

Explainable Image Classification: The Journey So Far and the Road Ahead


Abstract
:1. Introduction
2. Basic Definitions
- Black Box refers to the model whose working needs to be explained. This is also called the Explanandum in XAI literature. In this survey focussing on the image classification task, the Convolutional Neural Networks (CNNs), among the state-of-the-art image classifiers, are the black boxes whose explanation is sought.
- Explainer refers to the approximator or the algorithmic procedure that explains the working mechanism of the black box.
- Classifier refers to the model that maps the instance to one of the pre-defined categories called classes.
- In-domain classifier refers to a classifier that is trained and tested on data sampled from the same distribution, while Cross-domain classifiers would be trained and tested on data sampled from different distributions.
- Explanation refers to a simplified illustration of the working mechanism the black box model under consideration employs.
- Inherently Interpretable Models refer to the family of Machine Learning models whose working mechanism can be summarized in a user-friendly manner. For example, Decision trees whose working can be viewed as a disjunction of conjunctions of various constraints on the input variables, Linear Regressors whose linear combination weights provide an assessment of the priority the model gives to each input variable, are among the inherently interpretable models.
- Faithfulness refers to the extent to which the explainer mimics the working mechanism of the black box it explains.
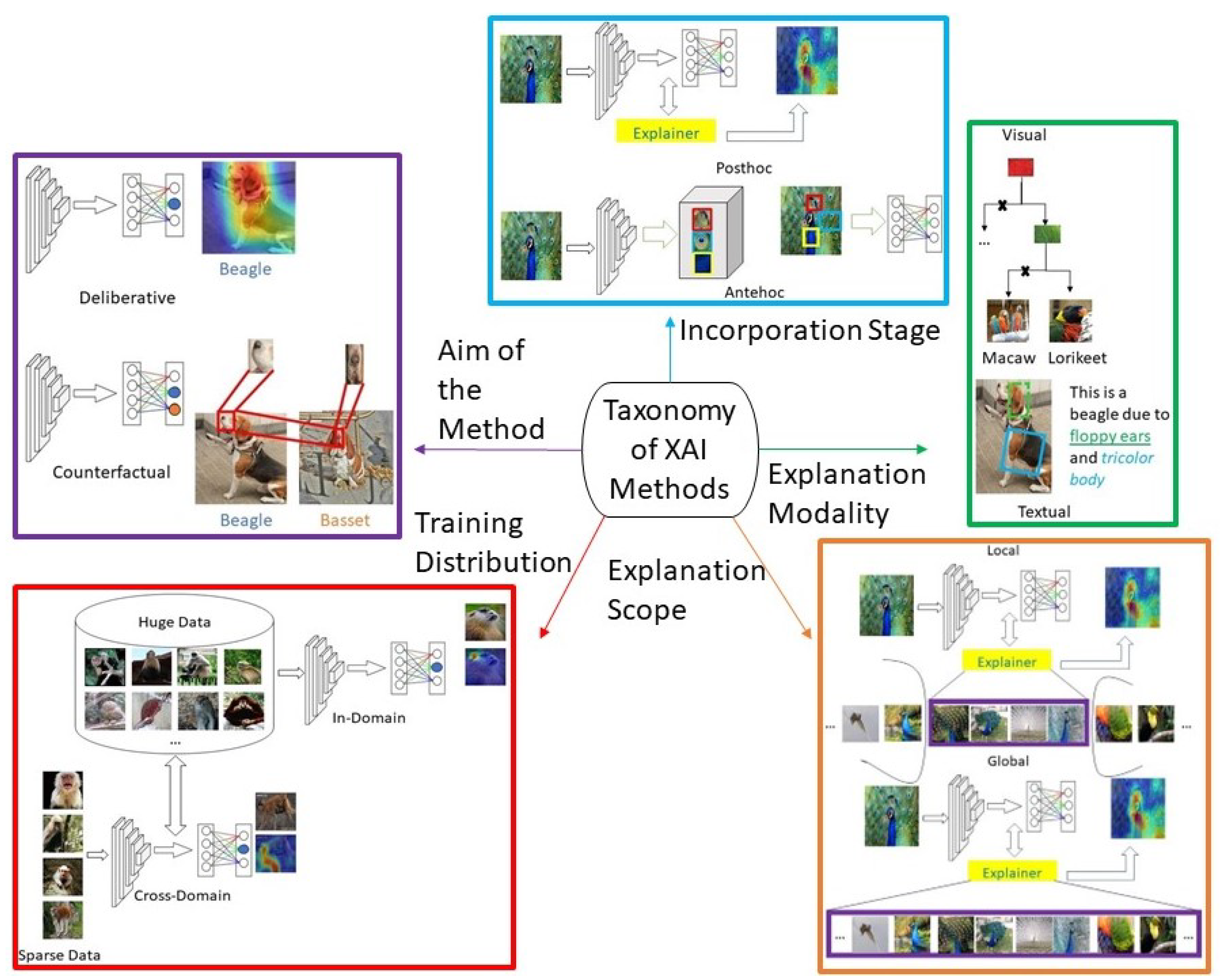
- Local Explanations refers to the category of explanations whose reliability is limited to a small neighborhood around the instance of interest to be explained. On the other hand, Global Explanations are reliable anywhere in the entire instance space.
