
Physics-Consistency Condition for Infinite Neural Networks and Experimental Characterization †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Physics-Consistent Gaussian Processes
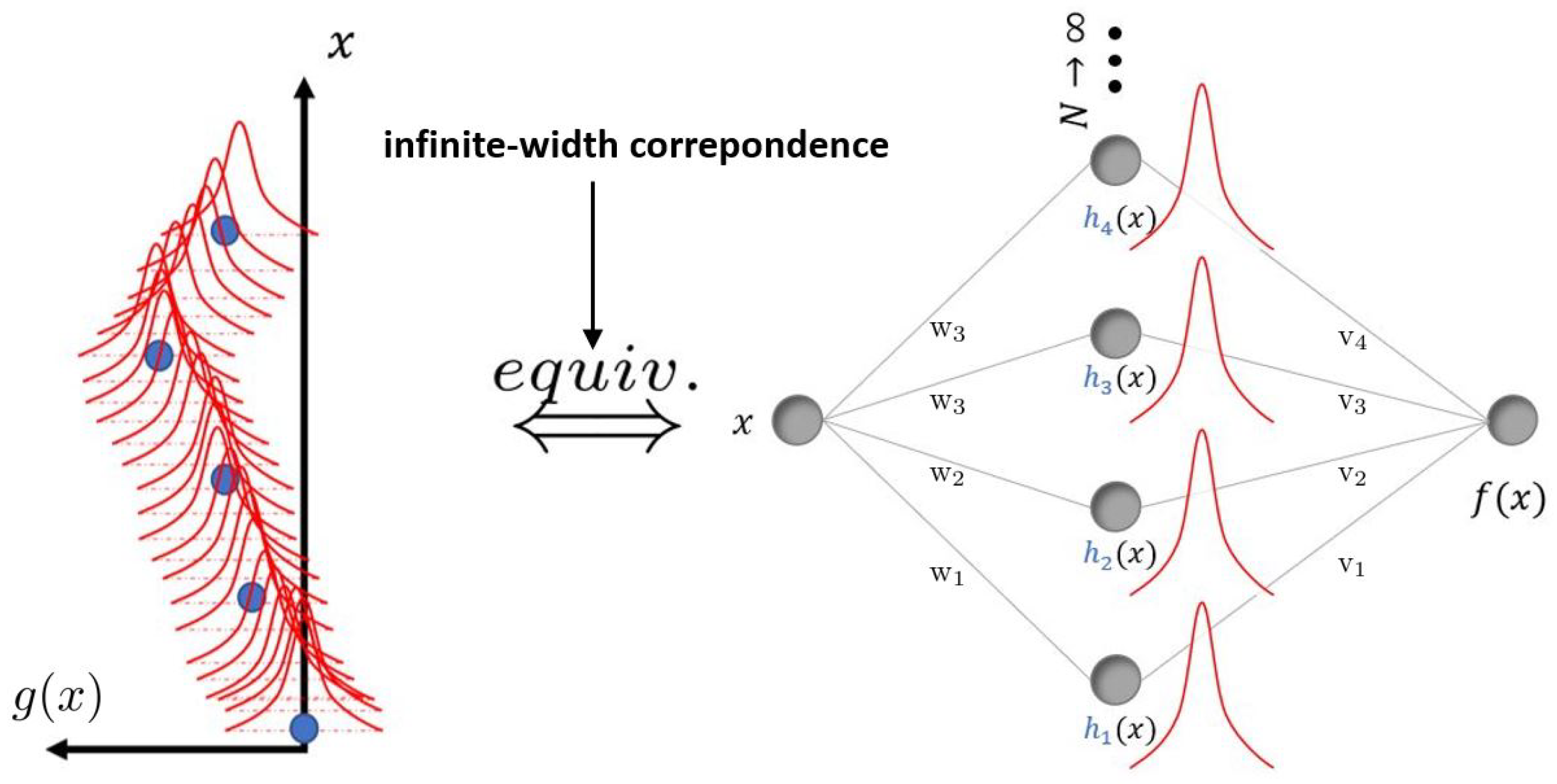
2.2. Infinite Neural Networks
3. Infinite Neural Networks Converging to Physics-Consistent Gaussian Processes
3.1. Physics-Consistent Gaussian Processes
3.2. Infinite Neural Networks
3.3. Physics-Consistency Condition for Neural Networks
3.4. Training and Regularization with Physics-Information
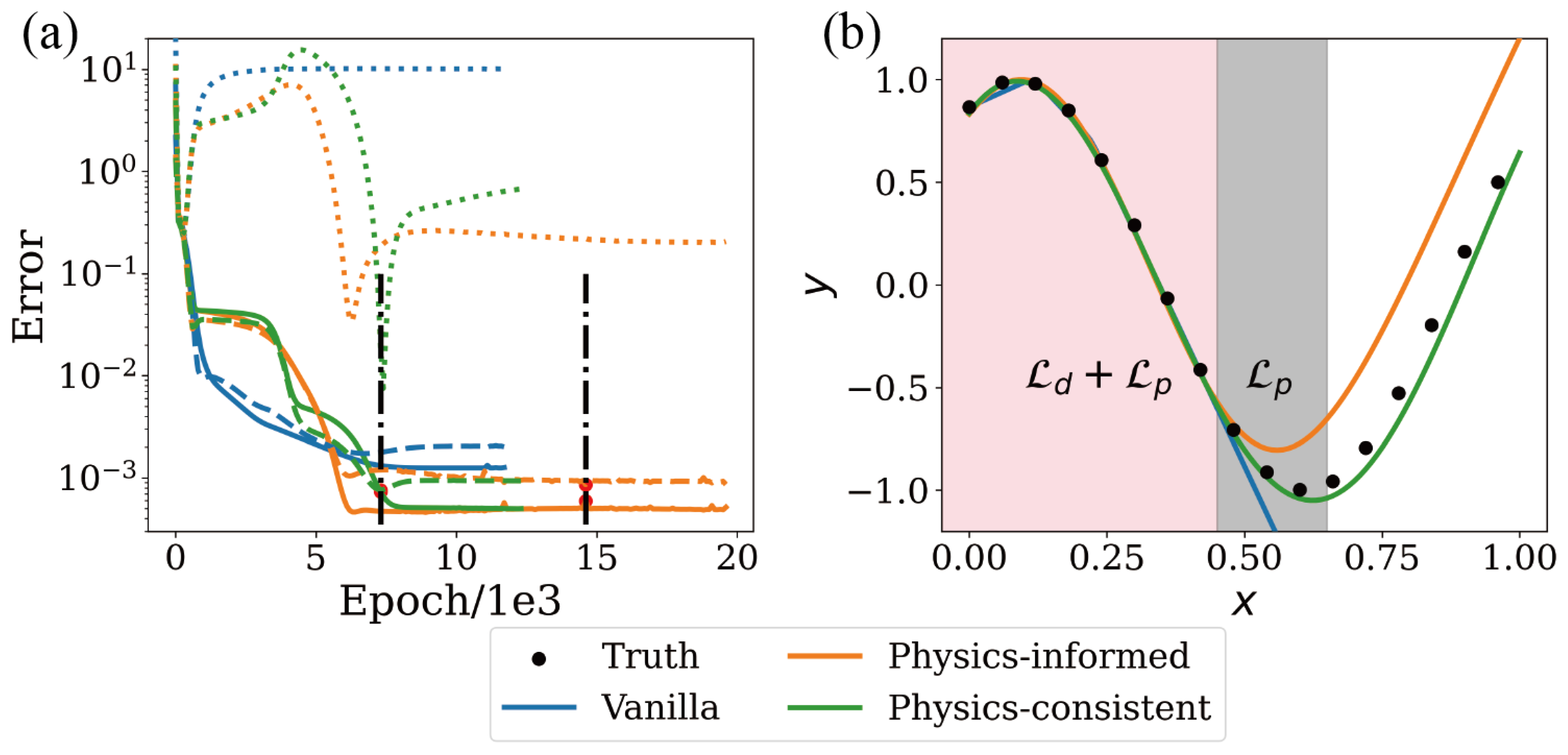
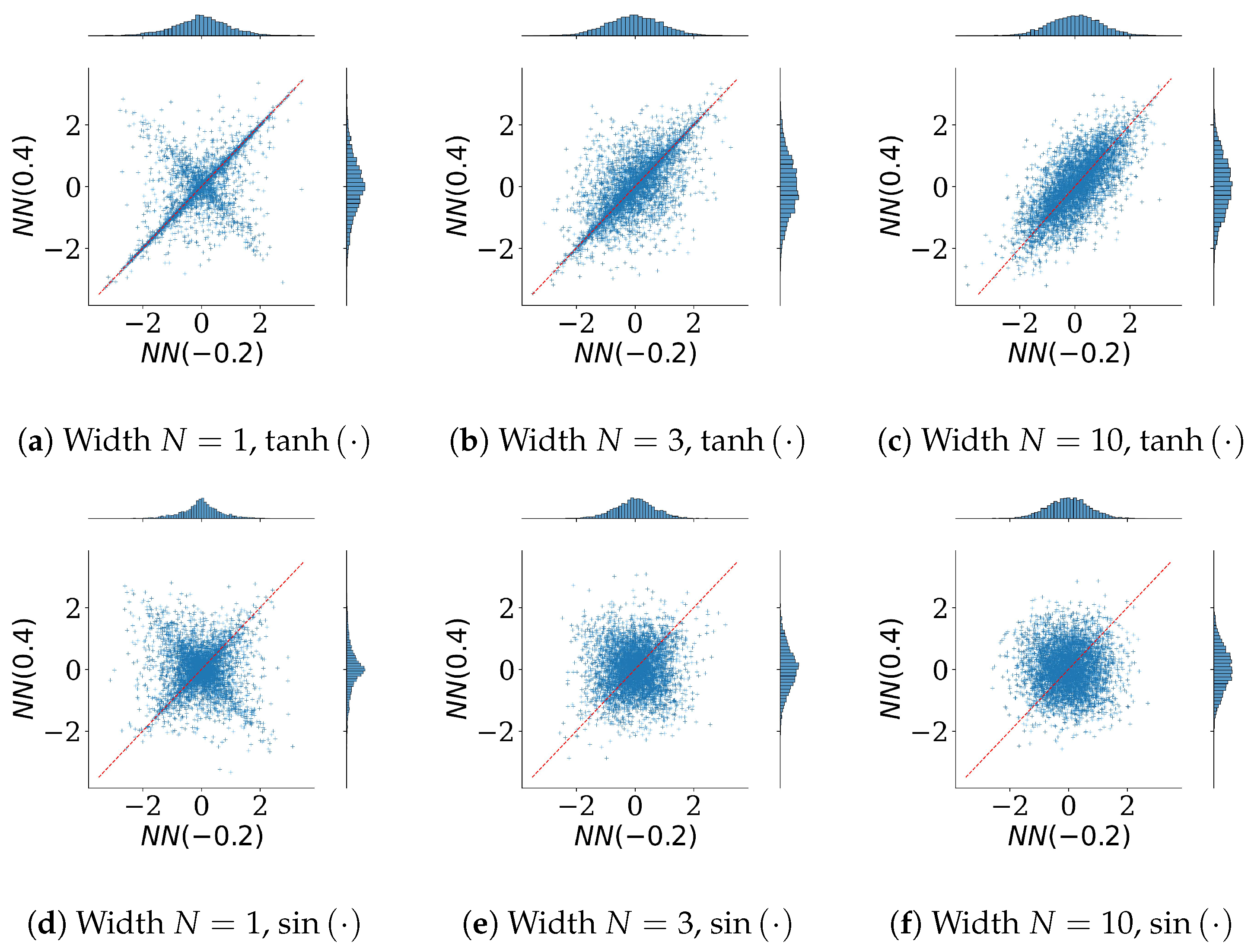
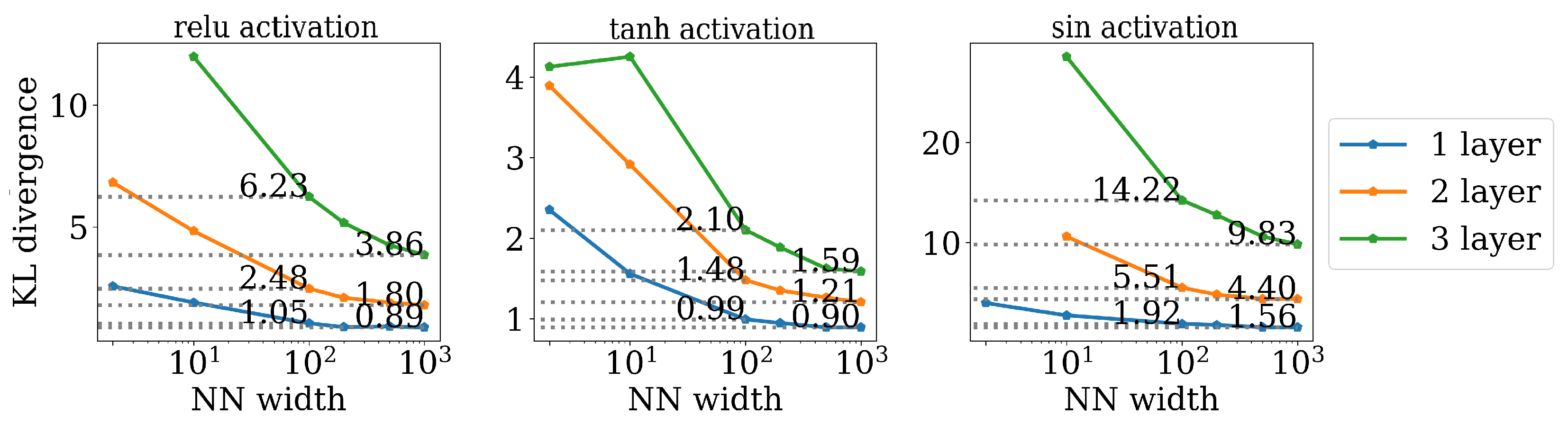
4. Experiments
4.1. Generalization
4.2. Convergence to Gaussian as a Function of Network Width
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ranftl, S.; von der Linden, W. Bayesian Surrogate Analysis and Uncertainty Propagation. Phys. Sci. Forum 2021, 3, 6. [Google Scholar] [CrossRef]
- Ranftl, S.; Rolf-Pissarczyk, M.; Wolkerstorfer, G.; Pepe, A.; Egger, J.; von der Linden, W.; Holzapfel, G.A. Stochastic modeling of inhomogeneities in the aortic wall and uncertainty quantification using a Bayesian encoder–decoder surrogate. Comput. Methods Appl. Mech. Eng. 2022, 401, 115594. [Google Scholar] [CrossRef]
- Ranftl, S. A Connection between Probability, Physics and Neural Networks. Phys. Sci. Forum 2022, 5, 11. [Google Scholar] [CrossRef]
- Dong, A. Kriging Variables that Satisfy the Partial Differential Equation ΔZ = Y. In Geostatistics: Proceedings of the Third International Geostatistics Congress September 5–9, 1988; Armstrong, M., Ed.; Springer: Dordrecht, The Netherlands, 1989; Volume 4, pp. 237–248. [Google Scholar] [CrossRef]
