

Comparing ANOVA and PowerShap Feature Selection Methods via Shapley Additive Explanations of Models of Mental Workload Built with the Theta and Alpha EEG Band Ratios



Abstract
:1. Introduction
- Model comparison: Comparing the performance of various models and pinpointing their strengths and weaknesses can aid in selecting the most suitable model for a particular task and identifying areas for enhancement [17].
- Bias detection: Identify any potential features that may result in bias or discrimination in the model’s predictions. It is imperative to take immediate action to address this bias and improve the model’s fairness [9].
2. Related Work
2.1. Shapley Values in Machine Learning
2.2. The Concept of Mental Workload
2.3. Feature Selection with Statistical and Shapley-Based Methods
2.3.1. Traditional Statistical Feature Selection Methods
2.3.2. Shapley Values and Their Application as a Feature Selection Method
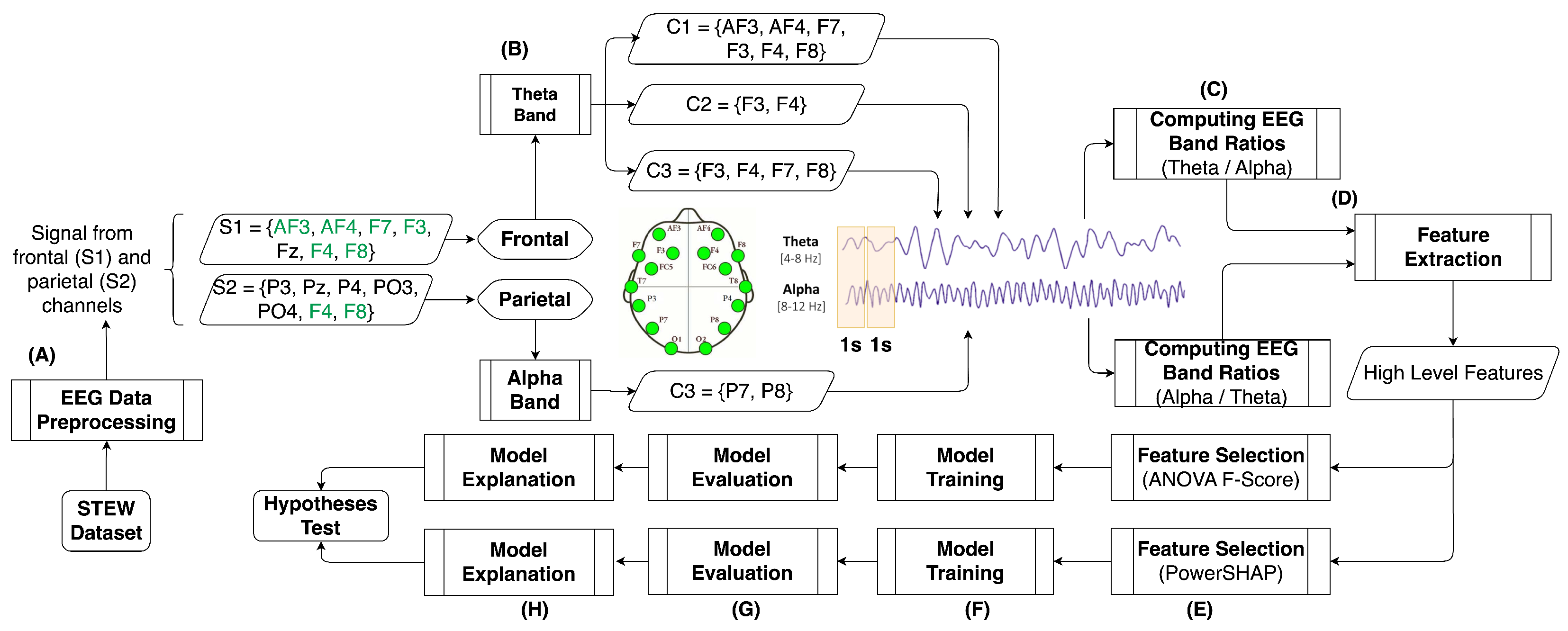
3. Materials and Methods
3.1. Dataset
3.2. EEG Data Pre-Processing
3.3. Computing EEG Band Ratios from the Theta and Alpha Bands as Indicators of Objective Mental Workload
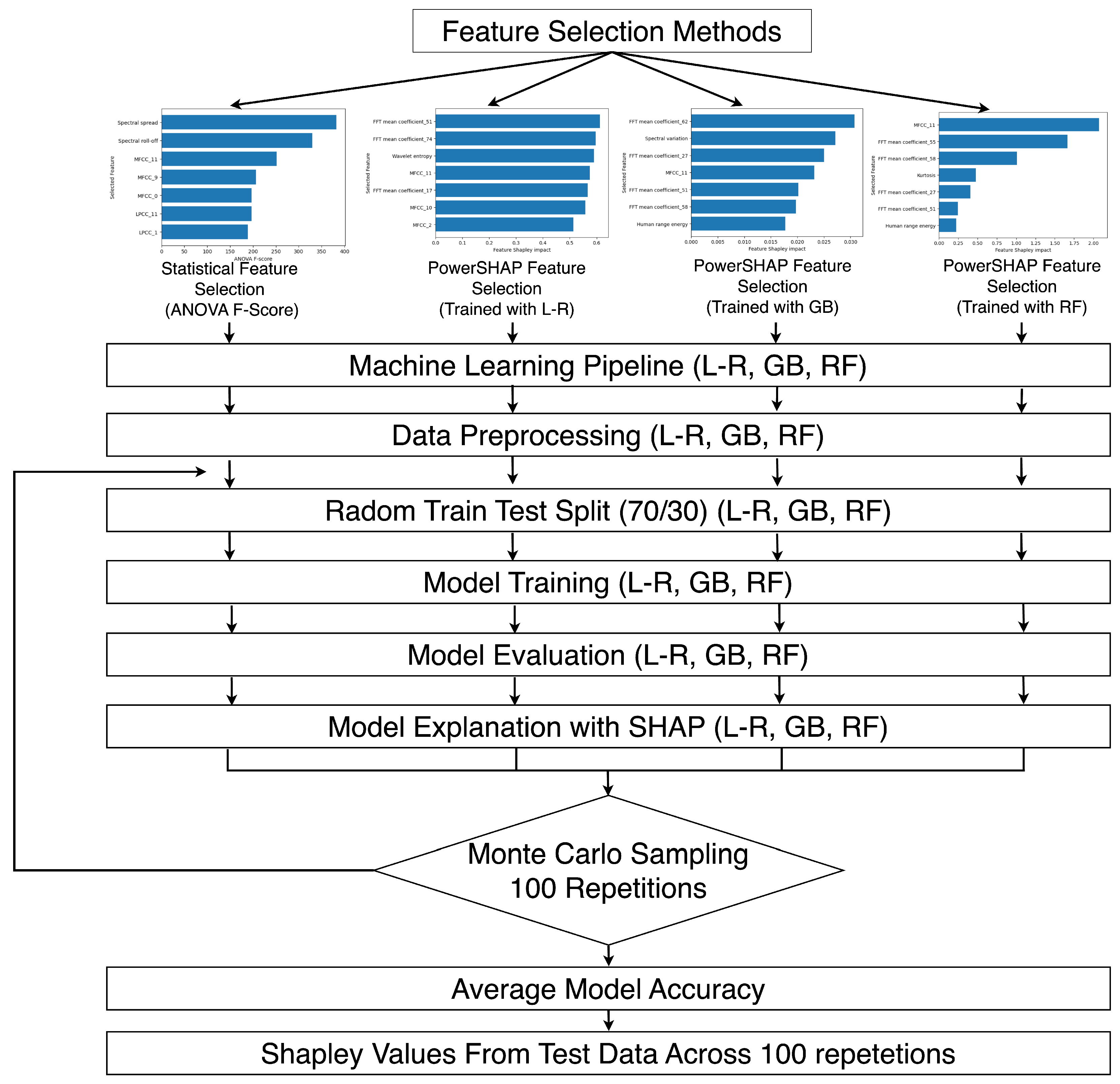
3.4. Feature Selection Using Statistical and Shapley-Based Methods
- By applying the statistical (ANOVA F-score) and Shapley-based (PowerSHAP) methods, the research tends to demonstrate a comprehensive approach to feature selection, closely matching the type of data we explore (EEG) and model complexities that arise from it, thus providing a methodological diversity to the study.
- Whilst Shapley-based feature selection and model interpretability may vary, including ANOVA F-score ensures that at least one method in the study provides straightforward interpretability, which is expected to enhance the comprehensibility of the findings.
