1. Introduction
We are often interested in quantitative details about quantities that are difficult or even impossible to measure directly. In many cases we may be fortunate enough to find measureable quantities that are related to our variables of interest. Such examples are abundant in nature. Consider a community of microbes coexisting in humans or other metazoan species [
1,
2]. It is possible to measure the relative abundances of different species in the microbial community in individual hosts, but it could be difficult to directly measure parameters that regulate interspecies interactions in these diverse communities. Knowing the quantitative values of the parameters representing microbial interactions is of great interest, both because of their role in development of therapeutic strategies against diseases such as colitis, and for basic understanding, as we have discussed in [
3].
Inference of these unknown variables from the available data is a subject of a vast literature in diverse disciplines including statistics, information theory, and, machine learning [
4–
7]. In this paper we will be interested in a specific problem where the unknown variables in a large dimension are related to a smaller number of variables whose joint probability distribution is known from measurements.
In the above example, parameters describing microbial interactions could represent such unknown variables, and their number could be substantially larger than the number of measurable variables, such as abundances of distinct microbial species. The distribution of abundances of microbial species in a host population can be calculated from measurements performed on a large number of individual subjects. The challenge is to estimate the distribution of microbial interaction parameters using the distribution of microbial abundances.
These inference problems can be dealt with by Maximum Entropy (MaxEnt)-based methods that maximize an entropy function subject to constraints provided by the expectation values calculated from measured data [
4,
5,
7,
8]. In standard applications of MaxEnt, usually, averages, covariances, and, sometimes, higher-order moments calculated from the data are used to infer such distributions [
4,
5,
7]. Including larger number of constraints in the MaxEnt formalism involves calculating a large number of Lagrange multipliers by solving an equal number of nonlinear equations, which can pose a great computational challenge [
9]. Here we propose a novel MaxEnt-based method to infer the distribution of the unknown variables. Our method uses the distribution of the measured variables and provides an elegant MaxEnt solution that bypasses direct calculation of the Lagrange multipliers. Instead, the inferred distribution is described in terms of a degeneracy factor, described by a closed form expression, which depends only on the symmetry properties of the relation between the measured and the unknown variables.
More generally, the above problem relates to the issue of calculating a probability function of
X from the probability function of
Y, where
X and
Y are both random variables, and
Y and X have a functional relationship. This could involve either discrete or continuous random variables. Standard textbooks [
10] in probability theory usually deal with cases where (a) variables X are related to variables of Y by a well-defined functional relationship (x = g(y)), with the distribution of the Y variables (y) known, and (b) X resides in a manifold (dimension
n) of lower dimension than the Y manifold (dimension
m). However, it is not clear how to extend the standard calculations pertaining to the above well-defined case when multiple values of X variables are associated with the same Y variable. This situation easily arises when
n is greater than
m. We address this problem here, where we estimate Q(x) from P(y) when n > m.
i.e., we infer the higher-dimension variable from the lower-dimension one. We show that when the variables are discrete, no unique solution exists for Q(x), as the system is underdetermined. However, the MaxEnt-based method can provide a MaxEnt solution in this situation that is constrained only by the available information (P(y) in this case) and is free from any additional assumptions. We then extend the results for continuous variables.
2. The Problem
We state the problem, illustrating in this section with discrete random variables. Consider a case when n different random variables, x1,…, xn, are related to m (n > m) different variables, y1, …, ym, as {Yi = fi(x1,…, xn)} (f:
). We know the probabilities for the y variables and want to reach some conclusion about the probabilities of the x variables.
We introduce a few terms and notations borrowed from physics that we will use to simplify the mathematical description [
11]. A state in the x (or y) space refers to a particular set of values in the variables x
1,…, x
n (or y
1,…, y
m). We denote the set of these states as {x
1,…, x
n} or {y
1,…, y
m}. The vector notations,
and
, will be used to compactly describe expressions when required. For the same reason, when we use f without a subscript, it will refer to a vector of f values,
i.e.,
. In standard textbook examples in elementary probability theory and physics, we are provided with the probability distribution function
, where X is related to Y by a well-defined function,
. Such cases are common when Y resides in a higher or equal dimension (m ≥ n) than X. Then
, with lower dimension n, is calculated using
The summation in
Equation (1a) is performed over only those states {y
1,…, y
m} that correspond to the specified state
. However, note that the above relation does not hold even when m ≥ n if multiple values of X variables are associated with the same values of the Y variables, e.g., x
2 = y, where −∞ < x < ∞ and 0 ≤ y < ∞. The MaxEnt formalism developed here can be used for estimating
using
in such cases (see
Appendix A1).
