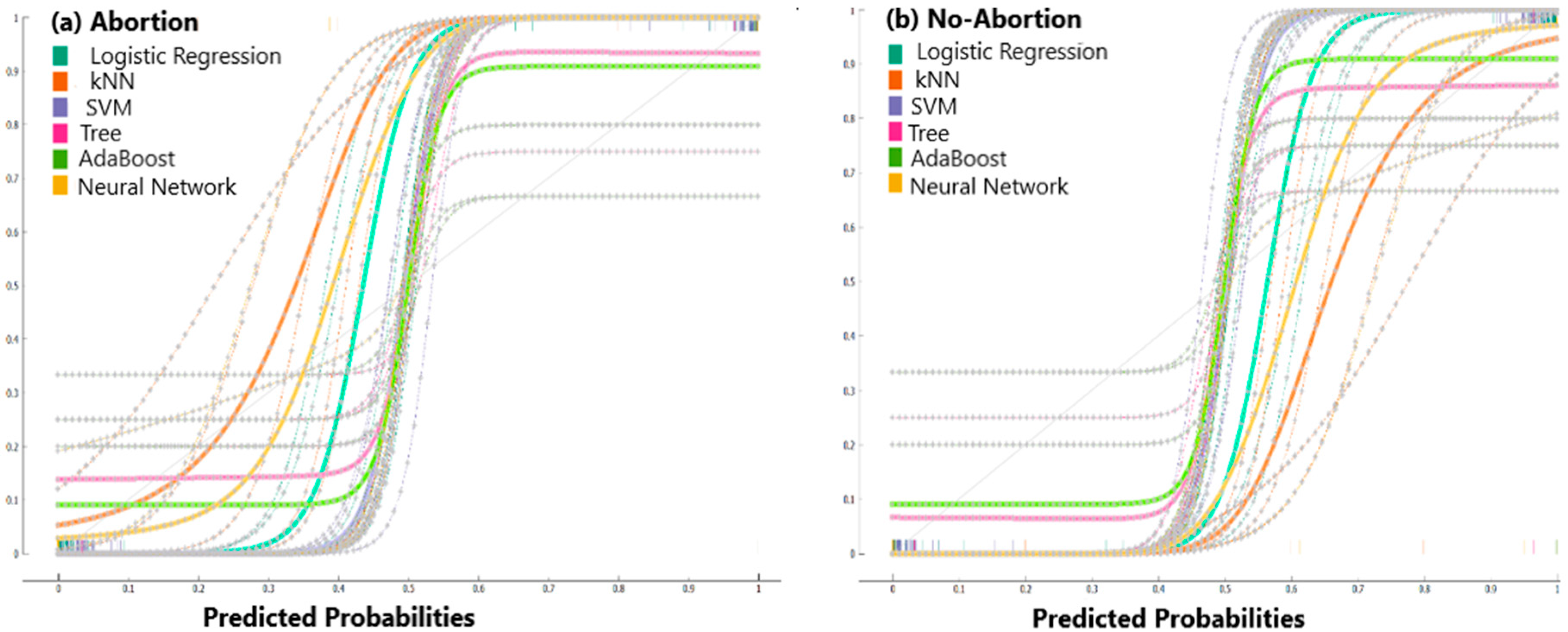
2.5.3. Calibration Plot
3. Results and Discussion
3.1. Binary Classification Algorithms
3.2. Deep Convolutional Neural Network
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Borrás, L.; Vitantonio-Mazzini, L.N. Maize reproductive development and kernel set under limited plant growth environments. J. Exp. Bot. 2018, 69, 3235–3243. [Google Scholar] [CrossRef]
- Hanft, J.M.; Jones, R.J. Kernel abortion in maize. Plant Physiol. 1986, 81, 511–515. [Google Scholar] [CrossRef] [Green Version]
- Gustin, J.L.; Boehlein, S.K.; Shaw, J.R.; Junior, W.; Settles, A.M.; Webster, A.; Tracy, W.F.; Hannah, L.C. Ovary abortion is prevalent in diverse maize inbred lines and is under genetic control. Sci. Rep. 2018, 8, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Tao, H.; Zhang, B.; Huang, S.; Wang, P. Timing of water deficit limits maize kernel setting in association with changes in the source-flow-sink relationship. Front. Plant Sci. 2018, 9, 1326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheikh, N.; Jones, R.J. Disruption of maize kernel growth and development by heat stress (role of cytokinin/abscisic acid balance). Plant Physiol. Am. Soc. Plant Biol. 1994, 106, 45–51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vasseur, F.; Bresson, J.; Wang, G.; Schwab, R.; Weigel, D. Image-based methods for phenotyping growth dynamics and fitness components in Arabidopsis thaliana. Plant Methods 2018, 14, 63. [Google Scholar] [CrossRef]
- Makanza, R.; Zaman-Allah, M.; Cairns, J.E.; Eyre, J.; Burgueño, J.; Pacheco, Á.; Diepenbrock, C.; Magorokosho, C.; Tarekegne, A.; Olsen, M.; et al. High—Throughput method for ear phenotyping and kernel weight estimation in maize using ear digital imaging. Plant Methods 2018, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Miller, N.D.; Haase, N.J.; Lee, J.; Kaeppler, S.M.; de Leon, N.; Spalding, E.P. A robust, high-throughput method for computing maize ear, cob, and kernel attributes automatically from images. Plant J. 2017, 89, 169–178. [Google Scholar] [CrossRef]
- Liang, X.; Wang, K.; Huang, C.; Zhang, X.; Yan, J.; Yang, W. A high-throughput maize kernel traits scorer based on line-scan imaging. Meas. J. Int. Meas. Confed. 2016, 90, 453–460. [Google Scholar] [CrossRef]
- Hausmann, N.J.; Abadie, T.E.; Cooper, M.; Lafitte, H.R.; Schussler, J.R. Method and System for Digital Image Analysis of Ear Traits. 2009. Available online: https://patents.google.com/patent/US20090046890 (accessed on 12 February 2018).
