Trends and Prospects in Multimedia
Share This Topical Collection
Editors
 Prof. Dr. Cheonshik Kim
Prof. Dr. Cheonshik Kim
Prof. Dr. Cheonshik Kim
E-Mail
Website
Collection Editor
Department of Computer Engineering, Sejong University, Seoul 05006, Korea
Interests: multimedia security; multimedia signal processing; image compression; watermark technology; steganography; multimedia database
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
This topical collection aims to introduce the latest research on multimedia signals, including digital contents and the various devices supporting them, in the open access journal Applied Sciences. We are currently open for manuscripts from authors interested in this topical collection. We look forward to the submission of creative research papers and review papers on related topics in this field of research that will enhance the quality of this collection and advance the knowledge base of this subject.
Prof. Dr. Cheonshik Kim
Prof. Dr. Andrew Teoh Beng Jin
Collection Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Applied Sciences is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- multimedia systems
- multimedia processing
- multimedia applications
- multimedia security
- system software for multimedia
- system hardware for multimedia
- network for multimedia
- signal processing for multimedia
- AI technology for multimedia
- every topic related multimedia
Published Papers (4 papers)
Open AccessArticle
A Self-Paced Multiple Instance Learning Framework for Weakly Supervised Video Anomaly Detection
by
Ping He, Huibin Li and Miaolin Han
Viewed by 484
Abstract
Weakly supervised video anomaly detection (WS-VAD) is often addressed as a multi-instance learning problem in which a few fixed number of video segments are selected for classifier training. However, this kind of selection strategy usually leads to a biased classifier. To solve this
[...] Read more.
Weakly supervised video anomaly detection (WS-VAD) is often addressed as a multi-instance learning problem in which a few fixed number of video segments are selected for classifier training. However, this kind of selection strategy usually leads to a biased classifier. To solve this problem, we propose a novel self-paced multiple-instance learning (SP-MIL) framework for WS-VAD. Given a pre-trained baseline model, the proposed SP-MIL can enhance its performance by adaptively selecting video segments (from easy to hard) and persistently updating the classifier. In particular, for each training epoch, the baseline classifier is firstly used to predict the anomaly score of each segment, and their pseudo-labels are generated. Then, for all segments in each video, their age parameter is estimated based on their loss values. Based on the age parameter, we can determine the self-paced learning weight (hard weight with values of 0 or 1) of each segment, which is used to select the subset of segments. Finally, the selected segments, along with their pseudo-labels, are used to update the classifier. Extensive experiments conducted on the UCF-Crime, ShanghaiTech, and XD-Violence datasets demonstrate the effectiveness of the proposed framework, outperforming state-of-the-art methods.
Full article
►▼
Show Figures
Open AccessArticle
A Survey of Grapheme-to-Phoneme Conversion Methods
by
Shiyang Cheng, Pengcheng Zhu, Jueting Liu and Zehua Wang
Viewed by 835
Abstract
Grapheme-to-phoneme conversion (G2P) is the task of converting letters (grapheme sequences) into their pronunciations (phoneme sequences). It plays a crucial role in natural language processing, text-to-speech synthesis, and automatic speech recognition systems. This paper provides a systematical overview of the G2P conversion from
[...] Read more.
Grapheme-to-phoneme conversion (G2P) is the task of converting letters (grapheme sequences) into their pronunciations (phoneme sequences). It plays a crucial role in natural language processing, text-to-speech synthesis, and automatic speech recognition systems. This paper provides a systematical overview of the G2P conversion from different perspectives. The conversion methods are first presented in the paper; detailed discussions are conducted on methods based on deep learning technology. For each method, the key ideas, advantages, disadvantages, and representative models are summarized. This paper then mentioned the learning strategies and multilingual G2P conversions. Finally, this paper summarized the commonly used monolingual and multilingual datasets, including Mandarin, Japanese, Arabic, etc. Two tables illustrated the performance of various methods with relative datasets. After making a general overall of G2P conversion, this paper concluded with the current issues and the future directions of deep learning-based G2P conversion.
