
Predictive Analysis of Endoscope Demand in Otolaryngology Outpatient Settings

Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Data Preprocessing
3.2. Predictive Analytics
4. Results and Discussion
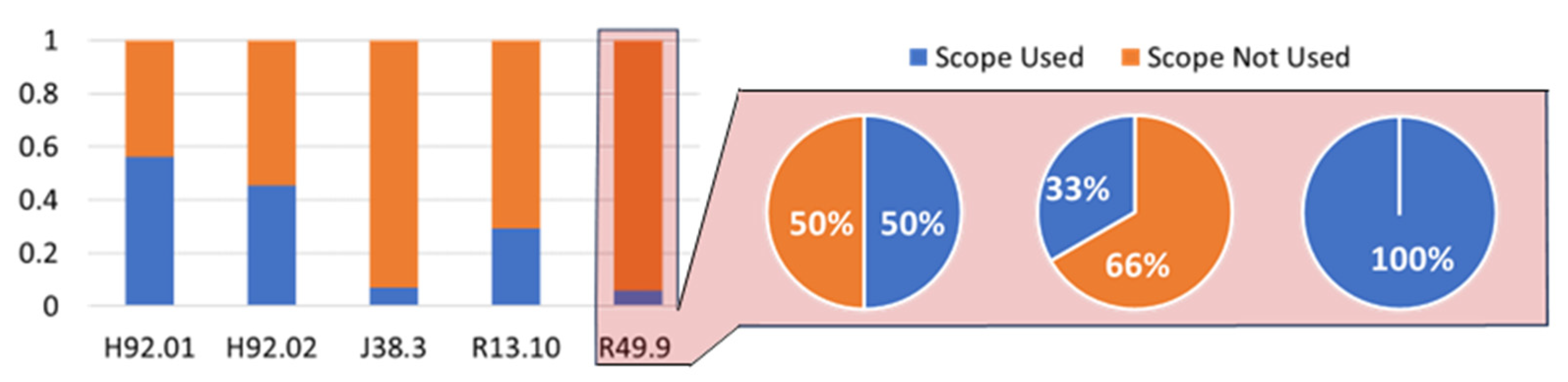
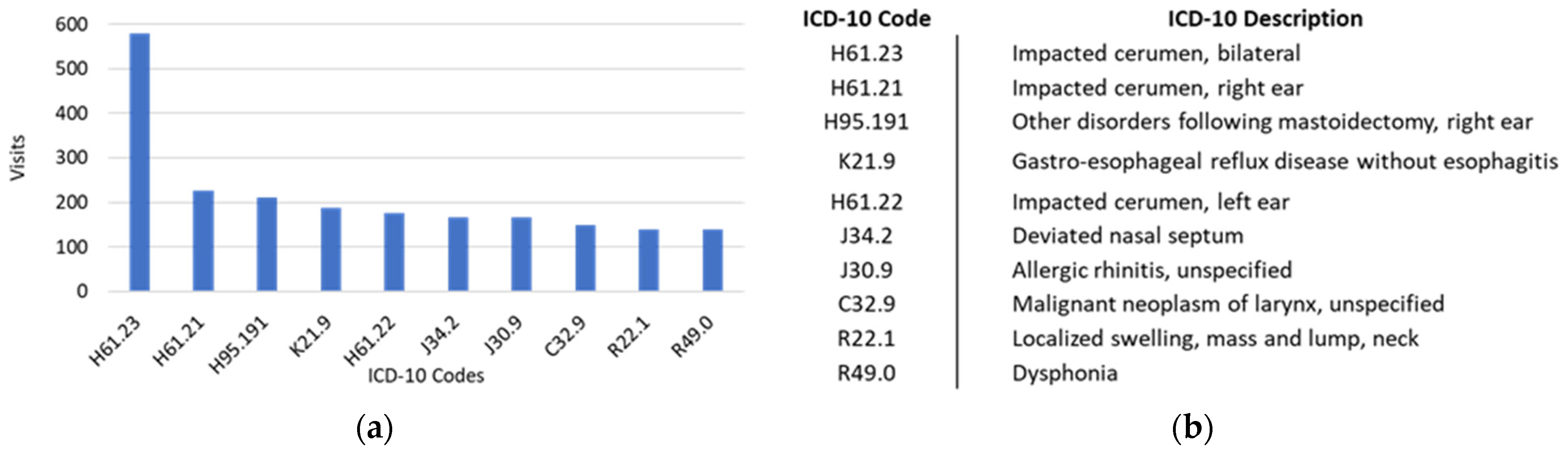
4.1. Data Preprocessing
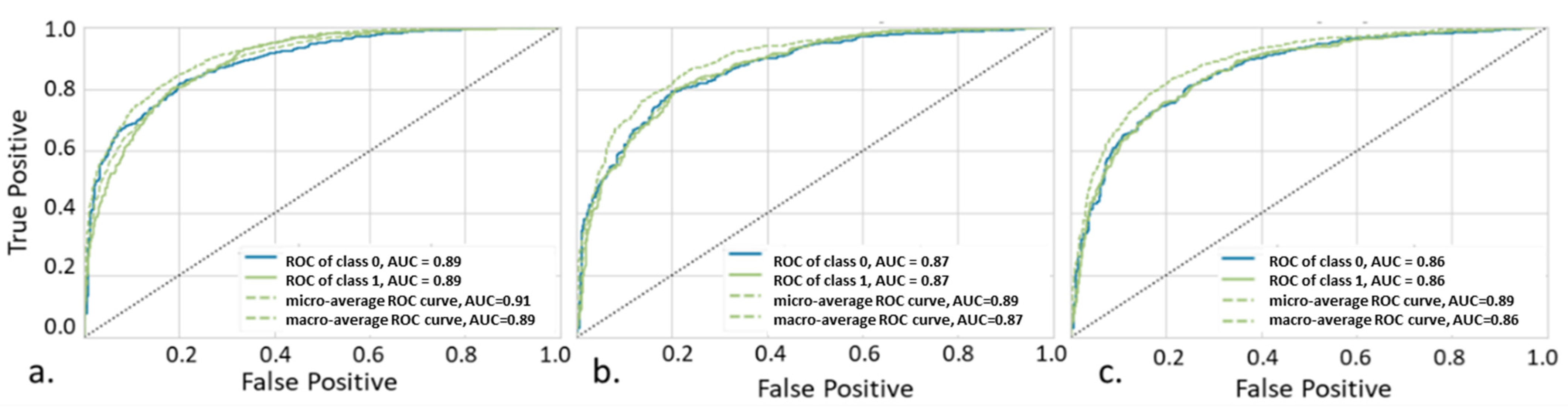
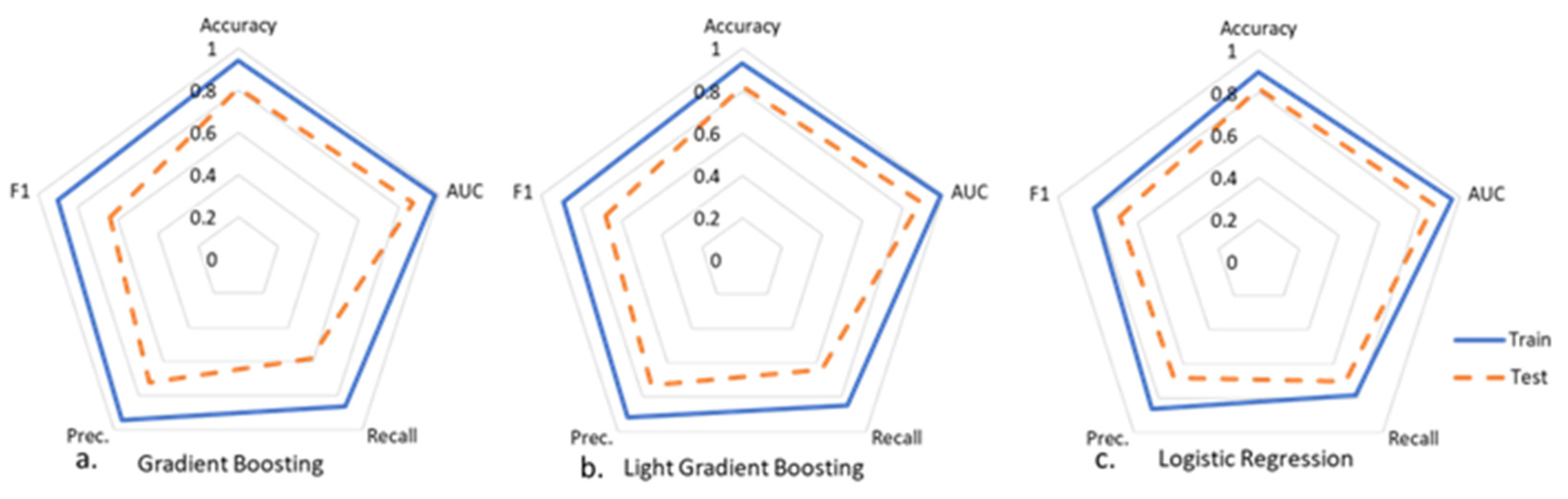
4.2. Predictive Analytics
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benedict, M. Delays in Endoscope Reprocessing … and the Biofilms within; Olympus Corporation, Olympus America Inc.: Tokyo, Japan, 2018; Available online: https://medical.olympusamerica.com/sites/default/files/us/files/pdf/Whitepaper---Delays-in-Endoscope-Reprocessing-FINAL-APPROVED-single-page-version.pdf (accessed on 2 April 2023).
- Gurewich, D.; Shwartz, M.; Beilstein-Wedel, E.; Davila, H.; Rosen, A. Did Access to Care Improve Since Passage of the Veterans Choice Act?: Differences between Rural and Urban Veterans. Med. Care 2021, 59, S270–S278. [Google Scholar] [CrossRef]
- Centers for Medicare & Medicaid Services. Access Measures. Measure Management & You; Centers for Medicare & Medicaid Services: Baltimore, MD, USA, 2018; pp. 1–2. [Google Scholar]
- Etu, E.E.; Monplaisir, L.; Masoud, S.; Arslanturk, S.; Emakhu, J.; Tenebe, I.; Miller, J.B.; Hagerman, T.; Jourdan, D.; Krupp, S. A comparison of univariate and multivariate forecasting models predicting emergency department patient arrivals during the COVID-19 pandemic. Healthcare 2022, 10, 1120. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Luna, S.A.; Siddique, Z. Machine-learning-based disease diagnosis: A comprehensive review. Healthcare 2022, 10, 541. [Google Scholar] [CrossRef] [PubMed]
