Entropy Ensemble Filter: A Modified Bootstrap Aggregating (Bagging) Procedure to Improve Efficiency in Ensemble Model Simulation


Abstract
:1. Introduction
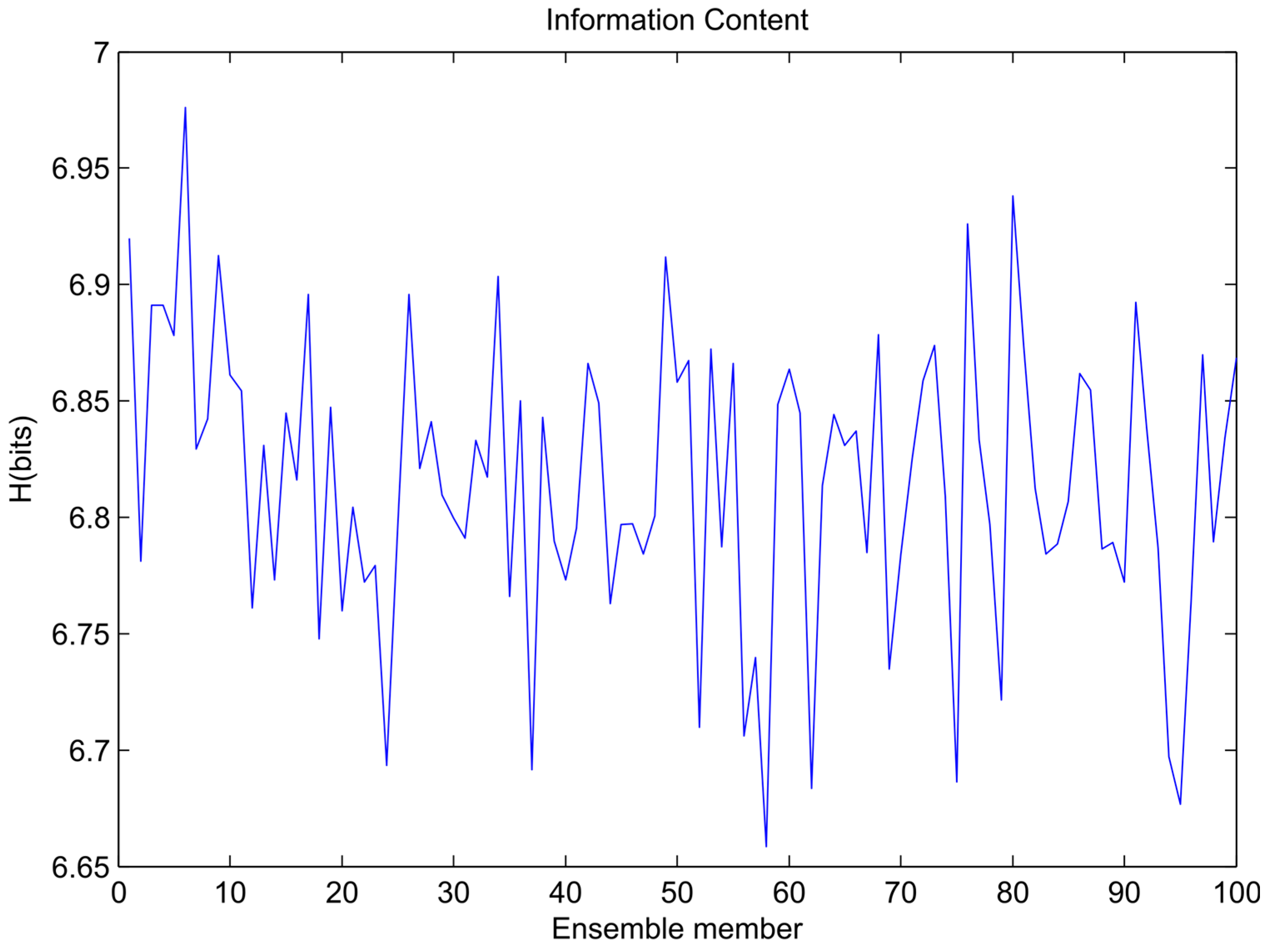
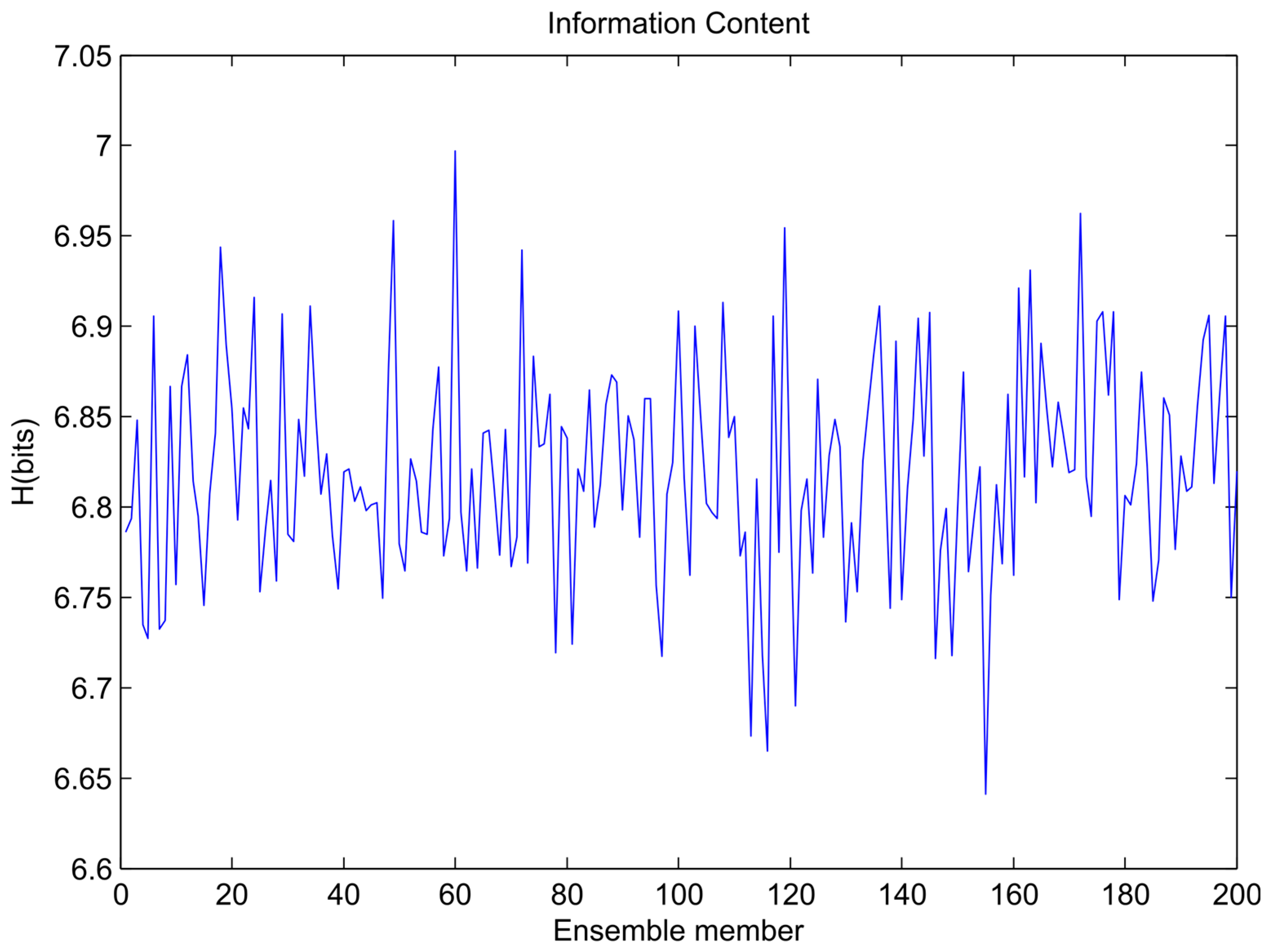
2. Methods: Entropy Ensemble Filter
| Algorithm 1. Entropy Ensemble Filter | ||
| Begin | Comment | |
| 1 | Initialize the procedure of bagging | |