- The study also tends to benefit from the robustness to outliers and nonlinear relationships of Shapley-based feature selection methods, while still leveraging the efficiency and performance of ANOVA F-score in identifying significant feature differences.
- Comparing Shapley-based feature selection methods with other common feature selection techniques, the research aims to showcase a broad understanding of the importance of feature selection in Mental Workload Studies using EEG, offering insights into the strengths and limitations of various feature selection approaches in the context of model explainability.
3.4.1. Statistical Feature Selection Methods
3.4.2. Shapley-Value-Based Feature Selection Methods
3.5. Model Training
- For model training, a randomised 70% of subjects are chosen from both the “suboptimal MWL” and “super optimal MWL” categories, which are dependent features.
- The remaining 30% of the data is reserved for model testing.
- To capture the probability density of the target variable, the above splits are repeated 100 times to observe random training data.
3.6. Model Explainability and Evaluation
4. Results
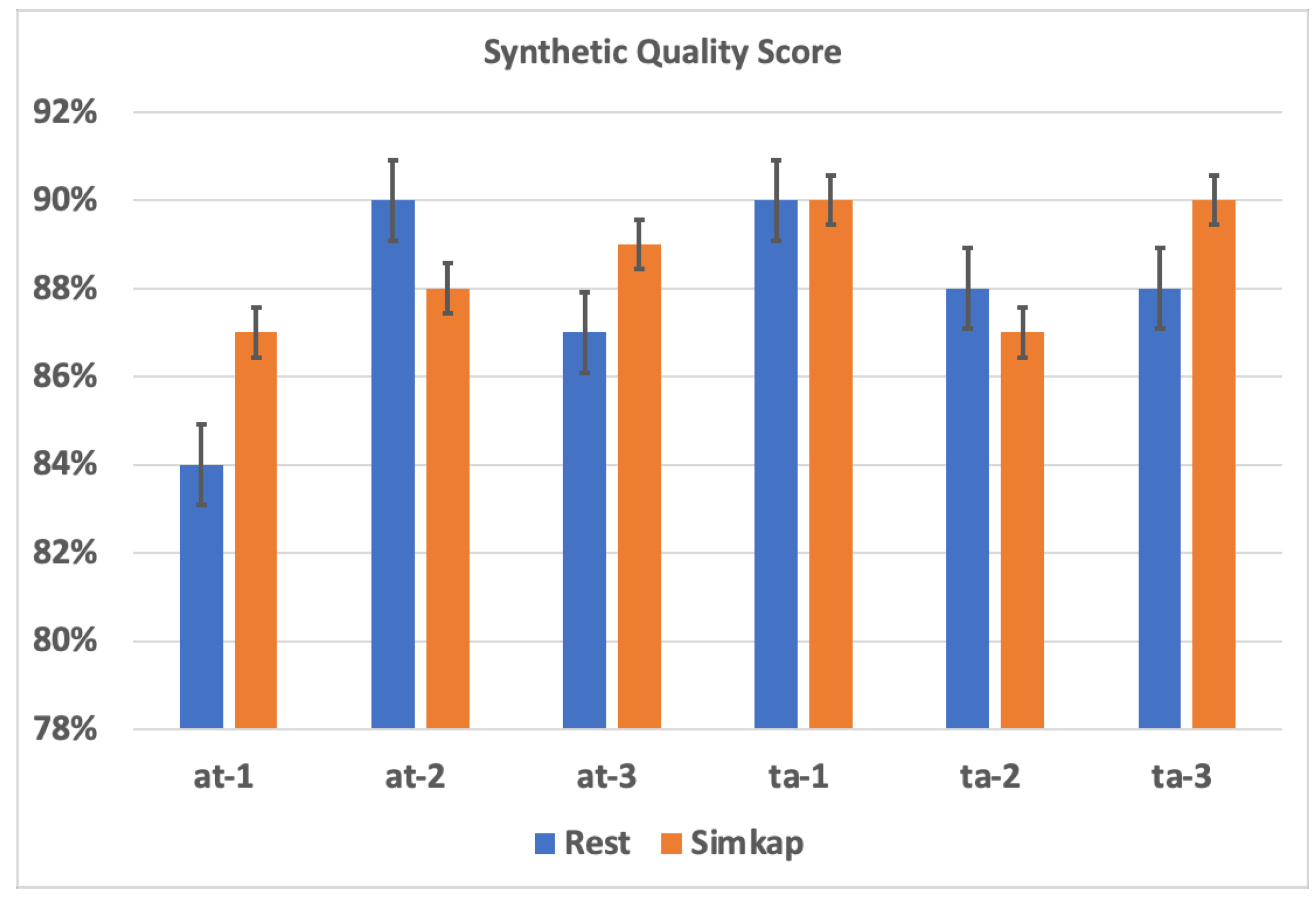
4.1. EEG Artifact Removal
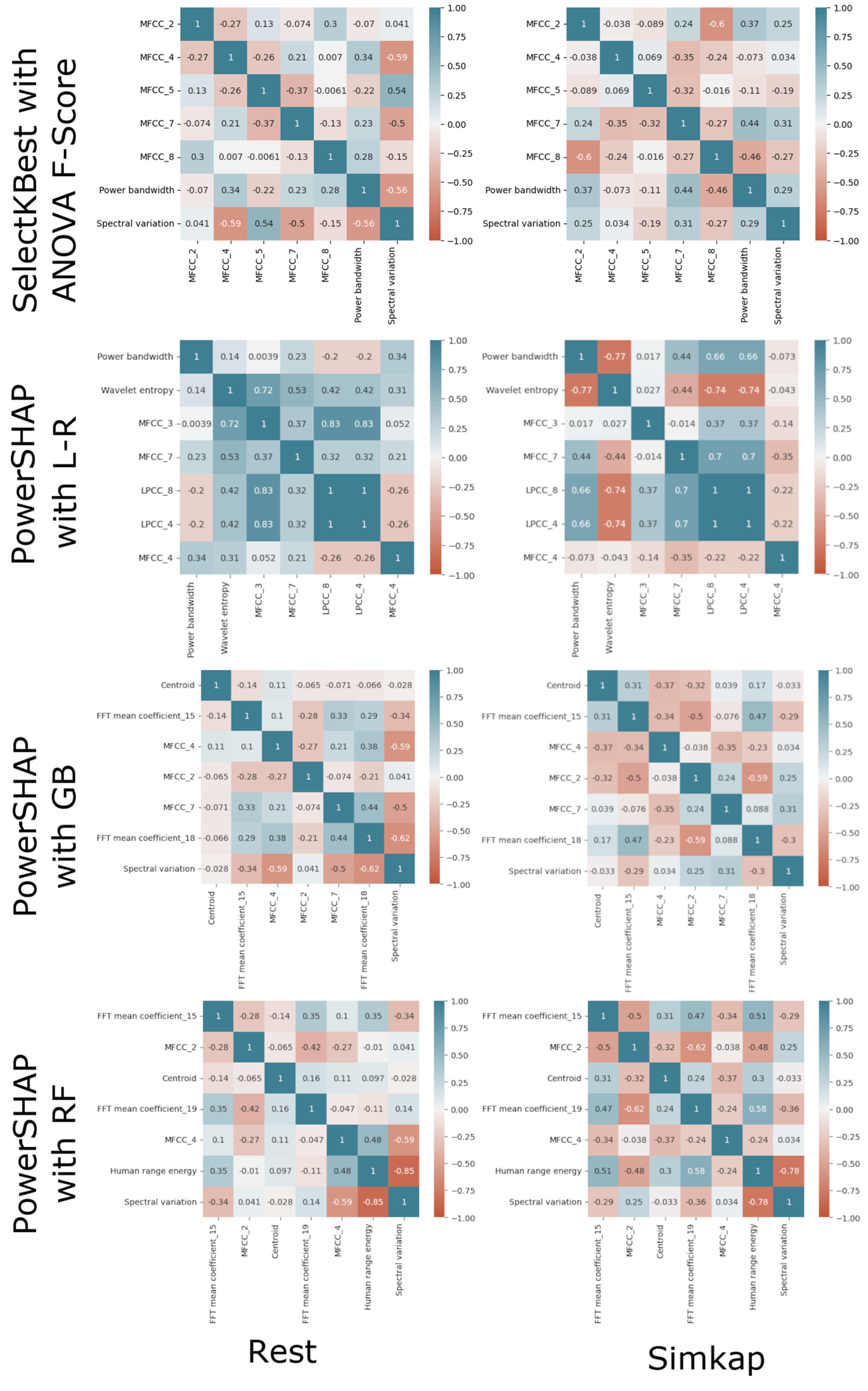
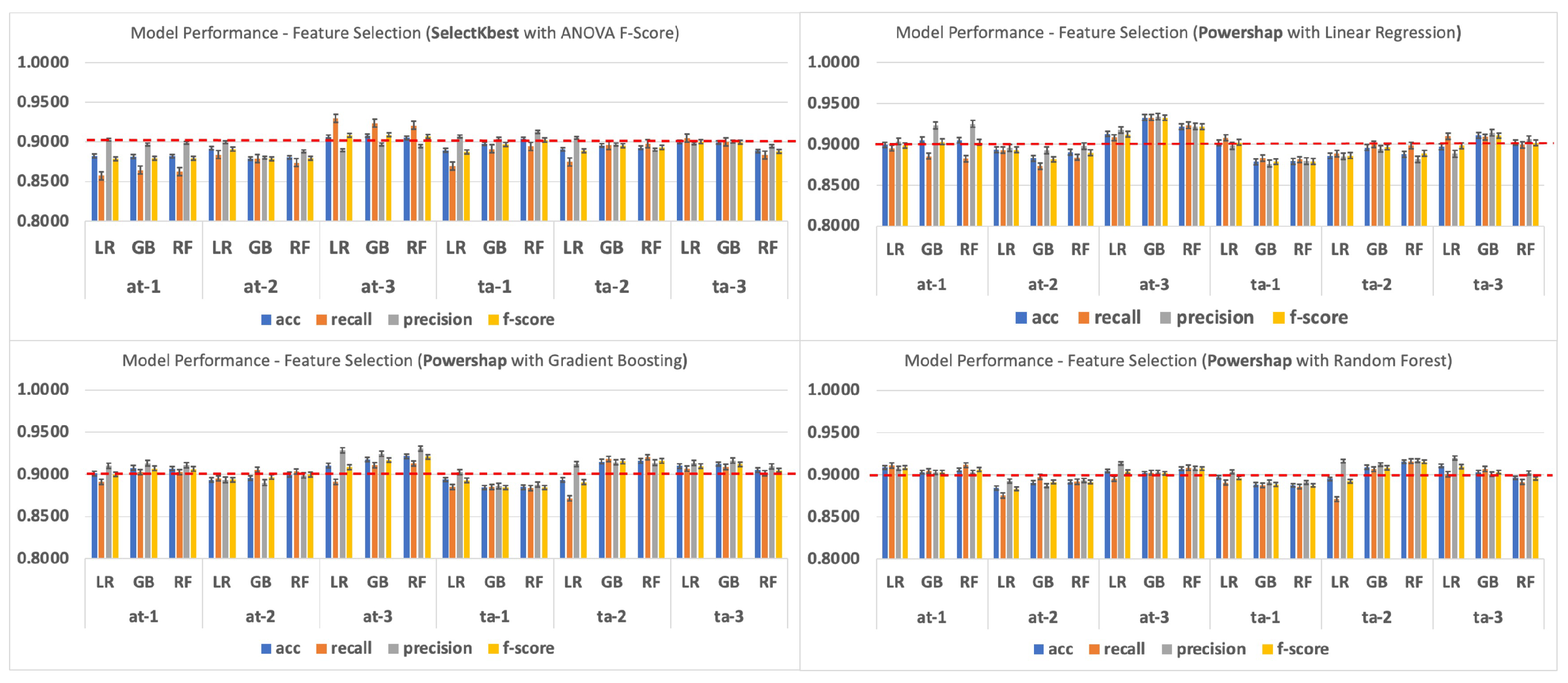
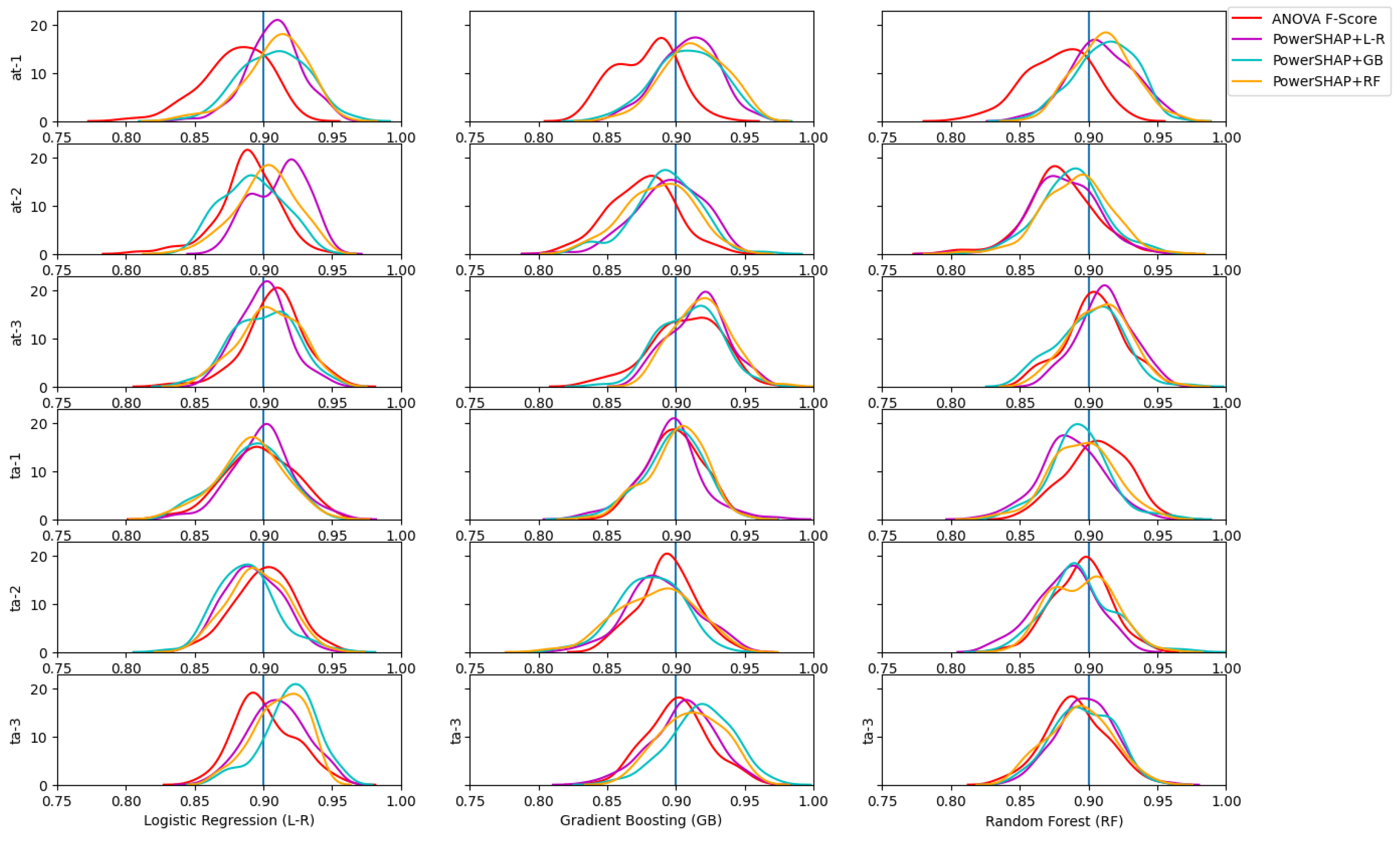
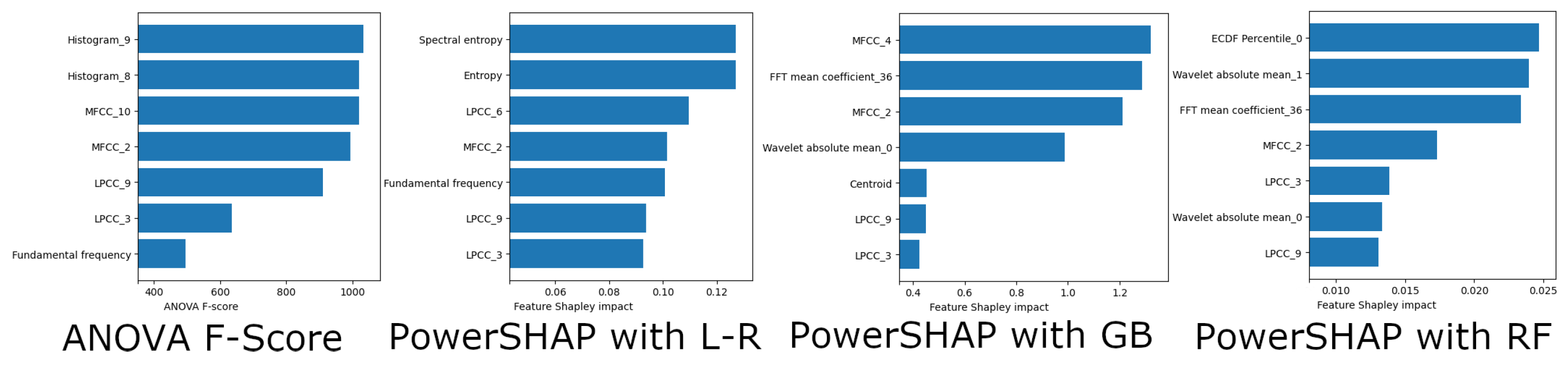
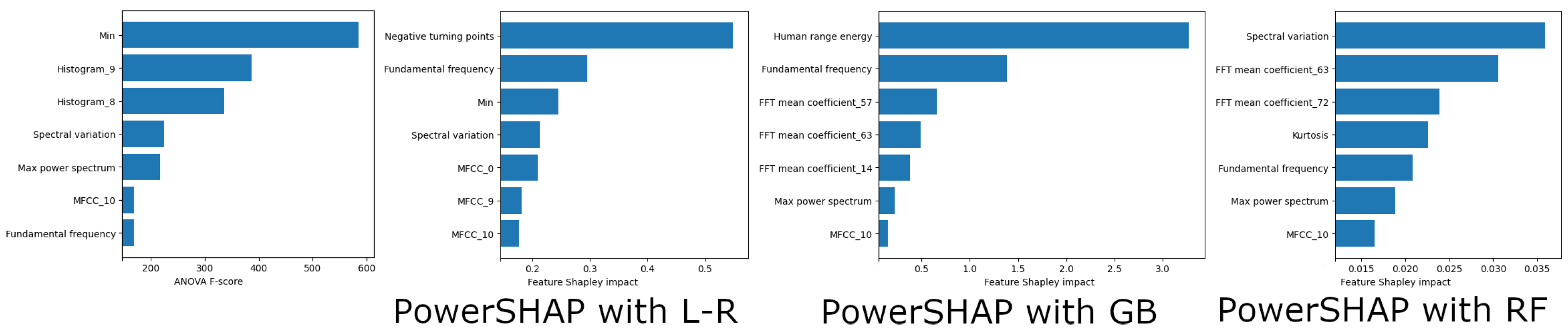
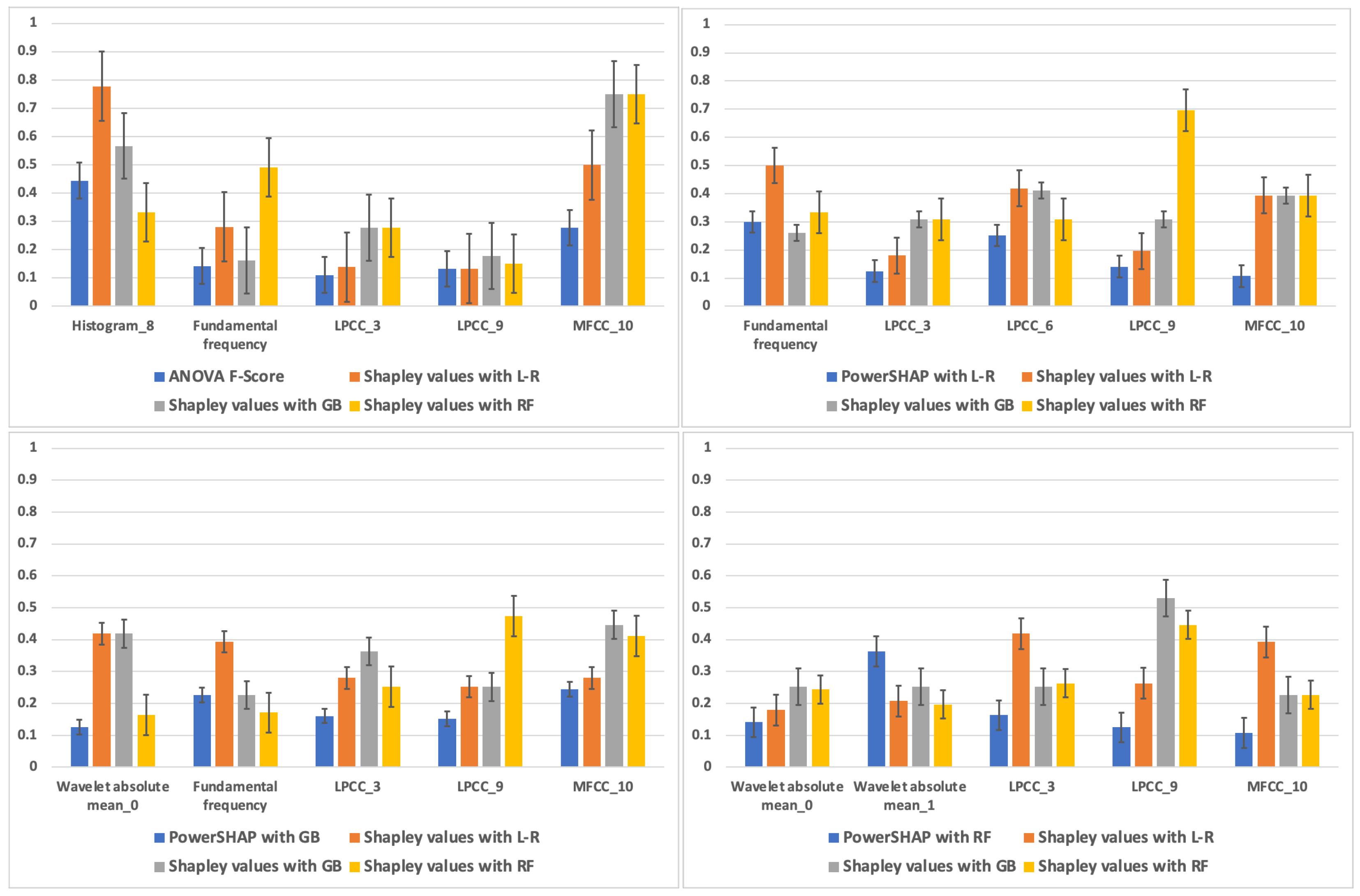
4.2. Evaluation of Feature Selection
4.3. Training Set Evaluation across Indexes
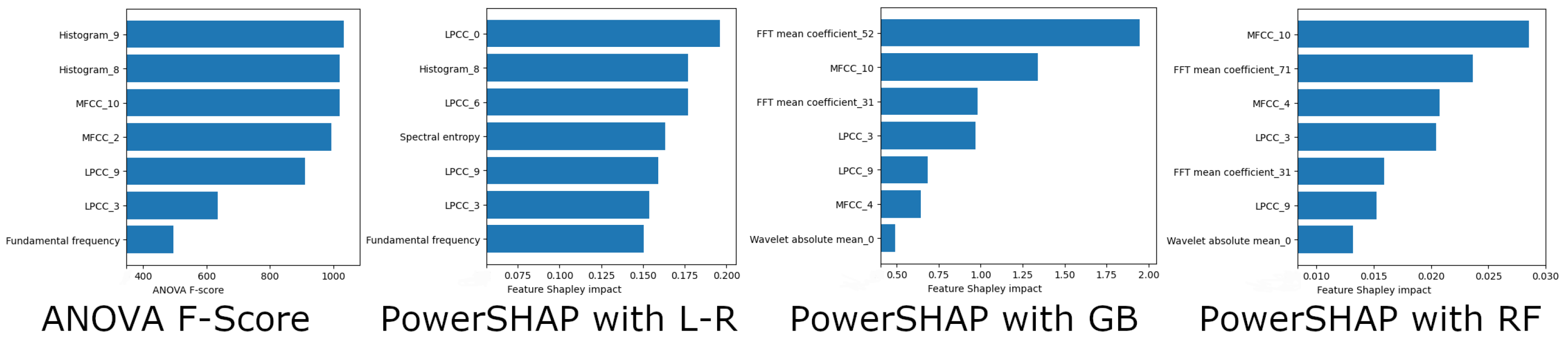
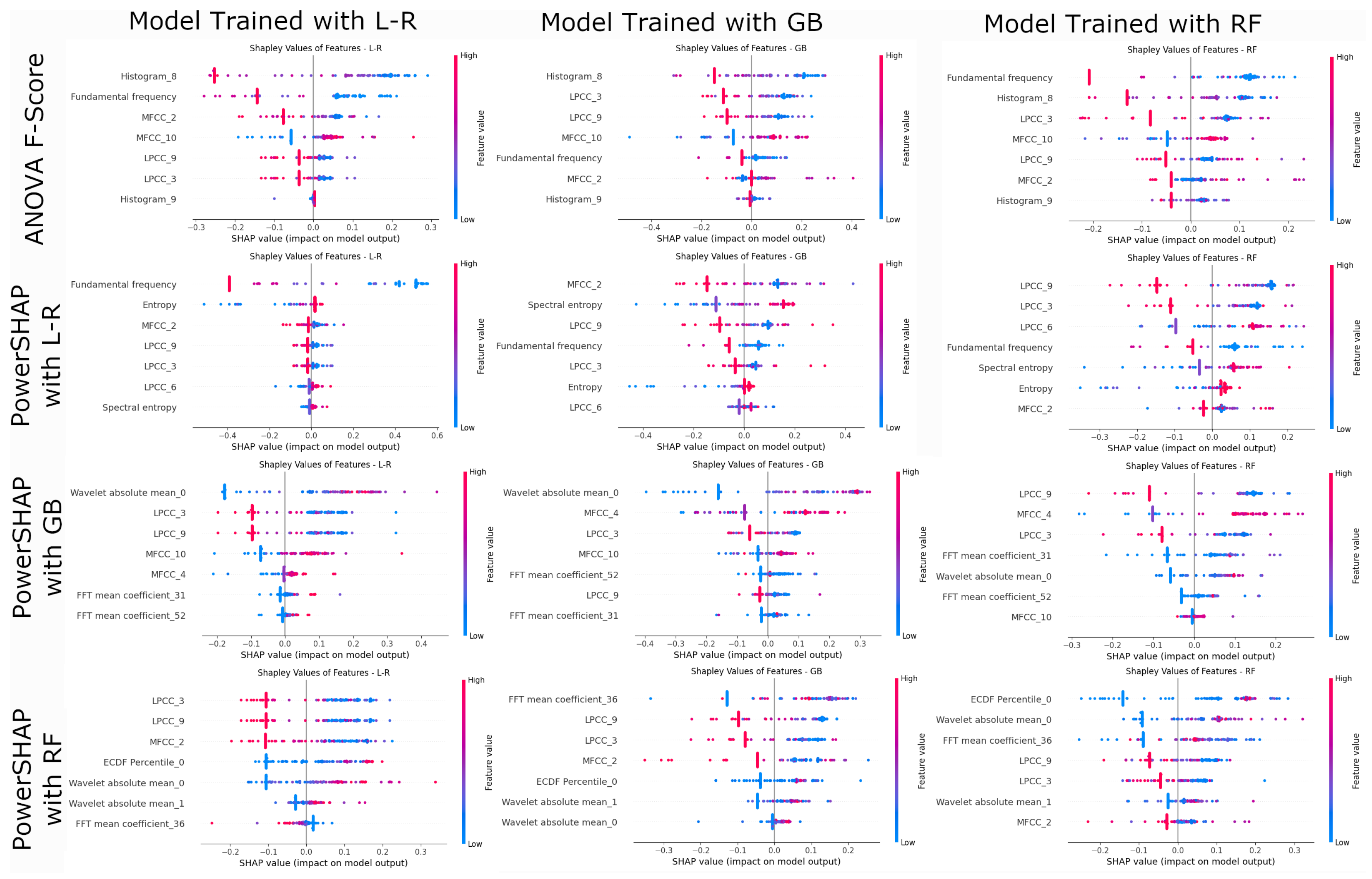
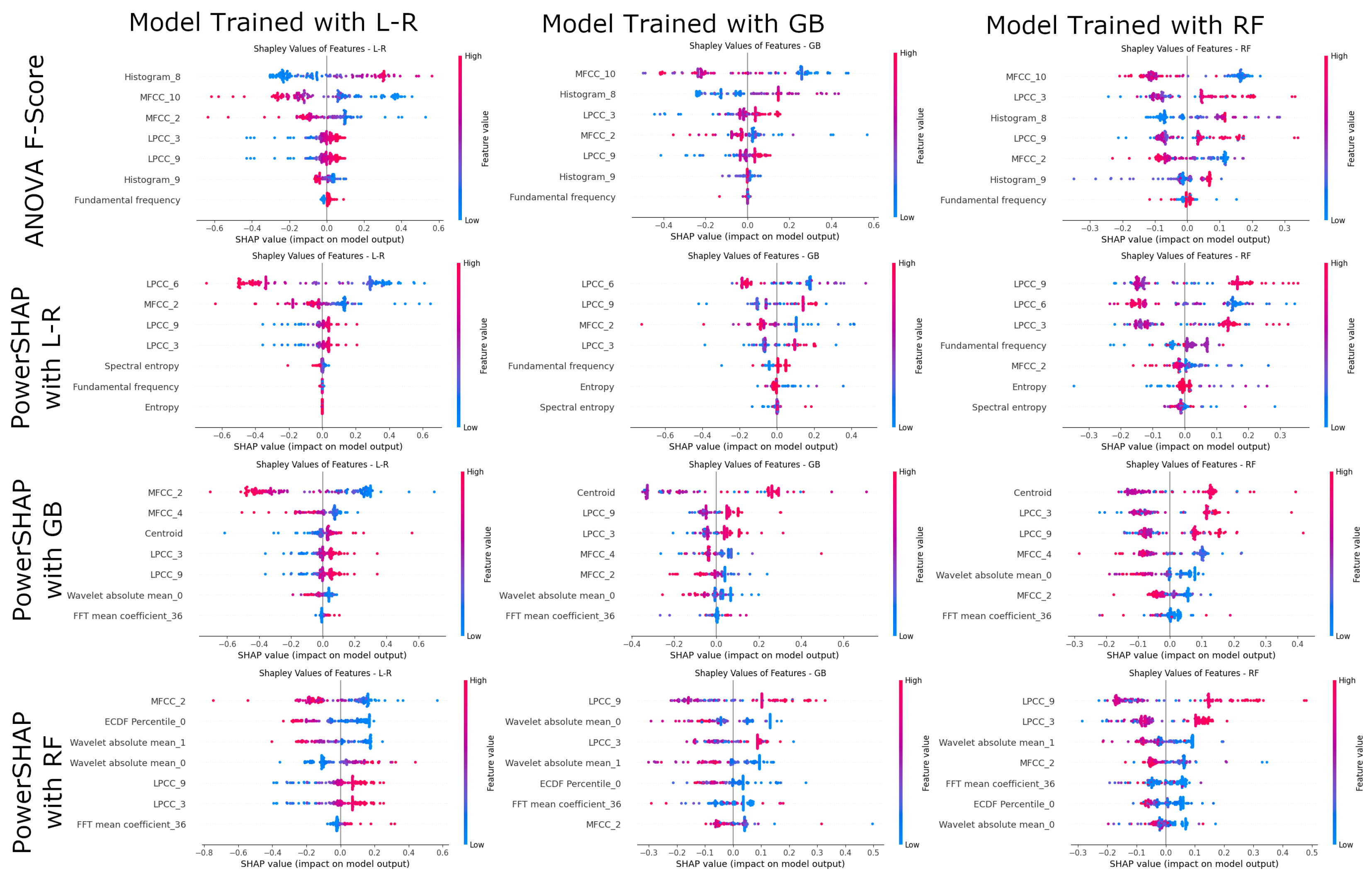
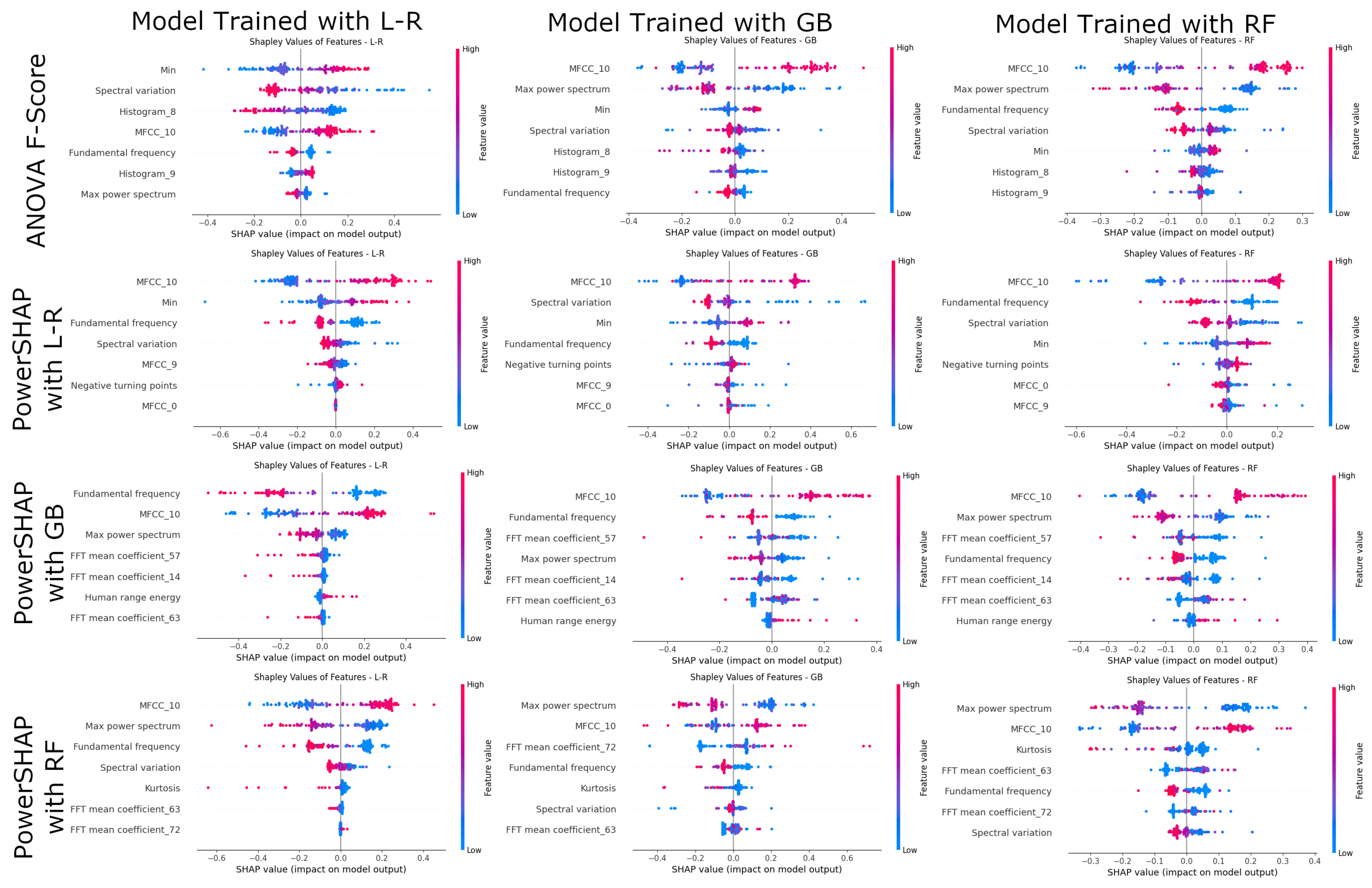
4.4. Model Explainability and Validation
5. Discussion
- Methods based on Shapley values are not tied to any specific machine learning model and can be used with linear and nonlinear models, decision trees, and neural networks. These methods are effective, as they avoid common mistakes such as using a “one-size-fits-all” approach to interpretability, poor model generalization, over-reliance on complex models for explainability, and neglecting feature dependence [62]. On the other hand, statistical feature selection methods often require a particular model or make assumptions about data distribution.
- When working with complex datasets, Shapley-based methods are crucial as they consider the interaction between features. On the other hand, statistical feature selection techniques like correlation-based feature selection only consider pairwise correlations between features and may overlook significant interactions.
