2.1. Data Preparation
In this study, we considered one hundred and nine healthy adults who range in physical characteristics (e.g., height, weight, mass, age). We used two public databases that cumulatively provided 4079 full cycles of gait, and our own database, which provided 124 cycles of gait. Moissenet database [
13] used 51 participants, Horst database [
14] used 56 participants, and our database used 2 participants (See
Table A9). In our experiments we used a set of in-house developed 9-degrees of freedom orientation IMU sensor with a 3-axis magnetometer, 3-axis gyroscope, and 3-axis accelerometer that used the Madwick sensor-fusion algorithm to calculate angular displacement and wirelessly transmit the information to a remote host using the TCP protocol [
17,
22].
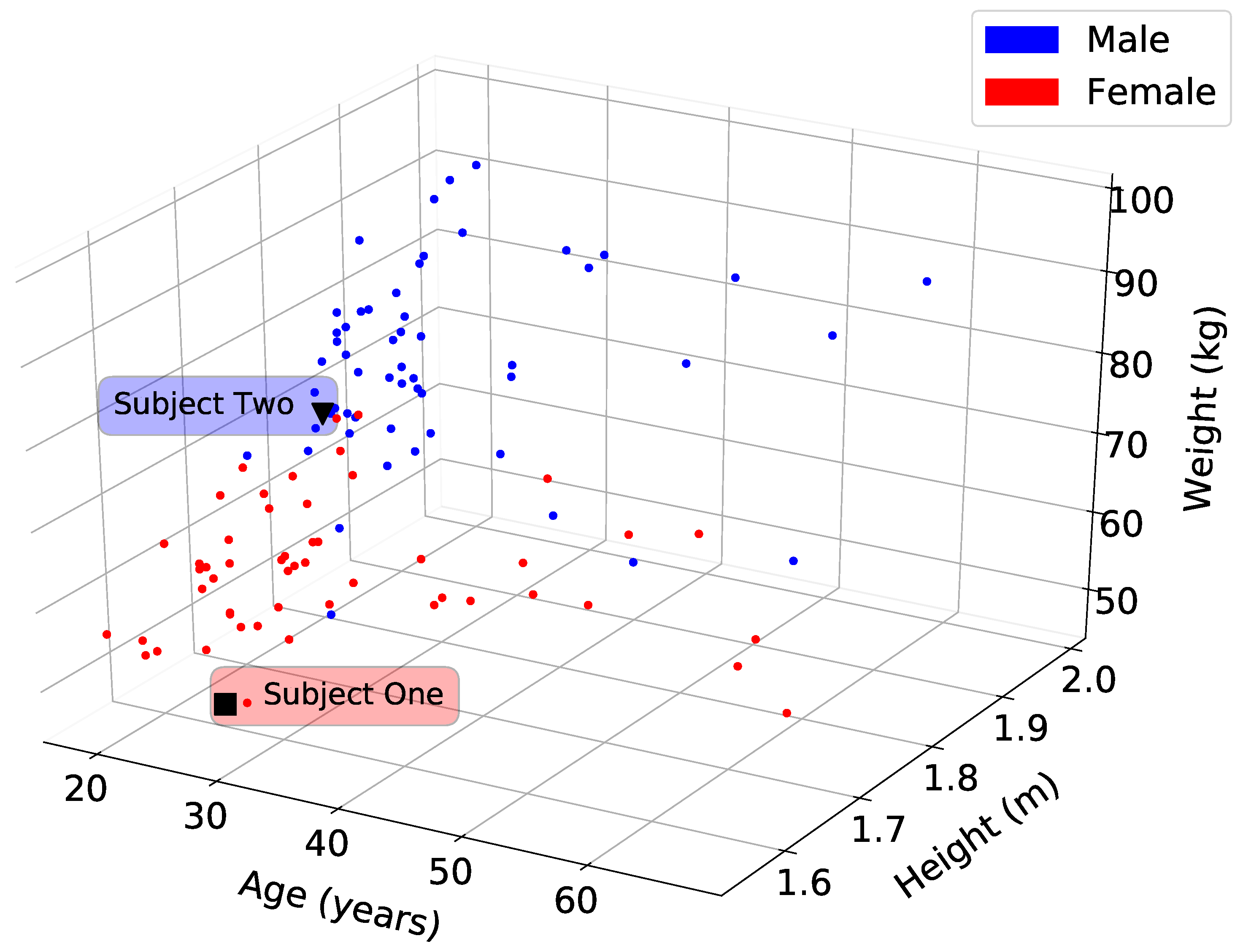
Figure 1 shows the correlation between the age, height, and weight for all of the participants.
Since each database had its unique recording strategy (e.g., different marker placement and different sampling rate), the experimental data were preprocessed using Algorithm 1 to include marker numbers, frames, samples, mass, gender, and height into a single matrix representing each subject’s biometrics [
23]. For example, the Moissenet and our own databases were sampled at 100 Hz, while the Horst database was recorded at 250 Hz. We downsampled Horst database to match the other two sets of data and generate a training data set that consists of over 700,000 samples at 100 Hz. It is important to note that the markers and their locations for both the Moissenet and Horst databases were interpreted by BioMechZoo solvers to output a joint angle relationship that yielded similar ranges of motion. Both of these databases included foot–ground reaction forces. We simulated the ground reaction force using “the simulated force plate” component available in OpenSim.
| Algorithm 1: Data Preparation Pipeline |
![Biomechanics 02 00006 i001]() |
The organization of the data structure for the recorded motion (
T) shown in Equation (
1), contains a Cartesian markers (
), frame number (
f), and individual trials or samples (
i).
