1. Introduction
Complex patterns exist in various real-world fields and can be simplified into complex networks. Individuals are represented as nodes, and the connections between them are correspondingly transformed to edges in a graph [
1,
2,
3]. For example, the connections between proteins in organisms and the relationship between cities in a traffic system [
4]—these real complex systems can be transformed into complex networks. Community detection is a common task in the field of complex network analysis [
5,
6].
Many studies have attempted to incorporate attribute and topology information in the community detection methodologies [
7] beyond the traditional approaches [
8,
9]. In addition to the topological structure of nodes connected by edges, the nodes or edges themselves always carry attribute information—that is, they form an attributed network. The attributes can be used as complementary information to overcome the sparsity of topological structure [
10,
11]. However, these two sources of information may be contradictory to each other in some cases [
12]. This makes it challenging to detect communities on attributed networks. In real-world networks, there may exist some vertices that belong to several communities simultaneously. Consequently, overlapping community detection has become a valuable research topic [
13]. The proposed OCEA and AOCEA are implemented over attributed networks and can be used to detect overlapping communities. Most of the real-world networks are full of attribute information and overlapping communities are quite common in social networks. Therefore, the proposed algorithms will have a wide range of applications in real life.
The main contributions of this work are as follows: (1) We proposed two algorithms OCEA and AOCEA that can be used to detect overlapping communities on attributed networks, which considers the multiple vertex-community memberships and employs a strategy to adjust attribute weights iteratively according to the memberships. (2) A new method for the automatic estimation of the number of communities is proposed to improve the practicability of OCEA. (3) Experimental results on synthetic and real-world datasets validate the effectiveness of OCEA and AOCEA.
Related work for Big Data Networks. Researches on community detection in large-scale networks are motivated by the situation that the traditional methods cannot handle the increasing size of networks. ADVNDS [
14] utilized modularity maximization and designed a heuristic method to solve it. The algorithm proposed in [
15] combined parallel processing techniques with binary trees to solve the efficiency problem. The algorithm proposed in [
16] extended it later using CPU-GPU modules. CDMEC [
17] introduced several functions to construct similarity matrices and integrated a stacked autoencoder and transfer learning to learn the embeddings of large-scale networks.
Related work on Attributed Networks. From the perspective of processing attribute information, existing algorithms can be classified into five categories [
18]. First, algorithms based on distance design a distance function to combine attribute topology information. SToC [
19] made use of the Jaccard index and Euclidean distance to measure the similarity of topology or attribute information, respectively. SA-cluster [
20] obtains the distance by applying a random walk on an augmented attribute graph, and Inc-cluster [
21] is a time-saving version of SA-cluster. Algorithms based on representation learning mainly focus on the process of learning the low-dimension vectors of nodes—that is, the embeddings. Community detection can be performed directly through clustering by embeddings. Potential information in the network can then be fully utilized by this method. MGAE [
22] proposes a marginal graph convolutional network and obtained deeper representations through multiple autoencoders. DANE [
23] employs two sub-processes to learn the attribute and topology representation. The final result is obtained by minimizing a designed negative log-likelihood. Evolutionary-algorithm-based methods measure the similarity of the topology and attribute information, and then transform the problem of community detection into a multi-objective optimization problem. BBO [
24] proposes Simatt to represent the similarity of node attributes. Similarly, MOEA-SA [
25] proposes SA to measure the attribute information. Nonnegative matrix factorization can also be used to obtain the representation of nodes. SCI [
10] proposes a non-negative matrix factorization model with two sets of parameters. SCD [
26] introduces an additional community relationship indicator matrix. The elements of the matrix describe the relationship between the corresponding communities. ASCD [
27] introduces the concept of a mismatch between attributes and structural information, and then related adaptive parameters were added to detect communities. Finally, probabilistic generative model-based algorithms focus primarily on obtaining a generative model of communities. They directly transform the complex network structure into a probability model determined by several parameters. CESNA [
28] models the interaction between a network structure and attributes to detect overlapping communities. The NEMBP [
29] model utilizes nesting EM algorithms and confidence propagation to detect the communities based on the correlation between topology and attribute.
Related work on Overlapping Community Detection. The recent overlapping community detection algorithms can be classified into five categories. First, algorithms based on multi-objective evolutionary approach the global optimal solutions by swarm evolution [
30,
31,
32]. MR-MOEA [
31] introduces a mixed representation that consists of all the potential overlapping vertices and all the non-overlapping vertices. They evolve together to detect communities. MOGA-OCD [
32] uses measures related to network connectivity to optimize two objectives: maximizing internal connectivity and minimizing external connectivity. Algorithms based on similarity partition vertices into communities according to their mutual similarity. OCDDP [
33] proposes a method based on density peaks. LED [
34] transforms the similarity into weights of the networks. Algorithms based on local expansion first select initial vertices and then expand them to obtain communities. [
35] optimizes the conductance community score to determine good seeds and then greedily expands them. [
36] aims to find the structural centers of communities. Algorithms based on random walk utilize the path of random walk to define the connectivity among individuals. MCLC [
37] employs a random walk on the edges and obtains “link communities” that are transformed into overlapping “node communities.” Finally, algorithms based on representation learning are similar to those based on attributed networks. Through underlying community membership, CDE [
38] formulates community detection as a non-negative matrix factorization model based on the encoded community structures and attributes.
It is still challenging to detect overlapping communities on attribute networks. As introduced above in related work, only CESNA [
28] and CDE [
38] can solve the problem. To solve the problem, an overlapping community detection algorithm based on attribute augmented graph, OCEA, is proposed. We employ fuzzy k-medoids [
39] on attribute augmented graph first proposed by [
20] to obtain the communities. Furthermore, the number of communities
k can be evaluated using the density of vertices. Through the evaluation, the automatic OCEA can detect overlapping communities without parameter
k and obtain comparable or even better results comparing to the baseline methods.
