


Significance of Machine Learning for Detection of Malicious Websites on an Unbalanced Dataset

 ,
, 
Abstract
:1. Introduction
2. Related Work
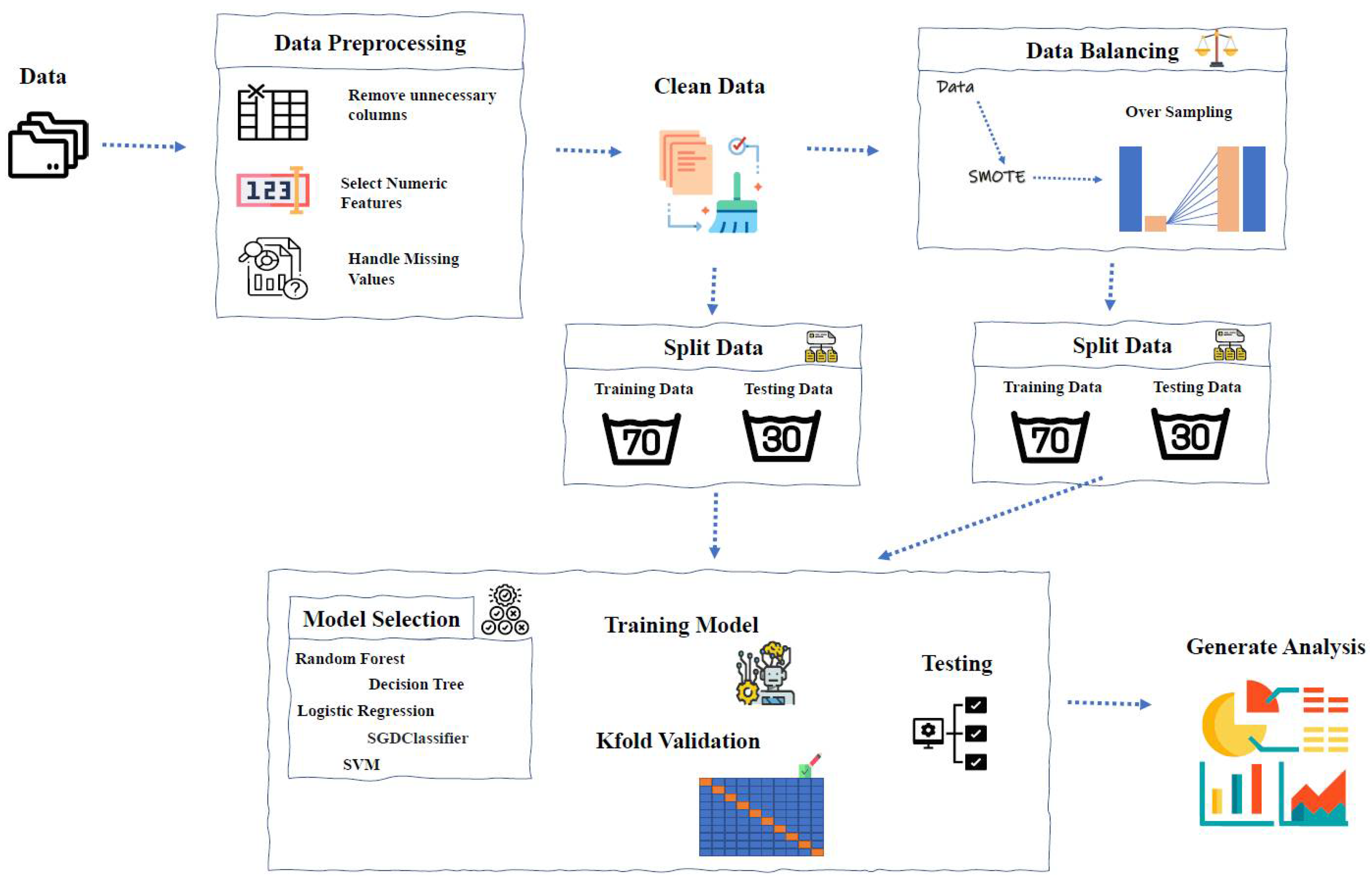
3. Methodology
3.1. Dataset Description
3.2. Data Balancing Technique
3.2.1. Random Undersampling Technique
3.2.2. Random Oversampling Technique
3.2.3. Synthetic Minority Oversampling Technique (SMOTE)
3.3. Classifiers
3.3.1. Decision Trees
3.3.2. Random Forest
- Random forest selects n random records at random from a data set of k records.
- A distinct decision tree is constructed for each sample.
- Each decision tree yields a result.
- In classification, the final result is determined by majority voting.