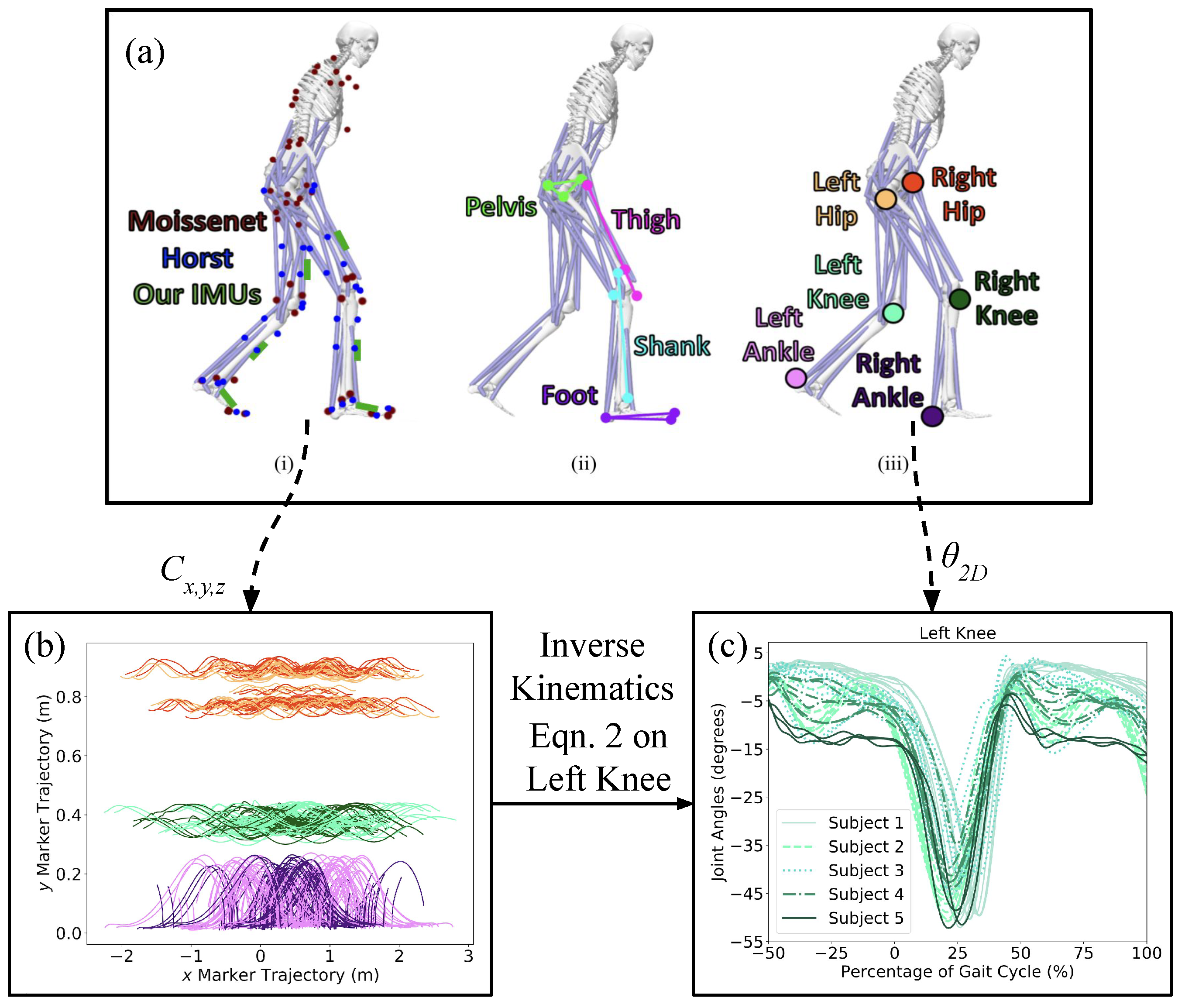
Figure 2 illustrates the process of extracting Cartesian coordinates from raw marker data and convert them into joint angles. This means that our system is capable accepting different sources of motion capture, and the pre-processing pipeline from Algorithm 1, we convert the data sets into a consistent parent–child joint angle relationship for all subjects. To clean up the data set, we scripted Equation (
2) to determine the joint angle representation along the sagittal plane (
Figure 3) for the lower extremity joints [
13,
14]. After the joint angles were found for all participants, we verified the alignment for all calculated joint angles to ensure they are in the same range of motion.