Full article
►▼
Show Figures
Open AccessArticle
Few-Shot Continuous Authentication for Mobile-Based Biometrics
by
Kensuke Wagata and Andrew Beng Jin Teoh
Cited by 8 | Viewed by 2174
Abstract
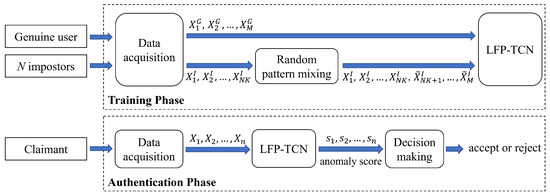
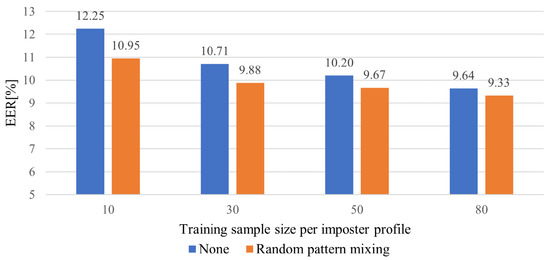
The rapid growth of smartphone financial services raises the need for secure mobile authentication. Continuous authentication is a user-friendly way to strengthen the security of smartphones by implicitly monitoring a user’s identity through sessions. Mobile continuous authentication can be viewed as an anomaly
[...] Read more.
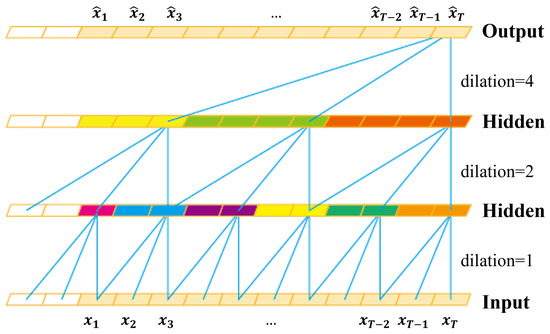
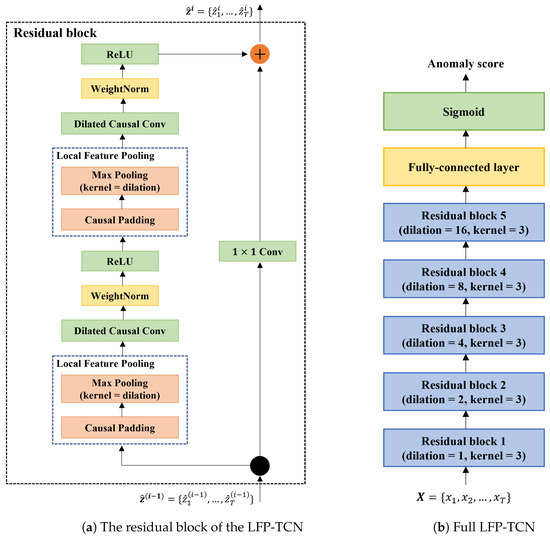
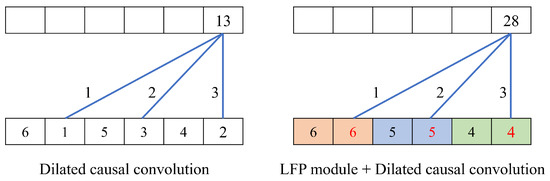
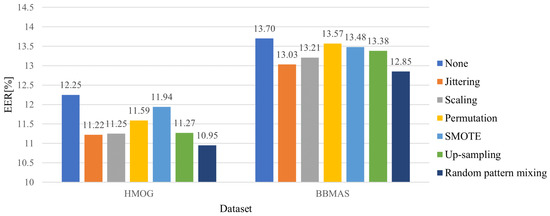
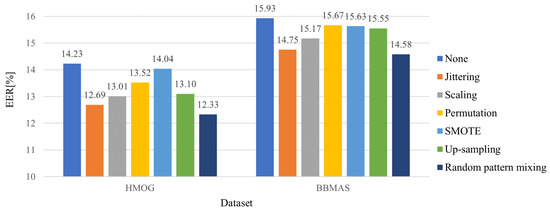
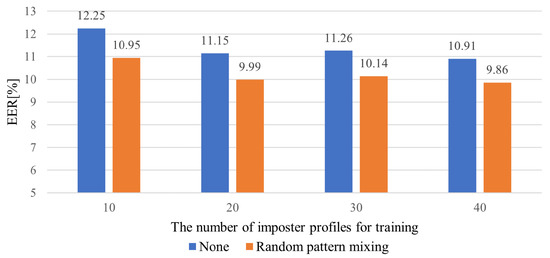
The rapid growth of smartphone financial services raises the need for secure mobile authentication. Continuous authentication is a user-friendly way to strengthen the security of smartphones by implicitly monitoring a user’s identity through sessions. Mobile continuous authentication can be viewed as an anomaly detection problem in which models discriminate between one genuine user and the rest of the impostors (anomalies). In practice, complete impostor profiles are hardly available due to the time and monetary cost, while leveraging genuine data alone yields poorly generalized models due to the lack of knowledge about impostors. To address this challenge, we recast continuous mobile authentication as a few-shot anomaly detection problem, aiming to enhance the inference robustness of unseen impostors by using partial knowledge of available impostor profiles. Specifically, we propose a novel deep learning-based model, namely a local feature pooling-based temporal convolution network (LFP-TCN), which directly models raw sequential mobile data, aggregating global and local feature information. In addition, we introduce a random pattern mixing augmentation to generate class-unconstrained impostor data for the training. The augmented pool enables characterizing various impostor patterns from limited impostor data. Finally, we demonstrate practical continuous authentication using score-level fusion, which prevents long-term dependency or increased model complexity due to extended re-authentication time. Experiments on two public benchmark datasets show the effectiveness of our method and its state-of-the-art performance.
