Multi-Modal Deep Hand Sign Language Recognition in Still Images Using Restricted Boltzmann Machine


Abstract
:1. Introduction
- (a)
- A generative model, Restricted Boltzmann Machine (RBM), is used for hand sign recognition. We benefit from the generative capabilities of the network and the need for fewer network parameters to achieve better generalization capabilities with fewer input data. Additionally, we show enhanced performance by the fusion of different RBM blocks, each one considering a different visual modality.
- (b)
- To improve the recognition performance against noise and missing data, our model is enriched with additional data in the form of augmentation based on cropped image regions and noisy regions.
- (c)
- We evaluate the robustness of the proposed model against different kinds of noise; as well as the effect of the different model hyper-parameters.
- (d)
- We provide state-of-the-art results on five public sign recognition datasets.
2. Materials and Methods
2.1. Related Work
- Deep-based models: In this category, the proposed models use deep learning approaches for accuracy improvement. A profoundly deaf sign language recognition model using the Convolutional Neural Network (CNN) was developed by Garcia and Viesca [5]. Their model classifies correctly some letters of the American alphabet when tested for the first time, and some other letters most of the time. They fine-tuned the GoogLeNet model and trained their model on American Sign Language (ASL) and the Finger Spelling Dataset from the University of Surrey’s Center for Vision, Speech, and Signal Processing and Massey University Gesture Dataset 2012 [5]. Koller et al. used Deep Convolutional Neural Network (DCNN) and Hidden-Markov-Model (HMM) to model mouth shapes to recognize sign language. The classification accuracy of their model outperformed state-of-the-art mouth model recognition systems [6]. An RGB ASL Image Dataset (ASLID) and a deep learning-based model were introduced by Gattupalli et al. to improve the pose estimation of the sign language models. They measured the recognition accuracy of two deep learning-based state-of-the-art methods on the provided dataset [7]. Koller et al. proposed a hybrid model, including CNN and Hidden Markov Model (HMM), to handle the sequence data in sign language recognition. They interpreted the output of their model in a Bayesian fashion [8]. Guo et al. suggested a tree-structured Region Ensemble Network (REN) for 3D hand pose estimation by dividing the last convolution outputs of CNN into some grid regions. They achieved state-of-the-art estimation accuracy on three public datasets [9]. Deng et al. designed a 3D CNN for hand pose estimation from a single depth image. This model directly produces the 3D hand pose and does not need further processing. They achieved state-of-the-art estimation accuracy on two public datasets [10]. A model-based deep learning approach has been suggested by Zhou et al. [11]. They used a 3D CNN with a kinematics-based layer to estimate the hand geometric parameters. The report of experimental results of their model shows that they attained state-of-the-art estimation accuracy on some publicly available datasets. A Deep Neural Network (DNN) has been proposed by the LIRIS team of ChaLearn challenge 2014 for hand gesture recognition from two input modalities, RGB and Depth. They achieved the highest accuracy results of the challenge, using early fusion of joint motion features from two input modalities [12]. Koller et al. presented a new approach to classify the input frames using an embedded CNN within an iterative Expectation Maximum (EM) algorithm. The proposed model has been evaluated on over 3000 manually labelled hand shape images of 60 different classes and led to 62.8 top-1 accuracy on the input data [13]. While their model is applied not only for image input but also for frame sequences of a video, there are many rooms to improve the model performance in the case of time and complexity due to using HMMs and the EM algorithm. Guo et al. [14] proposed a simple tree-structured REN for 3D coordinate regression of depth image input. They partitioned the last convolution outputs of ConvNet into several grid regions and integrated the output of fully connected (FC) regressors from regions into another FC layer.
- Non-deep models: In this category, the proposed model does not use deep learning approaches. Philomena and Jasmin suggested a smart system composed of a group of Flex sensors, machine learning and artificial intelligence concepts to recognize hand gestures and show the suitable form of outputs. Unfortunately, this system has been defined as a research project and the experimental results have not been reported [15]. Narayan Sawant designed and implemented an Indian Sign Language recognition system to recognize the 26-character alphabet by using the HSV color model and Principal Component Analysis (PCA) algorithm. In this work, the experimental results have not been reported [16]. Ullah designed a hand gesture recognition system using the Cartesian Genetic Programming (CGP) technique for American Sign Language (ASL). Unfortunately, the designed system is still restricted and slow. Improving the recognition accuracy and learning ability of the suggested system are necessary [17]. Kalsh and Garewal proposed a real-time system for hand sign recognition using different hand shapes. They used the Canny edge detection algorithm and Gray-level images. They selected only six alphabets of ASL and achieved a recognition accuracy of 100 [18]. An Adaptive Neuro-Fuzzy Inference System (ANFIS) was designed to recognize sign language by Wankhade and Zade. They compared the performance of Neural Network, HMM, and Adaptive Neuro-Fuzzy Inference System (ANFIS) for sign language recognition. Based on their experimental results for 35 samples, ANFIS had a higher accuracy than the other methods [19]. Plawiak et al. [20] designed a system for efficient recognition of hand body language based on specialized glove sensors. Their model used Probabilistic Neural Network, Support Vector Machine, and K-Nearest Neighbor algorithms for gesture recognition. The proposed model has been evaluated on data collected from ten people performing 22 hand body languages. While the experimental results show high recognition performance, gestures with low inter-class variability use are miss-classified.
