
List Decoding of Arıkan’s PAC Codes †


Abstract
:1. Introduction
1.1. Brief Overview of PAC Codes
1.2. Our Contributions
1.3. Related Work
1.4. Paper Outline
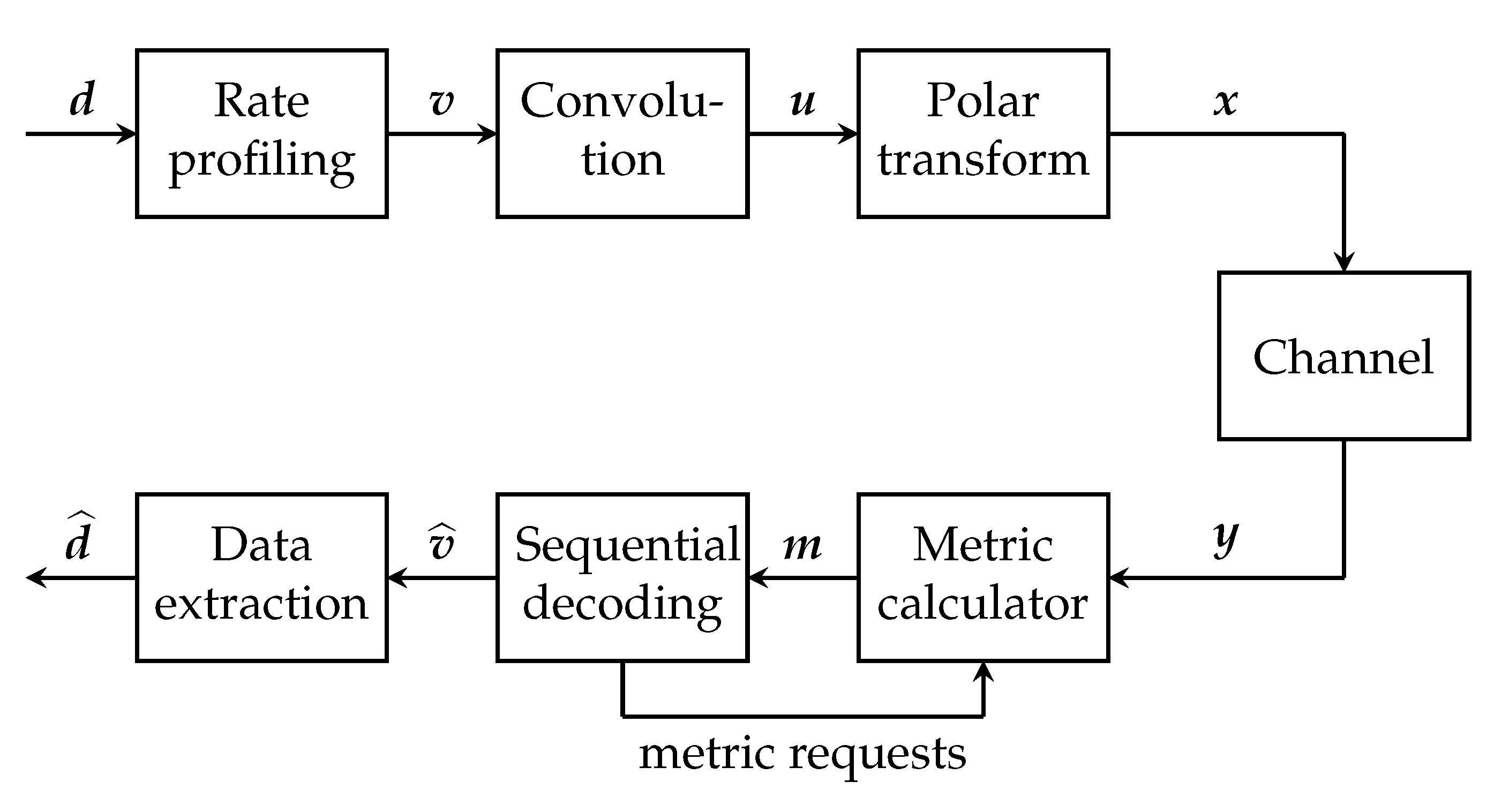
2. Overview of Arıkan’s PAC Codes
