Author Contributions
Conceptualization, Y.Y.; Methodology, Y.B.; Formal analysis, Y.Y. and Y.B.; Investigation, Y.Y.; Resources, Y.Y.; Data curation, Y.B.; Writing—original draft, Y.B.; Writing—review and editing, Y.B.; Visualization, Y.B.; Supervision, Y.Y.; Project administration, Y.Y.; Funding acquisition, Y.Y. All authors have read and agreed to the published version of the manuscript.
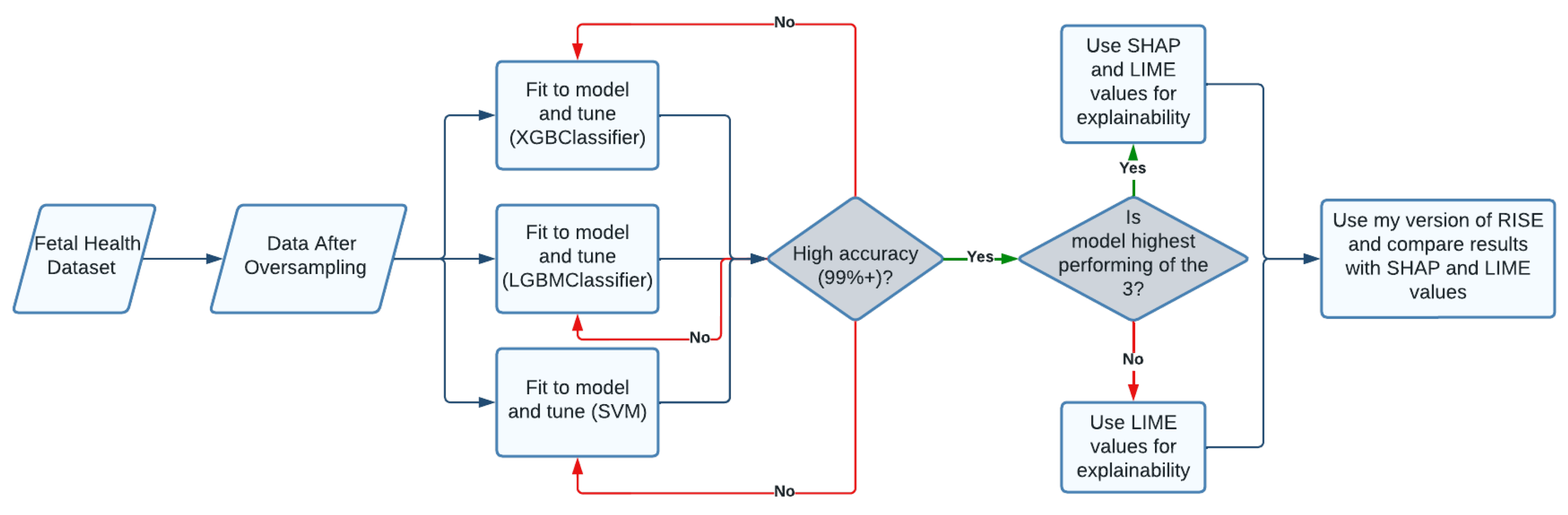
Figure 1.
Executive Diagram: This flowchart describes the steps taken in research process.