- Shen, S.; Zhang, L.; Liang, X.G.; Zhao, X.; Lin, S.; Qu, L.H.; Liu, Y.P.; Gao, Z.; Ruan, Y.L.; Zhou, S.L. Delayed pollination and low availability of assimilates are major factors causing maize kernel abortion. J. Exp. Bot. 2018, 69, 1599–1613. [Google Scholar] [CrossRef]
- Turc, O.; Tardieu, F. Drought affects abortion of reproductive organs by exacerbating developmentally driven processes via expansive growth and hydraulics. J. Exp. Bot. 2018, 69, 3245–3254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–27. [Google Scholar] [CrossRef]
- Paiva, R.P. Machine Learning: Applications, Process and Techniques. 2013. Available online: https://eden.dei.uc.pt/~ruipedro/publications/Tutorials/slidesML.pdf (accessed on 30 August 2020).
- Joshi, P. Artificial Intelligence with Python; Packt Publishing: Birmingham, UK, 2017; ISBN 9781786469670. [Google Scholar]
- Jin, S.; Su, Y.; Gao, S.; Wu, F.; Hu, T.; Liu, J.; Li, W.; Wang, D.; Chen, S.; Jiang, Y.; et al. Deep learning: Individual maize segmentation from terrestrial lidar data using faster R-CNN and regional growth algorithms. Front. Plant Sci. 2018, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Pound, M.P.; Atkinson, J.A.; Townsend, A.J.; Wilson, M.H.; Griffiths, M.; Jackson, A.S.; Bulat, A.; Tzimiropoulos, G.; Wells, D.M.; Murchie, E.H.; et al. Deep machine learning provides state-of-the-art performance in image-based plant phenotyping. GigaScience 2017, 6, 1–10. [Google Scholar] [CrossRef]
- Ubbens, J.R.; Stavness, I. Deep plant phenomics: A deep learning platform for complex plant phenotyping tasks. Front. Plant Sci. 2017, 8. [Google Scholar] [CrossRef] [Green Version]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Baweja, H.S.; Parhar, T.; Mirbod, O.; Nuske, S. StalkNet: A deep learning pipeline for high-throughput measurement of plant stalk count and stalk width. In Field and Service Robotics; Springer: Cham, Switzerland, 2018; pp. 271–284. [Google Scholar] [CrossRef]
- Xiong, X.; Duan, L.; Liu, L.; Tu, H.; Yang, P.; Wu, D.; Chen, G.; Xiong, L.; Yang, W.; Liu, Q. Panicle-SEG: A robust image segmentation method for rice panicles in the field based on deep learning and superpixel optimization. Plant Methods 2017, 13, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Russell, S. Handbook of Perception and Cognition, Volume 14, Chapter 4: Machine Learning. 2007. Available online: https://people.eecs.berkeley.edu/~russell/papers/hpc-machine-learning.pdf (accessed on 30 August 2020).
