1. Introduction
The problem of wealth inequality is the subject of intense research in economics [
1,
2,
3,
4,
5], sociology and econophysics [
6], but it also arouses great interest outside of science [
7,
8,
9,
10,
11,
12,
13]. Parallel to empirical studies, theoretical research is carried out to explain the main features of wealth statistics and wealth dynamics observed in macroeconomic data, like the presence of Pareto tails in wealth distribution or increasing wealth inequality in the world.
In theoretical models, wealth dynamics is often described by stochastic equations representing the evolution of wealth of a typical individual in a given economic environment. In physical terminology, this can be called the one-body approach. Even today this approach is used in mainstream economics, for example, in studies of wealth inequality [
14]. An alternative is to use population dynamics, which in this context is often referred to as agent-based modelling. It was introduced in [
15] and popularised in [
16]. In agent-based modelling, the economy is perceived as a complex system consisting of many entities interacting with each other under given macroeconomic conditions. Unlike the one-body approach, this can be called the multi-body approach. The main idea of agent-based modelling is to statistically look at the problem of wealth distribution from the perspective of the entire system. This allows studying collective effects, like correlations between agents, or emergent phenomena, such as the formation of wealth classes, or self-organisation of the economy, or instability of the system. This perspective is in many aspects similar to that used in statistical physics, aiming at deriving macroscopic physical laws from microscopic rules by applying laws of large numbers. This is probably why the problem of wealth distribution has been intensively studied in the econophysical literature [
6]. Many ideas behind agent-based modelling have been derived from concepts like kinetic theory [
17,
18], scattering [
19], rate equations [
20], random matrix theory [
21,
22], Brownian motion [
23] which were developed in statistical physics. Using this type of ideas, one was able to model wealth or income distributions [
24], dynamics of wealth inequality [
25,
26], wealth concentration [
27], structure emergence [
28,
29], economic instability and corruption mechanisms [
30,
31,
32], systemic risk in economic networks [
33], emergence of heavy tails in wealth and income distributions [
24,
34], and herding behaviour [
35], or to analyse statistical behaviour or rational agents [
36].
Since the time of Keynes, it has been widely believed that a closed economy eventually reaches a stationary state, also known as a steady state or saturation. What is usually meant as a stationary state economy is a system where macroeconomic quantities have stationary distributions. A typical example is the wealth distribution that does not change over time after reaching a steady state. This does not mean that each person’s wealth is constant in time, but that the system as a whole has a stationary distribution in a statistical sense. In fact, the wealth of individuals may change all the time even in the stationary state. Wealth flows from one individual to another: some people get richer, some poorer—
panta rhei. In this article, we will take a closer look at the flow of wealth. We call this class of phenomena wealth rheology. To be specific, in the paper we study the dynamics of wealth rank correlations using the Bouchaud–Mézard model of macroeconomy [
24]. The model is implemented as a stochastic process based on Gibrat’s law of proportionate growth [
37] which is combined with dynamics representing agents’ interactions. The model generates Pareto’s tail in the wealth distribution [
38]. The stochastic process belongs to the class of Kesten processes [
39], which is a class of multiplicative contracting stochastic processes. It is a generic feature of Kesten processes that they lead to a stationary state with a power-law tail.
2. The Model
In this section, we briefly recall the Bouchaud–Mézard model [
24]. The model describes evolution of wealth of
N interacting agents in a closed macroeconomic system. The evolution is given by
N stochastic differential equations for wealth
of agents
at time
t. In the continuous time formalism the equations read
where
,
are independent Wiener processes (continuous Brownian motions). The above equations are written in the Itô formalism (in the Stratonovich approach the term
would be replaced with
). In this paper, we shall use the discrete time formalism. Equation (
1) can be discretised by introducing an elementary time interval
relating physical time
t to discrete time
as follows
. In the leading order, up to
-terms, the discretisation of Equation (
1) gives
where
,
and
are independent identically distributed random variables with the normal distribution
with
and
. In the limit
, Equation (
1) is restored. The first term on the right hand side of Equation (
2) corresponds to random multiplicative fluctuations of wealth. In the economic literature, it is referred to as the law of proportionate effect [
37] stating that growth rates
are independent of wealth. In the simplest version of the model it is assumed that the growth rates have the same mean
and the same variance
for all agents throughout evolution of the system. The first term on the right hand side of Equation (
2) reflects spontaneous changes in wealth due to changing market conditions and expectations. The second one describes the flow of wealth between individuals, resulting from interactions and trading. Coefficient
is the fraction of wealth of agent
a which is transferred to agent
b within a single time interval
. Equations (
2) are invariant under rescaling of wealth by a common factor
for all
. In particular, this means that the equations do not change when the monetary units change. Therefore, it is convenient to express wealth in units of the mean wealth
. We denote the corresponding quantities by small letters
The normalised wealth values (
3) are insensitive to the parameter
controlling the mean growth rate, because it cancels in the numerator and the denominator of Equation (
3). The change
can be interpreted as a change of the inflation rate by
.