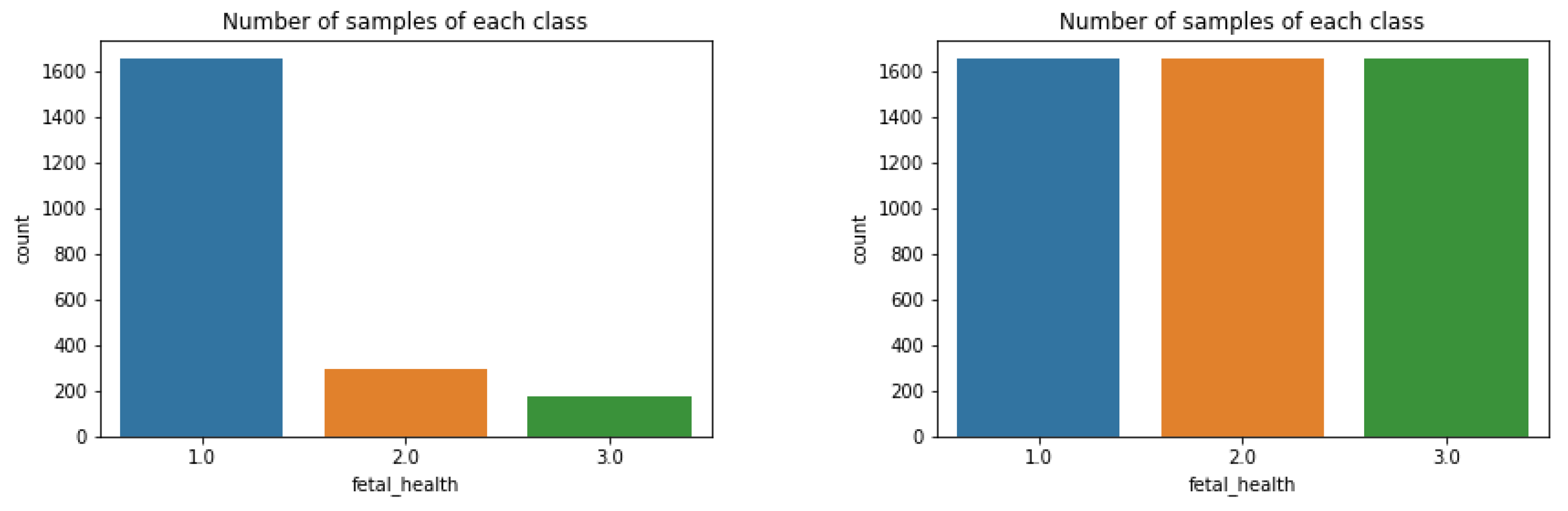
Figure 2.
Bar graph displaying number of occurrences in each group. A healthy fetus was much more prevalent than both suspect and pathological.
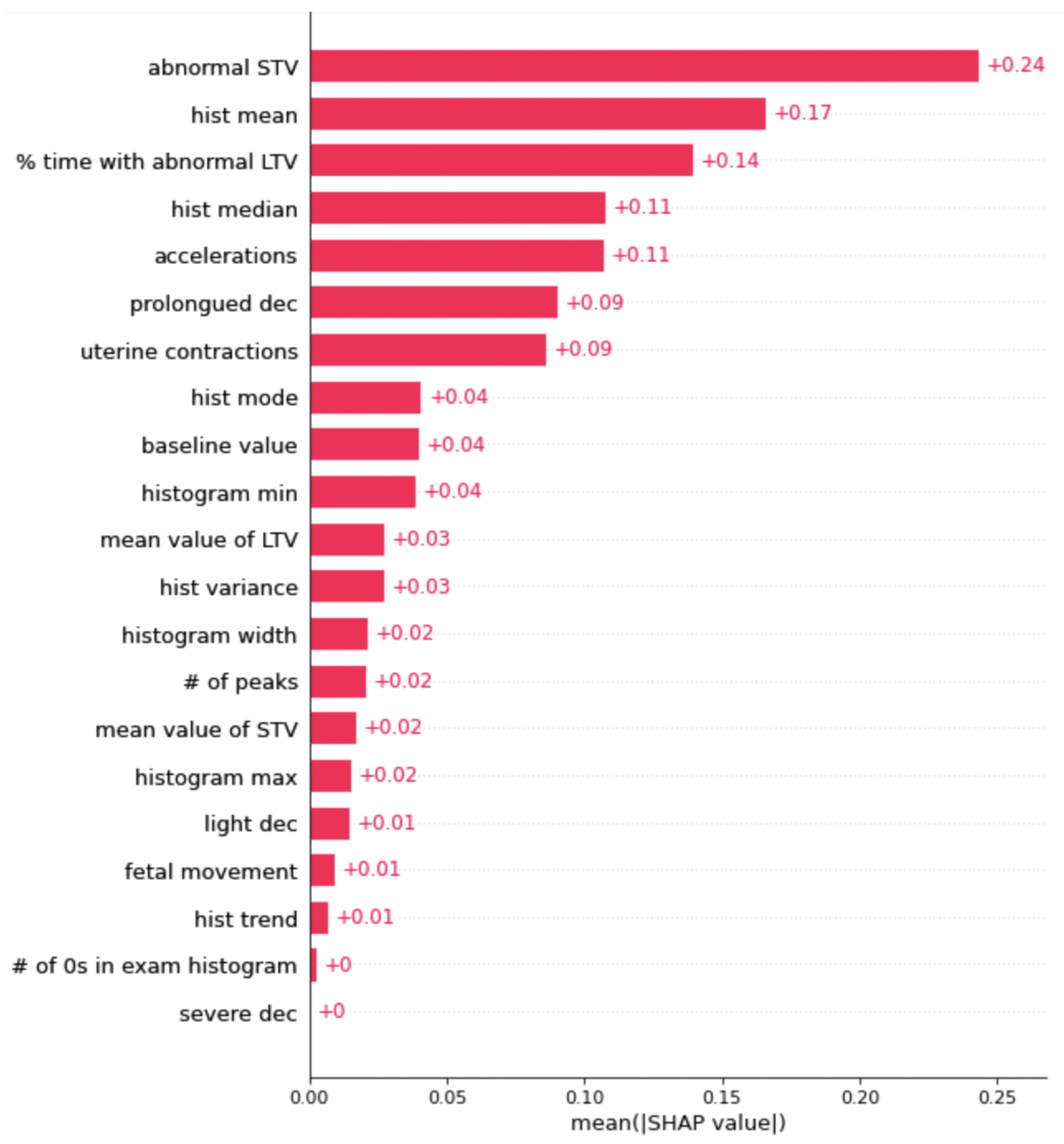