In some cases there exists multiple trials of the same subject, but in the event the participant changed, all of the subjects attributes (
S): gender (
g), mass (
m), height (
h), and age (
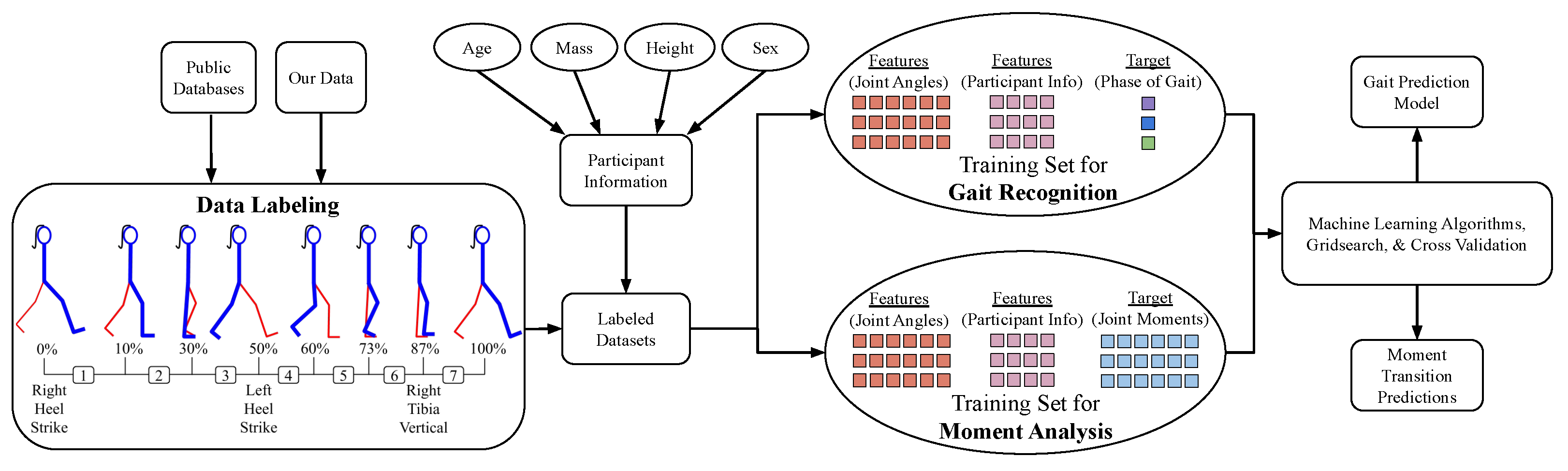
a) were assigned as a new person. After the data sets have been labeled for phase of gait (
P), subject attributes (
S), and joint angle kinematics (
), we transitioned into the process for training both the Gait Prediction and Moment Transition Predictions (
Figure 4).
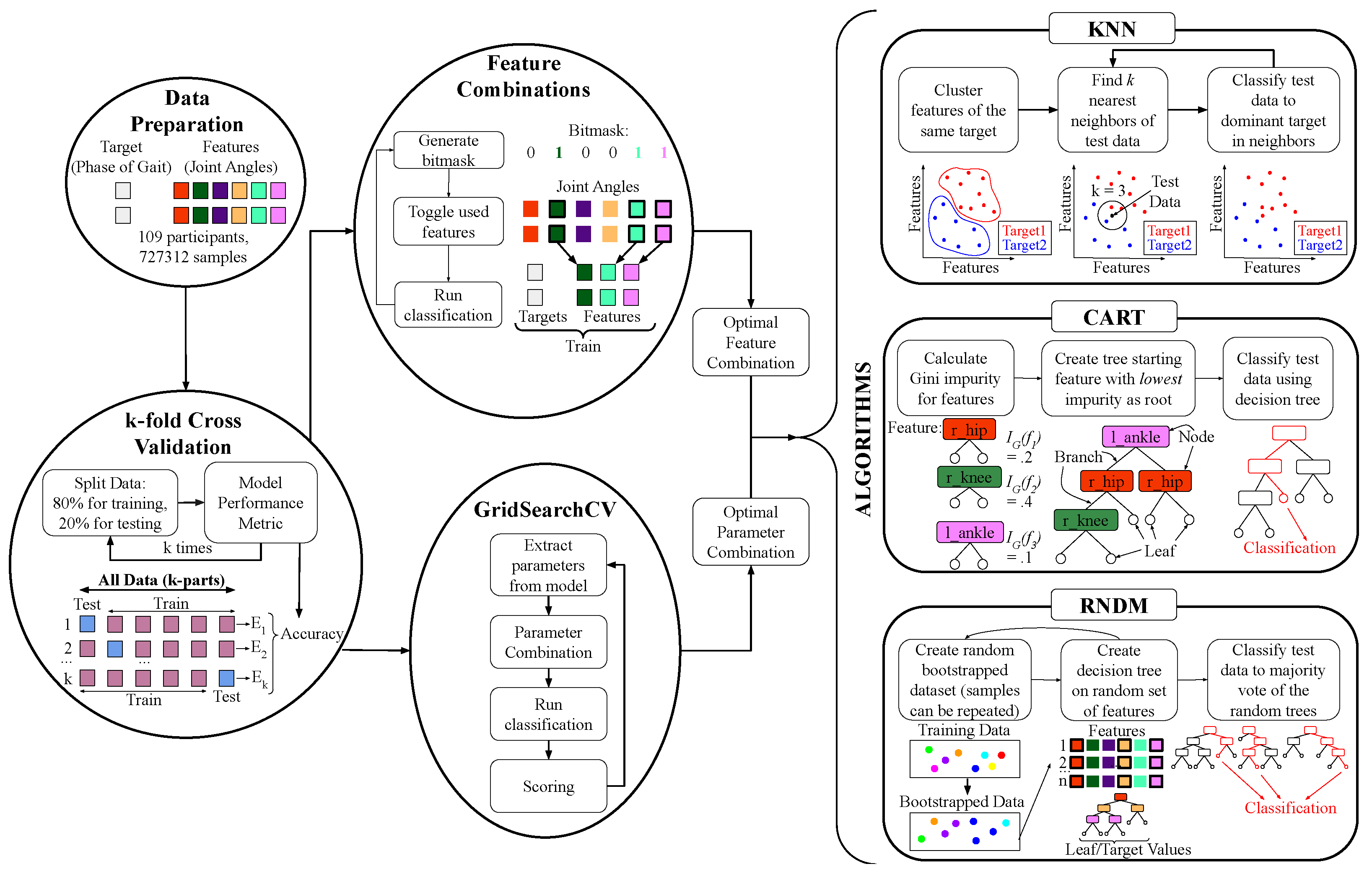
2.2. Classification Techniques and Algorithms
Machine learning automates the process of interpreting large sets of data to learn and make estimations [
24] as well as construct a model to perform data-driven classifications. One of the primary goals of this work was to create a model that can accurately predict the phase of gait using joint angles. The model is trained to find a correlation between the input
features (i.e., the observed and recorded input data) and the output
targets (i.e., different phases of gait). This correlation is used to calculate targets for stand-alone or unlabeled features. The accuracy of each model is evaluated by interpreting how well the correlation can be found by the algorithm to predict the target using the features with cross validation.