Here we are interested in the inverse problem: we are still provided with the probability distribution P(y
1,…, y
m) and need to estimate the probability distribution Q(x
1,…, x
n), but now m < n. In this situation, multiple values of the unknown variable X are associated with the same values of observable Y variables and no unique solution for Q(x
1,…, x
n) exists as the system is underdetermined. Instead of
Equation (1a), we use this equation:
The constraints imposed on the summation in the last term by the relations
between the states in x and y are incorporated using the Kronecker delta function (δab, where, δa,b = 1 when a = b, and, δa,b = 0 when a ≠ b). For pedagogical reasons we elucidate the problem of non-uniqueness in the solutions using a simple example. This example can be easily generalized.
Example 1. We start with a discrete random variable y, with known distribution
for y = 0, 1, 2. Then assume that discrete random variables x1 and x2 are related to y, as, y = f(x1,x2) = x1 + x2. We restrict x1 and x2 to being nonnegative integers; hence x1, and x2 can assume only three values, 0, 1, and 2.
It follows that Q(x
1,x
2) are related to P(y) following
Equation (1b) as,
Hence
The above relation provides three independent linear equations for determining six unknown variables, Q(0,0), Q(1,0), Q(0,1), Q(1,1), Q(2,0), and, Q(0,2). Note, the condition of
is satisfied by the above linear equations, which also makes Q(1,2) = Q(2,1) = Q(2,2) = 0. Therefore, the linear system in
Equation (2) is underdetermined and Q(x
1,x
2) cannot be found uniquely using these equations. (e.g., Q(0,1) and Q(1,0) could each equal 1/6; or Q(0,1) could equal 1/12, with Q(1,0) = 1/4;
etc.)
This issue of non-uniqueness is general and will hold as long as the number of constraints imposed by P(y1,…, ym) is smaller than that of the number of unknown Q(x1,…, xn). For example, when each direction in y (or x) can take L (or L1) discrete values and all the states in x are mapped to all the states in y, then the system will be underdetermined as long as, Lm < L1n.
3. A MaxEnt Based Solution (Discrete)
In this section we propose a solution of this problem using a Maximum Entropy based principle, for discrete variables. We can define Shannon’s entropy [
4,
5,
7],
S, given by
and then maximize
S with the constraint that
should generate the distribution
in
Equation (1b).
Equation (1b) describes the set of constraints spanning the distinct states in the y space. For example, when each element in the y vector assumes binary values (+1 or −1) there are in total 2
m number of distinct states in the y space providing 2
m number of equations of constraints. We can introduce a Lagrange multiplier for each of the constraint equations, which we denote compactly as a function, λ(y
1, …, y
m) or
describing a map from
. That is, every possible y vector is associated with a unique value of λ. Also note, when
is normalized,
is normalized due to
Equation (1b), therefore, we will not use any additional Lagrange multiplier for the normalization condition of
. The distribution,
, that optimizes
S, subject to the constraints can be calculated as follows.
is slightly perturbed from
,
i.e.,
. Then expanding
S in
Equation (3) and the constraints in
Equation (1b) in terms of
and setting the terms proportional to
zero (optimization condition) yields
in terms of the Lagrange multipliers,
i.e.,
One can indeed confirm that the terms in the expansion of
S and the constraints proportional to
at
is
, thus,
maximizes
S. The method used here for maximizing S subject to the constraints is a standard one [
4,
11].