Figure 3.
This is the graph of SHAP values for the XGBoost. The features with a higher number are more important when classifying the data.
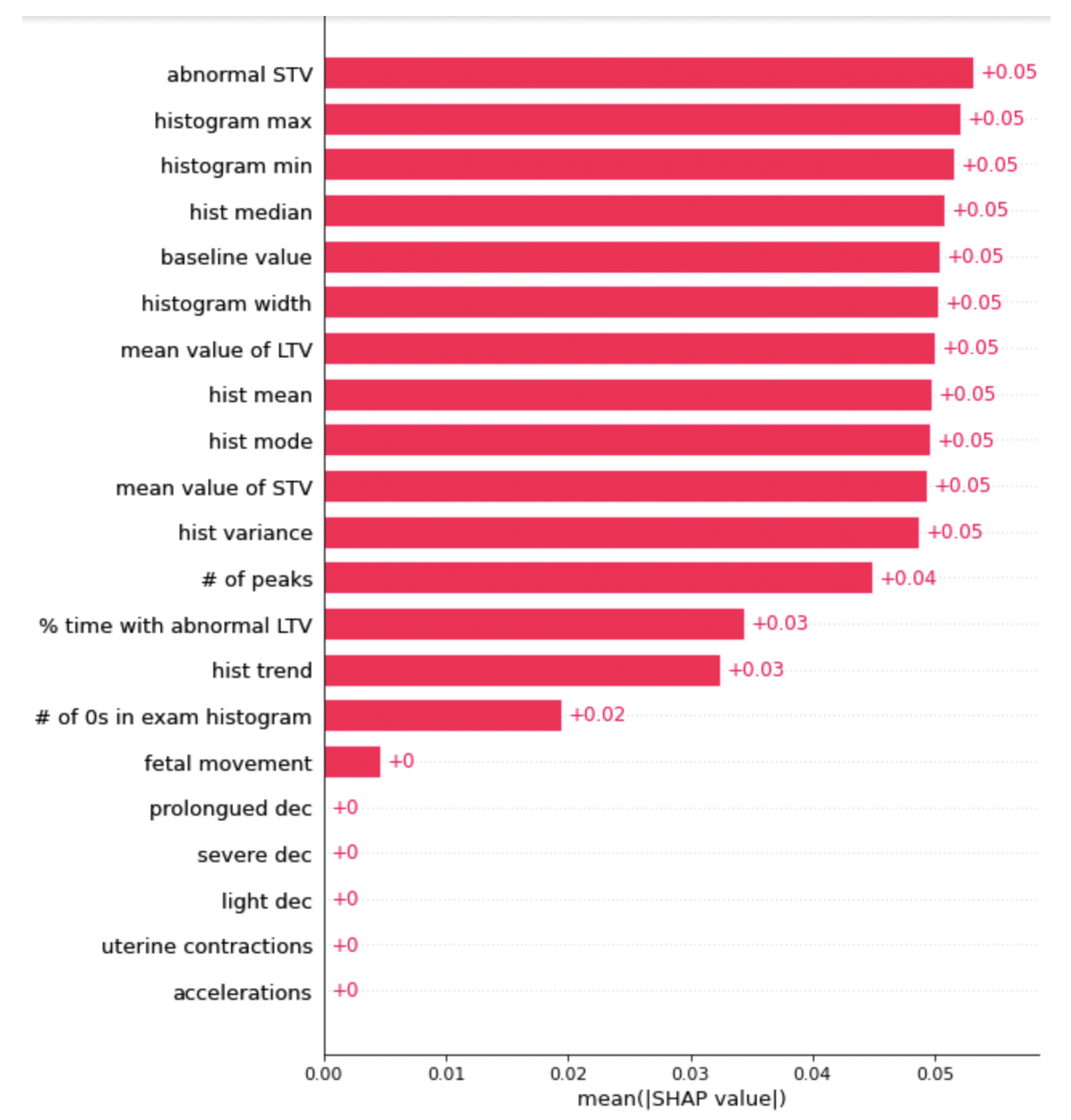
Figure 4.