2.2. Proposed Model
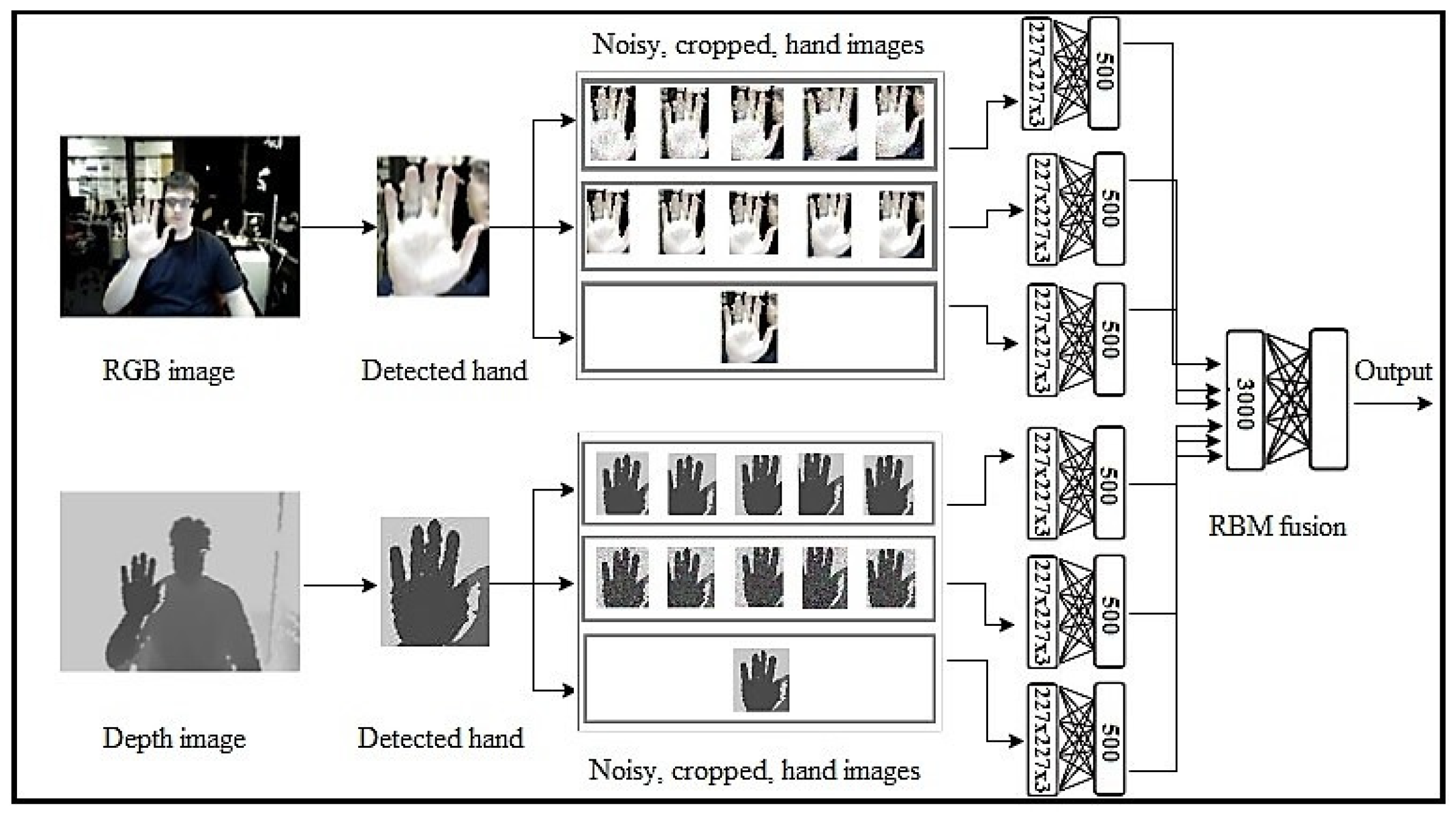
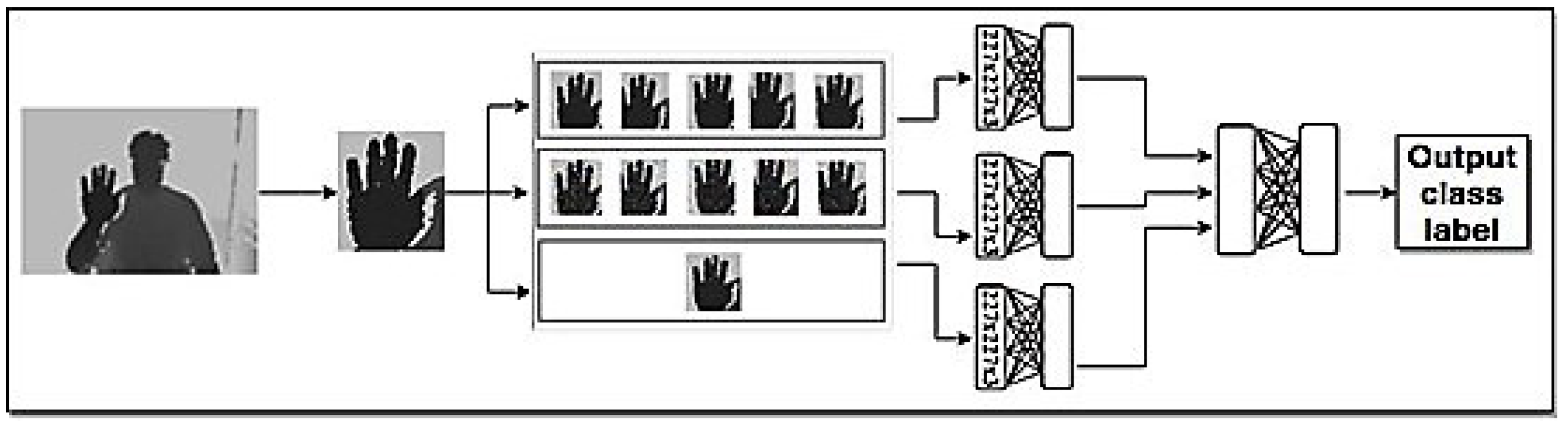
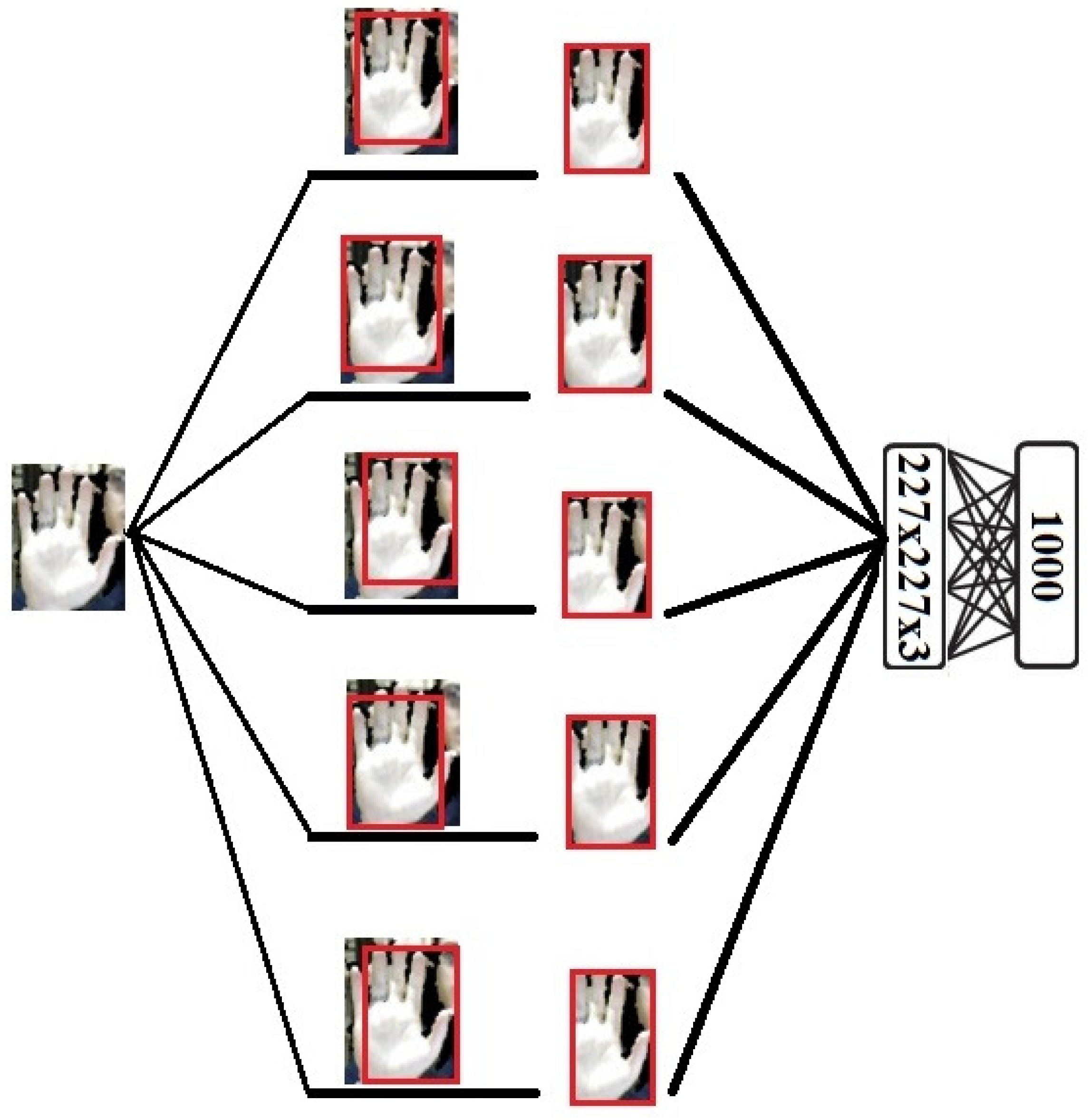
- Inputs: The original input images are entered into the model in order to extract their features. As Figure 1 shows, we use two modalities, RGB and Depth, in the input images. In the case of one modality in the input images, we use the model illustrated in Figure 2 and Figure 3 for depth and RGB input images.