The model can be solved in the mean-field approximation assuming that all agents interact with each other with the same intensity
for all pairs
. For
, in the limit
and
, the normalised wealth (
3) can be shown to approach a stationary state with the distribution given by the inverse gamma distribution with the following probability density function [
24]:
where the parameter
is
One can easily check that the mean of this distribution is equal to one, that is
in accordance with the normalisation (
3). The distribution has a Pareto tail
for
with the exponent
, given by Equation (
5). The index
depends on the ratio of the flow intensity parameter
j and the volatility of growth rates
, so the stationary distribution does not change when
and
j are simultaneously re-scaled by the same factor
and
. The parameters
and
j can be interpreted as economic activity parameters. The flow parameter
j reflects the intensity of trade and wealth exchange. The parameter
is the growth rate volatility and it reflects the degree of economic freedom: the larger
the more liberal economy. Large values of
mean that the state does not intervene and does not help if economic entities need support. On the contrary it supports and encourages a free market, new ideas, bold businesses and the foundation of start-ups, etc. In effect, some companies may quickly grow, while some large established companies can shrink or go bankrupt quickly. For a large
, large changes in the wealth of individuals are expected. In such circumstances, the economic landscape is changing rapidly. On the other hand, small values of
mean that the economy is very conservative, that is, the system discourages risky investments and the state intervenes when established companies need help, the system supports economic status quo and the economy is more predictable in the short term.
The aim of this paper is to compare the wealth dynamics in steady state for systems having the same stationary distribution (
4), but different economic activity parameters
and
j. To get an insight into wealth flow dynamics in the steady state, we study temporal evolution of wealth rank correlations and quantify them by measuring Kendall’s
[
40] and Spearman’s
[
41] for wealth distributions separated by
k steps of evolution (
2). Standard definitions of rank correlations are recalled in
Appendix A.
4. Results
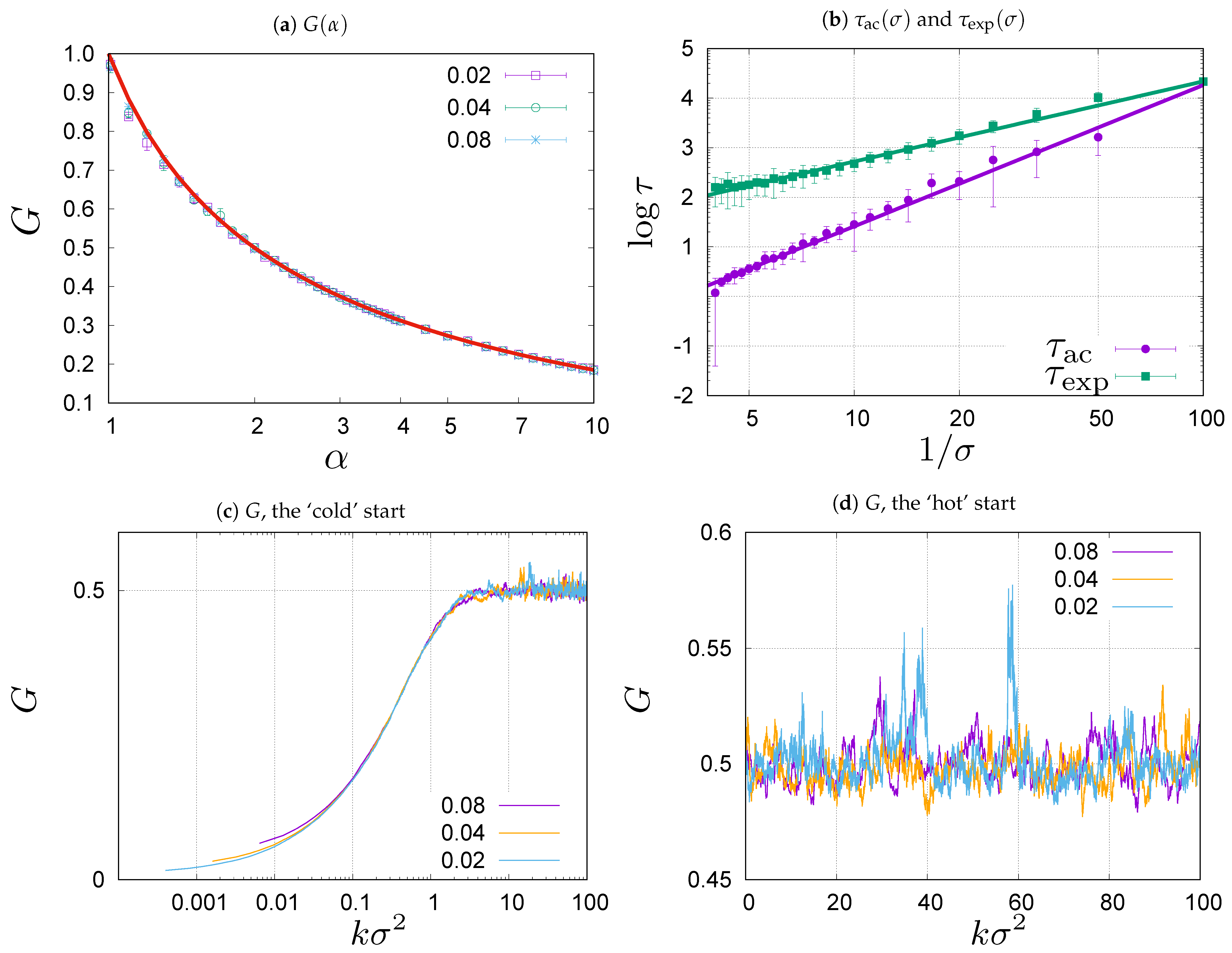
In
Figure 1a, we compare a theoretical prediction for the Gini coefficient with the values obtained in Monte Carlo simulations of the system with
and
. The theoretical prediction for the distribution (
4) reads [
26]
where
is the hypergeometric function [
42]. One can see in
Figure 1a that the experimental and theoretical values are consistent. This means that the evolution Equation (
7) bring the system to the predicted steady state. In fact, there are some slight deviations from the theoretical prediction which can be attributed to the fact that the theoretical results are derived in the continuous time formalism, while the Monte Carlo simulations are done for discrete time. The deviations grow with the volatility
.
The main conclusion from the comparison shown in
Figure 1a is that the stationary state in the first-order approximation depends on the combination
and not on