- van den Boogaart, K.G. Kriging for processes solving partial differential equations. In Proceedings of the Conference of the International Association for Mathematical Geology (IAMG), Cancun, Mexico, 6–12 September 2001. [Google Scholar]
- Albert, C.G. Gaussian processes for data fulfilling linear differential equations. Proceedings 2019, 33, 5. [Google Scholar] [CrossRef]
- Lange-Hegermann, M. Algorithmic linearly constrained Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Härkönen, M.; Lange-Hegermann, M.; Raiţă, B. Gaussian Process Priors for Systems of Linear Partial Differential Equations with Constant Coefficients. arXiv 2022, arXiv:2212.14319. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Networks. Chapter 2: Priors on Infinite Networks. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 1996. [Google Scholar] [CrossRef]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L.; Perdikaris, P.; Wang, S.; Yang, L. Physics-informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- O’Hagan, A. Curve Fitting and Optimal Design for Prediction. J. R. Stat. Soc. Ser. B (Methodol.) 1978, 40, 1–24. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Eberle, V.; Frank, P.; Stadler, J.; Streit, S.; Enßlin, T. Efficient Representations of Spatially Variant Point Spread Functions with Butterfly Transforms in Bayesian Imaging Algorithms. Phys. Sci. Forum 2022, 5, 33. [Google Scholar] [CrossRef]
- Bilionis, I.; Zabaras, N.; Konomi, B.A.; Lin, G. Multi-output separable Gaussian process: Towards an efficient, fully Bayesian paradigm for uncertainty quantification. J. Comput. Phys. 2013, 241, 212–239. [Google Scholar] [CrossRef]