- Hand detection: To improve the recognition accuracy of the proposed model, a fine-tuned CNN model, based on the Faster-RCNN model [2], is used to detect hands in the input images.
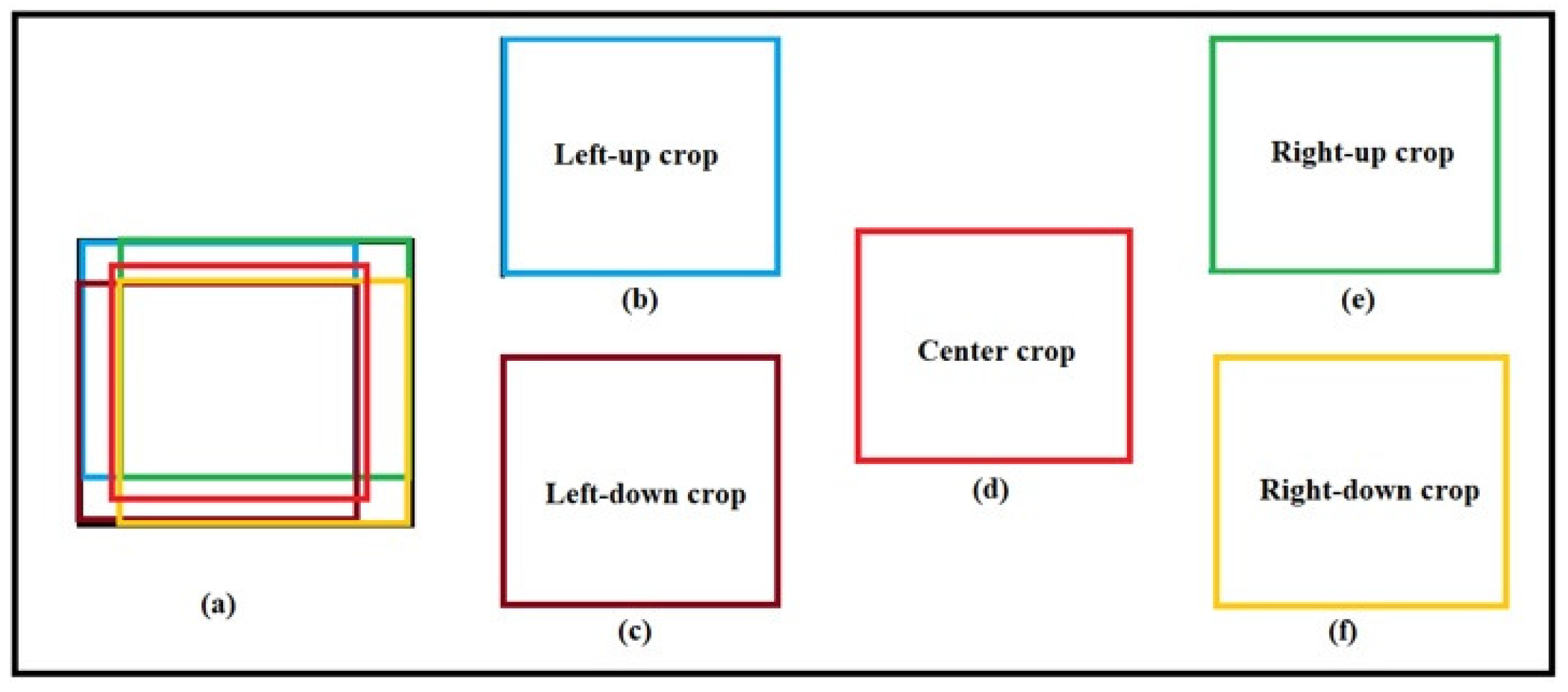
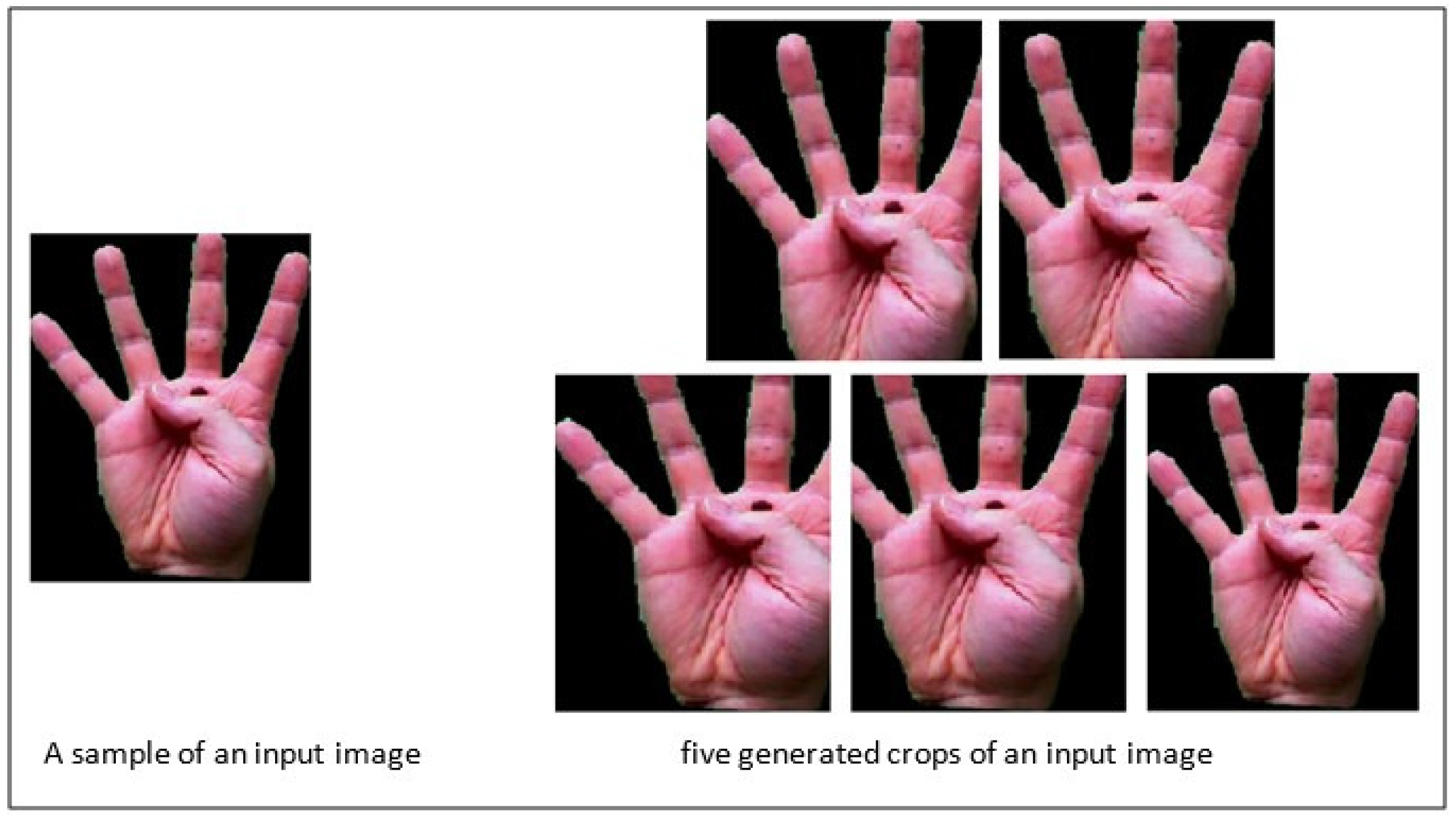
- Crop the images: The input images are cropped from five regions of the image using a CNN.
- Add noise: To increase the robustness of the proposed model, two types of noise, Gaussian and Salt-and-Pepper, are added to input images of the model.
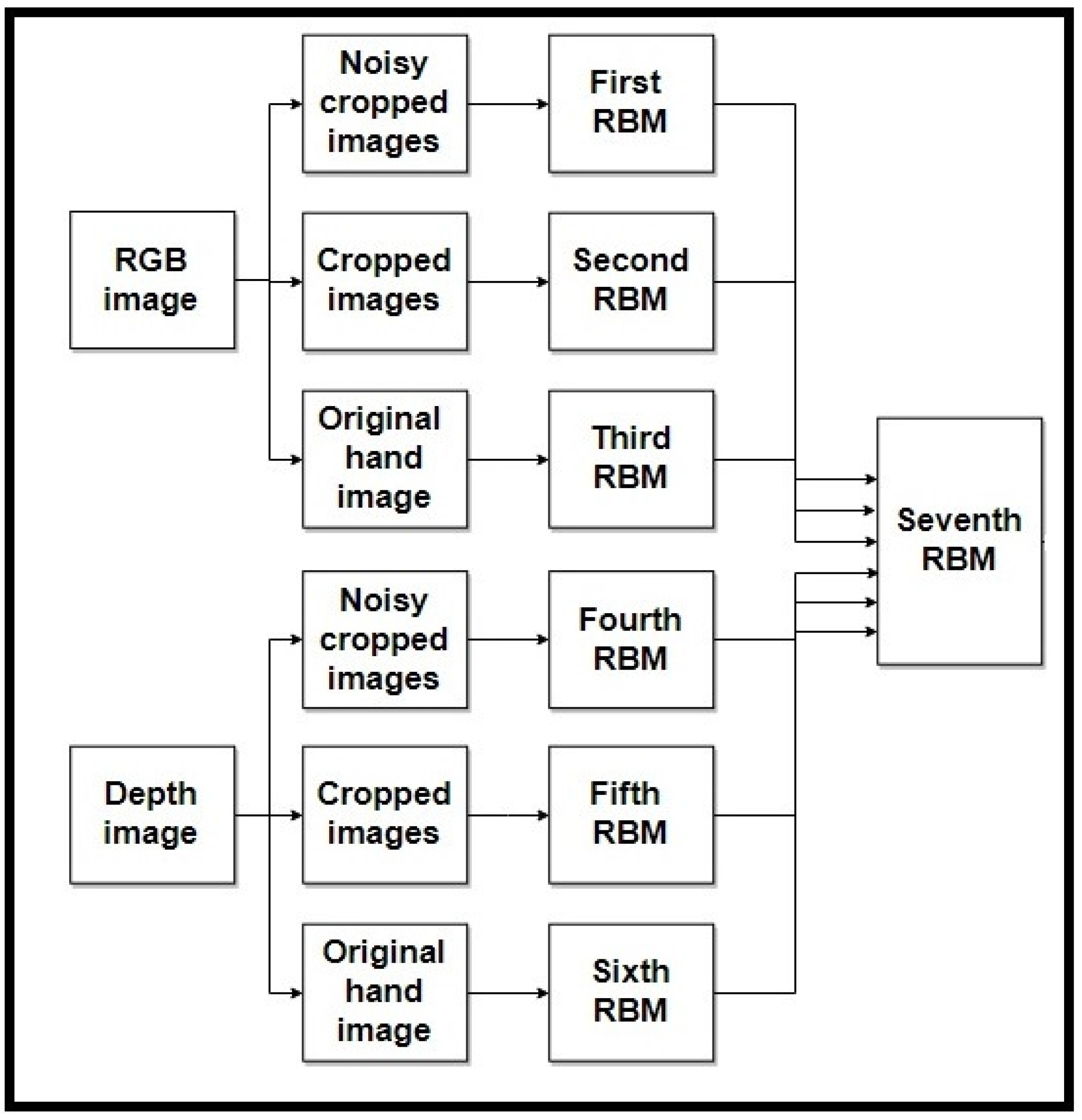