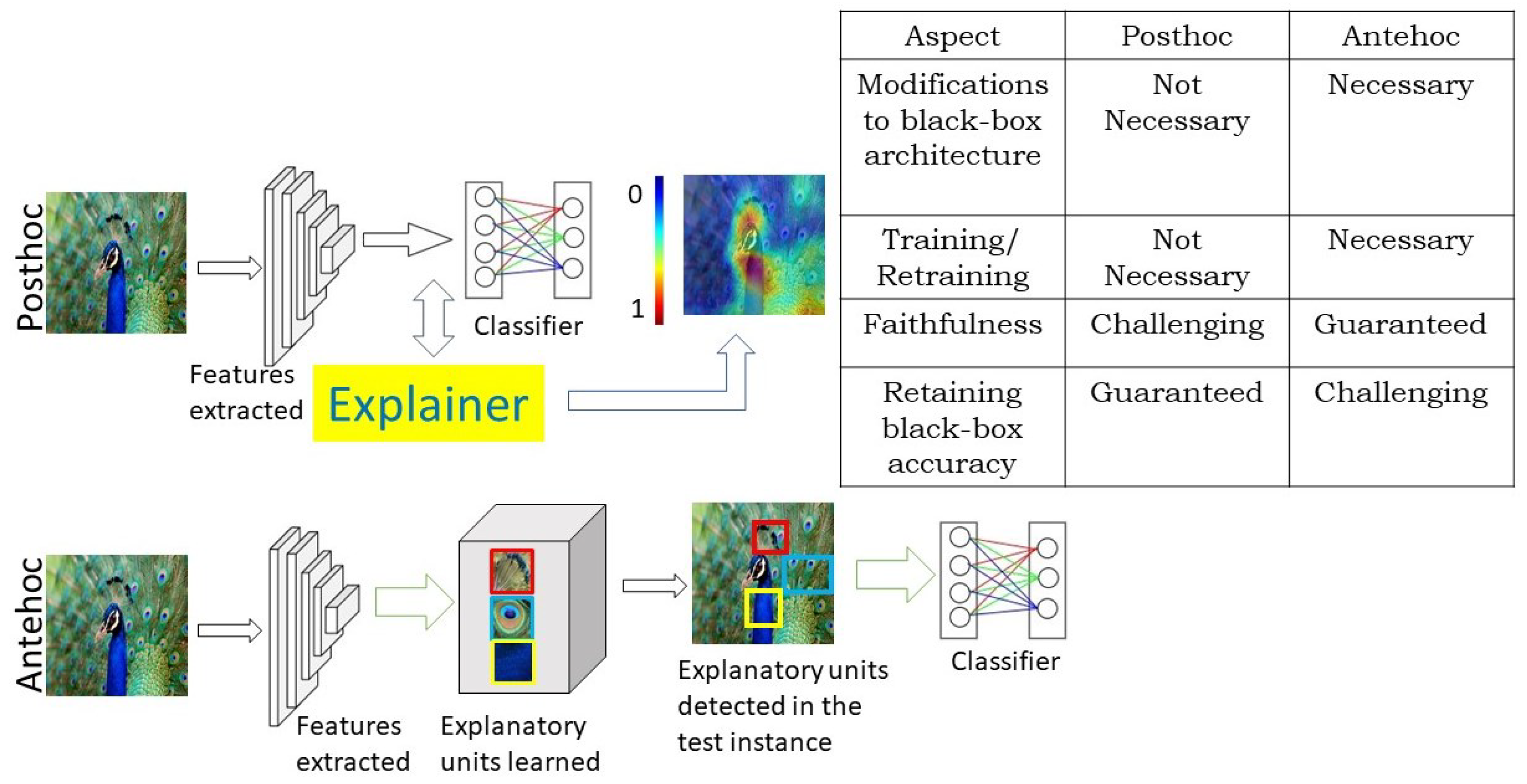
- Posthoc Explanations refer to the category of explanations that approximate the working mechanism of the black box without making any modifications to its architecture or parameters. On the contrary, the other family of explanations called the Antehoc Explanations enforce changes to the black box under consideration so that it gains the ability to explain itself analogous to that of the inherently interpretable models.
- Counterfactuals refers to the hypothetical instances that steer the prediction of the black box towards the desired class of interest
- Counterfactual explanations refer to the family of explanatory methods that aim to generate hypothetical counterfactuals that alter the prediction to a desired class.
- Deliberative explanations aim to extract input features that help justify a given prediction.
- Visual Explanations bring out the working mechanism of the black box through visual cues in a human-understandable format, while Textual explanations leverage natural language phrases to bring out the working mechanism of the classifier.
- Concepts refer to an abstract vector representation that can be mapped to interpretable input regions.
- Relevance refers to an estimate of the importance of a concept towards predicting a given class.
3. Survey Methodology
4. Trajectory Traversed by Object Recognition Models
5. Need for Explaining the CNNs
6. A Brief Overview of the Previous Attempts in Explainable AI
7. Taxonomy of XAI Methods
7.1. Posthoc Methods
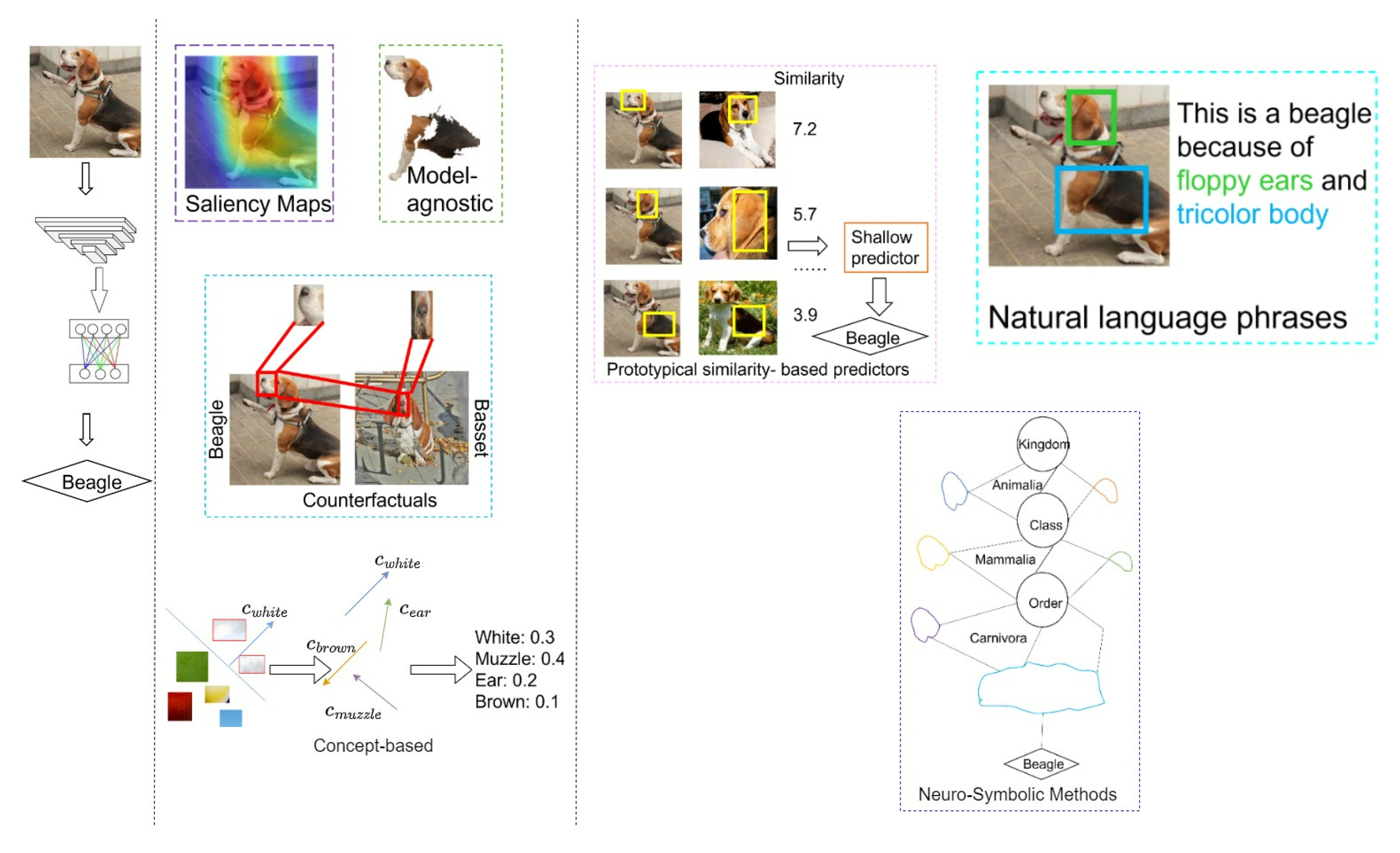
7.1.1. Class Activation Maps
7.1.2. Model-Agnostic Explanations
7.1.3. Counterfactual Explanations
7.1.4. Concept-Based Explanations
7.2. Antehoc Explanations
7.2.1. Visual Explanations
7.2.2. Natural Language Explanations
7.2.3. Neuro-Symbolic Methods
8. Causal Explanations
9. Explaining Cross-Domain Classification
10. Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl.-Based Syst. 2023, 263, 110273. [Google Scholar] [CrossRef]
- Chaddad, A.; Peng, J.; Xu, J.; Bouridane, A. Survey of Explainable AI Techniques in Healthcare. Sensors 2023, 23, 634. [Google Scholar] [CrossRef]
- Weber, P.; Carl, K.V.; Hinz, O. Applications of Explainable Artificial Intelligence in Finance—A systematic review of Finance, Information Systems, and Computer Science literature. Manag. Rev. Q. 2023. [Google Scholar] [CrossRef]
- Clement, T.; Kemmerzell, N.; Abdelaal, M.; Amberg, M. XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process. Mach. Learn. Knowl. Extr. 2023, 5, 78–108. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Malgieri, G.; Natali, C.; Schneeberger, D.; Stoeger, K.; Holzinger, A. Quod erat demonstrandum?—Towards a typology of the concept of explanation for the design of explainable AI. Expert Syst. Appl. 2023, 213, 118888. [Google Scholar] [CrossRef]
- Schwalbe, G.; Finzel, B. A comprehensive taxonomy for explainable artificial intelligence: A systematic survey of surveys on methods and concepts. Data Min. Knowl. Discov. 2023. [Google Scholar] [CrossRef]
- Yang, C.H.H.; Liu, Y.C.; Chen, P.Y.; Ma, X.; Tsai, Y.C.J. When causal intervention meets adversarial examples and image masking for deep neural networks. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 3811–3815. [Google Scholar]
- Panda, P.; Kancheti, S.S.; Balasubramanian, V.N. Instance-wise causal feature selection for model interpretation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1756–1759. [Google Scholar]
- Prabhushankar, M.; AlRegib, G. Extracting causal visual features for limited label classification. In Proceedings of the IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 3697–3701. [Google Scholar]
- Ganguly, N.; Fazlija, D.; Badar, M.; Fisichella, M.; Sikdar, S.; Schrader, J.; Wallat, J.; Rudra, K.; Koubarakis, M.; Patro, G.K.; et al. A review of the role of causality in developing trustworthy ai systems. arXiv 2023, arXiv:2302.06975. [Google Scholar]
- Bahadori, M.T.; Heckerman, D. Debiasing Concept-based Explanations with Causal Analysis. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Kancheti, S.S.; Reddy, A.G.; Balasubramanian, V.N.; Sharma, A. Matching learned causal effects of neural networks with domain priors. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; p. 10676. [Google Scholar]
- Dash, S.; Balasubramanian, V.N.; Sharma, A. Evaluating and mitigating bias in image classifiers: A causal perspective using counterfactuals. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 915–924. [Google Scholar]
- Singhal, P.; Walambe, R.; Ramanna, S.; Kotecha, K. Domain Adaptation: Challenges, Methods, Datasets, and Applications. IEEE Access 2023, 11, 6973–7020. [Google Scholar] [CrossRef]
- Iman, M.; Arabnia, H.R.; Rasheed, K. A review of deep transfer learning and recent advancements. Technologies 2023, 11, 40. [Google Scholar] [CrossRef]
- Szabó, R.; Katona, D.; Csillag, M.; Csiszárik, A.; Varga, D. Visualizing Transfer Learning. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning, Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Hou, Y.; Zheng, L. Visualizing Adapted Knowledge in Domain Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13824–13833. [Google Scholar]
- Kamakshi, V.; Krishnan, N.C. Explainable supervised domain adaptation. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Xiao, W.; Ding, Z.; Liu, H. Visualizing Transferred Knowledge: An Interpretive Model of Unsupervised Domain Adaptation. arXiv 2023, arXiv:2303.02302. [Google Scholar]