| Generate M new training datasets from input data using bootstrapping (M committee members) | M: Initially user defines the ensemble size | |
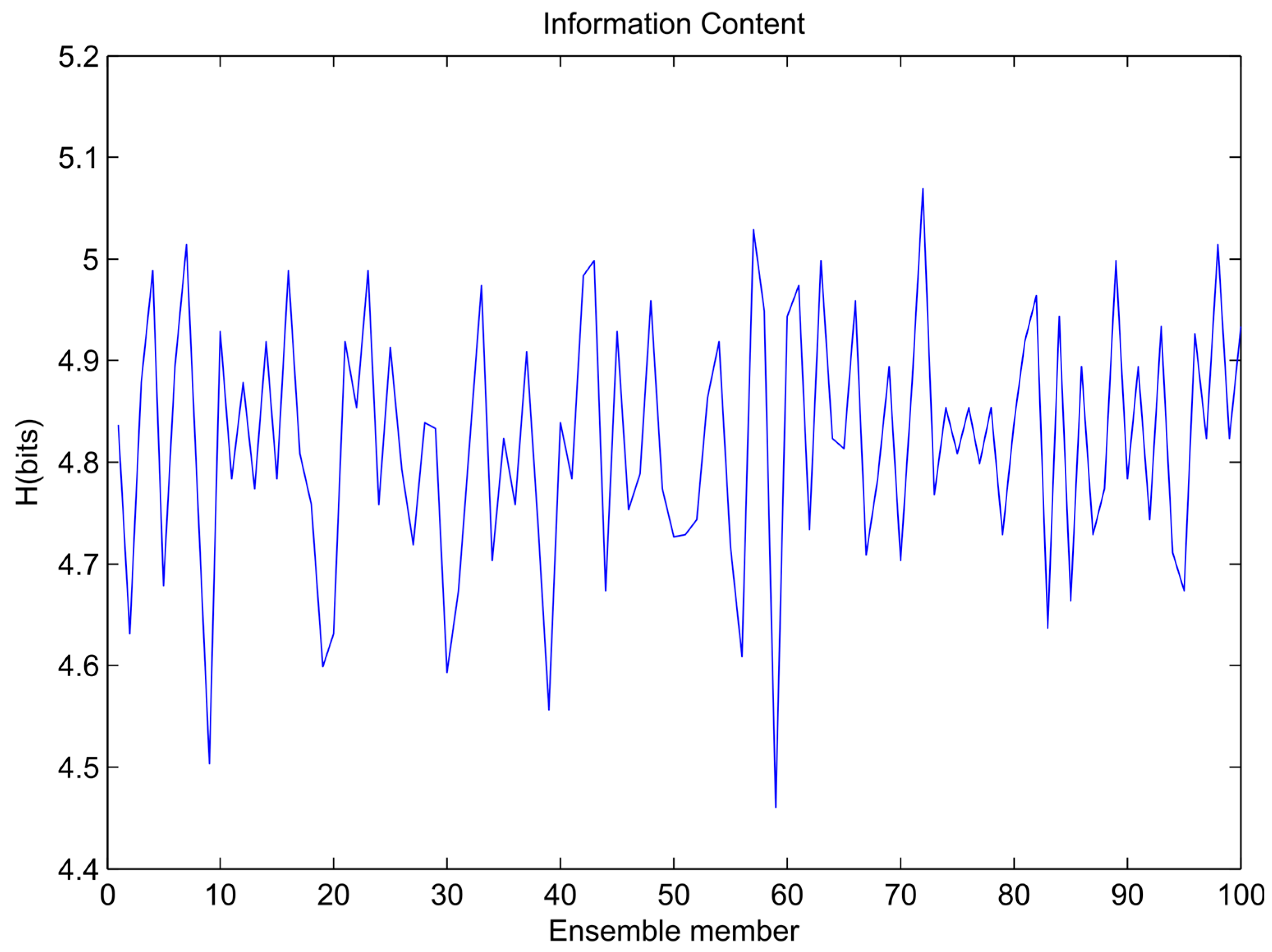
| 2 | Estimate the entropy of each ensemble member | |
| Hm ← Equation (1) | ||
| 3 | Find the top L ensemble member with maximum entropy | Determine L based on computational constraints. Alternative choice is to use 40% of members based on the analysis of error gradient (L = 0.4M) |
