



Algorithms 2025, 18(1), 14; https://doi.org/10.3390/a18010014 - 2 Jan 2025
Viewed by 376
Abstract
►
Show Figures
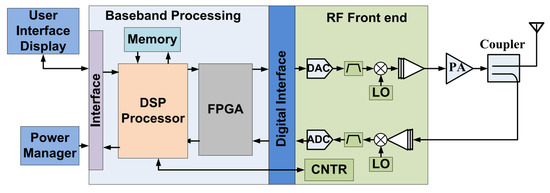
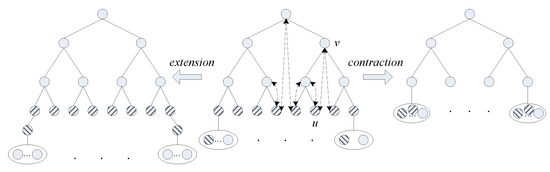
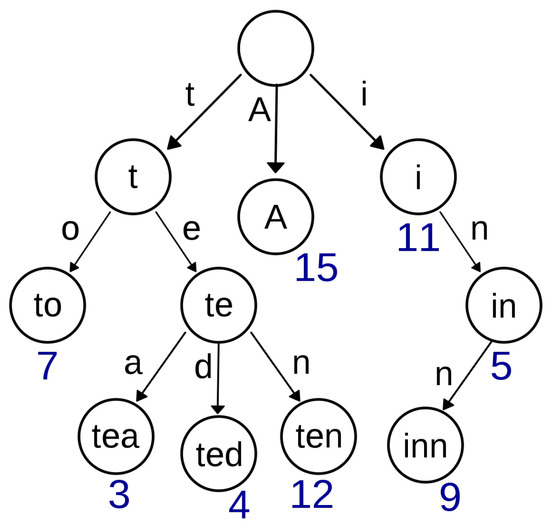
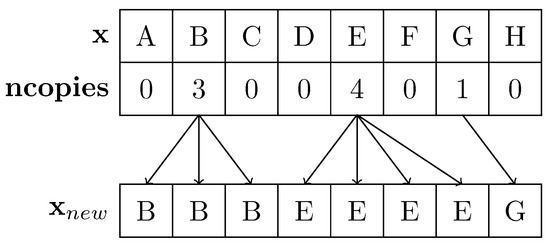
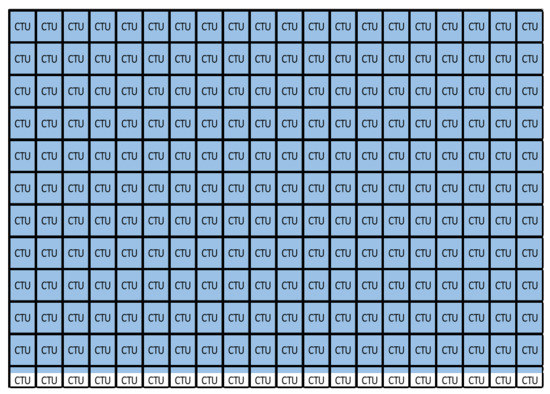
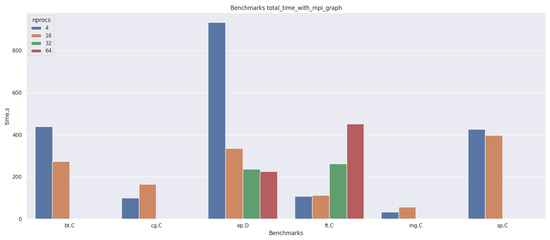
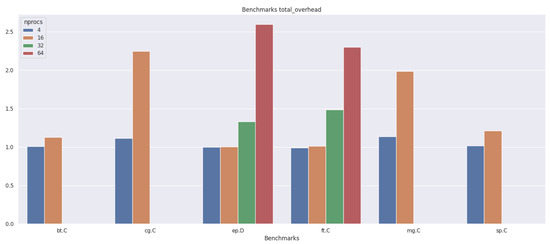
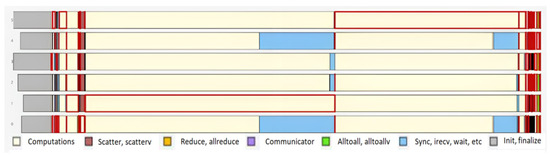
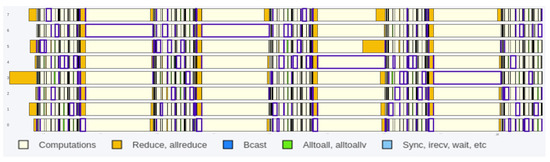
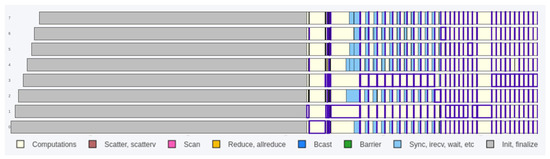
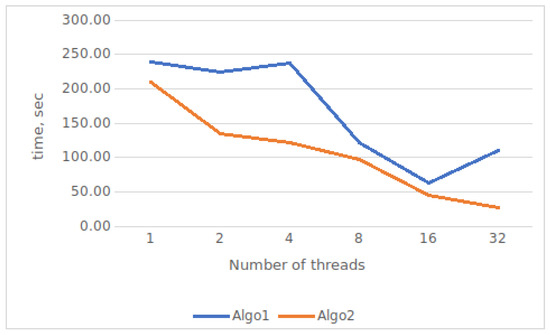
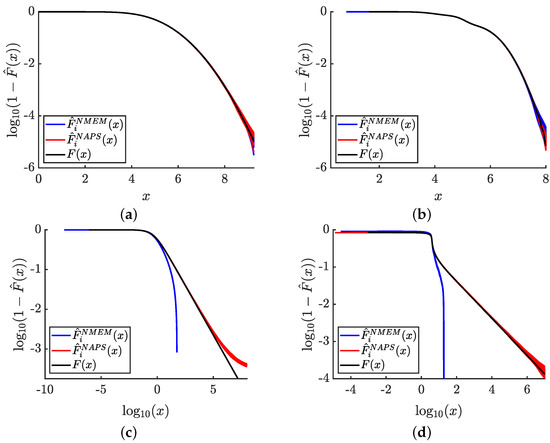
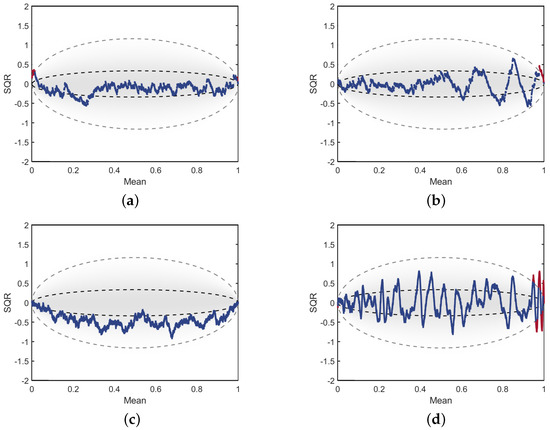
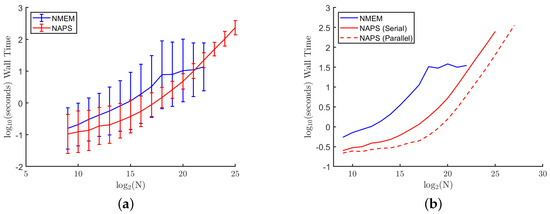
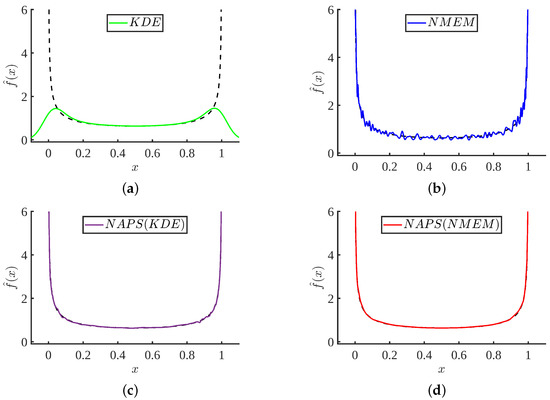