- Sarkar, N.K.; Singh, M.M.; Nandi, U. Recent Researches on Image Classification Using Deep Learning Approach. Int. J. Comput. Digit. Syst. 2022, 12, 1357–1374. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez-Garcia, A. Image Context for Object Detection, Object Context for Part Detection. Ph.D. Thesis, The University of Edinburgh, Edinburgh, UK, 2018. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object detectors emerge from training CNNs for scene recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–12. [Google Scholar]
- Lipton, Z.C. The doctor just won’t accept that! Interpretable ML symposium. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bonicalzi, S. A matter of justice. The opacity of algorithmic decision-making and the trade-off between uniformity and discretion in legal applications of artificial intelligence. Teor. Riv. Filos. 2022, 42, 131–147. [Google Scholar]
- Council of European Union. 2018 Reform of EU Data Protection Rules. 2018. Available online: https://ec.europa.eu/commission/sites/beta-political/files/data-protection-factsheet-changes_en.pdf (accessed on 1 June 2019).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You? Explaining the Predictions of Any Classifier. In Proceedings of the ACM International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 618–626. [Google Scholar]
- Neuhaus, Y.; Augustin, M.; Boreiko, V.; Hein, M. Spurious Features Everywhere—Large-Scale Detection of Harmful Spurious Features in ImageNet. arXiv 2022, arXiv:2212.04871. [Google Scholar]
- Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Martino, F.D.; Delmastro, F. Explainable AI for clinical and remote health applications: A survey on tabular and time series data. Artif. Intell. Rev. 2023, 56, 5261–5315. [Google Scholar] [CrossRef]
- Zhu, L.; Zhu, Z.; Zhang, C.; Xu, Y.; Kong, X. Multimodal sentiment analysis based on fusion methods: A survey. Inf. Fusion 2023, 95, 306–325. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Salahuddin, Z.; Woodruff, H.C.; Chatterjee, A.; Lambin, P. Transparency of deep neural networks for medical image analysis: A review of interpretability methods. Comput. Biol. Med. 2022, 140, 105111. [Google Scholar] [CrossRef]
- Holzinger, A.; Malle, B.; Saranti, A.; Pfeifer, B. Towards multi-modal causability with graph neural networks enabling information fusion for explainable AI. Inf. Fusion 2021, 71, 28–37. [Google Scholar] [CrossRef]
- Owens, E.; Sheehan, B.; Mullins, M.; Cunneen, M.; Ressel, J.; Castignani, G. Explainable Artificial Intelligence (XAI) in Insurance. Risks 2022, 10, 230. [Google Scholar] [CrossRef]
- Shanthini, M.; Sanmugam, B. A Performance Comparison of State-of-the-Art Imputation and Classification Strategies on Insurance Fraud Detection. In Micro-Electronics and Telecommunication Engineering: Proceedings of 6th ICMETE, Ghaziabad, India, 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 215–225. [Google Scholar]
- Barnett, A.J.; Schwartz, F.R.; Tao, C.; Chen, C.; Ren, Y.; Lo, J.Y.; Rudin, C. A case-based interpretable deep learning model for classification of mass lesions in digital mammography. Nat. Mach. Intell. 2021, 3, 1061–1070. [Google Scholar] [CrossRef]
- Wu, S.; Yuksekgonul, M.; Zhang, L.; Zou, J. Discover and Cure: Concept-aware Mitigation of Spurious Correlation. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Degas, A.; Islam, M.R.; Hurter, C.; Barua, S.; Rahman, H.; Poudel, M.; Ruscio, D.; Ahmed, M.U.; Begum, S.; Rahman, M.A.; et al. A Survey on Artificial Intelligence (AI) and Explainable AI in Air Traffic Management: Current Trends and Development with Future Research Trajectory. Appl. Sci. 2022, 12, 1295. [Google Scholar] [CrossRef]
- Buhrmester, V.; Münch, D.; Arens, M. Analysis of explainers of black box deep neural networks for computer vision: A survey. Mach. Learn. Knowl. Extr. 2021, 3, 966–989. [Google Scholar] [CrossRef]
- Kang, J.S.; Kang, J.; Kim, J.J.; Jeon, K.W.; Chung, H.J.; Park, B.H. Neural Architecture Search Survey: A Computer Vision Perspective. Sensors 2023, 23, 1713. [Google Scholar] [CrossRef]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Desai, S.; Ramaswamy, H.G. Ablation-CAM: Visual Explanations for Deep Convolutional Network via Gradient-free Localization. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 983–991. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Chen, C.; Li, O.; Tao, D.; Barnett, A.; Rudin, C.; Su, J.K. This looks like that: Deep learning for interpretable image recognition. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8928–8939. [Google Scholar]
- Nauta, M.; van Bree, R.; Seifert, C. Neural prototype trees for interpretable fine-grained image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14933–14943. [Google Scholar]
- Singla, S.; Wallace, S.; Triantafillou, S.; Batmanghelich, K. Using causal analysis for conceptual deep learning explanation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2021; pp. 519–528. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Friedman, J.H.; Popescu, B.E. Predictive learning via rule ensembles. Ann. Appl. Stat. 2008, 2, 916–954. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.G.; Lee, S.I. Consistent individualized feature attribution for tree ensembles. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning, Sydney, Australia, 11–15 August 2017. [Google Scholar]
- Harris, C.; Pymar, R.; Rowat, C. Joint Shapley values: A measure of joint feature importance. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Zafar, M.R.; Khan, N. Deterministic local interpretable model-agnostic explanations for stable explainability. Mach. Learn. Knowl. Extr. 2021, 3, 525–541. [Google Scholar] [CrossRef]