itself, exactly as predicted by the theoretical Formula (
8). Let us now address the question how the dynamic properties of evolution depend on
. First, we will study the rate of relaxation towards the steady state by measuring the exponential auto-correlation time
[
43] for the Gini coefficient. Roughly speaking the exponential time corresponds to the time needed for the system to reach the stationary state. To measure
we initiate the system from a uniform wealth distribution (cold start), for which the Gini coefficient is
, and wait till the Gini coefficient of the current configuration exceeds the steady state value for the first time. In
Figure 1b we show the mean exponential auto-correlation time
as a function of
for
and
averaged over a sample of 100 values obtained from independent simulations. We see that
grows as
decreases. This effect is clearly seen in
Figure 1c which shows examples of the evolution of the Gini coefficient for
,
from cold starts for
,
and
. In all three cases the Gini coefficient evolves from the initial value
towards the stationary state value (
5) which is equal to
for
. The values of
G during the evolution are plotted against
in
Figure 1c. The variable
on the horizontal axis is proportional to physical time
, for given
in Equation (
1), because
. The curves in
Figure 1c correspond to different time intervals
used in the discretization of Equation (
1). The small variations between the curves, seen in
Figure 1c for small
, can be attributed to the higher-order corrections in
that occur in the discretization of Equation (
1), skipped in Equation (
2). Generally, we can expect that in the presented range of
the evolution is universally described by the parameter
, that we shall use from here on.
Once the stationary state is reached, the value of the Gini coefficient fluctuates about the steady state value. This is illustrated in
Figure 1d where we show evolution of the Gini coefficient in systems initiated from hot starts, that correspond to the stationary wealth distribution given by Equation (
4). The Gini coefficient fluctuates about the stationary value
but the way it fluctuates about this value slightly depends on the volatility
. The reason for this is related to the presence of a heavy tail in the limiting distribution (
4), which for
, leads to an infinite variance. In effect, the curves representing the evolution in
Figure 1d exhibit strong fluctuations which depart from mean value. For the simulations shown in the figure, the length of evolution measured in the discrete time steps,
k, is sixteen and four times longer for
and
, respectively, than for
. Therefore, we observe more fluctuations and larger deviations for
and
than for
. To quantify the degree of correlation between the values of the Gini coefficient at different times, we measure the integrated auto-correlation time
[
43] which gives a typical timescale for the length of temporal fluctuations. Coming back to
Figure 1b we show there the dependence of the integrated auto-correlation time
on
for the system with
and
. It can be compared in the figure to the relaxation time
that we previously discussed. As you can see, both
and
grow when
decreases. The straight lines in
Figure 1b are to guide the eye. They are determined as the best power-law fits:
, where
and
, where
.
