Comparing U-Net Based Models for Denoising Color Images


Abstract
:1. Introduction
- Residual U-Net and Dense U-Net tend to be robust in denoising different kinds of noise even if the parameters of the noise level are unknown during the training process.
- Comparing the quality of the loss objectives, the stronger L1 norm and the L1 norm summed with adversarial loss output better peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) results in the testing phase than the simple L1 norm.
2. Related Study: Denoising Learning
3. U-Net Architectures for Denoising
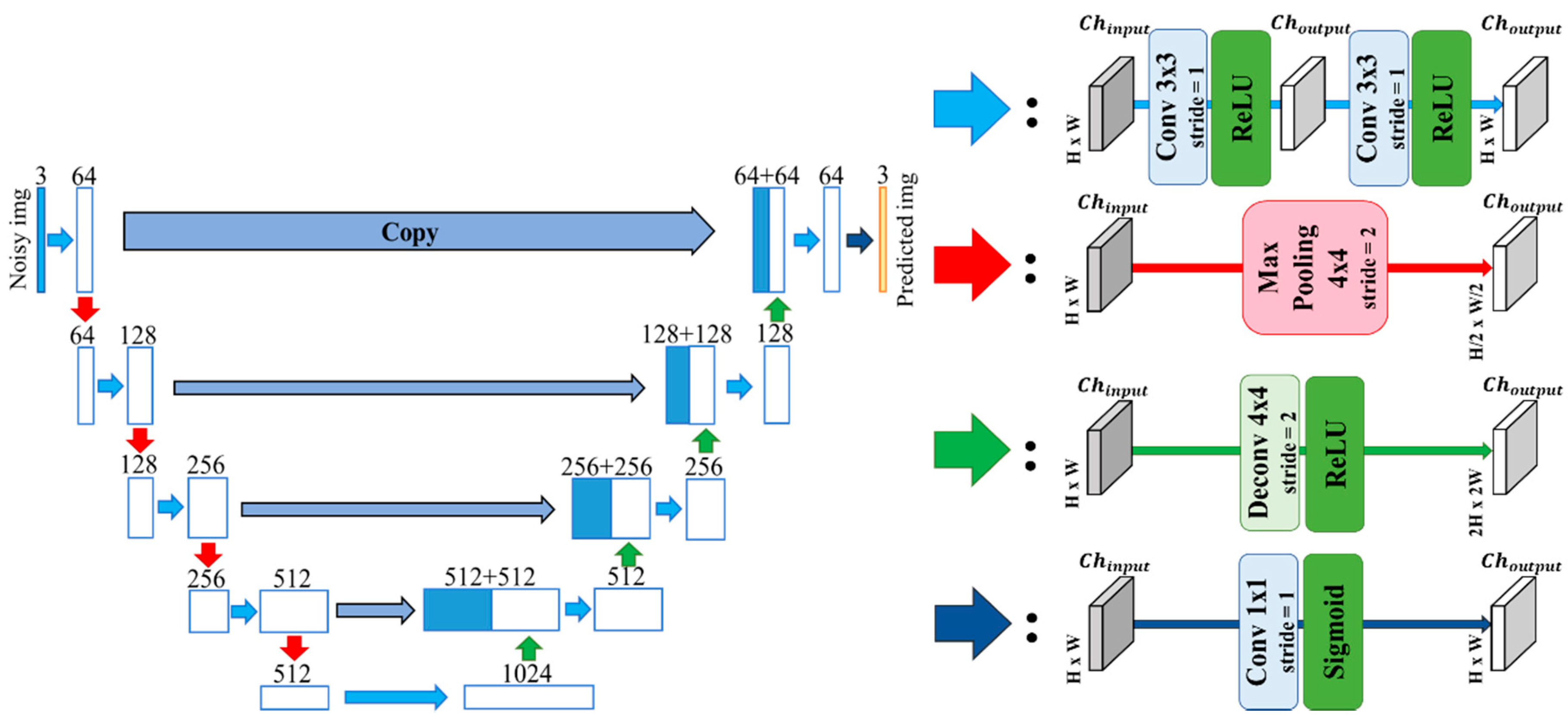
3.1. U-Net
3.2. U-Net with Group Normalization
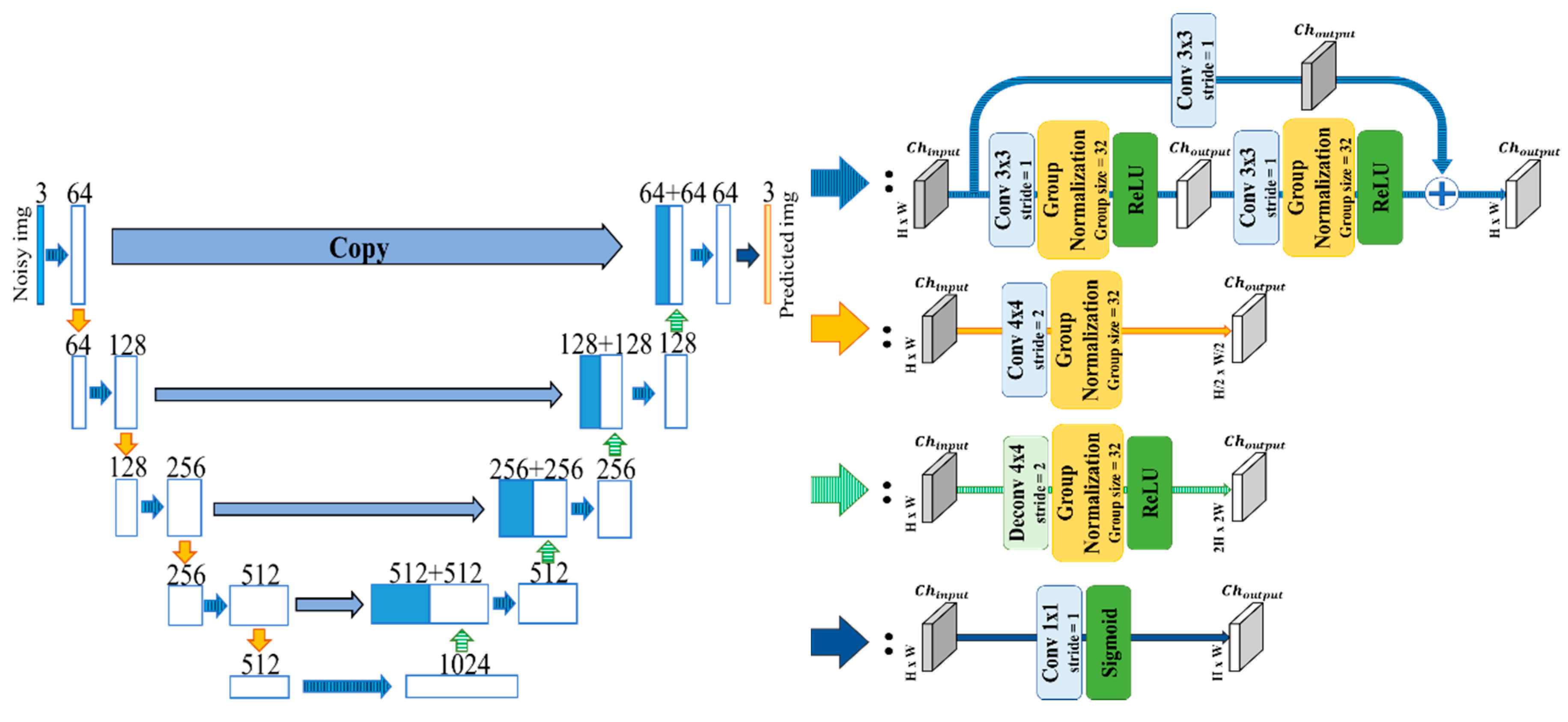
3.3. Residual U-Net
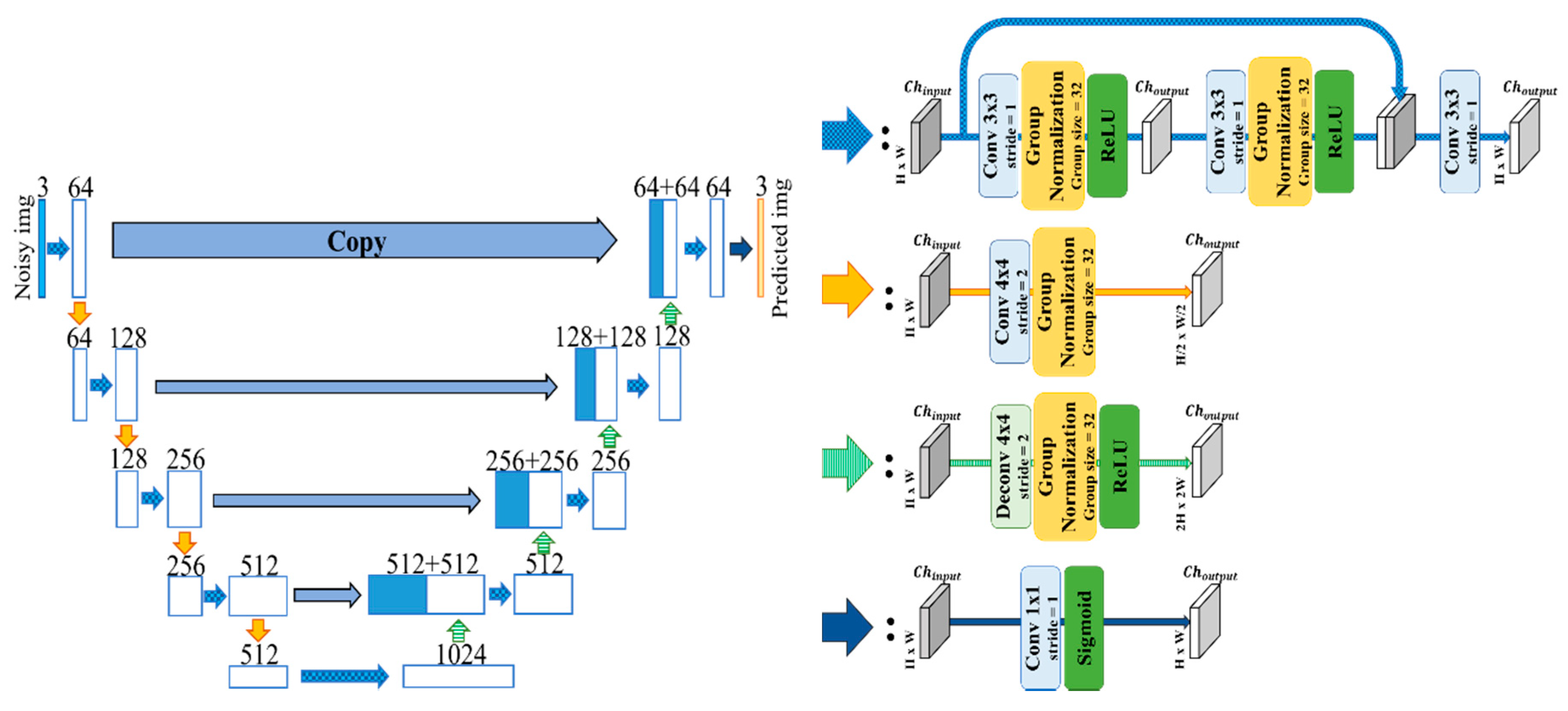
3.4. Dense U-Net
4. Loss Functions for Denoising
4.1. L1 Norm
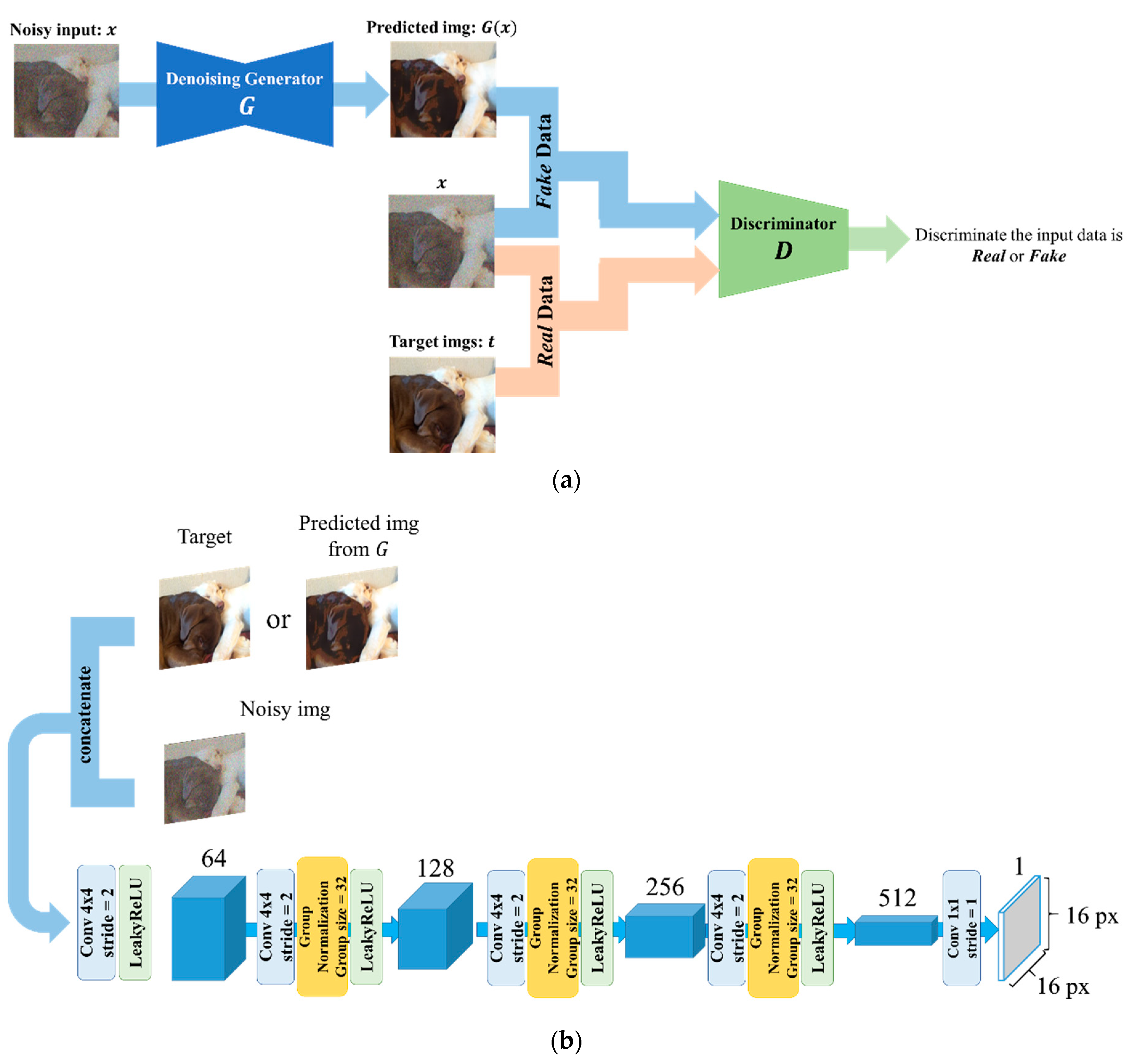
4.2. L1 Norm + Adversarial Loss
5. Denoising Experiments
5.1. Dataset
5.2. Image Pre-Processing
