


Ensuring Explainability and Dimensionality Reduction in a Multidimensional HSI World for Early XAI-Diagnostics of Plant Stress

Abstract
:1. Introduction
1.1. HSI as Multidimensional World
1.2. HSI and AI in Agriculture
1.3. Notions of XAI and Explainability in AI
- Explanation: Systems deliver accompanying evidence or reason(s) for all outputs.
- Meaningful: Systems provide explanations that are understandable to individual users.
- Explanation Accuracy: The explanation correctly reflects the system’s process for generating the output.
- Knowledge Limits: The system only operates under conditions for which it was designed or when the system reaches sufficient confidence in its output.
1.4. Theory and Practice of Feature-Space Dimensionality Reduction in AI-HSI Applications
2. Materials and Methods
2.1. Materials
2.2. Construction of XAI Early Diagnostics Network on the Input Explanators Having Only High-Dimentional I Data as the Source
2.3. Building a Plant Mask for Automation of HSI Markup and Tools for Correlation and Regression Research Based on It
- (1)
- A plants’ mask managed by a threshold (thr), which separates plant from soil, was constructed. For this goal the vegetation index NDblue (1) [1] was used. The condition of belonging to the plants’ mask is NDblue ≥ thr.
- (2)
- A special tool with interface (Figure 4) for the plants’ masks setting has been implemented. This tool removes from the mask those points of the point cloud (PC) that have deviated from the linear regression by more than a up or b down. This can provide both homoscedasticity of the regression and control over the size of the standard error of the regression. Parameters a and b can vary independently, but the study used only the symmetrical variant a = b.
2.4. Dimensionality Reduction and Building of the XAI System Based on HSI-Input-Data as the Source of High-Level Features
3. Results and Their Discussion
3.1. HSI-Input-Data Dimensionality Reduction via Searching Channels That Can Be Consided as High-Level Features
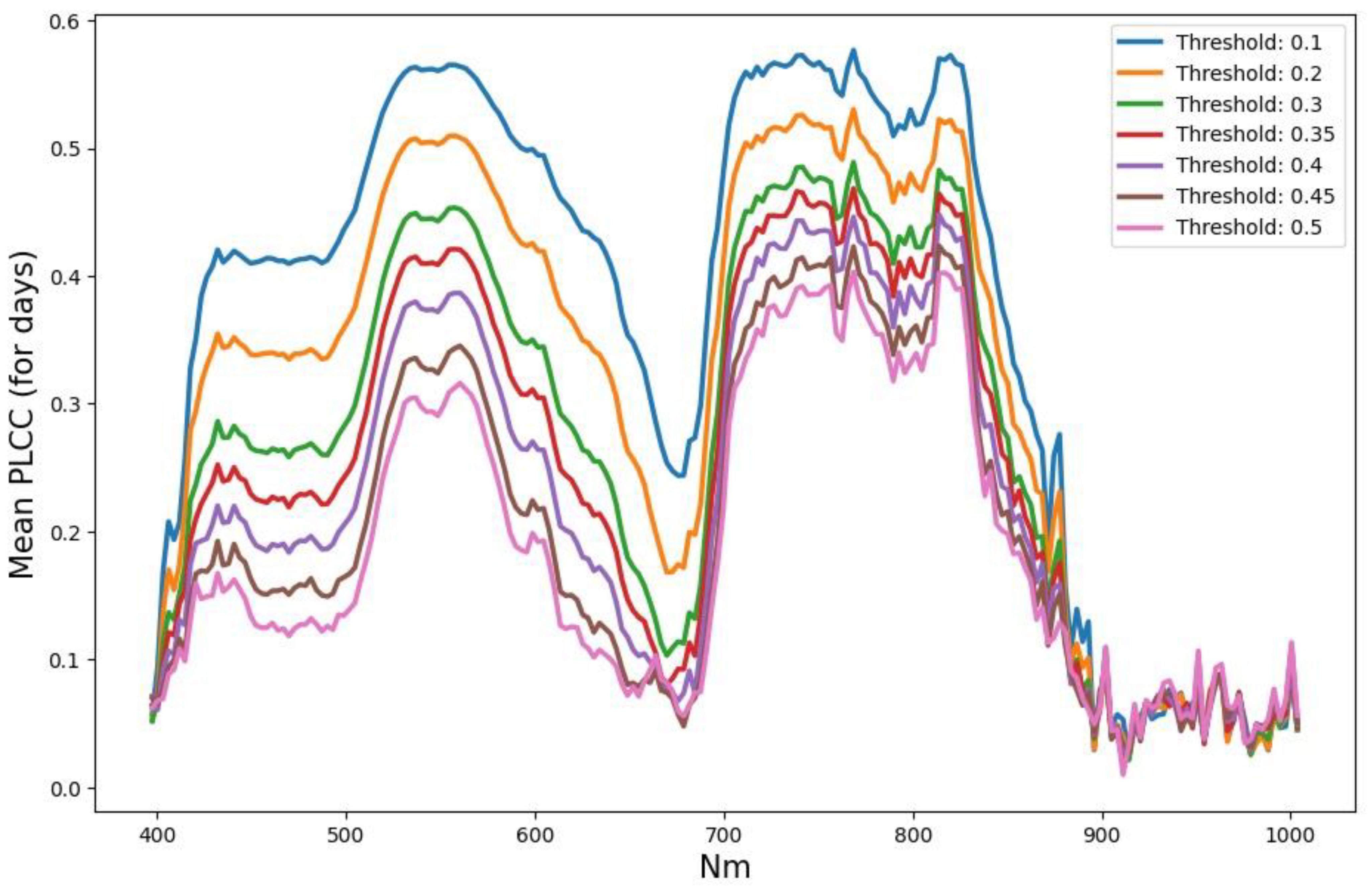
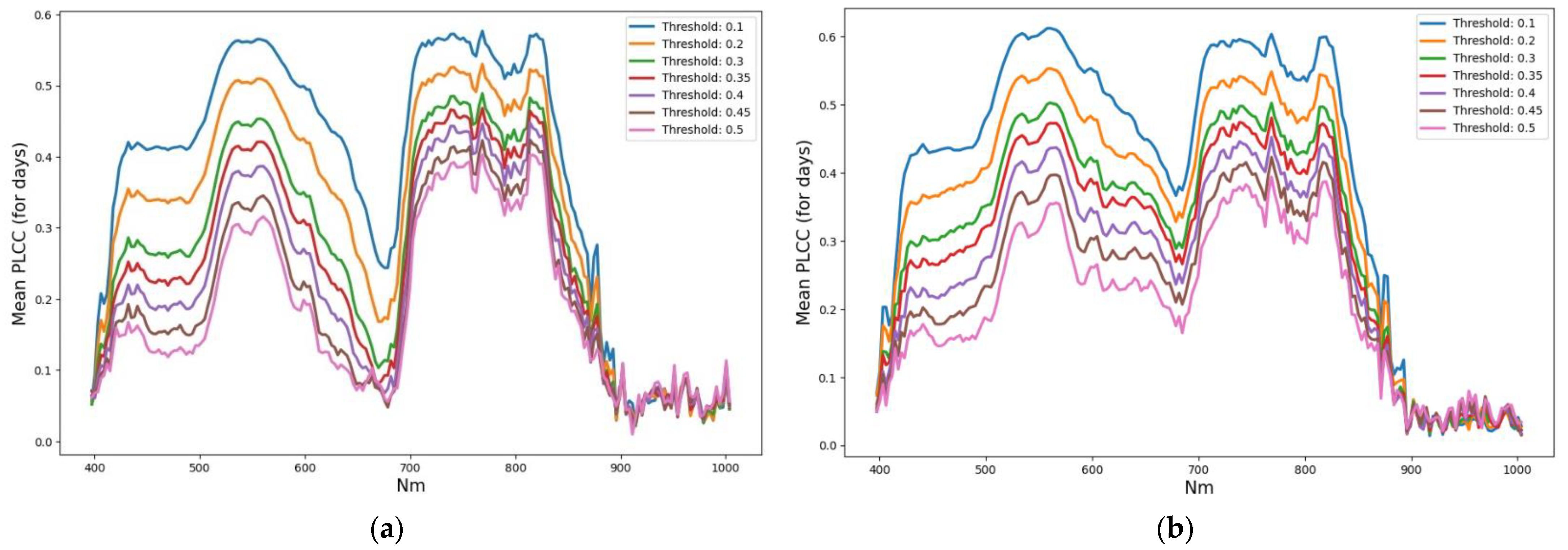
- (1)
- The leaders in correlation with TIR in terms of the average PLCC when thr changes are the channels of the NIR range (112–144 channels), followed by visible green channels. Channel 143 was identified as the leader.