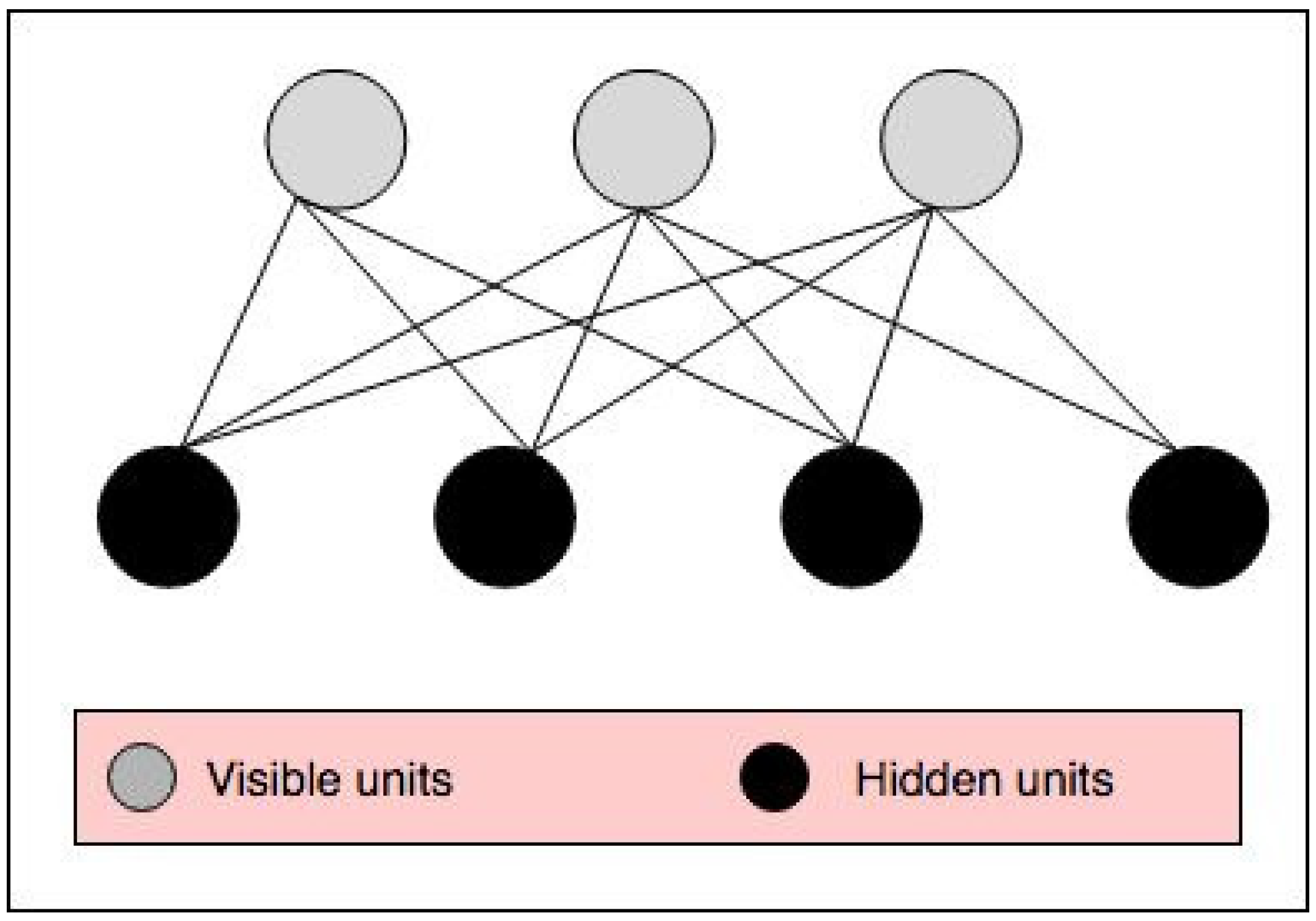
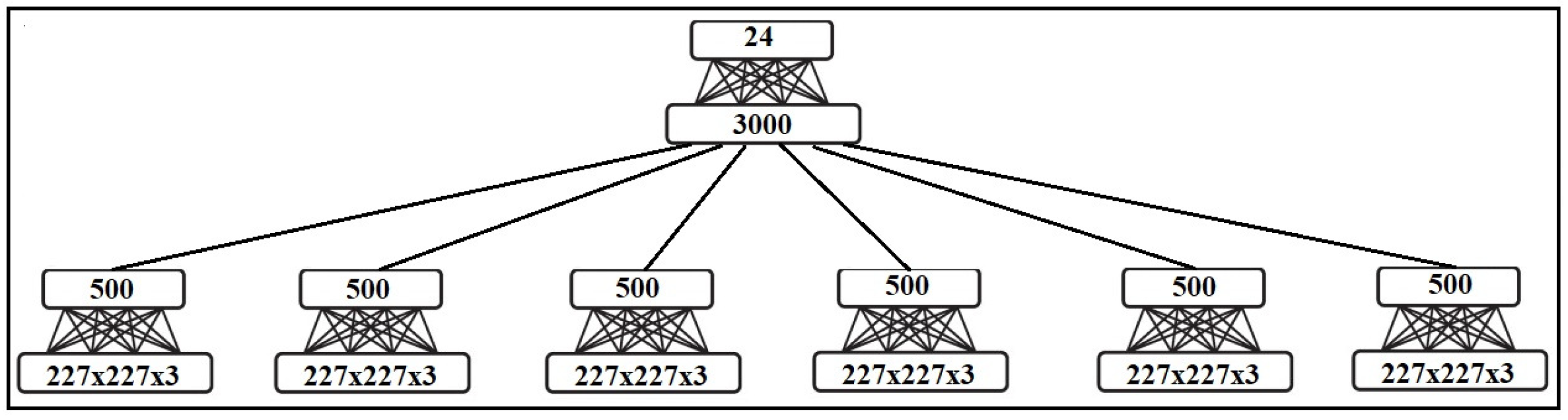
- Enter into the RBM: In the proposed model, we use not only two modalities, RGB and Depth, but also three forms of input image: an original input image, a five cropped input image, and a five noisy cropped input image. For each model, we use these three forms of input image and send them to the RBM. Six RBMs are used in this step as follows:First RBM: The inputs of the first RBM are five RGB noisy cropped images. Each of these five noisy crops is separately input to the RBM.Second RBM: Five crops of RGB input image are the inputs of the second RBM.Third RBM: Only the original detected hand of the RGB input image is considered as the input of third RBM.Fourth RBM: Five depth noisy cropped images are separately sent to the fourth RBM.Fifth RBM: The inputs of the fifth RBM are five depth cropped images.Sixth RBM: The original depth detected hand is considered as the input of the sixth RBM.
