

Visual Analytics in Explaining Neural Networks with Neuron Clustering


Abstract
:1. Introduction
- a clustering approach to resolve visual clutter problems in neural network architecture.
- a new visual platform to interpret data flow in DNN.

2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies | Visual Clutter | Interactions | Purpose of Explanation | ||||
|---|---|---|---|---|---|---|---|
| Filtering | Reduction Operations | Bundling | Clustering | Others | |||
| Deepvix [15] | X | F, H, DM | AA, PA | ||||
| Summit [16] | X | C, H | AA | ||||
| ReVACNN [17] | X | F, DM | AA, PA | ||||
| Rauber et al. [20] | X | X | C, F | FA | |||
| CNNVis [8] | X | X | DM | AA, FA | |||
| Wu et al. [26] | X | X | DM | PA, FA | |||
| Activis [7] | X | DM | AA, FA | ||||
| TensorFlow PlayGround [32] | A, DM | FA, PA | |||||
| TensorBoard [33] | X | Node Expansion | C | AA, PA | |||
| Bellgardt et al. [30] | X | 3D in VR | C | AA, PA | |||
| DeepVID [21] | X | C | FA | ||||
| USEVis [31] | X | Thresholds | C, F, DM | FA | |||
| Shen et al. [29] | X | C, F | FA | ||||
| Chae et al. [12] | Stripes design | C | FA, PA | ||||
| Our VA tool | X | Circular design | C, H | AA, FA | |||
3. The Proposed Tool
3.1. Design Challenges
3.2. Design Goals
4. Methodology
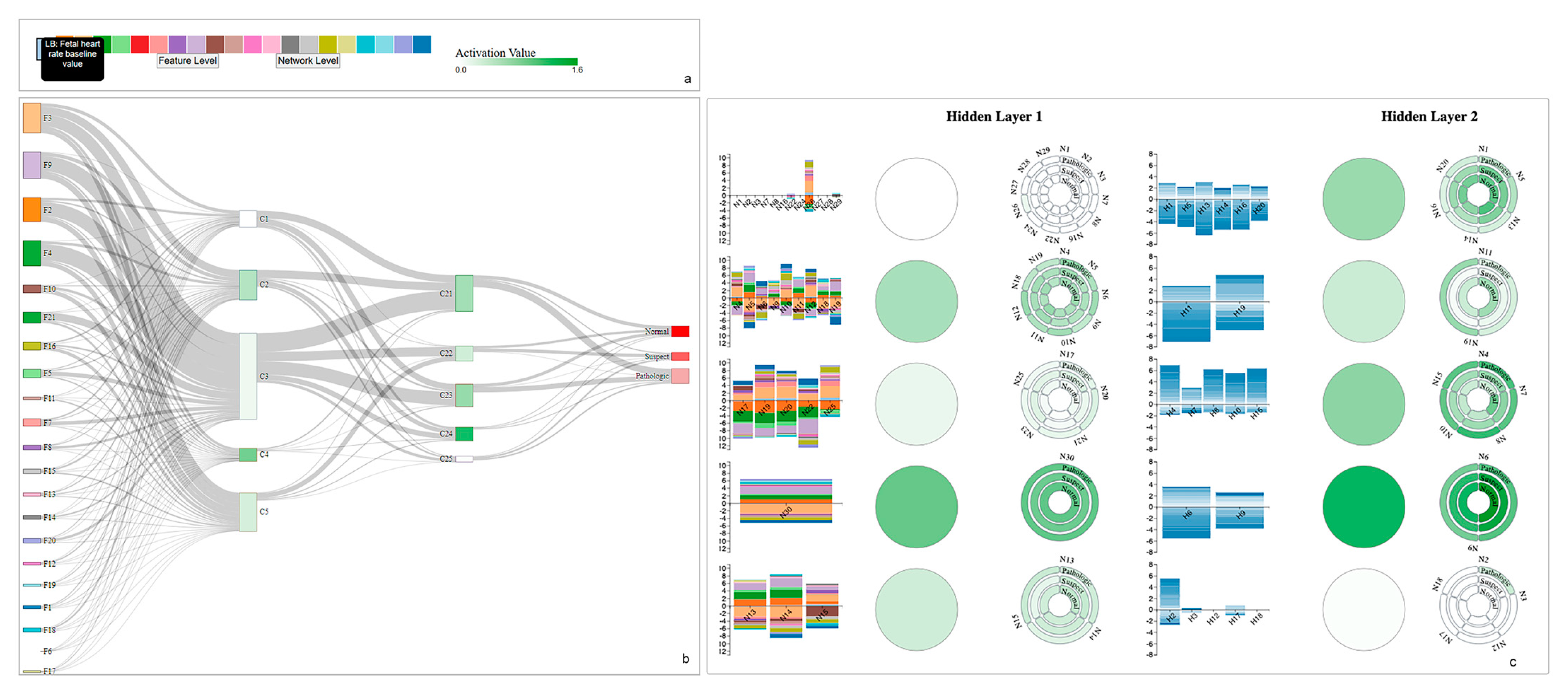
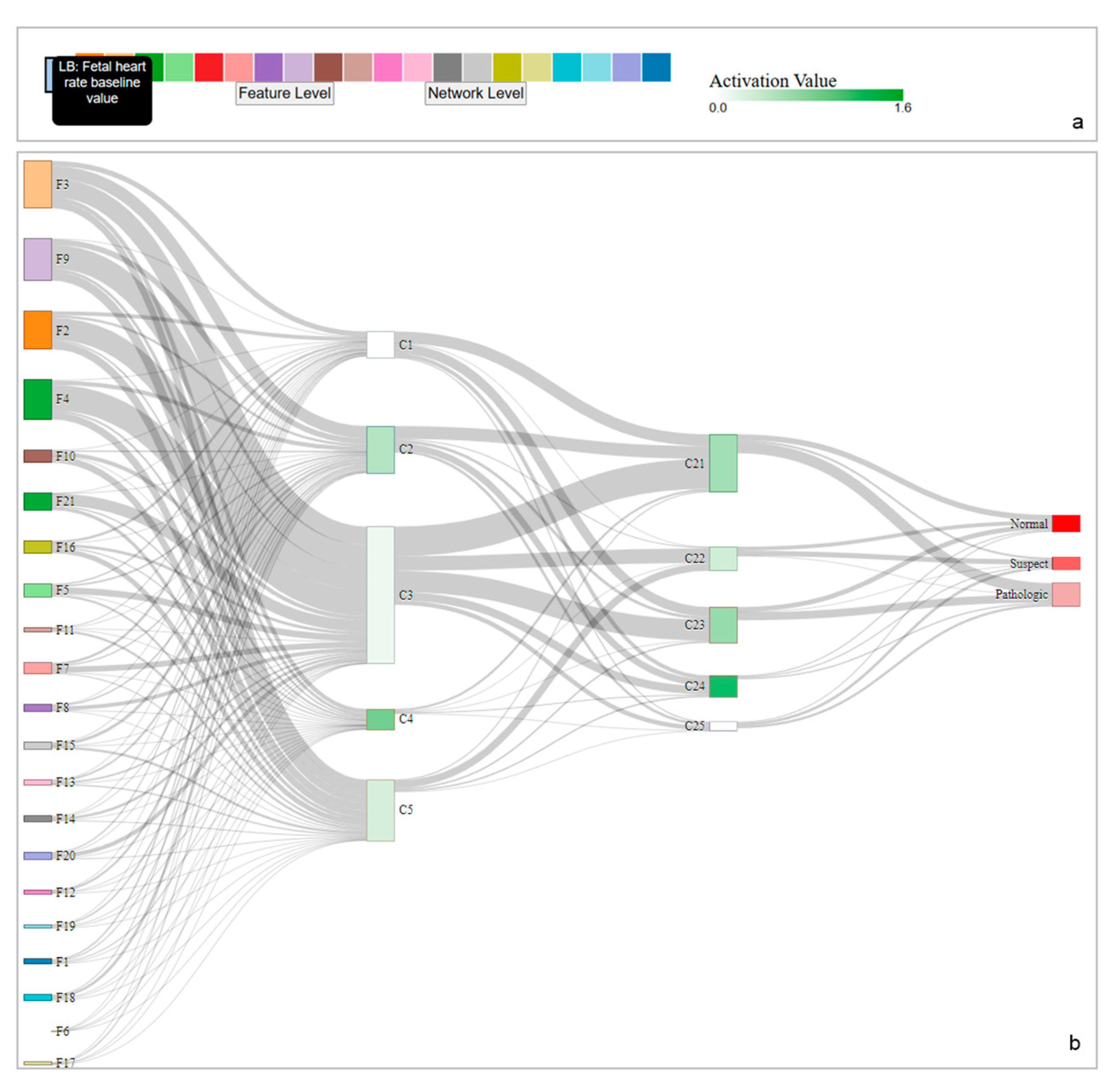
4.1. Use Case: CTG Dataset
4.2. Model Selection
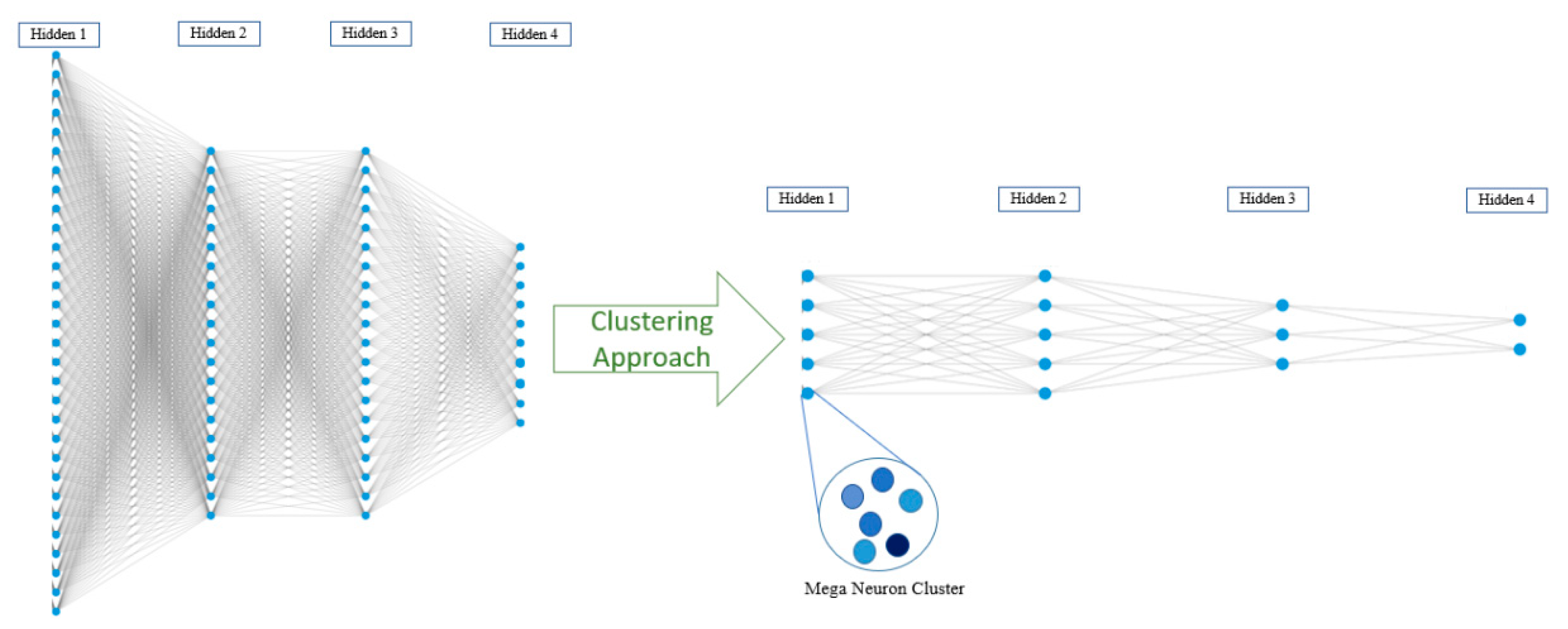
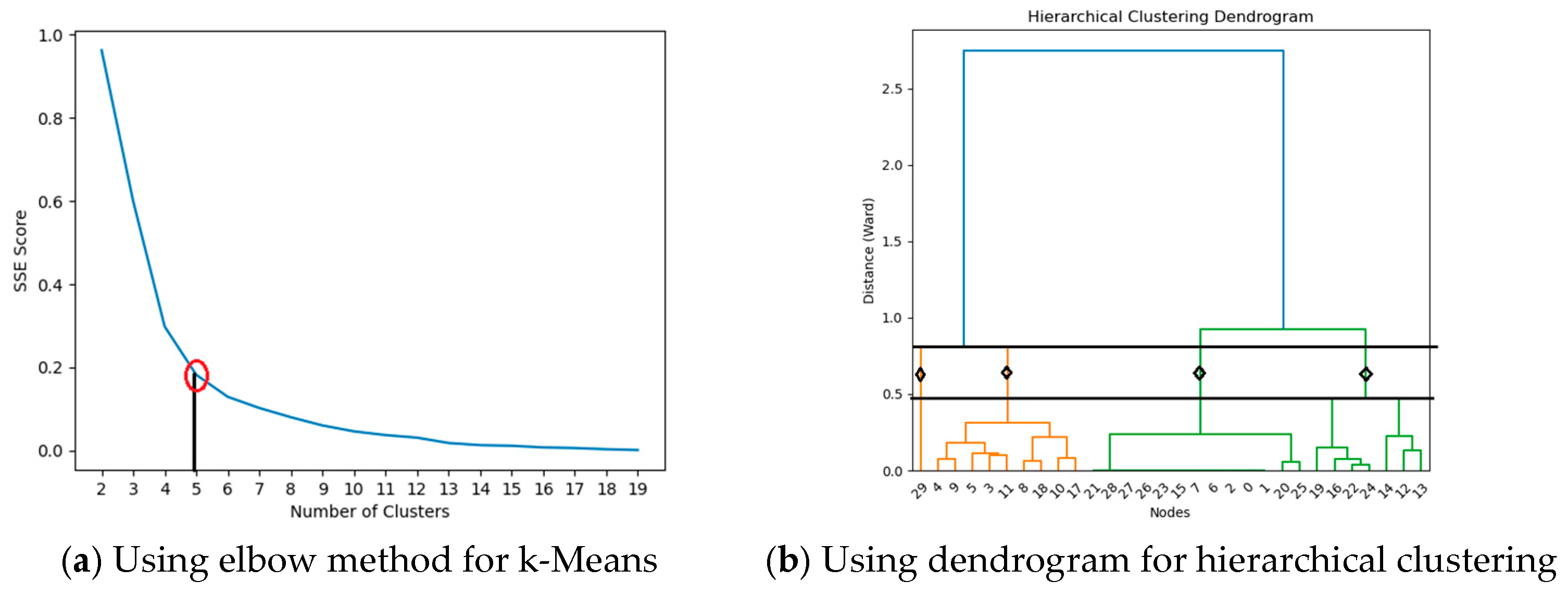
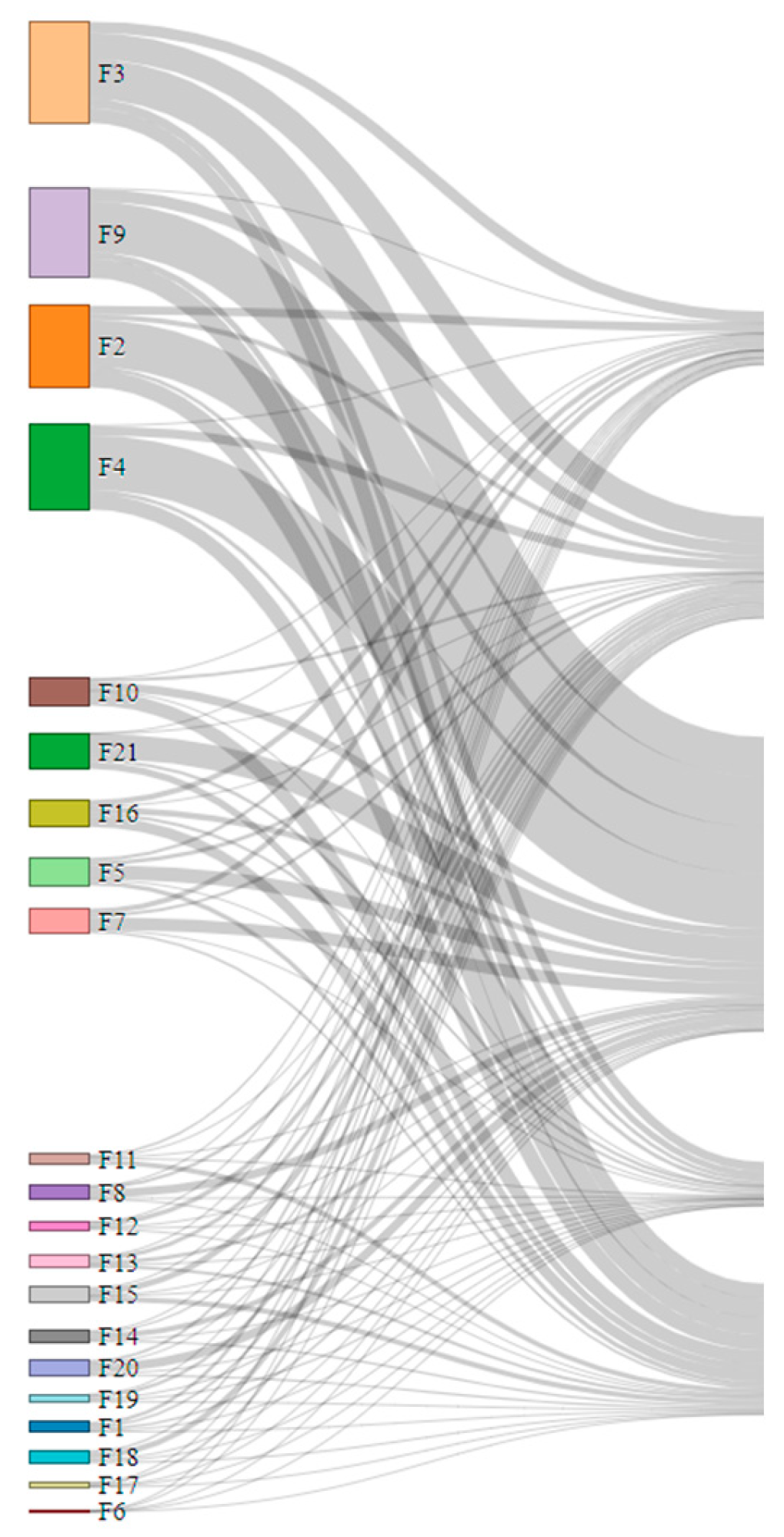
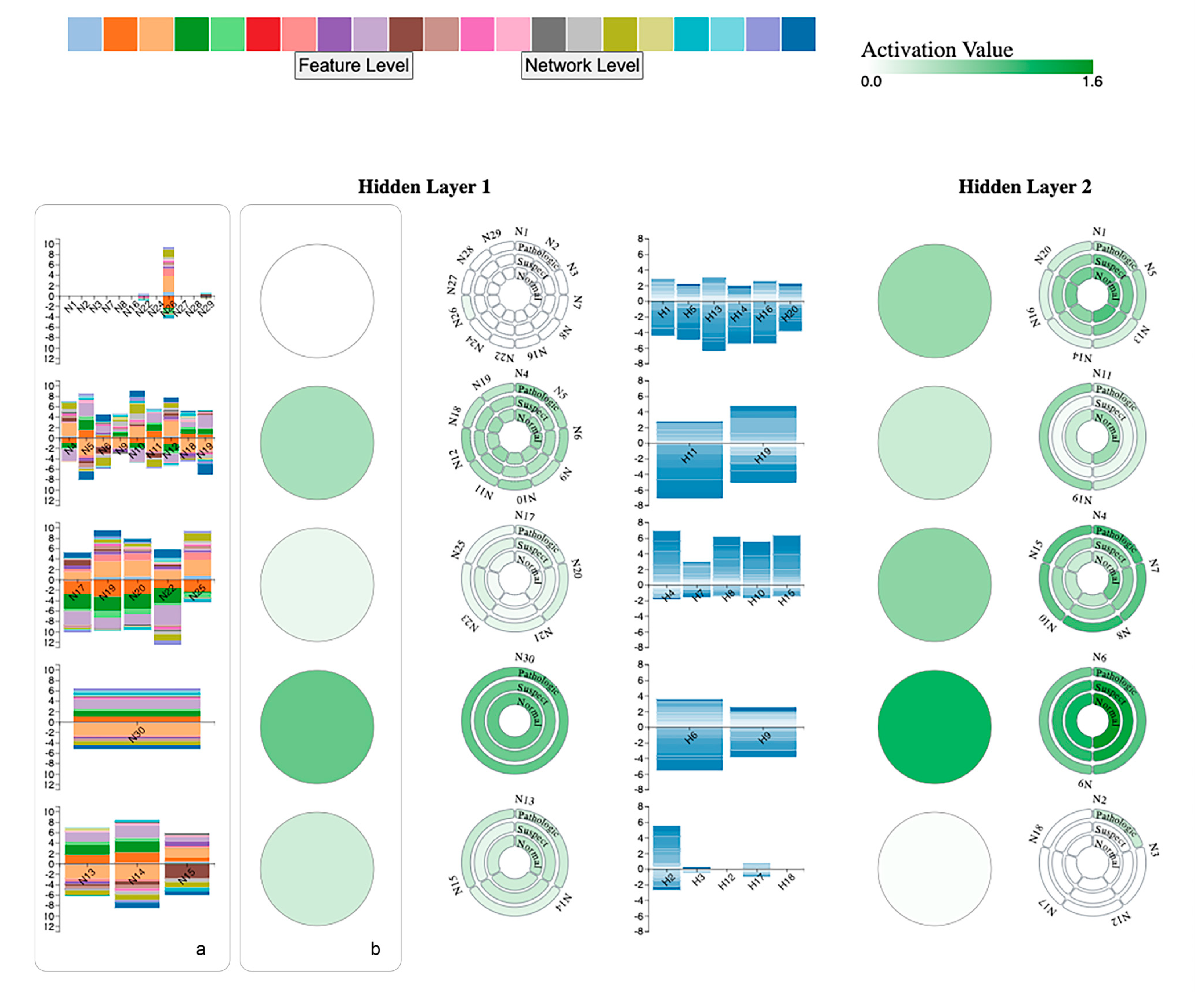
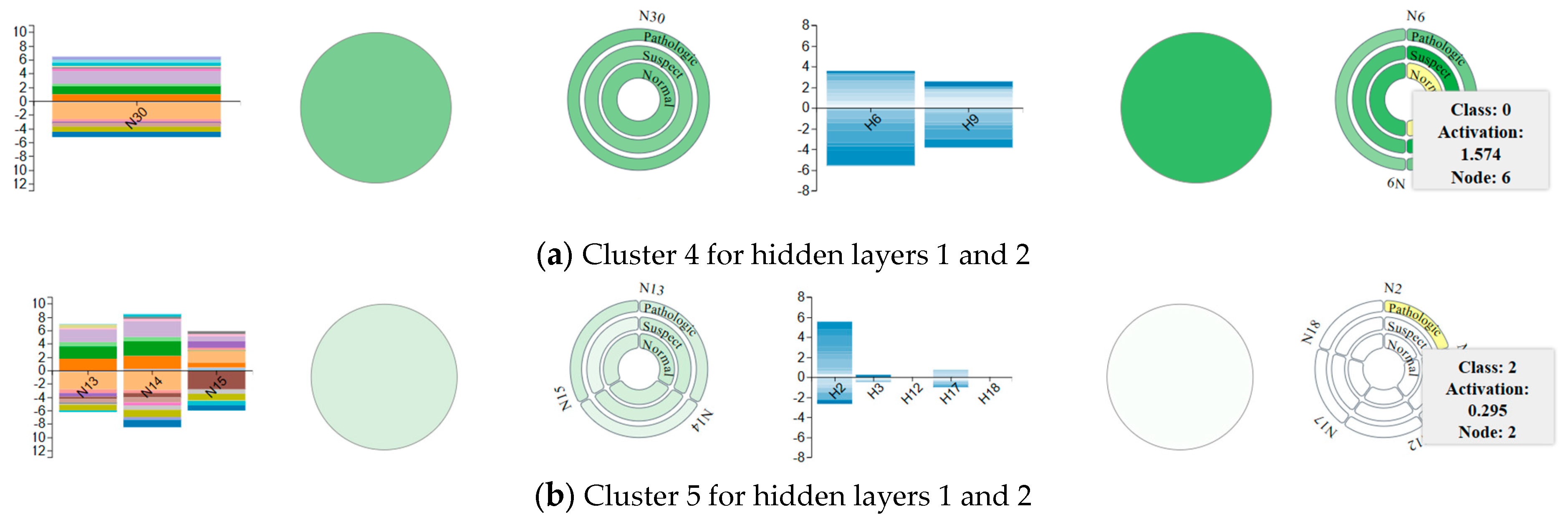
4.3. Neuron Clustering Approach and Results
4.4. Visualization Overview and Usage Scenario