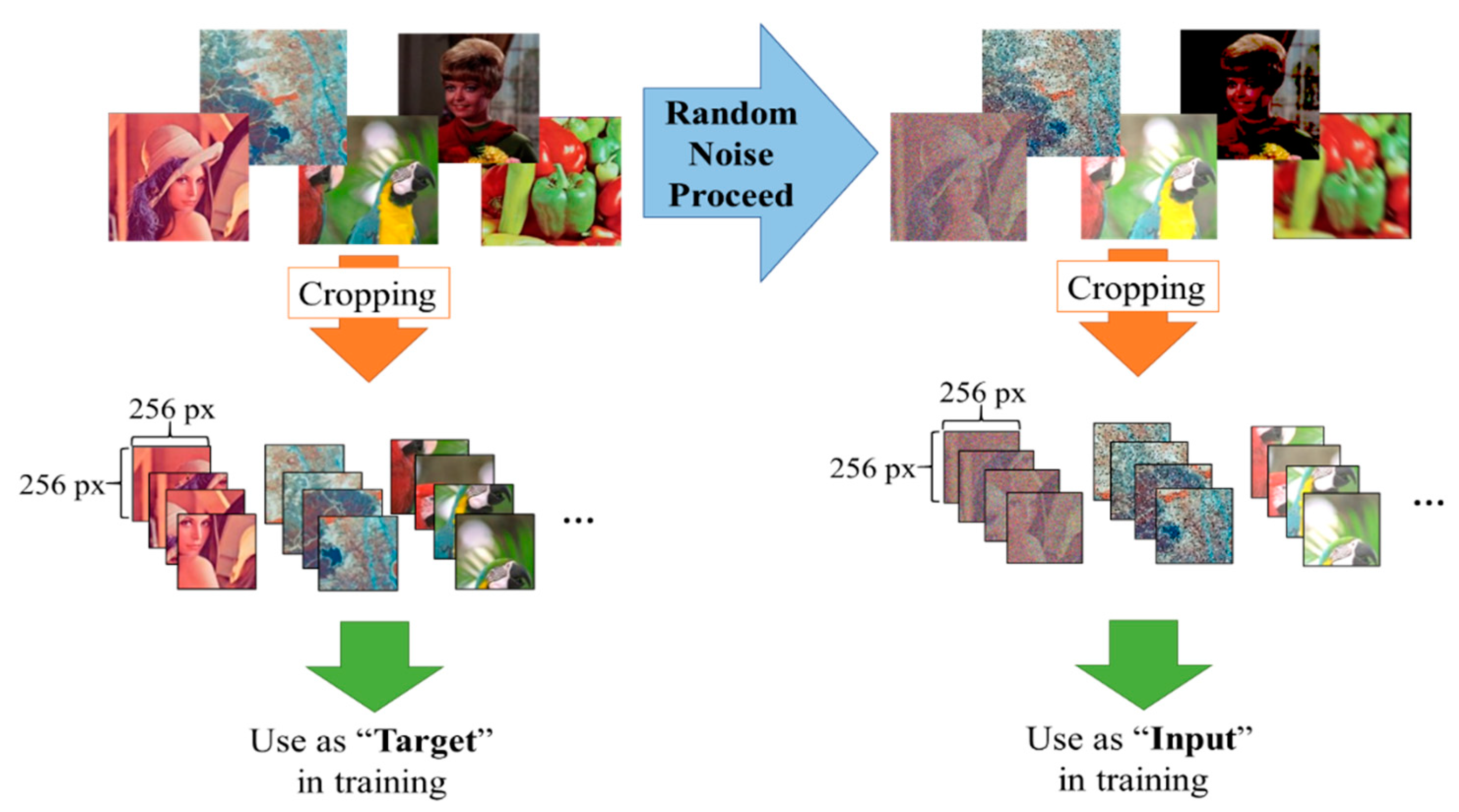
5.3. Adding Noise to Training Images at Random
5.4. Generating Patches from the Image
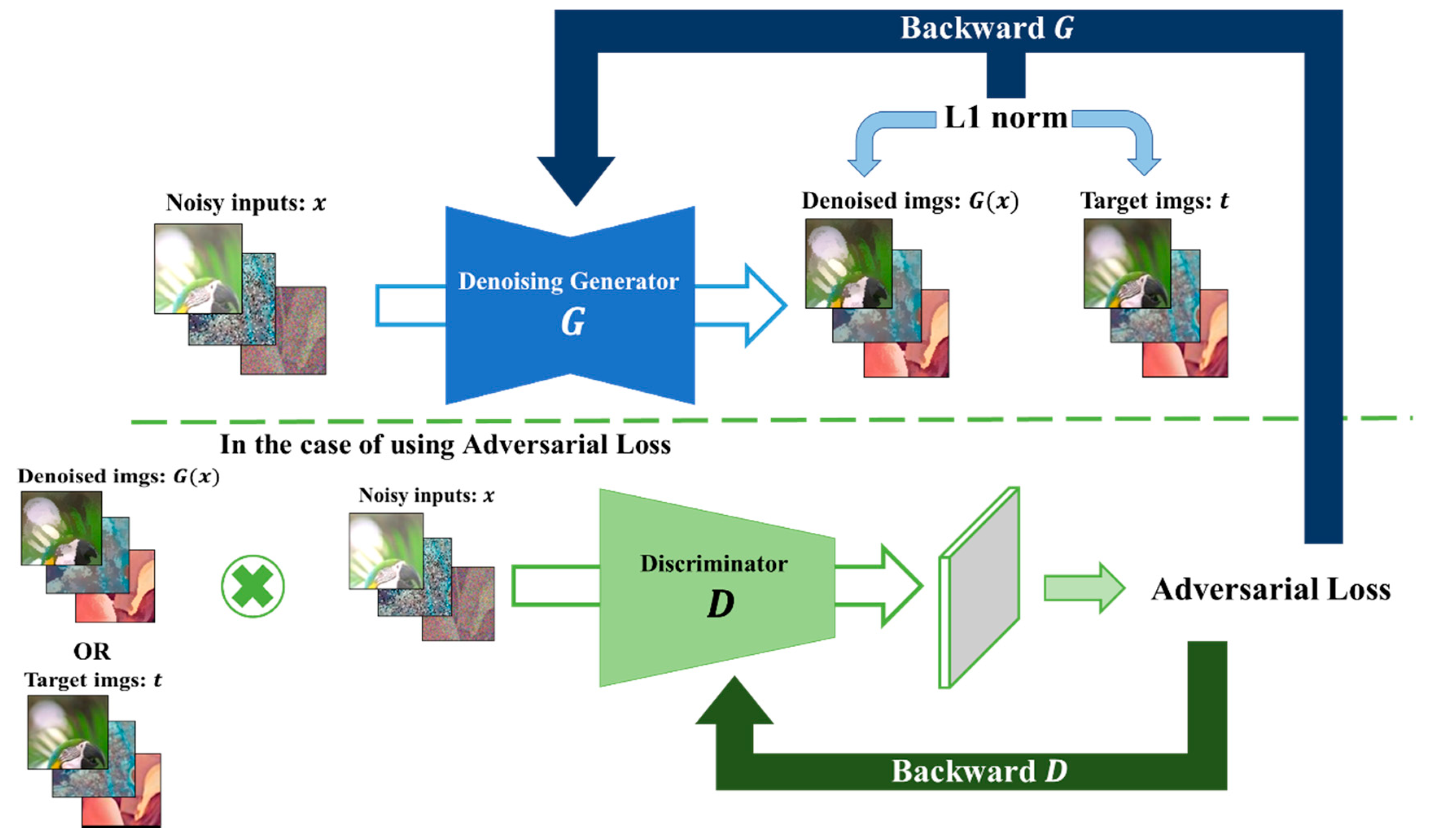
5.5. Denoising Training Implementation
- S1.
- Input the noisy images to .
- S2.
- Get the predicted denoised output images .
- S3.
- Compute L1 norm loss by comparing and clean target images .
- S4.
- Train the parameters of through backpropagation.
- S1.
- Input to .
- S2.