- RBM outputs fusion: We use another RBM for fusing the outputs of six RBMs used in the previous step. The outputs of six RBMs are fused and input into the seventh RBM in order not only to decrease the dimension but also to generate the distribution of data to recognize the final hand sign label. In Figure 1, we show how to use these RBMs in our model.
2.2.1. Input Image
2.2.2. Hand Detecting
2.2.3. Image Cropping
2.2.4. Add Noise
- TSet1: In this test set, Gaussian noise is added to the data.
- TSet2: In this test set, Salt-and-Pepper noise is added to the data.
- TSet3: In this test set, Gaussian noise is added to one part of data and Salt-and-Pepper noise is added to another part of data.
- TSet4: In this test set, Gaussian Blur noise is added to the data.
2.2.5. Entry into the RBM
2.2.6. Outputs Fusing
3. Results and Discussion
3.1. Implementation Details
3.2. Datasets
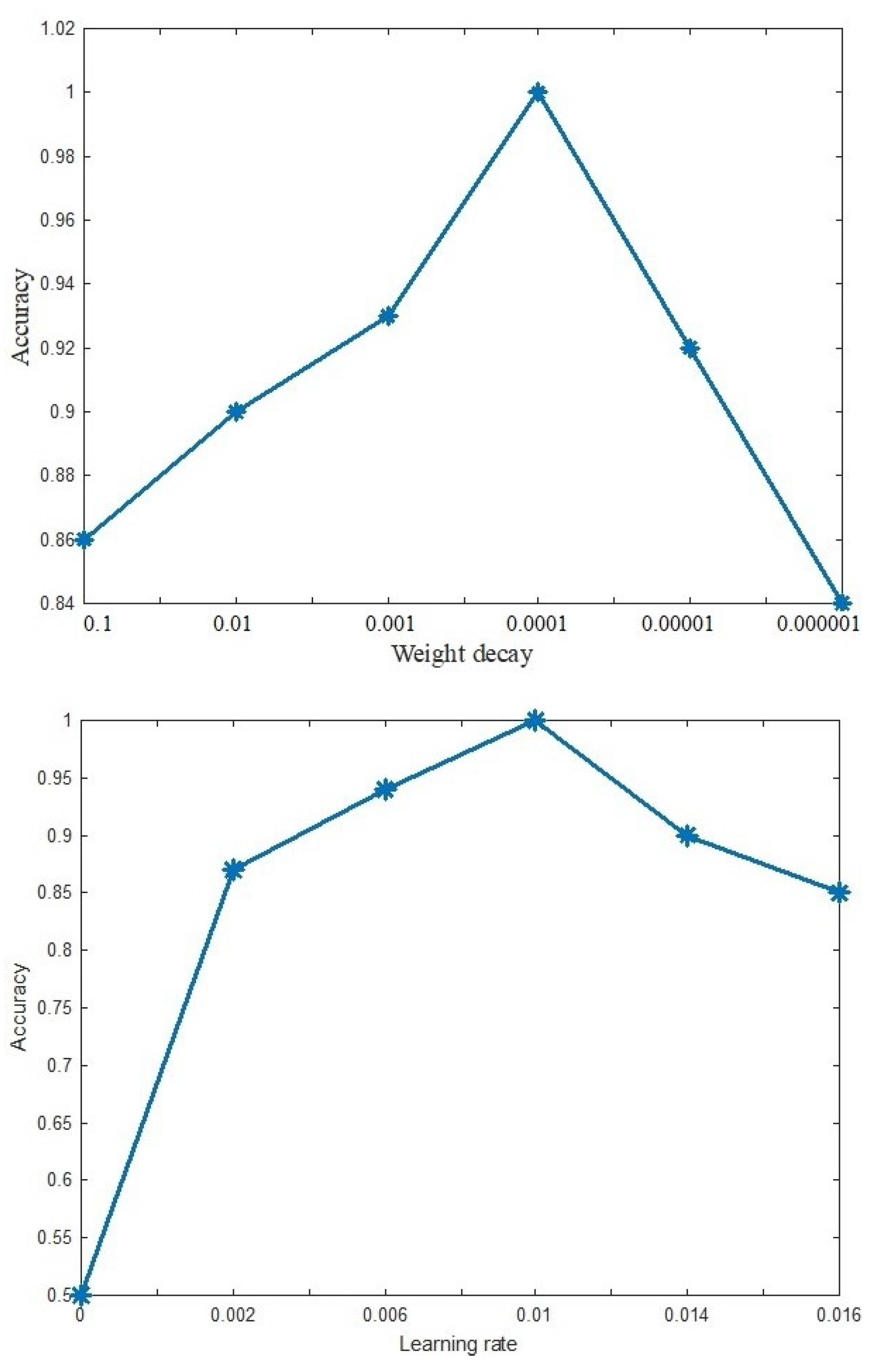
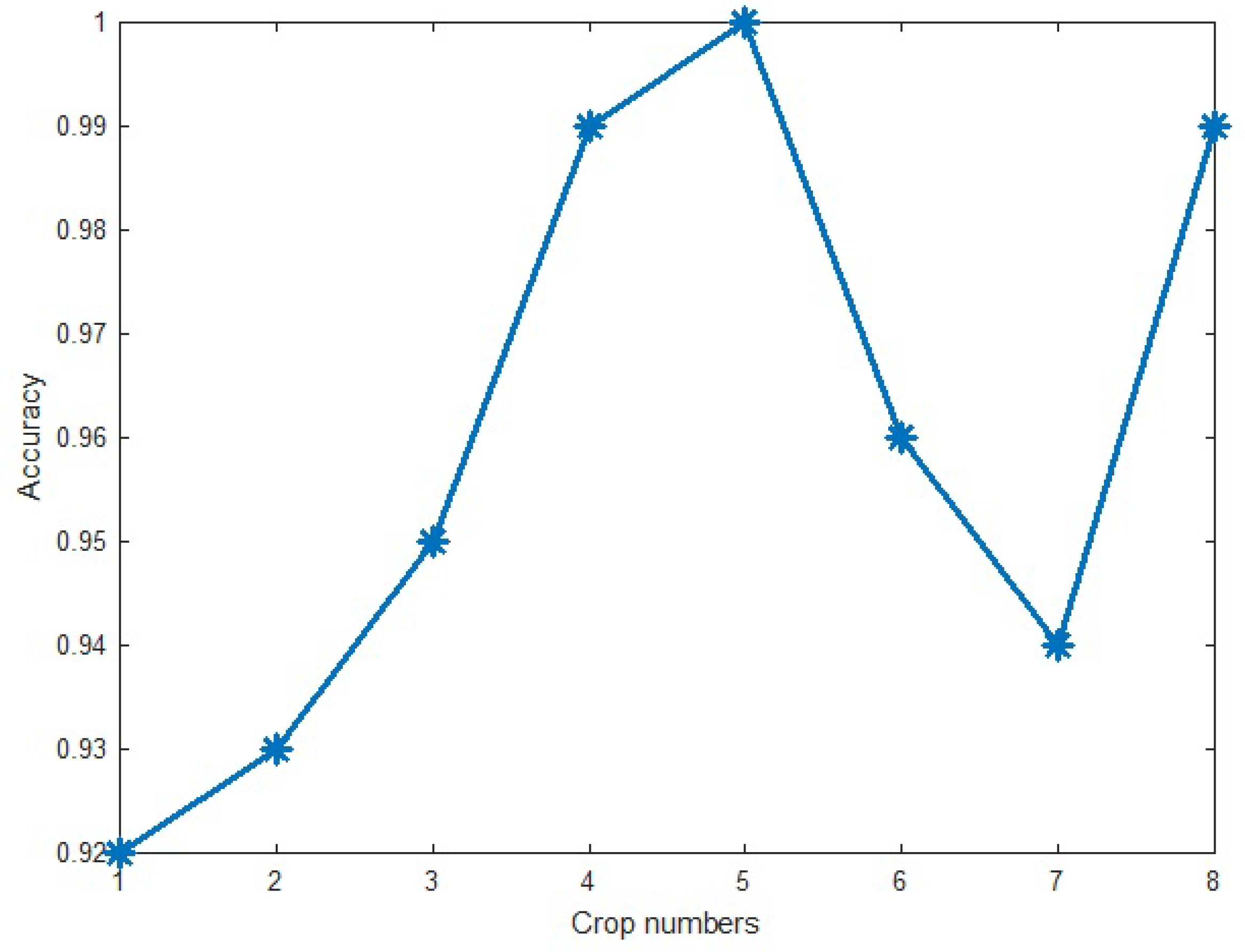
3.3. Parameter Evaluation
3.4. Self-Comparison
3.5. Evaluating the Robustness to Noise of the Proposed Method
- TSet1: In this test set, the Gaussian noise with zero mean and variance equal to 0.16 is added.
- TSet2: In this test set, the Salt-and-Pepper noise with noise density equal to 0.13 is added.
- TSet3: In this test set, the Gaussian noise with zero mean, variance equal to 0.16 is added to one part of data, and Salt-and-Pepper noise with noise density equal to 0.13 is added to another part of data.
- TSet4: In this test set, the Gaussian Blur noise with zero mean and variance equal to 0.16 is added.
