1. Introduction
Recommendation has become an indispensable part of software systems, particularly e-commerce and online streaming applications such as Spotify (spotify.com) and Netflix (netflix.com), alleviating the load of search for users in a vast item collection and positively affecting the perception of the users about the applications through improved user experience [
1]. Recommender systems process user history to generate recommendations. One way of obtaining a user’ previous experience on an item is through explicit ratings. As an alternative way, implicit rating indirectly provides information about the user’s opinion on an item, based on activities of the user such as clicking, searching some keywords, purchases, etc., and gives hints for the user’s intent and interest [
2]. The Collaborative Filtering (CF) method [
3], being a popular recommendation technique, uses the similarity between past preferences of users. However, CF suffers from well-known
data sparsity and
cold start problems. In order to overcome the performance degrading due to such problems, recommender systems employ a variety of auxiliary information including product details of the items, social network of users or external contextual information such as weather or currency rate [
4].
In social relationships, concepts such as
trust and
loyalty are important and useful to describe and quantify the nature of the relationship between users [
1]. Loyalty expresses the strength of the tie between a user and an object or environment, whereas trust is merely about the relationship between the users in an environment, such as a social network. In recommendation methods, specifically in CF, these concepts provide valuable information to improve recommendation performance, and hence it has been used within recommender systems in the literature mostly to overcome the aforementioned issues of CF. Particularly, trust information helps to reduce the data sparsity through enrichment with the ratings of trusted neighbors. It is also useful against the cold start problem as the preferences of trusted neighbors or trusted users, in general, can provide a basis for recommendation.
In trust-aware recommendation studies, two types of trust data are used:
explicit and
implicit trust. Explicit trust is obtained through user feedback on other users. A well-known example is Epinions (
http://www.epinions.com/help/faq/?show=faq_wot, accessed on 3 August 2022), which is a website of product reviews. It uses a trust system such that users can define their
web of Trust, which is a set of reviewers whose reviews and ratings are consistently found to be useful, and their
block list, which includes reviewers that a user consistently finds inaccurate or not useful (
http://www.trustlet.org/epinions.html, accessed on 3 August 2022). The data set crawled from The Epinions website, namely
