
Flow Annealed Kalman Inversion for Gradient-Free Inference in Bayesian Inverse Problems †


Abstract
:1. Introduction
2. Methods
2.1. Regularized Ensemble Kalman Inversion
| Algorithm 1 Ensemble Kalman Inversion |
|
2.2. Normalizing Flows
2.3. Flow Annealed Kalman Inversion
| Algorithm 2 Flow Annealed Kalman Inversion |
|
3. Results
3.1. Rosenbrock
3.2. Stochastic Lorenz System
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Iglesias, M.A.; Law, K.J.; Stuart, A.M. Ensemble Kalman methods for inverse problems. Inverse Probl. 2013, 29, 045001. [Google Scholar] [CrossRef]
- Iglesias, M.A. A regularizing iterative ensemble Kalman method for PDE-constrained inverse problems. Inverse Probl. 2016, 32, 025002. [Google Scholar] [CrossRef]
- Schillings, C.; Stuart, A.M. Analysis of the ensemble Kalman filter for inverse problems. SIAM J. Numer. Anal. 2017, 55, 1264–1290. [Google Scholar] [CrossRef]
- Chada, N.K.; Iglesias, M.A.; Roininen, L.; Stuart, A.M. Parameterizations for ensemble Kalman inversion. Inverse Probl. 2018, 34, 055009. [Google Scholar] [CrossRef]
- Schillings, C.; Stuart, A.M. Convergence analysis of ensemble Kalman inversion: The linear, noisy case. Appl. Anal. 2018, 97, 107–123. [Google Scholar] [CrossRef]
- Iglesias, M.; Yang, Y. Adaptive regularisation for ensemble Kalman inversion. Inverse Probl. 2021, 37, 025008. [Google Scholar] [CrossRef]
- Huang, D.Z.; Schneider, T.; Stuart, A.M. Iterated Kalman methodology for inverse problems. J. Comput. Phys. 2022, 463, 111262. [Google Scholar] [CrossRef]
- Huang, D.Z.; Huang, J.; Reich, S.; Stuart, A.M. Efficient derivative-free Bayesian inference for large-scale inverse problems. Inverse Probl. 2022, 38, 125006. [Google Scholar] [CrossRef]
- Geyer, C.J. Practical Markov Chain Monte Carlo. Stat. Sci. 1992, 7, 473–483. [Google Scholar] [CrossRef]
- Gelman, A.; Gilks, W.R.; Roberts, G.O. Weak convergence and optimal scaling of random walk Metropolis algorithms. Ann. Appl. Probab. 1997, 7, 110–120. [Google Scholar] [CrossRef]
- Cotter, S.L.; Roberts, G.O.; Stuart, A.M.; White, D. MCMC Methods for Functions: Modifying Old Algorithms to Make Them Faster. Stat. Sci. 2013, 28, 424–446. [Google Scholar] [CrossRef]
- Del Moral, P.; Doucet, A.; Jasra, A. Sequential Monte Carlo Samplers. J. R. Stat. Soc. Ser. B Stat. Methodol. 2006, 68, 411–436. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. Ocean. 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Xiao, H.; Wu, J.L.; Wang, J.X.; Sun, R.; Roy, C. Quantifying and reducing model-form uncertainties in Reynolds-averaged Navier–Stokes simulations: A data-driven, physics-informed Bayesian approach. J. Comput. Phys. 2016, 324, 115–136. [Google Scholar] [CrossRef]
- Schneider, T.; Lan, S.; Stuart, A.; Teixeira, J. Earth system modeling 2.0: A blueprint for models that learn from observations and targeted high-resolution simulations. Geophys. Res. Lett. 2017, 44, 12–396. [Google Scholar] [CrossRef]
- Kovachki, N.B.; Stuart, A.M. Ensemble Kalman inversion: A derivative-free technique for machine learning tasks. Inverse Probl. 2019, 35, 095005. [Google Scholar] [CrossRef]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017; Conference Track Proceedings. Available online: https://openreview.net/ (accessed on 30 June 2023).