The solution for
from the above
Equation (4) is given by,
Note the partition function (usually denoted as Z in textbooks [
4,
11]) does not arise in the above solution as the normalization condition for Q(x) is incorporated in the constraint equations in
Equation (1b). We show the derivation of
Equation (5) for Example 1 in
Appendix A2 for pedagogical reasons. From the above solution (
Equation (5)) we immediately observe the two main features that
exhibits:
The values of
for the states {x1, …, xn} that map to the same state y1, …, ym via
are equal to each other. In the simple example above, this implies Q(1,0) = Q(0,1), and, Q(1,1) = Q(0,2) = Q(2,0).
contains all the symmetry properties present in the relation {yi = fi(x1, …, xn)}. In the simple example, the relation between y and x was symmetric in permutation of x1 and x2, implying, Q(x1,x2) = Q(x2,x1).
We will take advantage of the above properties to avoid direct calculation of the Lagrange multipliers in
Equation (4): For the states
in the x space that map to the same state,
, in the y space,
Equation (1b) can rewritten as
where
gives the total number of distinct states
in the x space that correspond to the state,
or
. Since, all the states in
will have the same probability, in the second step in
Equation (6a) we replace the summation with
, multiplied by the probability of any state
or
in
. We designate
as the degeneracy factor, borrowing a similar terminology in physics.
can be expressed in terms of the Kronecker delta functions as,
Note, the degeneracy factor in
Equation (7) only depends on the relationship between
and
, and, does not depend on the probability distributions, P and Q. In our simple example above, since y = x
1 + x
2, Q(0,1) and Q(1,0) both correspond to y = 1, therefore
.
Equation (6b) is the main result of this section, which describes the inferred distribution
in terms of the known probability distribution
, and,
, which can be calculated from the given relation between y and x. Thus, the calculation of
, as shown in
Equation (6b), does not involve direct evaluation of the Lagrange multipliers,
. These two quantities are related to
, and,
, following
Equations (5), (
6b) and (
7), as,
Example 1, continued. We provide a solution for Example 1 presented above. By simple counting, we see the degeneracy factors are
Thus following
Equation (2), Q(0,0) = P(0) = 1/3, Q(0,1) = Q(1,0) = P(1)/2 = 1/6, and, Q(2,0) = Q(1,1) = Q(0,2) = P(2)/3 = 1/9. For more complex problems, the degeneracy factors can be calculated numerically. Maximizing the entropy, S, is what made all the Qs be equal for any one y value.
4. Results for Continuous Variables
The above results can be extended when {X
i} and {Y
i} are continuous variables. However, there is an issue that makes a straightforward extension of the calculations shown in the discrete case in the continuum limit difficult. The issue is related to the continuum limit of the entropy function
S in
Equation (3). Replacing the summation in
Equation (3) with an integral in the limit of large number of states as the step size separating the adjacent states is decreased to zero creates an entropy expression which is negative and unbounded [
12]. This problem can be ameliorated by defining a relative entropy, RE, defined as,
where, u is a uniform probability density function defined on the same domain as q. RE always remains positive with a lower bound at zero. The results obtained by maximizing S in the previous section can be derived by minimizing a relative entropy (RE) defined above with the discrete distributions, Q and a uniform distribution, U, where the integral in
Equation (9) is replaced by a summation over the states in the x space. RE in
Equation (9) quantifies the difference between the distribution q(x
1, …, x
n) and the corresponding uniform distribution.
The definition of RE in
Equation (9) still has an issue of defining the uniform distribution when the x variables are unbounded. In some cases, it may be possible to solve the problem by introducing finite upper and lower bounds and then analyzing the results in the limit where the upper (or lower) bound approaches ∞ (or −∞). We will illustrate this approach in Example 4, below. Also, see Example 3 for a comparison.
In the continuum limit, the constraints on q(x
1,…, x
n) or
, imposed by the probability density function (pdf) p(y
1,…,y
m) or
are given by,
The Dirac delta function for a single variable x is defined as,
where the region R contains the point
.
Since, the pdf
resides in a lower dimension compared to
, estimation of
in terms of
requires solution of an underdetermined system.
For continuous variables we can proceed with minimizing the relative entropy using functional calculus [
13,
14]. The calculation follows the same logic as in the discrete case, we show the steps explicitly for clarity and pedagogy.