This is the graph of SHAP values for the LightGBM. The features with a higher number are more important when classifying the data.
Figure 5.
This is the graph of SHAP values for the SVM. The features with a higher number are more important when classifying the data.
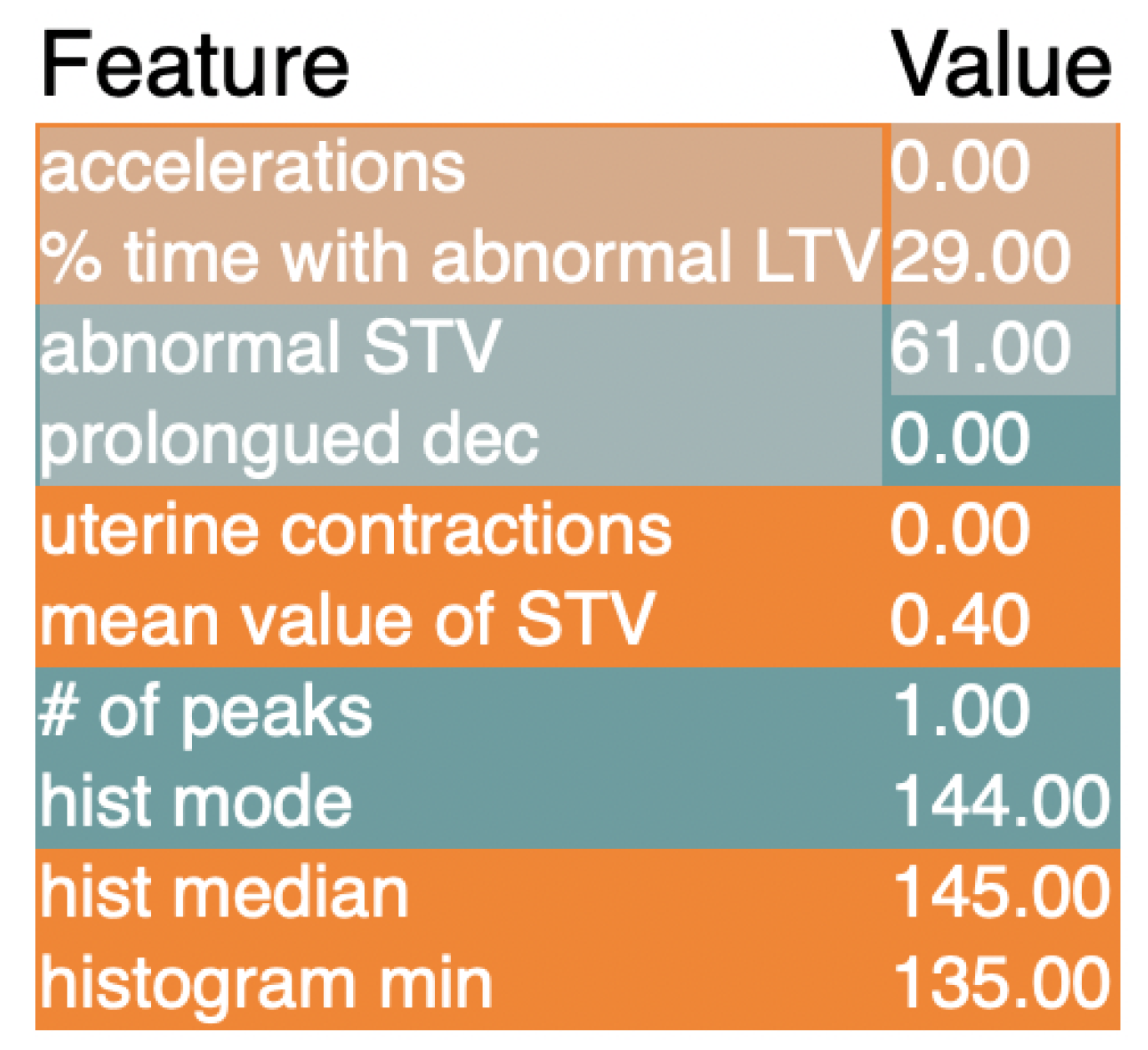
Figure 6.