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 12 December 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Application of Deep Learning for Object Detection. Procedia Comput. Sci. 2018, 132, 1706–1717. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; pp. 160–167. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey. arXiv 2020. [Google Scholar] [CrossRef]
- Liu, M.; Shi, J.; Cao, K.; Zhu, J.; Liu, S. Analyzing the Training Processes of Deep Generative Models. IEEE Trans. Vis. Comput. Graph. 2018, 24, 77–87. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Cui, W.; Jin, K.; Guo, Y.; Qu, H. DeepTracker: Visualizing the training process of convolutional neural networks. ACM Trans. Intell. Syst. Technol. 2018, 10, 6. [Google Scholar] [CrossRef]
- Kahng, M.; Andrews, P.Y.; Kalro, A.; Chau, D.H.P. ActiVis: Visual Exploration of Industry-Scale Deep Neural Network Models. IEEE Trans. Vis. Comput. Graph. 2018, 24, 88–97. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Shi, J.; Li, Z.; Li, C.; Zhu, J.; Liu, S. Towards Better Analysis of Deep Convolutional Neural Networks. IEEE Trans. Vis. Comput. Graph. 2017, 23, 91–100. [Google Scholar] [CrossRef] [PubMed]
- Sun, B. Use of Visual Analytics (VA) in Explainable Artificial Intelligence (XAI): A Framework of Information Granules; Springer International Publishing: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Krause, J.; Dasgupta, A.; Swartz, J.; Aphinyanaphongs, Y.; Bertini, E. A Workflow for Visual Diagnostics of Binary Classifiers using Instance-Level Explanations. In Proceedings of the 2017 IEEE Conference on Visual Analytics Science and Technology (VAST), Phoenix, AZ, USA, 3–6 October 2017; pp. 162–172. [Google Scholar] [CrossRef]
