Interpreting Social Accounting Matrix (SAM) as an Information Channel


Abstract
:1. Introduction
2. Information Measures and Information Channel
2.1. Basic Information-Theoretic Measures
2.2. Information Channel
- Input and output variables, X and Y, with probability distributions and , called marginal probabilities.
- Probability transition matrix (with elements conditional probabilities ) determining the output distribution given the input distribution : . Each row of , denoted by , is a probability distribution.
2.3. A Markov Chain as an Information Channel
2.3.1. Grouping Indexes
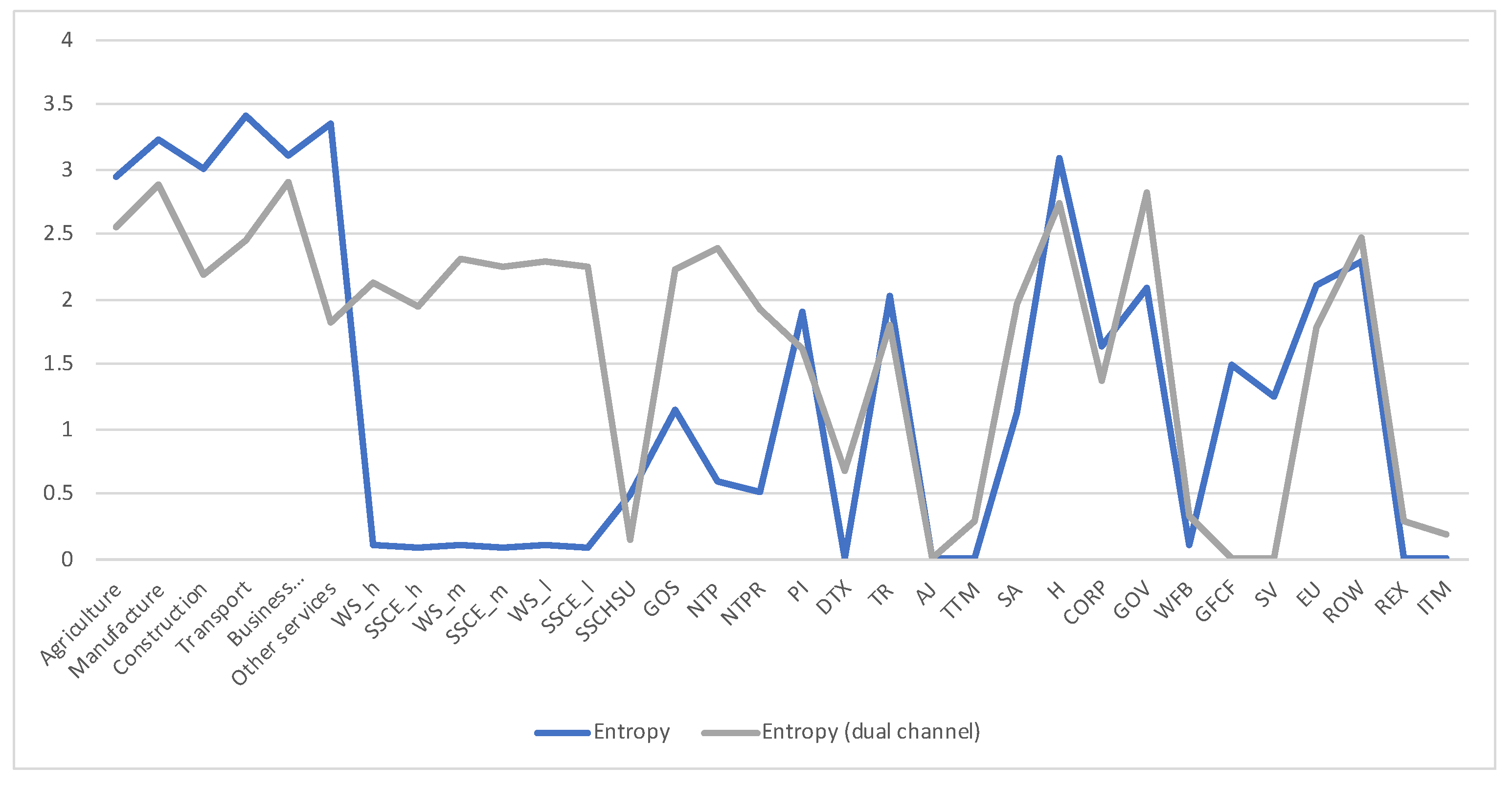
2.3.2. Dual Channel
3. SAM Matrix
3.1. SAM Coefficient Matrix as a Markov Chain
3.2. SAM Information Channel
- Being a Markov chain, input and output variables, in our case X and Y, which represent the economic actors, are equal, and thus probability distributions and are equal to the equilibrium distribution, the normalized y vector, .