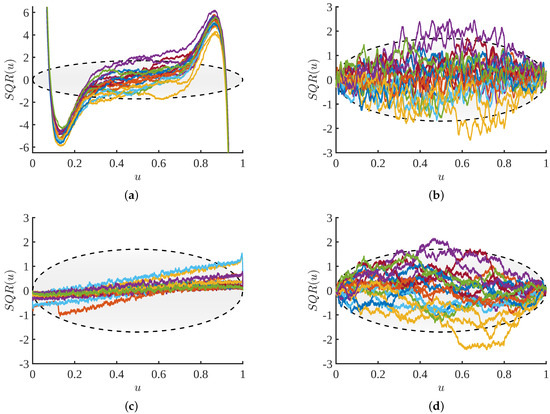
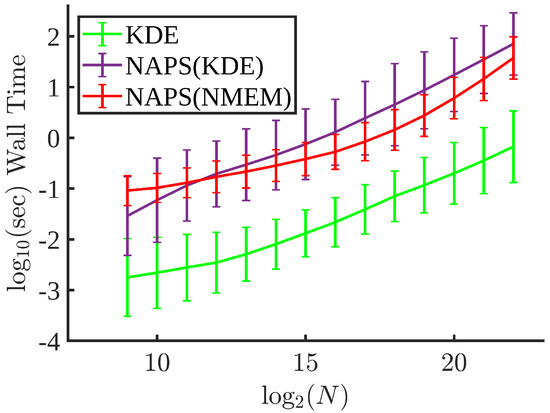
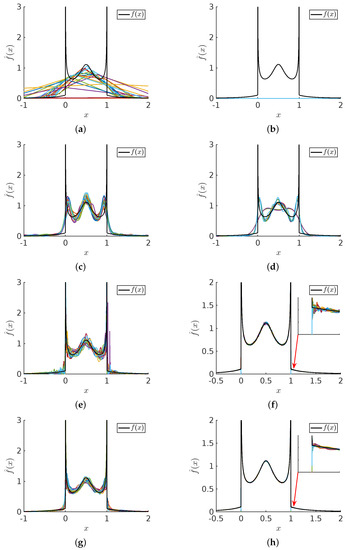
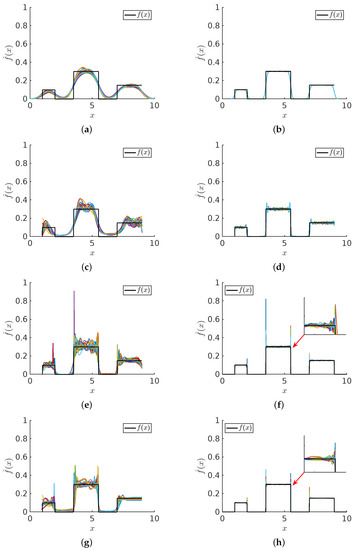
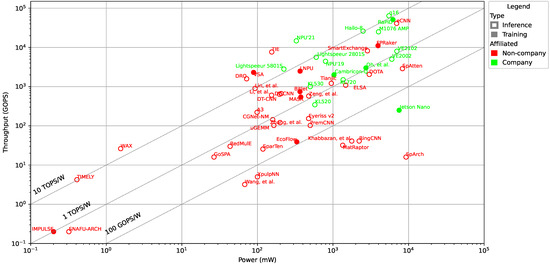
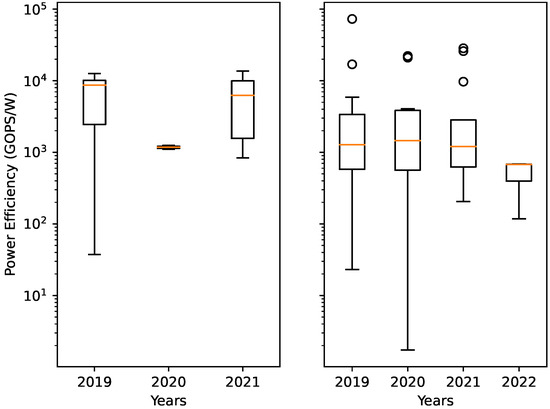
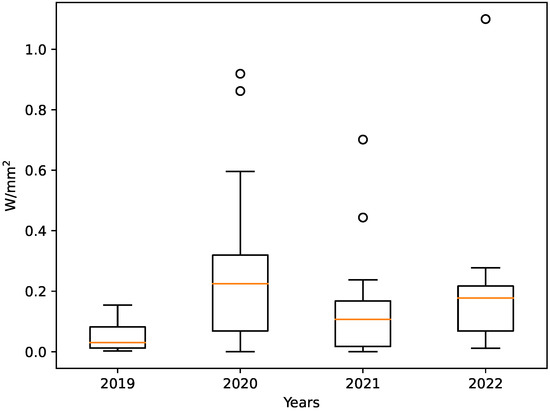
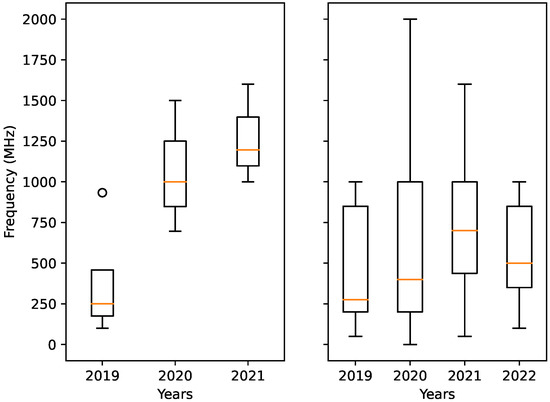
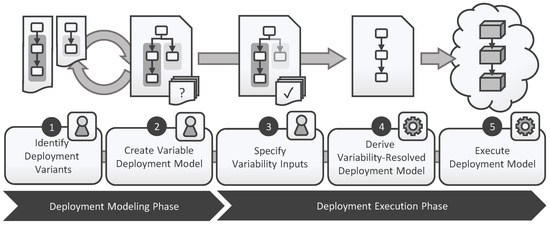
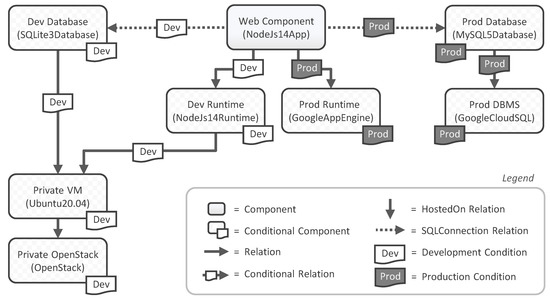
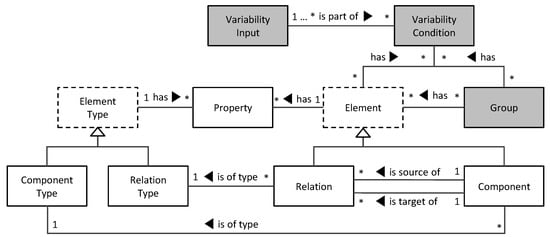
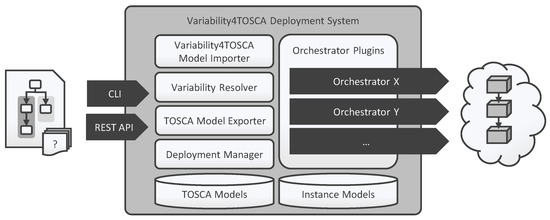
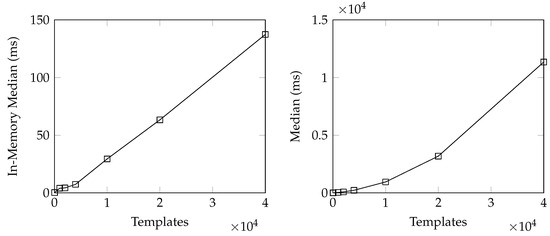
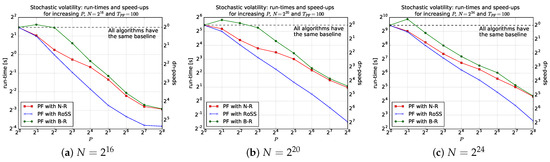
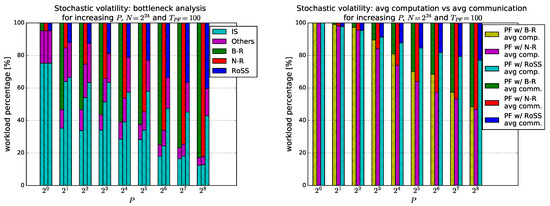
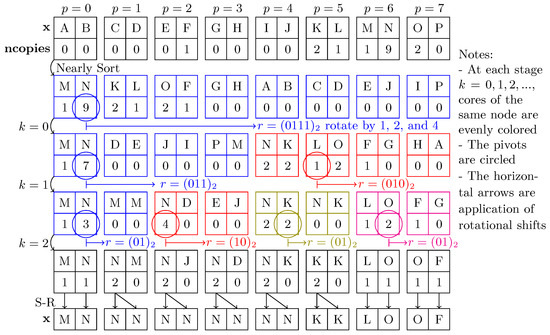
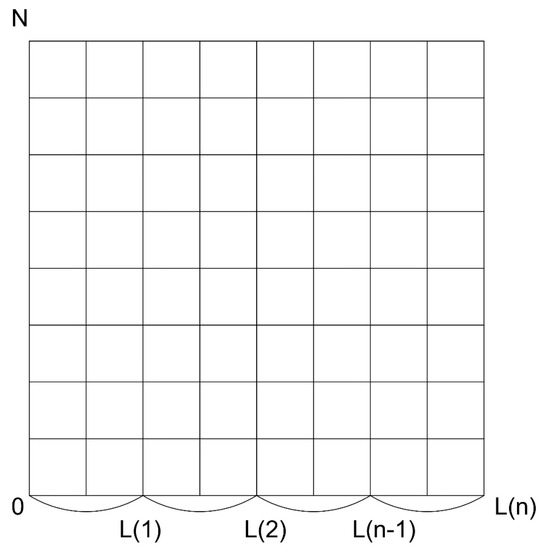