In this work we used cross-validation to quantify the performance of each model. We split a certain percentage of the labeled data to use as test data, while the remaining data was used to train a model [
25]. The training data is used as an input into the model, and the output was compared to its observed target to evaluate the accuracy against the other portion of the data set. Cross-validation iterates through the set of data multiple times, where each interval selects a different set of data samples to test, providing a more consistent performance metric of the entire model [
25]. The calculations from cross validation were used as a metric for accuracy to compare with the outputs of each model we train.
We used the
k-Nearest Neighbors (KNN) algorithm to classify the test features based on the most frequent phase of gait of their
k surrounding neighbors, or closest data samples [
26]. The parameter,
k, defines how many neighbors were used in each classification. A relatively larger
k results in a more accurate classification due to a larger scope of data. This reduces the effect of outliers and erroneous data for each prediction. The KNN algorithm has been used in other instances of training models for gait recognition based on different bio-mechanic features, including accelerometer data [
27], ground reaction forces [
28], and human gait shape analysis [
29].
To find the nearest neighbors of each test sample, we calculated the Euclidean distance,
D, between the feature sets of the test and already classified samples [
30]. Each feature can be represented as:
with
n representing the number of features in each sample, and every
representing one feature. A feature vector for one sample combines all relevant features for training:
The distance
D between the test feature set
x and the already classified feature set
y can be represented with the following formula:
where the iterator,
i, increments for every feature used to train the model [
30]. Equation (
4) was evaluated for all training data samples,
y. The number of samples (
k) used in the training data set with the smallest distance (
D) was selected as the test sample’s
k nearest neighbors. The mode target value, or most frequent phase of gait within the selected neighbors, was used as the classification of the test sample
x (
Figure 5) [
26]. This process was repeated to predict a phase of gait for each test feature set. Cross-validation repeats until all 10 folds and splits are iterated and completed. Generally, as
k increases, the accuracy of the prediction increases as more data points are considered for the final classification. Decreasing
k heightens the effect of inaccurate data on classifications; the balance for an ideal value of
k is described using GridSearch. GridSearch finds specified parameter values through an exhaustive search process [
31]. It sorts through all possible combinations of each parameter and finds the optimal values (
Table A1). Both GridSearch and feature extraction optimize the parameters of our model and the features considered to heighten the efficiency of our model for training.
We used GridSearch to programmatically iterate through different combinations of parameter values (
Table A1) to find the ideal values to run the model with [
32]. When applied to the KNN algorithm, it varies the number of neighbors in each classification,
k, to find a balance between the model over-fitting and under-fitting our data. If the number of neighbors was small, the effect of noise on the classification become larger since the model only learned from a small subset of neighbor samples. When outliers heavily influence the model, we notice a bias towards the minor details of the data (over-fitting) rather than finding a general trend [
33]. However if
k is large, we notice the opposite since every test sample will be classified to the target (under-fitting). This happens to be more frequent than a smaller
k in the overall training set, ignoring underlying trends in the data [
33]. Finding a balance of the value of
k is crucial to achieve an accurate and precise model.
We used the Classification And Regression Trees (CART) algorithm to focus on creating a decision tree that classifies the test samples [
34]. Decision trees are commonly used in many situations where supervised learning is practical: forming gait pattern models using other features such as inhibitory factors of an injury [
35], contact forces and angular velocity [
36], as well as step length, walking speed, and stride time [
37].
Each tree consists of nodes, branches, and leaves. Nodes are known as a “decision”, or a comparison or split made on a specific feature in the data set. Branches are the outcome of the decision made by the node. A leaf is a node at the end of the tree that does not have branches extending from it. It is important to note that leaf nodes do not make decisions. Each leaf represents a target or a specific phase of gait. When making a classification, the data presented in our test feature set compares each node by traversing along the corresponding branches until it reaches a leaf node [
34].