- Schöbi, R.; Sudret, B.; Wiart, J. Polynomial-chaos-based Kriging. Int. J. Uncertain. Quantif. 2015, 5, 171–193. [Google Scholar] [CrossRef]
- Duvenaud, D.K. Automatic Model Construction with Gaussian Processes. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2014. [Google Scholar] [CrossRef]
- Swiler, L.P.; Gulian, M.; Frankel, A.L.; Safta, C.; Jakeman, J.D. A Survey of Constrained Gaussian Process Regression: Approaches and Implementation Challenges. J. Mach. Learn. Model. Comput. 2020, 1, 119–156. [Google Scholar] [CrossRef]
- Jidling, C.; Wahlstrom, N.; Wills, A.; Schön, T.B. Linearly Constrained Gaussian Processes. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Graepel, T. Solving Noisy Linear Operator Equations by Gaussian Processes: Application to Ordinary and Partial Differential Equations. In Proceedings of the ICML, Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Gulian, M.; Frankel, A.L.; Swiler, L.P. Gaussian process regression constrained by boundary value problems. Comput. Methods Appl. Mech. Eng. 2022, 388, 114117. [Google Scholar] [CrossRef]
- Särkkä, S. Linear Operators and Stochastic Partial Differential Equations in Gaussian Process Regression. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN, Espoo, Finland, 14–17 June 2011; Springer: Berlin, Germany, 2011; pp. 151–158. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Machine learning of linear differential equations using Gaussian processes. J. Comput. Phys. 2017, 348, 683–693. [Google Scholar] [CrossRef]
- Álvarez, M.A.; Luengo, D.; Lawrence, N.D. Linear latent force models using gaussian processes. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2693–2705. [Google Scholar] [CrossRef] [PubMed]