- Probability transition matrix (composed of conditional probabilities . Each row of SAM matrix, , denoted by , is a probability distribution.
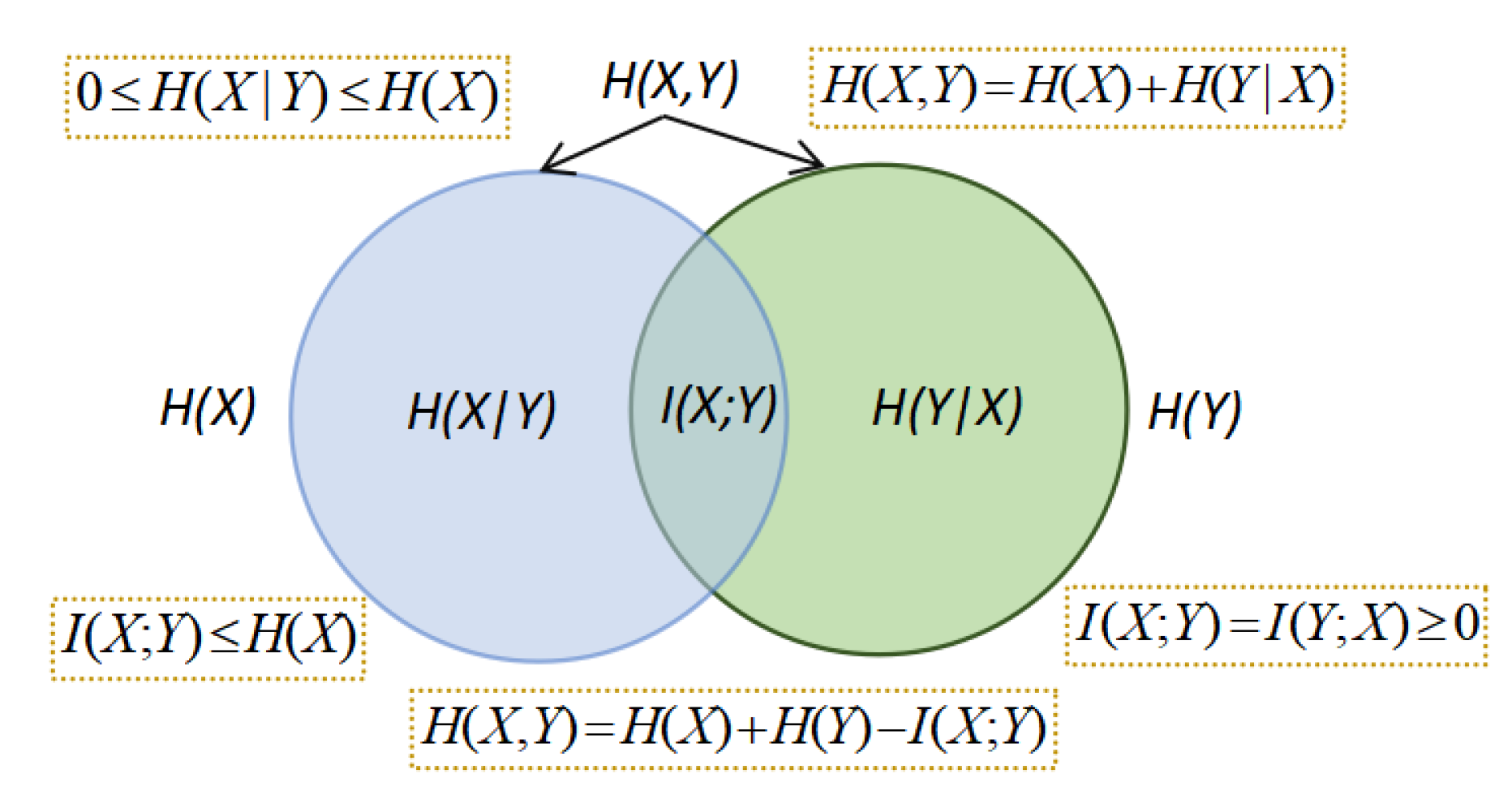
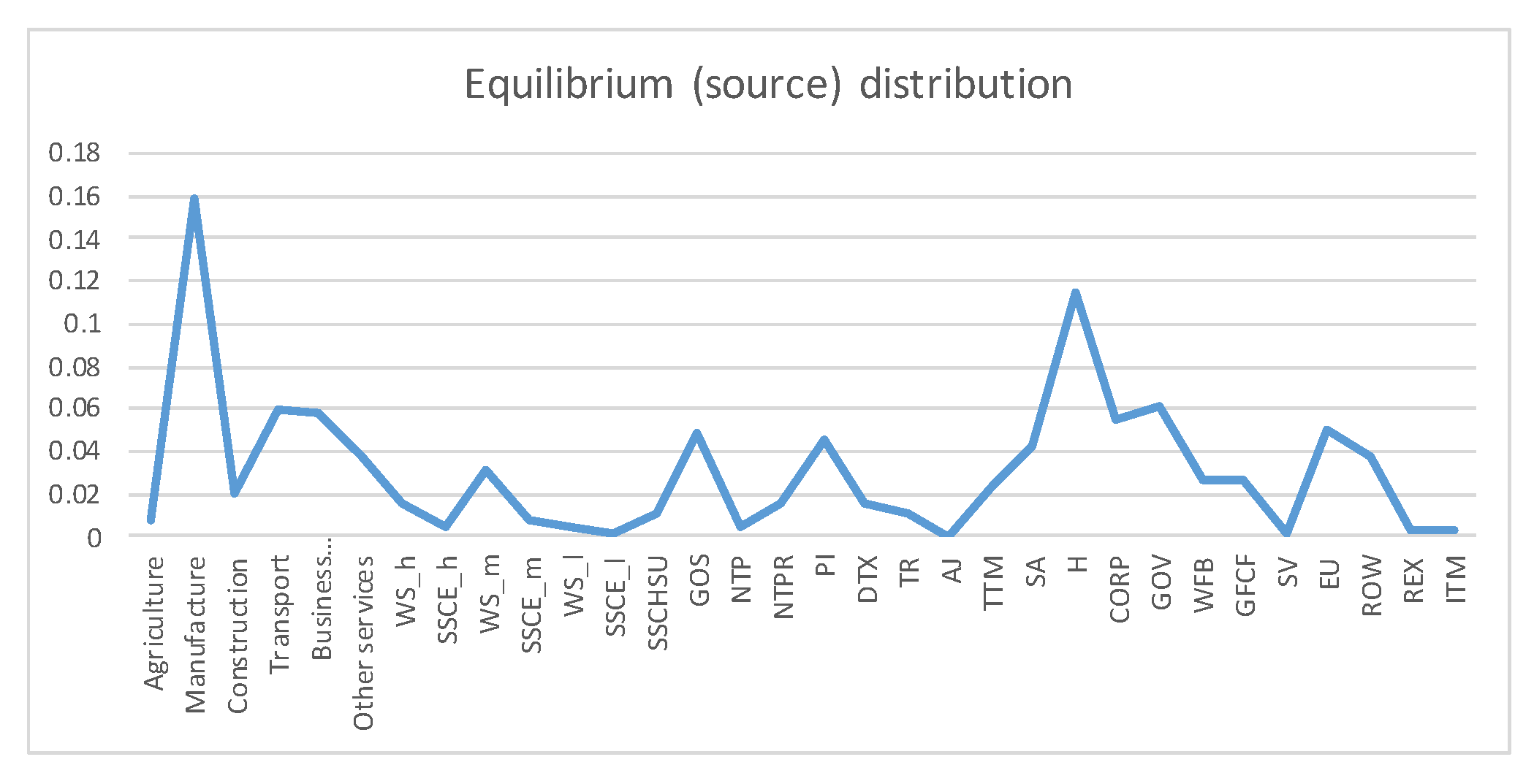
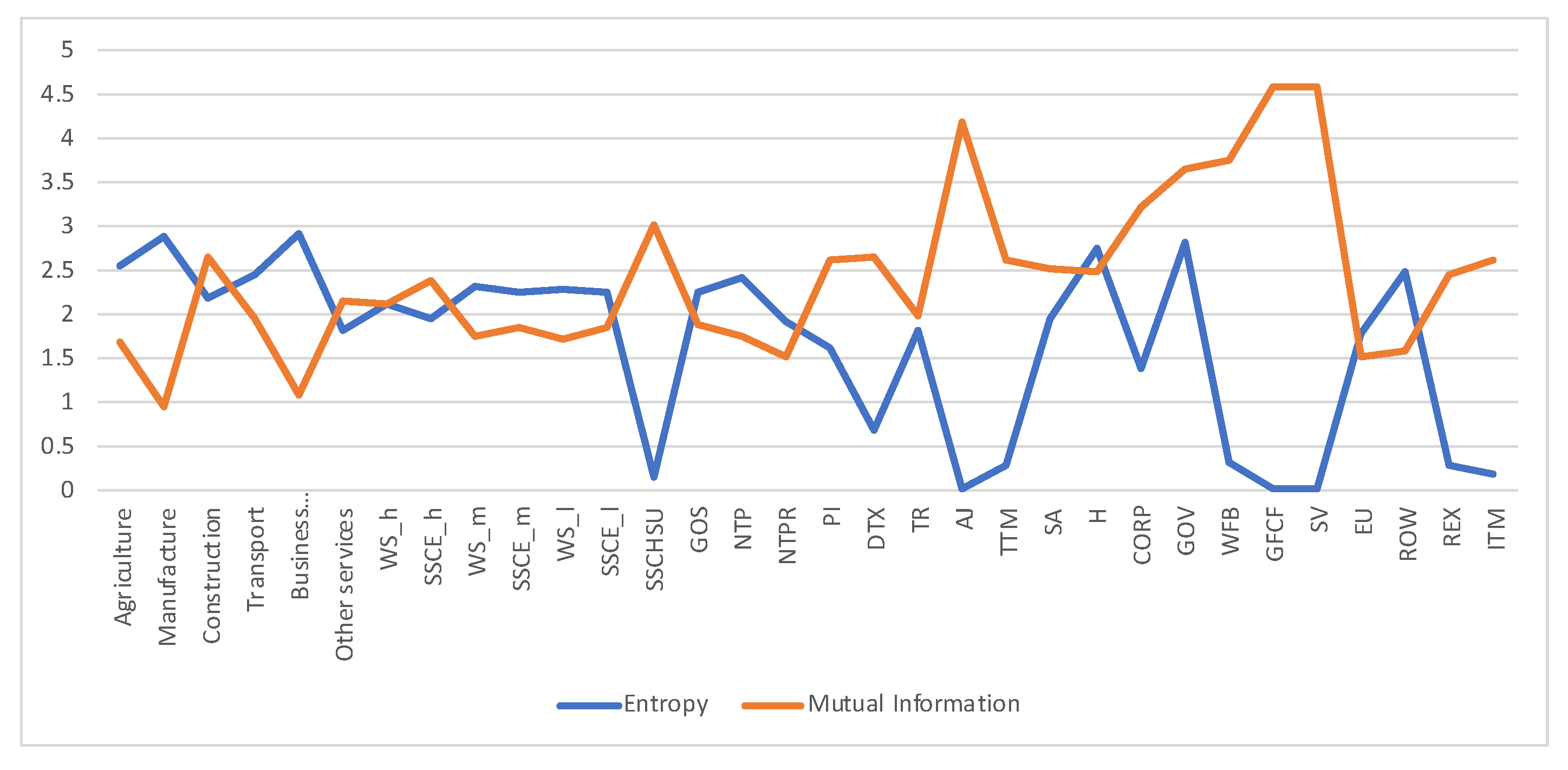
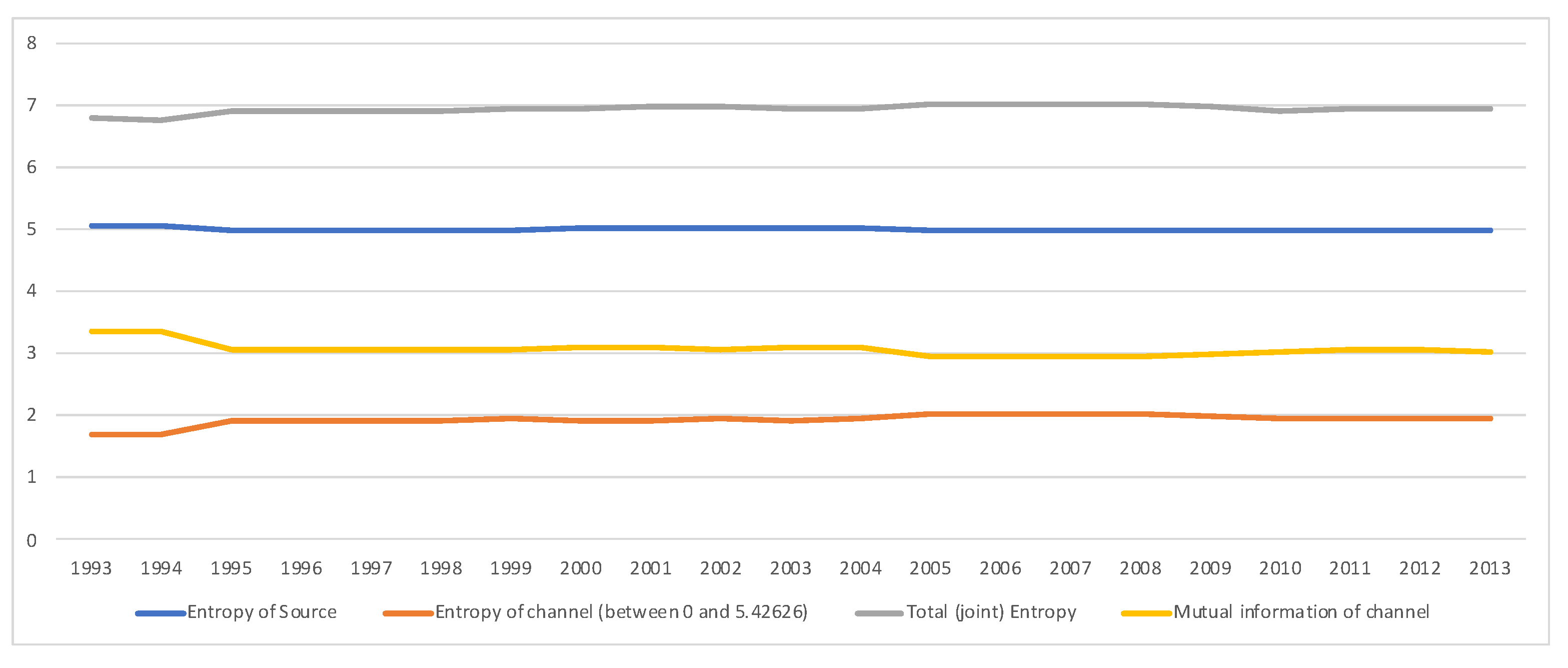
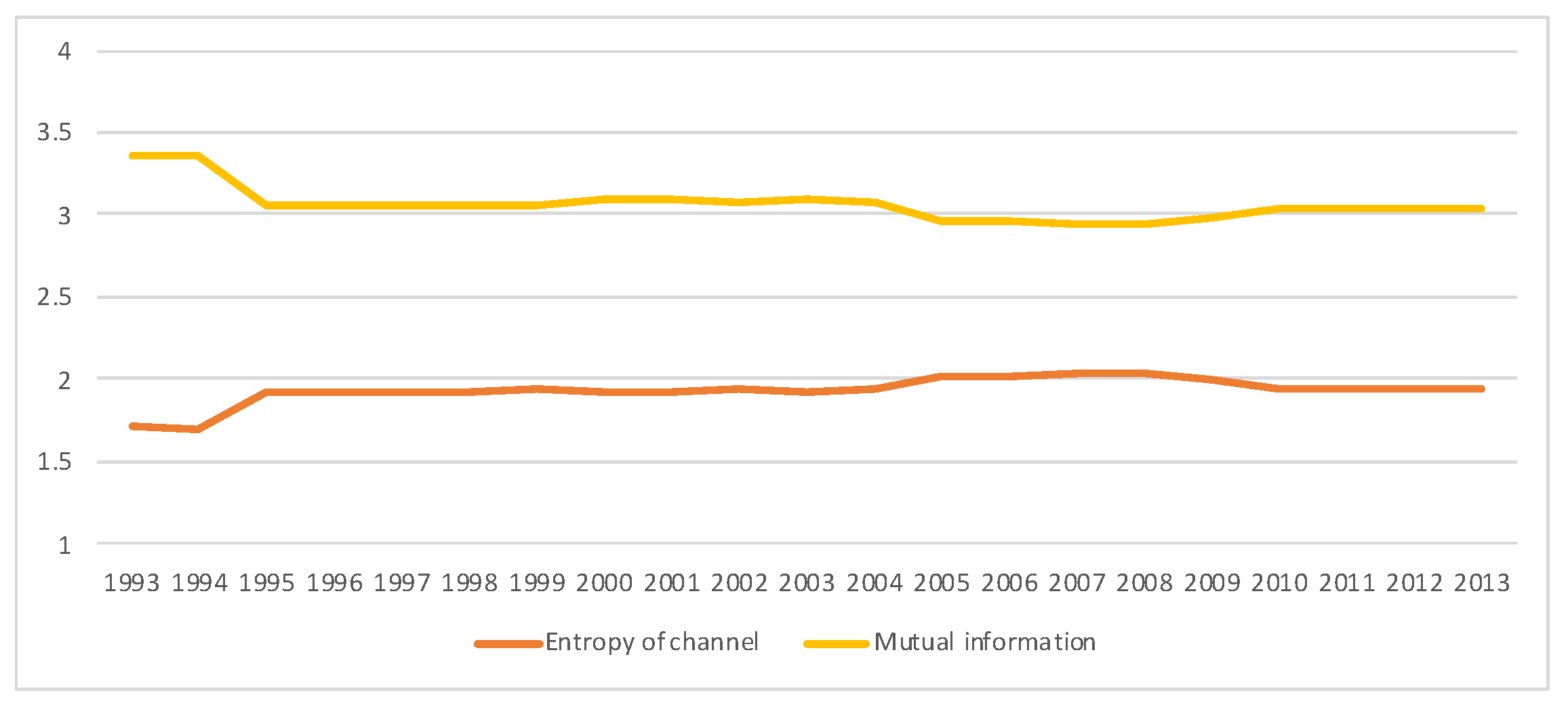
- Entropy of the source, . Entropy of equilibrium distribution measures average uncertainty (as an a priori measurement) of input random variable X, or alternatively information (as an a posteriori measurement) of output random variable Y, both with distribution . It measures how homogeneous is the importance between the different economic actors. The higher the entropy, the more equal are the actors. A low entropy means that some actors are more important. We can normalize it by the maximum entropy, , where M is the total number of economic actors.
- Entropy of row i, , represents the uncertainty about to which actor j will a unit payment from economic actor i go. It also measures the homogeneity of the payment flow. If payment from i is reduced to a single actor, the entropy of row i will be zero, if there is equal payment to all actors the entropy will be maximum. Golan and Vogel [25] consider this entropy, normalized by the maximum entropy , as the information of industry i.
- Conditional entropy (or entropy of the channel), . It measures the average uncertainty associated with a payment receptor if we know the emitter. Golan and Vogel [25] consider the non-weighted quantity , normalized by , as reflecting the information in the whole system (M industries).