- Regarding ranking features, Shapley-based methods are more reliable because small changes do not easily influence them in the data or model. On the other hand, statistical feature selection methods may yield different results depending on the particular data sample or model being utilized.
- Methods based on Shapley values are useful in clearly understanding each feature’s importance. This is because it highlights the contribution of a feature to the prediction, making it easy to explain to domain experts. On the other hand, statistical feature selection methods may require an easily interpretable feature importance measure.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Wang, J.; Jenna, W.; Scott, L. Shapley flow: A graph-based approach to interpreting model predictions. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 13–15 April 2021. [Google Scholar]
- Sim, R.H.L.; Xu, X.; Low, B.K.H. Data valuation in machine learning: “ingredients”, strategies, and open challenges. In Proceedings of the IJCAI, Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Zacharias, J.; von Zahn, M.; Chen, J.; Hinz, O. Designing a feature selection method based on explainable artificial intelligence. Electron. Mark. 2022, 32, 2159–2184. [Google Scholar] [CrossRef]
- Cohen, S.; Dror, G.; Ruppin, E. Feature selection via coalitional game theory. Neural Comput. 2007, 19, 1939–1961. [Google Scholar] [CrossRef] [PubMed]
- Rozemberczki, B.; Watson, L.; Bayer, P.; Yang, H.T.; Kiss, O.; Nilsson, S.; Sarkar, R. The shapley value in machine learning. arXiv 2022, arXiv:2202.05594. [Google Scholar]
- Wang, J.; Wiens, J.; Flow, S.L.S. A Graph-based Approach to Interpreting Model Predictions. arXiv 2020, arXiv:2010.14592. [Google Scholar]
- Sundararajan, M.; Najmi, A. The many Shapley values for model explanation. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 9269–9278. [Google Scholar]
- Covert, I.; Lee, S.I. Improving KernelSHAP: Practical Shapley value estimation using linear regression. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 13–15 April 2021. [Google Scholar]
- Shapley, L.S. A Value for n-Person Games. In Contributions to the Theory of Games (AM-28); Kuhn, H., Tucker, A., Eds.; Princeton University Press: Princeton, NJ, USA, 1953; Volume II, pp. 307–318. [Google Scholar] [CrossRef]
- Chalkiadakis, G.; Elkind, E.; Wooldridge, M. Computational Aspects of Cooperative Game Theory. Synth. Lect. Artif. Intell. Mach. Learn. 2011, 5, 1–168. [Google Scholar]