3.3.3. Logistic Regression
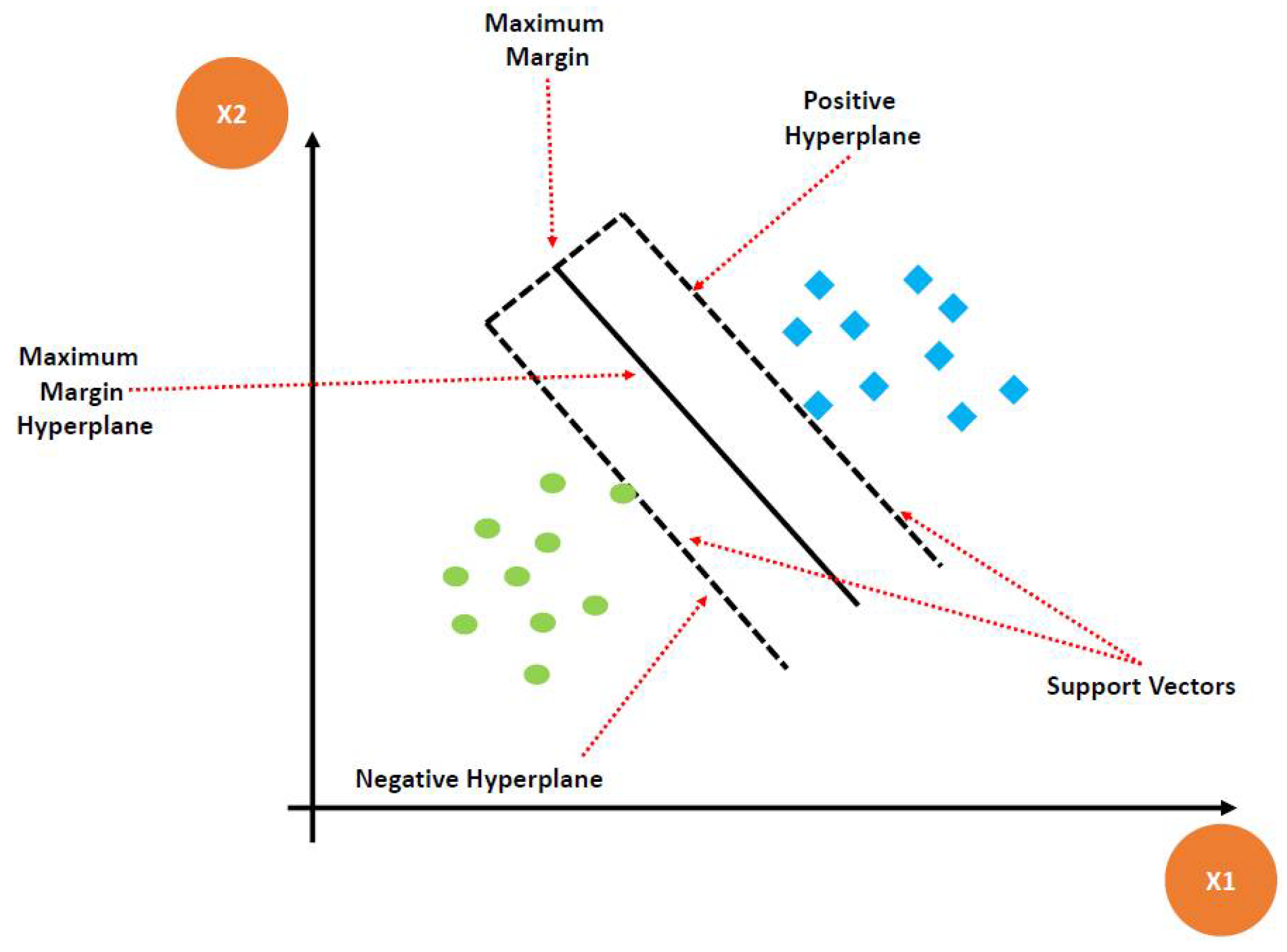
3.3.4. Support Vector Machine
3.3.5. Stochastic Gradient Descent
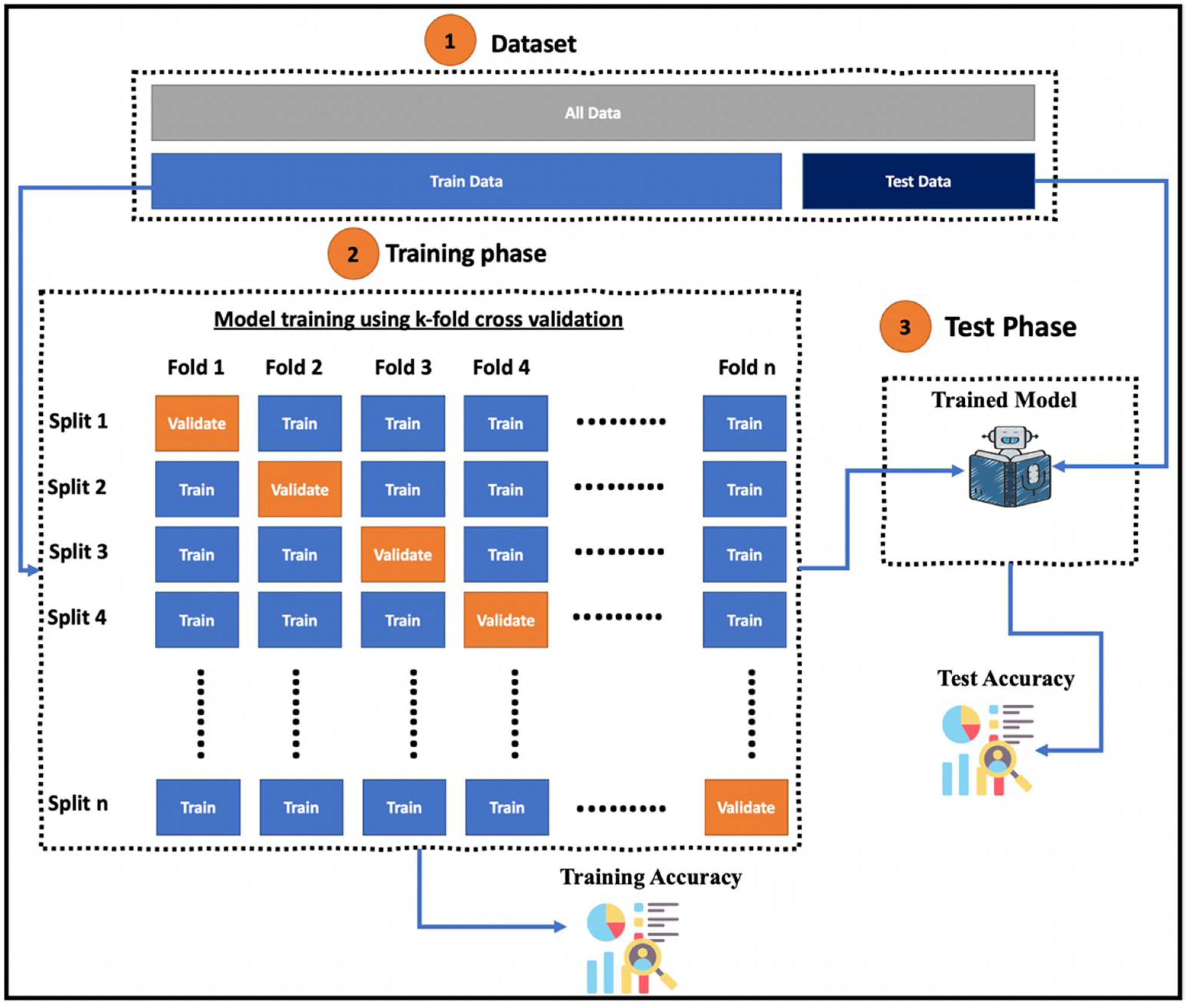
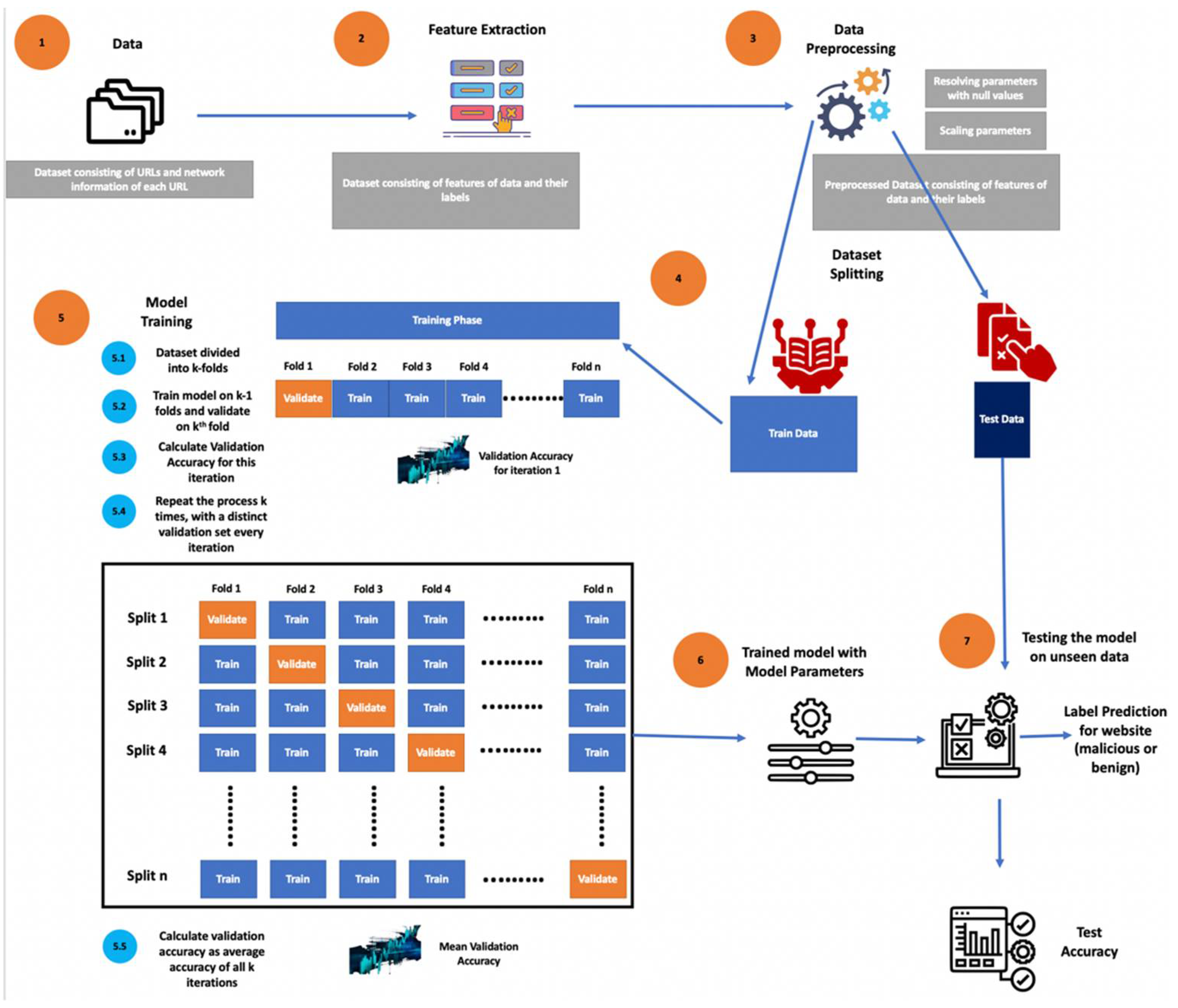
3.4. K-Fold Cross-Validation
3.5. Overall Methodology
3.6. Evaluation Metrics
3.6.1. Accuracy
3.6.2. Precision
3.6.3. Recall
3.6.4. F1-Score
3.6.5. False Positive Rate (FPR)
4. Results
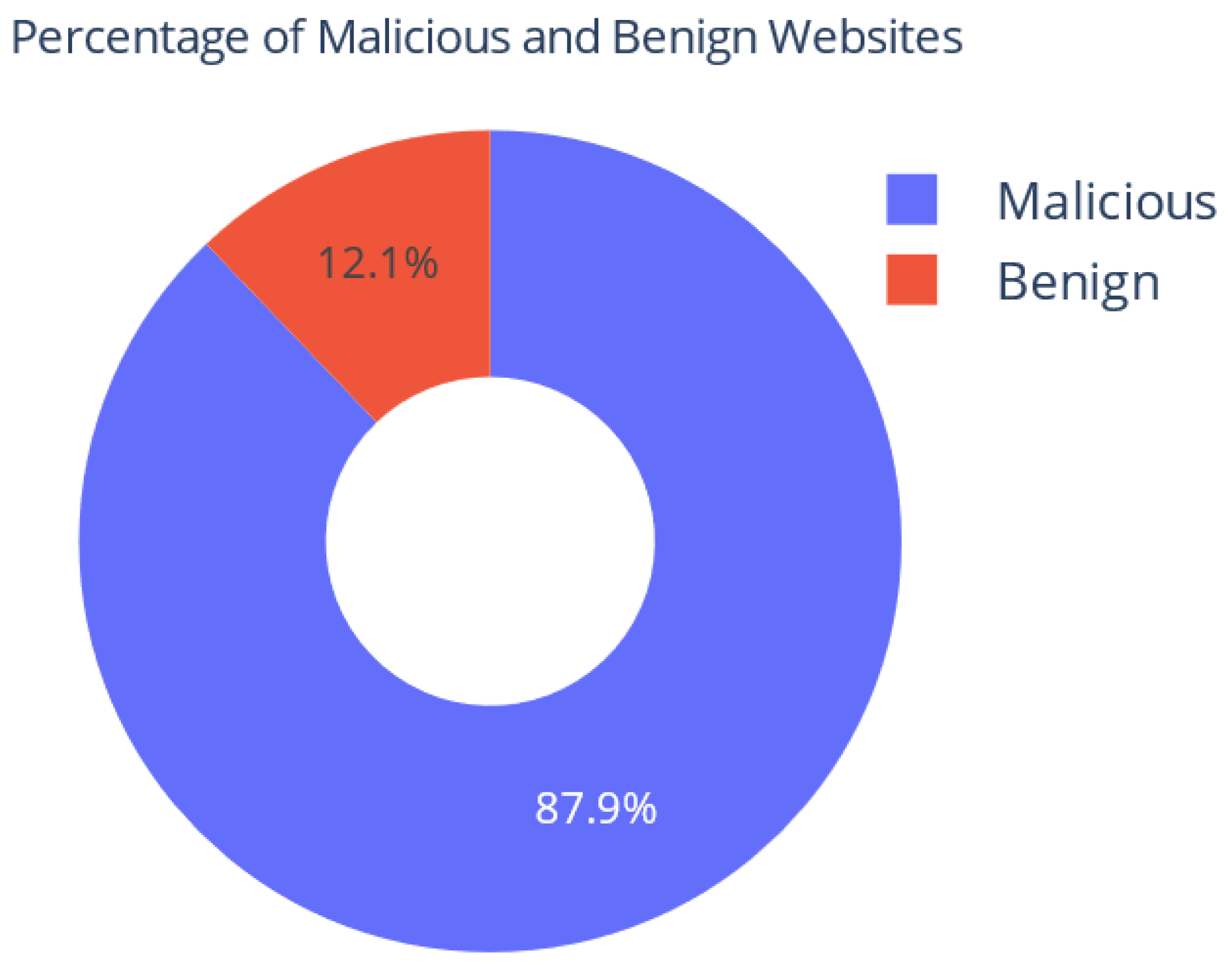
4.1. Exploratory Data Analysis
4.2. Confusion Matrix
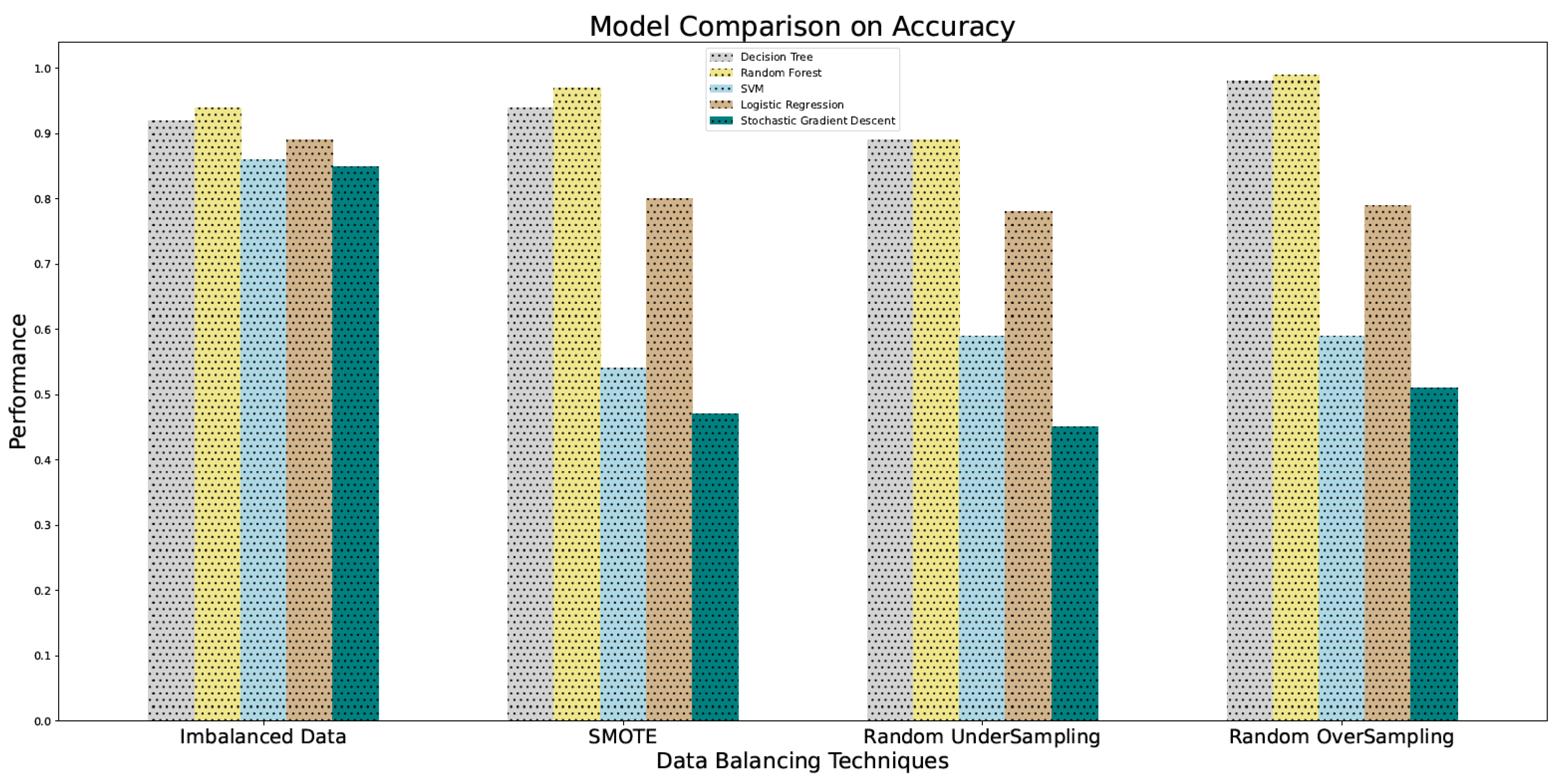
4.3. Accuracy
4.4. Precision
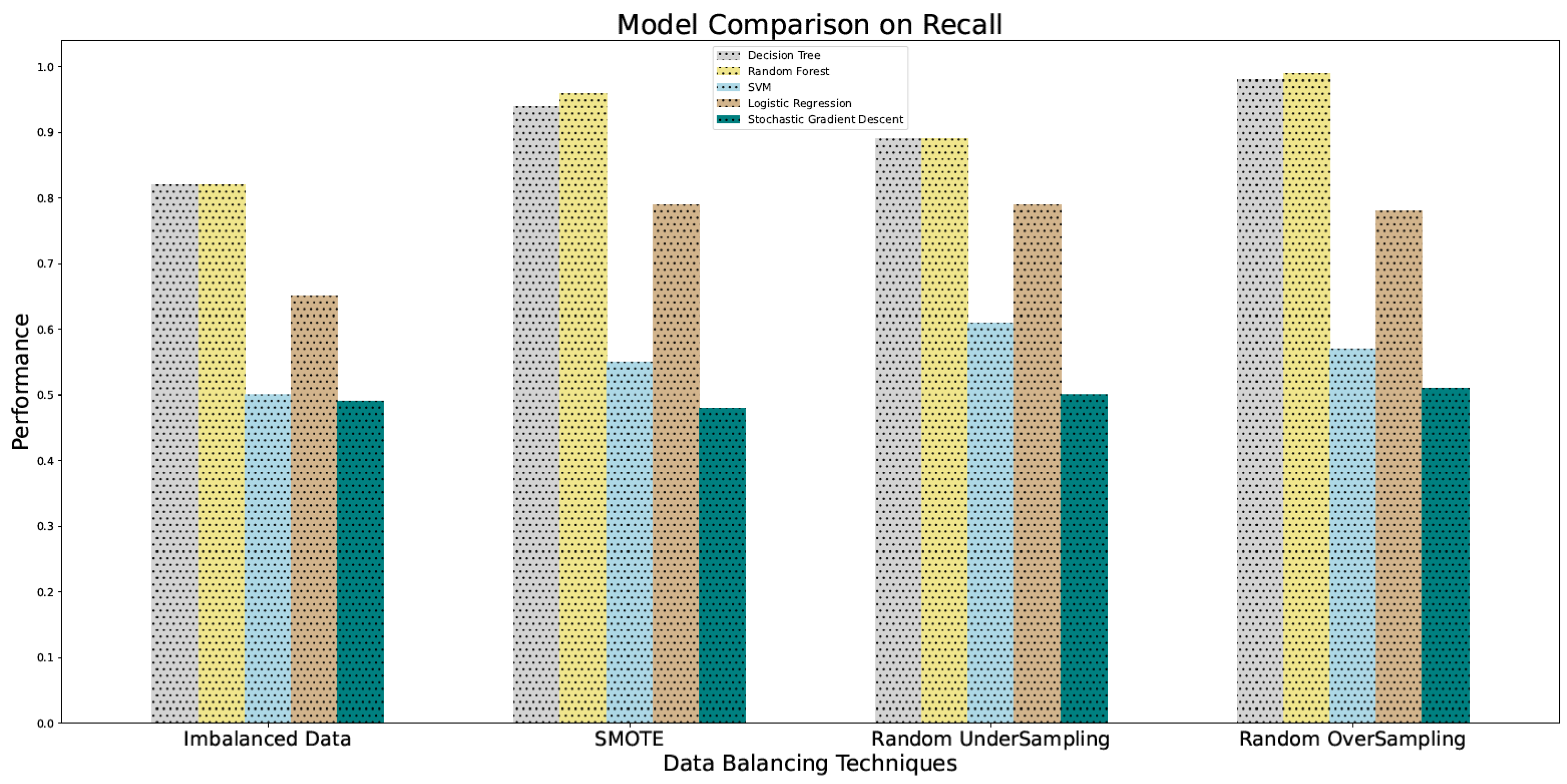
4.5. Recall
4.6. F1-Score
4.7. False Positive Rate (FPR)
5. Discussion
5.1. Using 10-Fold Cross Validation
5.2. Using Multiple Data Balancing Techniques
5.3. Evaluation with Multiple Evaluation Metrics
5.4. Overall Prospects
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gopal, B.G.; Kuppusamy, P.G. A comparative study on 4G and 5G technology for wireless applications. IOSR J. Electron. Commun. Eng. 2015, 10, 2278–2834. [Google Scholar]
- Piroșcă, G.I.; Șerban-Oprescu, G.L.; Badea, L.; Stanef-Puică, M.-R.; Valdebenito, C.R. Digitalization and labor market—A perspective within the framework of pandemic crisis. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 2843–2857. [Google Scholar] [CrossRef]
- Pandey, N.; Pal, A. Impact of digital surge during COVID-19 pandemic: A viewpoint on research and practice. Int. J. Inf. Manag. 2020, 55, 102171. [Google Scholar]
- Desolda, G.; Ferro, L.S.; Marrella, A.; Catarci, T.; Costabile, M.F. Human factors in phishing attacks: A systematic literature review. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Rupa, C.; Srivastava, G.; Bhattacharya, S.; Reddy, P.; Gadekallu, T.R. A machine learning driven threat intelligence system for malicious url detection. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–7. [Google Scholar]