- (2)
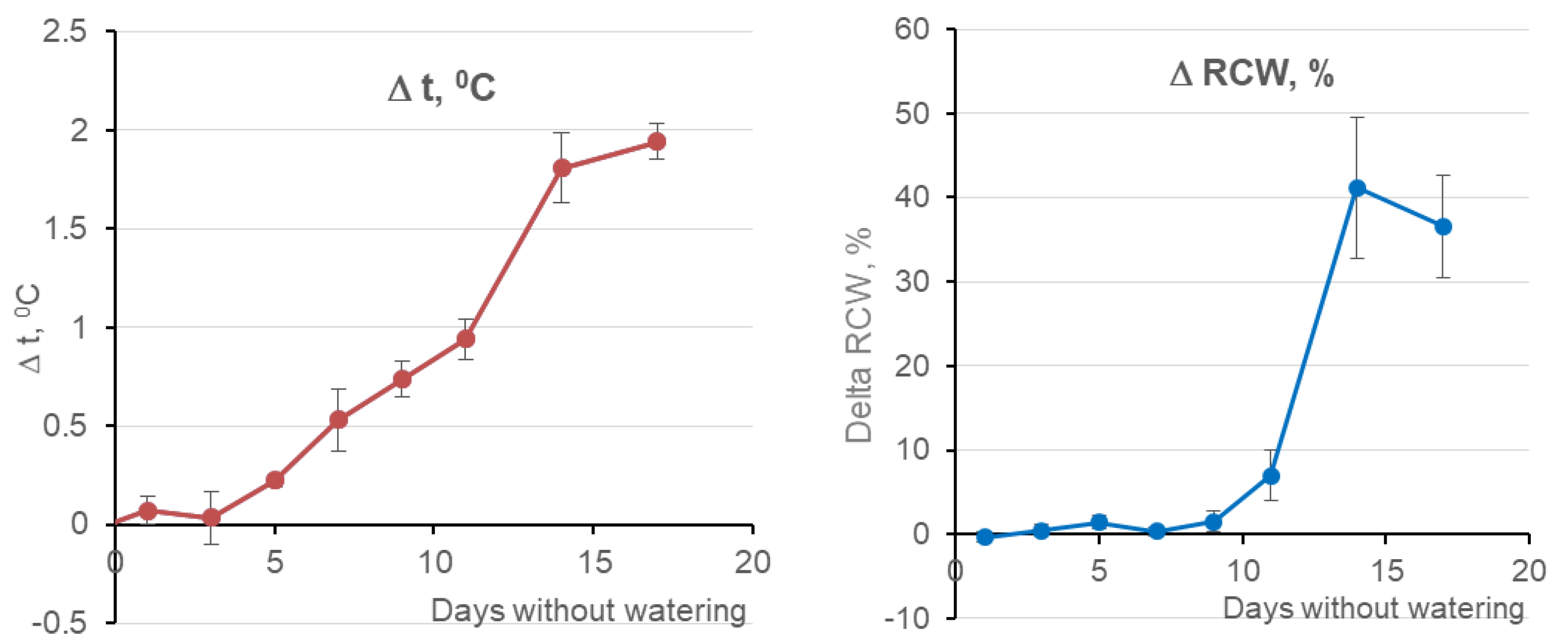
- During variations of the thr value from 0.1 to 0.5, the area of the plant mask decreases approximately linearly, by a factor of two–four depending on the key day. The area of the plants’ mask reaches a maximum of 2823 pix (near 7/8 of the image) and a minimum of the variation (less than two times) on day 12.
- (3)
- Each step increasing the threshold (thr) actually removes pixels with reduced soil content from the original mask. The value thr = 0.45 eliminates almost all mixed pixels, and thr = 0.5 guarantees that the pixel belongs to the inner part of the sheet.
- (4)
- The PLCC value on each day is maximum at thr = 0.1 and decreases monotonically by 1.5–3 times with an increase in thr, and by day the PLCC maximum is on the first day of the experiment (0.75 for channel 143).
- (5)
- According to Table A2 and Table 3, the usefulness of reducing the parameters a,b at high threshold values (thr = 0.4 or 0.5) is sharply reduced, as it leads to mask depletion. As a result, the accuracy of the forecast increases, and outside the truncated mask it even deteriorates slightly. For these thresholds, values of a,b closer to 0.5 should be recommended.
3.2. The Problem of Training HSI by Plant’s Temperatures from TIR-Values Using the Built XAI Neural Network and Reducing the Dimension of the Feature Space
- (1)
- All best results are near the TIR resolution of 0.1 °C and took place at a = b = 0.1 regardless of thr value. The worst RMSE values are near 0.2 °C at a,b equals 1 and 0.5.
- (2)
- The RMSE value is highly dependent on a, b and hence the area of the mask. Reducing the mask by about half improves the RMSE value by about two times.