- López-Lopera, A.F.; Durrande, N.; Álvarez, M.A. Physically-inspired Gaussian process models for post-transcriptional regulation in Drosophila. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 656–666. [Google Scholar] [CrossRef]
- Chen, Y.; Hosseini, B.; Owhadi, H.; Stuart, A.M. Solving and learning nonlinear PDEs with Gaussian processes. J. Comput. Phys. 2021, 447, 110668. [Google Scholar] [CrossRef]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef] [PubMed]
- Jagtap, A.D.; Karniadakis, G.E. How important are activation functions in regression and classification? A survey, performance comparison, and future directions. J. Mach. Learn. Model. Comput. 2022, 4, 21–75. [Google Scholar] [CrossRef]
- Williams, C.K. Computing with infinite networks. In Proceedings of the Advances in Neural Information Processing Systems 9 (NIPS 1996), Denver, CO, USA, 2–5 December 1996. [Google Scholar]
- Tsuchida, R.; Roosta-Khorasani, F.; Gallagher, M. Invariance of weight distributions in rectified MLPs. In Proceedings of the ICML, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Cho, Y.; Saul, L.K. Kernel methods for deep learning. In Proceedings of the Advances in Neural Information Processing Systems 22 (NIPS 2009), Vancouver, BC, Canada, 7–10 December 2009. [Google Scholar]
- Pearce, T.; Tsuchida, R.; Zaki, M.; Brintrup, A.; Neely, A. Expressive priors in Bayesian neural networks: Kernel combinations and periodic functions. In Proceedings of the UAI, Tel Aviv, Israel, 22–25 July 2019; PMLR: New York, NY, USA, 2020. [Google Scholar]