- Aksu, D.; Turgut, Z.; Üstebay, S.; Aydin, M.A. Phishing analysis of websites using classification techniques. In Proceedings of the ITelCon 2017, Istanbul, Turkey, 28–29 December 2017; Springer: Singapore, 2019; pp. 251–258. [Google Scholar]
- Naveen, I.N.V.D.; Manamohana, K.; Verma, R. Detection of malicious URLs using machine learning techniques. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 389–393. [Google Scholar]
- Vanitha, N.; Vinodhini, V. Malicious-url detection using logistic regression technique. Int. J. Eng. Manag. Res. 2019, 9, 108–113. [Google Scholar]
- Kaddoura, S. Classification of malicious and benign websites by network features using supervised machine learning algorithms. In Proceedings of the 2021 5th Cyber Security in Networking Conference (CSNet), Abu Dhabi, United Arab Emirates, 12–14 October 2021; pp. 36–40. [Google Scholar]
- Odeh, A.; Keshta, I.; Abdelfattah, E. Machine learningtechniquesfor detection of website phishing: A review for promises and challenges. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Virtual, 27–30 January 2021; pp. 813–818. [Google Scholar]
- Chaganti, S.Y.; Nanda, I.; Pandi, K.R.; Prudhvith, T.G.; Kumar, N. Image classification using SVM and CNN. In Proceedings of the 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 13–14 March 2020; pp. 1–5. [Google Scholar]
- Singh, N.; Chaturvedi, S.; Akhter, S. Weather forecasting using machine learning algorithm. In Proceedings of the 2019 International Conference on Signal Processing and Communication (ICSC), Noida, India, 7–9 March 2019; pp. 171–174. [Google Scholar]