| Sort the ensemble members and find the L most informative ones | ||
| 4 | Set up neural networks or other machine learning techniques | |
| Use the most informative ensemble L members rather than M ensemble members for training or calibrating the weights inside the model | ||
| 5 | Use ensemble averages instead of individual ensemble models | |
| The rationale for using ensemble averages is that the expected error of the ensemble average is less than or equal to the average expected error of the individual models in the ensemble | ||
| End | ||
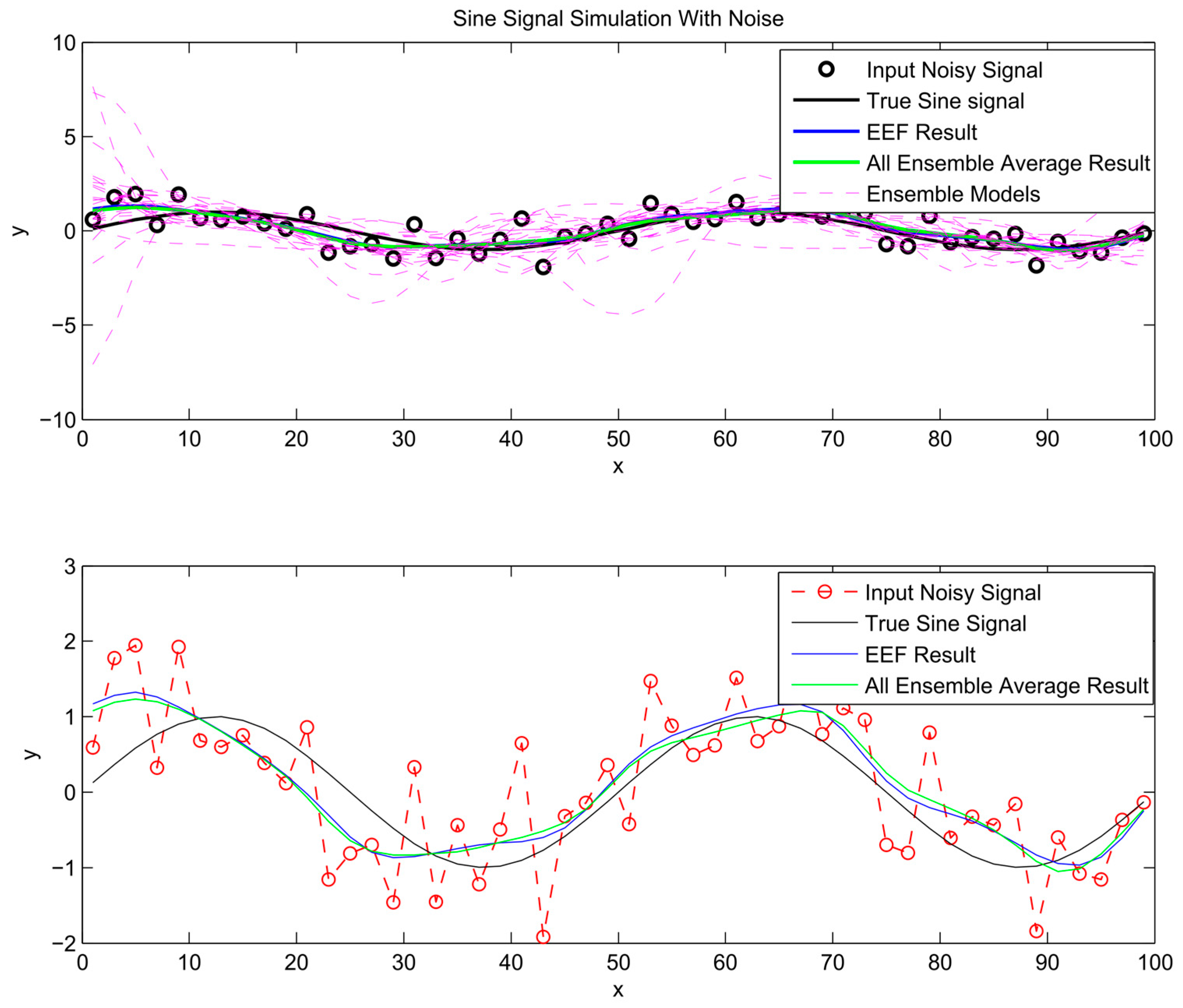
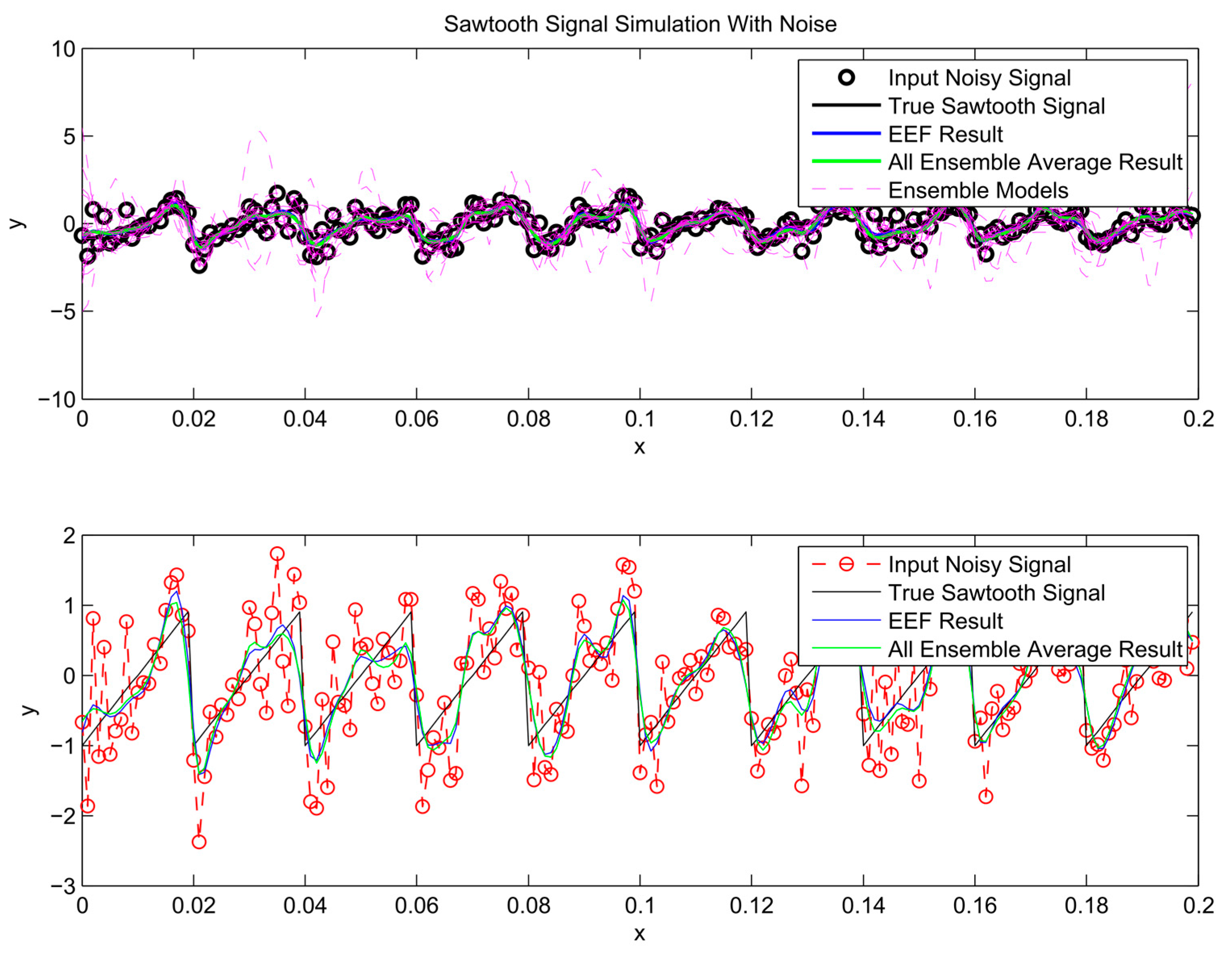
3. Application: Synthetic Data Simulation
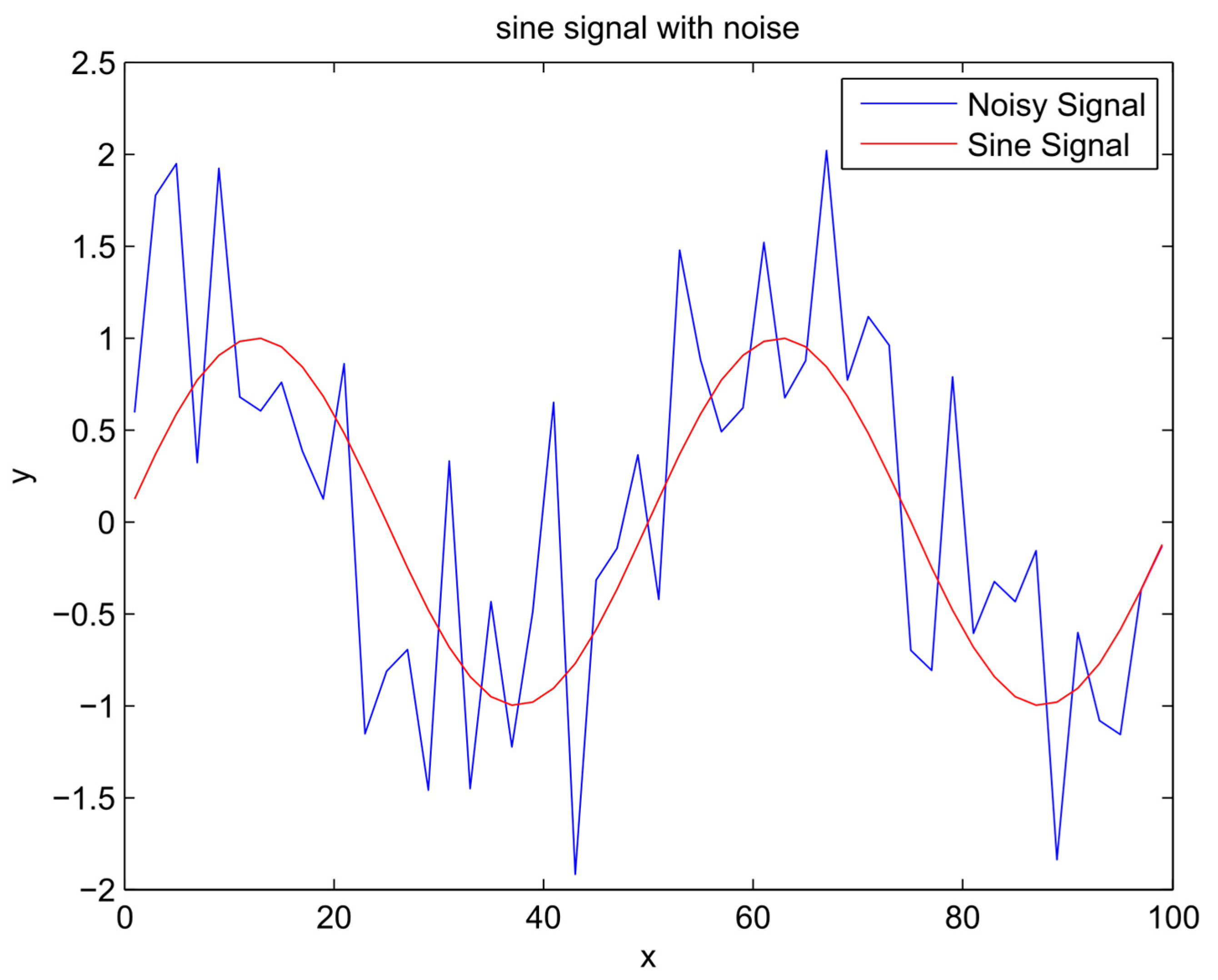
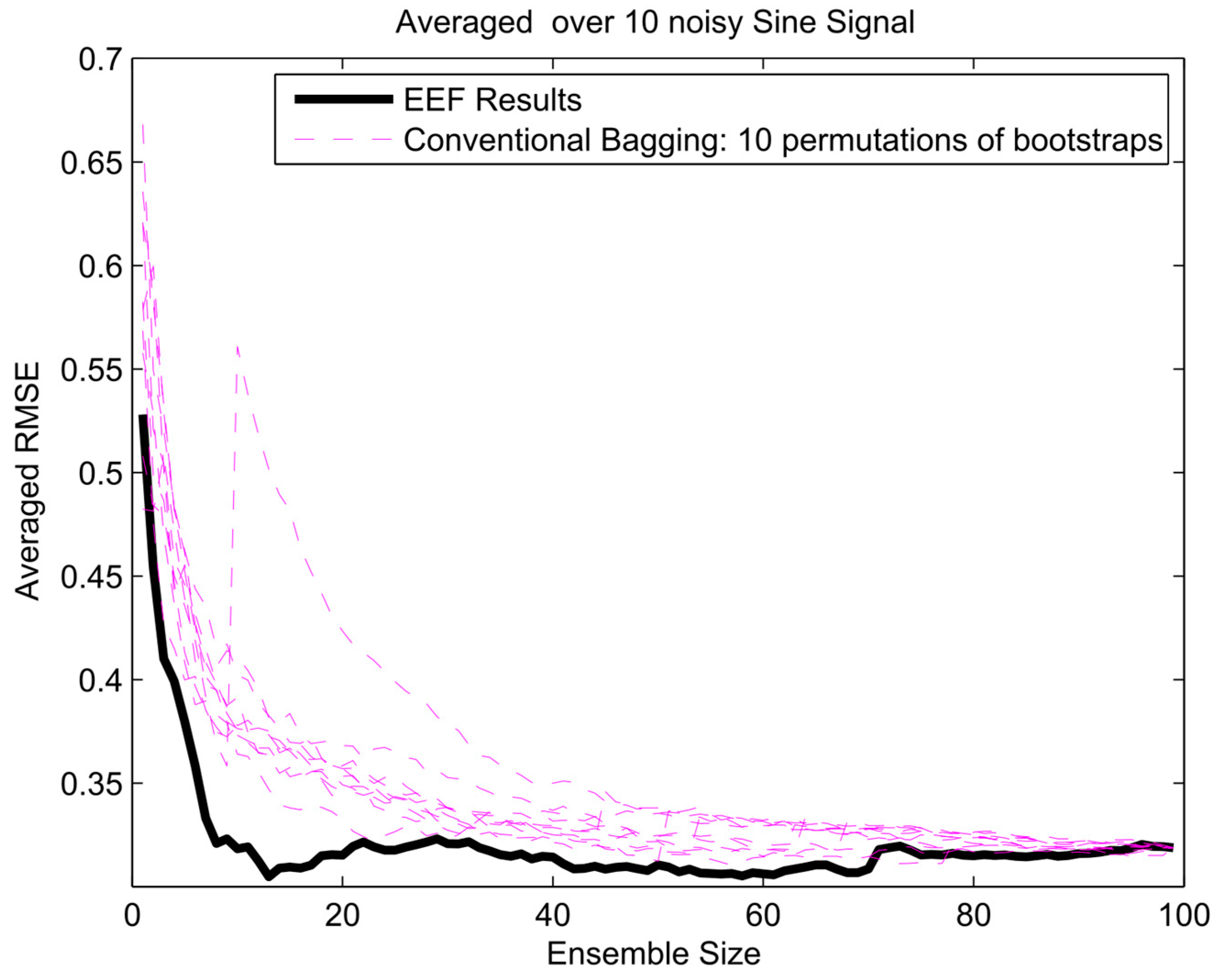
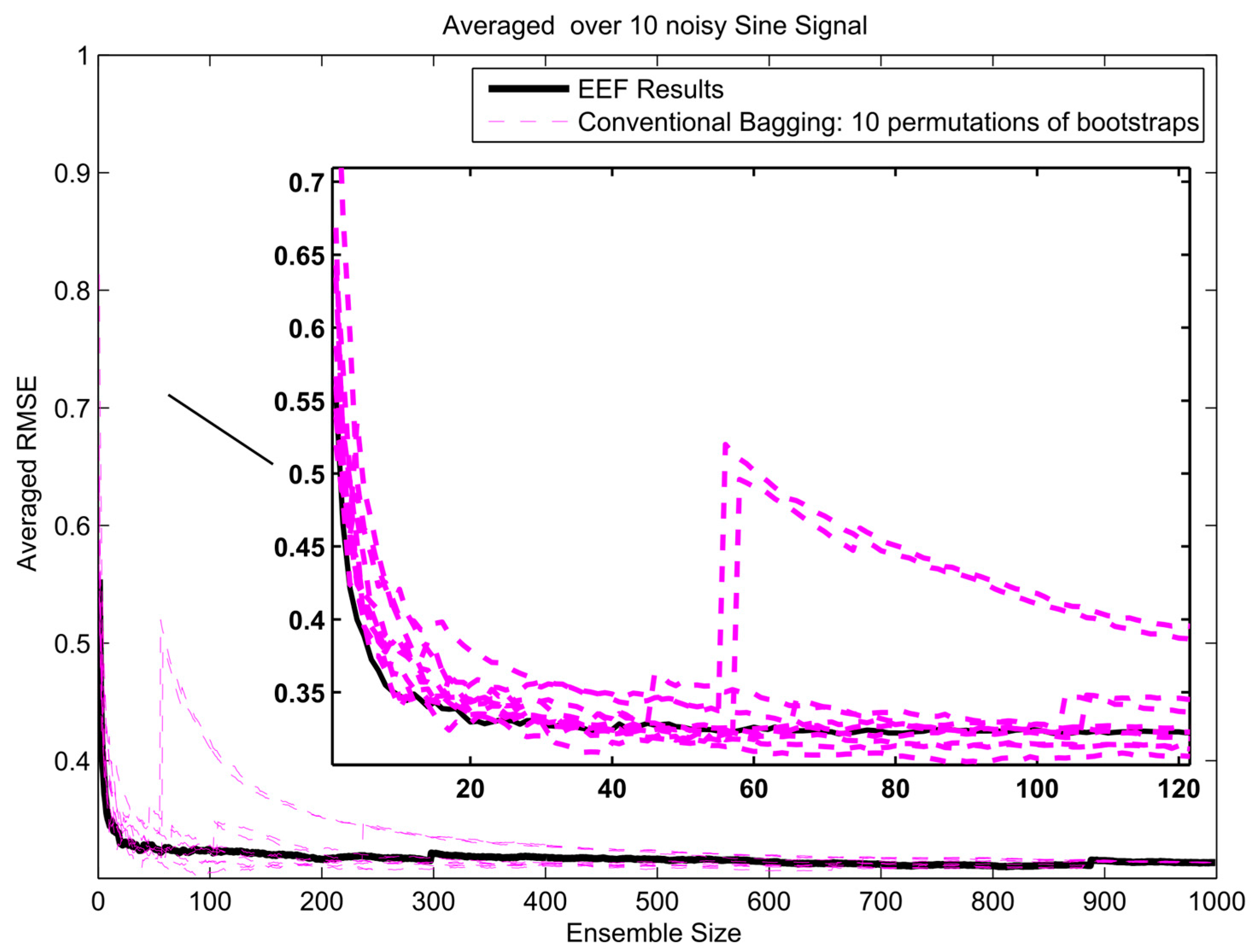