Bayesian approaches to decision trees (DTs) using Markov Chain Monte Carlo (MCMC) samplers have recently demonstrated state-of-the-art accuracy performance when it comes to training DTs to solve classification problems. Despite the competitive classification accuracy, MCMC requires a potentially long runtime to converge. A
[...] Read more.
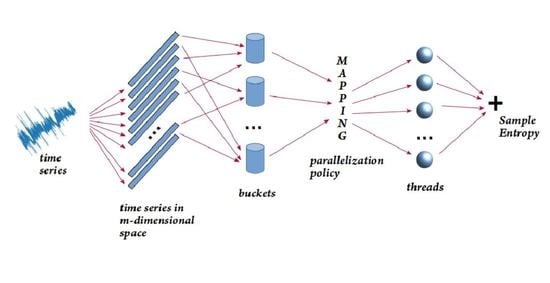
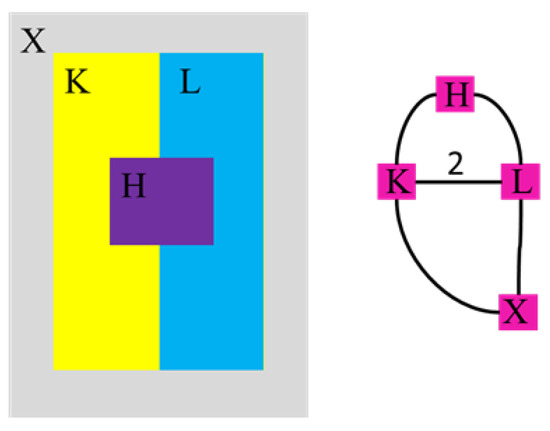
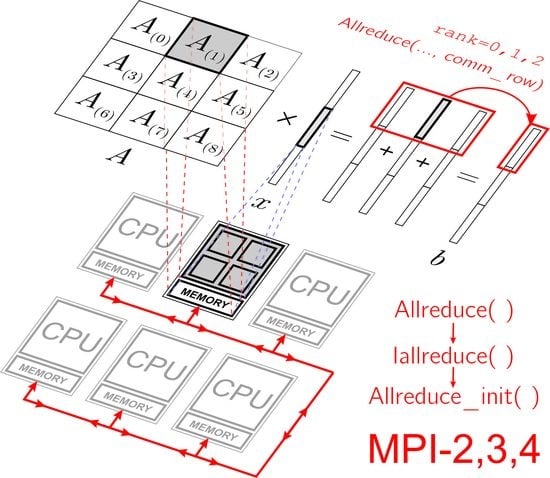
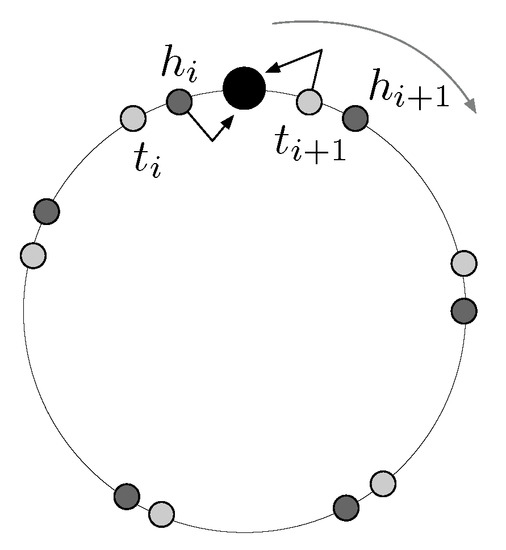
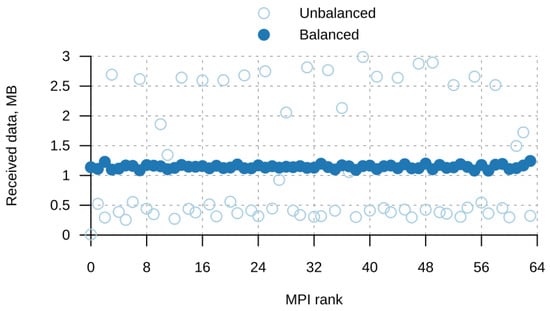
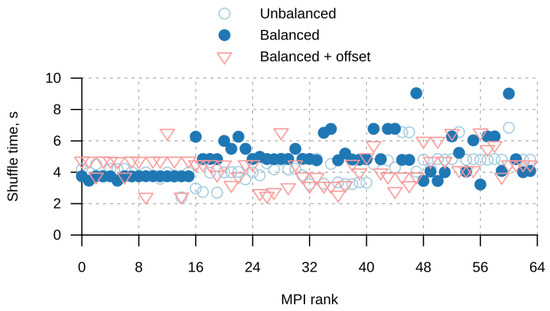
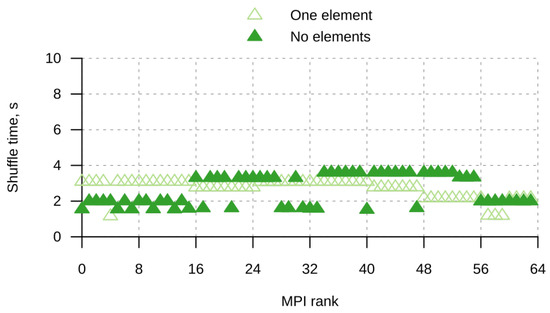
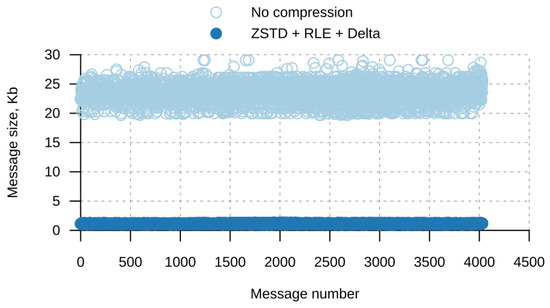
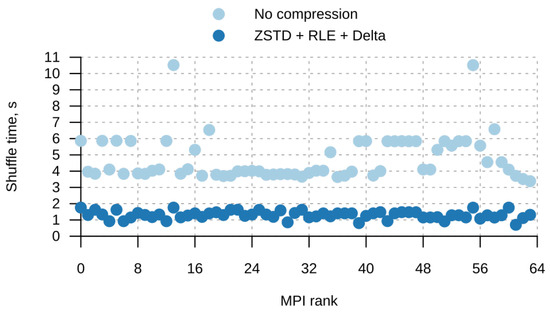
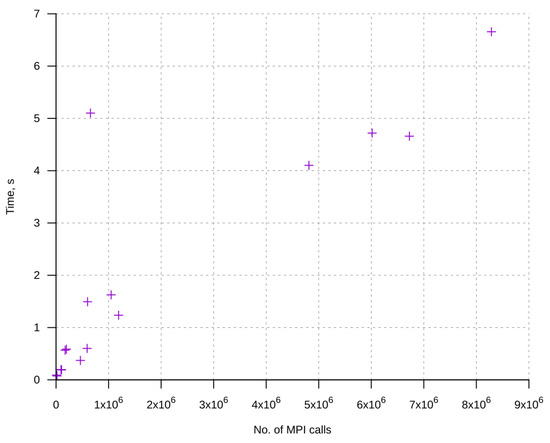