- Gegic, E.; Isakovic, B.; Keco, D.; Masetic, Z.; Kevric, J. Car price prediction using machine learning techniques. TEM J. 2019, 8, 113. [Google Scholar]
- Vijh, M.; Chandola, D.; Tikkiwal, V.A.; Kumar, A. Stock closing price prediction using machine learning techniques. Procedia Comput. Sci. 2020, 167, 599–606. [Google Scholar] [CrossRef]
- Alfeilat, H.A.A.; Hassanat, A.B.A.; Lasassmeh, O.; Tarawneh, A.S.; Alhasanat, M.B.; Salman, H.S.E.; Prasath, V.B.S. Effects of distance measure choice on k-nearest neighbor classifier performance: A review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef] [Green Version]
- Zendehboudi, A.; Baseer, M.A.; Saidur, R. Application of support vector machine models for forecasting solar and wind energy resources: A review. J. Clean. Prod. 2018, 199, 272–285. [Google Scholar] [CrossRef]
- Charbuty, B.; Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Christodoulou, E.; Ma, J.; Collins, G.S.; Steyerberg, E.W.; Verbakel, J.Y.; van Calster, B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J. Clin. Epidemiol. 2019, 110, 12–22. [Google Scholar] [CrossRef] [PubMed]
- Halimaa, A.; Sundarakantham, K. Machine learning based intrusion detection system. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 916–920. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A systematic review on imbalanced data challenges in machine learning: Applications and solutions. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Cham, Switzerland, 2018; Volume 10. [Google Scholar]
- Brandt, J.; Lanzén, E. A Comparative Review of SMOTE and ADASYN in Imbalanced Data Classification. Bachelor’s Thesis, Uppsala University, Uppsala, Sweden, 2021. [Google Scholar]