- Sinusoids are ubiquitous in physics because many physical systems that resonate or oscillate produce quasi-sinusoidal motion.
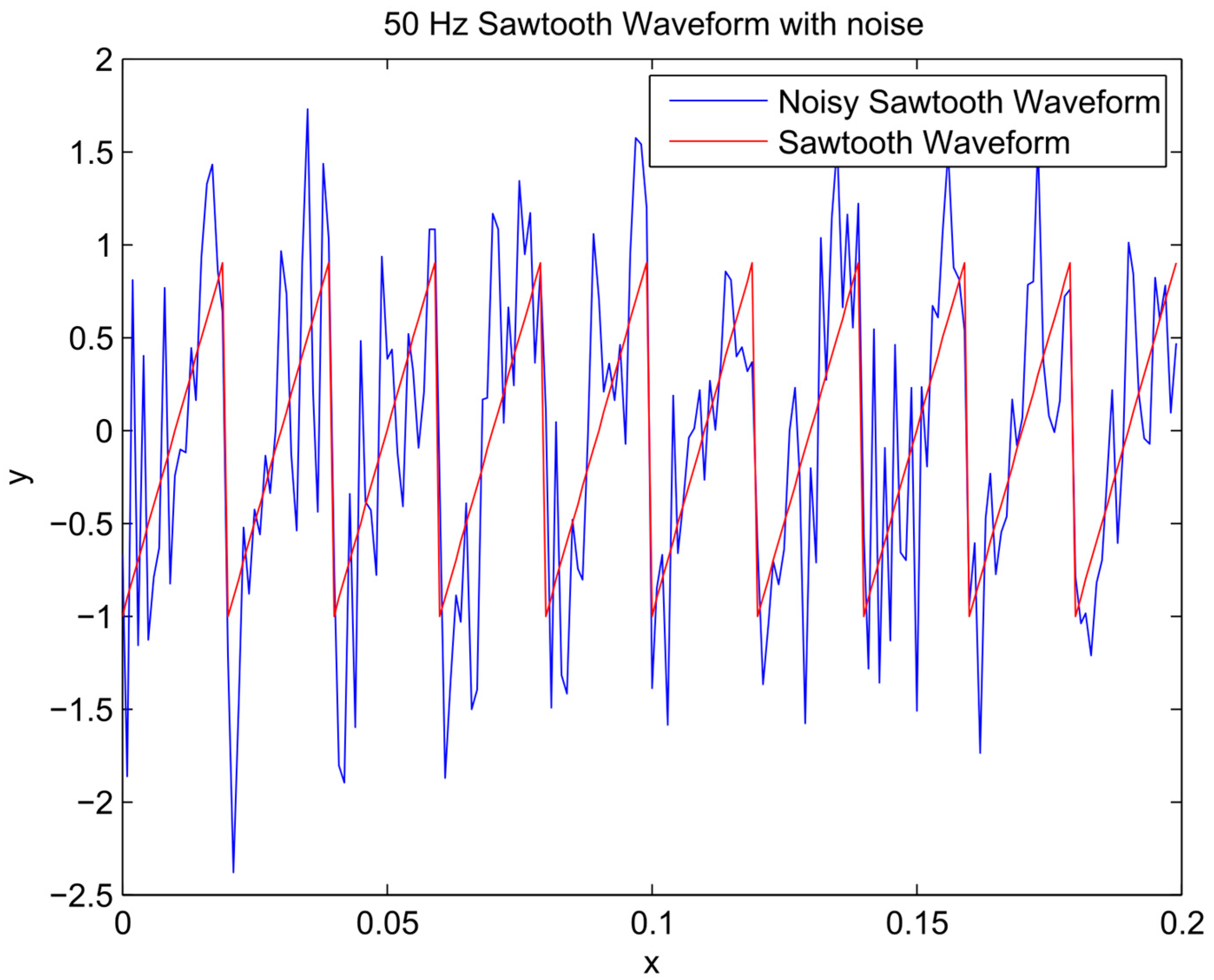
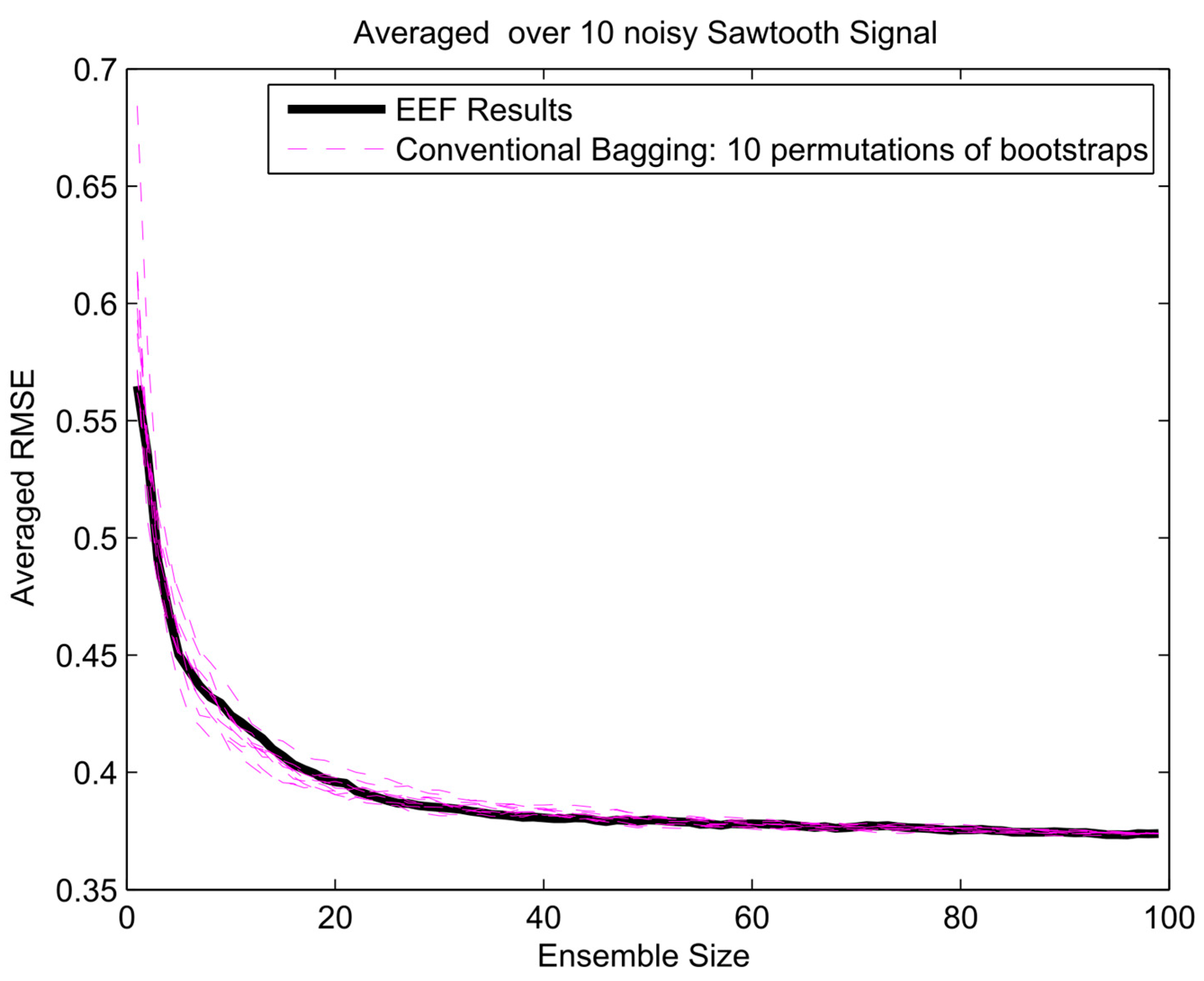
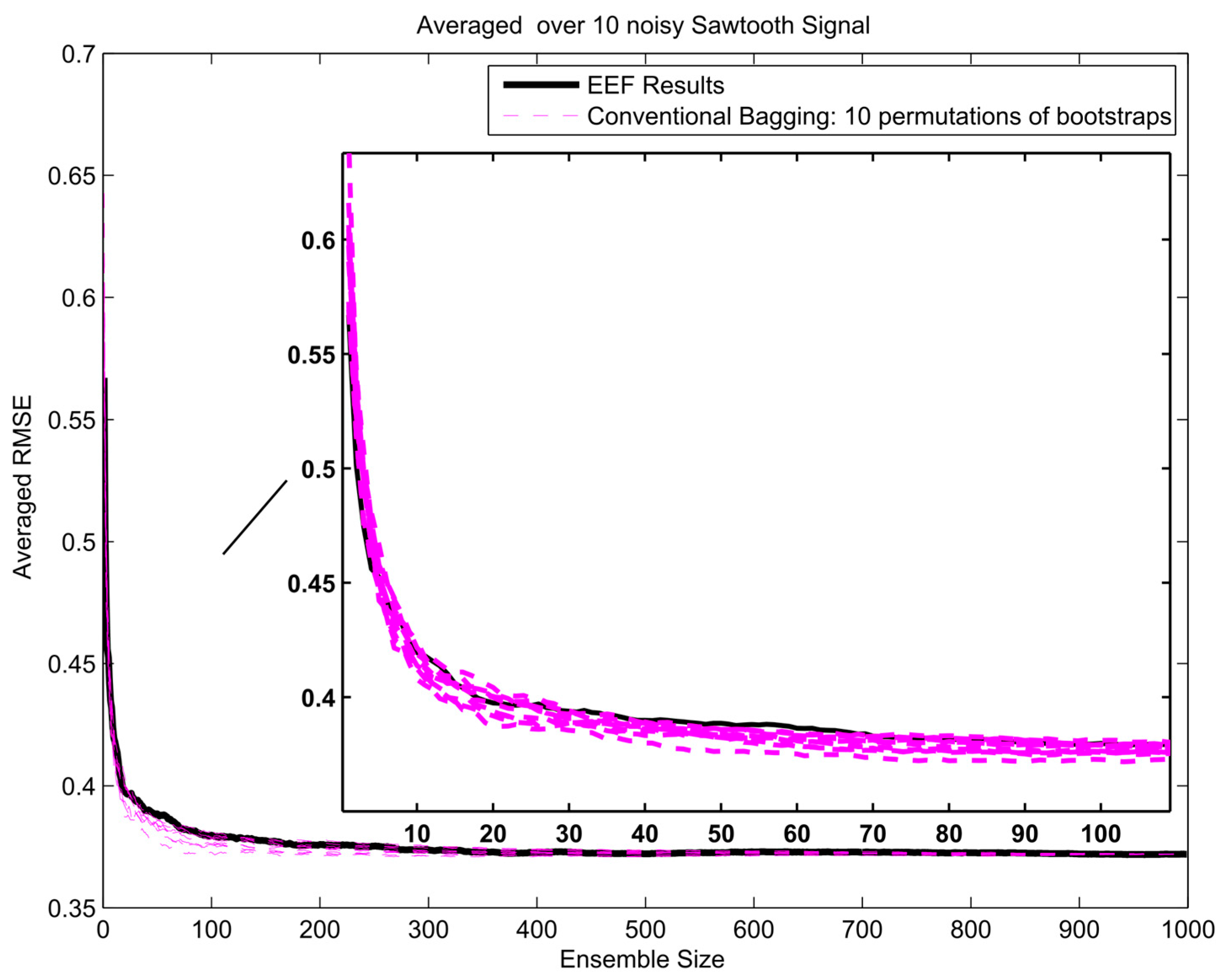
- The performance of the method for simulation of a non-sinusoidal waveform was tested on a sawtooth signal, a classical geometric waveform.
