
Convergence of a Fixed-Point Minimum Error Entropy Algorithm




Abstract
:1. Introduction
2. Fixed-Point MEE Algorithm
3. Convergence of the Fixed-Point MEE
4. Illustrative Example




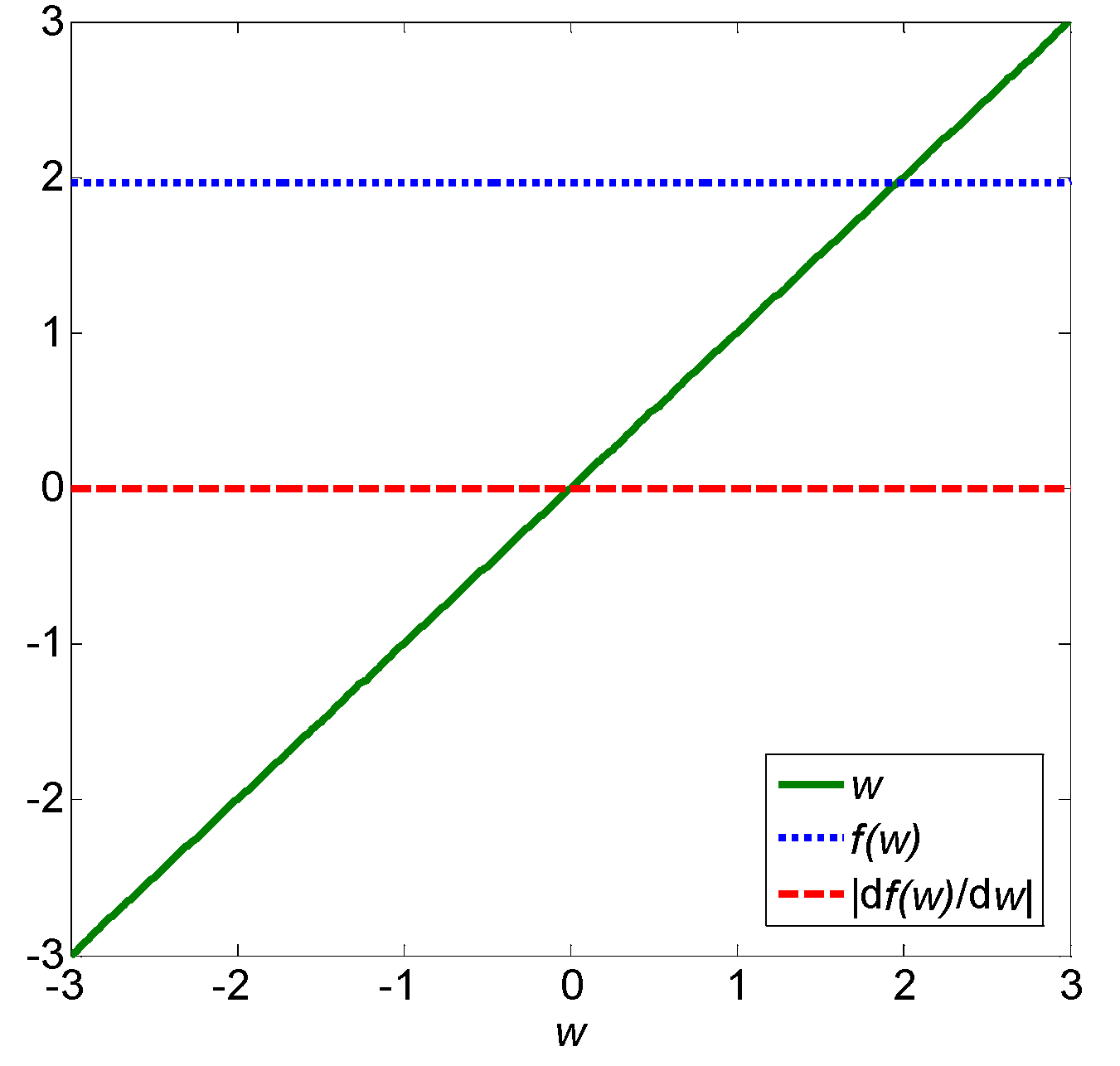{kind=link}
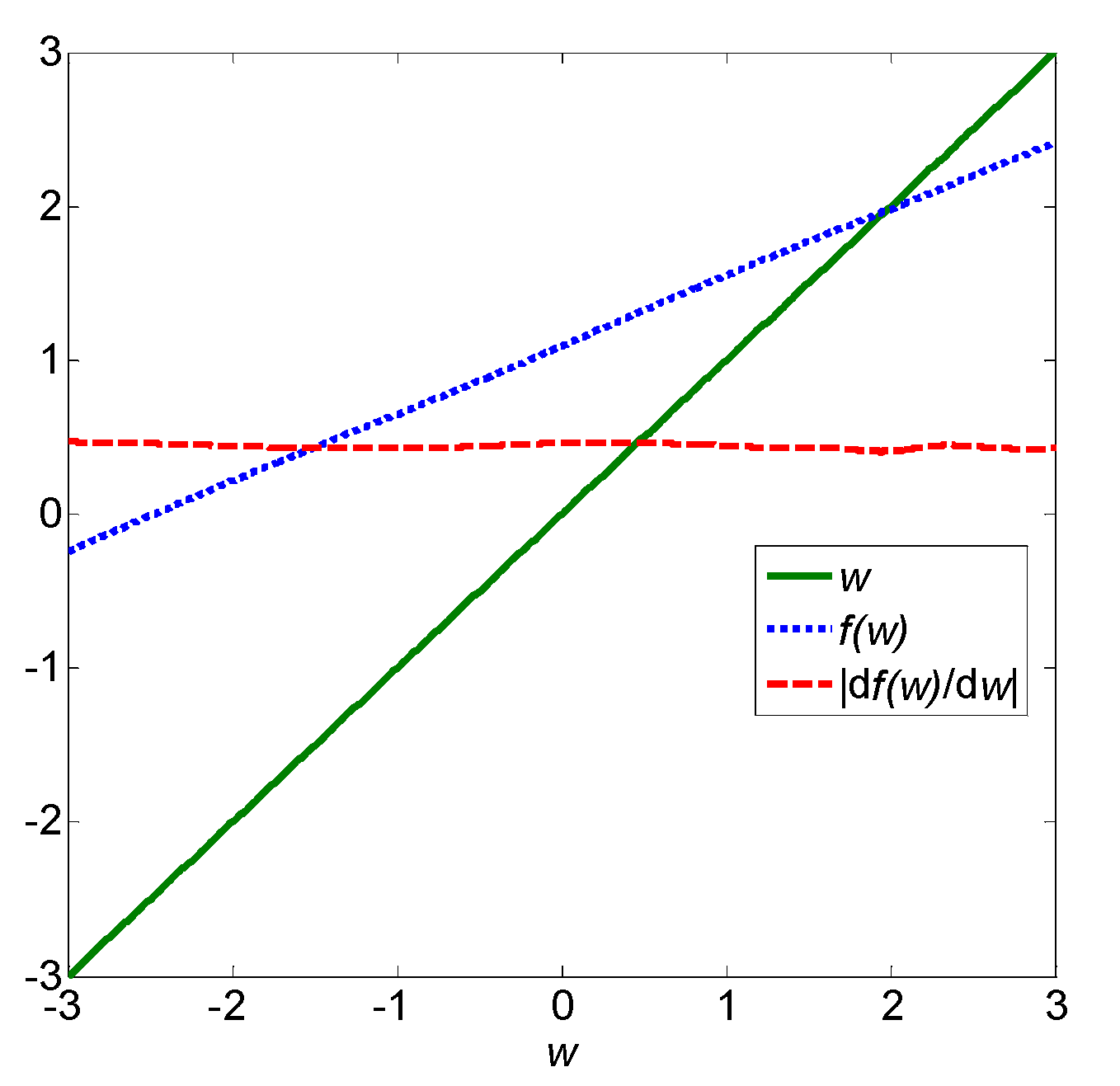{kind=link}
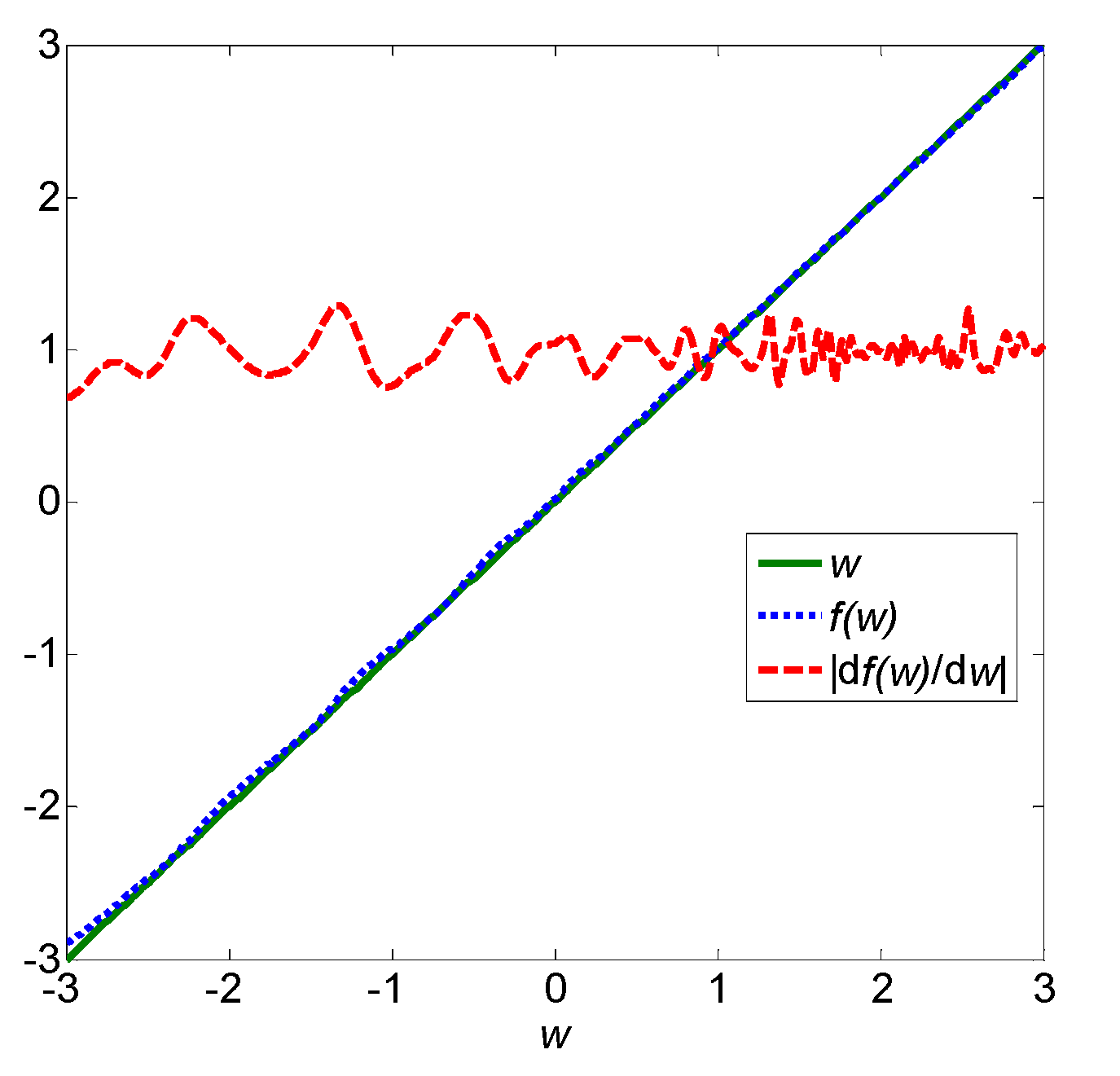{kind=link}
| 3.0 | 1.0 | 0.1 | 0.05 | |
| Iterations | 3 | 4 | 16 | 43 |
5. Conclusion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Principe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Chen, B.; Zhu, Y.; Hu, J.C.; Principe, J.C. System Parameter Identification: Information Criteria and Algorithms; Elsevier: Amsterdam, the Netherlands, 2013. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman & Hall: New York, NY, USA, 1986. [Google Scholar]
- Erdogmus, D.; Principe, J.C. An error-entropy minimization for supervised training of nonlinear adaptive systems. IEEE Trans. Signal Process. 2002, 50, 1780–1786. [Google Scholar] [CrossRef]
- Erdogmus, D.; Principe, J.C. Generalized information potential criterion for adaptive system training. IEEE Trans. Neural Netw. 2002, 13, 1035–1044. [Google Scholar] [CrossRef] [PubMed]