- Dondio, P.; Longo, L. Trust-based techniques for collective intelligence in social search systems. In Next Generation Data Technologies for Collective Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2011; pp. 113–135. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Merrick, L.; Taly, A. The explanation game: Explaining machine learning models using shapley values. In Proceedings of the Machine Learning and Knowledge Extraction: 4th IFIP TC 5, TC 12, WG 8.4, WG 8.9, WG 12.9 International Cross-Domain Conference, CD-MAKE 2020, Dublin, Ireland, 25–28 August 2020; Proceedings 4. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 17–38. [Google Scholar]
- Louhichi, M.; Nesmaoui, R.; Mbarek, M.; Lazaar, M. Shapley Values for Explaining the Black Box Nature of Machine Learning Model Clustering. Procedia Comput. Sci. 2023, 220, 806–811. [Google Scholar] [CrossRef]
- Tripathi, S.; Hemachandra, N.; Trivedi, P. Interpretable feature subset selection: A Shapley value based approach. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5463–5472. [Google Scholar]
- Främling, K.; Westberg, M.; Jullum, M.; Madhikermi, M.; Malhi, A. Comparison of contextual importance and utility with lime and Shapley values. In Proceedings of the Explainable and Transparent AI and Multi-Agent Systems: Third International Workshop, EXTRAAMAS 2021, Virtual Event, 3–7 May 2021; pp. 39–54. [Google Scholar]
- Longo, L.; Brcic, M.; Federico, C.; Jaesik, C.; Confalonieri, R.; Del Ser, J.; Guidotti, R.; Hayashi, Y.; Herrera, F.; Holzinger, A.; et al. Explainable Artificial Intelligence (XAI) 2.0: A manifesto of open challenges and interdisciplinary research directions. Inf. Fusion 2024, 106, 102301. [Google Scholar] [CrossRef]
- Zhang, J.; Xia, H.; Sun, Q.; Liu, J.; Xiong, L.; Pei, J.; Ren, K. Dynamic Shapley Value Computation. In Proceedings of the 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023; pp. 639–652. [Google Scholar]
- Jia, R.; Dao, D.; Wang, B.; Hubis, F.A.; Hynes, N.; Gürel, N.M.; Spanos, C.J. Towards efficient data valuation based on the shapley value. In Proceedings of the The 22nd International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; pp. 1167–1176. [Google Scholar]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M. Towards better understanding of gradient-based attribution methods for deep neural networks. arXiv 2017, arXiv:1711.06104. [Google Scholar]
- Gevins, A.; Smith, M.E. Neurophysiological measures of cognitive workload during human–computer interaction. Theor. Issues Ergon. Sci. 2003, 4, 113–131. [Google Scholar] [CrossRef]