- Using , input the pair of data to and get adversarial loss from by comparing with the real label.
- S3.
- Adopting L1 norm and adversarial loss as the total loss of , backpropagate and
- S4.
- update the parameters of .Input pairs of fake data and real data , to .
- S5.
- Calculate adversarial loss by comparing with fake label and with
- S6.
- real label. Adopting adversarial loss in Step5 as the total loss of , backpropagate and update the parameters of .
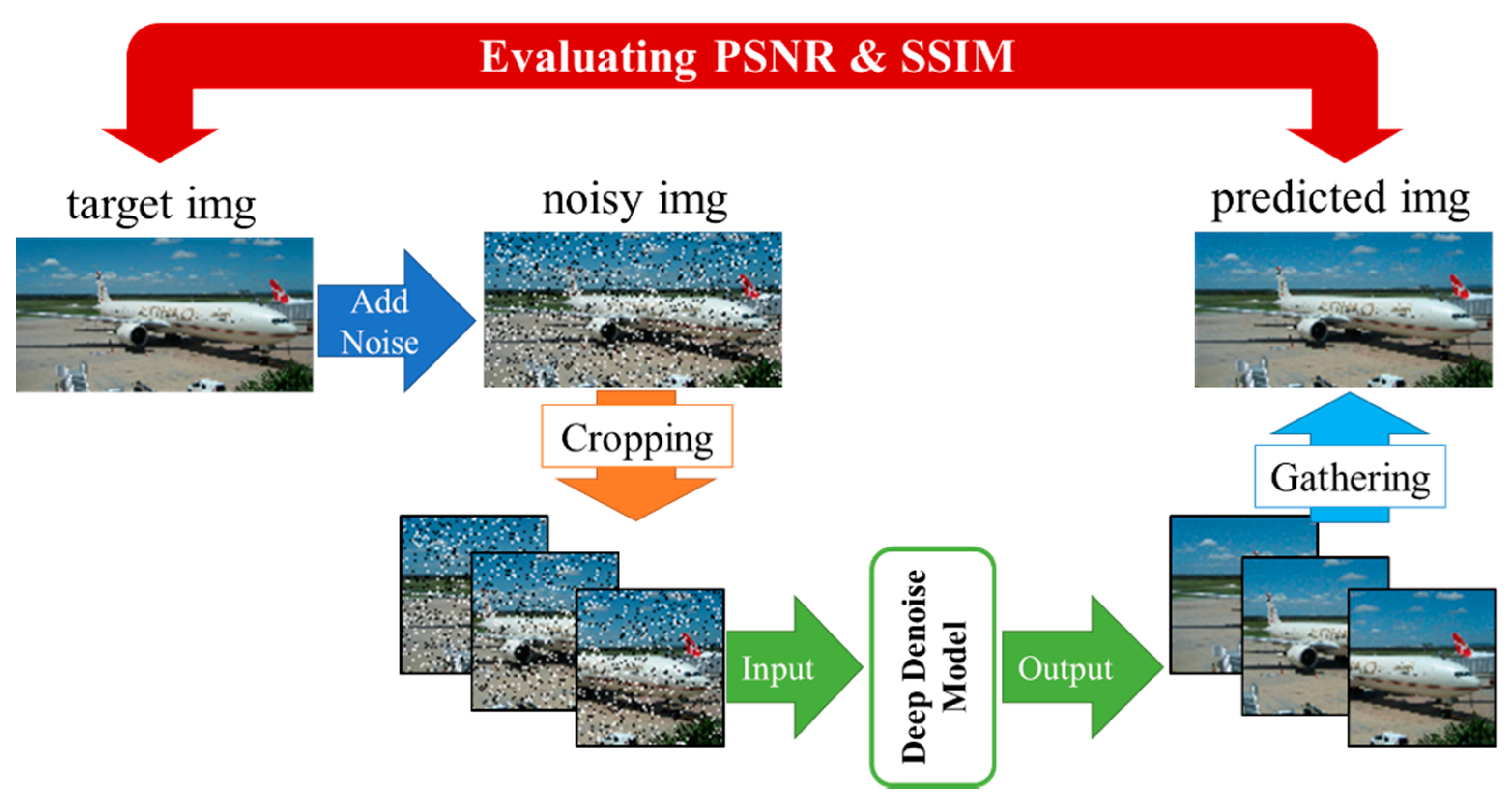
6. Results
- S1.