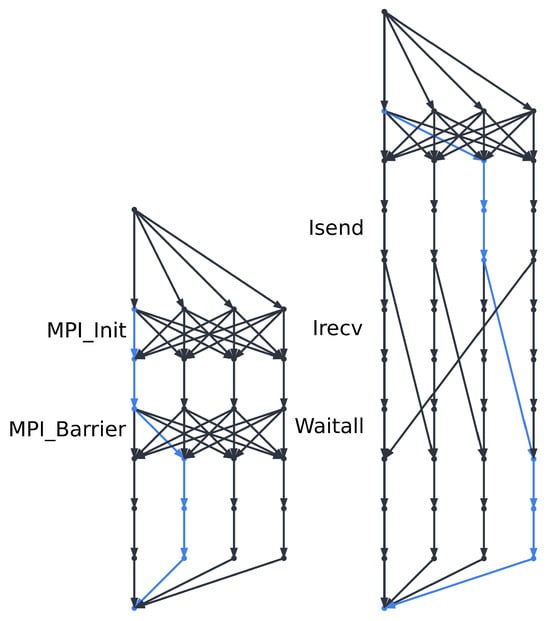
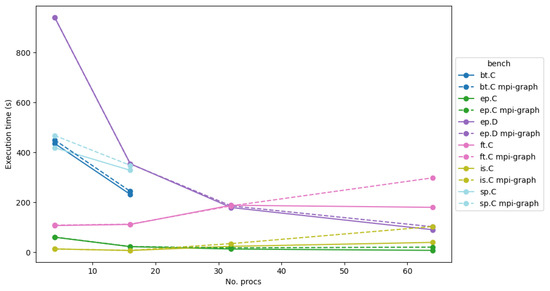
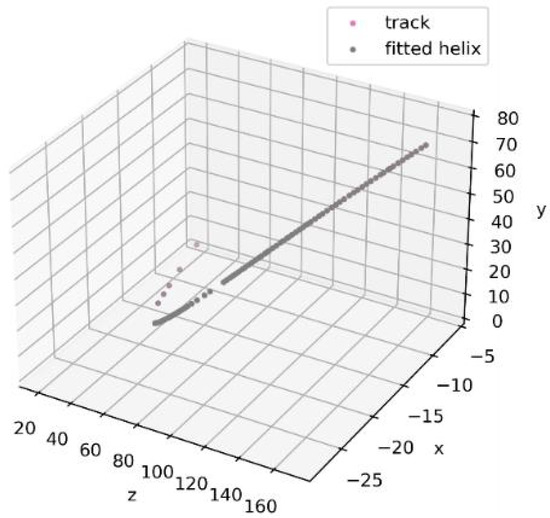
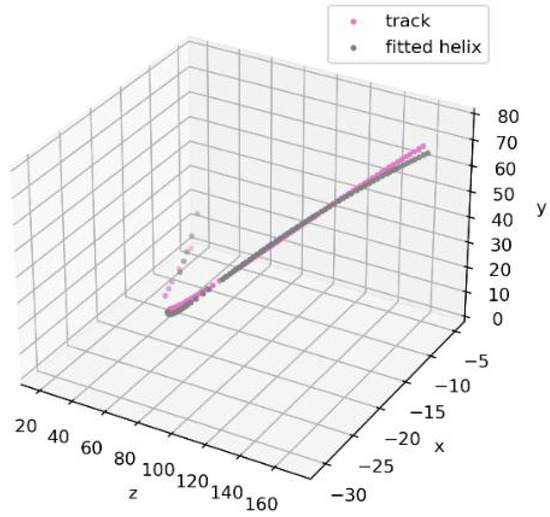
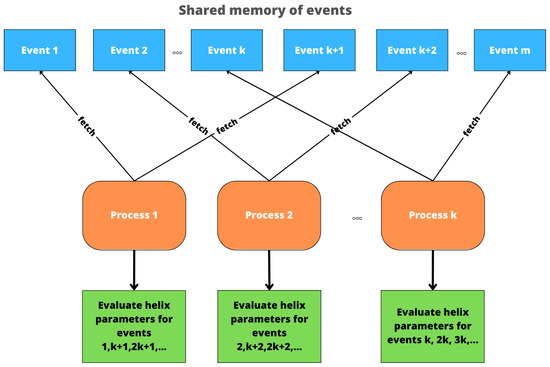
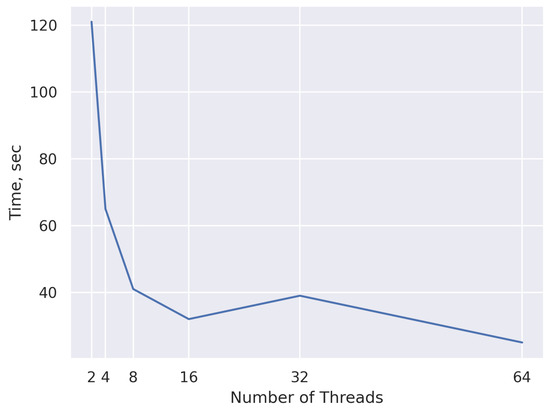
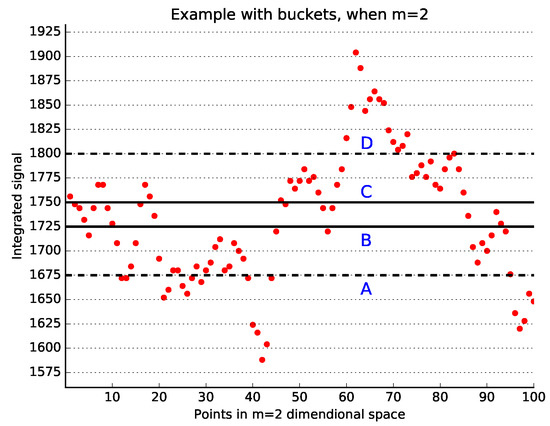
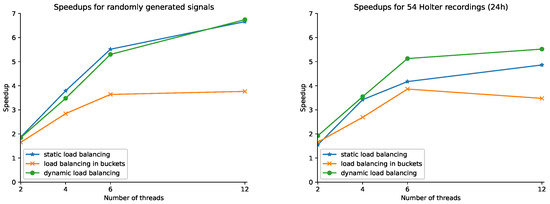
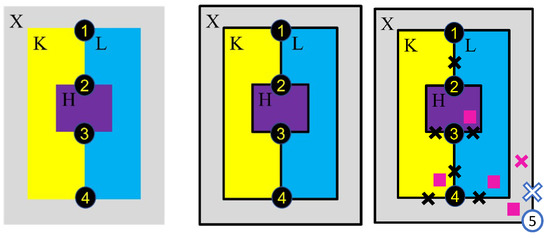
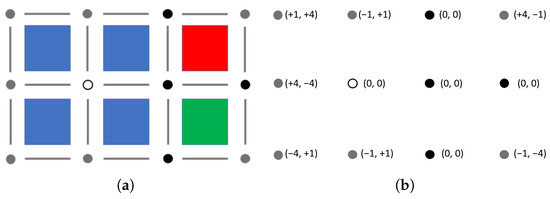
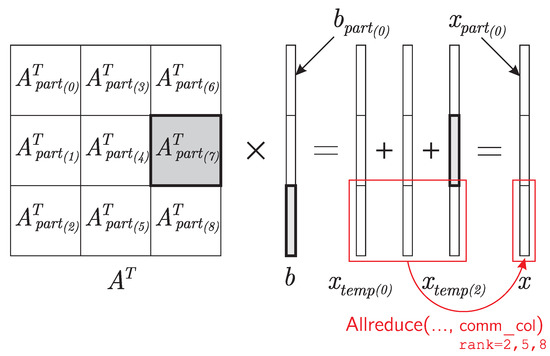
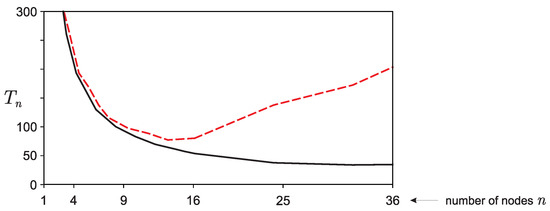
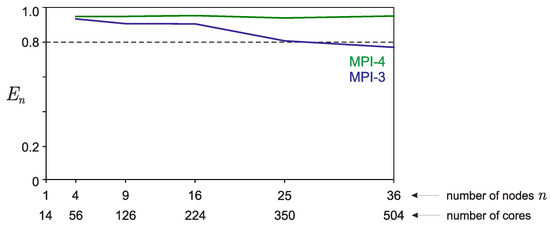
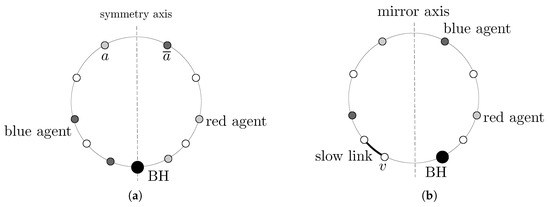
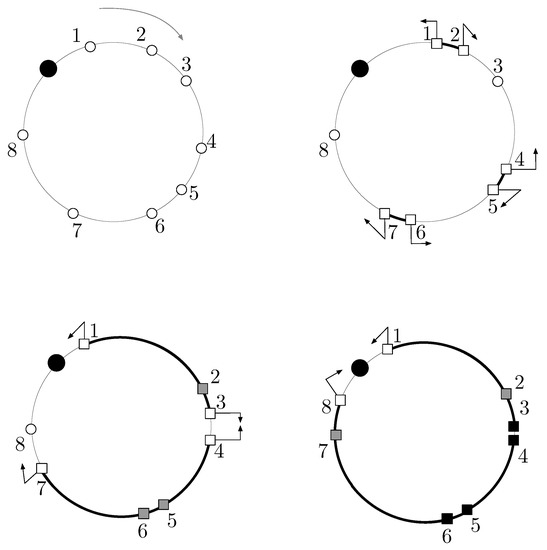
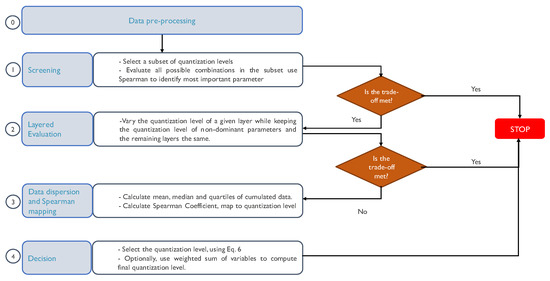
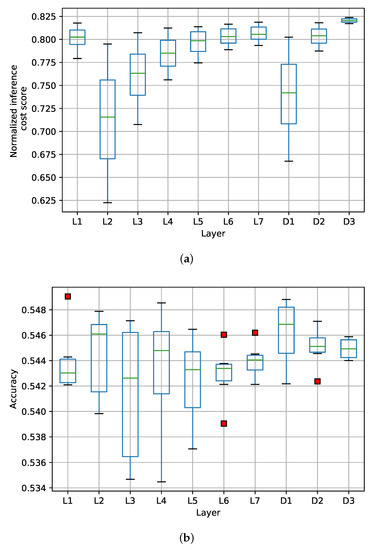