- Etu, E.E.; Larot, J.; Gunaga, S.; Tenebe, T.; Merklen, C.; Masoud, S.; Emakhu, J.; Morton, T.; Rammal, J.-A.; Chien, C.; et al. 313 Leveraging Decision Trees to Forecast Ambulance Traffic in Emergency Departments. Ann. Emerg. Med. 2023, 82, S136–S137. [Google Scholar] [CrossRef]
- Emakhu, J.; Monplaisir, L.; Aguwa, C.; Arslanturk, S.; Masoud, S.; Nassereddine, H.; Hamam, M.S.; Miller, J.B. Acute coronary syndrome prediction in emergency care: A machine learning approach. Comput. Methods Programs Biomed. 2022, 225, 107080. [Google Scholar] [CrossRef]
- Ray, A.; Chaudhuri, A.K. Smart healthcare disease diagnosis and patient management: Innovation, improvement and skill development. Mach. Learn. Appl. 2021, 3, 100011. [Google Scholar] [CrossRef]
- Zgheib, R.; Chahbandarian, G.; Kamalov, F.; El Messiry, H.; Al-Gindy, A. Towards an ML-based semantic IoT for pandemic management: A survey of enabling technologies for COVID-19. Neurocomputing 2023, 528, 160–177. [Google Scholar] [CrossRef]
- Ben-Israel, D.; Jacobs, W.B.; Casha, S.; Lang, S.; Ryu, W.H.A.; de Lotbiniere-Bassett, M.; Cadotte, D.W. The impact of machine learning on patient care: A systematic review. Artif. Intell. Med. 2020, 103, 101785. [Google Scholar] [CrossRef]
- Johnson, A.E.; Ghassemi, M.M.; Nemati, S.; Niehaus, K.E.; Clifton, D.A.; Clifford, G.D. Machine learning and decision support in critical care. Proc. IEEE 2016, 104, 444–466. [Google Scholar] [CrossRef] [PubMed]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94. [Google Scholar] [CrossRef]
- Kimbugwe, N.; Pei, T.; Kyebambe, M.N. Application of deep learning for quality of service enhancement in internet of things: A review. Energies 2021, 14, 6384. [Google Scholar] [CrossRef]
- Ross, J.; Webb, C.; Rahman, F. Artificial Intelligence in Healthcare; Academy of Medical Royal Colleges: London, UK, 2019. [Google Scholar]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505–515. [Google Scholar] [CrossRef]