As mentioned in the introduction, we are mainly interested in the dynamic aspects of the evolution of wealth distribution, such as wealth flow and wealth ranking reshuffling. We are now going to analyse the wealth rank correlations for different systems having the same stationary state, by studying systems with different
’s and
j’s but identical
’s (
5).
Wealth rank is a position on the ranking list ordered from the richest to the poorest individuals. The wealth ranking is continuously reshuffling, even in the stationary state. The rate of reshuffling depends on
and
j: the larger
and
j the faster is the reshuffling. Changes in wealth ranking are faster when
is larger. In
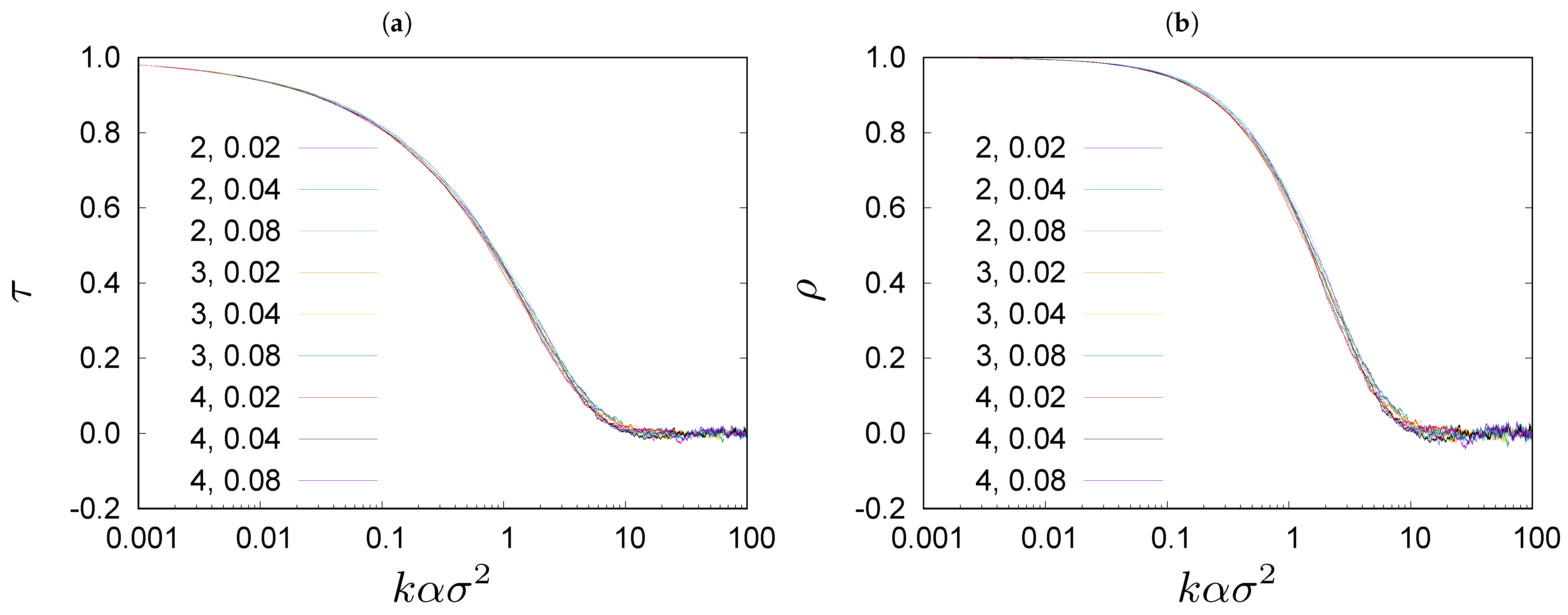
Figure 2, we show rank correlations between wealth ranking lists obtained in the Monte Carlo simulations of the Bouchaud–Mézard model [
24], for configurations separated by
k steps of evolution (
7), in the stationary state of the system with
, and
,
and
, and
,
and
. The degree of rank correlations is quantified by Kendall’s
[
40] and Spearman’s
[
41]
(see
Appendix A). In
Figure 2, we plot
and
against a rescaled variable
. We can see that the curves lie on top of each other, reflecting some universality of the wealth rheology in the model (
1).