- Input a clean test image and use it as a target image.
- S2.
- Add noise to target image and use it as noisy image.
- S3.
- Crop the noisy image to 256 × 256 size.
- S4.
- Input the noisy cropped images to the deep denoising model, and obtain de-noised cropped images.
- S5.
- Collected cropped output images from the model. Patch them together to form the denoised predicted image.
- S6.
- Evaluate the predicted image using PSNR and SSIM compared to the target image.
6.1. Denoising Results: Gaussian Noise
6.2. Denoising Results: Salt-and-Pepper Noise
6.3. Denoising Results: Clipped Whites
6.4. Denoising Results: Clipped Blacks
6.5. Denoising Results: Camera Shake
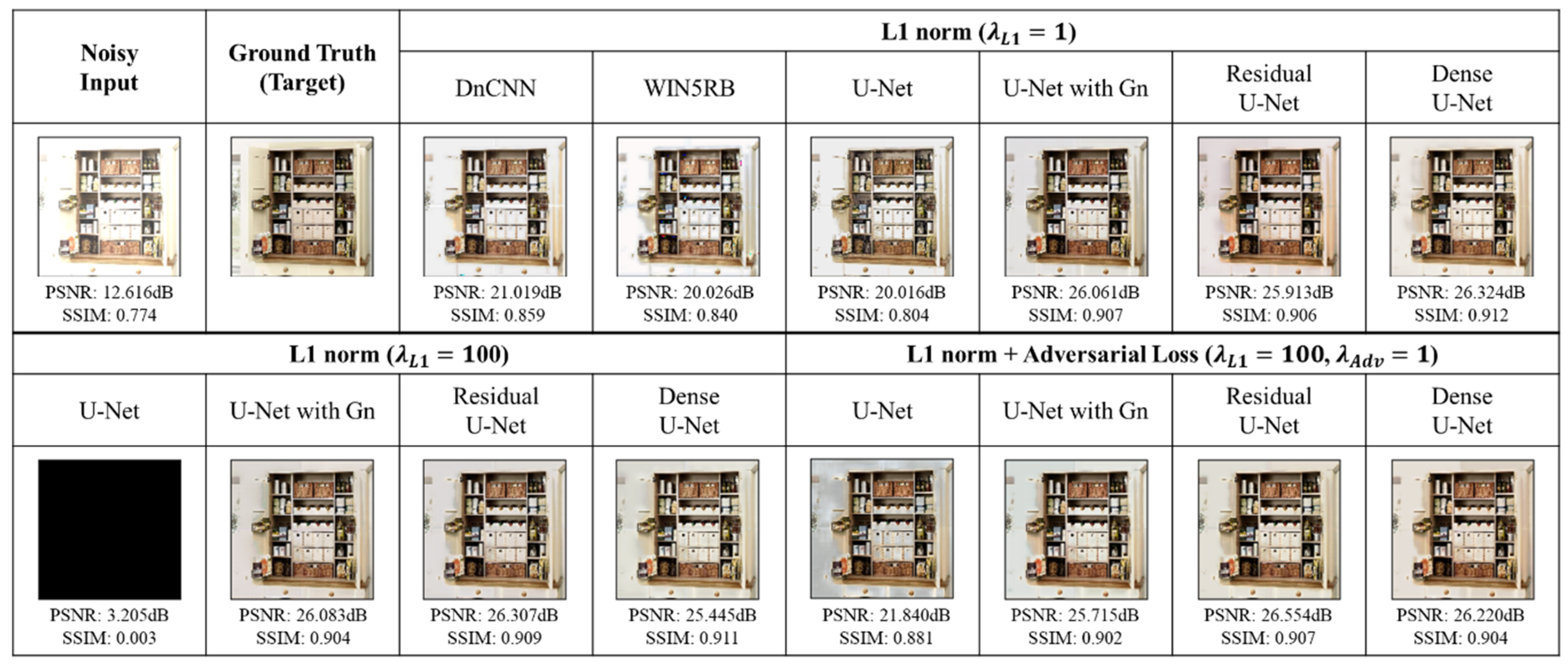
6.6. Comparing the U-Net Based Model’s Denoisng Perfromace with Standard Models
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, Y.; Zhang, B.; Florent, R. Understanding neural-network denoisers through an activation function perspective. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain Neural Networks compete with BM3D? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, Rhode Island, 16–21 June 2012.