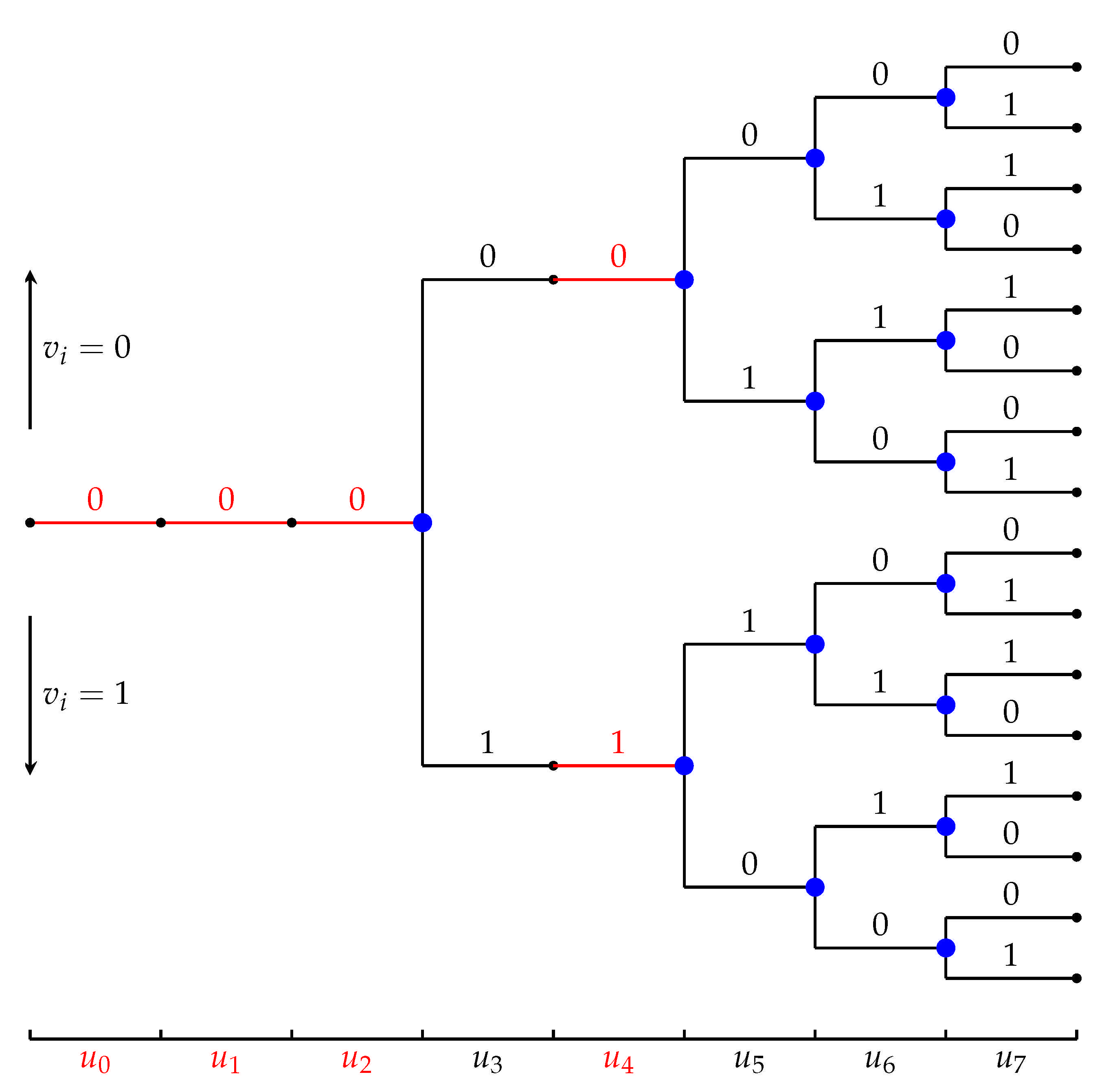
3. List Decoding of PAC Codes
3.1. PAC Codes as Polar Codes with Dynamically Frozen Bits
| Algorithm 1: List Decoder for PAC Codes |
 |
3.2. List Decoding of PAC Codes