The relative entropy (RE) in
Equation (9) is a functional of
. As in the discrete case, if
is normalized,
i.e.,
, then
Equations (10) and (
11) imply
is normalized as well,
i.e.,
We introduce a Lagrange multiplier function,
, and generate a functional,
Sλ[q], that we need to minimize in order to minimize
Equation (9) along with the constraints in
Equation (10). Since, the normalization condition in
Equation (12) follows from
Equation (10) we do not treat
Equation (12) as a separate constraint.
We can take the functional derivative to minimize S as,
In deriving
Equation (14) we used the standard relation
. For multiple dimensions this generalizes to,
. The chain rule for derivatives of functions can be easily generalized for functional derivatives [
14].
Equation (14) provides us with the solution that minimizes
Equation (13):
where, u
0 is a constant related to the density of the uniform distribution. Note the {x
i} dependence in the solution,
, arises only though
.
The second derivative of
Sλ in
Equation (18) is always positive, since q is positive. Therefore,
, minimizes the relative entropy in
Equation (9).
Equations (16) and (
17) are the main results of this section, which are the counterparts for the
Equations (6b) and (
7) in discrete case.
We apply the above results for two examples below.
Example 2. Consider a linear relationship between y and x, e.g., y = x
1 + x
2, where, 0 ≤ y ≤ ∞ and 0 ≤ x
1 ≤ ∞, 0 ≤ x
2 ≤ ∞. If the pdf in y is known as, p(y) = 1/μ exp(−y/μ), we would like to know the pdf corresponding q(x
1,x
2), where, the pdfs p and q are related by
Equation (10),
i.e.,
The degeneracy factor in the continuous case, according to
Equation (17), in this case is,
The second equality results from the fact that the Dirac delta function is zero outside that region. The fourth equality uses the property of the Delta function,
Therefore,
.
Example 3. Let
, 0 ≤ y ≤ ∞ and 0 ≤ (x
1, x
2) ≤ ∞. Then κ(y), as given by
Equation (17), is,
Therefore, according to
Equation (17),
In our final example, we illustrate solving the problem by taking the limit when the upper and/or lower bound(s) approach ± ∞, as mentioned near the beginning of this section of the paper.
Example 4. Let
, 0 ≤ y ≤ 2L
2 and 0 ≤ (x
1, x
2) ≤ L. First we calculate κ(y) as given in
Equation (17). Therefore, we need to evaluate the integral,
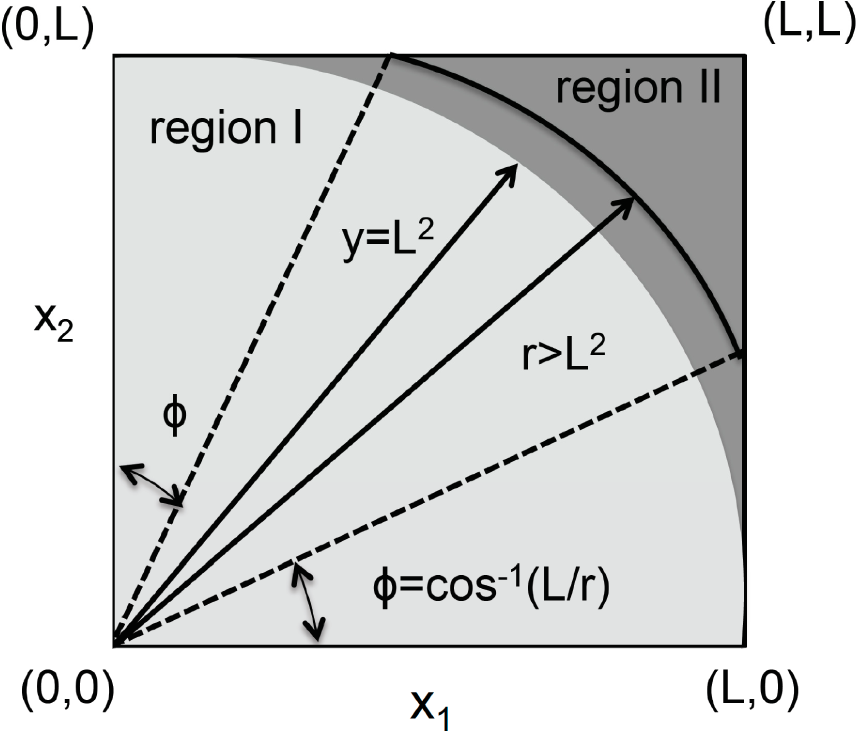
We divide the region of integration (0≤ (x
1, x
2) ≤ L) into two parts, region I (lighter shade) and II (darker shade) as shown in the
Figure 1. Region I contains x
1 and x
2 values, where, x
12 + x
22 = y
2 ≤ L
2, and, region II contains the remaining of the part of the domain (0≤ (x
1, x
2) ≤ L) of integration. The integrals in these regions are given by the first and the second term after the second equality sign in the equation below.