- Moons, B.; Bankman, D.; Verhelst, M. Embedded Deep Learning; Springer Nature Switzerland AG: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Ghatak, A. Deep Learning with R; Springer: Singapore, 2019. [Google Scholar] [CrossRef]
- Ciaburro, G.; Venkateswaran, B. Neural Networks with R Smart Models Using CNN, RNN, Deep Learning, and Artificial Intelligence Principles; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Johann, J.A.; Rocha, J.V.; Oliveira, S.R.D.M.; Rodrigues, L.H.; Lamparelli, R.A. Data mining techniques for identification of spectrally homogeneous areas using NDVI temporal profiles of soybean crop. Eng. Agrícola 2013, 33, 511–524. [Google Scholar] [CrossRef] [Green Version]
- Jackson, A.H. Machine learning. Expert Syst. 1988, 5, 132–150. [Google Scholar] [CrossRef]
- Taylor, A.; Arnold, M.T. Package “kerasR”. 2017. Available online: https://github.com/openjournals/joss-reviews/issues/296 (accessed on 30 August 2020).
- Neapolitan, R.E.; Neapolitan, R.E. Neural Networks and Deep Learning. In Artificial Intelligence: With an Introduction to Machine Learning, 2nd ed.; Chapman and Hall/CRC: New York, NY, USA, 2018; ISBN 9781315144863. [Google Scholar]
- Yoshida, Y.; Yuda, E.; Yamamoto, K.; Miura, Y.; Hayano, J. Machine-learning estimation of body posture and physical activity by wearable acceleration and heartbeat sensors. Int. J. (SIPIJ) 2019, 10, 1–9. [Google Scholar] [CrossRef]
- Warman, C.; Fowler, J.E. Custom built scanner and simple image processing pipeline enables low-cost, high-throughput phenotyping of maize ears. bioRxiv 2019. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, B.; He, X.; Ouyang, F.; Gu, D.; Dong, Y.; Zhang, L.; Mo, X.; Huang, W.; Tian, J.; Zhang, S. Radiomic machine-learning classifiers for prognostic biomarkers of advanced nasopharyngeal carcinoma. Cancer Lett. 2017. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Li, C.; Yang, F. Classification of foreign matter embedded inside cotton lint using short wave infrared (SWIR) hyperspectral transmittance imaging. Comput. Electron. Agric. 2017. [Google Scholar] [CrossRef]
- Ebrahimi, M.A.; Khoshtaghaza, M.H.; Minaei, S.; Jamshidi, B. Vision-based pest detection based on SVM classification method. Comput. Electron. Agric. 2017. [Google Scholar] [CrossRef]
- Vuk, M.; Curk, T. ROC curve, lift chart and calibration plot. Metodološki Zv. 2006, 3, 1. [Google Scholar]
- Pantazi, X.E.; Moshou, D.; Bravo, C. Active learning system for weed species recognition based on hyperspectral sensing. Biosyst. Eng. 2016. [Google Scholar] [CrossRef]
- Berrar, D. Cross-validation. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018. [Google Scholar] [CrossRef]
- Su, J.; Liu, C.; Coombes, M.; Hu, X.; Wang, C.; Xu, X.; Li, Q.; Guo, L.; Chen, W.H. Wheat yellow rust monitoring by learning from multispectral UAV aerial imagery. Comput. Electron. Agric. 2018. [Google Scholar] [CrossRef]
- Moshou, D.; Bravo, C.; Wahlen, S.; West, J.; McCartney, A.; De Baerdemaeker, J.; Ramon, H. Simultaneous identification of plant stresses and diseases in arable crops using proximal optical sensing and self-organising maps. Precis. Agric. 2006. [Google Scholar] [CrossRef]