| Algorithm 2: continuePaths_Unfzn (PAC version) |
 |
4. List Decoding versus Sequential Decoding
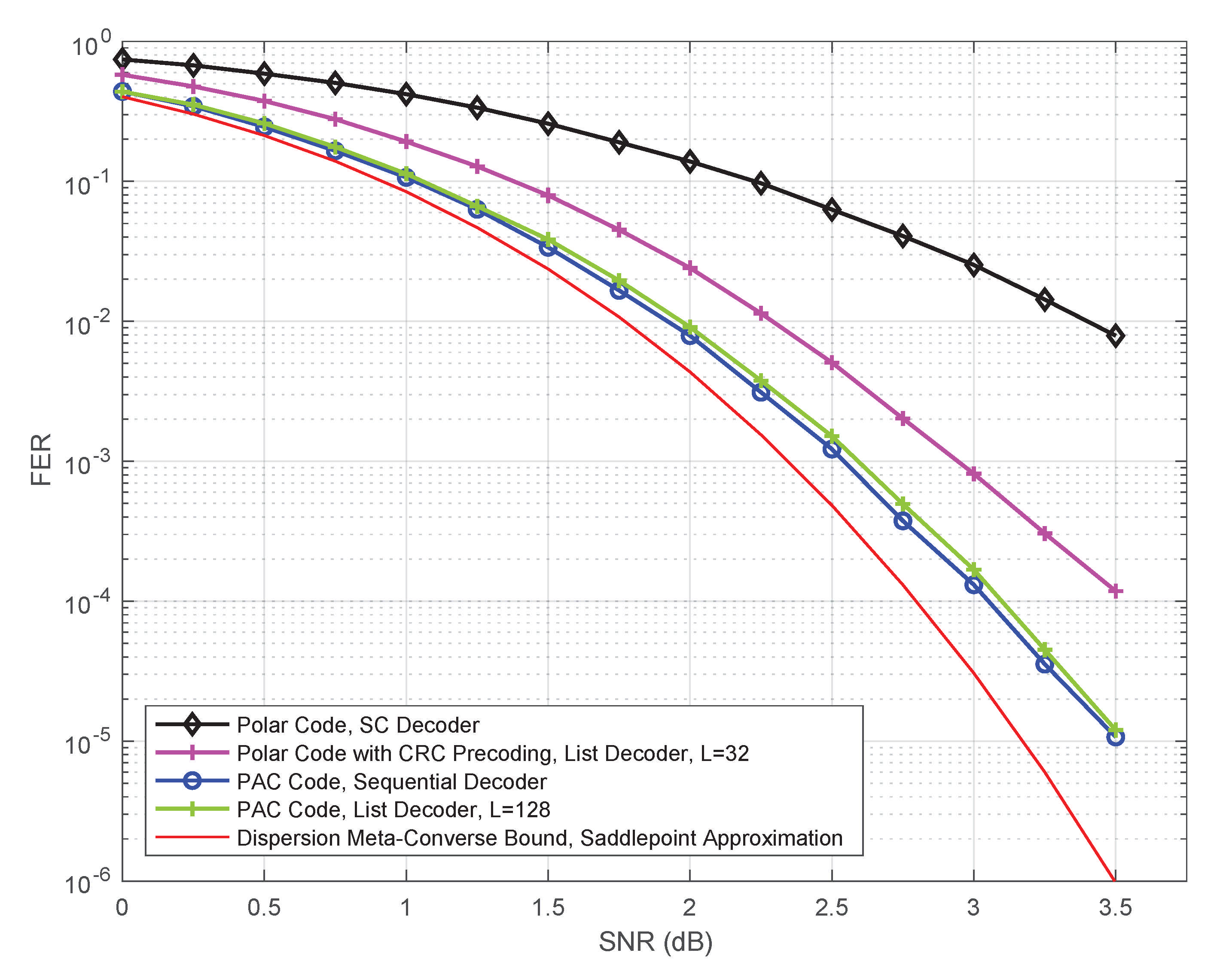
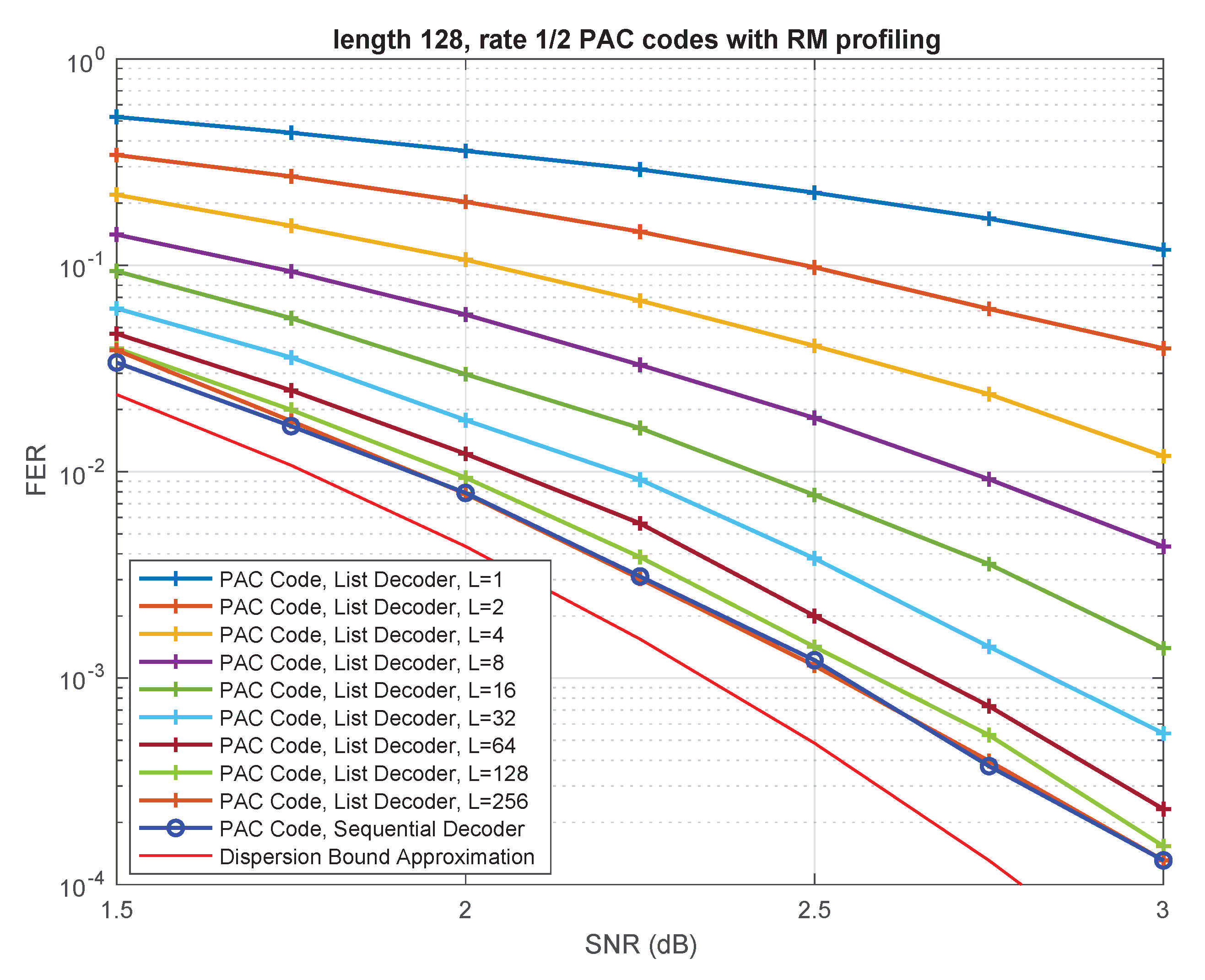
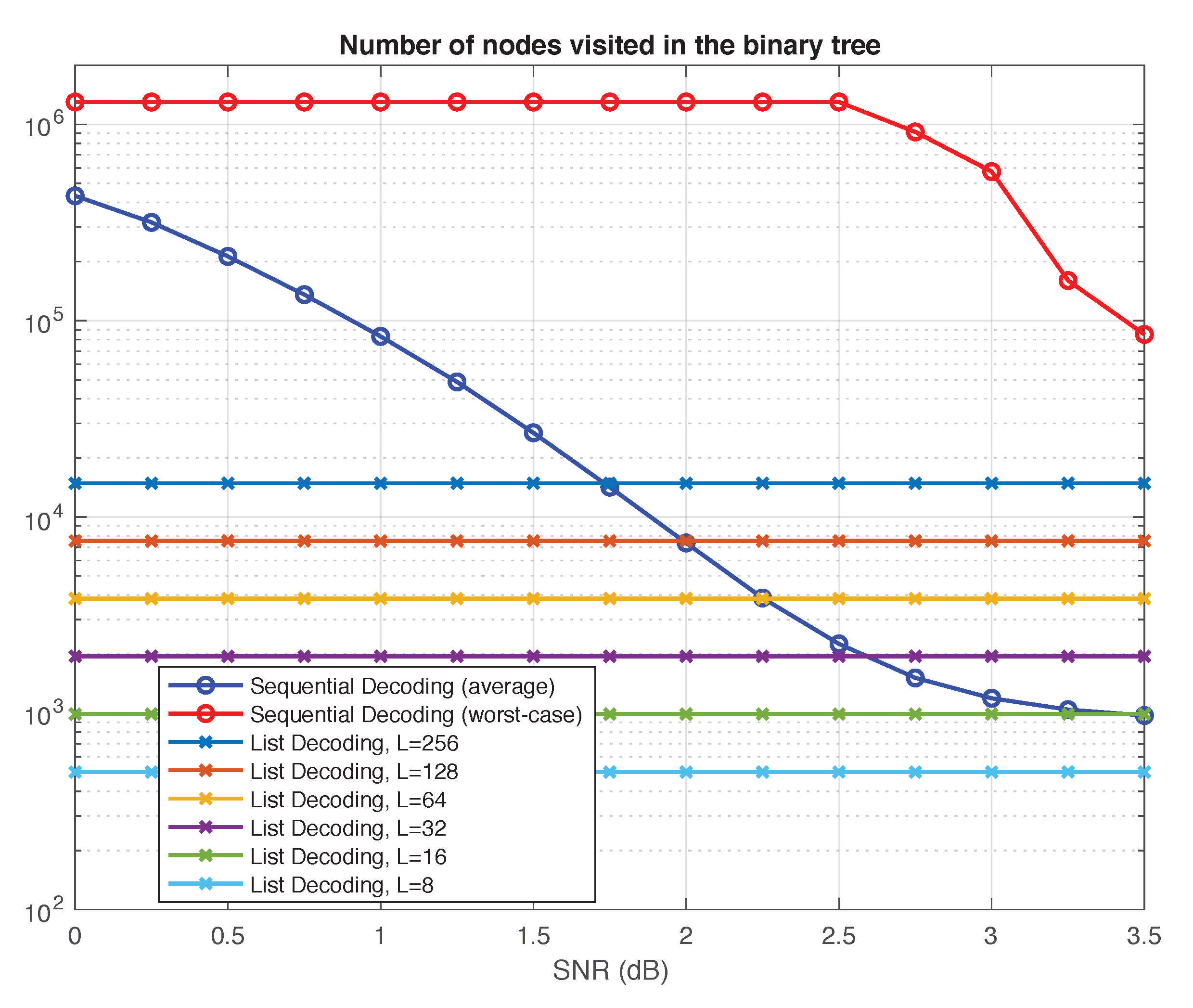