- Papamakarios, G.; Murray, I.; Pavlakou, T. Masked Autoregressive Flow for Density Estimation. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2017; pp. 2338–2347. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative Flow with Invertible 1x1 Convolutions. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; NeurIPS: La Jolla, CA, USA, 2018; pp. 10236–10245. [Google Scholar]
- Dai, B.; Seljak, U. Sliced Iterative Normalizing Flows. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Proceedings of Machine Learning Research. PMLR: New York, NY, USA, 2021; Volume 139, pp. 2352–2364. [Google Scholar]
- De Simon, L.; Iglesias, M.; Jones, B.; Wood, C. Quantifying uncertainty in thermophysical properties of walls by means of Bayesian inversion. Energy Build. 2018, 177, 220–245. [Google Scholar] [CrossRef]
- Iglesias, M.; Park, M.; Tretyakov, M. Bayesian inversion in resin transfer molding. Inverse Probl. 2018, 34, 105002. [Google Scholar] [CrossRef]
- Karamanis, M.; Beutler, F.; Peacock, J.A.; Nabergoj, D.; Seljak, U. Accelerating astronomical and cosmological inference with preconditioned Monte Carlo. Mon. Not. R. Astron. Soc. 2022, 516, 1644–1653. [Google Scholar] [CrossRef]