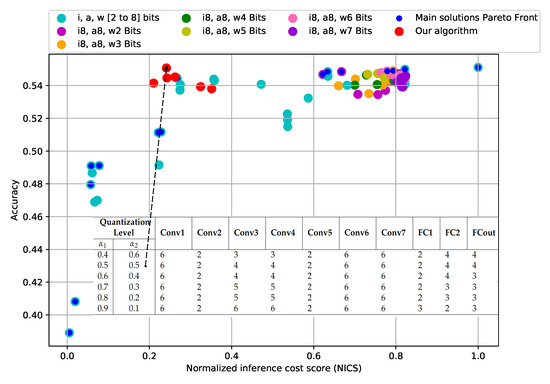
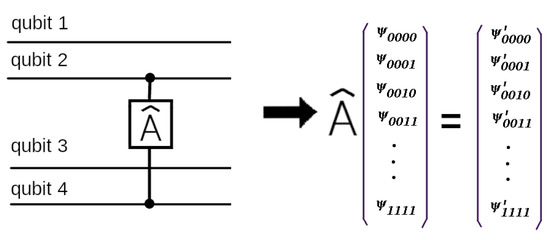
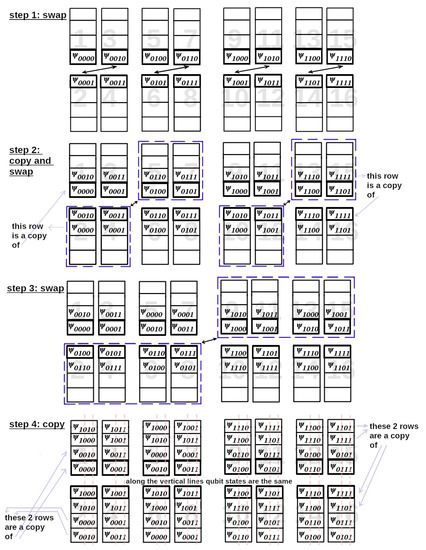
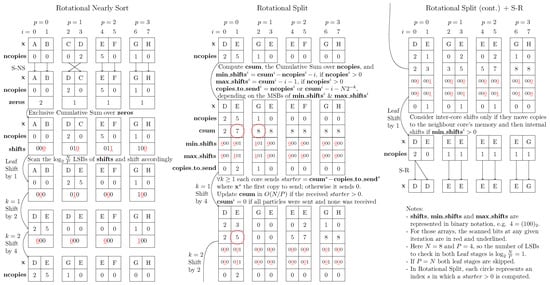
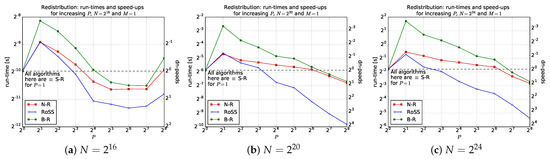
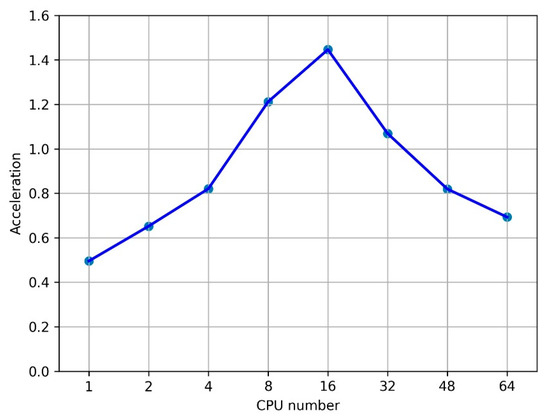
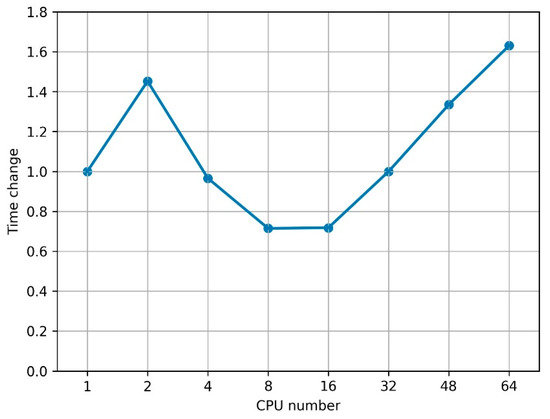
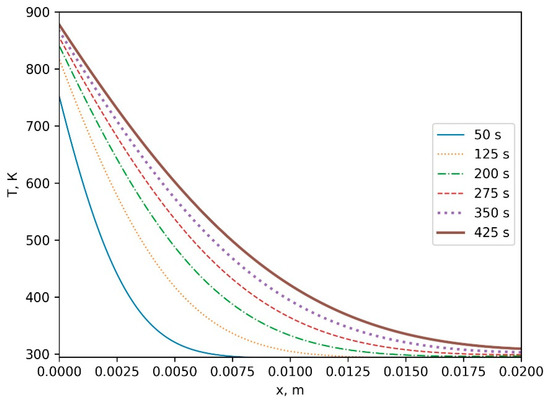
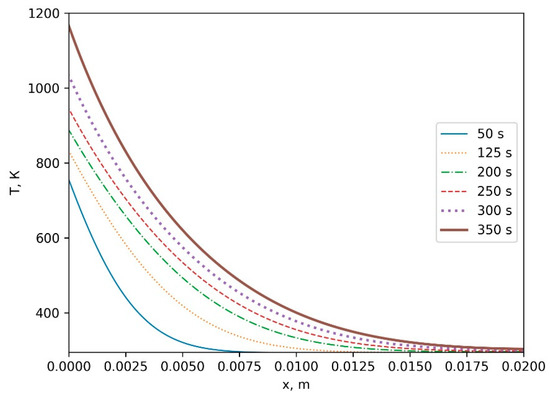
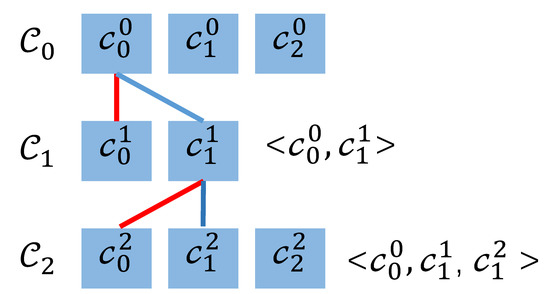
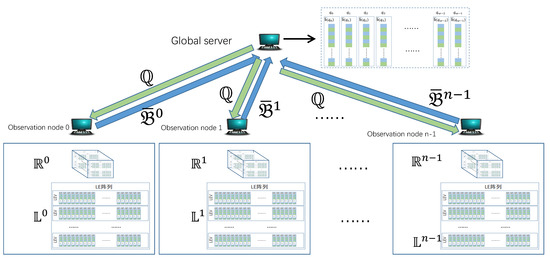
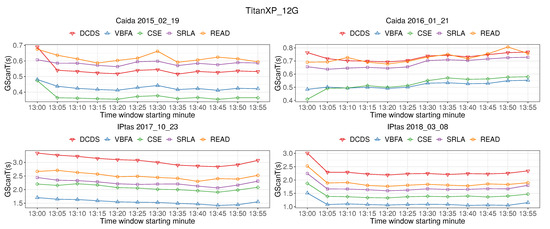
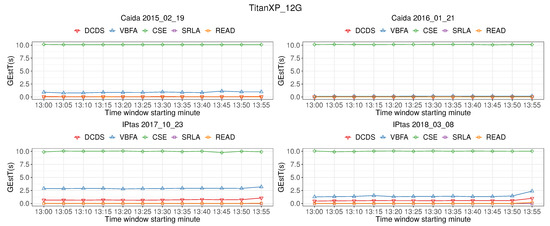
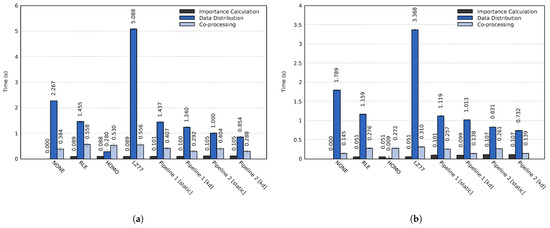
Bayesian approaches to decision trees (DTs) using Markov Chain Monte Carlo (MCMC) samplers have recently demonstrated state-of-the-art accuracy performance