4.1. Performance Comparison
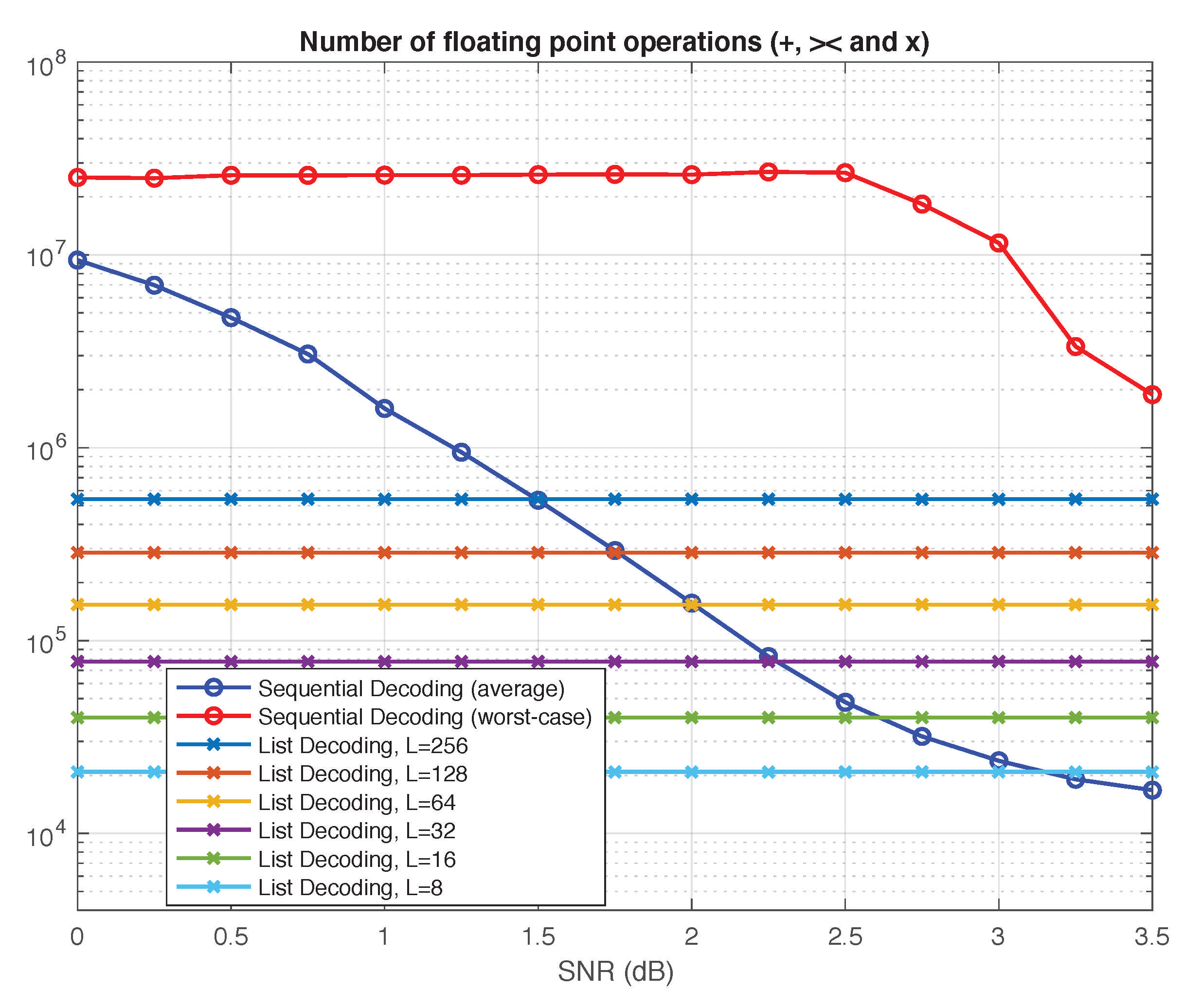
4.2. Complexity Comparison
5. Performance Analysis for PAC Codes
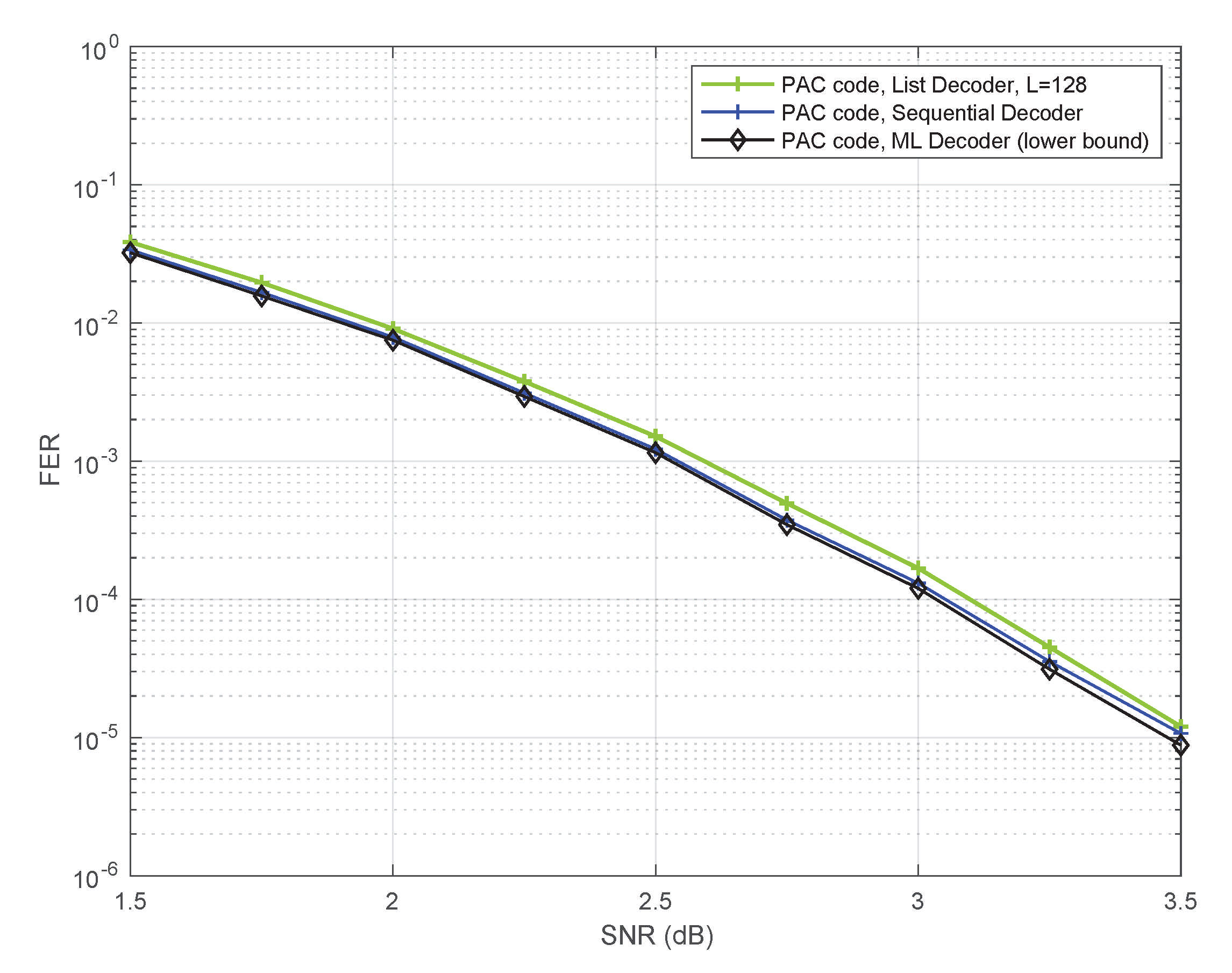
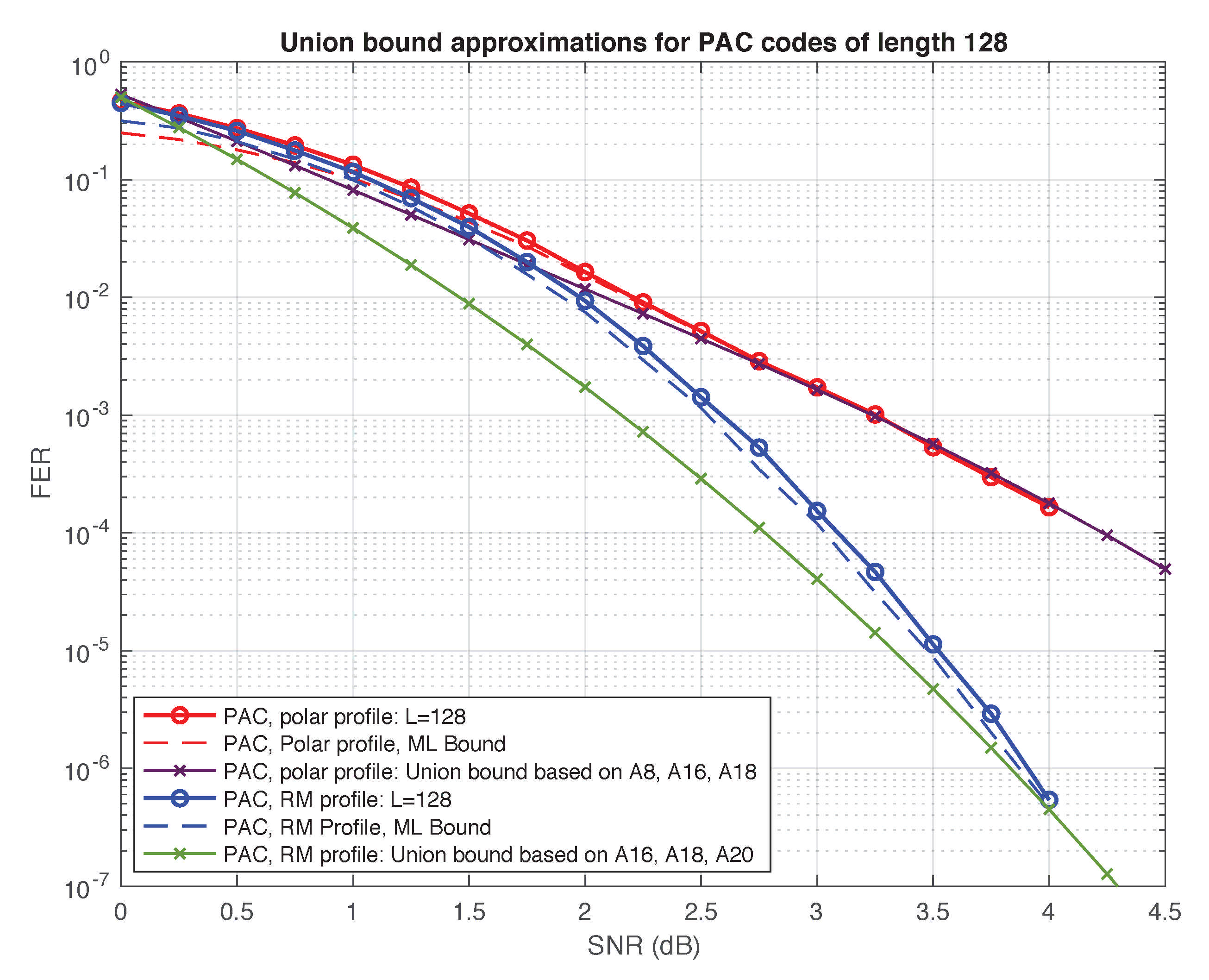