Another quantity which captures rank correlations is the overlap ratio which is defined as the percentage of people which are among
n richest people at times
and
. For example, you may be interested in how many people from the top 100 richest list in some year, are in the top 100 richest list one or two years later. If
denotes the set of people being in the top-
n richest list in the ranking at time
and
at time
, the overlap ratio is:
where the symbol ∩ denotes sets’ intersection, and # is the set’s cardinality. If the dynamics describing the wealth evolution is Markovian, then the overlap ratio
depends on the time difference
. In such a case, the overlap ratio can be estimated numerically as follows
where
k is the discrete time, which refers to consecutive configurations (rankings), and
K is the number of configurations in the sample. In
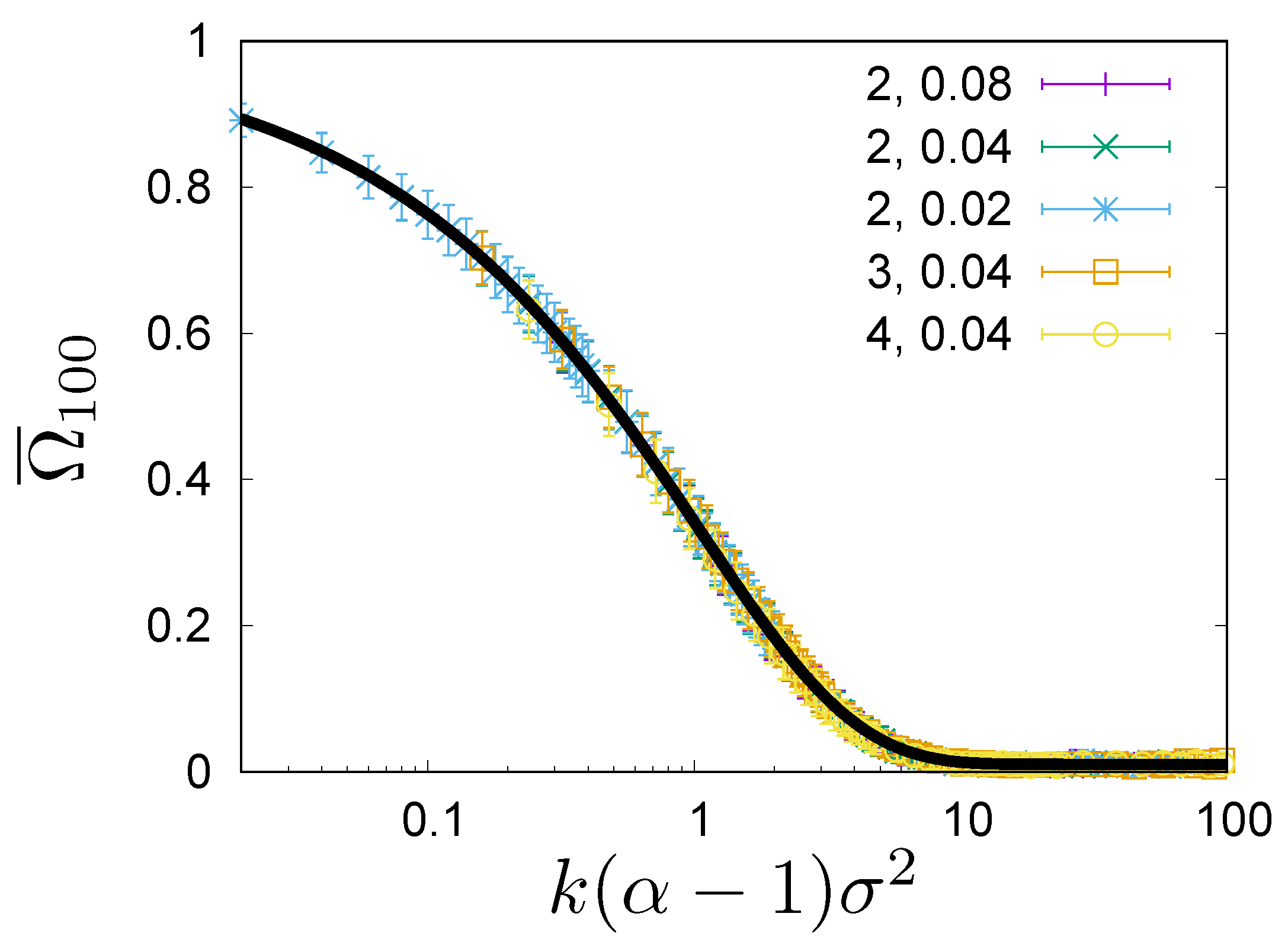
Figure 3, we show the expected overlap
for the top 100 richest list, estimated from the steady state configurations in Monte Carlo simulations for three values of
(
4) and for three values of
, for
. We see that all curves collapse to a single universal curve. By listing explicitly all arguments of the overlap ratio
, we see that the overlap ratio becomes a universal function of the argument
:
The function
interpolates monotonically between
for
and
for
. A simple phenomenological formula
gives a very good fit to the data (see
Figure 3). Notice that the scaling variable
is not the same as the scaling variable
for
and
.