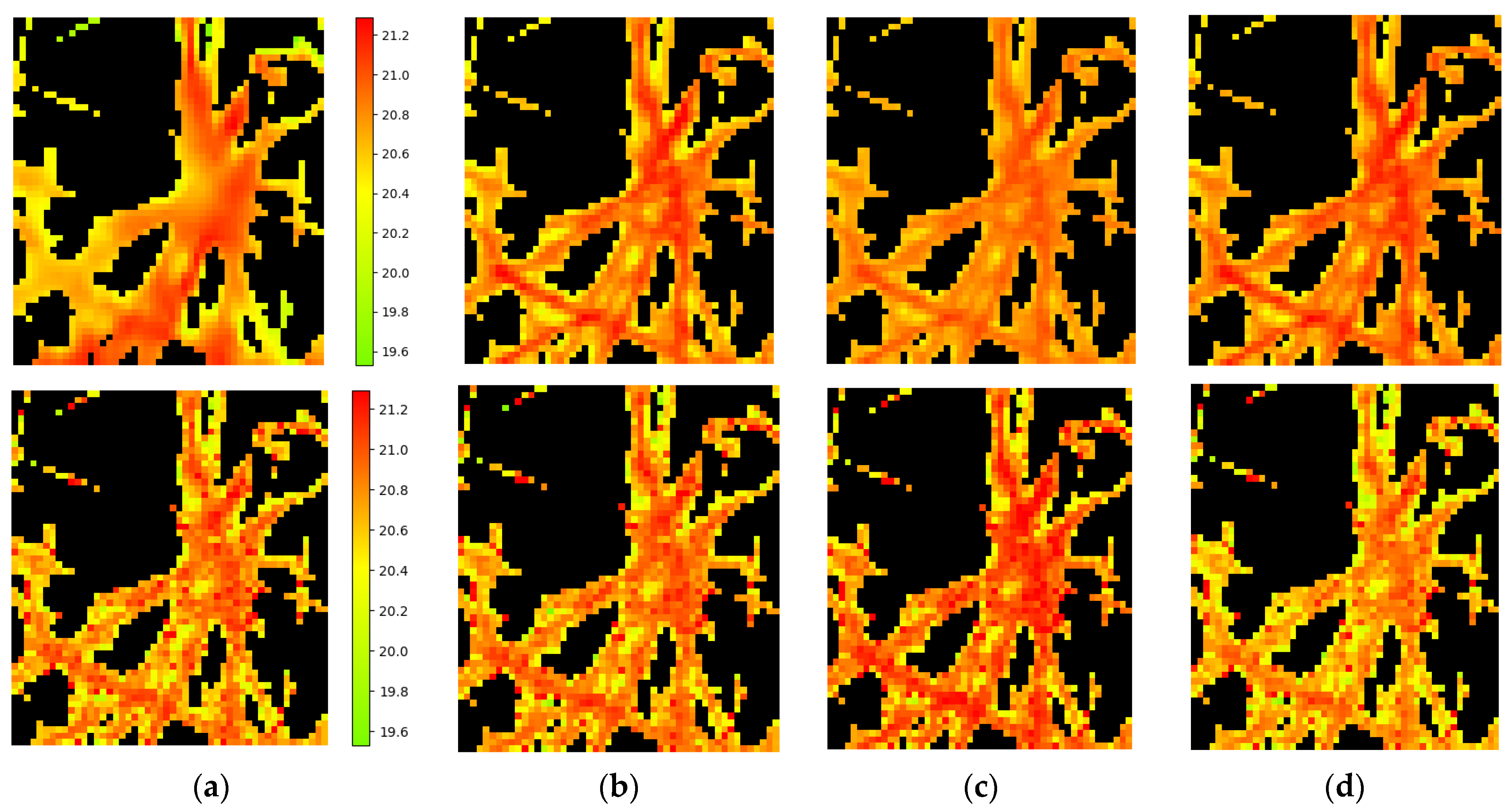
- Row 1—(a) the linear interpolated TIR image; approximation by Formula (3) for cases Table 3: (b) thr = 0.4; a,b = 1; RMSE = 0.1; (c) thr = 0.4; a,b = 0.1; and ‘RMSE out’ = 0.3; (d) thr = 0.5; a,b = 1; and RMSE = 0.21; and RMSE = 0.1 °C; (4) approximation by Formula (3) with a,b = 0.1 and also RMSE = 0.1 °C, but for ‘Mask in’, which is truncated to 794 pix from the full Mask = 1954 pix (see Table 3, Table A1 and Table A2). The real value of ‘RMSE out’ in this case equals 0.3 °C).
- Row 2 (for Table 5, 8 **, 7 ** which have very close RMSE)—(a)) the result of training our R-XAI block on k channels using the plants’ masks with parameters k = 8, thr = 0.4, a,b = 0.5; (b) the same for thr = 0.5; (c,d) are the same as previes two but for parameter k = 7. It can be seen that results for 7 ** and 8 ** are more noisy than in Row 1. This may be due to the use of data from different key days in the one common training process.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Day | Threshold | Mask, pix | PLCC | RMSE, °C | TIR Max | TIR Min | TIR Mean | TIR Std | Chan. Max | Chan. Min | Chan. Mean | Chan. Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.1 | 2534 | 0.75 | 0.21 | 21.5 | 20.2 | 20.8 | 0.23 | 1.37 | 0.05 | 0.53 | 0.29 |
| 1 | 0.2 | 2159 | 0.70 | 0.19 | 21.5 | 20.3 | 20.9 | 0.21 | 1.37 | 0.05 | 0.59 | 0.27 |
| 1 | 0.3 | 1702 | 0.63 | 0.19 | 21.5 | 20.4 | 20.9 | 0.19 | 1.37 | 0.16 | 0.67 | 0.24 |
| 1 | 0.4 | 1274 | 0.60 | 0.18 | 21.5 | 20.5 | 21.0 | 0.18 | 1.37 | 0.21 | 0.74 | 0.21 |
| 1 | 0.5 | 867 | 0.56 | 0.17 | 21.5 | 20.5 | 21.0 | 0.16 | 1.37 | 0.32 | 0.82 | 0.19 |
| 3 | 0.1 | 2744 | 0.52 | 0.28 | 21.5 | 20.1 | 20.9 | 0.23 | 1.42 | 0.05 | 0.49 | 0.30 |
| 3 | 0.2 | 2156 | 0.41 | 0.28 | 21.5 | 20.1 | 20.9 | 0.21 | 1.42 | 0.05 | 0.58 | 0.27 |
| 3 | 0.3 | 1643 | 0.29 | 0.29 | 21.5 | 20.1 | 21.0 | 0.19 | 1.42 | 0.16 | 0.67 | 0.24 |
| 3 | 0.4 | 1134 | 0.18 | 0.29 | 21.5 | 20.3 | 21.0 | 0.18 | 1.42 | 0.26 | 0.77 | 0.21 |
| 3 | 0.5 | 700 | 0.17 | 0.26 | 21.5 | 20.5 | 21.0 | 0.16 | 1.42 | 0.42 | 0.86 | 0.19 |
| 6 | 0.1 | 2411 | 0.52 | 0.32 | 21.6 | 20.1 | 20.9 | 0.24 | 1.30 | 0.04 | 0.57 | 0.28 |
| 6 | 0.2 | 2024 | 0.45 | 0.33 | 21.6 | 20.1 | 20.9 | 0.23 | 1.30 | 0.07 | 0.64 | 0.25 |
| 6 | 0.3 | 1633 | 0.40 | 0.32 | 21.6 | 20.1 | 20.9 | 0.21 | 1.30 | 0.11 | 0.71 | 0.22 |
| 6 | 0.4 | 1232 | 0.35 | 0.31 | 21.6 | 20.3 | 21.0 | 0.21 | 1.30 | 0.22 | 0.77 | 0.20 |
| 6 | 0.5 | 824 | 0.26 | 0.32 | 21.6 | 20.3 | 21.0 | 0.20 | 1.30 | 0.33 | 0.85 | 0.17 |
| 8 | 0.1 | 2492 | 0.68 | 0.30 | 20.9 | 19.1 | 20.1 | 0.30 | 1.37 | 0.04 | 0.62 | 0.28 |
| 8 | 0.2 | 2114 | 0.63 | 0.29 | 20.9 | 19.3 | 20.1 | 0.27 | 1.37 | 0.12 | 0.69 | 0.24 |
| 8 | 0.3 | 1761 | 0.59 | 0.28 | 20.9 | 19.4 | 20.2 | 0.25 | 1.37 | 0.19 | 0.75 | 0.21 |
| 8 | 0.4 | 1376 | 0.57 | 0.26 | 20.9 | 19.5 | 20.2 | 0.24 | 1.37 | 0.31 | 0.81 | 0.19 |