5.1. Sequential Decoding versus ML Decoding
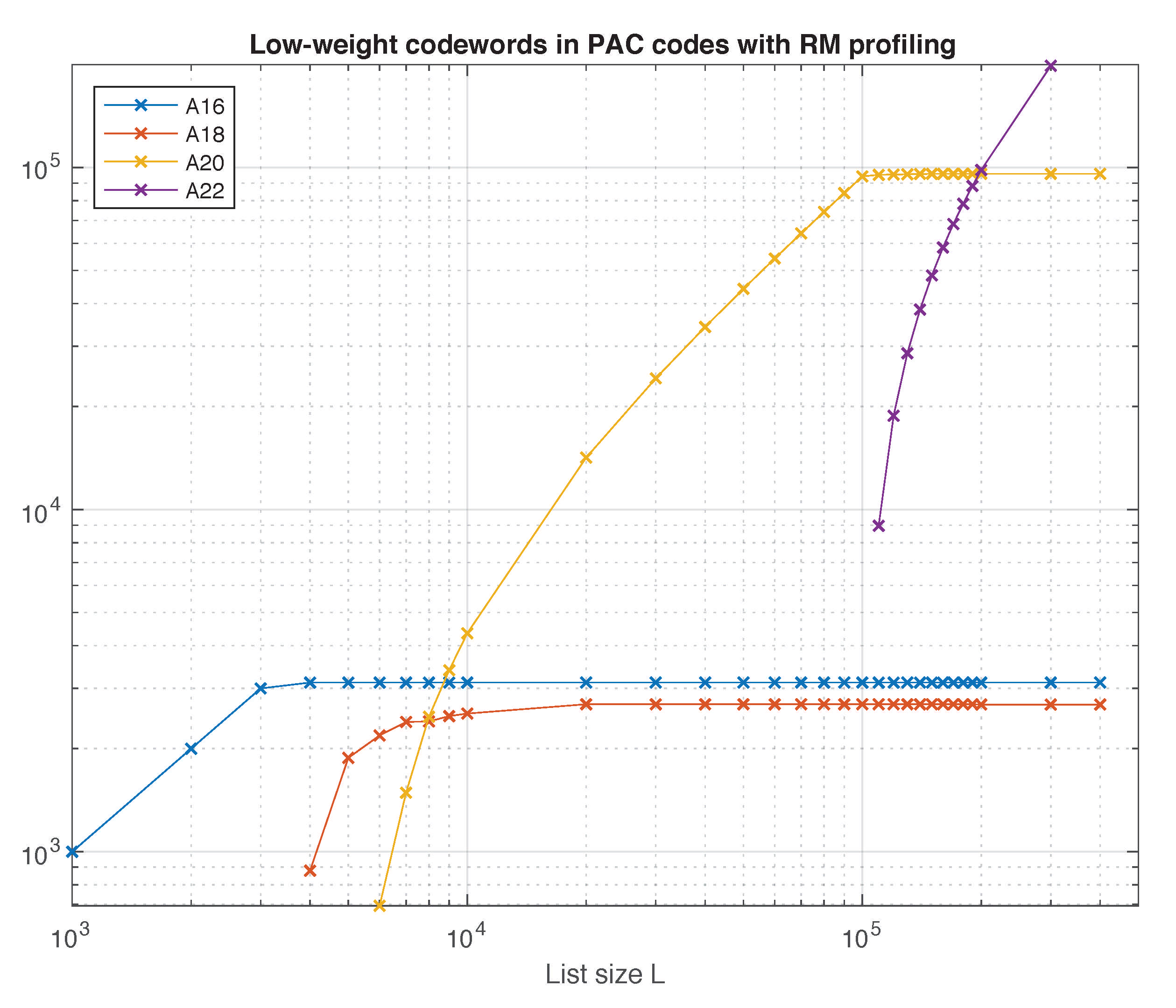
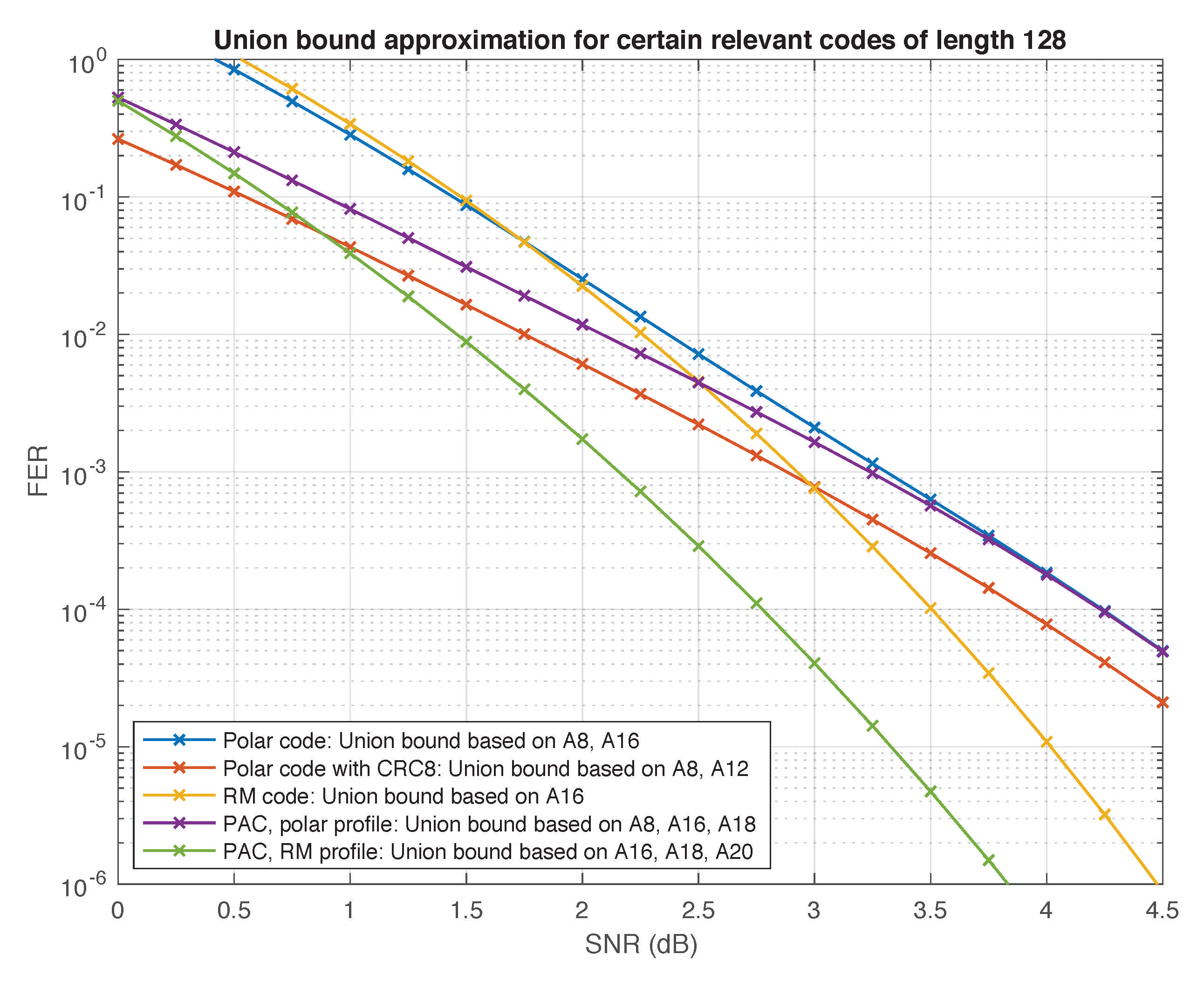
5.2. Weight Distributions and Union Bounds
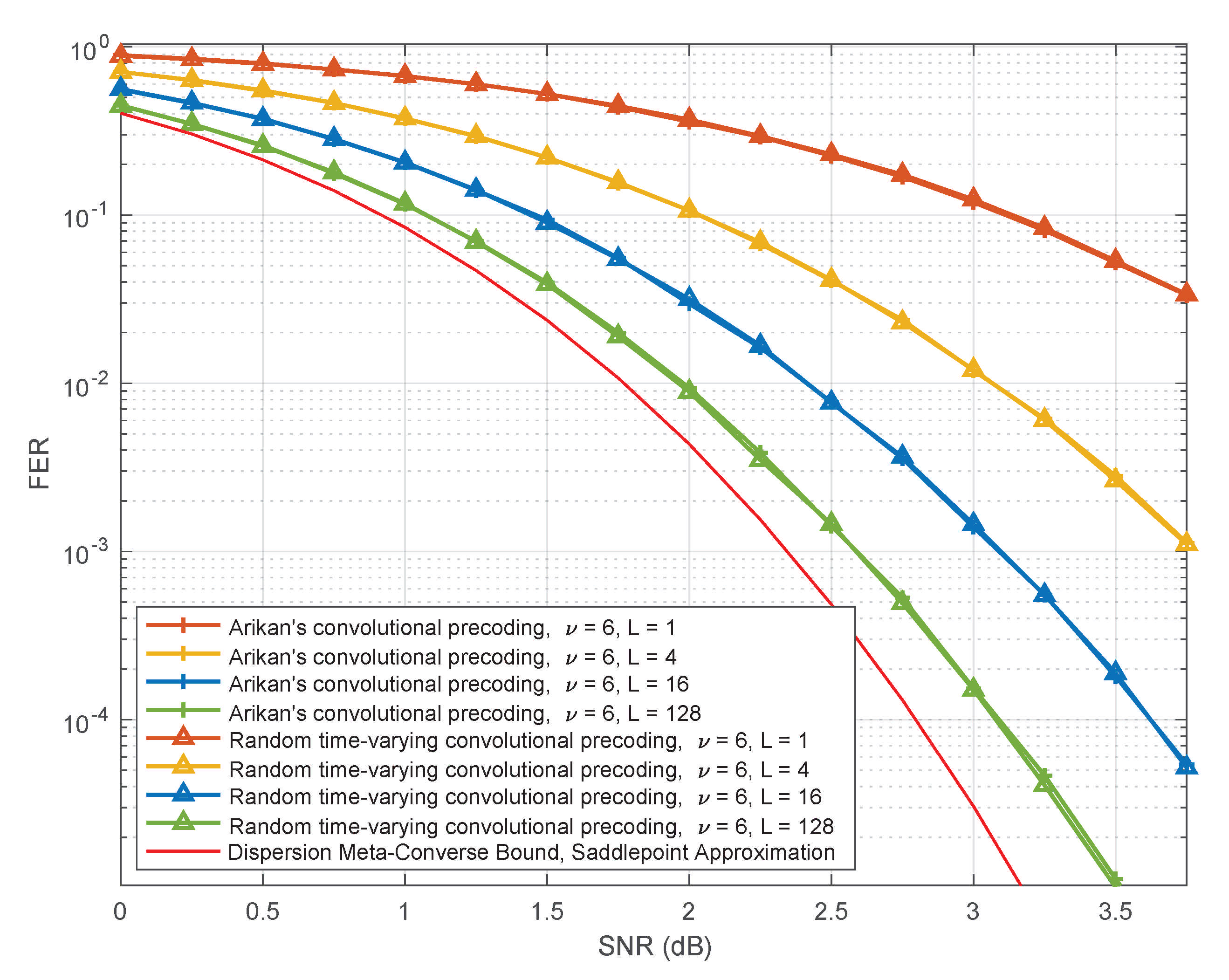