epinions data set, has been popularly used as explicit trust data in various studies [
5,
6,
7,
8]. Explicit trust networks can be
unsigned, including only positive trust links, or
signed, where both negative and positive trust links are available.
On the other hand,
implicit trust provides information about the trust relationship between users indirectly, generally through activities and behavior of users [
5,
9]. Since explicit trust information is scarcely available, and it is mostly sparse, several studies focus on generating implicit trust by using other data sources such as the rating data and social connection of users [
10]. For example, in [
11], interest similarity is used for inferring trust between two users, whereas in [
9], trust propagation over a social network is employed for constructing the trust network of a given user.
Research Questions. Trust information has been used in a variety of recommendation studies both in explicit and implicit form and it has been shown that it improves recommendation accuracy [
9,
12,
13]. In this work, focusing on a different aspect of trust-aware recommendation, the following two sub-problems of explicit and implicit trust are analyzed in the recommendation setting:
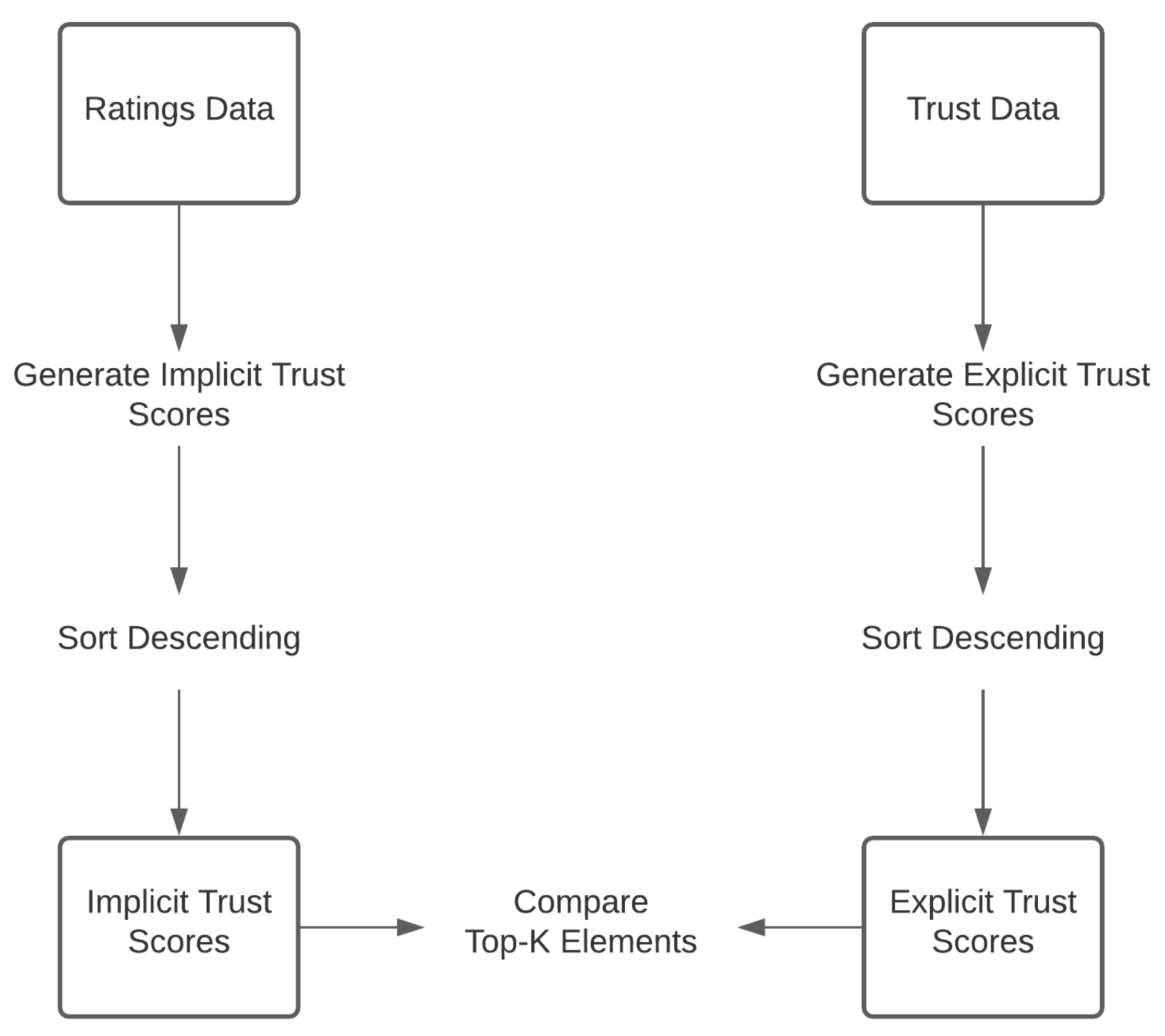
The first one is about examining the compatibility between explicit and implicit trust scores. For this analysis, an implicit trust model is devised, and by using this implicit trust model, the matching between implicit and explicit trust scores is analyzed. This analysis is crucial for understanding the nature of implicit and explicit trust and using them in either a complementary way or as a replacement.
The second sub-problem is about constructing a machine learning model for explicit trust in order to predict missing trust relationships in a trust network. In this way, the data sparsity in explicit trust information can be reduced. There are two types of explicit trust networks: an unsigned network with only positive links and a signed trust network with negative and positive links. In an unsigned trust matrix, trust information is explicitly expressed as 1 to denote trust. However, 0 as the trust value may indicate either a neutral or unknown trust relationship. For this, two different explicit trust models are generated. In the first model, users’ rating behavior is exploited for explicit trust modeling. A trust graph is generated in the second approach, and the problem is specified as a link prediction problem. In the graph model, trust value 1 in the matrix denotes a link, whereas trust value 0 shows that there is no edge between the given nodes (i.e., users). It is aimed to predict the missing trust relationships in the trust graph by constructing an explicit trust model. The effect of augmenting the trust matrix through the proposed approach is analyzed through trust-based recommendation methods in the literature.