- Erdogmus, D.; Principe, J.C. Convergence properties and data efficiency of the minimum error entropy criterion in adaline traing. IEEE Trans. Signal Process. 2003, 51, 1966–1978. [Google Scholar] [CrossRef]
- Chen, B.; Zhu, Y.; Hu, J. Mean-square convergence analysis of ADALINE training with minimum error entropy criterion. IEEE Trans. Neural Netw. 2010, 21, 1168–1179. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Principe, J.C. Some further results on the minimum error entropy estimation. Entropy 2012, 14, 966–977. [Google Scholar] [CrossRef]
- Chen, B.; Principe, J.C. On the Smoothed Minimum Error Entropy Criterion. Entropy 2012, 14, 2311–2323. [Google Scholar] [CrossRef]
- Marques de Sá, J.P.; Silva, L.M.A.; Santos, J.M.F.; Alexandre, L.A. Minimum Error Entropy Classification; Springer: London, UK, 2013. [Google Scholar]
- Agarwal, R.P.; Meehan, M.; O’Regan, D. Fixed Point Theory and Applications; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Cichocki, A.; Amari, S. Adaptive Blind Signal and Image Processing: Learning Algorithms and Applications; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Regalia, P.A.; Kofidis, E. Monotonic convergence of fixed-point algorithms for ICA. IEEE Trans. Neural Netw. 2003, 14, 943–949. [Google Scholar] [CrossRef] [PubMed]
- Fiori, S. Fast fixed-point neural blind-deconvolution algorithm. IEEE Trans. Neural Netw. 2004, 15, 455–459. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Principe, J.C. A fixed-point minimum error entropy algorithm. In Proceedings of the 16th IEEE Signal Processing Society Workshop on Machine Learning for Signal Processing, Arlington, VA, USA, 6–8 September 2006; pp. 167–172.
- Chen, J.; Richard, C.; Bermudez, J.C.M.; Honeine, P. Non-negative least-mean-square algorithm. IEEE Trans. Signal Process. 2011, 59, 5225–5235. [Google Scholar] [CrossRef]
- Chen, J.; Richard, C.; Bermudez, J.C.M.; Honeine, P. Variants of non-negative least-mean-square algorithm and convergence analysis. IEEE Trans. Signal Process. 2014, 62, 3990–4005. [Google Scholar] [CrossRef]