When training quantitative data, each node splits at a specific feature value. In our case, a node concerning right hip angles could split at
. This creates the left branch at
for the right hip node, and
for the right branch. The ideal split yields both branches as a completely homogeneous pool of data points with the same target. Each branch splits into more nodes until every leaf node is either a product of a perfect split or until the tree reaches the maximum depth or width as specified by the parameters. The Gini impurity (I) is a quantitative measure of how accurate a split is. Ideal splits have a Gini impurity value of 0 [
38], and is calculated as follows:
where
t = 7 is the number of targets, and
is the probability of selecting a data point with target
i within the entire data set.
The feature with the smallest Gini impurity is chosen as the root of the tree. In other words, if we randomly classified according to the target distribution of the data set, the feature with the smallest possibility of incorrect classification is the root (see
Figure 5) [
39]. Once we select a feature as the root node and splits according to the smallest Gini impurity value, choosing the next node and split is repeated with the data subset of each branch until a complete tree has formed. As seen in
Figure 5, our classification in a decision tree followed the splits made by the nodes for a test feature set until a leaf node, or target, is reached.
The parameters of maximum depth and width of a decision tree prevent the common problem of overfitting in decision trees [
34]. Suppose we let the tree grow until every split reaches an impurity of 0. In that case, every feature set likely traces a unique path to an individual leaf node due to noise in the data, making the classification overfitted and heavily affected by every outlier. To prevent this, we restrict the number of splits and nodes through a tree’s maximum depth and width. GridSearch iterates through different threshold values, so the parameter values shown in
Table A1 avoid underfitting and overfitting.
The random forest (RNDM) algorithm uses many different decision trees, as constructed in the CART algorithm, to create a forest [
40]. The most frequent classification made among all the decision trees in the forest is the classification of test data points [
40]. The logic behind using a forest of trees formed by randomly selected data samples and features is that the entire forest will have a low correlation between each tree. The product of uncorrelated models is far more accurate than any individual prediction. Similar to the wisdom of crowds, trees with erroneous data are protected by a more significant amount of trees with more accurate models.
We began the random forest algorithm developing each decision tree by creating a bootstrapped data set as portrayed in
Figure 5 [
40]. With repetition, a set of data samples randomly selected from the entire data set is the bootstrapped data set that will form our tree. Every bootstrapped data set has the same number of samples as the entire data set, so that most bootstrapped sets include the repetition of random samples.
For each bootstrapped data set, decision trees were formed with a random selection of
m features. Typically
, with
n being the total number of features in the data set (
Figure 4). The process of creating a decision tree (Algorithm 2) uses each tree formed from calculating Gini impurity to determine the order of features as nodes and the optimal split per node. The process of building different bootstrapped data sets and creating decision trees with random subsets of features for each bootstrapped group repeats until the maximum number of trees
t is reached. When classifying a test sample with the random forest algorithm, a test feature set serves an an input into all the decision trees in the forest. The most frequent target output of the trees is the classification derived from the test data.
The random forest algorithm is optimized using the parameters
m, the number of features used in each tree, and
t, the number of trees in a forest (
Table A1). A GridSearch through both these parameters usually reveals an increase in accuracy with the typically selected value of
m =
, and a larger
t to account for more significant variation in datasets. GridSearch is essential to prevent underfitting and overfitting in the RNDM algorithm due to the randomness of sample and feature selection.
| Algorithm 2: Classification of phase of gait in relation to joint angles using Random Forest. |
![Biomechanics 02 00006 i002]() |
2.4. Algorithm Applications
The classification algorithms (KNN, CART, Random forest) use the feature set that included joint angles (right and left hip, knee, and ankle) and participant information (e.g., height, mass, gender, age). Our feature set comprises 10 individual features, 6 joint angles, and 4 participant attributes. The target is the individual phase of gait for each data sample. We employ a 10-fold cross-validation and a 20/80 train–test split across all models when evaluating accuracy. The data is iterated 10 separate times during cross-validation to evaluate the accuracy. Each iteration selects a different 20% portion of the data set to reserve as sample test data points while the other 80% is selected as training data for the model.
Before selecting specific algorithms to use, we bench-marked the mean accuracy (with the standard deviation) in
Table A5 using cross-validation on 10-fold experiments for a sample set employing all available features to help us narrow our chosen algorithms to KNN, CART, and RNDM. It is important to note that the parameters found from cross-validation and GridSearch mentioned in the previous sections were consistent for all feature combinations. The Naive Bayes (NB) and Support Vector Machine (SVM) algorithm produced models with relatively low accuracy compared to the other algorithms. As a linear classifier, the NB algorithm was unfit for our human gait classification with natural variances. The inefficiency of the SVM classifier with the Radial Basis Function (RBF) kernel and its proneness to over-fitting given larger data sets makes it unsuitable for training our model, and its shortcomings are prevalent in a 22% average decrease in accuracy compared to the algorithms we employed (
Table A5). In addition, this SVM algorithm is particularly sensitive to noise, which makes it unsuitable for classifying our data with human variation. Therefore, we chose a final selection of the KNN, CART, and Random forest algorithms for our phase of gait prediction.