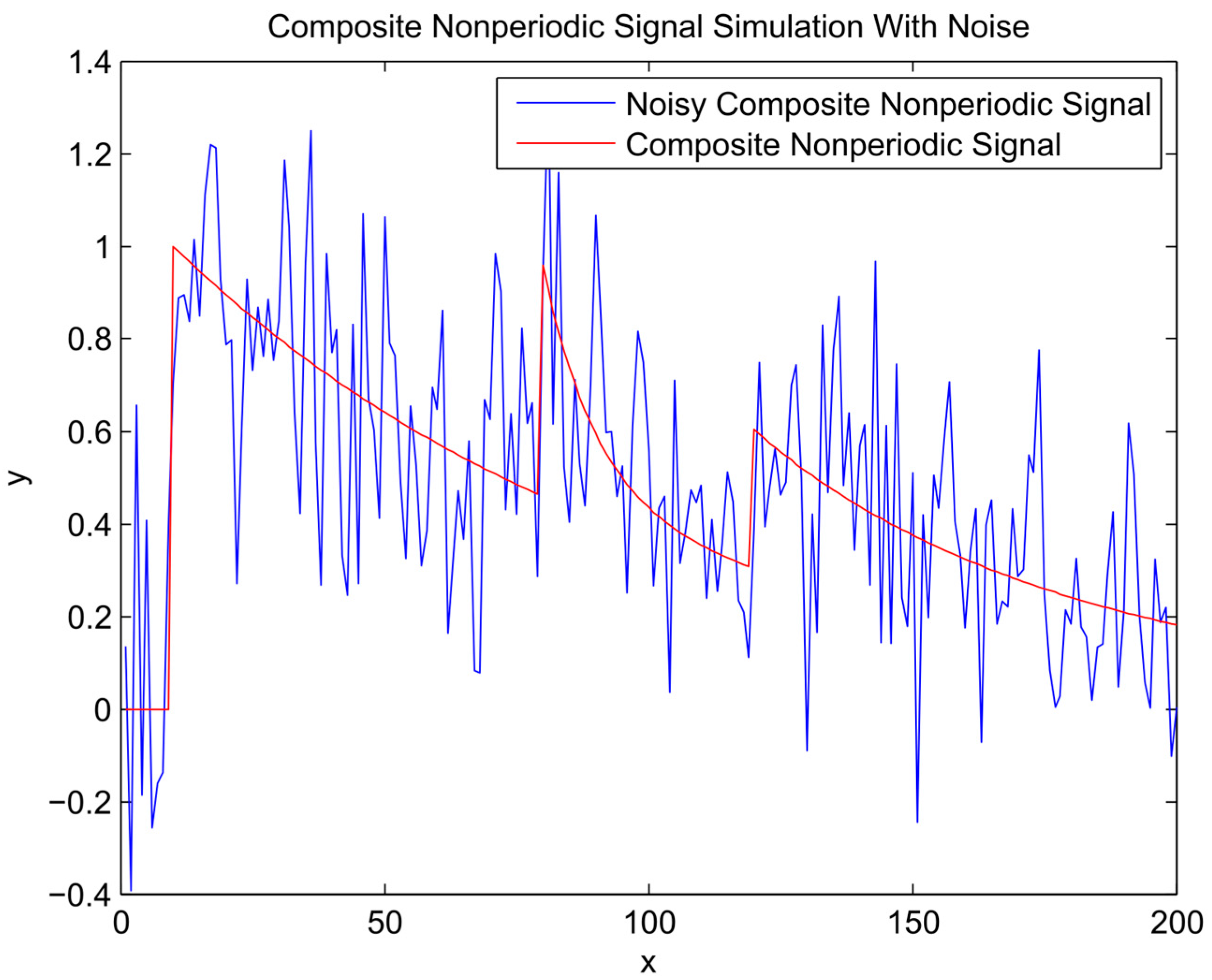
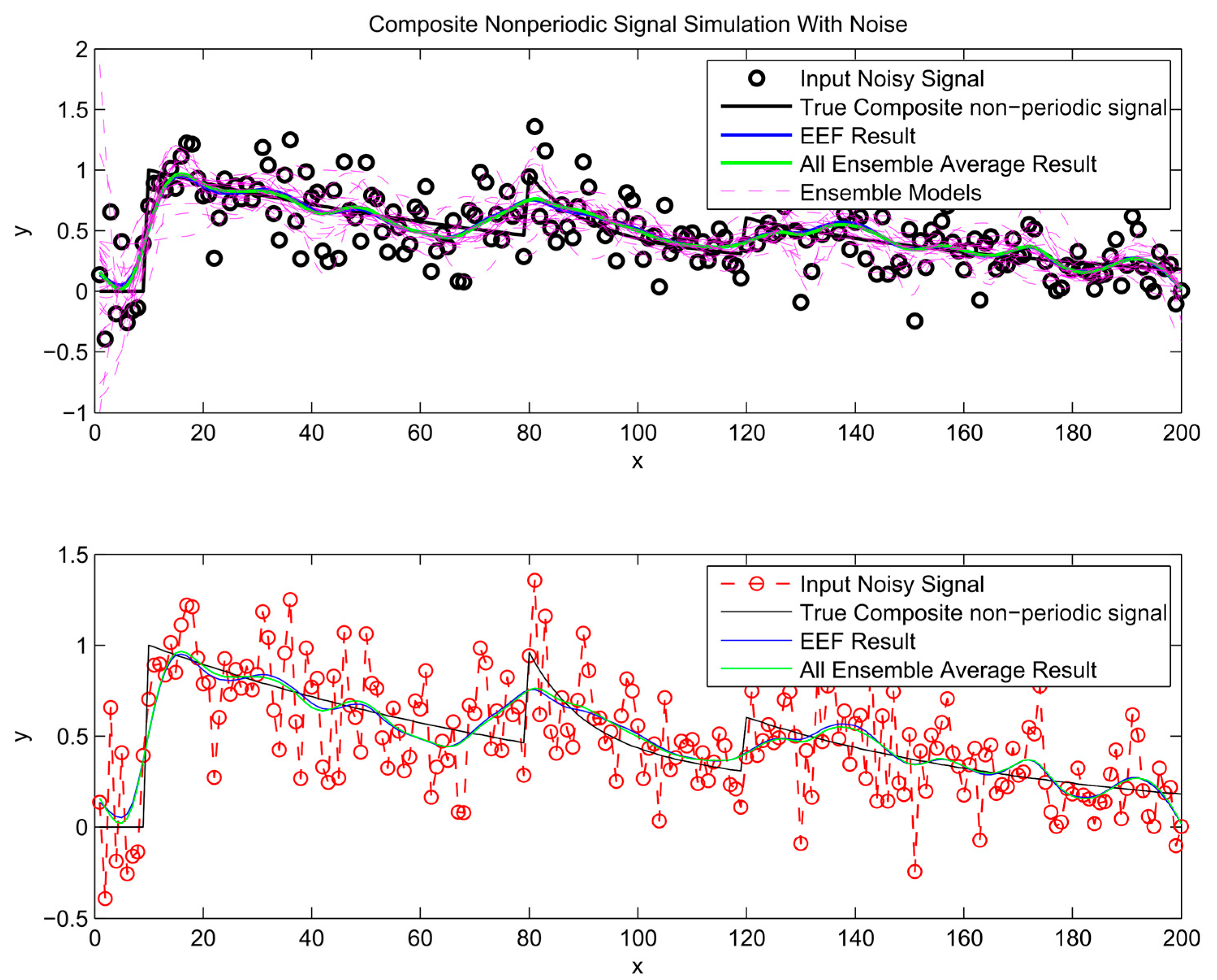
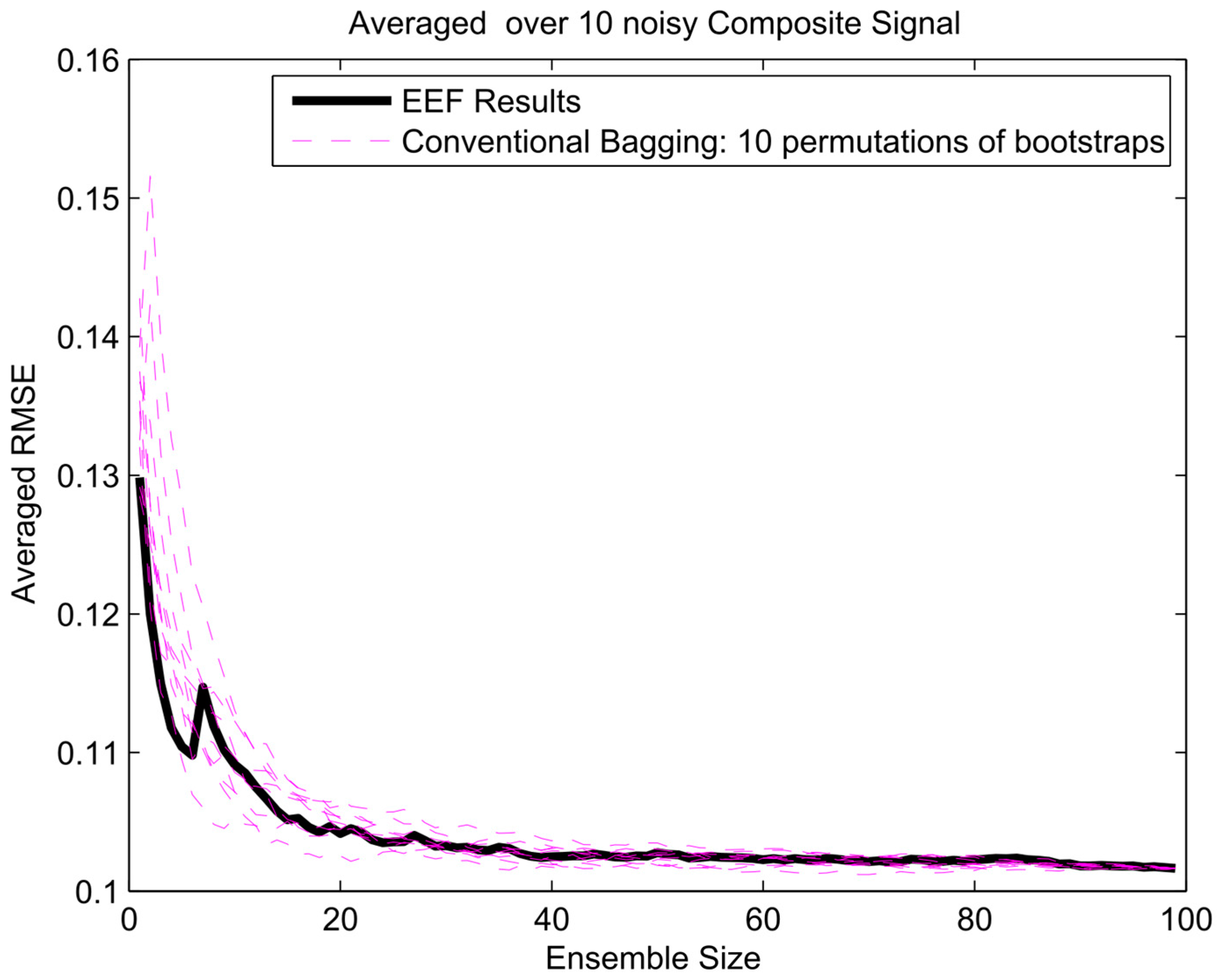
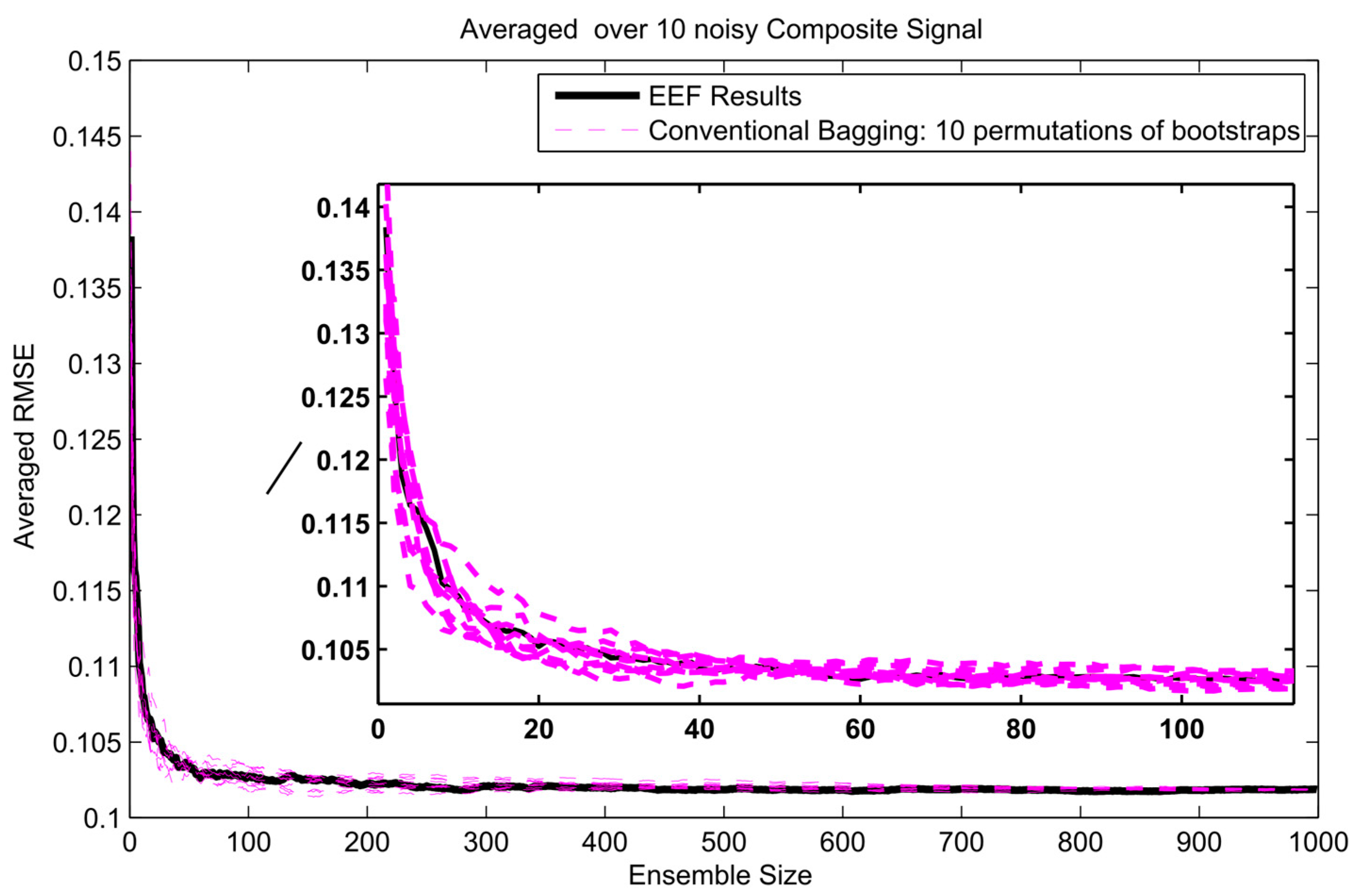
- A composite signal has been used to test the performance of the method for simulation of nonperiodic signals. The signal has been composed of upward steps followed by exponential decay functions, which resemble typical behaviour for river flow response to rainfall events.
Procedure
4. Results and Analysis
Protection against Overfitting
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Results of EFF Method for Three Different Signals

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| All Ensemble | EEF Ensemble | Run Time EEF Ensemble (s) | Run Time All Ensemble (s) | RMSE EEF Ensemble | RMSE All Ensemble | Average % of Saving Time | Average Rate of Change in Error |
|---|---|---|---|---|---|---|---|
| 100 | 56 | 14.7 | 25.0 | 0.374 | 0.361 | 0.46 | 0.05 |
| 100 | 94 | 23.0 | 24.0 | 0.372 | 0.375 | ||
| 100 | 23 | 6.0 | 24.3 | 0.361 | 0.400 | ||
| 100 | 55 | 14.0 | 23.7 | 0.367 | 0.380 | ||
| 100 | 86 | 21.0 | 24.6 | 0.340 | 0.395 | ||
| 100 | 44 | 11.0 | 24.6 | 0.364 | 0.397 | ||
| 100 | 35 | 8.5 | 26.3 | 0.342 | 0.377 | ||
| 100 | 21 | 4.6 | 25.1 | 0.362 | 0.389 | ||
| 100 | 52 | 11.8 | 25.1 | 0.357 | 0.380 | ||
| 100 | 83 | 19.8 | 24.9 | 0.386 | 0.385 | ||
| 200 | 151 | 40.7 | 57.4 | 0.349 | 0.398 | 0.56 | 0.04 |
| 200 | 54 | 13.4 | 48.8 | 0.374 | 0.375 | ||
| 200 | 103 | 23.7 | 47.6 | 0.340 | 0.376 | ||
| 200 | 97 | 22.3 | 49.4 | 0.355 | 0.371 | ||
| 200 | 166 | 39.1 | 47.7 | 0.374 | 0.369 | ||
| 200 | 61 | 15.4 | 52.5 | 0.401 | 0.411 | ||
| 200 | 28 | 6.9 | 46.8 | 0.389 | 0.387 | ||
| 200 | 106 | 23.8 | 49.3 | 0.363 | 0.366 | ||
| 200 | 69 | 16.0 | 47.6 | 0.383 | 0.394 | ||
| 200 | 86 | 19.4 | 48.1 | 0.381 | 0.404 | ||
| 1000 | 246 | 62.1 | 250.4 | 0.379 | 0.383 | 0.62 | 0.01 |
| 1000 | 647 | 161.7 | 257.1 | 0.371 | 0.368 | ||
| 1000 | 373 | 91.2 | 246.7 | 0.369 | 0.388 | ||
| 1000 | 413 | 100.9 | 251.3 | 0.363 | 0.374 | ||
| 1000 | 395 | 98.0 | 248.7 | 0.391 | 0.388 | ||
| 1000 | 624 | 156.0 | 251.1 | 0.381 | 0.382 | ||
| 1000 | 91 | 21.8 | 248.8 | 0.378 | 0.382 | ||
| 1000 | 6 | 1.4 | 250.2 | 0.378 | 0.384 | ||
| 1000 | 627 | 153.7 | 249.2 | 0.373 | 0.379 |
| All Ensemble | EEF Ensemble | Run Time EEF Ensemble | Run Time All Ensemble | RMSE EEF Ensemble | RMSE All Ensemble | Average % of Saving Time | Average Rate of Change in Error |
|---|---|---|---|---|---|---|---|
| 100 | 40 | 15.9 | 34.9 | 0.371 | 0.343 | 0.62 | −0.012 |
| 100 | 38 | 13.1 | 35.9 | 0.340 | 0.353 | ||
| 100 | 43 | 15.3 | 33.1 | 0.351 | 0.358 | ||
| 100 | 61 | 21.3 | 33.3 | 0.354 | 0.341 | ||
| 100 | 93 | 29.7 | 30.2 | 0.342 | 0.351 | ||
| 100 | 9 | 3.1 | 31.1 | 0.338 | 0.354 | ||
| 100 | 14 | 4.6 | 34.1 | 0.341 | 0.348 | ||
| 100 | 37 | 11.8 | 33.0 | 0.340 | 0.349 | ||
| 100 | 16 | 4.8 | 32.5 | 0.337 | 0.349 | ||
| 100 | 16 | 5.7 | 34.2 | 0.342 | 0.353 | ||
| 200 | 144 | 49.1 | 64.0 | 0.351 | 0.349 | 0.57 | −0.001 |
| 200 | 125 | 42.0 | 67.0 | 0.347 | 0.357 | ||
| 200 | 60 | 18.2 | 64.5 | 0.347 | 0.341 | ||
| 200 | 68 | 20.6 | 69.0 | 0.353 | 0.349 | ||
| 200 | 64 | 20.3 | 70.8 | 0.352 | 0.349 | ||
| 200 | 84 | 27.9 | 69.2 | 0.351 | 0.350 | ||
| 200 | 109 | 37.3 | 66.8 | 0.343 | 0.351 | ||
| 200 | 6 | 2.4 | 73.7 | 0.341 | 0.344 | ||
| 200 | 73 | 25.3 | 69.4 | 0.349 | 0.348 | ||
| 200 | 148 | 47.9 | 70.4 | 0.345 | 0.344 | ||
| 1000 | 861 | 278.5 | 312.6 | 0.346 | 0.342 | 0.50 | −0.004 |
| 1000 | 409 | 122.1 | 308.2 | 0.347 | 0.346 | ||