3.6. State-of-the-Art Comparison
- Category1: In this category, two models are trained on alphabets to include a–y.
- Category2: In this category, two models are trained on alphabets to include a–k.
- Category3: In this category, two models are trained on alphabets to include a–e.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| RBM | Restricted Boltzmann Machine |
| CNN | Convolutional Neural Network |
| DCNN | Deep Convolutional Neural Network |
| RPN | Region Proposal Network |
| CD | Contrastive Divergence |
| SGD | Stochastic Gradient Descent |
| EM | Expectation Maximum |
| PCA | Principal Component Analysis |
References
- Philomina, S.; Jasmin, M. Hand Talk: Intelligent Sign Language Recognition for Deaf and Dumb. Int. J. Innov. Res. Sci. Eng. Technol. 2015, 4. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suharjito, S.; Anderson, R.; Wiryana, F.; Ariesta, M.C.; Kusuma, G.P. Sign Language Recognition Application Systems for Deaf-Mute People: A Review Based on Input-Process-Output. Procedia Comput. Sci. 2017, 116, 441–448. [Google Scholar] [CrossRef]
- Cheok, M.J.; Omar, Z.; Jaward, M.H. A review of hand gesture and sign language recognition techniques. Int. J. Mach. Learn. Cybern. 2017, 1–23. [Google Scholar] [CrossRef]
- Garcia, B.; Viesca, S. Real-time American Sign Language Recognition with Convolutional Neural Networks. Reports. Stanford University: Stanford, CA, USA, 2016. Available online: http://cs231n.stanford.edu/reports/2016/pdfs/214_Report.pdf (accessed on 5 October 2018).