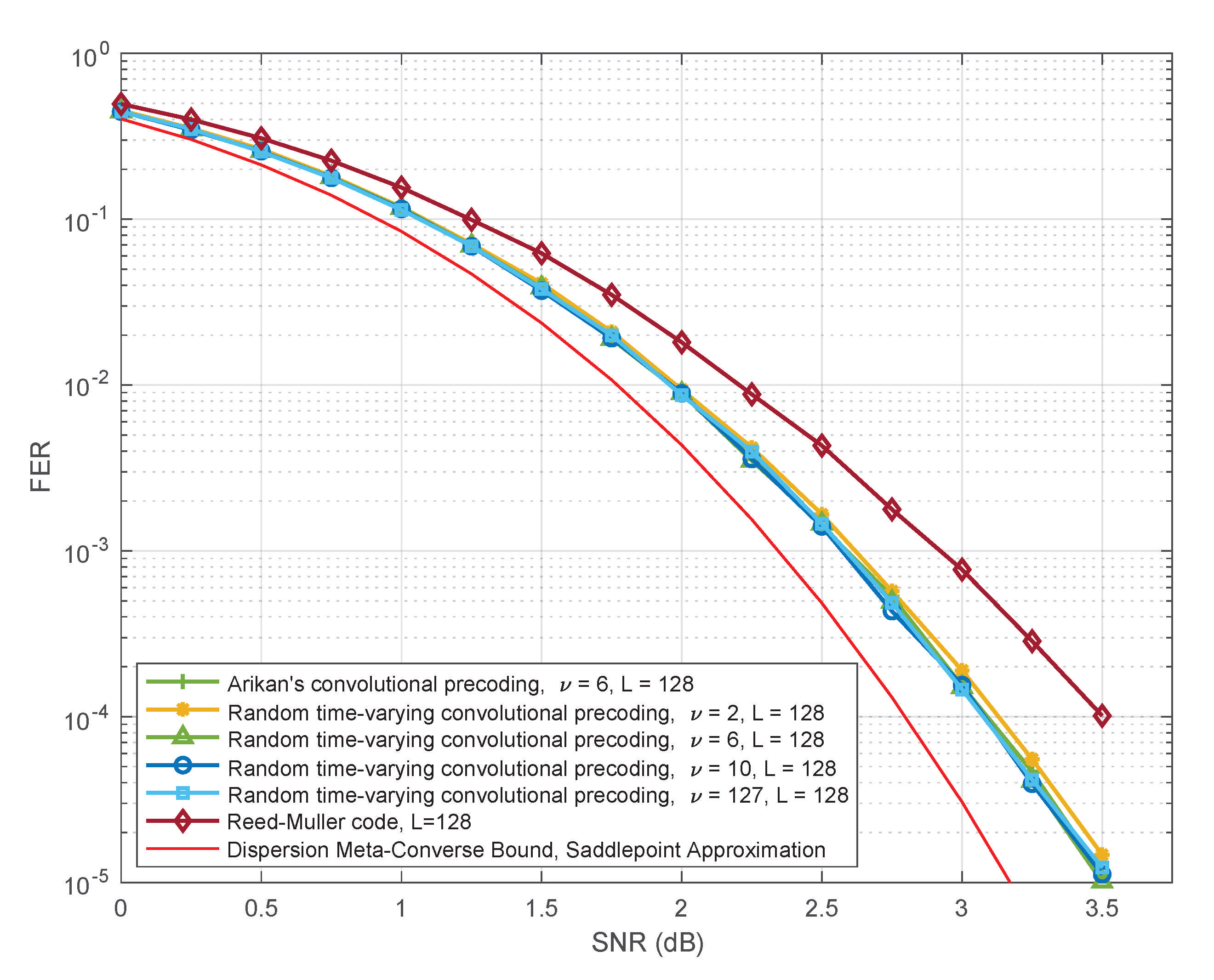
6. PAC Codes with Random Time-Varying Convolutional Precoding
As long as the constraint length of the convolution is sufficiently large, choosing c at random may be an acceptable design practice.