Full article
►▼
Show Figures
Open AccessArticle
Separable Reversible Data Hiding in Encrypted AMBTC Images Using Hamming Code
by
Cheonshik Kim
Cited by 4 | Viewed by 1735
Abstract
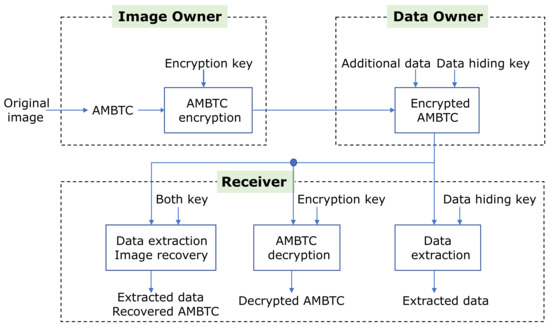
Data hiding is a field widely used in copyright, annotation, and secret communication for digital content, and has been continuously studied for more than 20 years. In general, data hiding uses the original image as a cover image to hide data, but recently,
[...] Read more.
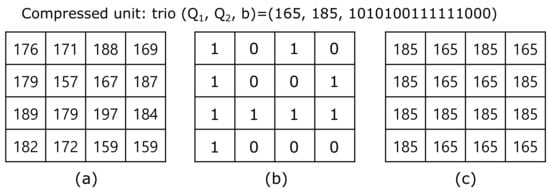
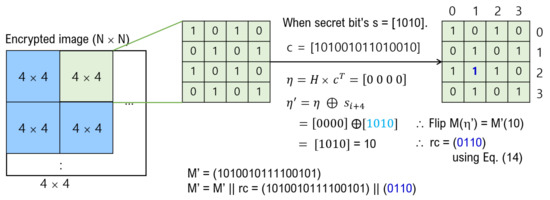
Data hiding is a field widely used in copyright, annotation, and secret communication for digital content, and has been continuously studied for more than 20 years. In general, data hiding uses the original image as a cover image to hide data, but recently, the research area has expanded to research on improving the security and privacy protection of image contents by encrypting the image. This research is called separable reversible data hiding in an encrypted image (SRDH-EI). In this paper, we proposed a more efficient SRDH-EI method based on AMBTC. AMBTC can guarantee very good network transmission efficiency for applications that do not require a particularly high image quality because the compression time is short and calculation is simple compared to other existing compression methods. The SRDH-EI method presented here divides AMBTC into non-overlapping
blocks and then performs image encryption on them. Thereafter, data can be hidden using a Hamming code for each block. The proposed method has an advantage in that the quality of the cover image and the hiding capacity can be adjusted by appropriately using the value
T of the difference between the two quantization levels. The experimental results proved the efficiency and superiority of our proposed model.
Full article
►▼
Show Figures





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}