
Analysis of the Impact of Positional Accuracy When Using a Block of Pixels for Thematic Accuracy Assessment



Abstract
:1. Introduction
2. Methods
2.1. Reference Data Collection with Positional Errors
2.2. Determine the Size and Label of a Block as an Assessment Unit
2.3. Thematic Accuracy Assessment and Positional Effect Analysis
3. Study Area and Experiment
3.1. Study Area
3.2. Classification Maps
3.3. Reference Data with Positional Errors
3.4. Accuracy Assessment and Analysis
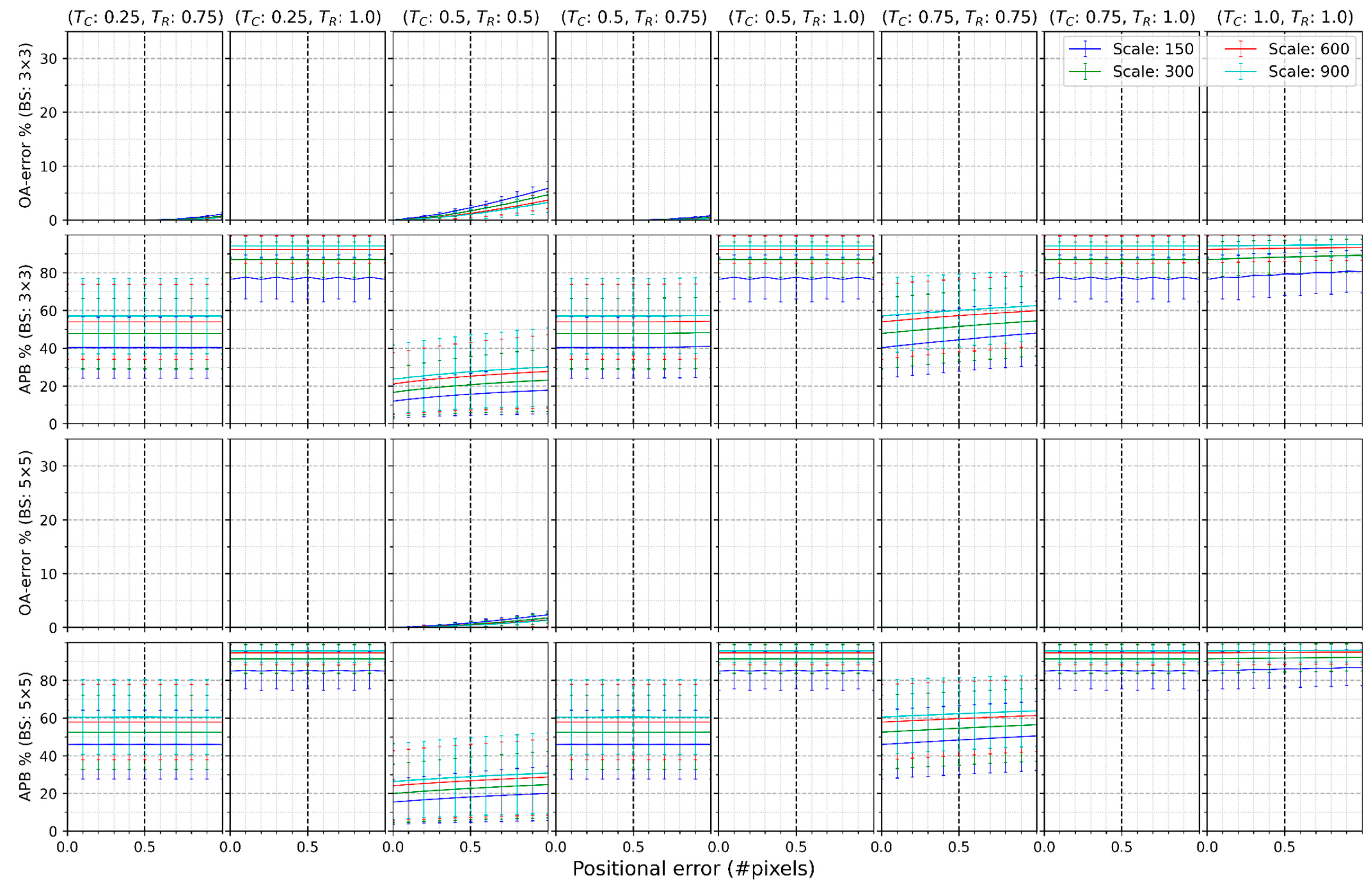
4. Results
5. Discussion
6. Conclusions
- (1)
- Labeling thresholds greater or equal to 0.75 are not a good choice for determining a block’s label. A labeling threshold equal to 0.5 applies to a higher spatial scale with lower heterogeneity. A labeling threshold less than 0.25 is appropriate for most remote sensing applications.