- Sharma, R.; Reddy, N.; Kamakshi, V.; Krishnan, N.C.; Jain, S. MAIRE-A Model-Agnostic Interpretable Rule Extraction Procedure for Explaining Classifiers. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2021; pp. 329–349. [Google Scholar]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Faithful and customizable explanations of black box models. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 131–138. [Google Scholar]
- Ben Zaken, D.; Segal, A.; Cavalier, D.; Shani, G.; Gal, K. Generating Recommendations with Post-Hoc Explanations for Citizen Science. In Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization, Barcelona, Spain, 4–7 July 2022; pp. 69–78. [Google Scholar]
- Kumar, A.; Sehgal, K.; Garg, P.; Kamakshi, V.; Krishnan, N.C. MACE: Model Agnostic Concept Extractor for Explaining Image Classification Networks. IEEE Trans. Artif. Intell. 2021, 2, 574–583. [Google Scholar] [CrossRef]
- Kamakshi, V.; Gupta, U.; Krishnan, N.C. PACE: Posthoc Architecture-Agnostic Concept Extractor for Explaining CNNs. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Collaris, D.; Gajane, P.; Jorritsma, J.; van Wijk, J.J.; Pechenizkiy, M. LEMON: Alternative Sampling for More Faithful Explanation through Local Surrogate Models. In Proceedings of the Advances in Intelligent Data Analysis XXI, Louvain-la-Neuve, Belgium, 12–14 April 2023; pp. 77–90. [Google Scholar]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 24–25. [Google Scholar]
- Salama, A.; Adly, N.; Torki, M. Ablation-CAM++: Grouped Recursive Visual Explanations for Deep Convolutional Networks. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 16–19 October 2022; pp. 2011–2015. [Google Scholar]
- Lee, J.R.; Kim, S.; Park, I.; Eo, T.; Hwang, D. Relevance-cam: Your model already knows where to look. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14944–14953. [Google Scholar]
- Jung, H.; Oh, Y. Towards better explanations of class activation mapping. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1336–1344. [Google Scholar]
- Sattarzadeh, S.; Sudhakar, M.; Plataniotis, K.N.; Jang, J.; Jeong, Y.; Kim, H. Integrated grad-CAM: Sensitivity-aware visual explanation of deep convolutional networks via integrated gradient-based scoring. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 1775–1779. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2668–2677. [Google Scholar]
- Pfau, J.; Young, A.T.; Wei, J.; Wei, M.L.; Keiser, M.J. Robust semantic interpretability: Revisiting concept activation vectors. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning, Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Ghorbani, A.; Wexler, J.; Zou, J.Y.; Kim, B. Towards automatic concept-based explanations. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 10–12 December 2019; pp. 9277–9286. [Google Scholar]
- Yuksekgonul, M.; Wang, M.; Zou, J. Post-hoc Concept Bottleneck Models. In Proceedings of the ICLR Workshop on PAIR2Struct: Privacy, Accountability, Interpretability, Robustness, Reasoning on Structured Data, Virtual, 25–29 April 2022. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 11–15 August 2017; pp. 3319–3328. [Google Scholar]
- Zhang, J.; Bargal, S.A.; Lin, Z.; Brandt, J.; Shen, X.; Sclaroff, S. Top-down neural attention by excitation backprop. Int. J. Comput. Vis. 2018, 126, 1084–1102. [Google Scholar] [CrossRef] [Green Version]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. In Proceedings of the Workshop at International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. In Proceedings of the Workshop at International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Fong, R.; Patrick, M.; Vedaldi, A. Understanding deep networks via extremal perturbations and smooth masks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2950–2958. [Google Scholar]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 11–15 August 2017; pp. 3145–3153. [Google Scholar]
- Wang, P.; Kong, X.; Guo, W.; Zhang, X. Exclusive Feature Constrained Class Activation Mapping for Better Visual Explanation. IEEE Access 2021, 9, 61417–61428. [Google Scholar] [CrossRef]
- Hartley, T.; Sidorov, K.; Willis, C.; Marshall, D. SWAG: Superpixels weighted by average gradients for explanations of CNNs. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 423–432. [Google Scholar]
- Goyal, Y.; Wu, Z.; Ernst, J.; Batra, D.; Parikh, D.; Lee, S. Counterfactual visual explanations. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 11–13 June 2019; pp. 2376–2384. [Google Scholar]
- Abid, A.; Yuksekgonul, M.; Zou, J. Meaningfully debugging model mistakes using conceptual counterfactual explanations. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 66–88. [Google Scholar]
- Singla, S.; Pollack, B. Explanation by Progressive Exaggeration. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, P.; Vasconcelos, N. Scout: Self-aware discriminant counterfactual explanations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8981–8990. [Google Scholar]
- Zhao, Y. Fast real-time counterfactual explanations. In Proceedings of the Workshop at International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020. [Google Scholar]
- Arendsen, P.; Marcos, D.; Tuia, D. Concept discovery for the interpretation of landscape scenicness. Mach. Learn. Knowl. Extr. 2020, 2, 22. [Google Scholar] [CrossRef]
- Yeh, C.K.; Kim, B.; Arik, S.; Li, C.L.; Pfister, T.; Ravikumar, P. On Completeness-aware Concept-Based Explanations in Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 20554–20565. [Google Scholar]
- Goyal, Y.; Feder, A.; Shalit, U.; Kim, B. Explaining classifiers with Causal Concept Effect (CaCE). arXiv 2019, arXiv:1907.07165. [Google Scholar]
- Lopez-Paz, D.; Nishihara, R.; Chintala, S.; Scholkopf, B.; Bottou, L. Discovering causal signals in images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, 21–26 July 2017; pp. 6979–6987. [Google Scholar]