- Singhal, S.; Chawla, U. Machine learning & concept drift based approach for malicious website detection. In Proceedings of the 2020 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bengaluru, India, 7–11 January 2020; pp. 2020–2023. [Google Scholar]
- Amrutkar, C.; Kim, Y.S.; Traynor, P.; Member, S. Detecting mobile malicious webpages in real time. IEEE Trans. Mob. Comput. 2017, 16, 2184–2197. [Google Scholar] [CrossRef]
- Iv, J.M. A comprehensive evaluation of HTTP header features for detecting malicious websites. In Proceedings of the 2019 15th European Dependable Computing Conference (EDCC), Naples, Italy, 17–20 September 2019. [Google Scholar] [CrossRef]
- Patil, D.R.; Patil, J.B. Malicious URLs detection using decision tree classifiers and majority voting technique. Cybern. Inf. Technol. 2018, 18, 11–29. [Google Scholar] [CrossRef] [Green Version]
- Al-milli, N. A Convolutional neural network model to detect illegitimate URLs. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 220–225. [Google Scholar]
- Jayakanthan, N.; Ramani, A.V.; Ravichandran, M. Two phase classification model to detect malicious URLs. Int. J. Appl. Eng. Res. 2017, 12, 1893–1898. [Google Scholar]
- Assefa, A.; Katarya, R. Intelligent phishing website detection using deep learning. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; pp. 1741–1745. [Google Scholar]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Evaluating deep learning approaches to characterize and classify malacious URL’s. J. Intell. Fuzzy Syst. 2022, 34, 1333–1343. [Google Scholar] [CrossRef]
- Vazhayil, A.; Vinayakumar, R.; Soman, K.P. Comparative study of the detection of malicious URLs using shallow and deep networks. In Proceedings of the 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–6. [Google Scholar]