- Zhou, H.; Xu, P.; Yuan, X.; Qu, H. Edge bundling in information visualization. Tsinghua Sci. Technol. 2013, 18, 145–156. [Google Scholar] [CrossRef]
- Mohamed, E.; Sirlantzis, K.; Howells, G. A review of visualisation-as-explanation techniques for convolutional neural networks and their evaluation. Displays 2022, 73, 102239. [Google Scholar] [CrossRef]
- Hohman, F.; Kahng, M.; Pienta, R.S.; Chau, D. Visual Analytics in Deep Learning: An Interrogative Survey for the Next Frontiers. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2674–2693. [Google Scholar] [CrossRef] [PubMed]
- Rosenholtz, R.; Li, Y.; Nakano, L. Measuring visual clutter. J. Vis. 2007, 7, 17. [Google Scholar] [CrossRef] [PubMed]
- Dang, T.; Van, H.; Nguyen, H.; Pham, V.; Hewett, R. DeepVix: Explaining Long Short-Term Memory Network with High Dimensional Time Series Data. In Proceedings of the 11th International Conference on Advances in Information Technology, Bangkok, Thailand, 1–3 July 2020. [Google Scholar] [CrossRef]
- Hohman, F.; Park, H.; Robinson, C.; Polo Chau, D.H. Summit: Scaling Deep Learning Interpretability by Visualizing Activation and Attribution Summarizations. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1096–1106. [Google Scholar] [CrossRef] [PubMed]
- Chung, S.; Suh, S.; Park, C.; Kang, K.; Choo, J.; Kwon, B.C. ReVACNN: Real-Time Visual Analytics for Convolutional Neural Network. In Proceedings of the ACM SIGKDD Workshop on Interactive Data Exploration and Analytics, San Francisco, CA, USA, 14 August 2016; pp. 30–36. Available online: http://www.image-net.org/challenges/LSVRC/ (accessed on 3 February 2022).