- Hazan, T.; Jaakkola, T. Steps Toward Deep Kernel Methods from Infinite Neural Networks. arXiv 2015, arXiv:1508.05133. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Dissanayake, M.W.M.G.; Phan-Thien, N. Neural-network-based approximations for solving partial differential equations. Commun. Numer. Methods Eng. 1994, 10, 195–201. [Google Scholar] [CrossRef]
- Lagaris, I.E.; Likas, A.; Fotiadis, D.I. Artificial neural networks for solving ordinary and partial differential equations. IEEE Trans. Neural Netw. 1998, 9, 987–1000. [Google Scholar] [CrossRef] [PubMed]
- Yang, G. Tensor Programs I: Wide feedforward or recurrent neural networks of any architecture are gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Novak, R.; Xiao, L.; Lee, J.; Bahri, Y.; Yang, G.; Hron, J.; Abolafia, D.A.; Pennington, J.; Sohl-Dickstein, J. Bayesian deep convolutional networks with many channels are Gaussian processes. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sun, X.; Kim, S.; Choi, J.i. Recurrent neural network-induced Gaussian process. Neurocomputing 2022, 509, 75–84. [Google Scholar] [CrossRef]
- Hron, J.; Bahri, Y.; Sohl-Dickstein, J.; Novak, R. Infinite attention: NNGP and NTK for deep attention networks. In Proceedings of the ICML, Online, 12–18 July 2020. [Google Scholar]
- Jacot, A.; Gabriel, F.; Hongler, C. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Rahimi, A.; Recht, B. Random Features for Large-Scale Kernel Machines. In Proceedings of the Advances in Neural Information Processing Systems 20 (NIPS 2007), Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Demirtas, M.; Halverson, J.; Maiti, A.; Schwartz, M.D.; Stoner, K. Neural Network Field Theories: Non-Gaussianity, Actions, and Locality. arXiv 2023, arXiv:2307.03223. [Google Scholar]