| 1000 | 142 | 41.0 | 313.3 | 0.344 | 0.345 | ||
| 1000 | 285 | 88.0 | 320.7 | 0.348 | 0.347 | ||
| 1000 | 511 | 154.8 | 313.4 | 0.347 | 0.343 | ||
| 1000 | 282 | 89.0 | 310.2 | 0.347 | 0.343 | ||
| 1000 | 743 | 222.5 | 311.5 | 0.343 | 0.343 | ||
| 1000 | 689 | 214.4 | 316.1 | 0.344 | 0.346 | ||
| 1000 | 948 | 306.1 | 320.5 | 0.346 | 0.344 |
| All Ensemble | EEF Ensemble | Run Time EEF Ensemble | Run Time All Ensemble | RMSE EEF Ensemble | RMSE All Ensemble | Average % of Saving Time | Average Rate of Change in Error |
|---|---|---|---|---|---|---|---|
| 100 | 91 | 28.6 | 34.3 | 0.09 | 0.089 | 0.4 | −0.019 |
| 100 | 32 | 10.4 | 44.1 | 0.089 | 0.092 | ||
| 100 | 78 | 24.7 | 37.4 | 0.091 | 0.09 | ||
| 100 | 91 | 34.5 | 41.9 | 0.093 | 0.09 | ||
| 100 | 55 | 18.9 | 34.7 | 0.092 | 0.09 | ||
| 100 | 72 | 23.1 | 34.3 | 0.09 | 0.089 | ||
| 100 | 76 | 25.6 | 33.7 | 0.091 | 0.089 | ||
| 100 | 26 | 9.2 | 36.5 | 0.092 | 0.089 | ||
| 100 | 83 | 29.3 | 36.6 | 0.095 | 0.093 | ||
| 100 | 36 | 13.7 | 33.8 | 0.094 | 0.089 | ||
| 200 | 69 | 22.2 | 61.9 | 0.088 | 0.088 | 0.48 | −0.001 |
| 200 | 76 | 24.2 | 64.6 | 0.092 | 0.092 | ||
| 200 | 175 | 56.5 | 63.6 | 0.089 | 0.089 | ||
| 200 | 29 | 10.4 | 65.9 | 0.089 | 0.088 | ||
| 200 | 189 | 59.4 | 65.9 | 0.092 | 0.092 | ||
| 200 | 112 | 38.5 | 62.3 | 0.092 | 0.09 | ||
| 200 | 60 | 19 | 66 | 0.091 | 0.09 | ||
| 200 | 174 | 54.6 | 67.4 | 0.091 | 0.091 | ||
| 200 | 55 | 16.1 | 66.7 | 0.09 | 0.09 | ||
| 200 | 115 | 36.7 | 68.4 | 0.089 | 0.091 | ||
| 1000 | 861 | 264.4 | 293.4 | 0.089 | 0.09 | 0.48 | 0.011 |
| 1000 | 317 | 93.7 | 291.6 | 0.089 | 0.09 | ||
| 1000 | 194 | 57.5 | 290 | 0.089 | 0.09 | ||
| 1000 | 71 | 19.7 | 294.7 | 0.089 | 0.092 | ||
| 1000 | 489 | 141.8 | 293.6 | 0.089 | 0.091 | ||
| 1000 | 534 | 155.3 | 290.7 | 0.09 | 0.09 | ||
| 1000 | 655 | 188.2 | 286.6 | 0.089 | 0.09 | ||
| 1000 | 673 | 196.5 | 288.3 | 0.089 | 0.091 | ||
| 1000 | 878 | 252.4 | 293.8 | 0.09 | 0.09 |
References
- Lazebnik, S.; Raginsky, M. Supervised Learning of Quantizer Codebooks by Information Loss Minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1294–1309. [Google Scholar] [CrossRef] [PubMed]
- Raginsky, M.; Rakhlin, A.; Tsao, M.; Wu, Y.; Xu, A. Information-Theoretic Analysis of Stability and Bias of Learning Algorithms. In Proceedings of the IEEE Information Theory Workshop (ITW), Cambridge, UK, 11–14 September 2016; pp. 26–30. [Google Scholar]
- Giffin, A.; Urniezius, R. Simultaneous State and Parameter Estimation Using Maximum Relative Entropy with Nonhomogenous Differential Equation Constraints. Entropy 2014, 16, 4974–4991. [Google Scholar] [CrossRef]
- Zaky, M.A.; Machado, J.A.T. On the Formulation and Numerical Simulation of Distributed-Order Fractional Optimal Control Problems. Commun. Nonlinear Sci. Numer. Simul. 2017, 52, 177–189. [Google Scholar] [CrossRef]
- Hsieh, W.W. Machine Learning Methods in the Environmental Sciences: Neural Networks and Kernels, 1st ed.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2009. [Google Scholar]
- Huang, S.; Ming, B.; Huang, Q.; Leng, G.; Hou, B. A Case Study on a Combination NDVI Forecasting Model Based on the Entropy Weight Method. Water Resour. Manag. 2017, 31, 3667–3681. [Google Scholar] [CrossRef]
- Amato, F.; López, A.; Peña-Méndez, E.M.; Vaňhara, P.; Hampl, A.; Havel, J. Artificial Neural Networks in Medical Diagnosis. J. Appl. Biomed. 2013, 11, 47–58. [Google Scholar] [CrossRef]