- (2)
- Blocks with the size of 5 × 5 pixels remove, on average, around 2% more positional error compared with a 3 × 3 pixel block. However, it may not be practical to collect reference samples of this size if the reference data are collected by field survey.
- (3)
- The in most land cover mapping projects except IGBP and UMD can be reduced to under 10% if using 3 × 3 pixel blocks with the labeling threshold being less than 0.25.
- (4)
- The in most remote-sensing applications achieving half-pixel registration is under 10% if using a 3 × 3 pixel block with labeling threshold being less than 0.25.
- (5)
- More chasses in a classification scheme or higher heterogeneity increase the positional effect.
- (6)
- Further research can focus on how to sample blocks based on the proportion or structure of the blocks.
Author Contributions
Funding
Conflicts of Interest
References
- Wulder, M.A.; Coops, N.C.; Roy, D.P.; White, J.C.; Hermosilla, T. Land cover 2.0. Int. J. Remote Sens. 2018, 39, 4254–4284. [Google Scholar] [CrossRef] [Green Version]
- Estes, L.; Chen, P.; Debats, S.; Evans, T.; Ferreira, S.; Kuemmerle, T.; Ragazzo, G.; Sheffield, J.; Wolf, A.; Wood, E.; et al. A large-area, spatially continuous assessment of land cover map error and its impact on downstream analyses. Glob. Chang. Biol. 2018, 24, 322–337. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Wang, Y.; Wang, R.; Zheng, P. Modeling and evaluating land-use/land-cover change for urban planning and sustainability: A case study of Dongying city, China. J. Clean. Prod. 2018, 172, 1529–1534. [Google Scholar] [CrossRef]
- Zaldo-Aubanell, Q.; Serra, I.; Sardanyés, J.; Alsedà, L.; Maneja, R. Reviewing the reliability of Land Use and Land Cover data in studies relating human health to the environment. Environ. Res. 2021, 194, 110578. [Google Scholar] [CrossRef]
- Bartholomé, E.; Belward, A.S. GLC2000: A new approach to global land cover mapping from Earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Gray, J.; Abercrombie, S.P.; Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The MODIS Collection 6 Land Cover product. Remote Sens. Environ. 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC: Boca Raton, FL, USA, 2019. [Google Scholar]
- Sylvander, S.; Henry, P.; Bastin-thiry, C.; Meunier, F.; Fuster, D. VEGETATION geometrical image quality. Bull. de la Société Française de Photogrammétrie et de Télédétection 2000, 159, 59–65. [Google Scholar]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Congalton, R.; Oderwald, R.G.; Mead, R. Assessing Landsat classification accuracy using discrete multivariate analysis statistical techniques. Photogramm. Eng. Remote Sens. 1983, 49, 1671–1678. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Stehman, S.V.; Czaplewski, R.L. Design and Analysis for Thematic Map Accuracy Assessment: Fundamental Principles. Remote Sens. Environ. 1998, 64, 331–344. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Foody, G.M. Assessing the accuracy of land cover change with imperfect ground reference data. Remote Sens. Environ. 2010, 114, 2271–2285. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G. Thematic and positional accuracy assessment of digital remotely sensed data. In Proceedings of the 7th Annual Forest Inventory and Analysis Symposium, Portland, ME, USA, 3–6 October 2005. [Google Scholar]
- Stehman, S.V. Sampling Designs for Assessing Map Accuracy. In Proceedings of the 8th International Symposium on Spatial Accuracy Assessment in Natural Resources and Environmental Sciences, Shanghai, China, 25–27 June 2008. [Google Scholar]