The remainder of this paper is organized as follows.
Section 2 introduces some preliminary information about the clustering problem and related definitions.
Section 3 discusses the details of OCEA and its automatic variant.
Section 4 presents empirical studies of the proposed algorithms. Finally, the conclusion and potential future work are reported in
Section 5.
3. Algorithms
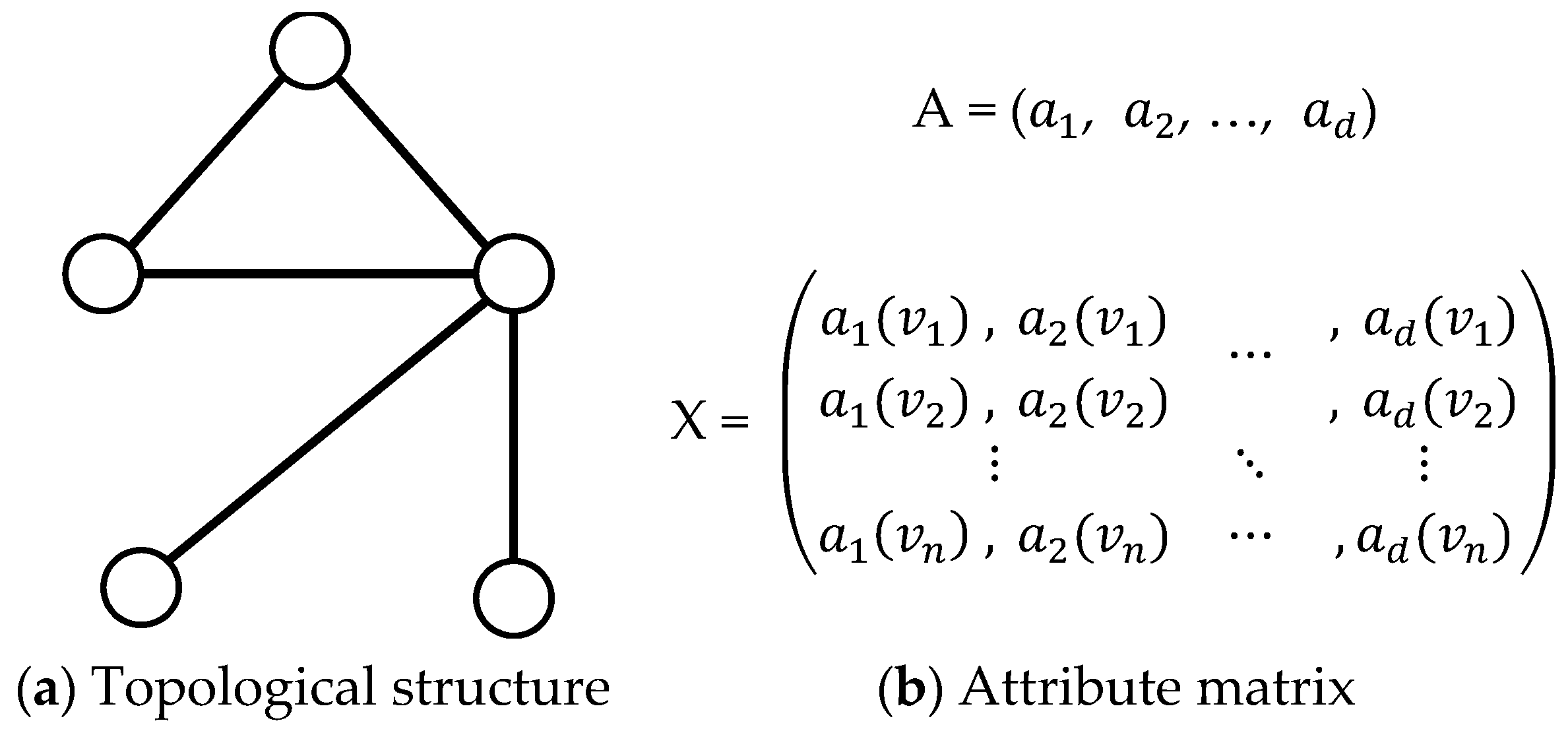
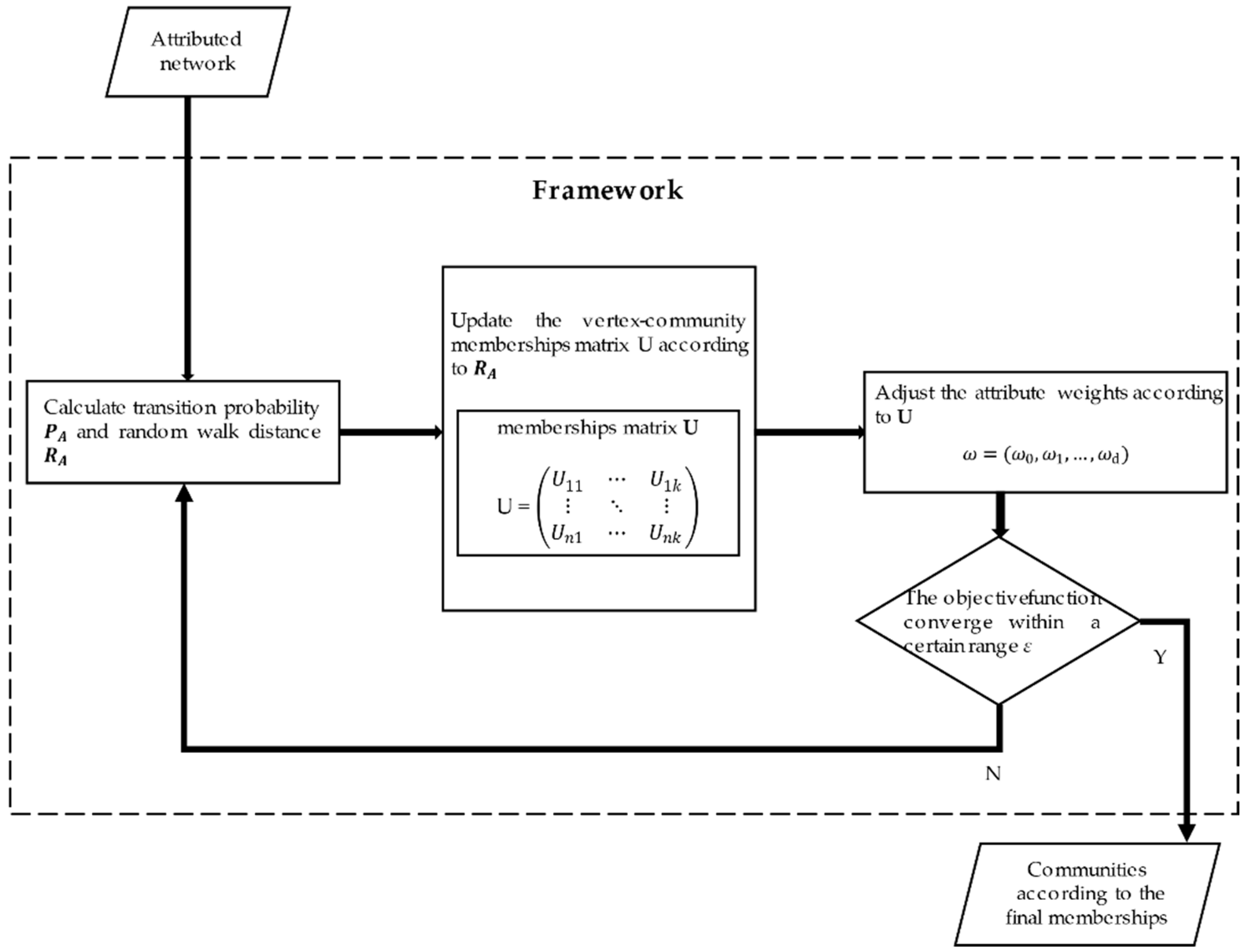
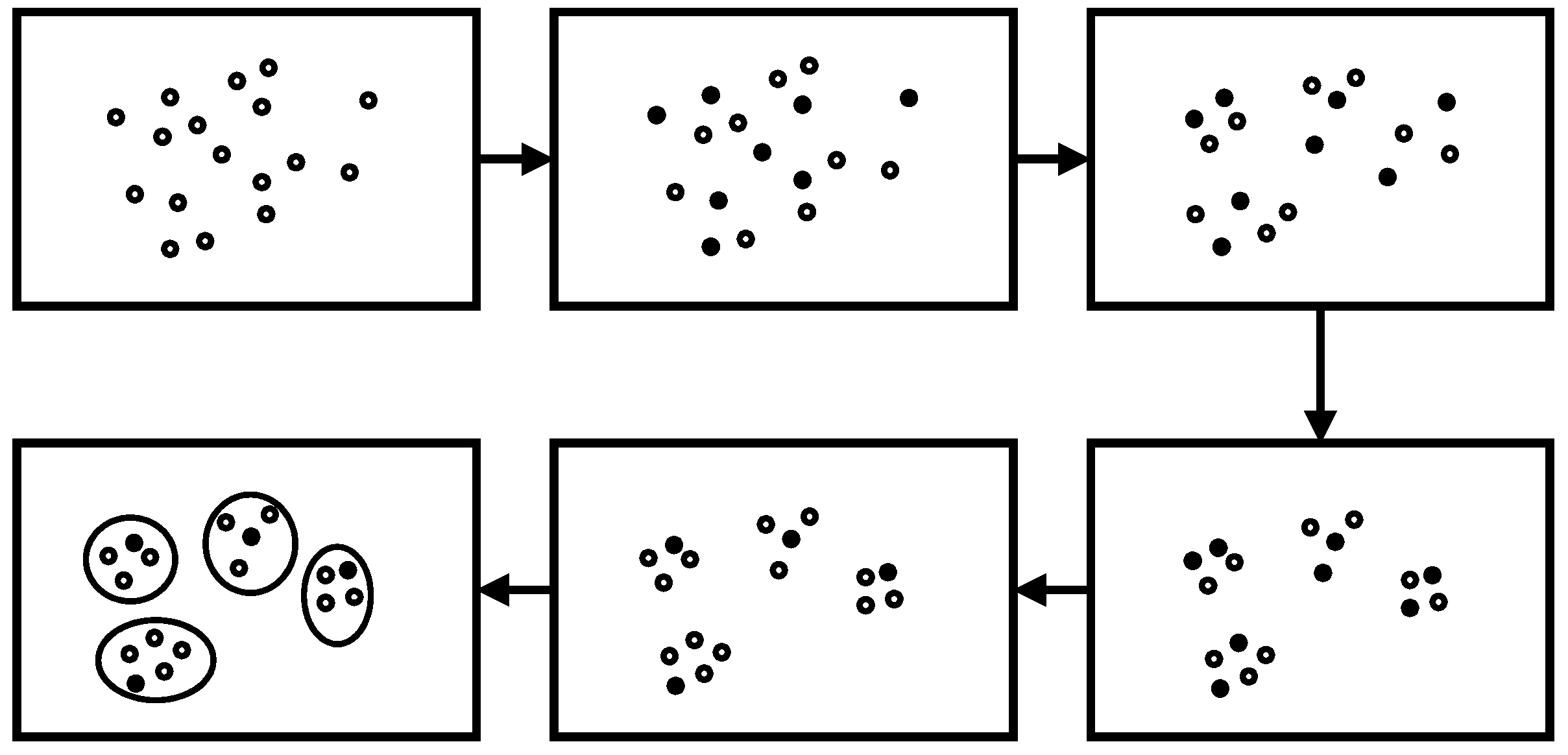
Here, we introduce the proposed OCEA based on augmented attribute graph and its extended version with an estimation of the number of communities. The framework of OCEA is shown as
Figure 3.