- Çallı, E.; Sogancioglu, E.; van Ginneken, B.; van Leeuwen, K.G.; Murphy, K. Deep learning for chest X-ray analysis: A survey. Med. Image Anal. 2021, 72, 102125. [Google Scholar] [CrossRef]
- Akcay, S.; Breckon, T. Towards automatic threat detection: A survey of advances of deep learning within X-ray security imaging. Pattern Recognit. 2022, 122, 108245. [Google Scholar] [CrossRef]
- Cuocolo, R.; Cipullo, M.B.; Stanzione, A.; Ugga, L.; Romeo, V.; Radice, L.; Brunetti, A.; Imbriaco, M. Machine learning applications in prostate cancer magnetic resonance imaging. Eur. Radiol. Exp. 2019, 3, 35. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.K.; Na, K.S. Application of machine learning classification for structural brain MRI in mood disorders: Critical review from a clinical perspective. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2018, 80, 71–80. [Google Scholar] [CrossRef] [PubMed]
- Khalid, H.; Hussain, M.; Al Ghamdi, M.A.; Khalid, T.; Khalid, K.; Khan, M.A.; Fatima, K.; Masood, K.; Almotiri, S.H.; Farooq, M.S.; et al. A comparative systematic literature review on knee bone reports from mri, X-rays and ct scans using deep learning and machine learning methodologies. Diagnostics 2020, 10, 518. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Summers, R.M. Machine learning and radiology. Med. Image Anal. 2012, 16, 933–951. [Google Scholar] [CrossRef] [PubMed]
- Hampe, N.; Wolterink, J.M.; Van Velzen, S.G.; Leiner, T.; Išgum, I. Machine learning for assessment of coronary artery disease in cardiac CT: A survey. Front. Cardiovasc. Med. 2019, 6, 172. [Google Scholar] [CrossRef]
- Shinde, S.A.; Rajeswari, P.R. Intelligent health risk prediction systems using machine learning: A review. Int. J. Eng. Technol. 2018, 7, 1019–1023. [Google Scholar] [CrossRef]