| 8 | 0.5 | 952 | 0.49 | 0.26 | 20.9 | 19.7 | 20.3 | 0.20 | 1.37 | 0.38 | 0.88 | 0.16 |
| 12 | 0.1 | 2823 | 0.65 | 0.30 | 21.4 | 19.6 | 20.6 | 0.30 | 1.42 | 0.08 | 0.70 | 0.28 |
| 12 | 0.2 | 2626 | 0.61 | 0.28 | 21.4 | 19.8 | 20.7 | 0.27 | 1.42 | 0.12 | 0.73 | 0.25 |
| 12 | 0.3 | 2359 | 0.57 | 0.26 | 21.4 | 19.9 | 20.7 | 0.25 | 1.42 | 0.20 | 0.77 | 0.22 |
| 12 | 0.4 | 1954 | 0.52 | 0.24 | 21.4 | 20.1 | 20.8 | 0.21 | 1.42 | 0.20 | 0.83 | 0.19 |
| 12 | 0.5 | 1495 | 0.47 | 0.21 | 21.3 | 20.2 | 20.8 | 0.19 | 1.42 | 0.40 | 0.89 | 0.17 |
| 19 | 0.1 | 2367 | −0.54 | 0.33 | 22.2 | 21.2 | 21.7 | 0.22 | 1.59 | 0.09 | 0.65 | 0.30 |
| 19 | 0.2 | 1940 | −0.49 | 0.31 | 22.2 | 21.2 | 21.6 | 0.21 | 1.59 | 0.23 | 0.73 | 0.27 |
| 19 | 0.3 | 1546 | −0.49 | 0.30 | 22.2 | 21.2 | 21.6 | 0.20 | 1.59 | 0.32 | 0.81 | 0.25 |
| 19 | 0.4 | 1124 | −0.43 | 0.27 | 22.2 | 21.2 | 21.6 | 0.18 | 1.59 | 0.41 | 0.91 | 0.22 |
| 19 | 0.5 | 768 | −0.37 | 0.25 | 22.0 | 21.2 | 21.5 | 0.16 | 1.59 | 0.59 | 1.00 | 0.19 |
| 25 | 0.1 | 2289 | −0.54 | 0.35 | 22.6 | 21.2 | 22.0 | 0.22 | 1.94 | 0.17 | 0.89 | 0.34 |
| 25 | 0.2 | 1842 | −0.50 | 0.34 | 22.5 | 21.2 | 22.0 | 0.22 | 1.94 | 0.28 | 0.99 | 0.30 |
| 25 | 0.3 | 1423 | −0.48 | 0.33 | 22.5 | 21.2 | 21.9 | 0.22 | 1.94 | 0.39 | 1.08 | 0.26 |
| 25 | 0.4 | 974 | −0.42 | 0.32 | 22.4 | 21.2 | 21.9 | 0.21 | 1.94 | 0.50 | 1.19 | 0.23 |
| 25 | 0.5 | 588 | −0.38 | 0.33 | 22.4 | 21.2 | 21.8 | 0.22 | 1.94 | 0.72 | 1.30 | 0.20 |
| Day | Threshold | PLCC a,b = 1 | RMSE a,b = 1, °C | a = b | Mask in, pix | PLCC in | RMSE in, °C | RMSE out, °C | TIR in Max | TIR in Min | TIR in Mean | TIR in Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.1 | 0.75 | 0.21 | 0.1 | 1243 | 0.95 | 0.14 | 0.26 | 21.38 | 20.45 | 20.82 | 0.17 |
| 1 | 0.2 | 0.70 | 0.19 | 0.1 | 1110 | 0.93 | 0.09 | 0.26 | 21.25 | 20.49 | 20.85 | 0.15 |
| 1 | 0.3 | 0.63 | 0.19 | 0.1 | 888 | 0.9 | 0.08 | 0.26 | 21.25 | 20.58 | 20.90 | 0.13 |
| 1 | 0.4 | 0.60 | 0.18 | 0.08 | 556 | 0.91 | 0.06 | 0.23 | 21.25 | 20.65 | 20.95 | 0.11 |
| 1 | 0.5 | 0.56 | 0.17 | 0.06 | 316 | 0.92 | 0.05 | 0.2 | 21.23 | 20.77 | 20.99 | 0.09 |
| 3 | 0.1 | 0.52 | 0.28 | 0.1 | 1207 | 0.92 | 0.19 | 0.35 | 21.50 | 20.07 | 20.87 | 0.23 |
| 3 | 0.2 | 0.41 | 0.28 | 0.08 | 735 | 0.9 | 0.2 | 0.32 | 21.50 | 20.10 | 20.92 | 0.21 |
| 3 | 0.3 | 0.29 | 0.29 | 0.06 | 447 | 0.82 | 0.2 | 0.32 | 21.50 | 20.10 | 20.96 | 0.19 |
| 3 | 0.4 | 0.18 | 0.29 | 0.05 | 284 | 0.64 | 0.2 | 0.32 | 21.50 | 20.31 | 21.00 | 0.18 |
| 3 | 0.5 | 0.17 | 0.26 | 0.04 | 141 | 0.63 | 0.17 | 0.29 | 21.49 | 20.52 | 21.04 | 0.16 |
| 6 | 0.1 | 0.52 | 0.32 | 0.08 | 730 | 0.94 | 0.16 | 0.36 | 21.23 | 20.58 | 20.88 | 0.13 |
| 6 | 0.2 | 0.45 | 0.33 | 0.07 | 578 | 0.93 | 0.17 | 0.37 | 21.18 | 20.62 | 20.91 | 0.11 |
| 6 | 0.3 | 0.40 | 0.32 | 0.05 | 353 | 0.95 | 0.17 | 0.35 | 21.18 | 20.73 | 20.94 | 0.09 |
| 6 | 0.4 | 0.35 | 0.31 | 0.05 | 255 | 0.95 | 0.17 | 0.34 | 21.18 | 20.77 | 20.99 | 0.08 |