- Wang, J.; Liu, H.; Wang, X.; Jing, L. Interpretable image recognition by constructing transparent embedding space. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 895–904. [Google Scholar]
- Li, O.; Liu, H.; Chen, C.; Rudin, C. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Hendricks, L.A.; Rohrbach, A.; Schiele, B.; Darrell, T.; Akata, Z. Generating visual explanations with natural language. Appl. AI Lett. 2021, 2, e55. [Google Scholar] [CrossRef]
- Koh, P.W.; Nguyen, T.; Tang, Y.S.; Mussmann, S.; Pierson, E.; Kim, B.; Liang, P. Concept bottleneck models. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 12–18 July 2020; pp. 5338–5348. [Google Scholar]
- Rymarczyk, D.; Struski, Ł.; Górszczak, M.; Lewandowska, K.; Tabor, J.; Zieliński, B. Interpretable image classification with differentiable prototypes assignment. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 351–368. [Google Scholar]
- Rymarczyk, D.; Struski, Ł.; Tabor, J.; Zieliński, B. ProtoPShare: Prototypical Parts Sharing for Similarity Discovery in Interpretable Image Classification. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1420–1430. [Google Scholar]
- Jain, S.; Wallace, B.C. Attention is not Explanation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 3543–3556. [Google Scholar]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual attention methods in deep learning: An in-depth survey. arXiv 2022, arXiv:2204.07756. [Google Scholar]
- Mohankumar, A.K.; Nema, P.; Narasimhan, S.; Khapra, M.M.; Srinivasan, B.V.; Ravindran, B. Towards Transparent and Explainable Attention Models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 4206–4216. [Google Scholar]
- Xu, W.; Wang, J.; Wang, Y.; Xu, G.; Lin, D.; Dai, W.; Wu, Y. Where is the Model Looking at—Concentrate and Explain the Network Attention. IEEE J. Sel. Top. Signal Process. 2020, 14, 506–516. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Zhang, Q.; Nian Wu, Y.; Zhu, S.C. Interpretable convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8827–8836. [Google Scholar]
- Hase, P.; Chen, C.; Li, O.; Rudin, C. Interpretable Image Recognition with Hierarchical Prototypes. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Honolulu, HI, USA, 27 January–1 February 2019; Volume 7, pp. 32–40. [Google Scholar]
- Kim, Y.; Mo, S.; Kim, M.; Lee, K.; Lee, J.; Shin, J. Explaining Visual Biases as Words by Generating Captions. arXiv 2023, arXiv:2301.11104. [Google Scholar]
- Yang, Y.; Kim, S.; Joo, J. Explaining deep convolutional neural networks via latent visual-semantic filter attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–23 June 2022; pp. 8333–8343. [Google Scholar]
- Hendricks, L.A.; Hu, R.; Darrell, T.; Akata, Z. Grounding visual explanations. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 264–279. [Google Scholar]
- Wickramanayake, S.; Hsu, W.; Lee, M.L. Comprehensible convolutional neural networks via guided concept learning. In Proceedings of the International Joint Conference on Neural Networks, Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Hendricks, L.A.; Akata, Z.; Rohrbach, M.; Donahue, J.; Schiele, B.; Darrell, T. Generating visual explanations. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–19. [Google Scholar]
- Khan, M.A.; Oikarinen, T.; Weng, T.W. Concept-Monitor: Understanding DNN training through individual neurons. arXiv 2023, arXiv:2304.13346. [Google Scholar]
- Frye, C.; Rowat, C.; Feige, I. Asymmetric shapley values: Incorporating causal knowledge into model-agnostic explainability. Adv. Neural Inf. Process. Syst. 2020, 33, 1229–1239. [Google Scholar]
- Watson, M.; Hasan, B.A.S.; Al Moubayed, N. Learning How to MIMIC: Using Model Explanations To Guide Deep Learning Training. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 1461–1470. [Google Scholar]
- Qin, W.; Zhang, H.; Hong, R.; Lim, E.P.; Sun, Q. Causal interventional training for image recognition. IEEE Trans. Multimed. 2021, 25, 1033–1044. [Google Scholar] [CrossRef]
- Zunino, A.; Bargal, S.A.; Volpi, R.; Sameki, M.; Zhang, J.; Sclaroff, S.; Murino, V.; Saenko, K. Explainable deep classification models for domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3233–3242. [Google Scholar]
- Zhang, Y.; Yao, T.; Qiu, Z.; Mei, T. Explaining Cross-Domain Recognition with Interpretable Deep Classifier. arXiv 2022, arXiv:2211.08249. [Google Scholar]
- Maillot, N.E.; Thonnat, M. Ontology based complex object recognition. Image Vis. Comput. 2008, 26, 102–113. [Google Scholar] [CrossRef] [Green Version]
- Ordonez, V.; Liu, W.; Deng, J.; Choi, Y.; Berg, A.C.; Berg, T.L. Predicting entry-level categories. Int. J. Comput. Vis. 2015, 115, 29–43. [Google Scholar] [CrossRef]
- Liao, Q.; Poggio, T. Object-Oriented Deep Learning; Technical Report; Center for Brains, Minds and Machines (CBMM): Cambridge, MA, USA, 2017. [Google Scholar]
- Icarte, R.T.; Baier, J.A.; Ruz, C.; Soto, A. How a general-purpose commonsense ontology can improve performance of learning-based image retrieval. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 1283–1289. [Google Scholar]
- Marino, K.; Salakhutdinov, R.; Gupta, A. The More You Know: Using Knowledge Graphs for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2673–2681. [Google Scholar]
- Alirezaie, M.; Längkvist, M.; Sioutis, M.; Loutfi, A. A Symbolic Approach for Explaining Errors in Image Classification Tasks. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Daniels, Z.A.; Frank, L.D.; Menart, C.J.; Raymer, M.; Hitzler, P. A framework for explainable deep neural models using external knowledge graphs. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications II; SPIE: Bellingham, WA, USA, 2020; Volume 11413, pp. 480–499. [Google Scholar]