- Foroozand, H.; Afzali, S.H. A Comparative Study of Honey-Bee Mating Optimization Algorithm and Support Vector Regression System Approach for River Discharge Prediction. Case Study: Kashkan River Basin. In Proceedings of the International Conference on Civil Engineering Architecture and Urban Infrastructure (CIVILICA; COI: ICICA01_0049), Tabriz, Iran, 29–30 July 2015; Volume 1. [Google Scholar]
- Ghahramani, A.; Karvigh, S.A.; Becerik-Gerber, B. HVAC System Energy Optimization Using an Adaptive Hybrid Metaheuristic. Energy Build. 2017, 152, 149–161. [Google Scholar] [CrossRef]
- Elshorbagy, A.; Corzo, G.; Srinivasulu, S.; Solomatine, D.P. Experimental Investigation of the Predictive Capabilities of Data Driven Modeling Techniques in Hydrology—Part 2: Application. Hydrol. Earth Syst. Sci. 2010, 14, 1943–1961. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap, Softcover Reprint of the Original, 1st ed.; Chapman and Hall/CRC: New York, NY, USA, 1993. [Google Scholar]
- Zhu, L.; Jin, J.; Cannon, A.J.; Hsieh, W.W. Bayesian Neural Networks Based Bootstrap Aggregating for Tropical Cyclone Tracks Prediction in South China Sea. In Neural Information Processing; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 475–482. [Google Scholar]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. An Ensemble Classification-Based Approach Applied to Retinal Blood Vessel Segmentation. IEEE Trans. Biomed. Eng. 2012, 59, 2538–2548. [Google Scholar] [CrossRef] [PubMed]
- Brenning, A. Spatial Prediction Models for Landslide Hazards: Review, Comparison and Evaluation. Nat. Hazards Earth Syst. Sci. 2005, 5, 853–862. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Weijs, S.V.; van de Giesen, N. An Information-Theoretical Perspective on Weighted Ensemble Forecasts. J. Hydrol. 2013, 498, 177–190. [Google Scholar] [CrossRef]
- Shannon, C.E. Communication in the Presence of Noise. Proc. IRE 1949, 37, 10–21. [Google Scholar] [CrossRef]
- Weijs, S.V.; van de Giesen, N.; Parlange, M.B. HydroZIP: How Hydrological Knowledge Can Be Used to Improve Compression of Hydrological Data. Entropy 2013, 15, 1289–1310. [Google Scholar] [CrossRef] [Green Version]
- Le, T.A.; Baydin, A.G.; Zinkov, R.; Wood, F. Using Synthetic Data to Train Neural Networks Is Model-Based Reasoning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 9–14 May 2017; pp. 3514–3521. [Google Scholar]
- Peng, H.; Lima, A.R.; Teakles, A.; Jin, J.; Cannon, A.J.; Hsieh, W.W. Evaluating Hourly Air Quality Forecasting in Canada with Nonlinear Updatable Machine Learning Methods. Air Qual. Atmos. Health 2017, 10, 195–211. [Google Scholar] [CrossRef]















© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Foroozand, H.; Weijs, S.V. Entropy Ensemble Filter: A Modified Bootstrap Aggregating (Bagging) Procedure to Improve Efficiency in Ensemble Model Simulation. Entropy 2017, 19, 520. https://doi.org/10.3390/e19100520
Foroozand H, Weijs SV. Entropy Ensemble Filter: A Modified Bootstrap Aggregating (Bagging) Procedure to Improve Efficiency in Ensemble Model Simulation. Entropy. 2017; 19(10):520. https://doi.org/10.3390/e19100520
Chicago/Turabian StyleForoozand, Hossein, and Steven V. Weijs. 2017. "Entropy Ensemble Filter: A Modified Bootstrap Aggregating (Bagging) Procedure to Improve Efficiency in Ensemble Model Simulation" Entropy 19, no. 10: 520. https://doi.org/10.3390/e19100520
APA StyleForoozand, H., & Weijs, S. V. (2017). Entropy Ensemble Filter: A Modified Bootstrap Aggregating (Bagging) Procedure to Improve Efficiency in Ensemble Model Simulation. Entropy, 19(10), 520. https://doi.org/10.3390/e19100520