- Giri, C.; Pengra, B.; Long, J.; Loveland, T. Next generation of global land cover characterization, mapping, and monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 30–37. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Janssen, L.L.F.; Vanderwel, F.J.M. Accuracy assessment of satellite-derived land-cover data-a review. Photogramm. Eng. Remote Sens. 1994, 60, 419–426. [Google Scholar]
- Richards, J.A. Classifier performance and map accuracy. Remote Sens. Environ. 1996, 57, 161–166. [Google Scholar] [CrossRef]
- Morales-Barquero, L.; Lyons, M.B.; Phinn, S.R.; Roelfsema, C.M. Trends in Remote Sensing Accuracy Assessment Approaches in the Context of Natural Resources. Remote Sens. 2019, 11, 2305. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Congalton, R. Analysis of the Impact of Positional Accuracy When Using a Single Pixel for Thematic Accuracy Assessment. Remote Sens. 2020, 12, 4093. [Google Scholar] [CrossRef]
- Gu, J.; Congalton, R.G.; Pan, Y. The Impact of Positional Errors on Soft Classification Accuracy Assessment: A Simulation Analysis. Remote Sens. 2015, 7, 579–599. [Google Scholar] [CrossRef] [Green Version]
- Powell, R.; Matzke, N.; de Souza, C.; Clark, M.; Numata, I.; Hess, L.; Roberts, D. Sources of error in accuracy assessment of thematic land-cover maps in the Brazilian Amazon. Remote Sens. Environ. 2004, 90, 221–234. [Google Scholar] [CrossRef]
- Brown, K.M.; Foody, G.M.; Atkinson, P.M. Modelling geometric and misregistration error in airborne sensor data to enhance change detection. Int. J. Remote Sens. 2007, 28, 2857–2879. [Google Scholar] [CrossRef]
- Yang, K.; Pan, A.; Yang, Y.; Zhang, S.; Ong, S.H.; Tang, H. Remote Sensing Image Registration Using Multiple Image Features. Remote Sens. 2017, 9, 581. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Dan, T.; Yang, Y. Multi-Temporal Remote Sensing Image Registration Using Deep Convolutional Features. IEEE Access 2018, 6, 38544–38555. [Google Scholar] [CrossRef]
- Beekhuizen, J.; Heuvelink, G.B.M.; Biesemans, J.; Reusen, I. Effect of DEM Uncertainty on the Positional Accuracy of Airborne Imagery. IEEE Trans. Geosci. Remote Sens. 2010, 49, 1567–1577. [Google Scholar] [CrossRef]
- Plourde, L.; Congalton, R.G. Sampling method and sample placement: How do they affect the accuracy of remotely sensed maps? Photogramm. Eng. Remote Sens. 2003, 69, 289–297. [Google Scholar] [CrossRef]
- Stehman, S.V.; Wickham, J.D. Pixels, blocks of pixels, and polygons: Choosing a spatial unit for thematic accuracy assessment. Remote Sens. Environ. 2011, 115, 3044–3055. [Google Scholar] [CrossRef]
- Carmel, Y. Controlling Data Uncertainty via Aggregation in Remotely Sensed Data. IEEE Geosci. Remote Sens. Lett. 2004, 1, 39–41. [Google Scholar] [CrossRef]
- Carmel, Y. Aggregation as a Means of Increasing Thematic Map Accuracy. In GeoDynamics; CRC Press: Boca Raton, FL, USA, 2004; pp. 29–38. [Google Scholar]
- Clinton, N.; Holt, A.; Scarborough, J.; Yan, L.; Gong, P. Accuracy Assessment Measures for Object-based Image Segmentation Goodness. Photogramm. Eng. Remote Sens. 2010, 76, 289–299. [Google Scholar] [CrossRef]
- Ye, S.; Pontius, R.G.; Rakshit, R. A review of accuracy assessment for object-based image analysis: From per-pixel to per-polygon approaches. ISPRS J. Photogramm. Remote Sens. 2018, 141, 137–147. [Google Scholar] [CrossRef]
- Huang, Z.; Lees, B. Assessing a single classification accuracy measure to deal with the imprecision of location and class: Fuzzy weighted kappa versus kappa. J. Spat. Sci. 2007, 52, 1–12. [Google Scholar] [CrossRef]
- Latifovic, R.; Olthof, I. Accuracy assessment using sub-pixel fractional error matrices of global land cover products derived from satellite data. Remote Sens. Environ. 2004, 90, 153–165. [Google Scholar] [CrossRef]