- Jin, Z.; Wang, Y.; Wang, Q.; Ming, Y.; Ma, T.; Qu, H. GNNVis: A Visual Analytics Approach for Prediction Error Diagnosis of Graph Neural Networks. arXiv 2020. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Rauber, P.E.; Fadel, S.G.; Falcão, A.X.; Telea, A.C. Visualizing the Hidden Activity of Artificial Neural Networks. IEEE Trans. Vis. Comput. Graph. 2017, 23, 101–110. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Gou, L.; Zhang, W.; Yang, H.; Shen, H. Deepvid: Deep visual interpre- tation and diagnosis for image classifiers via knowledge distillation. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2168–2180. [Google Scholar] [CrossRef] [PubMed]
- Van Der Zwan, M.; Codreanu, V.; Telea, A. CUBu: Universal Real-Time Bundling for Large Graphs. IEEE Trans. Vis. Comput. Graph. 2016, 22, 2550–2563. [Google Scholar] [CrossRef] [PubMed]
- Cantareira, G.D.; Etemad, E.; Paulovich, F.V. Exploring neural network hidden layer activity using vector fields. Information 2020, 11, 426. [Google Scholar] [CrossRef]
- Chen, C.; Wang, Z.; Wang, X.; Guo, L.; Li, Y.; Liu, S. Interactive Graph Construction for Graph-Based Semi-Supervised Learning. IEEE Trans. Vis. Comput. Graph. 2021, 27, 3701–3716. [Google Scholar] [CrossRef] [PubMed]
- Cakmak, E.; Jackle, D.; Schreck, T.; Keim, D. Dg2pix: Pixel-Based Visual Analysis of Dynamic Graphs. In Proceedings of the 2020 IEEE Visualization in Data Science (VDS), Salt Lake City, UT, USA, 26 October 2020; pp. 32–41. [Google Scholar]
- Wu, C.; Qian, A.; Dong, X.; Zhang, Y. Feature-oriented Design of Visual Analytics System for Interpretable Deep Learning based Intrusion Detection. In Proceedings of the 2020 International Symposium on Theoretical Aspects of Software Engineering (TASE), Hangzhou, China, 11–13 December 2020; pp. 73–80. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mane, D.; Fritz, D.; Krishnan, D.; Viegas, F.B.; Wattenberg, M. Visualizing Dataflow Graphs of Deep Learning Models in TensorFlow. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef]
- Shen, Q.; Wu, Y.; Jiang, Y.; Zeng, W.; Lau, A.K.H.; Vianova, A.; Qu, H. Visual Interpretation of Recurrent Neural Network on Multi-dimensional Time-series Forecast. In Proceedings of the 2020 IEEE Pacific Visualization Symposium (PacificVis), Tianjin, China, 3–5 June 2020; pp. 61–70. [Google Scholar] [CrossRef]
- Bellgardt, M.; Scheiderer, C.; Kuhlen, T.W. An Immersive Node-Link Visualization of Artificial Neural Networks for Machine Learning Experts. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), Utrecht, The Netherlands, 14–18 December 2020; pp. 33–36. [Google Scholar] [CrossRef]
- Ji, X.; Tu, Y.; He, W.; Wang, J.; Shen, H.; Yen, P. USEVis: Visual analytics of attention-based neural embedding in information retrieval. Vis. Inform. 2021, 5, 1–12. [Google Scholar] [CrossRef]
- TensorFlow PlayGround. Available online: https://playground.tensorflow.org/ (accessed on 16 December 2023).
- TensorBoard. Available online: https://www.tensorflow.org/tensorboard/graphs (accessed on 16 December 2023).