As shown in
Figure 3, OCEA is mainly composed of three steps. First, it calculates the transition probability matrix
and the random walk similarity matrix
. Second, the vertex-community membership matrix
U is updated according to
RA. Third, the structural weight
ω0 is fixed to 1, and the attribute weights
are updated according to matrix
U. The procedure is repeated until the objective function converges within a certain range
ε.
3.1. Overlapping Community Detection
Based on the framework of the augmented attribute graph, the OCEA utilizes fuzzy k-medoids [
39] to detect overlapping communities.
ith row of the random walk similarity matrix
RA is used as the vector of
vi that is denoted as
RA(
vi). Before the iteration of updating memberships,
k initial vertices are selected as the centers of each cluster.
Equations (6) and (7) show the process of updating memberships matrix
U and the vector
for centers in each cluster:
where
denotes the memberships of vertex
to cluster
j. Further,
is not the vector of an actual existing vertex that is regarded as the center of cluster
j. It denotes the average vector of all vertices in cluster
j. And
is used to update the memberships of all vertices in cluster
j. Thereafter, the center vertices of each cluster are selected as follows:
The main objective of the algorithm is to ensure the vertices are close to their corresponding cluster centers. To this end, the objective function is minimized by
where
cj denotes an actual existing vertex that is the center of cluster
j determined by Equation (8). It is different from
in Equation (7). The
m in Equation (7) and Equation (9) is a parameter and it will be set to 2 in experiments. The Euclidean distance is used to measure the similarity between vertices, after which the vertices are assigned to different communities according to their memberships to the communities.
3.2. Weights Adjustment
Each iteration of the update can obtain memberships. The weights of each attribute can be adjusted based on the currently detected communities. The equations of attribute weights adjustment are as follows:
Memberships can be observed as the influence of a vertex on a cluster. The high similarity of a certain attribute in a cluster implies that the attribute is an effective feature to detect communities. Subsequently, the weights of the corresponding attributes should be increased, or else they should be decreased.
3.3. Estimation on the Number of Communities
In the case of community detection without ground truth, we cannot obtain the number of communities k directly. Most algorithms need to input k as a hyperparameter or directly set k as a fixed value. Based on OCEA, the automatic version of it is proposed using a process for estimating the number of communities k. It will be called AOCEA for brevity in the following.
First, the density of vertex is defined by Equation (12):
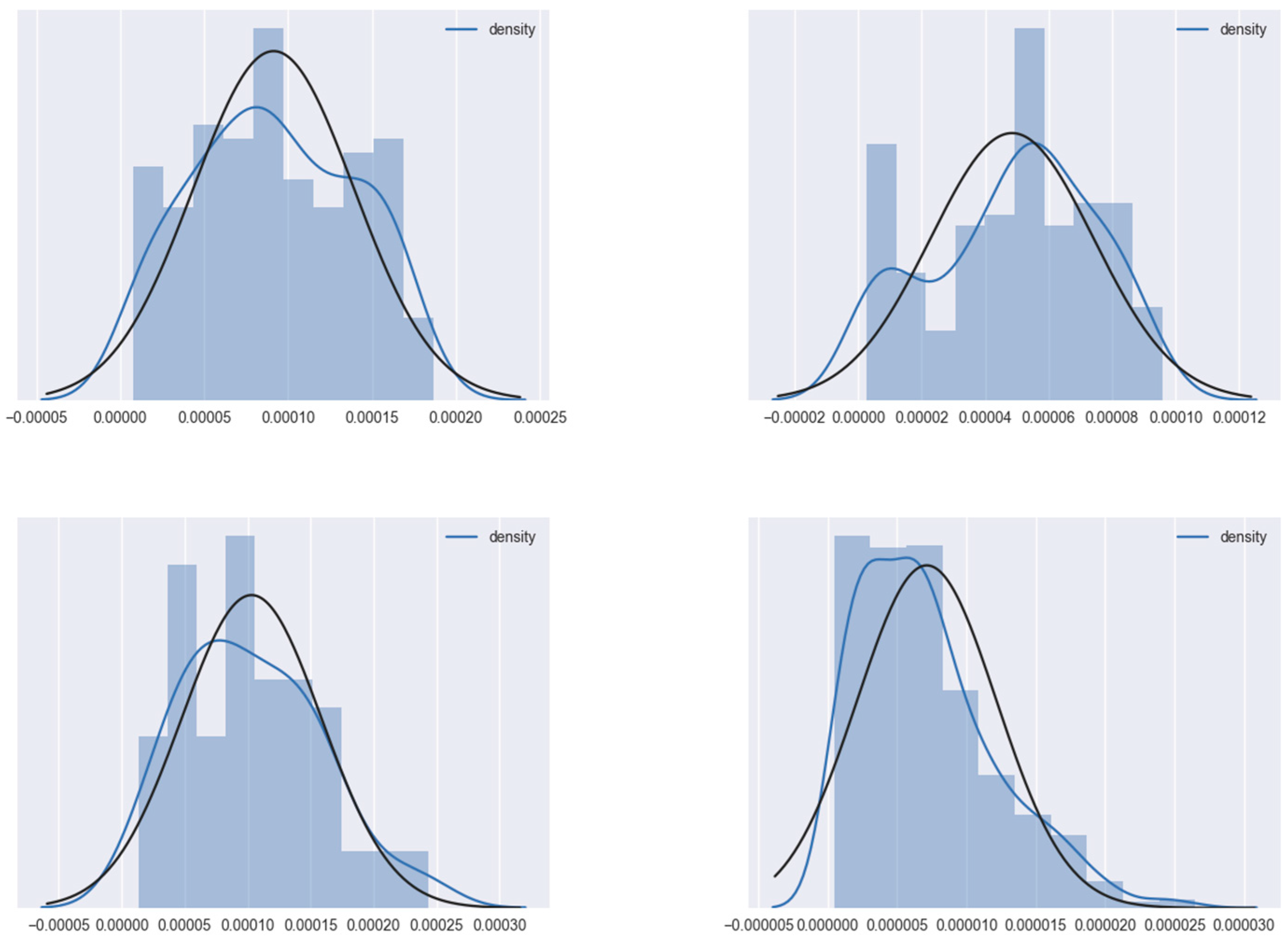
Taking out four egonetworks randomly from the Facebook egonetwork set introduced in
Section 4.1, we draw the histogram of the probability density distribution of each egonetwork’s vertex density value in
Figure 4. When calculating the density, the structural weight
is set to 1, and the attribute weights
are set to 1/
d. The stop probability
c is set to 0.5 to draw the curves.