In the remainder of this section, we will investigate the rheology of wealth in real world systems. People’s wealth data are very sensitive, so it is almost impossible to collect them. Therefore we restrict ourselves to data on the richest people that is publicly available. To be specific, we focus on the top 100 lists of richest people in Poland, Germany, the USA and the world [
11,
12,
13]. The top 100 richest lists are a small part of the whole picture but it is the part that usually gets the most attention. Data that we analyse covers the period 2000–2020 for Poland [
11], Germany [
12] and the USA [
13], and the period 2000–2018 for the world [
13]. We are going to determine the rank correlation coefficients
(
A2),
(
A4), and
(
A5) between the top 100 richest lists in years 2000 and
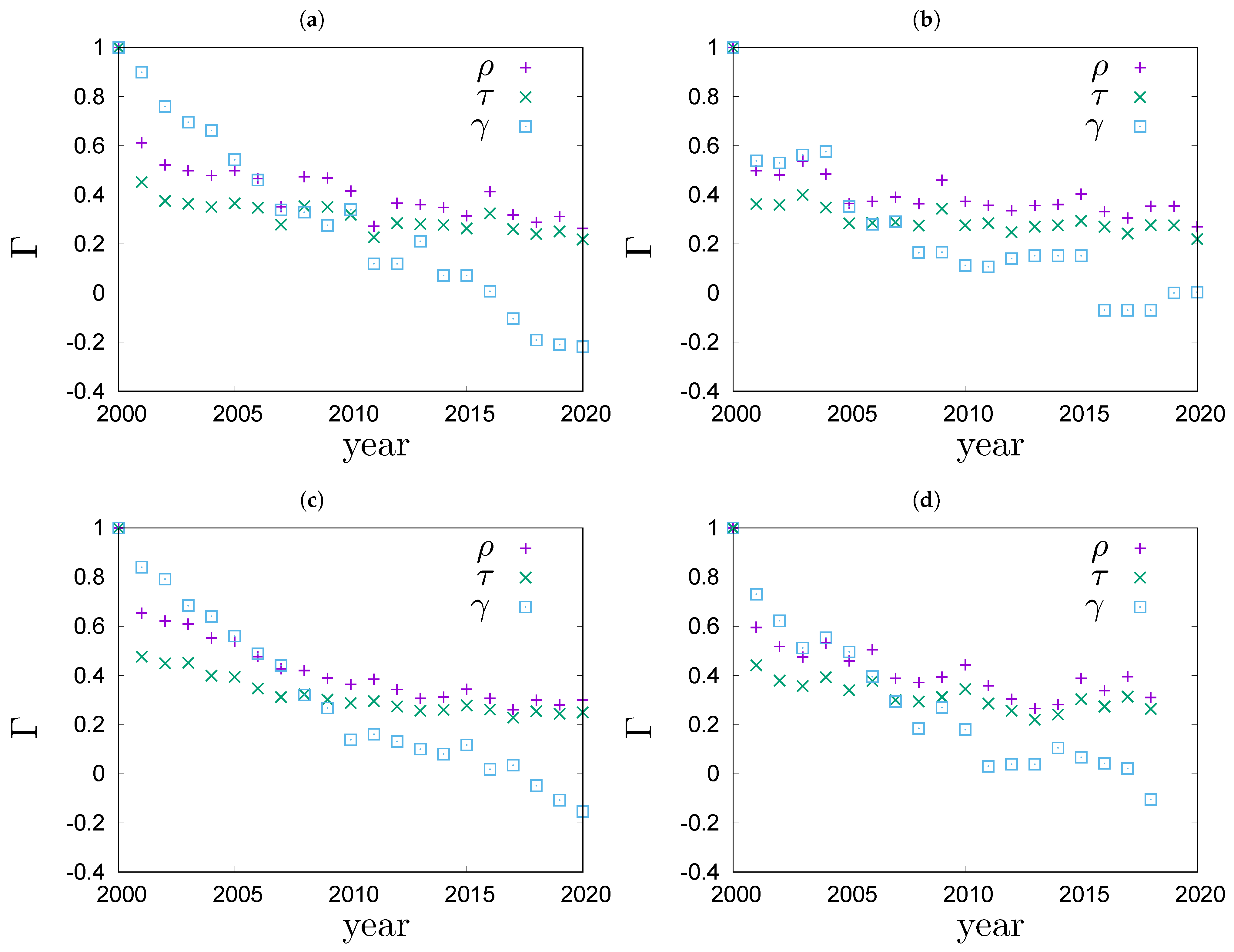
. The sets of people present in the top 100 richest lists vary from year to year: there are people who are in the top 100 richest list in some years but not in others. To compare the lists we must first standardize them so that they include the same set of people every year. To do so, we determine a full set of people who have been present on the top 100 list at least once in the studied period. The full set is then used to complete the annual top 100 lists in the following way: if a person from the full set is not in the top 100 richest list for a given year, s/he is added to this list with a unique random rank in the range between 101 and the number of people in the full set. In the analysed period, the full sets contain 360 people in Poland, 342 in Germany, 319 in the USA and 323 in the world. For each system, all standardized lists are of the same size and contain the same people every year. The standardized lists are used as input to calculations of
and
. The results are shown in
Figure 4. In the figure you can also see the results for Goodman–Kruskal’s
(
A5) computations. To compute
we used a slightly different algorithm to complement the annual lists. The algorithm assigns the same ex aequo rank to all people added as a complement, to the list. By design, the coefficient
omits ex aequo ranks, thus minimizing the statistical bias coming from the artificial completion of lists. Analysing the plots in
Figure 4 we see for example, that the values of
drop between
and
much less than the corresponding values of
and
. The big drop of
and
is related to the large number of additional rank pairs, created by the complement algorithm. The number of pairs is less in the complement algorithm for