- Mutual information of a row i, , represents the degree of correlation of economic actor i with the rest of the actors. Observe that it is the Kullback-Leibler distance from row i to output distribution . A low value of MI represents a behaviour of payments for actor i similar to the distribution , and that actor i behaviour represents the overall behaviour resumed in distribution . Alternatively, high values of represent a high deviation from . This happens for instance if is very homogeneous, but vector has a high inhomogeneity, preferring transitions to a small set of actors, or vice versa, when is very inhomogeneous and is very homogeneous, with similar behaviour with respect to all economic actors.
- Mutual information, , represents the total correlation, or the shared information, between economic actors, considered to be buyers and providers. We have that . It is the weighted average of the Kullback-Leibler distances from all rows to input distribution , where the weight for row i is given by .
- Cross entropy of row i, , where is the i row vector of . Please note that . Effectively, . As represents the average uncertainty or information of input and output variables both with distribution , cross entropy gives the uncertainty/information associated with actor i once we know the channel, which without any knowledge about the channel had been assigned as .
- Joint entropy, , represents the total uncertainty of the channel. It is the entropy of the joint distribution .
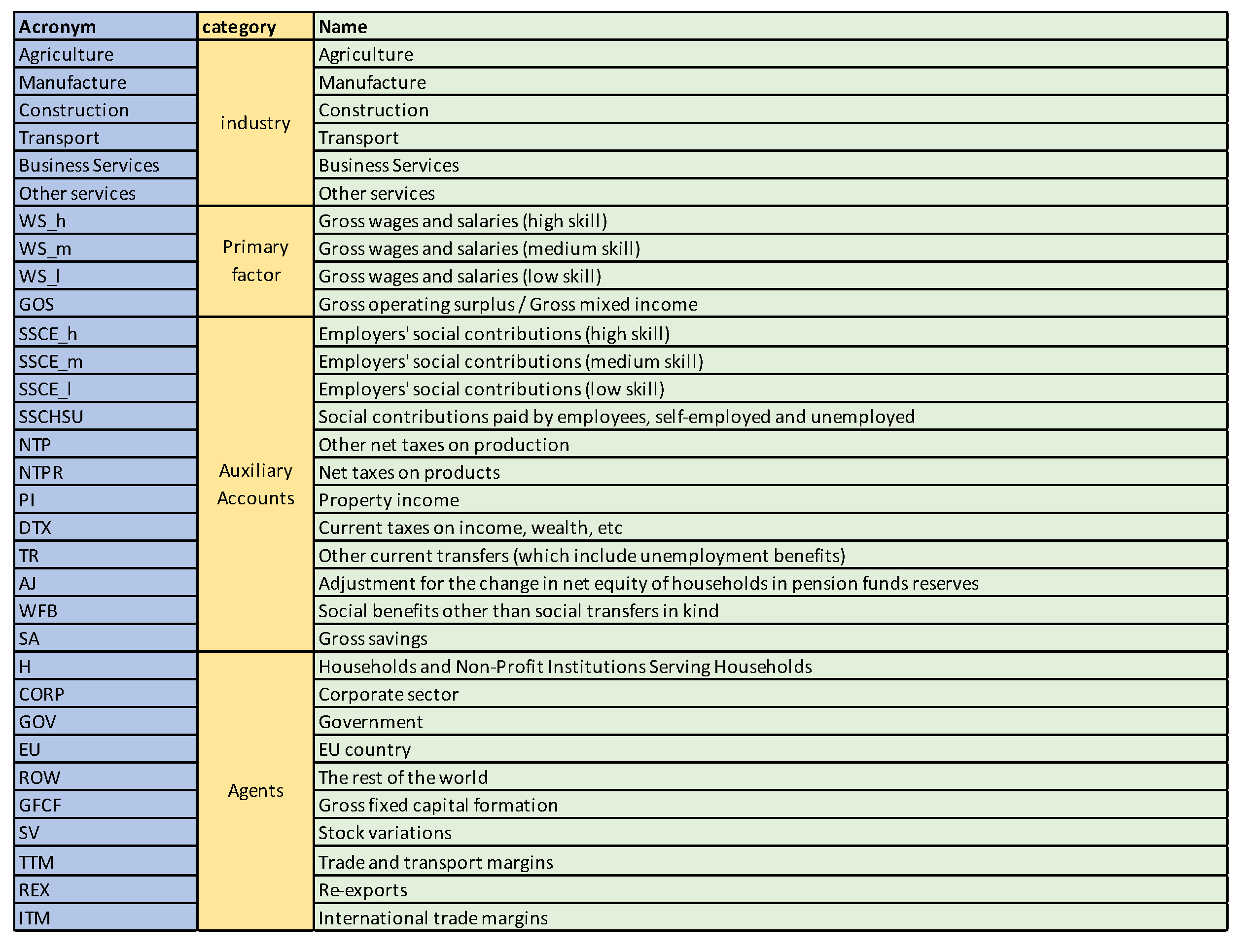
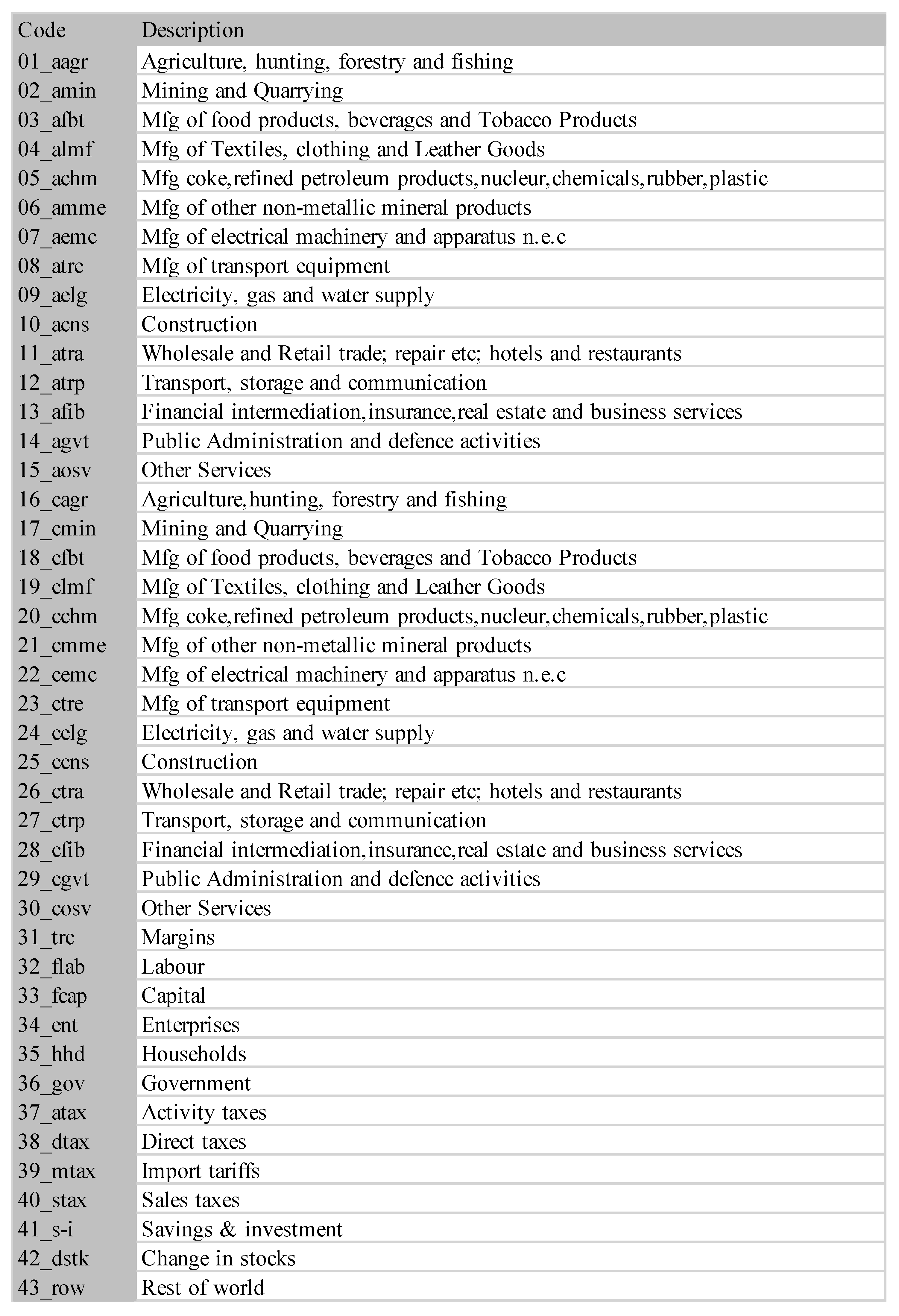
3.2.1. Grouping Sectors
4. Cross Entropy Method
5. Examples
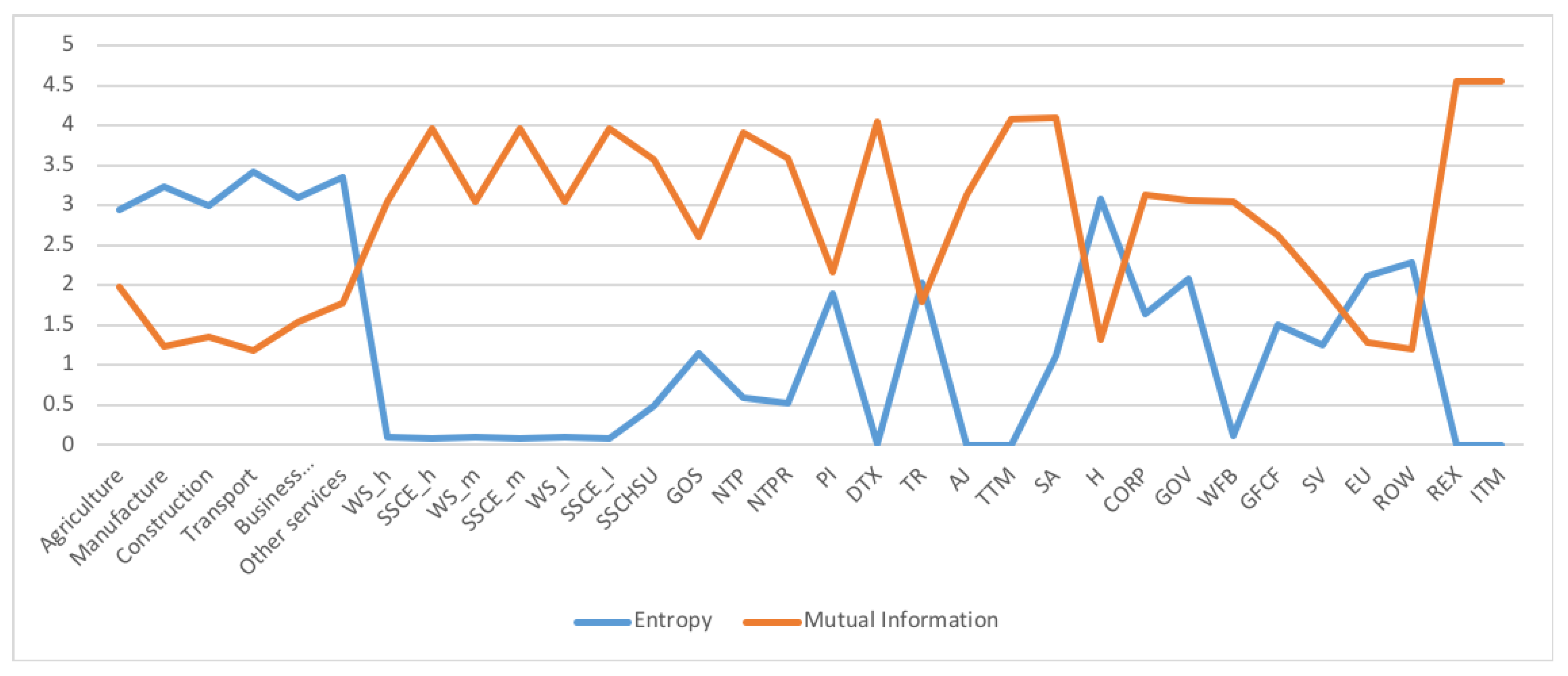
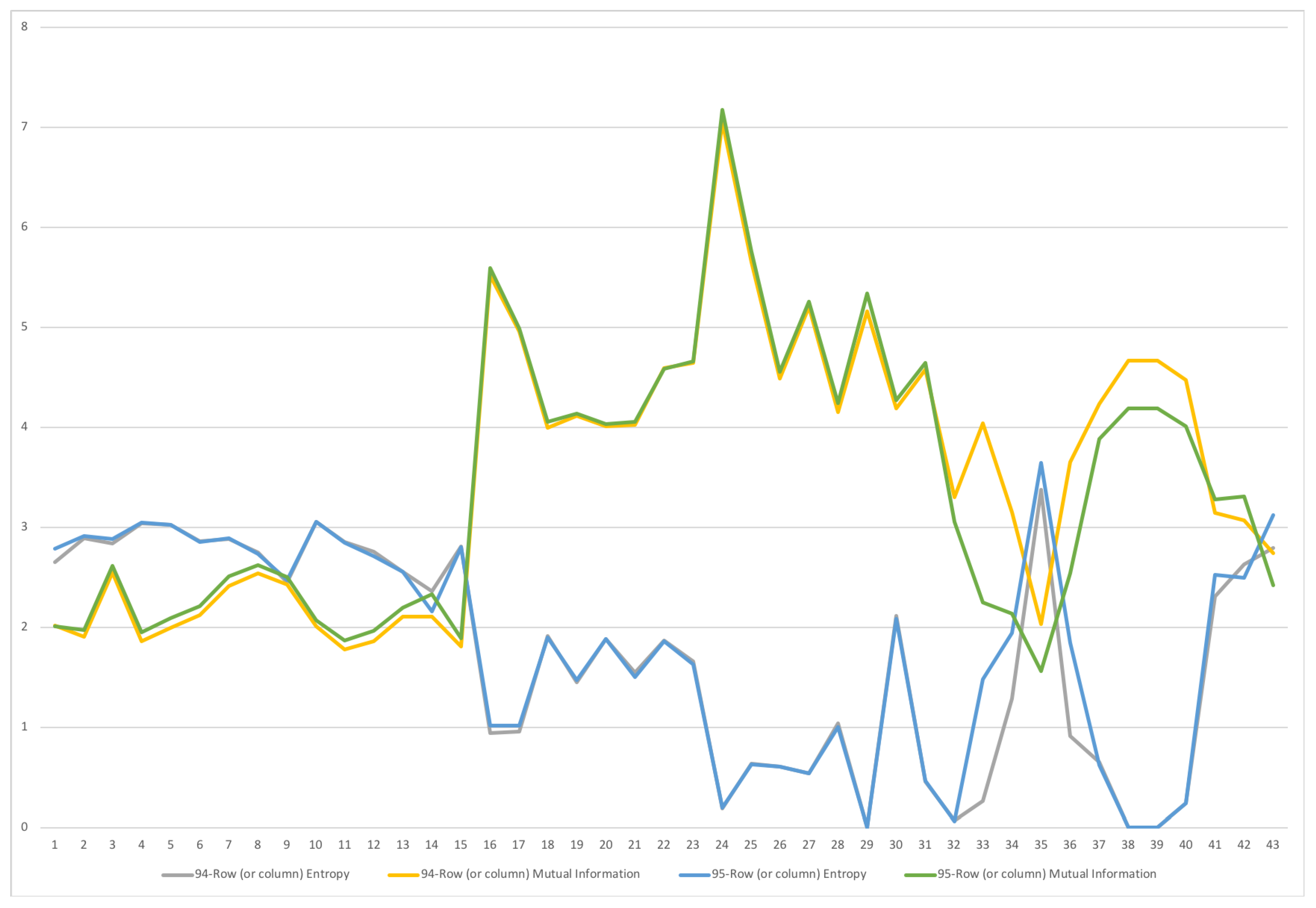
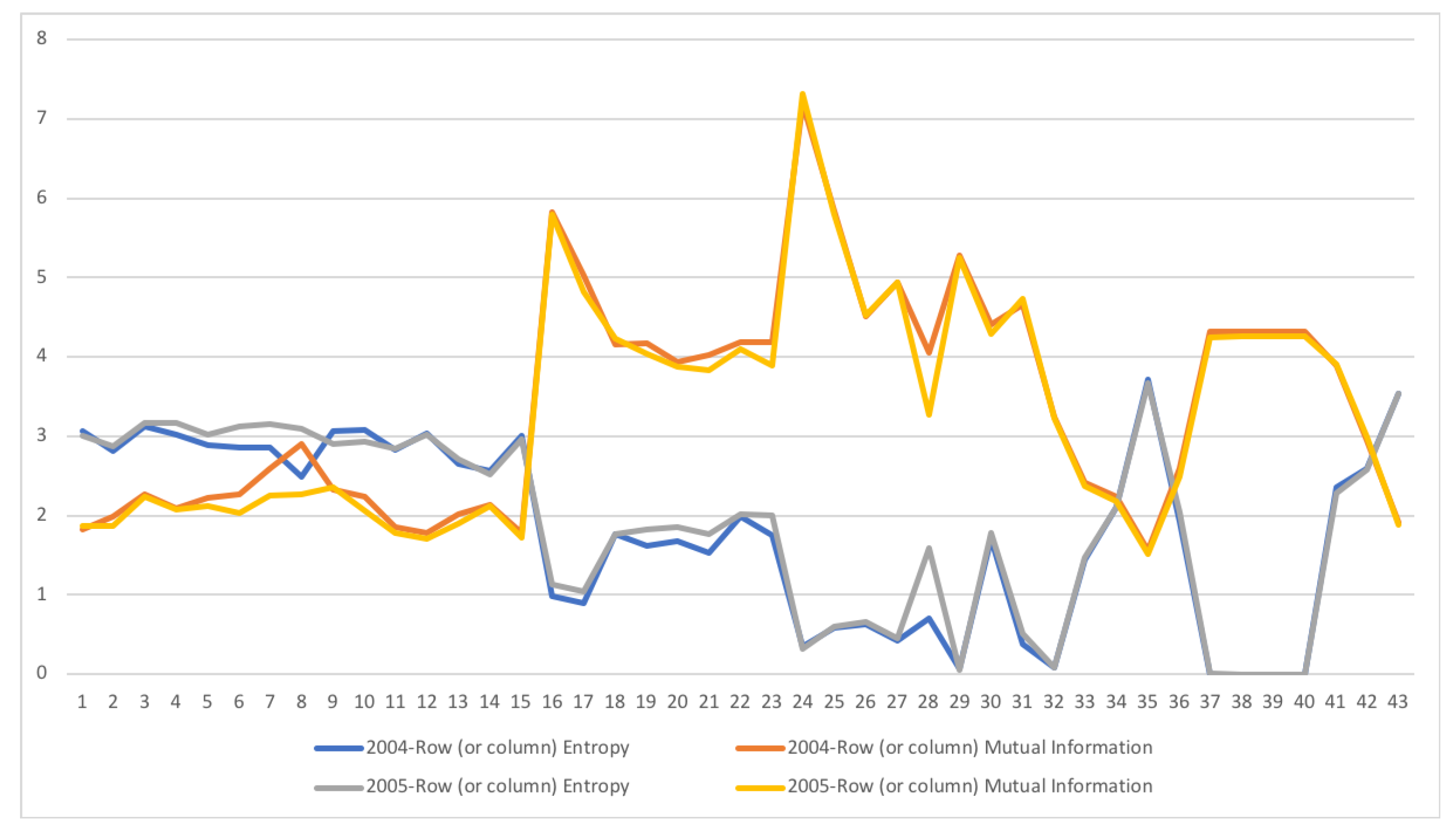
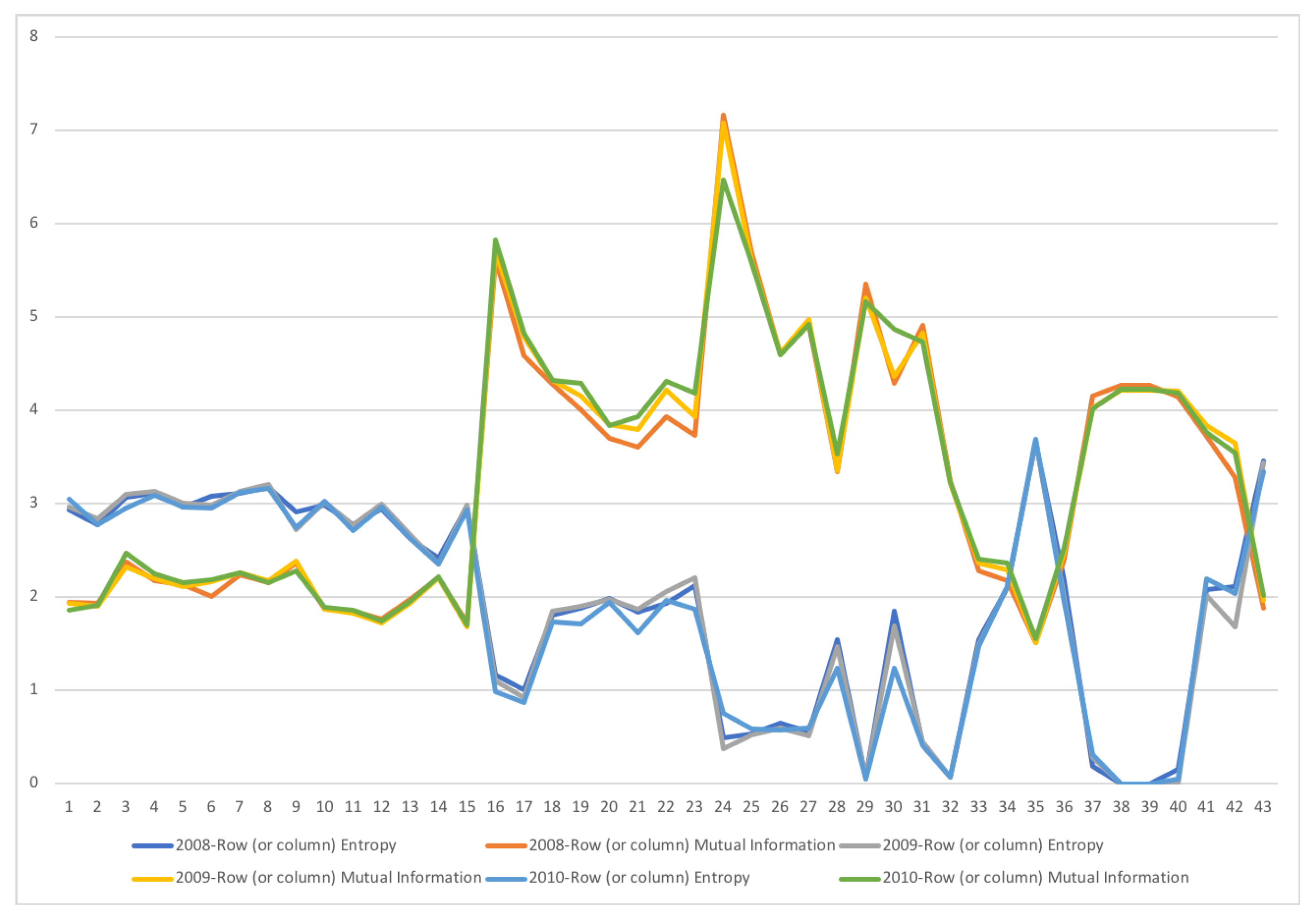
5.1. Austria SAM 2010 Matrix
5.2. Dual channel for Austria SAM 2010
5.2.1. Examining the Role of the Data Processing Inequality in Grouping
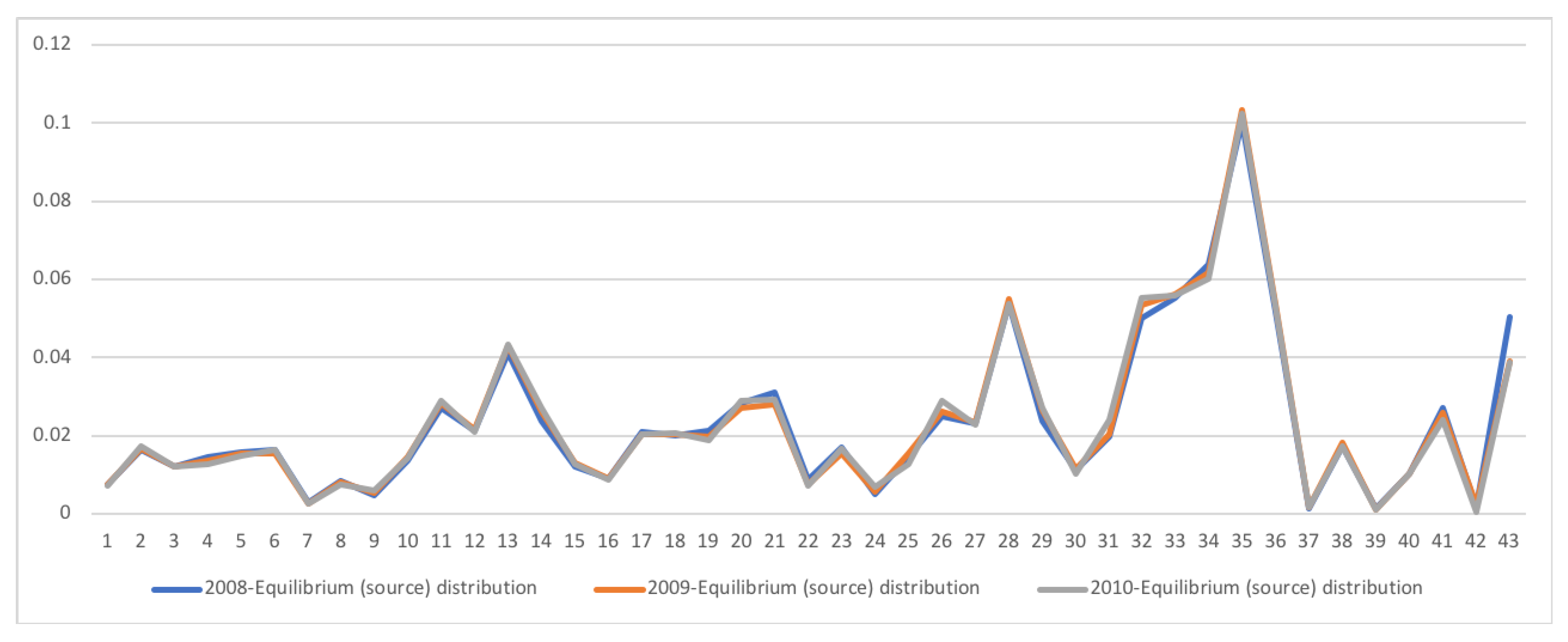
5.3. South Africa SAM Time Series Matrixes 1993–2013
Grouping Sectors
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. A SAM Toy Example
Appendix A.1. Ergodic Markov Chain
Appendix A.2. Information Channel

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entropy of source H(X)=H(Y) | 1.53049 |
| Entropy of channel H(Y|X)=H(X|Y) | 1.19499 |
| Joint entropy H(X,Y) | 2.72548 |
| Mutual information I(X;Y) | 0.3355 |
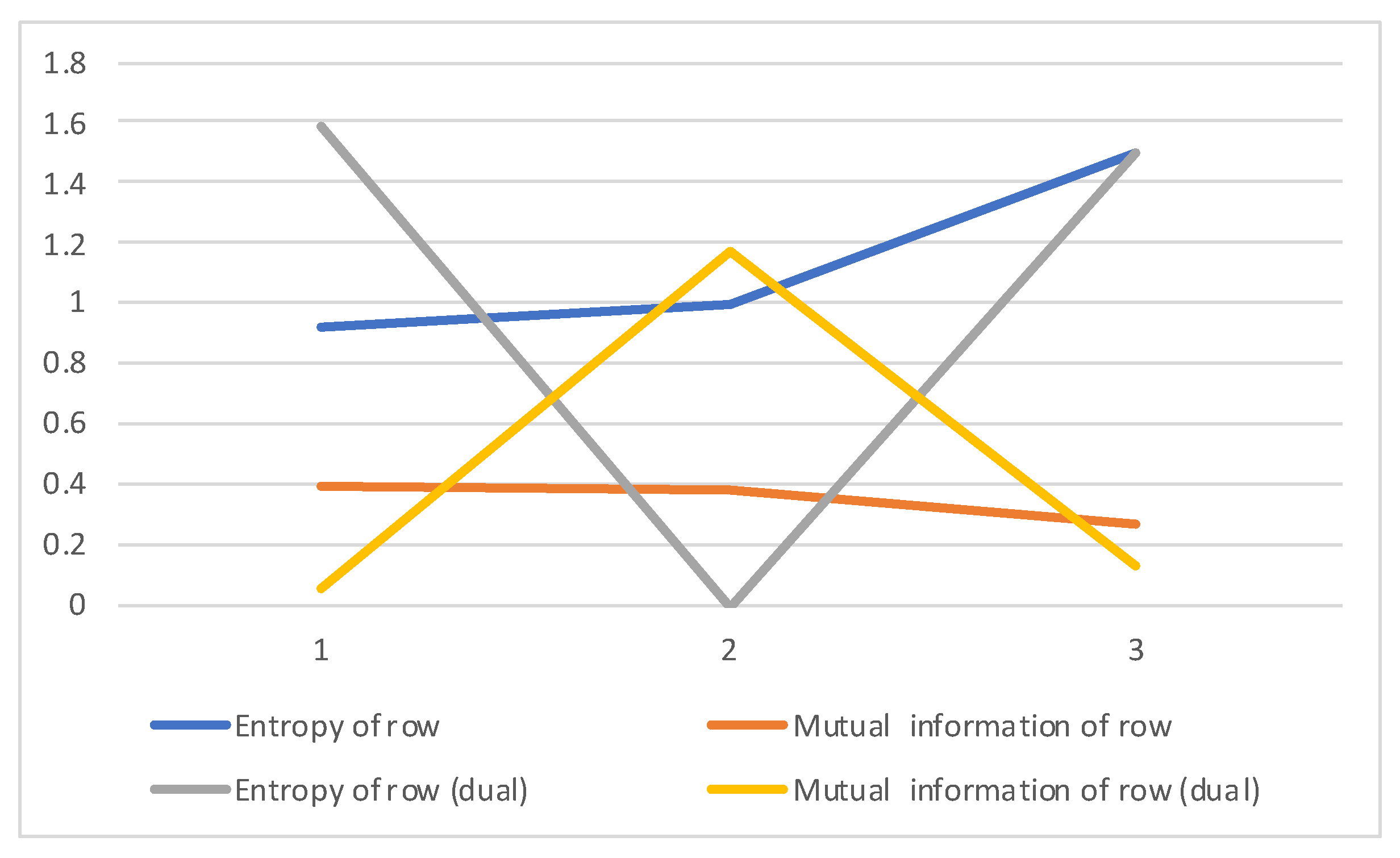
| Row | 1 | 2 | 3 |
|---|---|---|---|