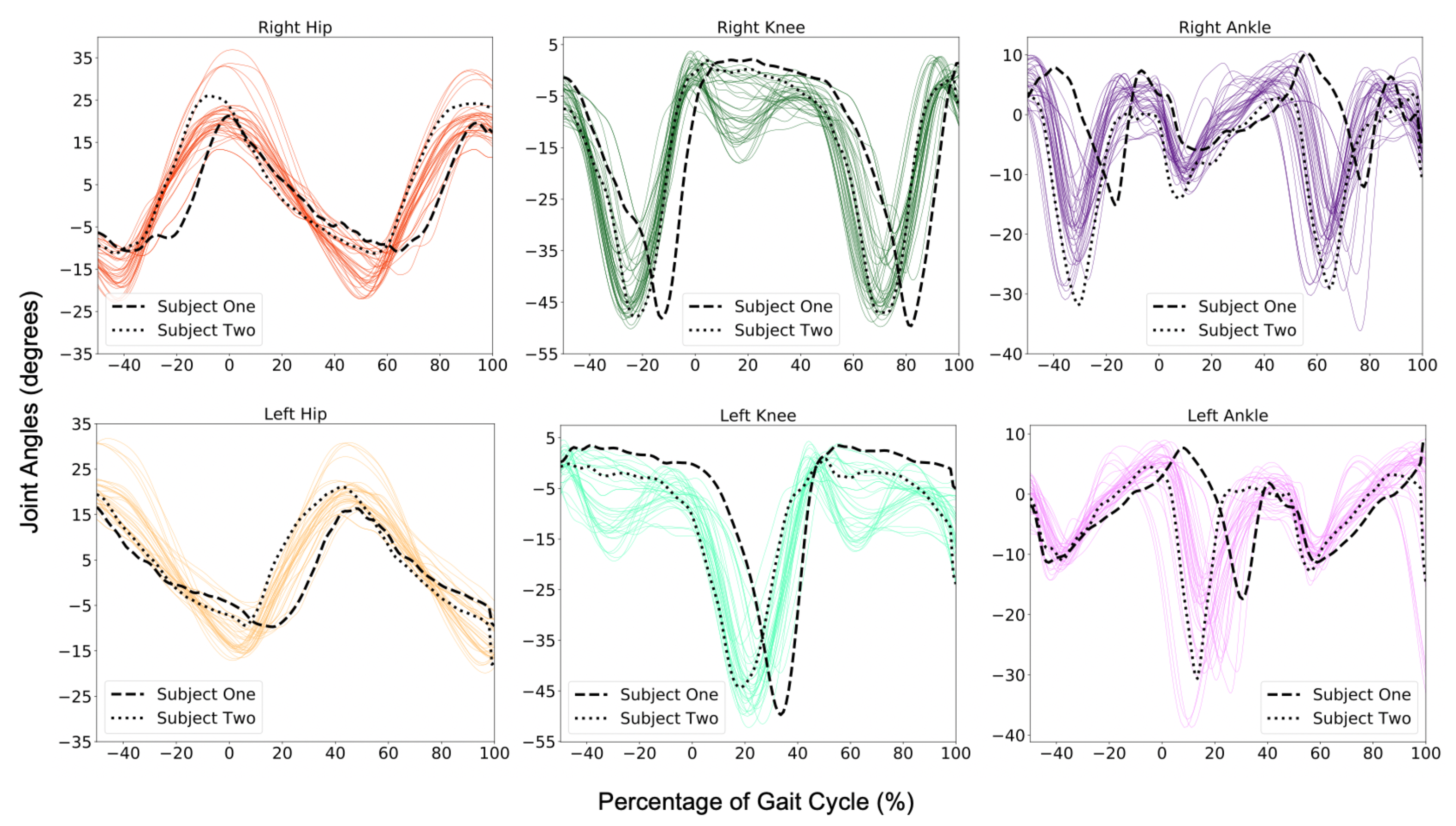
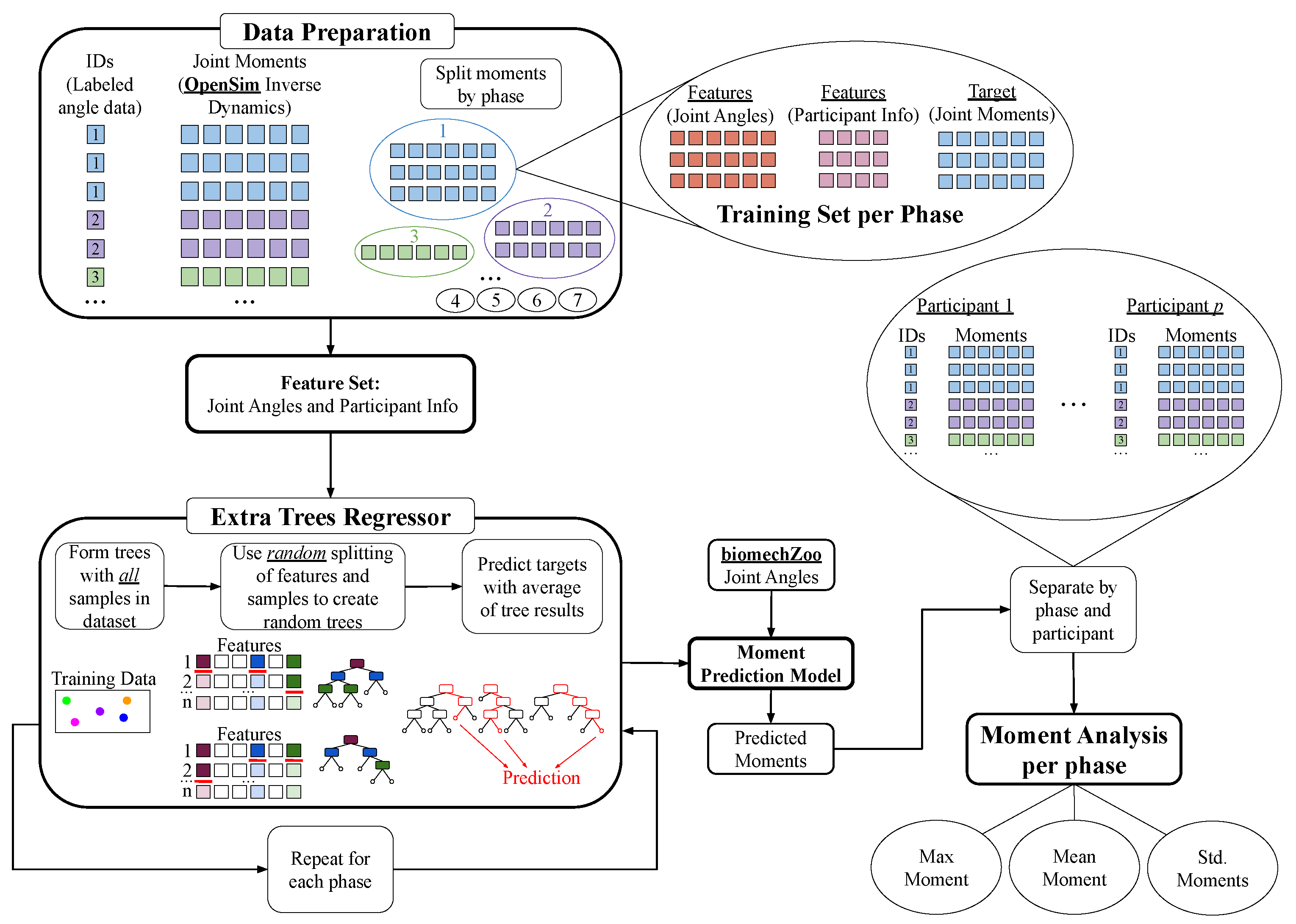
Since joint moments are only calculated for the subset of .mot data processed through OpenSim, we use regression techniques to roughly predict the moments corresponding to the joint angles from the .c3d files. In this scenario, the joint angles and participant information are the features, while we have a multi-class target: the moments for each of the six joints. By calculating moments for every test sample, we observed the trends of joint moments over each phase to approximate the maximum moment needed to move from one phase to the next, an addition to our overall gait pattern model.