- Borghini, G.; Astolfi, L.; Vecchiato, G.; Mattia, D.; Babiloni, F. Measuring neurophysiological signals in aircraft pilots and car drivers for the assessment of mental workload, fatigue and drowsiness. Neurosci. Biobehav. Rev. 2014, 44, 58–75. [Google Scholar] [CrossRef]
- Fernandez Rojas, R.; Debie, E.; Fidock, J.; Barlow, M.; Kasmarik, K.; Anavatti, S.; Abbass, H. Electroencephalographic workload indicators during teleoperation of an unmanned aerial vehicle shepherding a swarm of unmanned ground vehicles in contested environments. Front. Neurosci. 2020, 14, 40. [Google Scholar] [CrossRef]
- Raufi, B.; Longo, L. An Evaluation of the EEG alpha-to-theta and theta-to-alpha band Ratios as Indexes of Mental Workload. Front. Neuroinform. 2022, 16, 44. [Google Scholar] [CrossRef] [PubMed]
- Raufi, B. Hybrid models of performance using mental workload and usability features via supervised machine learning. In Proceedings of the Human Mental Workload: Models and Applications: Third International Symposium, H-WORKLOAD 2019, Rome, Italy, 14–15 November 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 136–155. [Google Scholar]
- Mohanavelu, K.; Poonguzhali, S.; Janani, A.; Vinutha, S. Machine learning-based approach for identifying mental workload of pilots. Biomed. Signal Process. Control 2022, 75, 103623. [Google Scholar] [CrossRef]
- Kakkos, I.; Dimitrakopoulos, G.N.; Sun, Y.; Yuan, J.; Matsopoulos, G.K.; Bezerianos, A.; Sun, Y. EEG fingerprints of task-independent mental workload discrimination. IEEE J. Biomed. Health Inform. 2021, 25, 3824–3833. [Google Scholar] [CrossRef]
- Longo, L. Designing medical interactive systems via assessment of human mental workload. In Proceedings of the 2015 IEEE 28th International Symposium on Computer-Based Medical Systems, Sao Carlos, Brazil, 22–25 June 2015; pp. 364–365. [Google Scholar]
- Longo, L.; Rajendran, M. A novel parabolic model of instructional efficiency grounded on ideal mental workload and performance. In Proceedings of the 5th International Symposium, H-WORKLOAD 2021, Virtual Event, 24–26 November 2021; pp. 11–36. [Google Scholar]
- Longo, L. Formalising human mental workload as non-monotonic concept for adaptive and personalised web-design. In Proceedings of the International Conference on User Modeling, Adaptation, and Personalization, Montreal, QC, Canada, 16–20 July 2012. [Google Scholar]
- Jafari, M.J.; Zaeri, F.; Jafari, A.H.; Payandeh Najafabadi, A.T.; Al-Qaisi, S.; Hassanzadeh-Rangi, N. Assessment and monitoring of mental workload in subway train operations using physiological, subjective, and performance measures. Hum. Factors Ergon. Manuf. Serv. Ind. 2020, 30, 165–175. [Google Scholar] [CrossRef]