- Tiddi, I.; Schlobach, S. Knowledge graphs as tools for explainable machine learning: A survey. Artif. Intell. 2022, 302, 103627. [Google Scholar] [CrossRef]
- Veugen, T.; Kamphorst, B.; Marcus, M. Privacy-preserving contrastive explanations with local foil trees. Cryptography 2022, 6, 54. [Google Scholar] [CrossRef]
- Nguyen, A.; Dosovitskiy, A.; Yosinski, J.; Brox, T.; Clune, J. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3387–3395. [Google Scholar]
- Wang, P.; Nvasconcelos, N. Deliberative explanations: Visualizing network insecurities. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 10–12 December 2019; Volume 32. [Google Scholar]
- Mosqueira-Rey, E.; Hernández-Pereira, E.; Alonso-Ríos, D.; Bobes-Bascarán, J.; Fernández-Leal, Á. Human-in-the-loop machine learning: A state of the art. Artif. Intell. Rev. 2023, 56, 3005–3054. [Google Scholar] [CrossRef]
- Hendricks, L.A.; Hu, R.; Darrell, T.; Akata, Z. Generating Counterfactual Explanations with Natural Language. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 95–98. [Google Scholar]
- Feldhus, N.; Hennig, L.; Nasert, M.D.; Ebert, C.; Schwarzenberg, R.; Möller, S. Saliency Map Verbalization: Comparing Feature Importance Representations from Model-free and Instruction-based Methods. In Proceedings of the First Workshop on Natural Language Reasoning and Structured Explanations (NLRSE), Toronto, ON, Canada, 13 July 2023. [Google Scholar]
- Neyshabur, B.; Sedghi, H.; Zhang, C. What is being transferred in transfer learning? Adv. Neural Inf. Process. Syst. 2020, 33, 512–523. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 2018, 51, 93. [Google Scholar] [CrossRef] [Green Version]
- Verma, S.; Arthur, A.; Dickerson, J.; Hines, K. Counterfactual Explanations for Machine Learning: A Review. In Proceedings of the NeurIPS Workshop: ML Retrospectives, Surveys & Meta-Analyses, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Ramaswamy, V.V.; Kim, S.S.; Fong, R.; Russakovsky, O. Overlooked factors in concept-based explanations: Dataset choice, concept salience, and human capability. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 20–22 June 2023. [Google Scholar]
- Wang, Y.; Su, H.; Zhang, B.; Hu, X. Learning Reliable Visual Saliency for Model Explanations. IEEE Trans. Multimed. 2019, 22, 1796–1807. [Google Scholar] [CrossRef]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity checks for saliency maps. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; pp. 9505–9515. [Google Scholar]
- Sixt, L.; Granz, M.; Landgraf, T. When Explanations Lie: Why Modified BP Attribution Fails. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Dabkowski, P.; Gal, Y. Real time image saliency for black box classifiers. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6967–6976. [Google Scholar]
- Huang, X.; Marques-Silva, J. The Inadequacy of Shapley Values for Explainability. arXiv 2023, arXiv:2302.08160. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Vedaldi, A.; Soatto, S. Quick shift and kernel methods for mode seeking. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 705–718. [Google Scholar]
- Rasouli, P.; Chieh Yu, I. CARE: Coherent actionable recourse based on sound counterfactual explanations. Int. J. Data Sci. Anal. 2022. [Google Scholar] [CrossRef]
- Pawelczyk, M.; Agarwal, C.; Joshi, S.; Upadhyay, S.; Lakkaraju, H. Exploring counterfactual explanations through the lens of adversarial examples: A theoretical and empirical analysis. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 28–30 March 2022; pp. 4574–4594. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–11 December 2014; Volume 27. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Lang, O.; Gandelsman, Y.; Yarom, M.; Wald, Y.; Elidan, G.; Hassidim, A.; Freeman, W.T.; Isola, P.; Globerson, A.; Irani, M.; et al. Explaining in style: Training a gan to explain a classifier in stylespace. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 693–702. [Google Scholar]
- Lake, B.M.; Ullman, T.D.; Tenenbaum, J.B.; Gershman, S.J. Building machines that learn and think like people. Behav. Brain Sci. 2017, 40, e253. [Google Scholar] [CrossRef] [Green Version]
- Armstrong, S.L.; Gleitman, L.R.; Gleitman, H. What some concepts might not be. Cognition 1983, 13, 263–308. [Google Scholar] [CrossRef] [PubMed]
- Biederman, I. Recognition-by-components: A theory of human image understanding. Psychol. Rev. 1987, 94, 115. [Google Scholar] [CrossRef] [Green Version]
- Gurrapu, S.; Kulkarni, A.; Huang, L.; Lourentzou, I.; Freeman, L.; Batarseh, F.A. Rationalization for Explainable NLP: A Survey. arXiv 2023, arXiv:2301.08912. [Google Scholar]
- Wu, J.; Mooney, R. Faithful Multimodal Explanation for Visual Question Answering. In Proceedings of the ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 28 July–2 August 2019; pp. 103–112. [Google Scholar]
- Park, D.H.; Hendricks, L.A.; Akata, Z.; Rohrbach, A.; Schiele, B.; Darrell, T.; Rohrbach, M. Multimodal explanations: Justifying decisions and pointing to the evidence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8779–8788. [Google Scholar]
- Akula, A.R.; Zhu, S.C. Attention cannot be an Explanation. arXiv 2022, arXiv:2201.11194. [Google Scholar]
- Hoffman, R.R.; Mueller, S.T.; Klein, G.; Litman, J. Metrics for explainable AI: Challenges and prospects. arXiv 2018, arXiv:1812.04608. [Google Scholar]
- Richter, M.M.; Weber, R.O. Case-Based Reasoning; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Hoffmann, A.; Fanconi, C.; Rade, R.; Kohler, J. This looks like that... does it? shortcomings of latent space prototype interpretability in deep networks. arXiv 2021, arXiv:2105.02968. [Google Scholar]