These are the results of the LIME explainer for the XGBClassifier model.
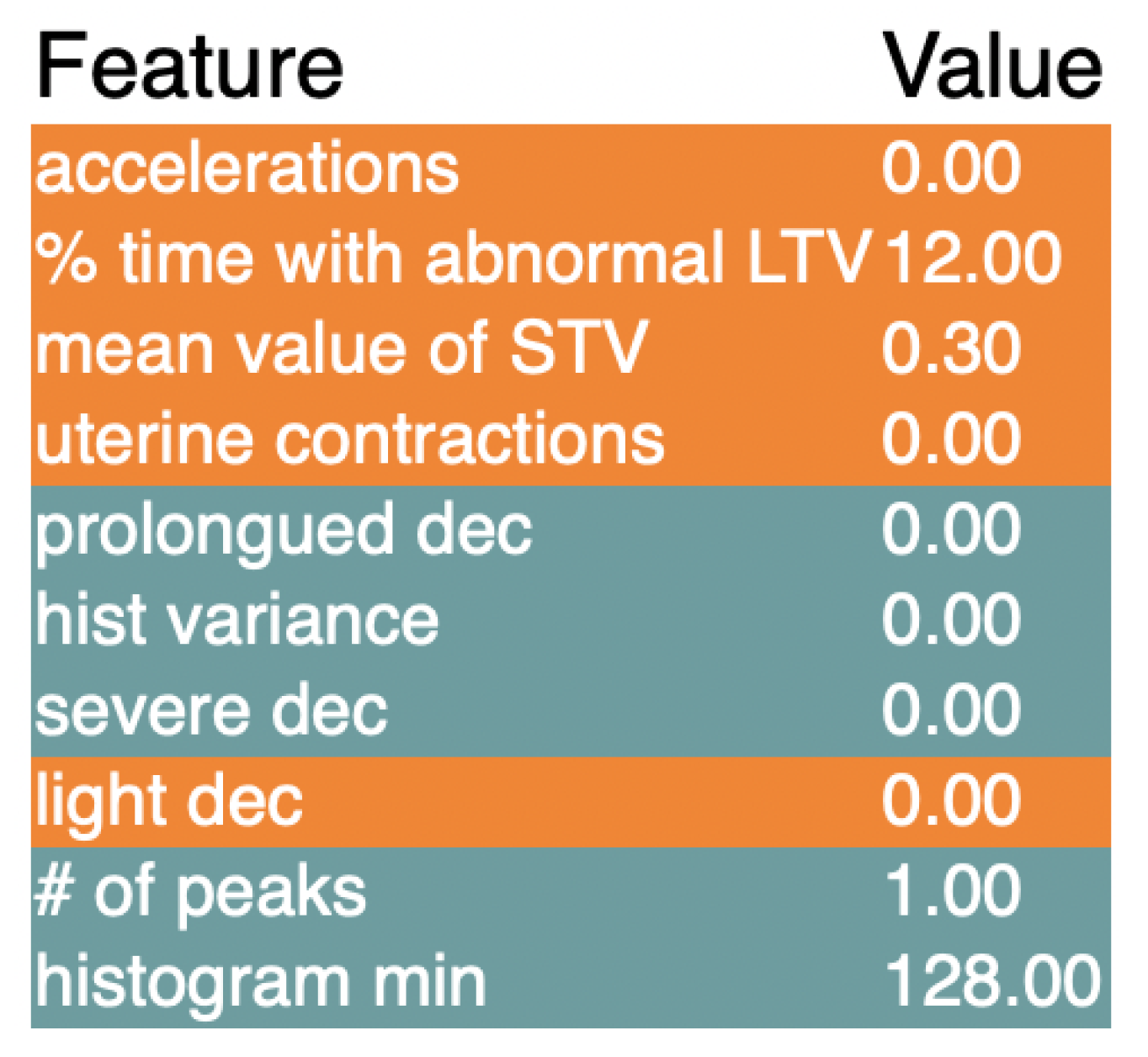
Figure 7.