To predict joint moments from the joint angles extracted from
.c3d files, we created a model with the extra trees regressor using joint angles and moments from OpenSim. Our features were joint angles and participant information, and our targets were joint moments. A separate model was created for each phase, as seen in
Figure 6. The regression accuracy calculated by cross-validation for each model is recorded in
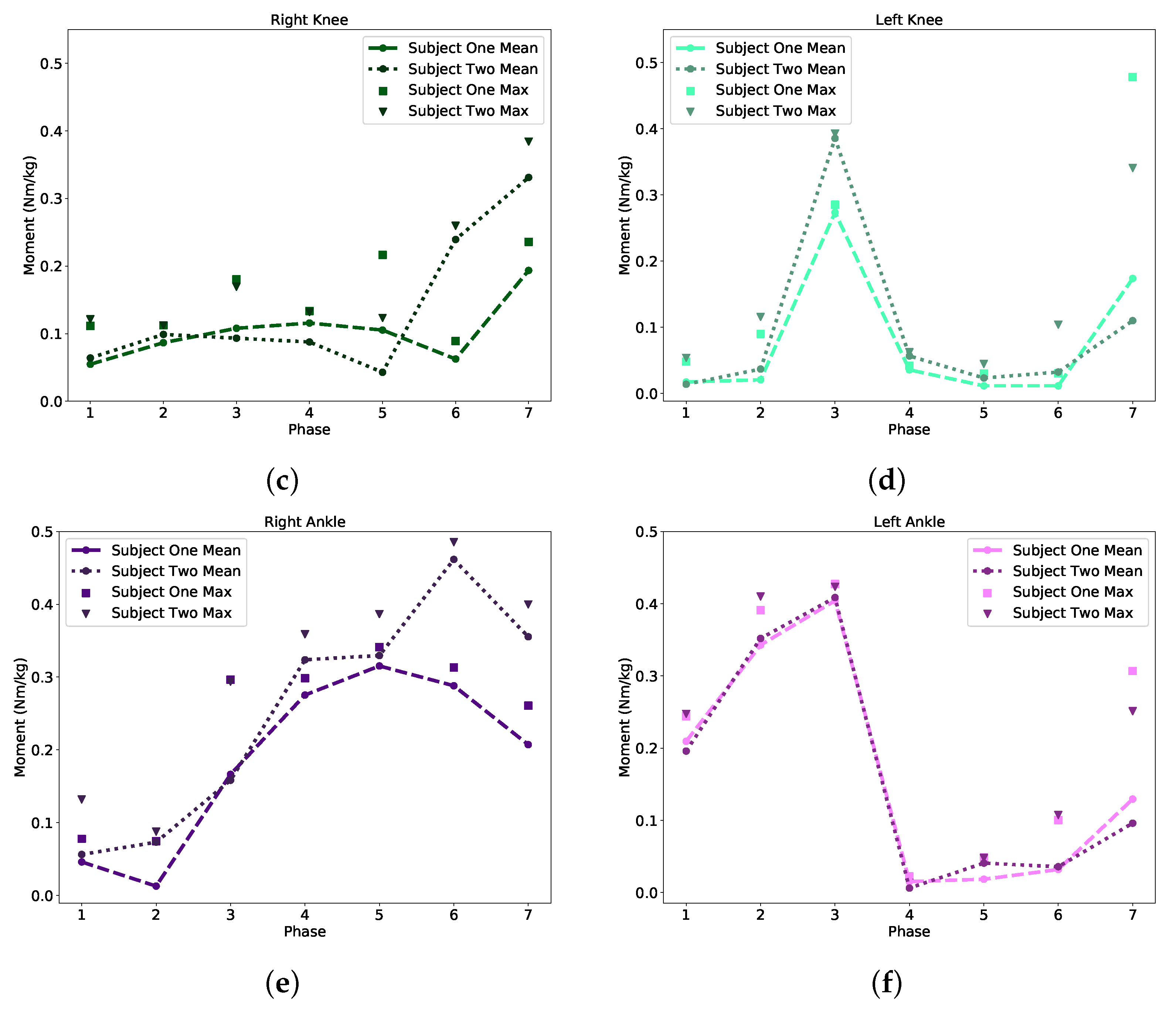
Table A7, where each model’s coefficient of determination exceeds 0.5, meaning each model accounts for a majority of the variance of the outputted moments. For this application, where joint angle trends varied