- Koller, O.; Ney, H.; Bowden, R. Deep Learning of Mouth Shapes for Sign Language. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Gattupalli, S.; Ghaderi, A.; Athitsos, V. Evaluation of Deep Learning based Pose Estimation for Sign Language Recognition. In Proceedings of the 9th ACM International Conference on Technologies Related to Assistive Environments, Corfu, Greece, 29 June–1 July 2016. [Google Scholar]
- Koller, O.; Zargaran, O.; Ney, H.; Bowden, R. Deep Sign: Hybrid CNN-HMM for Continuous Sign Language Recognition. In Proceedings of the 2016 British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016; pp. 3793–3802. [Google Scholar]
- Guo, H.; Wang, G.; Chen, X.; Zhang, C.; Qiao, F.; Yang, H. Region ensemble network: Improving convolutional network for hand pose estimation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4512–4516. [Google Scholar]
- Deng, X.; Yang, S.; Zhang, Y.; Tan, P.; Chang, L.; Wang, H. Hand3D: Hand Pose Estimation using 3D Neural Network. arXiv, 2017; arXiv:1704.02224. [Google Scholar]
- Zhou, X.; Wan, Q.; Zhang, W.; Xue, X.; Wei, Y. Model-based Deep Hand Pose Estimation. arXiv, 2016; arXiv:1606.06854v1. [Google Scholar]
- Escalera, S.; Baró, X.; Gonzalez, J.; Bautista, M.A.; Madadi, M.; Reyes, M.; Ponce-López, V.; Escalante, H.J.; Shotton, J.; Guyon, I. ChaLearn Looking at People Challenge 2014: Dataset and Results. In ECCV 2014: Computer Vision—ECCV 2014 Workshops; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Koller, O.; Ney, H.; Bowden, R. Deep Hand: How to Train a CNN on 1 Million Hand Images When Your Data Is Continuous and Weakly Labelled. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Guo, H.; Wang, G.; Chen, X.; Zhang, C. Towards Good Practices for Deep 3D Hand Pose Estimation. arXiv, 2017; arXiv:1707.07248v1. [Google Scholar]
- Kumar, P.; Gauba, H.; Roy, P.P.; Dogra, D.P. Coupled HMM-based multi-sensor data fusion for sign language recognition. Pattern Recognit. Lett. 2017, 86, 1–8. [Google Scholar] [CrossRef]
- Sawant, S.N. Sign Language Recognition System to aid Deaf-dumb People Using PCA. Int. J. Comput. Sci. Eng. Technol. (IJCSET) 2014, 5, 570–574. [Google Scholar]
- Ullah, F. American Sign Language Recognition System for Hearing Impaired People Using Cartesian Genetic Programming. In Proceedings of the 5th International Conference on Automation, Robotics and Applications, Wellington, New Zealand, 6–8 December 2011. [Google Scholar]
- Kalsh, E.A.; Garewal, N.S. Sign Language Recognition System. Int. J. Comput. Eng. Res. 2013, 3, 15–21. [Google Scholar]
- Wankhade, M.K.A.; Zade, G.N. Sign Language Recognition For Deaf And Dumb People Using ANFIS. Int. J. Sci. Eng. Technol. Res. (IJSETR) 2014, 3, 1206–1210. [Google Scholar]
- Pławiak, P.; Sośnicki, T.; Niedźwiecki, M.; Tabor, Z.; Rzecki, K. Hand Body Language Gesture Recognition Based on Signals From Specialized Glove and Machine Learning Algorithms. IEEE Trans. Ind. Inform. 2016, 12, 1104–1113. [Google Scholar] [CrossRef]
- Hinton, G.E. A Practical Guide to Training Restricted Boltzmann Machines. In Neural Networks: Tricks of the Trade; Montavon, G., Orr, G.B., Müller, K.R., Eds.; (Lecture Notes in Computer Science); Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700, pp. 599–619. [Google Scholar]
- Jampani, V. Learning Inference Models for Computer Vision. arXiv, 2017; arXiv:1709.00069v1. [Google Scholar]
- Ong, E.J.; Cooper, H.; Pugeault, N.; Bowden, R. Sign Language Recognition using Sequential Pattern Trees. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Barczak, A.L.C.; Reyes, N.H.; Abastillas, M.; Piccio, A.; Susnjak, T. A New 2D Static Hand Gesture Colour Image Dataset for ASL Gestures. Res. Lett. Inf. Math. Sci. 2011, 15, 12–20. [Google Scholar]
- Pugeault, N.; Bowden, R. Spelling It Out: Real-Time ASL Fingerspelling Recognition. In Proceedings of the 1st IEEE Workshop on Consumer Depth Cameras for Computer Vision, jointly with ICCV, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-time continuous pose recovery of human hands using convolutional networks. ACM Trans. Graph. (ToG) 2014, 33. [Google Scholar] [CrossRef]
- Yuan, S.; Ye, Q.; Stenger, B.; Jain, S.; Kim, T.K. BigHand2.2M Benchmark: Hand Pose Dataset and State of the Art Analysis. arXiv, 2014; arXiv:1704.02612. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Theta for Learning | 0.005 | Crop numbers | 5 |
| Weight Decay | Batch-size | 128 | |
| Iteration | 100, 1000, 5000, 10,000 | Size of the input image | |
| Gaussian Noise Parameters | Mean: 0, Variance: 0.16 | Salt-and-pepper noise parameter | noise density: 0.13 |
| Dataset | Language | Class Numbers | Samples | Type |
|---|---|---|---|---|
| Massey | American | 36 | 2524 | Image (RGB) |
| ASL Fingerspelling A | American | 24 | 131,000 | Image (RGB, Depth) |
| NYU | American | 36 | 81,009 | Image (RGB, Depth) |
| ASL Fingerspelling Dataset of the Surrey University | American | 24 | 130,000 | Image (RGB, Depth) |
| Dataset | Recognition Accuracy |
|---|---|
| Massey University Gesture Dataset 2012 | 99.31 |
| ASL Fingerspelling Dataset of the Surrey University | 97.56 |
| NYU | 90.01 |
| ASL Fingerspelling A | 98.13 |
| Accuracy of Proposed Method | TS1 | TS2 | TS3 | TS4 |
|---|---|---|---|---|
| Massey University Gesture Dataset 2012 | 95.01 | 94.94 | 94.86 | 95.36 |
| ASL Fingerspelling Dataset of the Surrey University | 91.09 | 90.74 | 90.03 | 91.18 |
| NYU | 85.01 | 83.84 | 83.00 | 85.23 |
| ASL Fingerspelling A | 93.84 | 93.33 | 92.93 | 94.04 |
| Reference | Result | Dataset |
|---|---|---|
| [9] | 87.00 | |
| [10] | 74.00 | |
| [14] | 84.40 | NYU |
| [27] | 79.40 | |
| Ours | 90.01 | |
| [5] | 72.00 | Massey University |
| Ours | 99.31 | |
| [25] | 87.00 | ASL Fingerspelling A |
| Ours | 98.13 | |
| [9] | 69.00 | ASL Surrey |
| Ours | 97.56 |
| Top-1 Val Accuracy | Proposed Method | Garcia [5] |
|---|---|---|
| Alphabets [a–y] | 98.91 | 69.65 |
| Alphabets [a–k] | 99.03 | 74.30 |
| Alphabets [a–e] | 99.15 | 97.82 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rastgoo, R.; Kiani, K.; Escalera, S. Multi-Modal Deep Hand Sign Language Recognition in Still Images Using Restricted Boltzmann Machine. Entropy 2018, 20, 809. https://doi.org/10.3390/e20110809
Rastgoo R, Kiani K, Escalera S. Multi-Modal Deep Hand Sign Language Recognition in Still Images Using Restricted Boltzmann Machine. Entropy. 2018; 20(11):809. https://doi.org/10.3390/e20110809
Chicago/Turabian StyleRastgoo, Razieh, Kourosh Kiani, and Sergio Escalera. 2018. "Multi-Modal Deep Hand Sign Language Recognition in Still Images Using Restricted Boltzmann Machine" Entropy 20, no. 11: 809. https://doi.org/10.3390/e20110809
APA StyleRastgoo, R., Kiani, K., & Escalera, S. (2018). Multi-Modal Deep Hand Sign Language Recognition in Still Images Using Restricted Boltzmann Machine. Entropy, 20(11), 809. https://doi.org/10.3390/e20110809