| 6 | 0.5 | 0.26 | 0.32 | 0.04 | 166 | 0.9 | 0.17 | 0.34 | 21.18 | 20.89 | 21.03 | 0.05 |
| 8 | 0.1 | 0.68 | 0.30 | 0.1 | 887 | 0.96 | 0.15 | 0.36 | 20.88 | 19.14 | 20.05 | 0.30 |
| 8 | 0.2 | 0.63 | 0.29 | 0.1 | 782 | 0.95 | 0.13 | 0.36 | 20.88 | 19.29 | 20.11 | 0.27 |
| 8 | 0.3 | 0.59 | 0.28 | 0.1 | 675 | 0.94 | 0.13 | 0.34 | 20.88 | 19.39 | 20.16 | 0.25 |
| 8 | 0.4 | 0.57 | 0.26 | 0.1 | 559 | 0.92 | 0.13 | 0.32 | 20.88 | 19.54 | 20.22 | 0.24 |
| 8 | 0.5 | 0.49 | 0.26 | 0.1 | 430 | 0.88 | 0.15 | 0.33 | 20.88 | 19.69 | 20.29 | 0.20 |
| 12 | 0.1 | 0.65 | 0.30 | 0.1 | 1063 | 0.96 | 0.14 | 0.37 | 21.35 | 19.62 | 20.64 | 0.30 |
| 12 | 0.2 | 0.61 | 0.28 | 0.1 | 1003 | 0.95 | 0.12 | 0.35 | 21.35 | 19.76 | 20.68 | 0.27 |
| 12 | 0.3 | 0.57 | 0.26 | 0.1 | 921 | 0.93 | 0.11 | 0.33 | 21.35 | 19.85 | 20.71 | 0.25 |
| 12 | 0.4 | 0.52 | 0.24 | 0.1 | 794 | 0.89 | 0.09 | 0.3 | 21.35 | 20.09 | 20.76 | 0.21 |
| 12 | 0.5 | 0.47 | 0.21 | 0.1 | 662 | 0.84 | 0.08 | 0.27 | 21.33 | 20.19 | 20.81 | 0.19 |
| 19 | 0.1 | −0.54 | 0.33 | 0.04 | 359 | −0.99 | 0.21 | 0.35 | 21.86 | 21.33 | 21.63 | 0.13 |
| 19 | 0.2 | −0.49 | 0.31 | 0.04 | 302 | −0.98 | 0.18 | 0.33 | 21.81 | 21.33 | 21.60 | 0.11 |
| 19 | 0.3 | −0.49 | 0.30 | 0.04 | 244 | −0.98 | 0.17 | 0.32 | 21.76 | 21.33 | 21.57 | 0.11 |
| 19 | 0.4 | −0.43 | 0.27 | 0.05 | 237 | −0.95 | 0.15 | 0.29 | 21.73 | 21.33 | 21.53 | 0.09 |
| 19 | 0.5 | −0.37 | 0.25 | 0.05 | 175 | −0.91 | 0.14 | 0.27 | 21.65 | 21.33 | 21.49 | 0.07 |
| 25 | 0.1 | −0.54 | 0.35 | 0.04 | 415 | −0.98 | 0.17 | 0.37 | 22.23 | 21.61 | 22.01 | 0.10 |
| 25 | 0.2 | −0.50 | 0.34 | 0.03 | 234 | −0.98 | 0.14 | 0.35 | 22.17 | 21.61 | 21.97 | 0.09 |
| 25 | 0.3 | −0.48 | 0.33 | 0.03 | 166 | −0.99 | 0.13 | 0.34 | 22.13 | 21.61 | 21.95 | 0.09 |
| 25 | 0.4 | −0.42 | 0.32 | 0.02 | 49 | −1 | 0.11 | 0.33 | 22.13 | 21.73 | 21.90 | 0.09 |
| 25 | 0.5 | −0.38 | 0.33 | 0.01 | 17 | −1 | 0.11 | 0.33 | 21.96 | 21.67 | 21.83 | 0.09 |
References
- Lysov, M.; Maximova, I.; Vasiliev, E.; Getmanskaya, A.; Turlapov, V. Entropy as a High-Level Feature for XAI-Based Early Plant Stress Detection. Entropy 2022, 24, 1597. [Google Scholar] [CrossRef]
- Boldú, F.X.P. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Kakogeorgiou, I.; Karantzalos, K. Evaluating Explainable Artificial Intelligence Methods for Multi-label Deep Learning Classification Tasks in Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102520. [Google Scholar] [CrossRef]
- Wei, K.; Chen, B.; Zhang, J.; Fan, S.; Wu, K.; Liu, G.; Chen, D. Explainable Deep Learning Study for Leaf Disease Classification. Agronomy 2022, 12, 1035. [Google Scholar] [CrossRef]
- Liu, Y.; Yue, H. The Temperature Vegetation Dryness Index (TVDI) Based on Bi-Parabolic NDVI-Ts Space and Gradient-Based Structural Similarity (GSSIM) for Long-Term Drought Assessment Across Shaanxi Province, China (2000–2016). Remote Sens. 2018, 10, 959. [Google Scholar] [CrossRef]