- Huang, Q.; Xue, M.; Zhang, H.; Song, J.; Song, M. Is ProtoPNet Really Explainable? Evaluating and Improving the Interpretability of Prototypes. arXiv 2022, arXiv:2212.05946. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Reimers, C.; Runge, J.; Denzler, J. Determining the Relevance of Features for Deep Neural Networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 330–346. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-adversarial domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Nauta, M.; Jutte, A.; Provoost, J.; Seifert, C. This looks like that, because... explaining prototypes for interpretable image recognition. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2021; pp. 441–456. [Google Scholar]
- Zhou, X.; Xu, X.; Venkatesan, R.; Swaminathan, G.; Majumder, O. d-SNE: Domain Adaptation Using Stochastic Neighborhood Embedding. In Domain Adaptation in Computer Vision with Deep Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 43–56. [Google Scholar]
- Köhler, M.; Eisenbach, M.; Gross, H.M. Few-Shot Object Detection: A Comprehensive Survey. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef]
- Cai, H.; Zhu, X.; Wen, P.; Han, W.; Wu, L. A Survey of Few-Shot Learning for Image Classification of Aerial Objects. In Proceedings of the China Aeronautical Science and Technology Youth Science Forum; Springer: Berlin/Heidelberg, Germany, 2023; pp. 570–582. [Google Scholar]
- Wang, B.; Li, L.; Verma, M.; Nakashima, Y.; Kawasaki, R.; Nagahara, H. Match them up: Visually explainable few-shot image classification. Appl. Intell. 2023, 53, 10956–10977. [Google Scholar] [CrossRef]
- Menezes, A.G.; de Moura, G.; Alves, C.; de Carvalho, A.C. Continual Object Detection: A review of definitions, strategies, and challenges. Neural Netw. 2023, 161, 476–493. [Google Scholar] [CrossRef]
- Wang, S.; Zhu, L.; Shi, L.; Mo, H.; Tan, S. A Survey of Full-Cycle Cross-Modal Retrieval: From a Representation Learning Perspective. Appl. Sci. 2023, 13, 4571. [Google Scholar] [CrossRef]
- Masana, M.; Liu, X.; Twardowski, B.; Menta, M.; Bagdanov, A.D.; van de Weijer, J. Class-incremental learning: Survey and performance evaluation on image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5513–5533. [Google Scholar] [CrossRef]
- Rymarczyk, D.; van de Weijer, J.; Zieliński, B.; Twardowski, B. ICICLE: Interpretable Class Incremental Continual Learning. arXiv 2023, arXiv:2303.07811. [Google Scholar]
- Leemann, T.; Rong, Y.; Kraft, S.; Kasneci, E.; Kasneci, G. Coherence Evaluation of Visual Concepts With Objects and Language. In Proceedings of the ICLR2022 Workshop on the Elements of Reasoning: Objects, Structure and Causality, Virtual, 29 April 2022. [Google Scholar]
- Zarlenga, M.E.; Barbiero, P.; Shams, Z.; Kazhdan, D.; Bhatt, U.; Weller, A.; Jamnik, M. Towards Robust Metrics For Concept Representation Evaluation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics 2021, 10, 593. [Google Scholar] [CrossRef]
- Arya, V.; Bellamy, R.K.; Chen, P.Y.; Dhurandhar, A.; Hind, M.; Hoffman, S.C.; Houde, S.; Liao, Q.V.; Luss, R.; Mojsilovic, A.; et al. One Explanation Does Not Fit All: A Toolkit And Taxonomy Of AI Explainability Techniques. In Proceedings of the INFORMS Annual Meeting, Houston, TX, USA, 3–5 April 2021. [Google Scholar]
- Elkhawaga, G.; Elzeki, O.; Abuelkheir, M.; Reichert, M. Evaluating Explainable Artificial Intelligence Methods Based on Feature Elimination: A Functionality-Grounded Approach. Electronics 2023, 12, 1670. [Google Scholar] [CrossRef]
- Agarwal, C.; Krishna, S.; Saxena, E.; Pawelczyk, M.; Johnson, N.; Puri, I.; Zitnik, M.; Lakkaraju, H. Openxai: Towards a transparent evaluation of model explanations. Adv. Neural Inf. Process. Syst. 2022, 35, 15784–15799. [Google Scholar]
- Lopes, P.; Silva, E.; Braga, C.; Oliveira, T.; Rosado, L. XAI Systems Evaluation: A Review of Human and Computer-Centred Methods. Appl. Sci. 2022, 12, 9423. [Google Scholar] [CrossRef]
- Herm, L.V.; Heinrich, K.; Wanner, J.; Janiesch, C. Stop ordering machine learning algorithms by their explainability! A user-centered investigation of performance and explainability. Int. J. Inf. Manag. 2023, 69, 102538. [Google Scholar] [CrossRef]
- Liu, C.H.; Han, Y.S.; Sung, Y.Y.; Lee, Y.; Chiang, H.Y.; Wu, K.C. FOX-NAS: Fast, On-device and Explainable Neural Architecture Search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 789–797. [Google Scholar]
- Hosseini, R.; Xie, P. Saliency-Aware Neural Architecture Search. Adv. Neural Inf. Process. Syst. 2022, 35, 14743–14757. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Elango, M.; Bau, D.; Torralba, A.; Madry, A. Editing a classifier by rewriting its prediction rules. Adv. Neural Inf. Process. Syst. 2021, 34, 23359–23373. [Google Scholar]
- Wang, J.; Hu, R.; Jiang, C.; Hu, R.; Sang, J. Counterexample Contrastive Learning for Spurious Correlation Elimination. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 4930–4938. [Google Scholar]
- Tanno, R.; F Pradier, M.; Nori, A.; Li, Y. Repairing Neural Networks by Leaving the Right Past Behind. Adv. Neural Inf. Process. Syst. 2022, 35, 13132–13145. [Google Scholar]
- Johs, A.J.; Agosto, D.E.; Weber, R.O. Explainable artificial intelligence and social science: Further insights for qualitative investigation. Appl. AI Lett. 2022, 3, e64. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Igami, M. Artificial Intelligence as Structural Estimation: Economic Interpretations of Deep Blue, Bonanza, and AlphaGo. arXiv 2018, arXiv:1710.10967. [Google Scholar]