- Longo, L.; Barrett, S. A computational analysis of cognitive effort. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Hue City, Vietnam, 24–26 March 2010. [Google Scholar]
- Hancock, G.M.; Longo, L.; Young, M.S.; Hancock, P.A. Mental Workload. Handbook of Human Factors and Ergonomics; Wiley Online Library: Hoboken, NJ, USA, 2021. [Google Scholar]
- Longo, L.; Wickens, C.D.; Hancock, G.; Hancock, P.A. Human Mental Workload: A Survey and a Novel Inclusive Definition. Front. Psychol. 2022, 13, 883321. [Google Scholar] [CrossRef]
- Käthner, I.; Wriessnegger, S.C.; Müller-Putz, G.R.; Kübler, A.; Halder, S. Effects of mental workload and fatigue on the P300, alpha and theta band power during operation of an ERP (P300) brain–computer interface. J. Biol. Psychiatry 2014, 102, 118–129. [Google Scholar] [CrossRef] [PubMed]
- Muñoz-de-Escalona, E.; Cañas, J.J.; Leva, C.; Longo, L. Task demand transition peak point effects on mental workload measures divergence. In Proceedings of the Human Mental Workload: Models and Applications: 4th International Symposium, H-WORKLOAD 2020, Granada, Spain, 3–5 December 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 207–226. [Google Scholar]
- Longo, L. Modeling Cognitive Load as a Self-Supervised Brain Rate with Electroencephalography and Deep Learning. Brain Sci. 2022, 12, 1416. [Google Scholar] [CrossRef]
- Rizzo, L. Middeldorf and Longo, Luca, Representing and inferring mental workload via defeasible reasoning: A comparison with the NASA Task Load Index and the Workload Profile. In Proceedings of the 1st Workshop on Advances in Argumentation in Artificial Intelligence AI3@AI*IA, Bari, Italy, 14–17 November 2017. [Google Scholar]
- Rizzo, L.; Luca, L. Inferential Models of Mental Workload with Defeasible Argumentation and Non-monotonic Fuzzy Reasoning: A Comparative Study. In Proceedings of the 2nd Workshop on Advances in Argumentation in Artificial Intelligence, Co-Located with XVII International Conference of the Italian Association for Artificial Intelligence, AI3@AI*IA 2018, Trento, Italy, 20–23 November 2018; pp. 11–26. [Google Scholar]
- Hoque, N.; Bhattacharyya, D.K.; Kalita, J.K. MIFS-ND: A mutual information-based feature selection method. Expert Syst. Appl. 2014, 41, 6371–6385. [Google Scholar] [CrossRef]
- Zhai, Y.; Song, W.; Liu, X.; Liu, L.; Zhao, X. A chi-square statistics based feature selection method in text classification. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 160–163. [Google Scholar]