These are the results of the LIME explainer for the LGBMClassifier model.
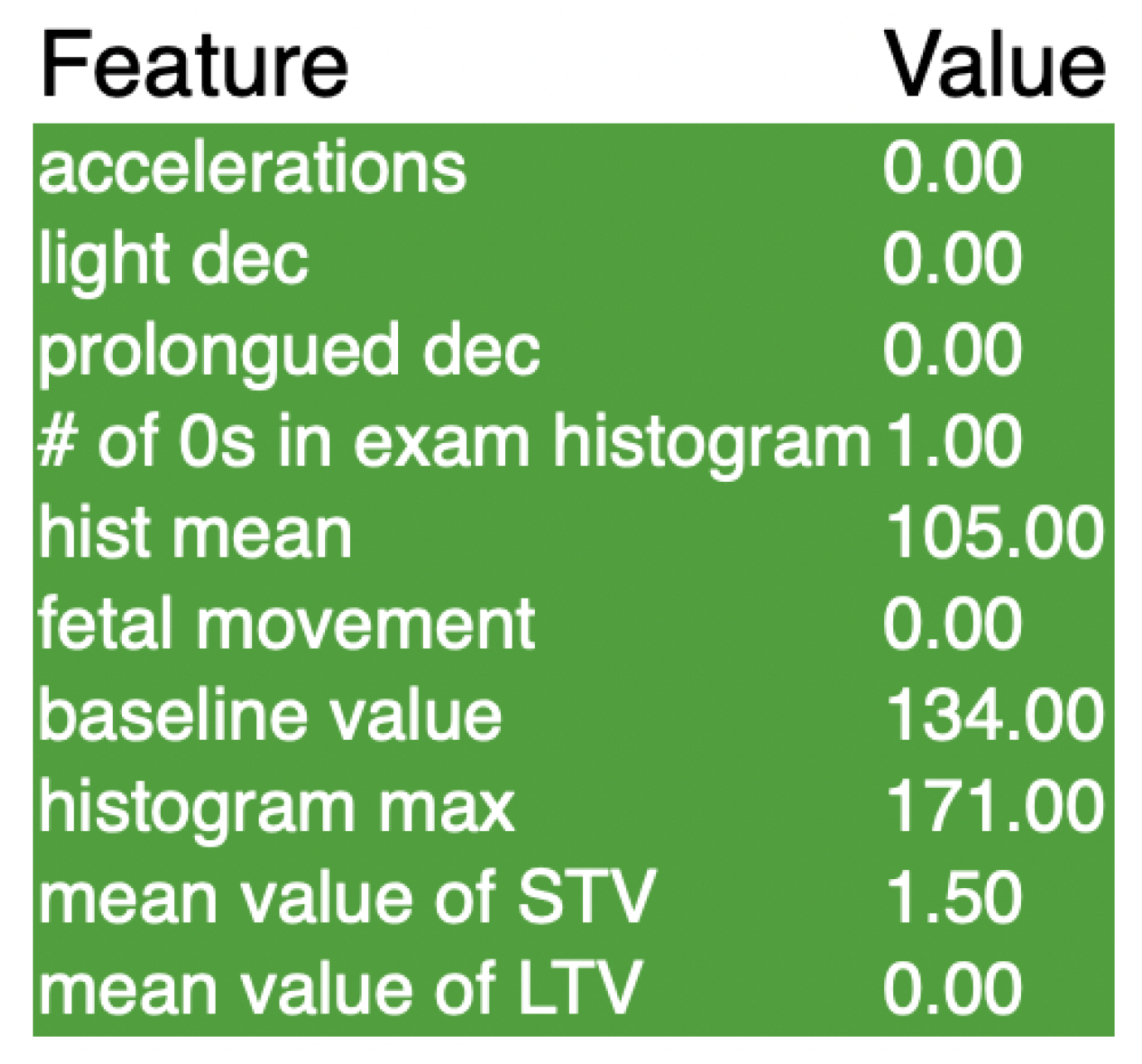
Figure 8.