when it comes to training DTs to solve classification problems. Despite the competitive classification accuracy, MCMC requires a potentially long runtime to converge. A widely used approach to reducing an algorithm’s runtime is to employ modern multi-core computer architectures, either with shared memory (SM) or distributed memory (DM), and use parallel computing to accelerate the algorithm. However, the inherent sequential nature of MCMC makes it unsuitable for parallel implementation unless the accuracy is sacrificed. This issue is particularly evident in DM architectures, which normally provide access to larger numbers of cores than SM. Sequential Monte Carlo (SMC) samplers are a parallel alternative to MCMC, which do not trade off accuracy for parallelism. However, the performance of SMC samplers in the context of DTs is underexplored, and the parallelization is complicated by the challenges in parallelizing its bottleneck, namely redistribution, especially on variable-size data types such as DTs. In this work, we study the problem of parallelizing SMC in the context of DTs both on SM and DM. On both memory architectures, we show that the proposed parallelization strategies achieve asymptotically optimal

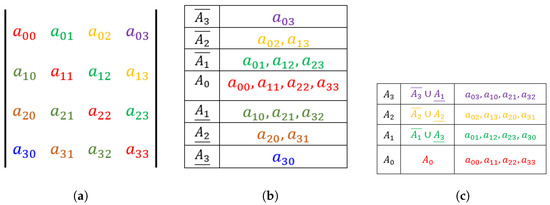
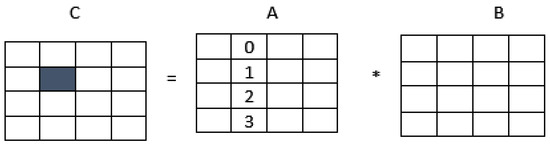
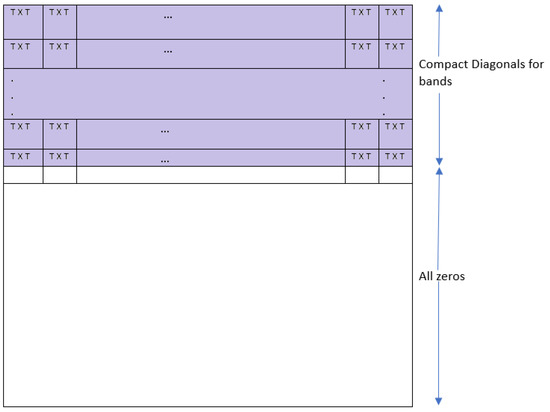
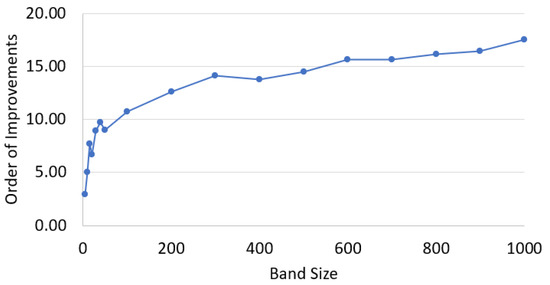
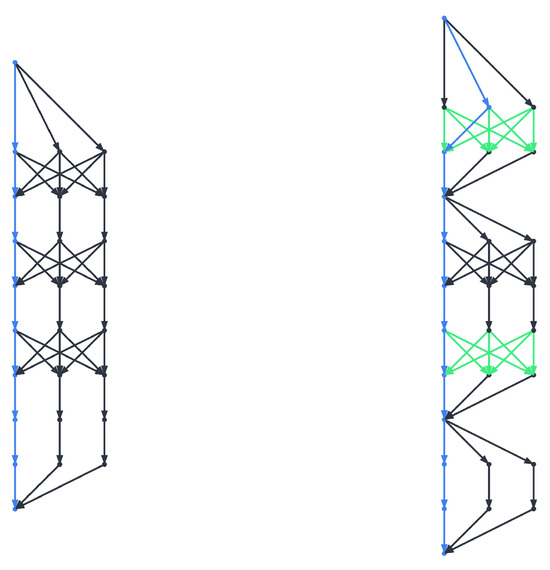