- Abubakar, A.; Zhao, X.; Li, S.; Takruri, M.; Bastaki, E.; Bermak, A. A Block-Matching and 3-D Filtering Algorithm for Gaussian Noise in DoFP Polarization Images. IEEE Sens. J. 2018, 18, 7429–7435. [Google Scholar] [CrossRef]
- Rabbouch, H.; Saâdaoui, F.; Vasilakos, A.V. A wavelet-assisted subband denoising for tomographic image reconstruction. J. Vis. Commun. Image Represent. 2018, 55, 115–130. [Google Scholar] [CrossRef]
- Kaur, G.; Kaur, R. Image De-Noising using Wavelet Transform and Various Filters. Int. J. Res. Comput. Sci. 2012, 2, 15–21. [Google Scholar] [CrossRef]
- Song, Q.; Ma, L.; Cao, J.; Han, X. Image Denoising Based on Mean Filter and Wavelet Transform. In Proceedings of the 4th International Conference on Advanced Information Technology and Sensor Application (AITS), Harbin, China, 21–23 August 2015. [Google Scholar]
- Vyas, A.; Paik, J. Applications of multiscale transforms to image denoising: Survey. In Proceedings of the International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018. [Google Scholar]
- Bhonsle, D.; Chandra, V.; Sinha, G. Medical Image Denoising Using Bilateral Filter. Int. J. Image Graph. Signal Process. 2012, 4, 36–43. [Google Scholar] [CrossRef] [Green Version]
- Kumar, B.K.S. Image denoising based on gaussian/bilateral filter and its method noise thresholding. Signal Image Video Process. 2012, 7, 1159–1172. [Google Scholar] [CrossRef]
- Sarker, S. Use of Non-Local Means Filter to Denoise Image Corrupted by Salt and Pepper Noise. Signal Image Process. Int. J. 2012, 3, 223–235. [Google Scholar] [CrossRef]
- Gacsadi, A.; Szolgay, P. Variational computing based images denoising methods by using cellular neural networks. In Proceedings of the European Conference on Circuit Theory and Design, Antalya, Turkey, 23–27 August 2009. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-Local Recurrent Network for Image Restoration. Adv. Neural Inf. Process. Syst. 2018, 2018-December, 1673–1682. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2019, 27, 1071–1092. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 1 May 2020).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 1, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Galea, C.; Farrugia, R.A. Matching Software-Generated Sketches to Face Photographs With a Very Deep CNN, Morphed Faces, and Transfer Learning. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1421–1431. [Google Scholar] [CrossRef]
- Ranjan, R.; Patel, V.M.; Chellappa, R. HyperFace: A Deep Multi-Task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 121–135. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, A.; Kim, J.; Lyndon, D.; Fulham, M.; Feng, D. An Ensemble of Fine-Tuned Convolutional Neural Networks for Medical Image Classification. IEEE J. Biomed. Heal. Inf. 2016, 21, 31–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chandra, B.S.; Sastry, C.S.; Jana, S. Robust Heartbeat Detection from Multimodal Data via CNN-Based Generalizable Information Fusion. IEEE Trans. Biomed. Eng. 2018, 66, 710–717. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.-W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef] [PubMed]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the Eighth International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Nazaré, T.S.; Da Costa, G.B.P.; Contato, W.A.; Ponti, M.A. Deep Convolutional Neural Networks and Noisy Images. In Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; pp. 416–424. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lucas, A.; Iliadis, M.; Molina, R.; Katsaggelos, A.K. Using Deep Neural Networks for Inverse Problems in Imaging: Beyond Analytical Methods. IEEE Signal Process. Mag. 2018, 35, 20–36. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: New York, NY, USA, 2015; pp. 234–241. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. Int. J. Comput. Vis. 2019, 128, 742–755. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hinton, G. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Gondara, L. Medical Image Denoising Using Convolutional Denoising Autoencoders. In Proceedings of the IEEE 16th International Conference on Data Mining Workshops (ICDMW); Institute of Electrical and Electronics Engineers (IEEE), Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Xiang, Q.; Pang, X. Improved Denoising Auto-Encoders for Image Denoising. In Proceedings of the 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018. [Google Scholar]
- Ghose, S.; Singh, N.; Singh, P. Image Denoising using Deep Learning: Convolutional Neural Network. In Proceedings of the 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020. [Google Scholar]
- Li, X.; Xiao, J.; Zhou, Y.; Ye, Y.; Lv, N.; Wang, X.; Wang, S.; Gao, S. Detail retaining convolutional neural network for image denoising. J. Vis. Commun. Image Represent. 2020, 71, 102774. [Google Scholar] [CrossRef]
- Esser, P.; Sutter, E. A Variational U-Net for Conditional Appearance and Shape Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Komatsu, R.; Gonsalves, T. Effectiveness of U-Net in Denoising RGB Images. Comput. Sci. Inf. Techn. 2019, 1–10. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Institute of Electrical and Electronics Engineers (IEEE), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, arXiv:1406.2661v1, 2672–2680. [Google Scholar]
- Yang, L.; Shangguan, H.; Zhang, X.; Wang, A.; Han, Z. High-Frequency Sensitive Generative Adversarial Network for Low-Dose CT Image Denoising. IEEE Access 2020, 8, 930–943. [Google Scholar] [CrossRef]
- Park, H.S.; Baek, J.; You, S.K.; Choi, J.K.; Seo, J.K. Unpaired Image Denoising Using a Generative Adversarial Network in X-Ray CT. IEEE Access 2019, 7, 110414–110425. [Google Scholar] [CrossRef]
- Alsaiari, A.; Rustagi, R.; Alhakamy, A.; Thomas, M.M.; Forbes, A.G. Image Denoising Using A Generative Adversarial Network. In Proceedings of the IEEE 2nd International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 13–17 March 2019. [Google Scholar]
- Gopan, K.; Kumar, G. Video Super Resolution with Generative Adversarial Network. In Proceedings of the 2nd International Conference on Trends in Electronics and Informatics (ICOEI), Tiruneveli, India, 11–12 May 2018. [Google Scholar]
- López-Tapia, S.; Lucas, A.; Molina, R.; Katsaggelos, A.K. A single video super-resolution GAN for multiple downsampling operators based on pseudo-inverse image formation models. Digit. Signal Process. 2020, 104, 102801. [Google Scholar] [CrossRef]
- Bell-Kligler, S.; Shocher, A.; Irani, M. Blind super-resolution kernel estimation using an internal-GAN. Adv. Neural Inf. Process. Syst. 2019, 1, 284–293. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Majeeth, S.; Babu, C.K. A Novel Algorithm to Remove Gaussian Noise in an Image. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Tamil Nadu, India, 14–16 December 2017. [Google Scholar]
- Thanh, D.N.H.; Thanh, L.T.; Hien, N.N.; Prasath, V.B.S. Adaptive total variation L1 regularization for salt and pepper image denoising. Optik 2020, 208, 163677. [Google Scholar] [CrossRef]
- Faraji, H.; MacLean, W.J. CCD noise removal in digital images. IEEE Trans. Image Process. 2006, 15, 2676–2685. [Google Scholar] [CrossRef]
- Anaya, J.; Barbu, A. RENOIR—A dataset for real low-light image noise reduction. J. Vis. Commun. Image Represent. 2018, 51, 144–154. [Google Scholar] [CrossRef] [Green Version]
- Guo, B.; Song, K.; Dong, H.; Yan, Y.; Tu, Z.; Zhu, L. NERNet: Noise estimation and removal network for image denoising. J. Vis. Commun. Image Represent. 2020, 71, 102851. [Google Scholar] [CrossRef]
- Dong, H.; Yang, G.; Liu, F.; Mo, Y.; Guo, Y. Automatic Brain Tumor Detection and Segmentation Using U-Net Based Fully Convolutional Networks. In Communications in Computer and Information Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2017; pp. 506–517. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation; Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2016; Volume 9901, pp. 424–432. [Google Scholar]
- Jansson, A.; Humphrey, E.; Montecchio, N.; Bittener, R.; Kumar, A.; Weyde, T. Singing Voice Separation with Deep U-Net Convolutional Networks. In Proceedings of the 18th International Society for Music Information Retrieval Conference, Suzhou, China, 23–27 October 2017. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? Adv. Neural Inf. Process. Syst. 2019, arXiv:1805.11604, 2483–2493. [Google Scholar]
- Zhang, L.; Ji, Y.; Lin, X.; Liu, C. Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GAN. In Proceedings of the 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2018. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Li, C.-N.; Shao, Y.-H.; Deng, N.-Y. Robust L1-norm two-dimensional linear discriminant analysis. Neural Netw. 2015, 65, 92–104. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2016; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Tokui, S.; Okuta, R.; Akiba, T.; Niitani, Y.; Ogawa, T.; Saito, S.; Suzuki, S.; Uenishi, K.; Vogel, B.; Vincent, H.Y. Chainer: A Deep Learning Framework for Accelerating the Research Cycle. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 3–7 August 2019. [Google Scholar]
- Liu, P.; Fang, R. Wide Inference Network for Image Denoising via Learning Pixel-distribution Prior. arXiv 2017, arXiv:1707.05414. Available online: https://arxiv.org/abs/1707.05414 (accessed on 1 May 2020).