These are the results of the LIME explainer for the SVM model.
Table 1.
Below is the list of all of the features in the data set along with their corresponding feature number, which is used various times throughout this research in order to address different features.
| Feature # | Feature | Feature # | Feature |
|---|
| 0 | Baseline Value | 11 | Histogram Width |
| 1 | Accelerations | 12 | Histogram Min |
| 2 | Fetal Movement | 13 | Histogram Max |
| 3 | Uterine Contractions | 14 | Histogram Number of Peaks |
| 4 | Light Decelerations | 15 | Histogram Number of Zeroes |
| 5 | Severe Decelerations | 16 | Histogram Mode |
| 6 | Prolonged Decelerations | 17 | Histogram Mean |
| 7 | Abnormal Short Term Variability | 18 | Histogram Median |
| 8 | Mean Value of Short Term Variability | 19 | Histogram Variance |
| 9 | Percentage of Time With Abnormal Long Term Variability | 20 | Histogram Tendency |
| 10 | Mean Value of Long Term Variability | | |
Table 2.
This table shows the performance of the training data at different levels of oversampling. The percentages represent the number of data points in the minority classes relative to the majority class, which is normal fetal health.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
25%
|
0.919
|
0.897
|
0.920
|
0.965
|
|
50%
|
0.964
|
0.961
|
0.964
|
0.988
|
|
75%
|
0.986
|
0.987
|
0.986
|
0.998
|
|
100%
|
0.995
|
0.995
|
0.995
|
0.998
|
Table 3.
Tuning the n_estimators parameter on the XGBClassifier model. Performance plateaus at 250 estimators. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
50
|
0.938
|
0.937
|
0.938
|
0.989
|
|
100
|
0.954
|
0.953
|
0.954
|
0.992
|
|
150
|
0.964
|
0.964
|
0.964
|
0.994
|
|
200
|
0.965
|
0.964
|
0.965
|
0.995
|
|
250
|
0.975
|
0.974
|
0.974
|
0.996
|
|
300
|
0.975
|
0.974
|
0.974
|
0.996
|
Table 4.
Tuning the learning rate parameter on the XGBClassifier model. There is a positive relationship between learning rate and performance, with a learning rate of 1 being the highest performing. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
0.000001
|
0.721
|
0.722
|
0.719
|
0.875
|
|
0.000010
|
0.721
|
0.722
|
0.719
|
0.875
|
|
0.000100
|
0.721
|
0.722
|
0.719
|
0.875
|
|
0.001000
|
0.735
|
0.738
|
0.737
|
0.877
|
|
0.100000
|
0.925
|
0.924
|
0.926
|
0.986
|
|
1.000000
|
0.975
|
0.974
|
0.974
|
0.996
|
Table 5.
Tuning the max depth of the XGBClassifier model. Using the accuracy metrics and the f1 score, a max depth of 15 is optimal. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
1
|
0.975
|
0.974
|
0.974
|
0.996
|
|
5
|
0.986
|
0.986
|
0.986
|
0.998
|
|
10
|
0.986
|
0.986
|
0.986
|
0.998
|
|
15
|
0.987
|
0.987
|
0.987
|
0.998
|
|
20
|
0.987
|
0.987
|
0.987
|
0.998
|
|
25
|
0.987
|
0.987
|
0.987
|
0.998
|
|
32
|
0.987
|
0.987
|
0.987
|
0.998
|
Table 6.
Tuning the n_estimators parameter for the LGBMClassifier. There seems to be a positive linear relationship between performance and number of estimators. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
50
|
0.941
|
0.940
|
0.941
|
0.990
|
|
100
|
0.955
|
0.955
|
0.955
|
0.993
|
|
150
|
0.961
|
0.960
|
0.961
|
0.994
|
|
200
|
0.969
|
0.968
|
0.969
|
0.995
|
|
250
|
0.974
|
0.973
|
0.974
|
0.995
|
|
300
|
0.975
|
0.975
|
0.975
|
0.995
|
Table 7.