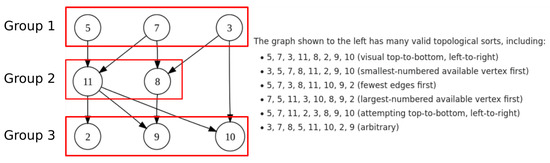
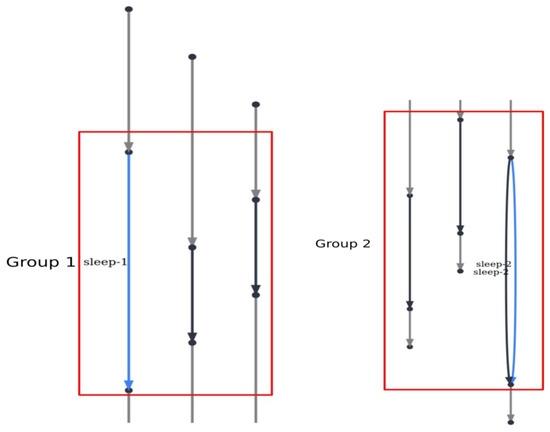
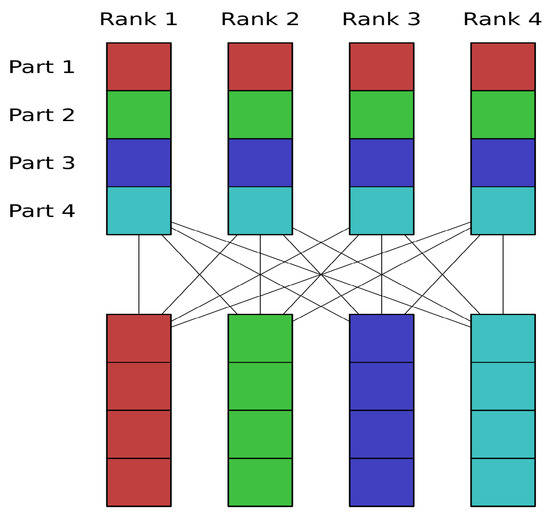
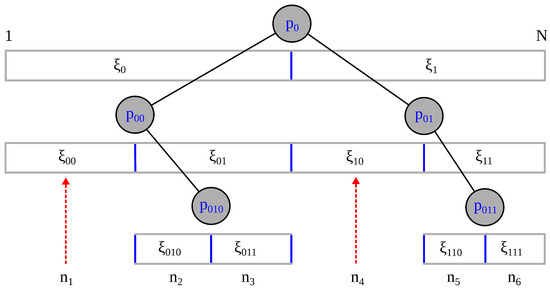
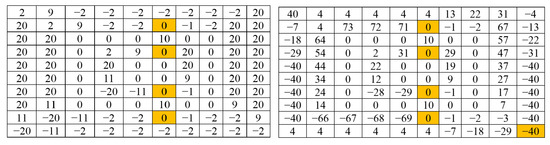
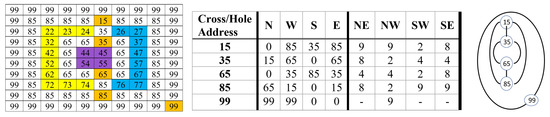
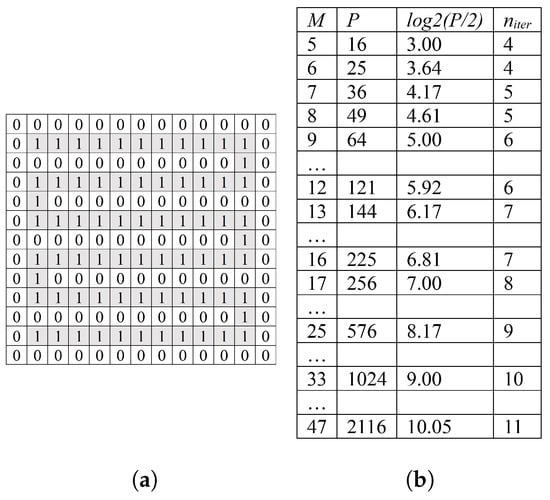
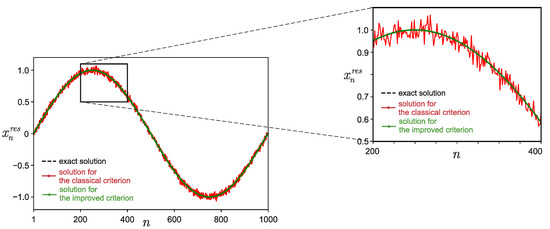
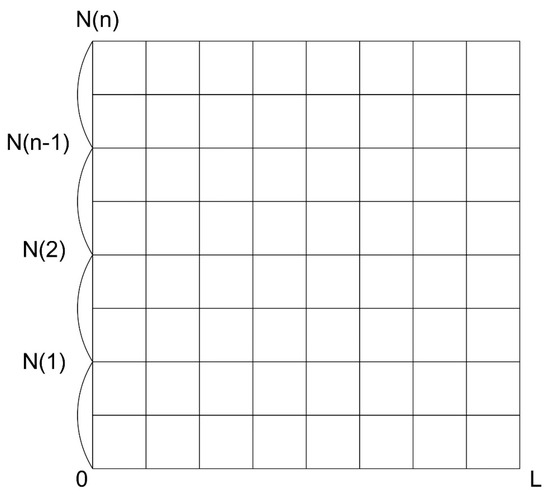
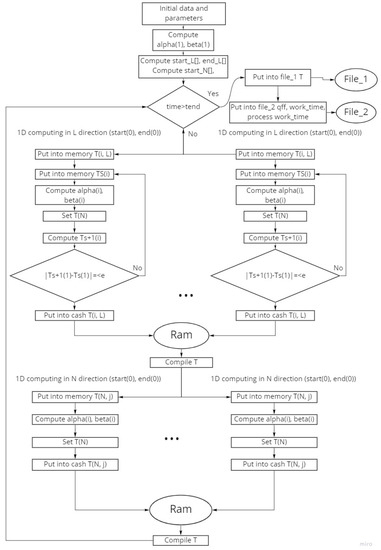
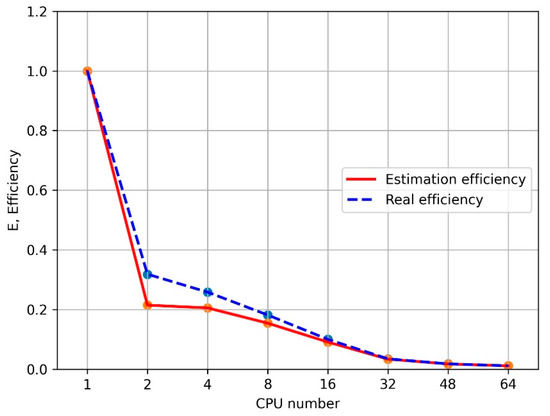
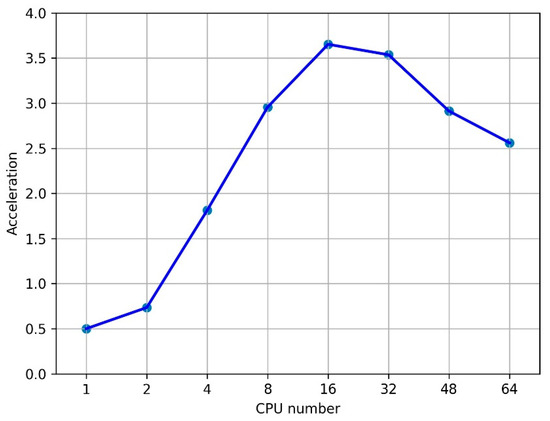
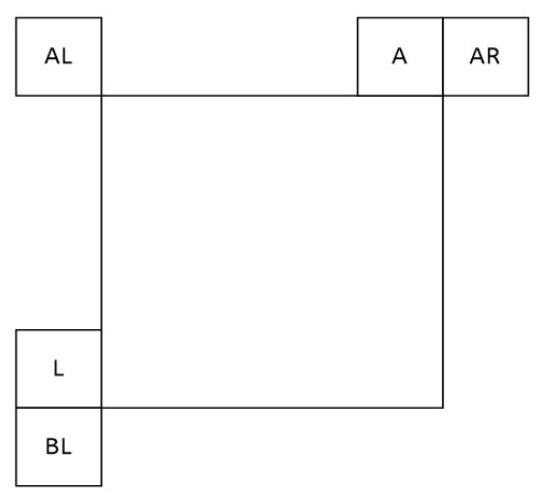
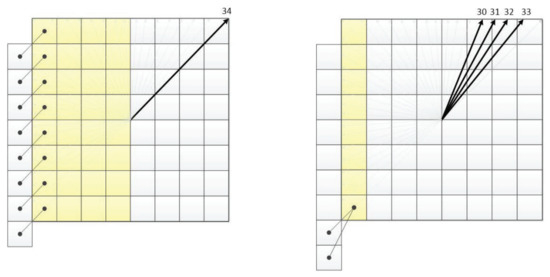
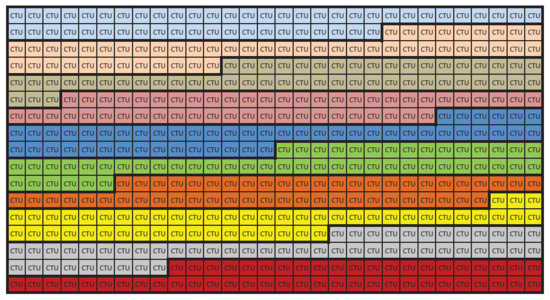
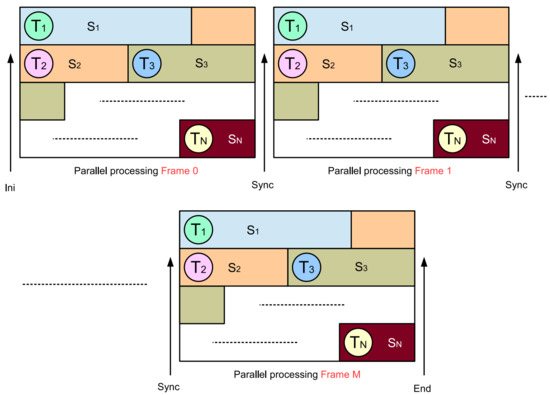
Figure 1




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}