The x-axis denotes the vertex density value and the y-axis denotes the number of vertices. Each blue curve denotes the probability distribution curve fitted to each histogram. Each black curve denotes the Gaussian distribution calculated according to the mean and standard deviation of each subnetwork’s vertex dense value, as shown in
Table 1.
As we can observe in
Figure 4, the fitted curves are very close to their corresponding calculated Gaussian distribution curves, which means that each sub-network’s vertex density value is nearly Gaussian distributed. It is assumed that centers should have higher density values than other vertices—higher density values imply a higher probability of being a center. Therefore, the sample mean of the density value is used as the threshold for selecting the candidate initial centers.
As shown in
Figure 5, the solid points denote the initial selected candidate centers based on the density value. In general, the number of initial centers was much larger than the number of real communities. Under the framework of OCEA, with the iterative update of centers and attribute weights using Equations (8) and (11), respectively, the
l step random walk probability changes and influences the similarity between vertices. In general, the vertices in the network gradually gather to several clusters in a distinct trend because of the adjustment of weights.
During the update of memberships, there may be several clusters that select the same vertex as their centers—that is, there may exist a vertex whose memberships to several clusters are all the highest in the current cluster. Only the vertices with the highest memberships are preserved as centers. This implies that parts of the candidate centers will be eliminated. As shown in
Figure 5, parts of the solid points are transformed into hollow points, which implies that the solid points are no longer regarded as centers. After the elimination of centers, the number of remaining centers can be observed as an approximation of the number of communities. Function 1 summaries the process of cluster number estimation.
| Function 1. ClusterNumberEstimation. |
| Input: Attribute Augmented Graph GA(V, E, A, X), random walk length l, stop probability c, number of epochs T |
| Output: Number of Communities k |
- 1:
Initialize weights ω0 = ω1 = … = ωd = 0, dS = 0 - 2:
for vertices vi ∈ V do - 3:
Compute density D(vi) by Equation (12) - 4:
dS = dS + D(vi) - 5:
end for - 6:
dT = dS/n - 7:
Initialize centers VD ← {vi|D(vi) ≥ dT, vi ∈ V} - 8:
Lk = |VD| - 9:
fori = 1, …, T do - 10:
for vertices vi ∈ V do - 11:
Update memberships Uij and Xc by Equations (6) and (7) - 12:
end for - 13:
for m = 1, …, d do - 14:
Update weights of attributes ωm by Equation (11) - 15:
end for - 16:
Compute RA by Equation (5) - 17:
end for - 18:
forj = 1, …, Lk do - 19:
VC ← argmaxvi(Uij) - 20:
end for - 21:
k = |VC| - 22:
returnk
|
3.4. OCEA and AOCEA
As introduced in the previous sections, the update of memberships and the adjustment of weights are the main processes of OCEA, as shown in Algorithm 1.
It initializes weights, the random walk similarity, and centers first (lines 1–3). Then, the memberships, centers, and weights of attributes are updated iteratively until the convergence of the objective function in a certain range (lines 4–17). Detected communities are obtained using memberships (lines 18–23).
| Algorithm 1 OCEA |
| Input: Attribute Augmented Graph GA(V, E, A, X), random walk length l, stop probability c, convergence parameter ε, overlapping parameter γ, number of communities k |
| Output: Communities C1, …, Ck |
- 1:
Initialize weights ω0 = ω1 = … = ωd = 1 - 2:
Compute initial RA by Equation (5) - 3:
Select the initial centers VC - 4:
whilemar > ε do - 5:
for vertices vi ∈ V do - 6:
for j = 1, …, k do - 7:
Update memberships Uij by Equation (6) - 8:
Update centers Xc by Equation (7) - 9:
end for - 10:
end for - 11:
for m = 1, …, d do - 12:
Update weights of attributes ωm by Equation (11) - 13:
end for - 14:
Compute RA by Equation (5) - 15:
Compute objective function Ft - 16:
mar = |Ft − Ft−1| - 17:
Ft−1 = Ft - 18:
end while - 19:
for vertices vi ∈ V do - 20:
μimax = max({Uij|j = 1, …, k}) - 21:
for j = 1, …, k do - 22:
Cj ← {vi|Uij ≥ γ × μimax} - 23:
end for - 24:
end for - 25:
return C1, …, Ck
|
As shown in Algorithm 2. AOCEA first utilizes the function
ClusterNumberEstimation to obtain an estimated number of communities
k. Then, this estimated
k is regarded as the input of the OCEA to detect the overlapping communities.