. When the sets of elements vary from year to year, the Goodman–Kruskal’s coefficient
better captures rank correlations of the original ranking lists. Therefore, we find it more reliable to use
to compare rank correlations for lists of different lengths.
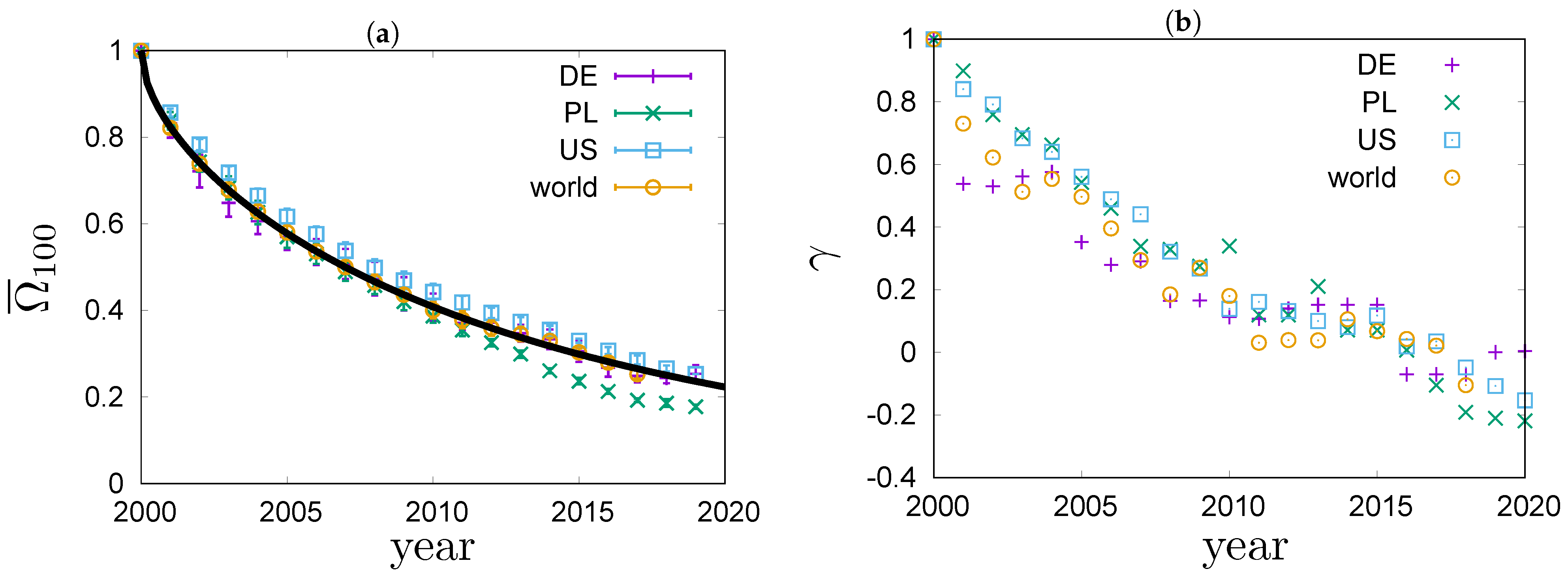
In
Figure 5a, values of the overlap ratio of the annual top 100 richest lists in Poland, Germany, the US and the world are compared. The overlap ratios exhibit a fairly universal behaviour that is well described by the phenomenological Formula (
12). The best fit to the top 100 richest people in the world is shown with a solid line in
Figure 5a. It fits the data very well. We can see that in the four systems the overlap ratio drops to
after
years. In
Figure 5b, values of the Goodman–Kruskal’s rank correlation coefficient
for the four systems are compared. We can see that the rank correlations fall off from one to zero roughly within 20 years. The rate of decay for
is quite similar in all the studied systems. For Germany, the dependence of
on time exhibits an interesting pattern. The values of
stay roughly constant for a couple of years, then significantly drop and again stay roughly constant for a couple of years. This motif repeats a couple of times, forming a stairway shape.
5. Conclusions
Steady-state macroeconomic systems are characterized by no statistical changes in the distribution of wealth and macroeconomic parameters. This does not mean that there are no changes in the system. On the contrary, in the microscale the system undergoes continuous dynamical changes. As far as the wealth distribution is concerned, the internal dynamics can be observed as a continuous process which manifests as reshuffling of wealth ranks of people on the wealth ranking lists: some people get richer, some get poorer. In this paper, we have studied the dynamical properties of macroeconomic systems related to the flow of wealth, and wealth rheology. We used the Bouchaud–Mézard model and the agent-based modelling approach to simulate the evolution of wealth in a closed macroeconomy. An interesting property of the Bouchaud–Mézard model is that it generates steady states with a Pareto tail in the wealth distribution, and that different combinations of economic activity parameters may lead to the same limiting wealth distribution. This allowed us to investigate the dependence of wealth rank correlations on the wealth activity parameters for various scenarios but the same wealth