- Mišić, V.V.; Gabel, E.; Hofer, I.; Rajaram, K.; Mahajan, A. Machine learning prediction of postoperative emergency department hospital readmission. Anesthesiology 2020, 132, 968–980. [Google Scholar] [CrossRef] [PubMed]
- Alfred, R.; Obit, J.H. The roles of machine learning methods in limiting the spread of deadly diseases: A systematic review. Heliyon 2021, 7, e07371. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Roy, J.; Stewart, W.F. Prediction modeling using EHR data: Challenges, strategies, and a comparison of machine learning approaches. Med. Care 2010, 48, S106–S113. [Google Scholar] [CrossRef]
- Friedman, C.; Elhadad, N. Natural language processing in health care and biomedicine. In Biomedical Informatics: Computer Applications in Health Care and Biomedicine; Springer: London, UK, 2014; pp. 255–284. [Google Scholar]
- Vamathevan, J.; Clark, D.; Czodrowski, P.; Dunham, I.; Ferran, E.; Lee, G.; Li, B.; Madabhushi, A.; Shah, P.; Spitzer, M.; et al. Applications of machine learning in drug discovery and development. Nat. Rev. Drug Discov. 2019, 18, 463–477. [Google Scholar] [CrossRef]
- Dara, S.; Dhamercherla, S.; Jadav, S.S.; Babu, C.M.; Ahsan, M.J. Machine learning in drug discovery: A review. Artif. Intell. Rev. 2022, 55, 1947–1999. [Google Scholar] [CrossRef]
- Sebastiani, M.; Vacchi, C.; Manfredi, A.; Cassone, G. Personalized medicine and machine learning: A roadmap for the future. J. Clin. Med. 2022, 11, 4110. [Google Scholar] [CrossRef]
- Malgwi, Y.M.; Goni, I.; Ahmad, B.M. A Survey on Recent Advances in Medical Diagnosis and Telemedicine Using Machine Learning Techniques. Orient. J. Comput. Sci. Technol. 2023, 16. Available online: https://bit.ly/3qCZ7DN (accessed on 2 April 2023).