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gaussian Noise | Salt-and-Pepper Noise |
|---|---|
 (a) Adding Gaussian Noise with : Standard deviation for Gaussian distribution. |  (b) Adding Salt-and-Pepper Noise with : Density of salt-and-pepper noise. |
| Clipped Whites | Clipped Blacks |
 (c) Adding Clipped Whites with : The value to add to the pixels in the ground truth image. |  (d) Adding Clipped Blacks with : Value to classify whether the pixel is set to 0 or not. |
| Camera Shake | |
| : Number of overlaps above the ground truth image. : Scalar to slide the overlapping image along the x-axis. : Scalar to slide the overlapping image along the y-axis. |  (e) Adding Camera Shake with and |
| Denoising Gaussian Noise (PSNR(dB)/SSIM) | |||||
|---|---|---|---|---|---|
| Noise Level | |||||
| Noisy | 22.890/0.667 | 14.363/0.255 | 13.117/0.181 | ||
| Denoising Models | L1 norm () | DnCNN | 23.695/0.700 | 18.388/0.323 | 16.690/0.244 |
| WIN5RB | 19.850/0.685 | 18.112/0.339 | 17.226/0.263 | ||
| U-Net | 23.493/0.754 | 21.924/0.586 | 19.323/0.494 | ||
| U-Net with Gn | 28.549/0.912 | 24.333/0.749 | 22.714/0.662 | ||
| Residual U-Net | 29.085/0.901 | 24.504/0.722 | 22.732/0.619 | ||
| Dense U-Net | 27.999/0.885 | 24.058/0.711 | 21.777/0.607 | ||
| L1 norm () | U-Net | 6.148/0.015 | 6.148/0.015 | 6.148/0.015 | |
| U-Net with Gn | 29.128/0.913 | 24.147/0.746 | 22.537/0.656 | ||
| Residual U-Net | 28.684/0.898 | 24.252/0.724 | 22.685/0.626 | ||
| Dense U-Net | 29.777/0.911 | 24.404/0.737 | 22.257/0.643 | ||
| L1 norm + Adversarial Loss (, ) | U-Net | 20.734/0.814 | 23.663/0.731 | 21.390/0.640 | |
| U-Net with Gn | 30.013/0.911 | 24.885/0.761 | 22.923/0.672 | ||
| Residual U-Net | 30.668/0.920 | 24.821/0.760 | 22.949/0.675 | ||
| Dense U-Net | 29.403/0.913 | 24.811/0.757 | 23.047/0.673 | ||
| Denoising Salt-and-Pepper Noise (PSNR(dB)/SSIM) | |||||
|---|---|---|---|---|---|
| Noise Level | |||||
| Noisy | 23.101/0.726 | 20.121/0.551 | 7.288/0.032 | ||
| Denoising Models | L1 norm () | DnCNN | 27.468/0.883 | 27.737/0.852 | 15.957/0.419 |
| WIN5RB | 22.970/0.864 | 23.990/0.843 | 16.171/0.371 | ||
| U-Net | 24.261/0.796 | 26.253/0.821 | 26.844/0.811 | ||
| U-Net with Gn | 35.520/0.968 | 36.154/0.968 | 26.282/0.822 | ||
| Residual U-Net | 36.685/0.962 | 36.954/0.963 | 25.707/0.804 | ||
| Dense U-Net | 36.409/0.962 | 36.513/0.961 | 26.105/0.837 | ||
| L1 norm () | U-Net | 6.148/0.015 | 6.148/0.015 | 6.148/0.015 | |
| U-Net with Gn | 33.441/0.959 | 34.159/0.961 | 26.286/0.828 | ||
| Residual U-Net | 35.241/0.951 | 36.055/0.956 | 26.869/0.820 | ||
| Dense U-Net | 36.352/0.963 | 36.779/0.964 | 27.165/0.837 | ||
| L1 norm + Adversarial Loss (, ) | U-Net | 39.087/0.984 | 38.846/0.983 | 27.792/0.868 | |
| U-Net with Gn | 35.432/0.961 | 36.334/0.967 | 26.267/0.822 | ||
| Residual U-Net | 37.711/0.970 | 38.382/0.972 | 26.304/0.826 | ||
| Dense U-Net | 36.224/0.968 | 37.365/0.969 | 26.555/0.840 | ||
| Denoising Clipped Whites (PSNR(dB)/SSIM) | |||||
|---|---|---|---|---|---|
| Noise Level | |||||
| Noisy | 14.560/0.829 | 11.265/0.742 | 9.048/0.656 | ||
| Denoising Models | L1 norm () | DnCNN | 20.773/0.826 | 18.563/0.825 | 14.056/0.730 |
| WIN5RB | 17.363/0.774 | 16.901/0.785 | 13.824/0.719 | ||
| U-Net | 17.921/0.709 | 16.643/0.698 | 14.057/0.675 | ||
| U-Net with Gn | 27.892/0.952 | 26.726/0.937 | 24.870/0.916 | ||
| Residual U-Net | 29.359/0.959 | 27.839/0.945 | 23.593/0.903 | ||
| Dense U-Net | 27.716/0.953 | 27.370/0.942 | 24.695/0.908 | ||
| L1 norm () | U-Net | 6.148/0.015 | 6.148/0.015 | 6.148/0.015 | |
| U-Net with Gn | 29.128/0.959 | 27.655/0.943 | 24.648/0.911 | ||
| Residual U-Net | 29.378/0.961 | 28.090/0.947 | 24.788/0.909 | ||
| Dense U-Net | 30.857/0.966 | 27.895/0.950 | 23.380/0.908 | ||
| L1 norm + Adversarial Loss (, ) | U-Net | 26.068/0.946 | 25.623/0.934 | 24.422/0.906 | |
| U-Net with Gn | 27.841/0.953 | 27.226/0.940 | 23.760/0.904 | ||
| Residual U-Net | 29.365/0.959 | 28.044/0.946 | 24.513/0.914 | ||
| Dense U-Net | 28.660/0.959 | 27.745/0.946 | 25.337/0.916 | ||
| Denoising Clipped Blacks (PSNR(dB)/SSIM) | |||||
|---|---|---|---|---|---|
| Noise Level | |||||
| Noisy | 26.417/0.802 | 20.514/0.676 | 16.678/0.549 | ||
| Denoising Models | L1 norm () | DnCNN | 23.045/0.835 | 22.501/0.781 | 19.815/0.697 |
| WIN5RB | 18.521/0.810 | 16.727/0.735 | 14.618/0.638 | ||