- Yadav, K.; Congalton, R.G. Issues with Large Area Thematic Accuracy Assessment for Mapping Cropland Extent: A Tale of Three Continents. Remote Sens. 2017, 10, 53. [Google Scholar] [CrossRef] [Green Version]
- Hammond, T.O.; Verbyla, D.L. Optimistic bias in classification accuracy assessment. Int. J. Remote Sens. 1996, 17, 1261–1266. [Google Scholar] [CrossRef]
- Dai, X.; Khorram, S. The effects of image misregistration on the accuracy of remotely sensed change detection. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1566–1577. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Zhao, K.; Powers, R. Assessment of the image misregistration effects on object-based change detection. ISPRS J. Photogramm. Remote Sens. 2014, 87, 19–27. [Google Scholar] [CrossRef]
- Gerçek, D.; Cesmeci, D.; Gullu, M.K.; Erturk, A.; Erturk, S. An automated fine registration of multisensor remote sensing imagery. 2012 IEEE Int. Geosci. Remote Sens. Symp. 2012, 1361–1364. [Google Scholar] [CrossRef]
- Dong, Y.; Long, T.; Jiao, W.; He, G.; Zhang, Z. A Novel Image Registration Method Based on Phase Correlation Using Low-Rank Matrix Factorization With Mixture of Gaussian. IEEE Trans. Geosci. Remote Sens. 2018, 56, 446–460. [Google Scholar] [CrossRef]
- Foody, G.M. Explaining the unsuitability of the kappa coefficient in the assessment and comparison of the accuracy of thematic maps obtained by image classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Warrens, M.J. Properties of the quantity disagreement and the allocation disagreement. Int. J. Remote Sens. 2015, 36, 1439–1446. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- McGarigal, K.; Marks, B.J. FRAGSTATS: Spatial Pattern Analysis Program for Quantifying Landscape Structure; General Technical Reports; Department of Agriculture, Forest Service, Pacific Northwest Research Station: Portland, OR, USA, 1995; Volume 122, p. 351.
- Congalton, R.G.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global Land Cover Mapping: A Review and Uncertainty Analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef] [Green Version]
- Steffen, F.; Linda, S.; Ian, M.; Christian, S.; Michael, O.; Marijn van der, V.; Hannes, B.; Petr, H.; Frédéric, A. Highlighting continued uncertainty in global land cover maps for the user community. Environ. Res. Lett. 2011, 6, 044005. [Google Scholar]
- Gu, J.; Congalton, R.G. The Positional Effect in Soft Classification Accuracy Assessment. Am. J. Remote Sens. 2019, 7, 50. [Google Scholar] [CrossRef]
- McRoberts, R.E. The effects of rectification and Global Positioning System errors on satellite image-based estimates of forest area. Remote Sens. Environ. 2010, 114, 1710–1717. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Molinari, M.E.; Hussein, E.; Chen, J.; Li, R. The First Comprehensive Accuracy Assessment of GlobeLand30 at a National Level: Methodology and Results. Remote Sens. 2015, 7, 4191–4212. [Google Scholar] [CrossRef] [Green Version]
- Bicheron, P.; Amberg, V.; Bourg, L.; Petit, D.; Huc, M.; Miras, B.; Brockmann, C.; Hagolle, O.; Delwart, S.; Ranera, F.; et al. Geolocation Assessment of MERIS GlobCover Orthorectified Products. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2972–2982. [Google Scholar] [CrossRef]
- Sylvander, S.; Albert-Grousset, I.; Henry, P. Geometrical performance of the VEGETATION products. In Proceedings of the IGARSS 2003, 2003 IEEE International Geoscience and Remote Sensing Symposium, Proceedings (IEEE Cat. No.03CH37477), Toulouse, France, 21–25 July 2004; Institute of Electrical and Electronics Engineers (IEEE): Toulouse, France, 2004; Volume 571, pp. 573–575. [Google Scholar]