6.1. Random Time-Varying Convolutional Precoding
6.2. Performance of PAC Codes with Random Time-Varying Convolutional Precoding
7. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arıkan, E. Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- Arıkan, E. From sequential decoding to channel polarization and back again. arXiv 2019, arXiv:1908.09594. [Google Scholar]
- Polyanskiy, Y.; Poor, H.V.; Verdu, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Tal, I.; Vardy, A. List decoding of polar codes. IEEE Trans. Inf. Theory 2015, 61, 2213–2226. [Google Scholar] [CrossRef]
- Li, B.; Shen, H.; Tse, D. An adaptive successive cancellation list decoder for polar codes with cyclic redundancy check. IEEE Commun. Lett. 2012, 16, 2044–2047. [Google Scholar] [CrossRef] [Green Version]
- Miloslavskaya, V.; Trifonov, P. Sequential decoding of polar codes. IEEE Commun. Lett. 2014, 16, 1127–1130. [Google Scholar] [CrossRef]
- Niu, K.; Chen, K. CRC-aided decoding of polar codes. IEEE Commun. Lett. 2012, 16, 1668–1671. [Google Scholar] [CrossRef]
- 3GPP Technical Specification Group Radio Access Network, “Multiplexing and channel coding” Release 16, 3GPP TS 38.212 V16.3.0. November 2020. Available online: https://www.etsi.org/deliver/etsi_ts/138200_138299/138212/16.03.00_60/ts_138212v160300p.pdf (accessed on 27 June 2021).
- Erseghe, T. Coding in the finite-blocklength regime: Bounds based on Laplace integrals and their asymptotic approximations. IEEE Trans. Inf. Theory 2016, 62, 6854–6883. [Google Scholar] [CrossRef]
- Fano, R. A heuristic discussion of probabilistic decoding. IEEE Trans. Inf. Theory 1963, 9, 64–74. [Google Scholar] [CrossRef]
- Gallager, R.G. Information Theory and Reliable Communication; Wiley: New York, NY, USA, 1968. [Google Scholar]
- Trifonov, P. A score function for sequential decoding of polar codes. In Proceedings of the IEEE International Symposium on Information Theory, Vail, CO, USA, 21–26 June 2018; pp. 1470–1474. [Google Scholar]
- Fazeli, A.; Hassani, H.; Mondelli, M.; Vardy, A. Binary linear codes with optimal scaling: Polar codes with large kernels. IEEE Trans. Inf. Theory 2020. [Google Scholar] [CrossRef]
- Fazeli, A.; Vardy, A. On the scaling exponent of binary polarization kernels. In Proceedings of the Allerton Conference Communication, Control, and Computing, Monticello, IL, USA, 30 September–3 October 2014; pp. 797–804. [Google Scholar]
- Korada, S.B.; Şaşoğlu, E.; Urbanke, R. Polar codes: Characterization of exponent, bounds, and constructions. IEEE Trans. Inf. Theory 2010, 56, 6253–6264. [Google Scholar] [CrossRef] [Green Version]
- Moskovskaya, E.; Trifonov, P. Design of BCH polarization kernels with reduced processing complexity. IEEE Commun. Lett. 2020, 24, 1383–1386. [Google Scholar] [CrossRef]
- Trifonov, P. On construction of polar subcodes with large kernels. In Proceedings of the IEEE International Symposium on Information Theory, Paris, France, 7–12 July 2019; pp. 1932–1936. [Google Scholar]
- Trifonov, P. Trellis-based decoding techniques for polar codes with large kernels. In Proceedings of the IEEE Information Theory Workshop, Visby, Sweden, 25–28 August 2019; pp. 1–5. [Google Scholar]
- Trofimiuk, G.; Trifonov, P. Efficient decoding of polar codes with some 16×16 kernels. In Proceedings of the IEEE Information Theory Workshop, Guangzhou, China, 25–29 November 2018; pp. 11–15. [Google Scholar]
- Trofimiuk, G.; Trifonov, P. Reduced complexity window processing of binary polarization kernels. In Proceedings of the IEEE International Symposium on Information Theory, Paris, France, 7–12 July 2019; pp. 1412–1416. [Google Scholar]
- Yao, H.; Fazeli, A.; Vardy, A. Explicit polar codes with small scaling exponent. In Proceedings of the IEEE International Symposium on Information Theory, Paris, France, 7–12 July 2019; pp. 1757–1761. [Google Scholar]
- Morozov, R.; Trifonov, P. Successive and two-stage systematic encoding of polar subcodes. IEEE Wireless Commun. Lett. 2019, 8, 877–880. [Google Scholar] [CrossRef]
- Trifonov, P. Star polar subcodes. In Proceedings of the IEEE Wireless Communications and Networking Conference, San Francisco, CA, USA, 17–21 March 2017; pp. 1–6. [Google Scholar]
- Trifonov, P. Randomized polar subcodes with optimized error coefficient. IEEE Trans. Commun. 2020, 68, 6714–6722. [Google Scholar] [CrossRef]
- Trifonov, P.; Miloslavskaya, V. Polar codes with dynamic frozen symbols and their decoding by directed search. In Proceedings of the IEEE Information Theory Workshop, Sevilla, Spain, 9–13 September 2013; pp. 1–5. [Google Scholar]
- Trifonov, P.; Miloslavskaya, V. Polar subcodes. IEEE J. Sel. Areas Commun. 2016, 34, 254–266. [Google Scholar] [CrossRef] [Green Version]
- Trifonov, P.; Trofimiuk, G. A randomized construction of polar subcodes. In Proceedings of the IEEE International Symposium on Information Theory, Aachen, Germany, 25–30 June 2017; pp. 1863–1867. [Google Scholar]
- Ferris, A.J.; Poulin, D. Branching MERA codes: A natural extension of polar codes. arXiv 2013, arXiv:1312.4575. [Google Scholar]
- Ferris, A.J.; Hirche, D.C.; Poulin, D. Convolutional polar codes. arXiv 2017, arXiv:1704.00715. [Google Scholar]
- Morozov, R. Convolutional polar kernels. IEEE Trans. Commun. 2020, 68, 7352–7361. [Google Scholar] [CrossRef]
- Morozov, R.; Trifonov, P. On distance properties of convolutional polar codes. IEEE Trans. Commun. 2019, 67, 4585–4592. [Google Scholar] [CrossRef]
- Abbe, E.; Ye, M. Reed-Muller codes polarize. IEEE Trans. Inf. Theory 2020, 66, 7311–7332. [Google Scholar] [CrossRef]
- Li, B.; Shen, H.; Tse, D. RM-polar codes. arXiv 2014, arXiv:1407.5483. [Google Scholar]
- Mondelli, M.; Hassani, S.H.; Urbanke, R.L. From polar to Reed–Muller codes: A technique to improve the finite-length performance. IEEE Trans. Commun. 2020, 62, 3084–3091. [Google Scholar] [CrossRef] [Green Version]
- Ye, M.; Abbe, E. Recursive projection-aggregation decoding of Reed–Muller codes. arXiv 2019, arXiv:1902.01470. [Google Scholar]