distribution. We have seen that the wealth rank correlations depend mainly on the growth rate volatility. The smaller the volatility, the larger the correlations. The rank correlations are closely related to auto-correlations in the system. We have also studied rank correlations on the top 100 richest lists in Poland, Germany, the US and the world using the Goodman–Kruskal’s and the lists overlap ratio . We have observed that the rank correlations in the studied systems exhibit a certain degree of universality, for example, the overlap ratio gets reduced by half within and the Goodman–Kruskal’s decreases to zero within two decades. We have focused on the top 100 richest lists because they are easily available. It would be interesting to perform a similar analysis for top-n lists for larger n and for longer periods, years, in the future to get a full picture on wealth rank dynamics.
There are also some theoretical questions—regarding the scaling and universality of results—that are extremely interesting. We have seen that the correlation coefficients
and
depend on a universal variable
while the overlap ratio
on
. The question is if this scaling is the general feature of the Kesten processes? To solve this problem we have considered an alternative implementation of Kesten dynamics, where the wealth of agents is generated as exponents
of independent random walks
,
on the positive semi-axis with the drift towards the reflective wall located at
. Such a stochastic process is probably the simplest implementation of the Kesten process. It leads to a stationary state with a power law in the probability density function of wealth distribution
for
, with the exponent
, where
are the drift and the volatility of the underlying random walk. The rank statistics of
W’s and
x’s are the same because the map
is monotonic. The Kesten dynamics is thus mapped onto the dynamics of a gas of particles performing independent random walks on the positive semiaxis. The gas of particles is much easier to analyse. For instance, one can give a simple argument that the overlap ratio for this system depends on the combination
, so the scaling is different than for the model discussed in this paper. Thus, the scaling is not universal. It would be interesting to find an analytical way to calculate the rank correlation measures in the models discussed in this paper. For the gas of random walkers on the positive semi-axis one can maybe use the spectral methods [
44].


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