- Lorenz, E.N. Deterministic Nonperiodic Flow. J. Atmos. Sci. 1963, 20, 130–148. [Google Scholar] [CrossRef]
- Ambrogioni, L.; Lin, K.; Fertig, E.; Vikram, S.; Hinne, M.; Moore, D.; van Gerven, M. Automatic structured variational inference. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 13–15 April 2021; PMLR: New York, NY, USA, 2021; pp. 676–684. [Google Scholar]
- Villani, C. Optimal Transport—Old and New; Springer: Berlin/Heidelberg, Germany, 2008; Volume 338, pp. xxii+973. [Google Scholar]
- Zhang, L.; Carpenter, B.; Gelman, A.; Vehtari, A. Pathfinder: Parallel quasi-Newton variational inference. J. Mach. Learn. Res. 2022, 23, 13802–13850. [Google Scholar]
- Neal, R.M. MCMC using Hamiltonian dynamics. Handb. Markov Chain. Monte Carlo 2011, 2, 2. [Google Scholar]
- Hoffman, M.D.; Gelman, A. The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]



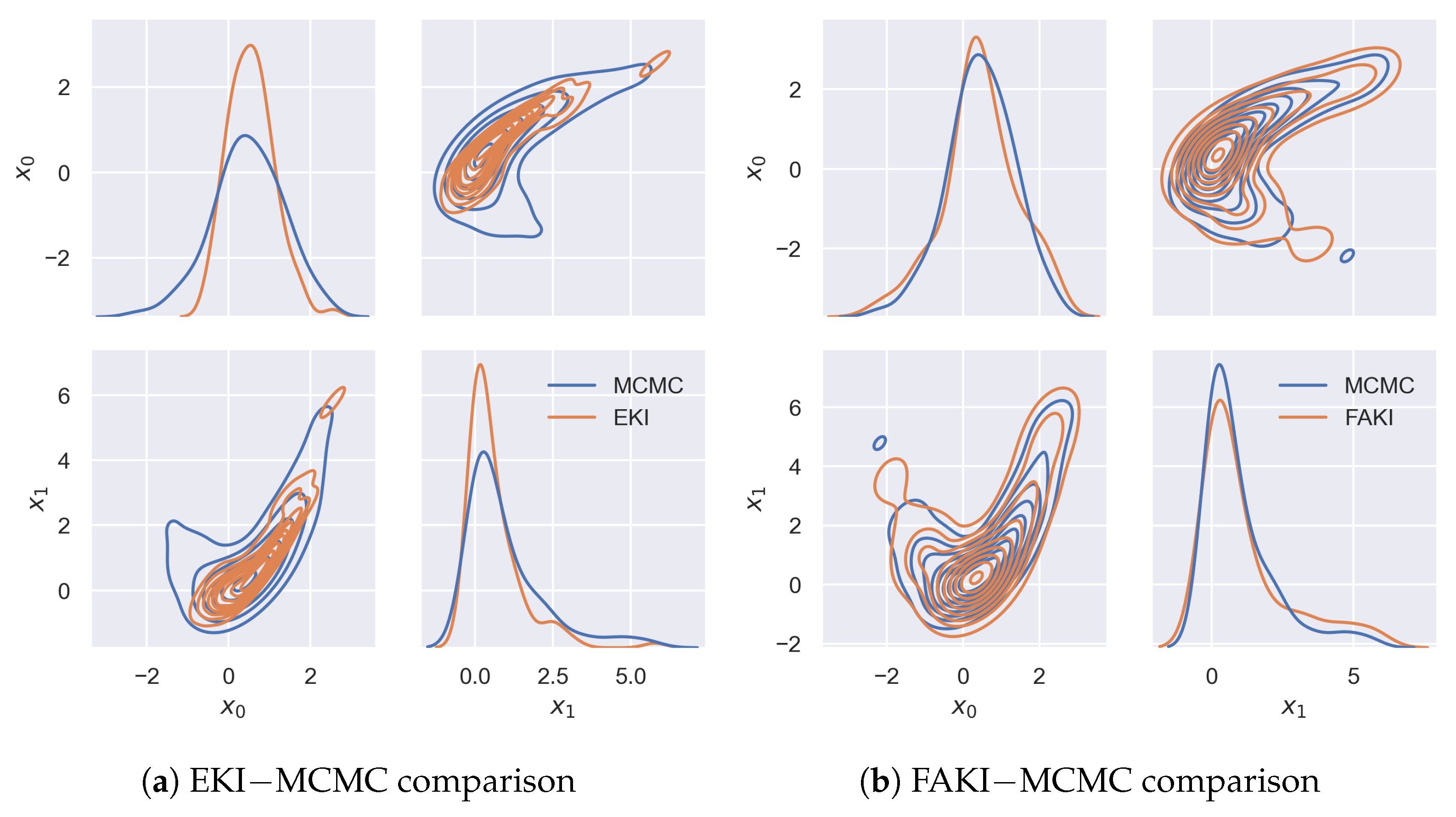{kind=link}
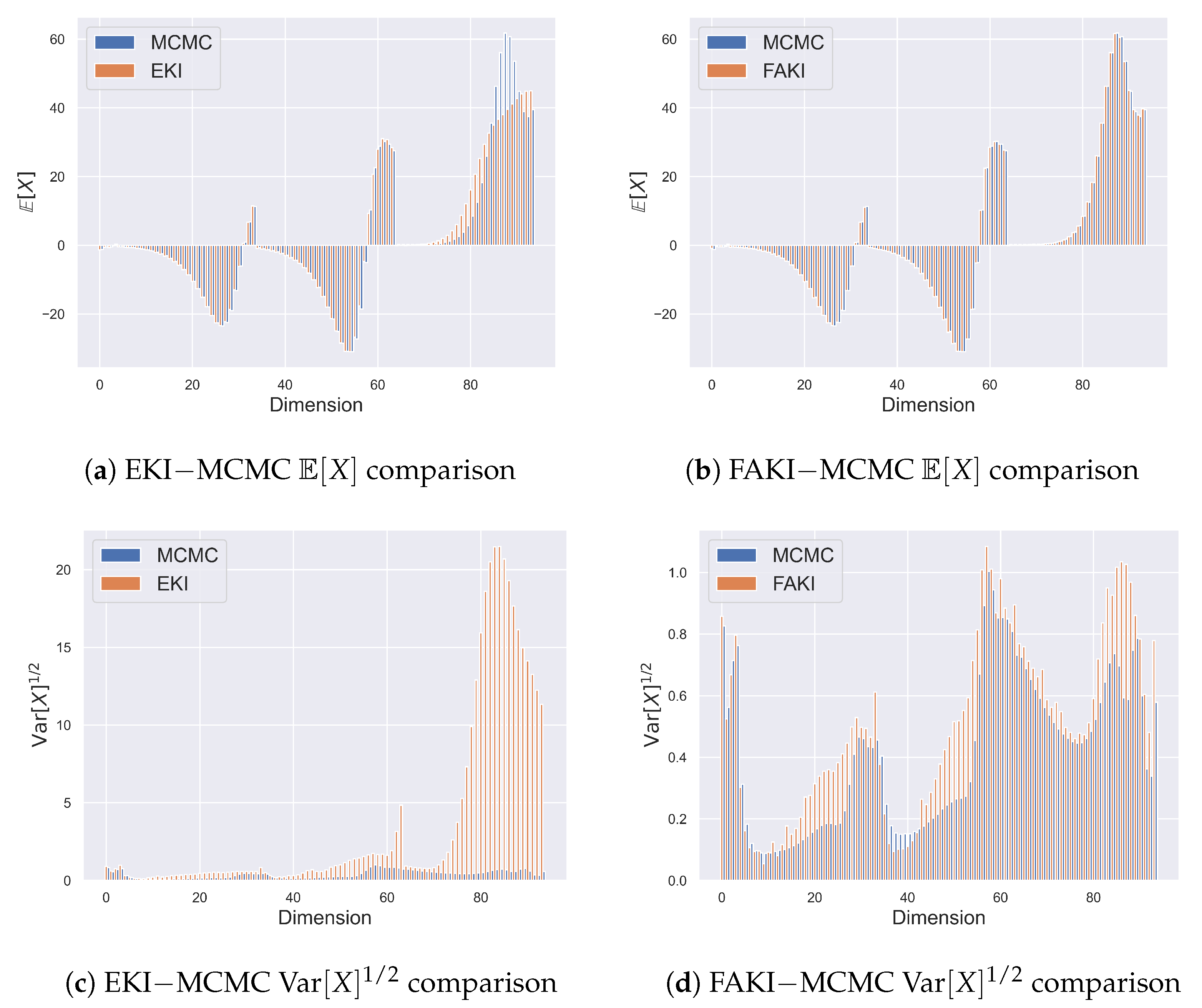{kind=link}
| Model | Algorithm | ||||
|---|---|---|---|---|---|