- Coşkun, M.C.; Neu, J.; Pfister, H.D. Successive cancellation inactivation decoding for modified Reed–Muller and eBCH codes. In Proceedings of the IEEE International Symposium on Information Theory, Los Angeles, CA, USA, 21–26 June 2020; pp. 437–442. [Google Scholar]
- Miloslavskaya, V.; Vucetic, B. Design of short polar codes for SCL decoding. IEEE Trans. Commun. 2021, 68, 6657–6668. [Google Scholar] [CrossRef]
- Yuan, P.; Prinz, T.; Böcherer, G.; Iscan, O.; Boehnke, R.; Xu, W. Polar code construction for list decoding. In Proceedings of the 12th International ITG Conference on Systems, Communications and Coding, Rostock, Germany, 11–14 February 2019; pp. 1–6. [Google Scholar]
- Fazeli, A.; Tian, K.; Vardy, A. Viterbi-aided successive-cancellation decoding of polar codes. In Proceedings of the IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Fazeli, A.; Vardy, A.; Yao, H. Convolutional decoding of polar codes. In Proceedings of the IEEE International Symposium on Information Theory, Paris, France, 7–12 July 2019; pp. 1397–1401. [Google Scholar]
- Arıkan, E. Systematic encoding and shortening of PAC Codes. Entropy 2020, 22, 1301. [Google Scholar] [CrossRef]
- Li, B.; Zhang, H.; Gu, J. On pre-transformed polar codes. arXiv 2019, arXiv:1912.06359. [Google Scholar]
- Mishra, S.K.; Kim, K.C. Selectively precoded polar codes. arXiv 2020, arXiv:2011.04930. [Google Scholar]
- Moradi, M.; Mozammel, A.; Qin, K.; Arıkan, E. Performance and complexity of sequential decoding of PAC codes. arXiv 2020, arXiv:2012.04990v1. [Google Scholar]
- Mozammel, A. Hardware implementation of Fano decoder for PAC codes. arXiv 2020, arXiv:2011.09819. [Google Scholar]
- Tonnellier, T.; Gross, W.J. On systematic polarization-adjusted convolutional (PAC) codes. arXiv 2020, arXiv:2011.03177. [Google Scholar]
- Wang, L.; Jiang, M.; Zhao, C.; Li, Z. Genetic optimization of short block-length PAC codes for high capacity PHz communications. In Proceedings of the International Conference on Optoelectronic and Microelectronic Technology and Application, Nanjing, China, 17–19 October 2020; Volume 11617. [Google Scholar]
- Rowshan, M.; Burg, A.; Viterbo, E. Polarization-adjusted convolutional (PAC) codes: Fano decoding vs. list decoding. arXiv 2020, arXiv:2002.06805v1. [Google Scholar]
- Rowshan, M.; Viterbo, E. List Viterbi decoding of PAC codes. arXiv 2020, arXiv:2007.05353. [Google Scholar]
- Yao, H.; Fazeli, A.; Vardy, A. List decoding of Arıkan’s PAC codes. In Proceedings of the IEEE International Symposium on Information Theory, Los Angeles, CA, USA, 21–26 June 2020; pp. 443–448. [Google Scholar]
- Vazquez-Vilar, G.; Fabregas, A.G.; Koch, T.; Lancho, A. Saddlepoint approximation of the error probability of binary hypothesis testing. In Proceedings of the IEEE International Symposium on Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 2306–2310. [Google Scholar]
- Coşkun, M.C.; Durisi, G.; Jerkovits, T.; Liva, G.; Ryan, W.; Stein, B.; Steiner, F. Efficient error-correcting codes in the short blocklength regime. Phys. Commun. 2019, 34, 66–79. [Google Scholar] [CrossRef] [Green Version]
- Goldin, D.; Burshtein, D. Performance bounds of concatenated polar coding schemes. IEEE Trans. Inf. Theory 2019, 65, 7131–7148. [Google Scholar] [CrossRef] [Green Version]
- Sarkis, G.; Giard, P.; Vardy, A.; Thibeault, C.; Gross, W.J. Increasing the speed of polar list decoders. In Proceedings of the IEEE Workshop on Signal Processing Systems (SiPS), Belfast, UK, 20–22 October 2014; pp. 1–6. [Google Scholar]
- Sarkis, G.; Giard, P.; Vardy, A.; Thibeault, C.; Gross, W.J. Fast list decoders for polar codes. IEEE J. Sel. Areas Commun. 2016, 34, 318–328. [Google Scholar] [CrossRef] [Green Version]
- Balatsoukas-Stimming, A. Private Communication, August 2019.
- Sugino, M.; Ienaga, Y.; Tokura, N.; Kasami, T. Weight distribution of (128,64) Reed–Muller code. IEEE Trans. Inf. Theory 1971, 17, 627–628. [Google Scholar] [CrossRef]
- Yao, H.; Fazeli, A.; Vardy, A. A deterministic algorithm for computing the weight distribution of polar codes. arXiv 2021, arXiv:2102.07362. [Google Scholar]
- Sason, I.; Shamai, S. Performance analysis of linear codes under maximum-likelihood decoding: A tutorial. Found. Trends Commun. Inf. Theory 2006, 3, 1–225. [Google Scholar] [CrossRef]
- Zhu, H.; Cao, Z.; Zhao, Y.; Li, D.; Yang, Y.; Wang, Y.; Guo, Z. Fast list decoders for polarization-adjusted convolutional (PAC) codes. arXiv 2020, arXiv:20122.09425. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR [dB] | 1.00 | 1.25 | 1.50 | 1.75 | 2.00 | 2.25 |
| % of failures | 4.53% | 3.56% | 1.86% | 1.38% | 1.01% | 0.29% |
| SNR [dB] | 1.50 | 1.75 | 2.00 | 2.25 | 2.50 | 2.75 | 3.00 |
| 32.1% | 32.2% | 32.5% | 32.3% | 29.4% | 36.7% | 39.6% | |
| 50.0% | 51.6% | 54.6% | 53.6% | 58.4% | 60.4% | 63.2% | |
| 66.2% | 71.0% | 75.2% | 78.0% | 79.9% | 83.6% | 82.8% |
| Polar code | 48 | 0 | 68,856 | 0 | 897,024 | 0 |
| Polar code, CRC8 | 20 | 173 | ⩾7069 | - | - | - |
| Reed–Muller | 0 | 0 | 94,488 | 0 | 0 | 0 |
| PAC, polar profile | 48 | 0 | 11,032 | 6024 | > | - |
| PAC, RM profile | 0 | 0 | 3120 | 2696 | 95,828 | >10 |
| Random precoding with | 0 | 6424 | 7780 | 142,618 | >10 |
| Arıkan’s PAC code with | 0 | 3120 | 2696 | 95,828 | >10 |
| Random precoding with | 0 | 2870 | 1526 | 88,250 | >10 |
| Random precoding with | 0 | 2969 | 412 | 81,026 | >10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, H.; Fazeli, A.; Vardy, A. List Decoding of Arıkan’s PAC Codes. Entropy 2021, 23, 841. https://doi.org/10.3390/e23070841
Yao H, Fazeli A, Vardy A. List Decoding of Arıkan’s PAC Codes. Entropy. 2021; 23(7):841. https://doi.org/10.3390/e23070841
Chicago/Turabian StyleYao, Hanwen, Arman Fazeli, and Alexander Vardy. 2021. "List Decoding of Arıkan’s PAC Codes" Entropy 23, no. 7: 841. https://doi.org/10.3390/e23070841
APA StyleYao, H., Fazeli, A., & Vardy, A. (2021). List Decoding of Arıkan’s PAC Codes. Entropy, 23(7), 841. https://doi.org/10.3390/e23070841