- Perangin-Angin, D.J.; Bachtiar, F.A. Classification of Stress in Office Work Activities Using Extreme Learning Machine Algorithm and One-Way ANOVA F-Test Feature Selection. In Proceedings of the 2021 4th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 16–17 December 2021; pp. 503–508. [Google Scholar]
- Fryer, D.; Strümke, I.; Nguyen, H. Shapley Values for Feature Selection The Good, the Bad, and the Axioms. arXiv 2021, arXiv:2102.10936. [Google Scholar] [CrossRef]
- Williamson, B.; Feng, J. Efficient nonparametric statistical inference on population feature importance using Shapley values. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 10282–10291. [Google Scholar]
- Junaid, M.; Ali, S.; Eid, F.; El-Sappagh, S.; Abuhmed, T. Explainable machine learning models based on multimodal time-series data for the early detection of Parkinson’s disease. Comput. Methods Programs Biomed. 2023, 234, 107495. [Google Scholar] [CrossRef]
- Msonda, J.R.; He, Z.; Lu, C. Feature Reconstruction Based Channel Selection for Emotion Recognition Using EEG. In Proceedings of the 2021 IEEE Signal Processing in Medicine and Biology Symposium, 2021 (SPMB), Philadelphia, PA, USA, 4 December 2021; pp. 1–7. [Google Scholar]
- Moussa, M.M.; Alzaabi, Y.; Khandoker, A.H. Explainable computer-aided detection of obstructive sleep apnea and depression. IEEE Access 2022, 10, 110916–110933. [Google Scholar] [CrossRef]
- Khosla, A.; Khandnor, P.; Chand, T. Automated diagnosis of depression from EEG signals using traditional and deep learning approaches: A comparative analysis. Biocybern. Biomed. Eng. 2022, 42, 108–142. [Google Scholar] [CrossRef]
- Shanarova, N.; Pronina, M.; Lipkovich, M.; Ponomarev, V.; Müller, A.; Kropotov, J. Application of Machine Learning to Diagnostics of Schizophrenia Patients Based on Event-Related Potentials. Diagnostics 2023, 13, 509. [Google Scholar] [CrossRef] [PubMed]
- Islam, R.; Andreev, A.V.; Shusharina, N.N.; Hramov, A.E. Explainable machine learning methods for classification of brain states during visual perception. Mathematics 2022, 10, 2819. [Google Scholar] [CrossRef]
- Kaczorowska, M.; Plechawska-Wójcik, M.; Tokovarov, M. Interpretable machine learning models for three-way classification of cognitive workload levels for eye-tracking features. Brain Sci. 2021, 11, 210. [Google Scholar] [CrossRef]
- Lim, W.L.; Sourina, O.; Wang, L.P. STEW: Simultaneous task EEG workload data set. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 2106–2114. [Google Scholar] [CrossRef]
- Mikayoshi, M. Makoto’s Preprocessing Pipeline. 2018. Available online: https://sccn.ucsd.edu/wiki/Makotoś_preprocessing_pipeline (accessed on 4 April 2023).