- Somvanshi, M.; Chavan, P.; Tambade, S.; Shinde, S.V. A review of machine learning techniques using decision tree and support vector machine. In Proceedings of the 2016 International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 12–13 August 2016; pp. 1–7. [Google Scholar]
- More, A.S.; Rana, D.P. Review of random forest classification techniques to resolve data imbalance. In Proceedings of the 2017 1st International Conference on Intelligent Systems and Information Management (ICISIM), Aurangabad, India, 5–6 October 2017; pp. 72–78. [Google Scholar]
- Wang, Y. A multinomial logistic regression modeling approach for anomaly intrusion detection. Comput. Secur. 2005, 24, 662–674. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Deepa, N.; Prabadevi, B.; Maddikunta, P.K.; Gadekallu, T.R.; Baker, T.; Khan, M.A.; Tariq, U. An AI-based intelligent system for healthcare analysis using Ridge-Adaline Stochastic Gradient Descent Classifier. J. Supercomput. 2021, 77, 1998–2017. [Google Scholar] [CrossRef]
- Kumar, S.; Chong, I. Correlation analysis to identify the effective data in machine learning: Prediction of depressive disorder and emotion states. Int. J. Environ. Res. Public Health 2018, 15, 2907. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Breach Name | Date of Data Breach | Impact | Caused by |
|---|---|---|---|
| Ronin (Ethereum sidechain to power Axie Infinity) Breach | March 2022 | Looted over 540 million USD | Hackers (Lazarus Group, North Korea) |
| 0ktapus | August 2022 | Compromised at least 130 companies (including Cloudflare, Doordash, Mailchimp) | Extended Phishing Campaign |
| Uber Total Compromise | August 2022 | Complete access to Uber’s source code, internal databases, and more information by a hacker under the alias “teapotuberhacker” | Hacker with ties to Lapsus$ using purchased credentials and MFA fatigue attack |