greatly with each participant and even between each gait cycle, the extra trees outperformed all other regression algorithms due to the randomness in splitting nodes to smooth noise in the data set. It is important to note that due to the variance of subjects’ physical characteristics (i.e., subjects can be very small to large), the regression accuracy per phase may seem lower than normal. This does not affect the system’s ability to take physical characteristics and derive a estimation on required moments to transition between phases of gait.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
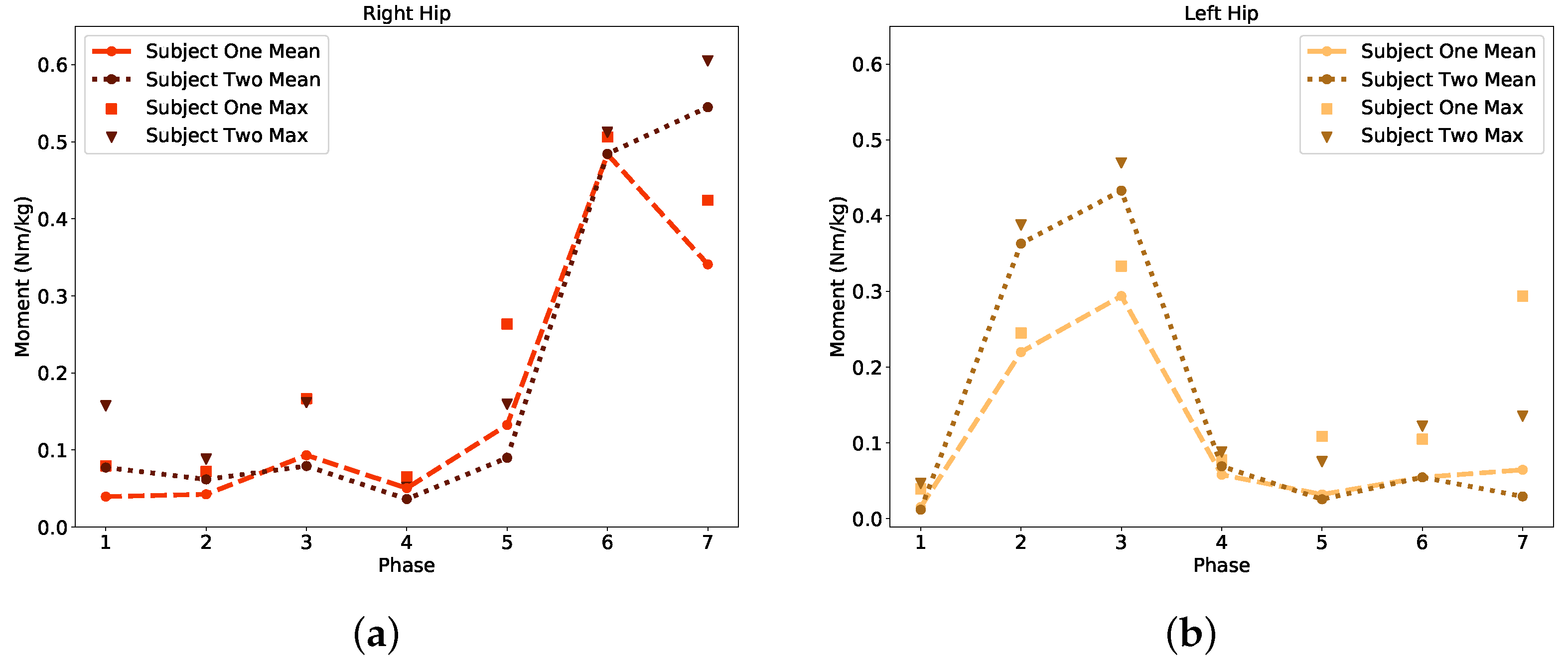{kind=link}
{kind=link}