| Entropy of row | 0.918296 | 1 | 1.5 |
| Mutual information of row | 0.38997 | 0.37744 | 0.27368 |
| Entropy of row (dual) | 1.58496 | 0 | 1.5 |
| Mutual information of row (dual) | 0.05664 | 1.16993 | 0.12744 |

References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef] [Green Version]
- Dervis, K.; Melo, J.D.; Robinson, S. General Equilibrium Models for Development Policy; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar]
- Mainar-Causapé, A.; Ferrari, E.; McDonald, S. Social Accounting Matrices: Basic Aspects and Main Steps for Estimation; JRC Technical Reports; Publications Office of the European Union: Luxembourg, 2018. [Google Scholar]
- Ferrari, G.; Mondejar Jimenez, J.; Secondi, L. Tourists’ Expenditure in Tuscany and its impact on the regional economic system. J. Clean. Prod. 2018, 171, 1437–1446. [Google Scholar] [CrossRef]
- Li, Y.; Su, B.; Dasgupta, S. Structural path analysis of India’s carbon emissions using input-output and social accounting matrix frameworks. Energy Econ. 2018, 76, 457–469. [Google Scholar] [CrossRef]
- Fuentes-Saguar, P.D.; Mainar-Causapé, A.J.; Ferrari, E. The role of bioeconomy sectors and natural resources in EU economies: A social accounting matrix-based analysis approach. Sustainability 2017, 9, 2383. [Google Scholar] [CrossRef] [Green Version]
- Hawkins, J.; Hunt, J.D. Development of environmentally extended social accounting matrices for policy analysis in Alberta. Econ. Syst. Res. 2019, 31, 114–131. [Google Scholar] [CrossRef]
- Cardenete Flores, M.A.; López Álvarez, J.M. Key Sectors Analysis by Social Accounting Matrices: The Case of Andalusia. Stud. Appl. Econ. 2015, 33, 203–222. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley Series in Telecommunications; Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Yeung, R.W. Information Theory and Network Coding; Springer: New York, NY, USA, 2008. [Google Scholar]
- Golan, A. Foundations of Info-Metrics: Modeling, Inference, and Imperfect Information; Oxford University Press: New York, NY, USA, 2018. [Google Scholar]
- Hartley, R.V.L. Transmission of Information. Bell Syst. Tech. J. 1928, 7, 535–563. [Google Scholar] [CrossRef]
- Skórski, M. Shannon Entropy Versus Renyi Entropy from a Cryptographic Viewpoint. In Cryptography and Coding. IMACC 2015; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Wikipedia Contributors. Diversity Index—Wikipedia, The Free Encyclopedia. 2020. Available online: https://en.wikipedia.org/wiki/Diversity_index (accessed on 17 November 2020).