| U-Net | 21.378/0.789 | 21.623/0.769 | 20.809/0.720 | ||
| U-Net with Gn | 31.453/0.927 | 28.103/0.880 | 24.713/0.815 | ||
| Residual U-Net | 31.460/0.926 | 28.415/0.880 | 24.426/0.810 | ||
| Dense U-Net | 31.654/0.928 | 28.194/0.881 | 24.751/0.815 | ||
| L1 norm () | U-Net | 6.148/0.015 | 6.148/0.015 | 6.148/0.015 | |
| U-Net with Gn | 29.941/0.925 | 27.479/0.879 | 24.575/0.813 | ||
| Residual U-Net | 30.849/0.923 | 27.879/0.875 | 24.644/0.810 | ||
| Dense U-Net | 31.443/0.923 | 28.250/0.882 | 24.235/0.811 | ||
| L1 norm + Adversarial Loss (, ) | U-Net | 29.259/0.926 | 27.280/0.886 | 23.668/0.814 | |
| U-Net with Gn | 31.892/0.930 | 28.131/0.881 | 23.892/0.807 | ||
| Residual U-Net | 32.836/0.934 | 28.634/0.886 | 24.481/0.816 | ||
| Dense U-Net | 31.848/0.929 | 28.398/0.883 | 24.846/0.818 | ||
| Denoising Camera Shake (PSNR(dB)/SSIM) | |||||
|---|---|---|---|---|---|
| Noise Level | |||||
| Noisy | 22.698/0.766 | 19.905/0.602 | 18.304/0.532 | ||
| Denoising Models | L1 norm () | DnCNN | 20.777/0.720 | 20.023/0.592 | 18.378/0.524 |
| WIN5RB | 21.115/0.757 | 20.644/0.628 | 19.123/0.548 | ||
| U-Net | 19.943/0.698 | 19.183/0.573 | 18.202/0.508 | ||
| U-Net with Gn | 26.753/0.835 | 24.184/0.721 | 21.899/0.621 | ||
| Residual U-Net | 27.311/0.838 | 24.770/0.736 | 22.265/0.633 | ||
| Dense U-Net | 27.030/0.831 | 24.448/0.722 | 22.012/0.625 | ||
| L1 norm () | U-Net | 6.148/0.015 | 6.148/0.015 | 6.148/0.015 | |
| U-Net with Gn | 26.545/0.830 | 24.239/0.723 | 21.887/0.620 | ||
| Residual U-Net | 26.917/0.831 | 24.496/0.725 | 21.980/0.623 | ||
| Dense U-Net | 27.560/0.846 | 25.014/0.749 | 22.480/0.648 | ||
| L1 norm + Adversarial Loss (, ) | U-Net | 24.959/0.813 | 23.057/0.693 | 20.803/0.596 | |
| U-Net with Gn | 27.013/0.835 | 24.405/0.725 | 21.978/0.623 | ||
| Residual U-Net | 26.553/0.829 | 24.068/0.721 | 21.504/0.619 | ||
| Dense U-Net | 27.120/0.835 | 24.632/0.732 | 22.183/0.632 | ||
| Denoising Gaussian Noise ((PSNR(dB)) | |||
|---|---|---|---|
| Noise Level | |||
| Noisy | 22.890 | 14.363 | 13.117 |
| DnCNN | 23.695 | 18.388 | 16.690 |
| WIN5RB | 19.850 | 18.112 | 17.226 |
| Best U-Net based model | 30.668 | 24.885 | 23.047 |
| Residual U-Net (L1 norm + Adversarial Loss) | U-Net with Gn (L1 norm + Adversarial Loss) | Dense U-Net (L1 norm + Adversarial Loss) | |
| Denoising Salt-and-Pepper Noise ((PSNR(dB)) | |||
| Noise Level | |||
| Noisy | 23.101 | 20.121 | 7.288 |
| DnCNN | 27.468 | 27.737 | 15.957 |
| WIN5RB | 22.970 | 23.990 | 16.171 |
| Best U-Net based model | 39.087 | 38.864 | 27.792 |
| U-Net (L1 norm + Adversarial Loss) | U-Net (L1 norm + Adversarial Loss) | U-Net (L1 norm + Adversarial Loss) | |
| Denoising Clipped Whites ((PSNR(dB)) | |||
| Noise Level | |||
| Noisy | 14.560 | 11.265 | 9.048 |
| DnCNN | 20.773 | 18.563 | 14.056 |
| WIN5RB | 17.363 | 16.901 | 13.824 |
| Best U-Net based model | 30.857 | 28.090 | 25.337 |
| Dense U-Net (L1 norm ()) | Residual U-Net (L1 norm ()) | Dense U-Net (L1 norm + Adversarial Loss) | |
| Denoising Clipped Blacks((PSNR(dB)) | |||
| Noise Level | |||
| Noisy | 26.417 | 20.514 | 16.678 |
| DnCNN | 23.045 | 22.501 | 19.815 |
| WIN5RB | 18.521 | 16.727 | 14.618 |
| Best U-Net based model | 32.836 | 28.634 | 24.846 |
| Residual U-Net (L1 norm + Adversarial Loss) | Residual U-Net (L1 norm + Adversarial Loss) | Dense U-Net (L1 norm + Adversarial Loss) | |
| Denoising Camera Shake ((PSNR(dB)/SSIM) | |||
| Noise Level | |||
| Noisy | 22.698 | 19.905 | 18.304 |
| DnCNN | 20.777 | 20.023 | 18.378 |
| WIN5RB | 21.115 | 20.644 | 19.123 |
| Best U-Net based model | 27.560 | 25.014 | 22.480 |
| Dense U-Net (L1 norm ()) | Dense U-Net (L1 norm ()) | Dense U-Net (L1 norm ()) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komatsu, R.; Gonsalves, T. Comparing U-Net Based Models for Denoising Color Images. AI 2020, 1, 465-486. https://doi.org/10.3390/ai1040029
Komatsu R, Gonsalves T. Comparing U-Net Based Models for Denoising Color Images. AI. 2020; 1(4):465-486. https://doi.org/10.3390/ai1040029
Chicago/Turabian StyleKomatsu, Rina, and Tad Gonsalves. 2020. "Comparing U-Net Based Models for Denoising Color Images" AI 1, no. 4: 465-486. https://doi.org/10.3390/ai1040029
APA StyleKomatsu, R., & Gonsalves, T. (2020). Comparing U-Net Based Models for Denoising Color Images. AI, 1(4), 465-486. https://doi.org/10.3390/ai1040029