- Bauder, R.A.; Khoshgoftaar, T.M. Medicare fraud detection using machine learning methods. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 858–865. [Google Scholar]
- Eghbali-Zarch, M.; Tavakkoli-Moghaddam, R.; Esfahanian, F.; Masoud, S. Prioritizing the glucose-lowering medicines for type 2 diabetes by an extended fuzzy decision-making approach with target-based attributes. Med. Biol. Eng. Comput. 2022, 60, 2423–2444. [Google Scholar] [CrossRef] [PubMed]
- Emakhu, J.; Etu, E.E.; Monplaisir, L.; Aguwa, C.; Arslanturk, S.; Masoud, S.; Tenebe, I.T.; Nassereddine, H.; Hamam, M.; Miller, J. A hybrid machine learning and natural language processing model for early detection of acute coronary syndrome. Healthc. Anal. 2023, 4, 100249. [Google Scholar] [CrossRef]
- Alvi, S.; Harsha, P. Flexible Nasopharyngoscopy; StatPearls [Internet]: Treasure Island, FL, USA, 2022. [Google Scholar]
- Aremu, S.K. Evaluation and appraisal of its diagnostic yield, The Nigerian experience. J. Fam. Med. Prim. Care 2019, 8, 3399–3403. [Google Scholar] [CrossRef]
- Pynnonen, M.A.; Whelan, J. Reprocessing Flexible Endoscopes in the Otolaryngology Clinic. Otolaryngol. Clin. N. Am. 2019, 52, 391–402. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Area under the Curve (AUC) | Recall | Precision | F1 Score |
|---|---|---|---|---|---|
| Logistic Regression (LR) | 90% | 96% | 78% | 86% | 82% |
| Gradient Boosting (GB) | 94% | 98% | 86% | 94% | 90% |
| Light Gradient Boosting (LGB) | 93% | 99% | 85% | 92% | 89% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lanier, D.; Roush, C.; Young, G.; Masoud, S. Predictive Analysis of Endoscope Demand in Otolaryngology Outpatient Settings. BioMedInformatics 2024, 4, 721-732. https://doi.org/10.3390/biomedinformatics4010040
Lanier D, Roush C, Young G, Masoud S. Predictive Analysis of Endoscope Demand in Otolaryngology Outpatient Settings. BioMedInformatics. 2024; 4(1):721-732. https://doi.org/10.3390/biomedinformatics4010040
Chicago/Turabian StyleLanier, David, Cristie Roush, Gwendolyn Young, and Sara Masoud. 2024. "Predictive Analysis of Endoscope Demand in Otolaryngology Outpatient Settings" BioMedInformatics 4, no. 1: 721-732. https://doi.org/10.3390/biomedinformatics4010040
APA StyleLanier, D., Roush, C., Young, G., & Masoud, S. (2024). Predictive Analysis of Endoscope Demand in Otolaryngology Outpatient Settings. BioMedInformatics, 4(1), 721-732. https://doi.org/10.3390/biomedinformatics4010040