- Chen, B.; Wang, J.; Zhao, H.; Zheng, N.; Principe, J.C. Convergence of a fixed-point algorithm under Maximum Correntropy Criterion. IEEE Signal Process. Lett. 2015, 22, 1723–1727. [Google Scholar] [CrossRef]
- Kailath, T.; Sayed, A.H.; Hassibi, B. Linear Estimation; Prentice Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Chen, B.; Liu, X.; Yuan, Z.; Principe, J.C. Convergence of a Fixed-Point Minimum Error Entropy Algorithm. Entropy 2015, 17, 5549-5560. https://doi.org/10.3390/e17085549
Zhang Y, Chen B, Liu X, Yuan Z, Principe JC. Convergence of a Fixed-Point Minimum Error Entropy Algorithm. Entropy. 2015; 17(8):5549-5560. https://doi.org/10.3390/e17085549
Chicago/Turabian StyleZhang, Yu, Badong Chen, Xi Liu, Zejian Yuan, and Jose C. Principe. 2015. "Convergence of a Fixed-Point Minimum Error Entropy Algorithm" Entropy 17, no. 8: 5549-5560. https://doi.org/10.3390/e17085549
APA StyleZhang, Y., Chen, B., Liu, X., Yuan, Z., & Principe, J. C. (2015). Convergence of a Fixed-Point Minimum Error Entropy Algorithm. Entropy, 17(8), 5549-5560. https://doi.org/10.3390/e17085549