- Chan, G.Y.; Yuan, J.; Overton, K.; Barr, B.; Rees, K.; Nonato, L.; Bertini, E.; Silva, C.T. SUBPLEX: Towards a better understanding of black box model explanations at the subpopulation level. IEEE Comput. Graph. Appl. 2022, 42, 24–36. [Google Scholar] [CrossRef]
- Yuan, J.; Barr, B.; Overton, K.; Bertini, E. Visual Exploration of Machine Learning Model Behavior With Hierarchical Surrogate Rule Sets. IEEE Trans. Vis. Comput. Graph. 2022, 30, 1470–1488. [Google Scholar] [CrossRef] [PubMed]
- Spinner, T.; Schlegel, U.; Schäfer, H.; El-Assady, M. ExplAIner: A visual analytics framework for interactive and explainable machine learning. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1064–1074. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. ‘Why should i trust you?’ Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserma, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Letham, B.; Rudin, C.; McCormick, T.; Madigan, D. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. Ann. Appl. Stat. 2015, 9, 1350–1371. [Google Scholar] [CrossRef]
- Angelov, P.; Soares, E. Towards explainable deep neural networks (xDNN). Neural Netw. 2020, 130, 185–194. [Google Scholar] [CrossRef] [PubMed]
- Schlegel, U.; Cakmak, E.; Keim, D.A. ModelSpeX: Model specification using explainable artificial intelligence methods. In Proceedings of the International Workshop on Machine Learning in Visualization for Big Data, Norrköping, Sweden, 25–29 May 2020; Volume 1, pp. 2–6. [Google Scholar] [CrossRef]
- Alicioglu, G.; Sun, B. A survey of visual analytics for Explainable Artificial Intelligence methods. Comput. Graph. 2021, 102, 502–520. [Google Scholar] [CrossRef]
- Alicioglu, G.; Sun, B. ViewClassifier: Visual Analytics on Performance Analysis for Imbalanced Fatal Accident Data. In Intelligent Systems and Applications. IntelliSys 2021; Arai, K., Ed.; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2021; p. 296. [Google Scholar]
- Wang, Z.J.; Turko, R.; Shaikh, O.; Park, H.; Das, N.; Hohman, F.; Kahng, M.; Chau, D. CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1396–1406. [Google Scholar] [CrossRef] [PubMed]
- Kelly, M.; Longjohn, R.; Nottingham, K. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 1 March 2024).
- Ravindran, S.; Jambek, A.B.; Muthusamy, H.; Neoh, S.C. A novel clinical decision support system using improved adaptive genetic algorithm for the assessment of fetal well-being. Comput. Math. Methods Med. 2015, 2015, 283532. [Google Scholar] [CrossRef]
- Ayres-de-Campos, D.; Bernardes, J.; Garrido, A.; Marques-de-sá, J.; Pereira-leite, L. SisPorto 2.0: A Program for Automated Analysis of Cardiotocograms. J. Matern. Fetal Med. 2000, 9, 311–318. [Google Scholar] [CrossRef] [PubMed]
- Tamer, J.A. Abnormal Foetuses Classification Based on Cardiotocography Recordings Using Machine Learning and Deep Learning Algorithms. Master’s Thesis, National College of Ireland, Dublin, Ireland, 2020. [Google Scholar]
- Bostock, M.; Ogievetsky, V.; Heer, J. D3: Data-driven documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef] [PubMed]
- Comaniciu, D.; Meer, P. Mean Shift: A Robust Approach Toward Feature Space Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Nielsen, F. Hierarchical Clustering. In Introduction to HPC with MPI for Data Science; Undergraduate Topics in Computer Science; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Murtagh, F.; Legendre, P. Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef]
- Sci-Kit Learn. Available online: https://scikit-learn.org/stable/modules/clustering.html (accessed on 16 December 2023).
- Amin, B.; Salama, A.A.; Gamal, M.; El-Henawy, I.M.; Mahfouz, K. Classifying Cardiotocography Data based on Rough Neural Network. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 352–356. [Google Scholar] [CrossRef]








| Clustering Algorithms | The Number of Clusters | Silhouette Score (Max) | DB Score (Min) | CH Score (Max) | |
|---|---|---|---|---|---|
| 1st Hidden Layer | K-means | 5 | 0.632 | 0.49 | 159.44 |
| Mean Shift | 6 | 0.60 | 0.40 | 143.28 | |
| Hierarchical Clustering | 4 | 0.630 | 0.46 | 131.76 | |
| 2nd Hidden Layer | K-means | 5 | 0.59 | 0.53 | 41.60 |
| Mean Shift | 4 | 0.58 | 0.47 | 36.03 | |
| Hierarchical Clustering | 4 | 0.56 | 0.60 | 28.50 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alicioglu, G.; Sun, B. Visual Analytics in Explaining Neural Networks with Neuron Clustering. AI 2024, 5, 465-481. https://doi.org/10.3390/ai5020023
Alicioglu G, Sun B. Visual Analytics in Explaining Neural Networks with Neuron Clustering. AI. 2024; 5(2):465-481. https://doi.org/10.3390/ai5020023
Chicago/Turabian StyleAlicioglu, Gulsum, and Bo Sun. 2024. "Visual Analytics in Explaining Neural Networks with Neuron Clustering" AI 5, no. 2: 465-481. https://doi.org/10.3390/ai5020023
APA StyleAlicioglu, G., & Sun, B. (2024). Visual Analytics in Explaining Neural Networks with Neuron Clustering. AI, 5(2), 465-481. https://doi.org/10.3390/ai5020023