- Kumar, S.; Arya, S.; Jain, K. A SWIR-based vegetation index for change detection in land cover using multi-temporal Landsat satellite dataset. Int. J. Inf. Technol. 2022, 14, 2035–2048. [Google Scholar] [CrossRef]
- Dao, P.D.; He, Y.; Proctor, C. Plant drought impact detection using ultra-high spatial resolution hyperspectral images and machine learning. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102364. [Google Scholar] [CrossRef]
- Grechuka, B.; Gorban, A.N.; Tyukin, I.Y. General stochastic separation theorems with optimal bounds. Neural Netw. 2021, 138, 33–56. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.Y. Blessing of dimensionality: Mathematical foundations of the statistical physics of data. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2018, 376, 20170237. [Google Scholar] [CrossRef] [PubMed]
- Schmitter, P.; Steinrücken, J.; Römer, C.; Ballvora, A.; Léon, J.; Rascher, U.; Plümer, L. Unsupervised domain adaptation for early detection of drought stress in hyperspectral images. ISPRS J. Photogramm. Remote Sens. 2017, 131, 65–76. [Google Scholar] [CrossRef]
- Shahrimie, M.; Asaari, M. Detection of plant responses to drought using close-range hyperspectral imaging in a high-throughput phenotyping platform. In Proceedings of the 9th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote, Amsterdam, The Netherlands, 23–26 September 2018; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Hernández-Clemente, R.; Hornero, A.; Mottus, M.; Penuelas, J.; González-Dugo, V.; Jiménez, J.C.; Suárez, L. Early diagnosis of vegetation health from high-resolution hyperspectral and thermal imagery: Lessons learned from empirical relationships and radiative transfer modeling. Curr. For. Rep. 2019, 5, 169–183. [Google Scholar] [CrossRef]
- Zhang, N.; Guijun, Y.; Pan, Y.; Xiaodong, Y.; Chen, L.; Zhao, C. A review of advanced technologies and development for hyperspectral-based plant disease detection in the past three decades. Remote Sens. 2020, 12, 3188. [Google Scholar] [CrossRef]
- Maximova, I.; Vasiliev, E.; Getmanskaya, A.; Kior, D.; Sukhov, V.; Vodeneev, V.; Turlapov, V. Study of XAI-capabilities for early diagnosis of plant drought. In Proceedings of the IJCNN 2021: International Joint Conference on Neural Networks, INNS, Shenzhen, China, 18–22 July 2021; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Ma, J.; Zheng, B.; He, Y. Applications of a Hyperspectral Imaging System Used to Estimate Wheat Grain Protein: A Review. Front. Plant Sci. 2022, 13, 837200. [Google Scholar] [CrossRef]
- Pan, E.; Ma, Y.; Fan, F.; Mei, X.; Huang, J. Hyperspectral Image Classification across Different Datasets: A Generalization to Unseen Categories. Remote Sens. 2021, 13, 1672. [Google Scholar] [CrossRef]
- Zhang, Y.; Weng, Y.; Lund, J. Applications of Explainable Artificial Intelligence in Diagnosis and Surgery. Diagnostics 2022, 12, 237. [Google Scholar] [CrossRef] [PubMed]