In region I, where y ≤ L
2,
In region II, where L
2 ≤ y ≤ 2L
2,
varies between 0 (on the line x
12 + x
22 = L
2) and π/4 (at x
1 = x
2 = L). Note, κ(y) = 0 when x
1 = x
2 = L, which does have any degeneracy. Therefore,
Equation (16) is not valid at this point. Thus, as in Example 2 and 3,
Limit L→∞: When y ≤ L
2, κ(y) = π/4. Thus, as L→∞, as long as y remains in region I we correctly recover the result in example III. If y is in region II, then we can expand κ(y) in a series of a small parameter ε = (y − L
2)/L
2 as κ(y) = π/4 −
+ O(ε
3/2). This result follows from the expansion of
in region II. We can write,
where, 0 < ε[= (y − L
2)/L
2] ≤ 1. Using series expansion of cos
−1(x) [
15] we find,
, and thus, κ(y) = π/4 −
+ O(ε
3/2).
5. Discussion
The problem we have attacked here arose from our work with microbial communities [
3], but it also has broader statistical applications. For example, the responses of immune cells to external stimuli involve protein interaction networks, where protein-protein interactions, described by biochemical reaction rates, are not directly accessible for measurement
in vivo. Recent developments in single cell measurement techniques allow for measuring many protein abundances in single cells, making it possible to evaluate distribution of protein abundances in a cell population [
16]. However, it is a challenge to characterize protein-protein interactions underlying a cellular response because the number of these interactions could be substantially larger than the number of measured protein species [
17]. These problems involve determining the distribution of a random variable x, where y is another random variable, and X and Y have a functional relationship. In the more common situation, x has dimensionality less than or equal to that of y, and there is often a unique solution. In contrast, we considered here the case where x’s dimensionality is greater than that of y, so there is no unique solution to the problem.
Since there is no unique solution, we propose taking a MaxEnt approach, as a way of “spreading out the uncertainty” as evenly as possible. In the discrete case, intuition would suggest that if
k values of Q sum to a given value of P, then the solution that makes the least additional assumptions is for each Q to equal P/k. This intuition is confirmed by our MaxEnt results for the discrete case. In the continuous case, the intuition is not as obvious. However, the MaxEnt solution does capture the same intuitive idea. Instead of dividing P by
(an integer), we divide p by
, where
when
y has dimension 1, or more generally by
Equation (17). This use of the Dirac delta function has the similar effect of spreading out the uncertainty evenly.
Estimating the distribution Q(x) does not require explicit calculation of the Lagrange multipliers and the partition sum. Rather, Q(x) is directly evaluated following
Equation (6b) (or
Equation (17) in the continuous case), using the measured P(y) (or p(y)), and, k(y) (or κ(y)), which depends only on the relationship y = f(x). In standard MaxEnt applications, where constraints are imposed by the average values and other moments of the data, inference of probability distributions requires evaluation of the Lagrange multipliers and the partition sum Z. This involves solving a set of nonlinear equations and the relation between the Z and the Lagrange multipliers. Calculating these quantities, which is usually carried out numerically, can pose a technical challenge when the variables reside in large dimensions. In our case, we avoid these calculations and provide a solution for Q(x) in terms of a closed analytical expression, which is general and thus applicable to any well-behaved example. A limitation is that calculation of the degeneracy factor k(y) (or κ(y) in the continuous case) can present a challenge in higher dimensions and for complicated relations between y and x. Monte Carlo sampling techniques[
18] and discretization schemes for Dirac delta functions[
19] can be helpful in that regard.


{kind=link}