Tuning the learning rate of the LGBMClassifier model. Using accuracy and F1 score, a learning rate of 1 is the best for this dataset. However, using AUC, a learning rate of 0.1 is optimal. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
0.000001
|
0.322
|
0.333
|
0.157
|
0.987
|
|
0.000010
|
0.553
|
0.567
|
0.460
|
0.987
|
|
0.000100
|
0.927
|
0.926
|
0.927
|
0.987
|
|
0.001000
|
0.943
|
0.942
|
0.943
|
0.992
|
|
0.010000
|
0.980
|
0.980
|
0.980
|
0.998
|
|
0.100000
|
0.991
|
0.991
|
0.991
|
0.999
|
|
1.000000
|
0.992
|
0.992
|
0.992
|
0.998
|
Table 8.
Tuning the max depth of the LGBMClassifier. A max depth of 5 results in the highest value of all 4 metrics. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
1
|
0.927
|
0.926
|
0.927
|
0.987
|
|
5
|
0.991
|
0.991
|
0.991
|
0.999
|
|
10
|
0.991
|
0.991
|
0.991
|
0.999
|
|
15
|
0.991
|
0.991
|
0.991
|
0.999
|
|
20
|
0.991
|
0.991
|
0.991
|
0.999
|
|
25
|
0.991
|
0.991
|
0.991
|
0.999
|
|
32
|
0.991
|
0.991
|
0.991
|
0.999
|
Table 9.
Tuning the C parameter in the SVC model. The highest metrics seem to be obtained with a higher C of 1000. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
0.01
|
0.664
|
0.667
|
0.670
|
0.861
|
|
0.10
|
0.803
|
0.803
|
0.805
|
0.918
|
|
1.00
|
0.819
|
0.818
|
0.820
|
0.936
|
|
10.00
|
0.838
|
0.838
|
0.840
|
0.957
|
|
100.00
|
0.878
|
0.877
|
0.879
|
0.971
|
|
1000.00
|
0.918
|
0.917
|
0.918
|
0.978
|
Table 10.
Tuning the gamma parameter in the SVC model. The accuracy and F1 score plateau at a gamma of 1, while the ROC AUC reaches a peak at a gamma of 0.1. The accuracy is denoted as “Acc”. The balanced accuracy is denoted as “Bal Acc”. The Receiver Operating Characteristics Area Under Curve (ROC AUC) is also presented.
|
Acc
|
Bal Acc
|
F1
|
ROC AUC
|
|---|
|
0.001
|
0.977
|
0.976
|
0.977
|
0.993
|
|
0.010
|
0.989
|
0.989
|
0.989
|
0.998
|
|
0.100
|
0.995
|
0.995
|
0.995
|
0.999
|
|
1.000
|
0.996
|
0.996
|
0.996
|
0.999
|
|
10.000
|
0.996
|
0.996
|
0.996
|
0.998
|
|
100.000
|
0.996
|
0.996
|
0.996
|
0.998
|
Table 11.
This is the output of the FAB algorithm for the XGBoost model. It lists the most and least important feature using 3 different metrics. Feature # corresponds to
Table 1.
| | Most Important Feature | Feature # | Least Important Feature | Feature # |
|---|
| Acc | 0.98068 | 7 | 0.98953 | 2 |
| F1 | 0.98062 | 7 | 0.98953 | 2 |
| ROC AUC | 0.99810 | 3 | 0.99886 | 0 |
Table 12.
When using FAB on the LightGB model, the results were similar to the XGBoost model. The results also matched up with SHAP and LIME rankings.
| | Most Important Feature | Feature # | Least Important Feature | Feature # |
|---|
| Acc | 0.98470 | 7 | 0.99356 | 5 |
| F1 | 0.98470 | 7 | 0.99356 | 5 |
| ROC AUC | 0.99872 | 8 | 0.99958 | 0 |
Table 13.
The FAB results for the SVM were very similar to the SHAP and LIME outputs, with feature 9 being the most important with all metrics.
| | Most Important Feature | Feature # | Least Important Feature | Feature # |
|---|
| Acc | 0.99597 | 9 | 0.99758 | 0 |
| F1 | 0.99597 | 9 | 0.99758 | 0 |
| ROC AUC | 0.99744 | 9 | 0.99936 | 18 |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}