- Nolan, H.; Whelan, R.; Reilly, R.B. FASTER: Fully automated statistical thresholding for EEG artifact rejection. J. Neurosci. Methods 2010, 192, 152–162. [Google Scholar] [CrossRef]
- Verhaeghe, J.; Van Der Donckt, J.; Ongenae, F.; Van Hoecke, S. Powershap: A power-full shapley feature selection method. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2022, Grenoble, France, 19–23 September 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 71–87. [Google Scholar]
- Lieberman, M.G.; Morris, J.D. The precise effect of multicollinearity on classification prediction. Mult. Linear Regres. Viewpoints 2014, 40, 5–10. [Google Scholar]
- Mridha, K.; Kumar, D.; Shukla, M.; Jani, M. Temporal features and machine learning approaches to study brain activity with EEG and ECG. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 409–414. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Frølich, L.; Dowding, I. Removal of muscular artifacts in EEG signals: A comparison of linear decomposition methods. Brain Inform. 2018, 5, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Hernandez-Matamoros, A.; Fujita, H.; Perez-Meana, H. A novel approach to create synthetic biomedical signals using BiRNN. Inf. Sci. 2020, 541, 218–241. [Google Scholar] [CrossRef]
- Molnar, C.; König, G.; Herbinger, J.; Freiesleben, T.; Dandl, S.; Scholbeck, C.A.; Bischl, B. General pitfalls of model-agnostic interpretation methods for machine learning models. In Proceedings of the xxAI-Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, Vienna, Austria, 18 July 2020; Revised and Extended Papers. Springer International Publishing: Cham, Switzerland, 2022; pp. 39–68. [Google Scholar]
- Kumar, I.E.; Venkatasubramanian, S.; Scheidegger, C.; Friedler, S. Problems with Shapley-value-based explanations as feature importance measures. In Proceedings of the International Conference on Machine Learning, Virtual, 21 November 2020; pp. 5491–5500. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. Distributed feature selection: An application to microarray data classification. Appl. Soft Comput. 2015, 30, 136–150. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster Notation | Band | Electrodes |
|---|---|---|
| Theta | AF3, AF4, F3, F4, F7, and F8 | |
| Theta | F3 and F4 | |
| Theta | F3, F4, F7, and F8 | |
| Alpha | P7 and P8 |
| Feature Selection Method | Method Type | Interpret-Ability | Assumptions | Scalability | Robustness | Performance |
|---|---|---|---|---|---|---|
| ANOVA F-Score | Statistical | Easy to interpret | Linearity assumed | Efficient | Susceptible to outliers and non-normal distributions | Effective in identifying significant differences between groups |
| PowerSHAP | Shapley-based | Variable interpretability | No assumptions | Computationally expensive | More robust to outliers and non-linear relationships | Can capture complex interactions and nonlinear relationships |
| RFE | Heuristic | Moderate | May overlook complex interactions | Model complexity dependent | Sensitive to noise | Performance based on underlying model |
| LASSO | Regularization | Moderate | Linearity assumed | Efficient | May shrink coefficients too fast during regularization | Effective on a sparse set of features |
| Random forest feature importance | Ensemble | Moderate | Assumes no interactions between features | Efficient | Handles outliers well | Captures nonlinear relationships |
| PCA | Dimensionality reduction | Challenging | Assumes linearity, orthogonality | Efficient | Loss of interpretability | Captures variance that is not specific to target |
| Workload Index | Logistic Regression (L−R) | Gradient Boosting (GB) | Random Forest (RF) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| t-Stat. | p-Value | t-Stat. | p-Value | t-Stat. | p-Value | ||||
| at-1 | −9.20 | 5.01 | 1.309 | −10.29 | 3.45 | 1.154 | −9.63 | 2.88 | 1.26 |
| −8.16 | 3.76 | 1.45 | −9.52 | 5.85 | 1.34 | −10.49 | 9.06 | 1.61 | |
| −8.92 | 2.98 | 1.36 | −11.40 | 1.72 | 1.48 | −10.28 | 2.40 | 1.46 | |
| at-2 | −8.05 | 7.39 | 1.14 | −5.90 | 1.50 | 0.15 | −0.68 | 0.49 | 0.61 |
| −1.08 | 0.27 | 0.83 | −5.28 | 3.24 | 0.74 | −2.47 | 0.01 | 0.50 | |
| −4.33 | 2.36 | 0.09 | −3.53 | 0.0004 | 0.35 | −3.39 | 0.0008 | 0.48 | |
| at-3 | 2.84 | 0.004 | −0.40 | −2.95 | 0.003 | −0.32 | −2.79 | 0.005 | 0.13 |
| 2.28 | 0.02 | 0.42 | −0.95 | 0.34 | 0.13 | 1.12 | 0.26 | 0.52 | |
| 0.93 | 0.35 | 0.39 | −3.68 | 0.0002 | −0.15 | −1.16 | 0.24 | 0.16 | |
| ta-1 | −0.66 | 0.50 | 0.09 | 1.27 | 0.20 | −0.23 | 5.66 | 5.24 | −0.26 |
| 1.66 | 0.09 | −0.18 | 0.45 | 0.64 | −0.06 | 3.98 | 9.60 | 0.05 | |
| 1.86 | 0.06 | −0.80 | −0.36 | 0.71 | 0.56 | 3.20 | 0.001 | 0.45 | |
| ta-2 | 2.90 | 0.004 | −0.41 | 1.11 | 0.26 | −0.58 | 3.78 | 0.0002 | −0.22 |
| 4.16 | 4.48 | −0.15 | 4.10 | 5.86 | −0.58 | 0.47 | 0.63 | −0.33 | |
| 1.61 | 0.10 | −0.53 | 2.35 | 0.01 | −0.06 | −0.29 | 0.76 | 0.04 | |
| ta-3 | −3.02 | 0.002 | 0.42 | −1.17 | 0.24 | 0.89 | −2.29 | 0.02 | 0.52 |
| −6.29 | 1.96 | 0.16 | −5.25 | 3.83 | 0.74 | −1.76 | 0.07 | 0.46 | |
| −3.73 | 0.0002 | 0.32 | −3.27 | 0.001 | 0.44 | −0.77 | 0.44 | 0.10 | |
| Feature Name | Feature Description |
|---|---|
| Histogram_8 | Histogram 8 of the EEG signal (nine histogram features are extracted). |
| Histogram_9 | Histogram 9 of the EEG signal (nine histogram features are extracted). |
| LPCC_3 | Linear prediction cepstrum coefficients. |
| MFCC_2 | The MEL cepstral coefficient 2 (ten MFCC coefficients are extracted). |
| MFCC_10 | The MEL cepstral coefficient 10 (ten MFCC coefficients are extracted). |
| Wavelet absolute mean | Continuous wavelet transform absolute mean value of EEG signal. |
| Fundamental frequency | Fundamental frequency of the EEG signal. |
| Entropy | Entropy of the EEG signal using the Shannon Entropy method. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raufi, B.; Longo, L. Comparing ANOVA and PowerShap Feature Selection Methods via Shapley Additive Explanations of Models of Mental Workload Built with the Theta and Alpha EEG Band Ratios. BioMedInformatics 2024, 4, 853-876. https://doi.org/10.3390/biomedinformatics4010048
Raufi B, Longo L. Comparing ANOVA and PowerShap Feature Selection Methods via Shapley Additive Explanations of Models of Mental Workload Built with the Theta and Alpha EEG Band Ratios. BioMedInformatics. 2024; 4(1):853-876. https://doi.org/10.3390/biomedinformatics4010048
Chicago/Turabian StyleRaufi, Bujar, and Luca Longo. 2024. "Comparing ANOVA and PowerShap Feature Selection Methods via Shapley Additive Explanations of Models of Mental Workload Built with the Theta and Alpha EEG Band Ratios" BioMedInformatics 4, no. 1: 853-876. https://doi.org/10.3390/biomedinformatics4010048
APA StyleRaufi, B., & Longo, L. (2024). Comparing ANOVA and PowerShap Feature Selection Methods via Shapley Additive Explanations of Models of Mental Workload Built with the Theta and Alpha EEG Band Ratios. BioMedInformatics, 4(1), 853-876. https://doi.org/10.3390/biomedinformatics4010048