Contributions. A preliminary version of the study is published in [
14]. In this paper, the study is extended both with more detailed explanations and discussions, and additional machine learning models, algorithms and their analysis. For the explicit and implicit trust model comparison part, the approach and analyses are described in more detail. Similarly, in explicit trust modeling, descriptions of the proposed approaches are given with additional explanations. As a new modeling approach in this paper, unsupervised machine learning algorithms are applied for explicit trust modeling, and an outlier detection-based model is developed based on Isolation Forest and One-Class Support Vector Machine (SVM). Additionally, the explicit trust model is constructed by SVM in addition to Random Forest and Naive Bayes classifier. For all the experiments, the results are further discussed and elaborated on.
The contributions of this study can be summarized as follows:
An implicit trust model is devised, which is adapted from the consistency model for reputation scores of users in [
15]. This model is used for compatibility analysis of implicit and explicit scores.
The implicit trust model generates a single score per user. In contrast, the available explicit trust data sets inform about the trust relationship between two users. To overcome this incompatibility, a mapping schema is proposed such that an explicit trust score per user is generated by using the explicit trust graph.
A supervised learning model is constructed for explicit trust score prediction by using the ratings that users give to model explicit trust data. This method is used for both signed and unsigned trust data.
Another explicit trust score prediction model is constructed such that finding an explicit trust between two users is considered an edge prediction problem and a supervised learning model is generated to predict unknown trust values. The effectiveness of an augmented trust network is analyzed through recommendation performance.
Organization. The rest of the paper is organized as follows. In
Section 2, related studies in the literature are summarized. The methods proposed and employed in this study are presented in
Section 3. The experiments and results are presented in
Section 4. Finally,
Section 5 concludes the paper with an overview and future work.
2. Literature Review
Trust-aware recommendation is a challenging research problem and there is a variety of solutions that focus on the use of the trust information to improve the accuracy of recommendations, particularly alleviating cold start and rating data sparsity problems.
As one of the initial trust-based studies, in [
11], Htun and Tar consider trust as a solution to cold-start problems in recommender systems. To this aim, explicit trust ratings are used for neighbor formation. Since reliable explicit trust data is rarely available, the authors propose a method to derive implicit trust relationships based on the similarity of user interests. Trust between users is measured according to the following similarity measures: user interest similarity, resource item similarity, and interest similarity on resource items. The resulting trust metric is incorporated into the recommender system. The performance of the proposed approach is reported to outperform traditional CF.
In [
16], Chen et al. propose a cold start recommendation method that integrates the user model with trust and distrust for each new user. With the proposed approach, trustworthy users can be identified by analyzing the web of trust of experienced users. In the proposed method, a user model is constructed by using a clustering algorithm to group experienced users into clusters. Each cluster is formed with users that have similar item preferences. A web of trust is constructed for each cluster and the PageRank algorithm is used for finding experienced users in the cluster. The authors use distrust networks to find unreliable users in a similar way. Following this, the most closely related cluster is identified for a cold start new user to predict an unrated item’s possible rating. Previously identified experienced users in the cluster are exploited to recommend new cold-start users. Moreover, the proposed method identifies implicit trust links between users by exploiting the given rating.
In another study [
13], Guo et al. propose three factored similarity models that use social trust based on implicit user feedback. The proposed trust-based recommendation approach generates top-N item recommendations based on social trust relationships between users. In [
17], the authors develop another trust-based recommender that uses explicitly specified social trust information for generating recommendations. The method merges the ratings of a user’s trusted neighbors in order to find similar users.
In [
12], Yang et al. propose TrustMF, a matrix factorization-based method that fuses rating and trust information. TrustMF defines two models: the
truster model which denotes how others will affect user
u’s preferences and the
trustee model which denotes how user
u will affect others’ preferences. The main motivation for the use of truster and trustee models is to link ratings and trust information.
In order to overcome accuracy issues due to cold start and data sparsity, in [
9], Li et al. propose an implicit trust recommendation approach (ITRA) that utilizes implicit user information. The method generates a set of trusted neighbors of a given user by exploiting the social network and trust diffusion features in a trust network. After finding the trust neighbor set, trust values are determined by computing the shortest distance between a user and inferred trusted neighbor.