| Lapsus$ hacking spree | February–March 2022 | Looted a terabyte of proprietary data (Nvidia) and blackmail the company. Leaked source codes and algorithms from Samsung. Temporarily brought down Ubisoft’s online gaming services. Partial source code released for Bing and Cortana, breaching Microsoft Inc. | Method not known |
| Neopets Breach | 19 July 2022 | Personal data of 69 million Neopets users including username, email addresses, date of birth, zip codes was released | Phishing attack |
| Author Name | Balanced Dataset | Model | Metric | Metric Value (Accuracy) |
|---|---|---|---|---|
| Singhal et al. [24] | Yes | Random forest, Gradient boosting, Decision trees, Deep neural networks. | Accuracy, Precision, Recall. | 96.4% |
| Patil et al. [25] | kAYO (self-Proposed) | Accuracy. | 90 % | |
| Iv et al. [26] | No (SMOTE) | Adaptive Boosting, Extra Trees, Random Forest, Gradient Boosting, Bagging Classifier, Logistic Regression, K-Nearest Neighbors. | Accuracy, False positive rate, False negative rate, AUC. | 89% |
| Patil et al. [27] | Yes | J48 decision tree, Simple CART, Random forest, Random tree, ADTree, REPTree. | Accuracy, False-positive rate, False-negative rate. | 99.29% |
| Al-milli et al. [28] | One-dimensional Convolutional Neural Network (1D-CNN) | Accuracy, ROC curve. | 94.31% | |
| Jayakanthan et al. [29] | Enhanced Probing Classification (EPCMU) for detection, Naïve Bayes. | |||
| Assefa et al. [30] | Auto-encoder, SVM, Decision trees. | Accuracy. | 91.24% | |
| Vinayakumar et al. [31] | Deep Learning. | Accuracy. | 99.96% | |
| Vazhayil et al. [32] | CNN-LSTM. | Accuracy. | 98% |
| Imbalanced Data | SMOTE | |||||||
| Model Name | TP | FP | FN | TN | TP | FP | FN | TN |