- Larese, M.G.; Namías, R.; Craviotto, R.M.; Arango, M.R.; Gallo, C.; Granitto, P.M. Automatic classification of legumes using leaf vein image features. Pattern Recognit. 2014. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Train Time (s) | Test Time (s) | CA | F1 | Precision | Recall | LogLoss | Specificity |
|---|---|---|---|---|---|---|---|---|
| CART | 1.550 | 0.000 | 0.894 | 0.894 | 0.897 | 0.894 | 3.194 | 0.894 |
| AB | 3.245 | 1.502 | 0.909 | 0.909 | 0.909 | 0.909 | 3.140 | 0.909 |
| kNN | 2.572 | 2.409 | 0.939 | 0.939 | 0.946 | 0.939 | 0.607 | 0.939 |
| NN | 11.683 | 4.186 | 0.970 | 0.970 | 0.971 | 0.970 | 0.060 | 0.970 |
| LR | 2.821 | 2.306 | 1.000 | 1.000 | 1.000 | 1.000 | 0.026 | 1.000 |
| SVM | 8.997 | 2.932 | 1.000 | 1.000 | 1.000 | 1.000 | 0.034 | 1.000 |
| Activation | Solver | AUC | CA | F1 | Precision | Recall | LogLoss | Specificity |
|---|---|---|---|---|---|---|---|---|
| Identity | Adam | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.015 | 1.000 |
| L-BFGS-B | 1.000 | 0.985 | 0.985 | 0.985 | 0.985 | 0.041 | 0.985 | |
| SGD | 1.000 | 0.970 | 0.970 | 0.971 | 0.970 | 0.040 | 0.970 | |
| Logistic | Adam | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.014 | 1.000 |
| L-BFGS-B | 1.000 | 0.985 | 0.985 | 0.985 | 0.985 | 0.027 | 0.985 | |
| SGD | 1.000 | 0.985 | 0.985 | 0.985 | 0.985 | 0.027 | 0.985 | |
| Tanh | Adam | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.014 | 1.000 |
| L-BFGS-B | 1.000 | 0.985 | 0.985 | 0.985 | 0.985 | 0.041 | 0.985 | |
| SGD | 1.000 | 0.985 | 0.985 | 0.985 | 0.985 | 0.023 | 0.985 | |
| ReLu | Adam | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.014 | 1.000 |
| L-BFGS-B | 1.000 | 0.985 | 0.985 | 0.985 | 0.985 | 0.041 | 0.985 | |
| SGD | 1.000 | 0.985 | 0.985 | 0.985 | 0.985 | 0.023 | 0.985 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chipindu, L.; Mupangwa, W.; Mtsilizah, J.; Nyagumbo, I.; Zaman-Allah, M. Maize Kernel Abortion Recognition and Classification Using Binary Classification Machine Learning Algorithms and Deep Convolutional Neural Networks. AI 2020, 1, 361-375. https://doi.org/10.3390/ai1030024
Chipindu L, Mupangwa W, Mtsilizah J, Nyagumbo I, Zaman-Allah M. Maize Kernel Abortion Recognition and Classification Using Binary Classification Machine Learning Algorithms and Deep Convolutional Neural Networks. AI. 2020; 1(3):361-375. https://doi.org/10.3390/ai1030024
Chicago/Turabian StyleChipindu, Lovemore, Walter Mupangwa, Jihad Mtsilizah, Isaiah Nyagumbo, and Mainassara Zaman-Allah. 2020. "Maize Kernel Abortion Recognition and Classification Using Binary Classification Machine Learning Algorithms and Deep Convolutional Neural Networks" AI 1, no. 3: 361-375. https://doi.org/10.3390/ai1030024
APA StyleChipindu, L., Mupangwa, W., Mtsilizah, J., Nyagumbo, I., & Zaman-Allah, M. (2020). Maize Kernel Abortion Recognition and Classification Using Binary Classification Machine Learning Algorithms and Deep Convolutional Neural Networks. AI, 1(3), 361-375. https://doi.org/10.3390/ai1030024