- Evelin, U.; Marc, A.A.; Jüri, R.; Riho, M.; Ülo, M. Landscape Metrics and Indices: An Overview of Their Use in Landscape Research. Living Rev. Landsc. Res. 2009, 5–14. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, J.; Lian, J.; Fan, Z.; Ouyang, X.; Ye, W. Seeing the forest from drones: Testing the potential of lightweight drones as a tool for long-term forest monitoring. Biol. Conserv. 2016, 198, 60–69. [Google Scholar] [CrossRef]
- Ren, X.; Sun, M.; Jiang, C.; Liu, L.; Huang, W. An Augmented Reality Geo-Registration Method for Ground Target Localization from a Low-Cost UAV Platform. Sensors 2018, 18, 3739. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| Class 1 | Class 2 | … | Class C | Sample Total | Population Total | ||
| Classification | Class 1 | n11 | n12 | … | n1C | n1+ | N1 |
| Class 2 | n21 | n22 | … | n2C | n2+ | N2 | |
| … | … | … | … | … | … | … | |
| Class C | nC1 | nC2 | … | nCC | nC+ | NC | |
| n+1 | n+2 | … | n+C | n | N | ||
| Accuracy measures | |||||||
| Level I | Class Name | Level II | Class Name | Original Level | Original Classification Scheme |
|---|---|---|---|---|---|
| 1 | Forest | 1 | Needleleaf | 1 | Temperate or sub-polar needleleaf forest |
| 2 | Sub-polar taiga needleleaf forest | ||||
| 2 | Broadleaf | 3 | Tropical or sub-tropical broadleaf evergreen forest | ||
| 4 | Tropical or sub-tropical broadleaf deciduous forest | ||||
| 5 | Temperate or sub-polar broadleaf deciduous forest | ||||
| 3 | Mixed | 6 | Mixed forest | ||
| 2 | Shrub | 4 | Shrub | 7 | Tropical or sub-tropical shrubland |
| 8 | Temperate or sub-polar shrubland | ||||
| 3 | Herbaceous | 5 | Grassland | 9 | Tropical or sub-tropical grassland |
| 10 | Temperate or sub-polar grassland | ||||
| 6 | Lichen-moss | 11 | Sub-polar or polar shrubland-lichen-moss | ||
| 12 | Sub-polar or polar grassland-lichen-moss | ||||
| 13 | Sub-polar or polar barren-lichen-moss | ||||
| 4 | Wetland | 7 | Wetland | 14 | Wetland |
| 5 | Cropland | 8 | Cropland | 15 | Cropland |
| 6 | Urban/Bare | 9 | Barren lands | 16 | Barren lands |
| 10 | Urban | 17 | Urban | ||
| 7 | Water | 11 | Water | 18 | Water |
| 0 | Background (Ocean) | ||||
| 12 | Snow and Ice | 19 | Snow and Ice |
| Level | Landscape Shape Index (LSI) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Site #1 | Site #2 | Site #3 | Site #4 | Site #5 | Site #6 | Site #7 | Site #8 | Site #9 | Site #10 | Site #11 | Site #12 | |
| I | 302.0 | 353.7 | 377.4 | 439.9 | 461.7 | 456.0 | 483.2 | 352.2 | 508.9 | 589.4 | 465.2 | 685.8 |
| II | 310.3 | 365.9 | 393.5 | 448.0 | 465.2 | 485.8 | 557.6 | 650.1 | 688.3 | 707.3 | 860.7 | 938.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Congalton, R.G. Analysis of the Impact of Positional Accuracy When Using a Block of Pixels for Thematic Accuracy Assessment. Geographies 2021, 1, 143-165. https://doi.org/10.3390/geographies1020009
Gu J, Congalton RG. Analysis of the Impact of Positional Accuracy When Using a Block of Pixels for Thematic Accuracy Assessment. Geographies. 2021; 1(2):143-165. https://doi.org/10.3390/geographies1020009
Chicago/Turabian StyleGu, Jianyu, and Russell G. Congalton. 2021. "Analysis of the Impact of Positional Accuracy When Using a Block of Pixels for Thematic Accuracy Assessment" Geographies 1, no. 2: 143-165. https://doi.org/10.3390/geographies1020009
APA StyleGu, J., & Congalton, R. G. (2021). Analysis of the Impact of Positional Accuracy When Using a Block of Pixels for Thematic Accuracy Assessment. Geographies, 1(2), 143-165. https://doi.org/10.3390/geographies1020009