- Schaback, R.; Wendland, H. Kernel techniques: From machine learning to meshless methods. Acta Numer. 2006, 15, 543–639. [Google Scholar] [CrossRef]
- Kamihigashi, T. Interchanging a limit and an integral: Necessary and sufficient conditions. J. Inequalities Appl. 2020, 2020, 243. [Google Scholar] [CrossRef]
- Wang, S.; Yu, X.; Perdikaris, P. When and why PINNs fail to train: A neural tangent kernel perspective. J. Comput. Phys. 2022, 449, 110768. [Google Scholar] [CrossRef]
- Albert, C.G. Physics-informed transfer path analysis with parameter estimation using Gaussian Processes. Int. Congr. Acoust. 2019, 23, 459–466. [Google Scholar] [CrossRef]
- Rohrhofer, F.M.; Posch, S.; Geiger, B.C. On the Pareto Front of Physics-Informed Neural Networks. arXiv 2021, arXiv:2105.00862. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ranftl, S.; Guan, S. Physics-Consistency Condition for Infinite Neural Networks and Experimental Characterization. Phys. Sci. Forum 2023, 9, 15. https://doi.org/10.3390/psf2023009015
Ranftl S, Guan S. Physics-Consistency Condition for Infinite Neural Networks and Experimental Characterization. Physical Sciences Forum. 2023; 9(1):15. https://doi.org/10.3390/psf2023009015
Chicago/Turabian StyleRanftl, Sascha, and Shaoheng Guan. 2023. "Physics-Consistency Condition for Infinite Neural Networks and Experimental Characterization" Physical Sciences Forum 9, no. 1: 15. https://doi.org/10.3390/psf2023009015
APA StyleRanftl, S., & Guan, S. (2023). Physics-Consistency Condition for Infinite Neural Networks and Experimental Characterization. Physical Sciences Forum, 9(1), 15. https://doi.org/10.3390/psf2023009015