| Algorithm 2 AOCEA |
| Input: Attribute Augmented Graph GA(V, E, A, F), random walk length l, stop probability c, convergence parameter ε, overlapping parameter γ |
| Output: Community C1, …, Ck |
- 1:
Initialize k = ClusterNumberEstimation (GA, l, c, T) - 2:
return OCEA (GA, l, c, ε, γ, k)
|
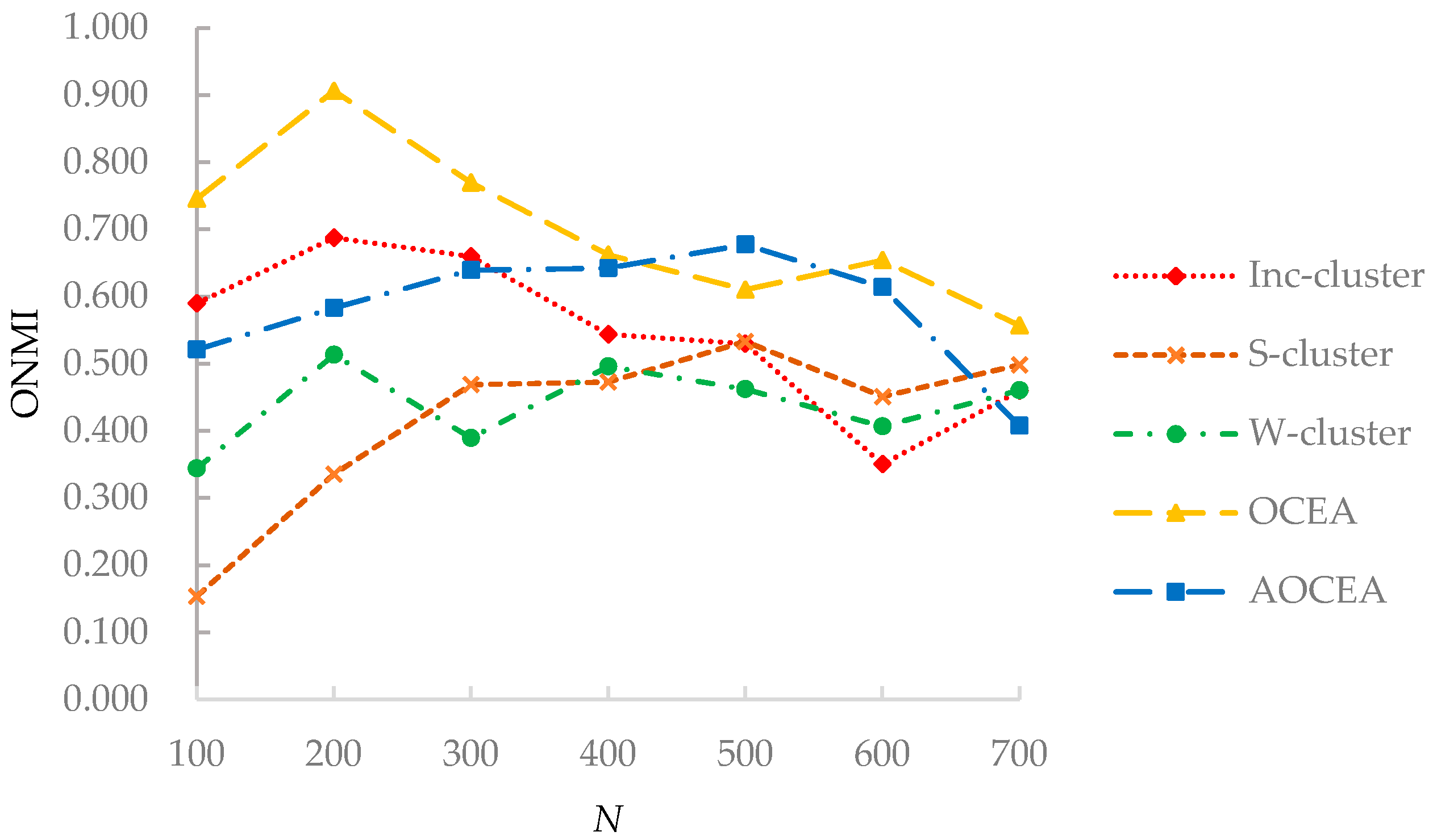
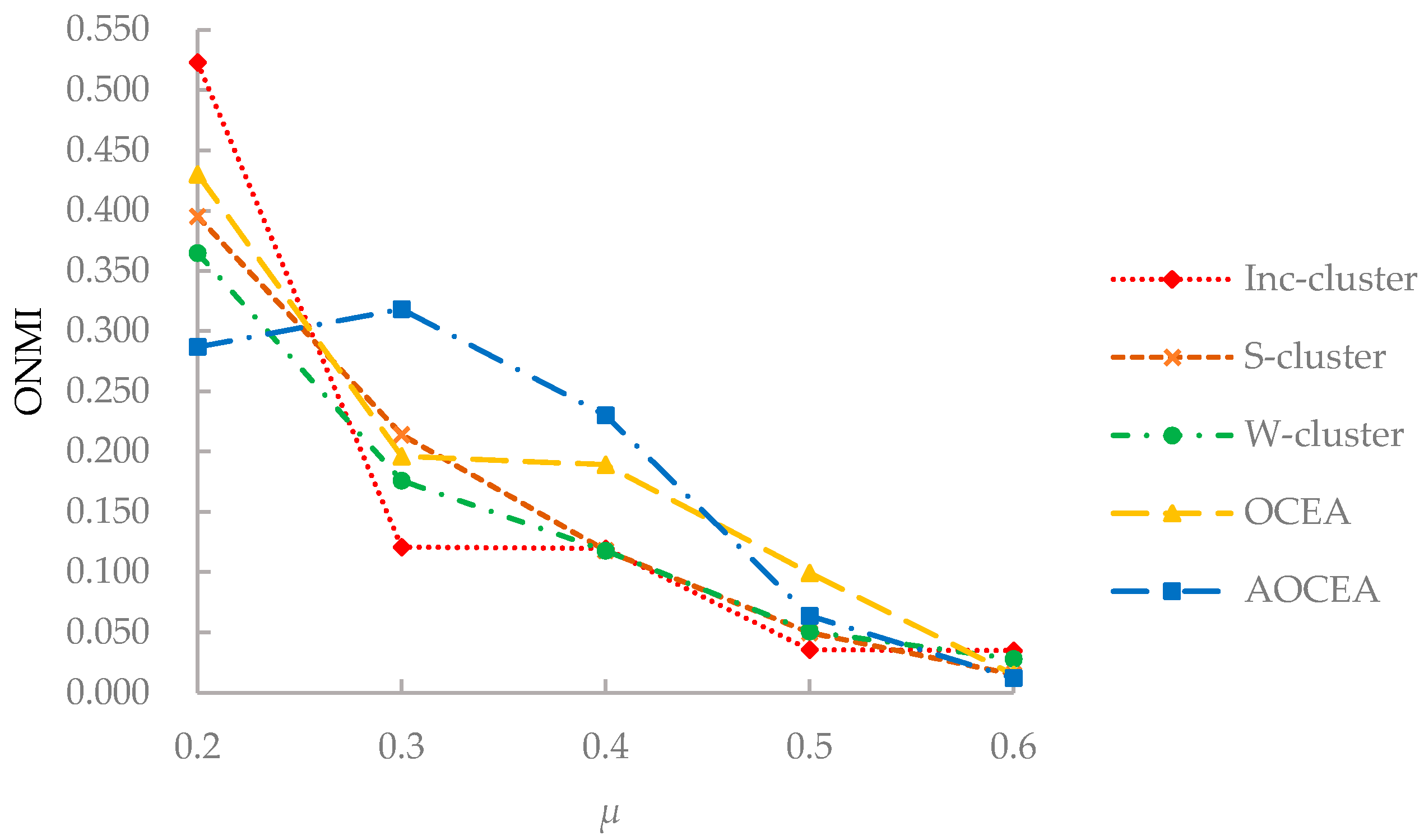
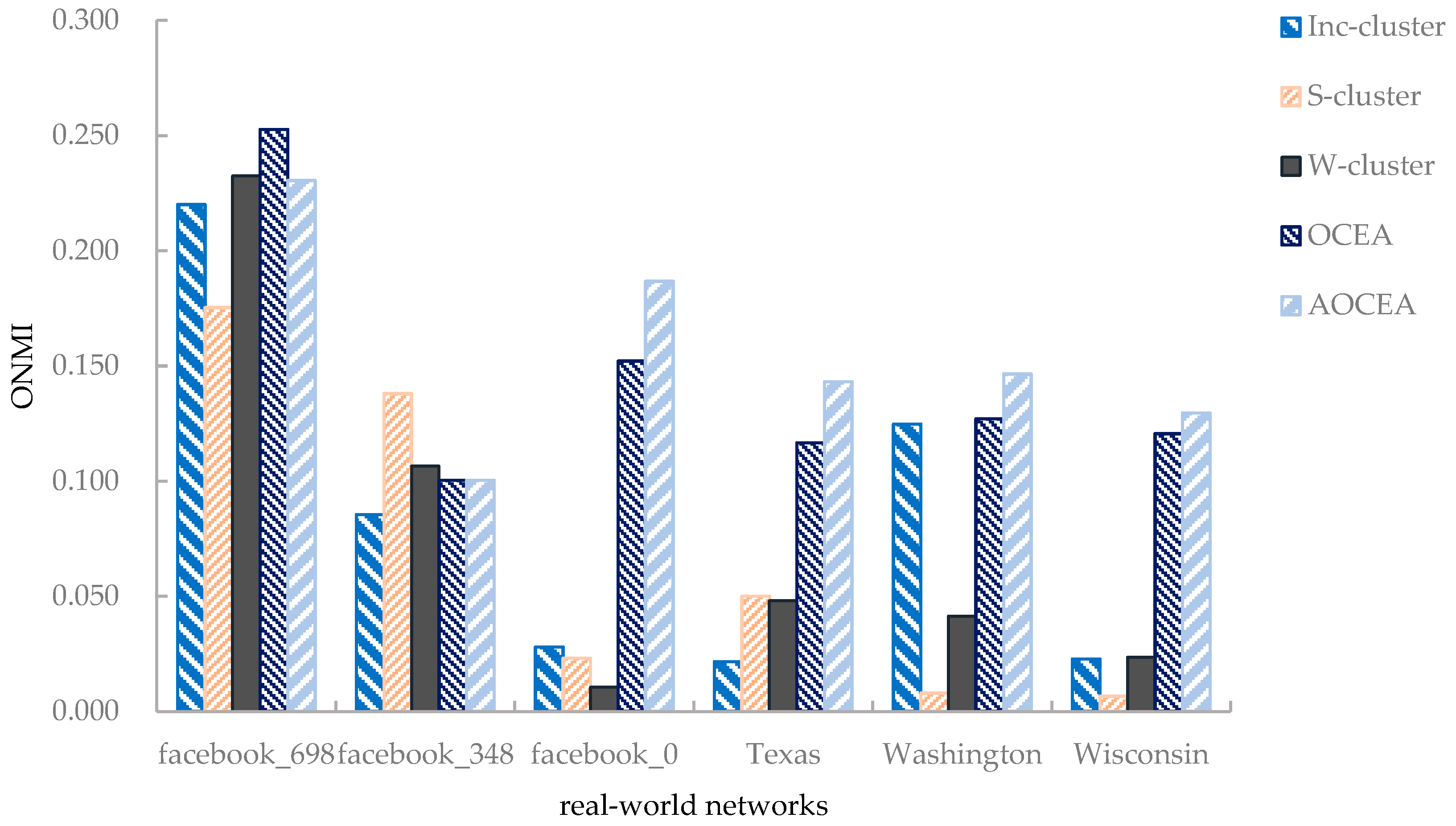
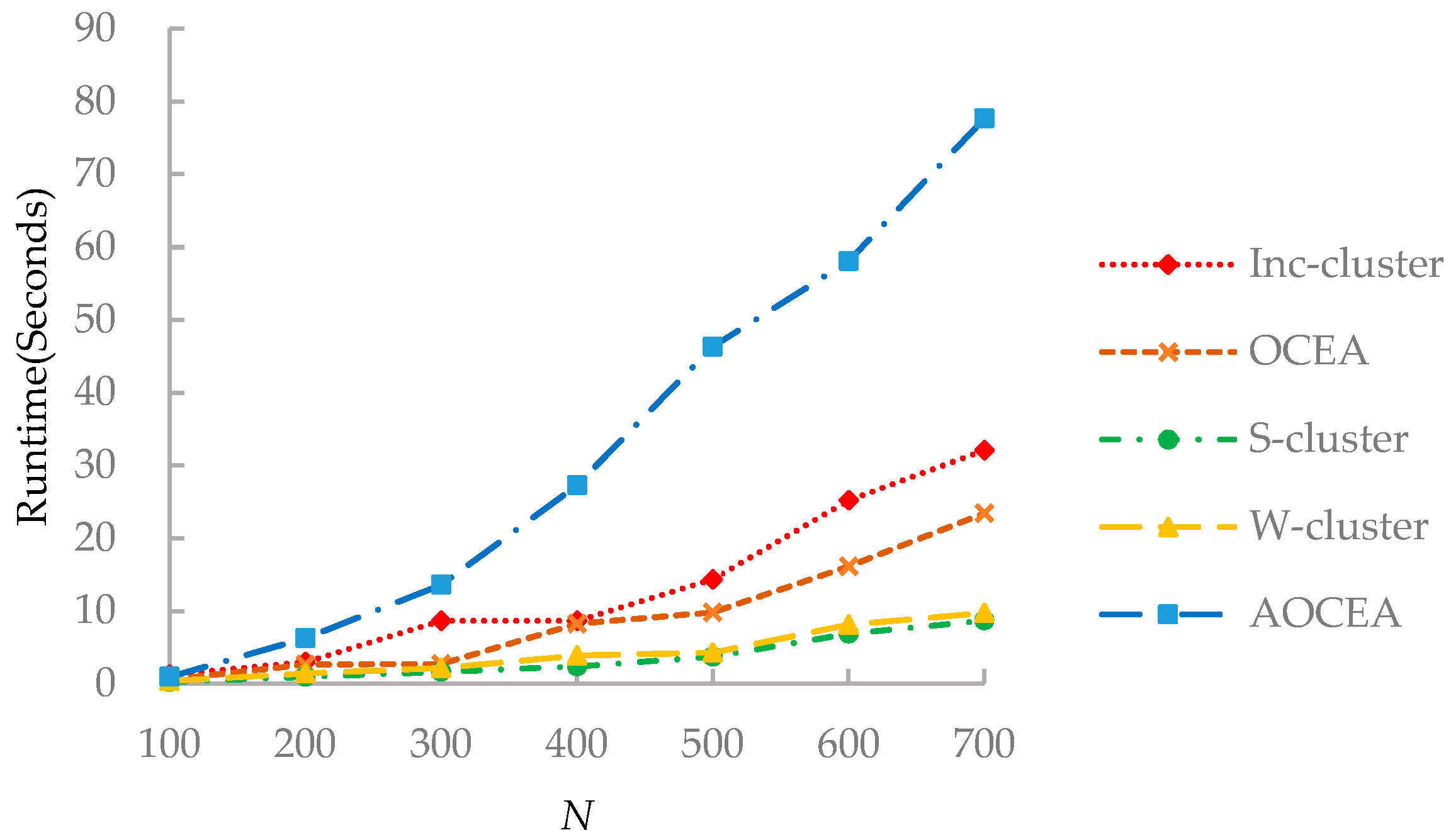
The time complexity of computing the transition probability is . Here, denotes the set of edges in an attribute augmented graph that consists of two parts. The edges in an attribute augmented graph composed of two parts. One includes the original edges in the topological graph, the other includes the added edges according to the attribute information. Let be the numbers of nonzero entries in transition probability matrix P and n be the number of vertices. Since P is a sparse matrix, the time complexity of the matrix multiplication is . Weight adjustment requires O(nk) time. Here, k is the true number of communities. Thus, the overall complexity of OCEA and AOCEA is , which can be reduced to O(n) because k << n. AOCEA has an extra procedure of estimating the number of communities, and its initial estimation of the number of communities is roughly equal to n/2. Therefore, the time complexity of weights adjustment in AOCEA is and gradually reduces to , where is the final estimation of the number of communities.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}