In [
18], Wang et al. introduce TeCF, a trust-enhanced collaborative filtering method that integrates user-based, item-based, and trust-based techniques to predict unrated items. The conducted experiments show that the proposed approach significantly reduces the effects of data sparsity by making the rating matrix denser.
The trust model of the SSL-SVD method in [
5] incorporates social trust (explicit trust) and sparse trust (implicit trust) information to improve recommendation accuracy. In the study, Hu et al. report that social trust is influenced by many social factors and has a limited effect on improving the accuracy of recommendations.
In recent studies, neural network-based solutions are also employed in trust-aware recommender systems. In [
19], a trust network is used in order to determine reliable implicit ratings of users. Once the rating profile of a user is augmented with such ratings, latent features of users are derived by using a deep representation model. The recommendation is generated based on the similarity of users through their latent feature representations.
As seen in the above-mentioned studies, the nature of trust information used in the recommendation and how it is incorporated varies; however, it is reported that overall the use of trust information has a positive effect on recommendation performance. In this study, another aspect of the use of trust modeling in the recommendation is focused on. The nature of implicit and explicit trust modeling and their compatibility are analyzed to further increase this positive effect.
5. Conclusions
In this work, trust modeling within the recommendation context is studied. More specifically, two sub-problems are focused on: (1) inferring the implicit trust information by examining the past user behaviors and analyzing the compatibility of implicit and explicit trust scores; (2) building an explicit trust model and predicting the missing explicit trust information.
For the first sub-problem, an implicit trust model is created. The implicit trust information is inferred by defining notions of conformity and consistency. After extracting implicit trust scores, the compatibility of implicit and explicit trust values is analyzed. The analysis of the approach reveals that there is no clear correlation between the implicit and explicit scores. The conducted experiments analyze how well the implicit and explicit scores match at the top-20% and top-10% of the trust scores. Under varying parameters, precision and recall scores are generally below 0.1. In addition, when the compatibility analysis is performed among more active users, it is seen that the precision increases above 0.1. The results hint at the effect of social ties in the trust relationship, and hence the implicit trust model cannot replace explicit trust but is merely helpful as complementary information.
For the second sub-problem, two different explicit models exhibit two different approaches. In the first approach, explicit trust is modeled by generating a set of new features containing liked and disliked items. While creating these features, users’ rating behavior is used. Here, separate experiments are performed for signed and unsigned trust networks. Expected performance could not be achieved in models created with one-class classification. However, in the experiments conducted with the augmented trust data created with the multi-class classification model, the precision and recall values in the SBPR and TBPR algorithms are boosted approximately twice. Here, it is seen that trust-based recommendation accuracy can be increased by modeling the ratings and explicit trust given by the users together.
For explicit trust score prediction, another solution is devised using the trust network itself. After generating the augmented trust network with this method, the effect of the augmented network is analyzed using various trust-based algorithms. The results show that the augmented trust matrix leads to improvement in performance, but the effect is not very high. This can be due to the fact that the trust values to be predicted are selected randomly, and the predictions do not significantly change the edge labels. Hence, with a more detailed mechanism for selecting the unknown trust relationships to be predicted, the performance could be further improved.
The proposed analysis on trust modeling for recommendation can be extended in a variety of directions. As one of the future dimensions, the proposed explicit trust model created by using rating behavior can be modified to be used for recommendation environments without any explicit trust data. Since the trust data is generally only scarcely available, such a solution widens the applicability of trust-based recommendation. In another future study, hybrid machine learning models and deep learning methods can be investigated to construct explicit trust models. The number of available data sets incurs a limitation, particularly for data-hungry deep learning-based solutions. At this point, mechanisms to incentive explicit trust in social network environments will be helpful to increase the amount of publicly available explicit trust data. Similar mechanisms have been employed in e-commerce platforms to express the reliability of e-stores. These mechanisms can be adapted and extended to social networks.
Another future work direction is conducting studies to detect and prevent attacks that can manipulate trust-based systems and affect users’ trust scores. Additionally, generating different implicit trust models and elaborating on their compatibility with explicit trust scores can be further studied. Another interesting direction could be developing an implicit trust model that produces a distrust score as well as trust value.









{kind=link}
{kind=link}
{kind=link}