| Rosenbrock | EKI | 100 | 7.0 | 0.72 | 0.05 |
| Rosenbrock | FAKI | 34.0 | 7.0 | 0.43 | 0.14 |
| Lorenz | EKI | 10.0 | 0.0 | 69.8 | 1.08 |
| Lorenz | FAKI | 8.0 | 0.0 | 5.65 | 0.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grumitt, R.D.P.; Karamanis, M.; Seljak, U. Flow Annealed Kalman Inversion for Gradient-Free Inference in Bayesian Inverse Problems. Phys. Sci. Forum 2023, 9, 21. https://doi.org/10.3390/psf2023009021
Grumitt RDP, Karamanis M, Seljak U. Flow Annealed Kalman Inversion for Gradient-Free Inference in Bayesian Inverse Problems. Physical Sciences Forum. 2023; 9(1):21. https://doi.org/10.3390/psf2023009021
Chicago/Turabian StyleGrumitt, Richard D. P., Minas Karamanis, and Uroš Seljak. 2023. "Flow Annealed Kalman Inversion for Gradient-Free Inference in Bayesian Inverse Problems" Physical Sciences Forum 9, no. 1: 21. https://doi.org/10.3390/psf2023009021
APA StyleGrumitt, R. D. P., Karamanis, M., & Seljak, U. (2023). Flow Annealed Kalman Inversion for Gradient-Free Inference in Bayesian Inverse Problems. Physical Sciences Forum, 9(1), 21. https://doi.org/10.3390/psf2023009021