| Decision Tree | 440 | 20 | 23 | 51 | 396 | 36 | 21 | 486 |
| Random Forest | 454 | 6 | 25 | 49 | 407 | 25 | 7 | 500 |
| SVC | 460 | 0 | 74 | 0 | 281 | 151 | 277 | 230 |
| Logistic Regression | 449 | 0 | 50 | 24 | 454 | 6 | 74 | 0 |
| Stochastic Gradient Decent | 454 | 6 | 74 | 0 | 258 | 174 | 324 | 183 |
| Random Under Sampling | Random Over Sampling | |||||||
| Model Name | TP | FP | FN | TN | TP | FP | FN | TN |
| Decision Tree | 66 | 5 | 9 | 50 | 420 | 20 | 0 | 499 |
| Random Forest | 67 | 4 | 10 | 49 | 428 | 12 | 0 | 499 |
| SVC | 30 | 41 | 12 | 47 | 122 | 318 | 66 | 433 |
| Logistic Regression | 48 | 23 | 6 | 53 | 287 | 153 | 42 | 457 |
| Stochastic Gradient Decent | 0 | 71 | 0 | 59 | 202 | 238 | 221 | 278 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ul Hassan, I.; Ali, R.H.; Ul Abideen, Z.; Khan, T.A.; Kouatly, R. Significance of Machine Learning for Detection of Malicious Websites on an Unbalanced Dataset. Digital 2022, 2, 501-519. https://doi.org/10.3390/digital2040027
Ul Hassan I, Ali RH, Ul Abideen Z, Khan TA, Kouatly R. Significance of Machine Learning for Detection of Malicious Websites on an Unbalanced Dataset. Digital. 2022; 2(4):501-519. https://doi.org/10.3390/digital2040027
Chicago/Turabian StyleUl Hassan, Ietezaz, Raja Hashim Ali, Zain Ul Abideen, Talha Ali Khan, and Rand Kouatly. 2022. "Significance of Machine Learning for Detection of Malicious Websites on an Unbalanced Dataset" Digital 2, no. 4: 501-519. https://doi.org/10.3390/digital2040027
APA StyleUl Hassan, I., Ali, R. H., Ul Abideen, Z., Khan, T. A., & Kouatly, R. (2022). Significance of Machine Learning for Detection of Malicious Websites on an Unbalanced Dataset. Digital, 2(4), 501-519. https://doi.org/10.3390/digital2040027