- Akyol, E.; Langbort, C.; Basar, T. Price of transparency in strategic machine learning. arXiv 2016, arXiv:1610.08210. [Google Scholar]
- Beaudouin, V.; Bloch, I.; Bounie, D.; Clémençon, S.; d’Alché Buc, F.; Eagan, J.; Maxwell, W.; Mozharovskyi, P.; Parekh, J. Flexible and context-specific AI explainability: A multidisciplinary approach. arXiv 2020, arXiv:2003.07703. [Google Scholar] [CrossRef] [Green Version]
- Langer, M.; Oster, D.; Speith, T.; Hermanns, H.; Kästner, L.; Schmidt, E.; Sesing, A.; Baum, K. What do we want from Explainable Artificial Intelligence (XAI)?—A stakeholder perspective on XAI and a conceptual model guiding interdisciplinary XAI research. Artif. Intell. 2021, 296, 103473. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categorization Basis | Categories | Suitability | References |
|---|---|---|---|
| Incorporation Stage | Posthoc | Suitable to explain an already deployed model | [11,12,13,14,23,32,33,48,49,50,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93] |
| Antehoc | Suitable when an application specifies the need to build models that have interpretability built into its design | [15,16,17,22,38,51,52,53,54,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125] | |
| Explanation Scope | Local | Useful in privacy-preserving applications as only information around the vicinity of the instance is explored | [32,33,48,49,50,51,59,60,61,65,66,67,68,69,70,73,75,76,77,78,79,80,81,83,84,96,107,108,109,110,111,126] |
| Global | Useful to explain the complete working logic of the AI system to business stakeholders who decide to adopt the AI system into the business pipeline | [20,52,53,54,55,56,57,58,71,72,74,81,82,85,87,89,91,94,97,98,99,106,112,118,119,120,121,122,123,124,125,127] | |
| Aim of the Method | Deliberative | Justify the given prediction | [32,50,53,59,60,61,65,71,72,73,76,77,78,90,91,96,109,111,128] |
| Counterfactual | Useful to create close looking hypothetical Machine Teaching examples so that learners understand looking at minute discriminant features | [17,85,86,87,88,89,129,130] | |
| Explanation Modality | Visual | Quickly summarize the CNNs’ working using visual cues | [33,48,49,51,52,53,63,64,66,67,68,69,70,77,78,79,80,84,94,95,99,100,101,102,103,104,105,106] |
| Textual | Useful to explain users with special needs through leveraging text modality | [96,107,108,109,110,111,112,131] | |
| Training Distribution | In-domain | Explain CNNs trained on a single large dataset | [32,50,51,59,60,61,65,71,72,73,76,77,78,91,96,107,108,109,110,111,112] |
| Cross-Domain | Explain CNNs generalizable to multiple datasets | [21,22,23,116,117,132] |
| Sub-Category | Strengths | Weaknesses | Training Complexity | References |
|---|---|---|---|---|
| CAMs | These mechanisms can be used as a Plug & Play module to an already deployed model due to simpler definition of an explanation being a linear combination of intermediate activation maps | The heatmaps exhibited are almost always coarse (Figure 3), rendering them unable to provide finer explanations | Low | [33,48,49,66,67,68,69,70,83,84] |
| Model-agnostic | These explanations are interpretable when applied to images since the images are segmented using a human-friendly mechanism | It is not necessary that the CNN also employs a similar segmentation mechanism to process images | Moderate | [32,50,55,56,57,58,59,60,61,65,133] |
| Counterfactual | These explanations are pedagogical in nature since hypothetical counterfactual instances which are closer to the data in hand govern the explanation so that the human learners look at finer discriminative features to better distinguish related classes | Realistic image generation is challenging | High | [85,86,87,88,89,134] |
| Concept-based | The concepts extracted are based on examples provided by humans and hence interpretable | To obtain faithful explanations, the examples provided have to be sampled from the same distribution on which the CNN is modelled | Moderate | [63,64,71,72,73,74,90,91,97,135] |
| Sub-Category | Strengths | Weaknesses | Training Complexity | References |
|---|---|---|---|---|
| Visual | The complete model pipeline from training till testing only relies on processing cues of a single modality | Possibility of misinterpretations due to subjectivity associated with the human analysis of visual cues | Moderate | [51,52,53,94,95,98,99,100,101,102,103,105,106] |
| Textual | Since visual cues are accompanied by natural language phrases, ambiguity is managed | Training language models, which are also black boxes and are introduced to make the CNNs transparent, is hard and time-consuming | High | [96,107,108,109,110,111,112,130,152,153] |
| Neuro-Symbolic | Since domain knowledge is referenced to make inferences; there is a high chance that the systems developed in this paradigm reflect the business requirements | It is difficult to devise such explainers when domain knowledge is unavailable | Moderate | [118,119,120,121,122,123,124,125] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamakshi, V.; Krishnan, N.C. Explainable Image Classification: The Journey So Far and the Road Ahead. AI 2023, 4, 620-651. https://doi.org/10.3390/ai4030033
Kamakshi V, Krishnan NC. Explainable Image Classification: The Journey So Far and the Road Ahead. AI. 2023; 4(3):620-651. https://doi.org/10.3390/ai4030033
Chicago/Turabian StyleKamakshi, Vidhya, and Narayanan C. Krishnan. 2023. "Explainable Image Classification: The Journey So Far and the Road Ahead" AI 4, no. 3: 620-651. https://doi.org/10.3390/ai4030033
APA StyleKamakshi, V., & Krishnan, N. C. (2023). Explainable Image Classification: The Journey So Far and the Road Ahead. AI, 4(3), 620-651. https://doi.org/10.3390/ai4030033