- Taneja, I.J. Generalized Information Measures and Their Applications; Departamento de Matemática, Universidade Federal de Santa Catarina: Florianópolis, Brazil, 2001. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The Information Bottleneck Method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September1999; pp. 368–377. [Google Scholar]
- Feixas, M.; Sbert, M. The role of information channel in visual computing. In Advances in Infometrics; Chen, M., Michael Dunn, J., Golan, A., Ullah, A., Eds.; Oxford University Press: New York, NY, USA, 2021. [Google Scholar]
- Maes, F.; Collignon, A.; Vandermeulen, D.; Marchal, G.; Suetens, P. Multimodality Image Registration by Maximization of Mutual Information. IEEE Trans. Med Imaging 1997, 16, 187–198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Viola, P.A. Alignment by Maximization of Mutual Information. Ph.D. Thesis, MIT Artificial Intelligence Laboratory (TR 1548), Cambridge, MA, USA, 1995. [Google Scholar]
- Borst, A.; Theunissen, F.E. Information Theory and Neural Coding. Nat. Neurosci. 1999, 2, 947–957. [Google Scholar] [CrossRef] [PubMed]
- Deweese, M.R.; Meister, M. How to measure the information gained from one symbol. Netw. Comput. Neural Syst. 1999, 10, 325–340. [Google Scholar] [CrossRef]
- Coleman, R. Stochastic Processes; George Allen & Unwin Ltd.: London, UK, 1974. [Google Scholar]
- Babai, L. FiniteMarkov Chains. 2005. Available online: https://www.classes.cs.uchicago.edu/archive/2005/fall/27100-1/Markov.pdf (accessed on 26 September 2020).
- Klappenecker, A. Markov Chains. 2018. Available online: https://people.engr.tamu.edu/andreas-klappenecker/csce658-s18/markov_chains.pdf (accessed on 4 October 2020).
- Golan, A.; Vogel, S.J. Estimation of Non-Stationary Social Accounting Matrix Coefficients with Supply-Side Information. Econ. Syst. Res. 2000, 12, 447–471. [Google Scholar] [CrossRef]
- Golan, A.; Judge, G.; Robinson, S. Recovering Information from Incomplete or Partial Multisectoral Economic Data. Rev. Econ. Stat. 1994, 76, 541–549. [Google Scholar] [CrossRef]
- Robinson, S.; Cattaneo, A.; El-Said, M. Updating and Estimating a Social Accounting Matrix Using Cross Entropy Methods. Econ. Syst. Res. 2010, 13, 47–64. [Google Scholar] [CrossRef]
- McDougall, R. Entropy Theory and RAS are Friends; GTAP Working Papers; Purdue University: West Lafayette, IN, USA, 1999. [Google Scholar]
- Alvarez-Martinez, M.T.; Lopez-Cobo, M. Social Accounting Matrices for the EU-27 in 2010; JRC Technical Reports; Publications Office of the European Union: Luxembourg, 2016. [Google Scholar]
- Gell-Mann, M. The Quark and the Jaguar: Adventures in the Simple and the Complex; W.H. Freeman: New York, NY, USA, 1994. [Google Scholar]
- Slonim, N.; Tishby, N. Agglomerative Information Bottleneck. In Proceedings of the NIPS-12 (Neural Information Processing Systems), Denver, CO, USA, 29 November–4 November 1999; MIT Press: Cambridge, MA, USA, 2000; pp. 617–623. [Google Scholar]
- Van Seventer, D. Compilation of Annual Mini SAMs for South Africa 1993–2013 in Current and Constant Prices; Technical Report; UNU-WIDER: Helsinki, Finland, 2015. [Google Scholar]
- Rényi, A. On Measures of Entropy and Information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability’ 60, Berkeley, CA, USA, 20 June–30 July 1960; University of California Press: Berkeley, CA, USA, 1961; Volume 1, pp. 547–561. [Google Scholar]
- Egle, K.; Fenyi, S. Stochastic Solution of Closed Leontief Input-Output Models. In Operations Research ’93; Bachem, A., Derigs, U., Jünger, M., Schrader, R., Eds.; Physica: Heidelberg, Germany, 1994. [Google Scholar]
- Kostoska, O.; Stojkoski, V.; Kocarev, L. On the Structure of the World Economy: An Absorbing Markov Chain Approach. Entropy 2020, 22, 482. [Google Scholar] [CrossRef] [Green Version]


















| Grouped Sectors (Wages and Social Contributions) | No Grouping | High + Medium | Medium + Low | High + Medium + Low |
|---|---|---|---|---|
| Entropy of source H(X) | 4.29052 | 4.23750 | 4.26602 | 4.20983 |
| Conditional entropy H(X|Y) | 2.13603 | 2.08578 | 2.11160 | 2.05848 |
| Total (Joint) entropy H(X,Y) | 6.42656 | 6.32328 | 6.37762 | 6.26831 |
| Mutual information I(X;Y) | 2.15449 | 2.15171 | 2.15442 | 2.15135 |
| Grouped Sectors | No Grouping | 1-3, 16-18 | 2-5,17-20 | 2-9, 17-24 | 5-9, 20-24 | 2-5-9, 17-20-24 | 1-3, 2-5-9, 16-18, 17-20-24 |
|---|---|---|---|---|---|---|---|
| Entropy of source | 4.98261 | 4.94231 | 4.90204 | 4.93709 | 4.93629 | 4.84288 | 4.80258 |
| Entropy of channel | 1.9502 | 1.9343 | 1.93281 | 1.94083 | 1.93744 | 1.90876 | 1.89281 |
| Total (Joint) entropy | 6.93282 | 6.87661 | 6.83484 | 6.87792 | 6.87373 | 6.75165 | 6.69539 |
| Mutual information | 3.03241 | 3.00801 | 2.96923 | 2.99626 | 2.99885 | 2.93412 | 2.90977 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sbert, M.; Chen, S.; Feixas, M.; Vila, M.; Golan, A. Interpreting Social Accounting Matrix (SAM) as an Information Channel. Entropy 2020, 22, 1346. https://doi.org/10.3390/e22121346
Sbert M, Chen S, Feixas M, Vila M, Golan A. Interpreting Social Accounting Matrix (SAM) as an Information Channel. Entropy. 2020; 22(12):1346. https://doi.org/10.3390/e22121346
Chicago/Turabian StyleSbert, Mateu, Shuning Chen, Miquel Feixas, Marius Vila, and Amos Golan. 2020. "Interpreting Social Accounting Matrix (SAM) as an Information Channel" Entropy 22, no. 12: 1346. https://doi.org/10.3390/e22121346
APA StyleSbert, M., Chen, S., Feixas, M., Vila, M., & Golan, A. (2020). Interpreting Social Accounting Matrix (SAM) as an Information Channel. Entropy, 22(12), 1346. https://doi.org/10.3390/e22121346