- Lamy, J.-B.; Sekar, B.; Guezennec, G.; Bouaud, J.; Sroussi, B. Explainable artificial intelligence for breast cancer: A visual case-based reasoning approach. Artif. Intell. Med. 2019, 94, 42–53. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.-W.; Newman, S.-F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2022, 2, 749–760. [Google Scholar] [CrossRef] [PubMed]
- Antoniadi, A.M.; Du, Y.; Guendouz, Y.; Wei, L.; Mazo, C.; Becker, B.A.; Mooney, C. Current Challenges and Future Opportunities for XAI in Machine Learning-Based Clinical Decision Support Systems: A Systematic Review. Appl. Sci. 2021, 11, 5088. [Google Scholar] [CrossRef]
- Wang, D.; Yang, Q.; Abdul, A.; Lim, B.Y. Designing Theory-Driven User-Centric Explainable AI. In Proceedings of the CHI ’19: 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019. 15p. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Explainable Artificial Intelligence: A Systematic Review. arXiv 2020. [Google Scholar] [CrossRef]
- Averkin, A. Explanatory Artificial Intelligence, Results and Prospects. In Proceedings of the Russian Advances in Fuzzy Systems and Soft Computing: Selected Contributions to the 10th International Conference «Integrated Models and Soft Computing in Artificial Intelligence» (IMSC-2021), Kolomna, Russia, 17–20 May 2021; 12p. Available online: https://ceur-ws.org/Vol-2965/paper11.pdf (accessed on 10 July 2022).
- Phillips, P.J.; Hahn, A.C.; Fontana, P.C.; Broniatowski, D.A.; Przybocki, M.A. Four Principles of Explainable Artificial Intelligence; Draft; NIST: Gaithersburg, MD, USA, 2020; p. 8312. [Google Scholar] [CrossRef]
- Gunning, D. DARPA’s explainable artificial intelligence (XAI) program. In Proceedings of the IUI ’19: Proceedings of the 24th International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 17–20 March 2019. [Google Scholar] [CrossRef]
- P2976—Standard for XAI—eXplainable Artificial Intelligence—For Achieving Clarity and Interoperability of AI Systems Design. Available online: https://standards.ieee.org/project/2976.html (accessed on 8 August 2022).
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Agilandeeswari, L.; Prabukumar, M.; Radhesyam, V.; Phaneendra, K.L.N.B.; Farhan, A. Crop Classification for Agricultural Applications in Hyperspectral Remote Sensing Images. Appl. Sci. 2022, 12, 1670. [Google Scholar] [CrossRef]
- Allegra, M.; Facco, E.; Denti, F.; Laio, A.; Mira, A. Data segmentation based on the local intrinsic dimension. Sci. Rep. 2020, 10, 16449. [Google Scholar] [CrossRef] [PubMed]
- Albergante, L.; Mirkes, E.; Bac, J.; Chen, H.; Martin, A.; Faure, L.; Barillot, E.; Pinello, L.; Gorban, A.; Zinovyev, A. Robust and scalable learning of complex intrinsic dataset geometry via ElPiGraph. Entropy 2020, 22, 296. [Google Scholar] [CrossRef] [PubMed]
- Bac, J.; Mirkes, E.M.; Gorban, A.N.; Tyukin, I.; Zinovyev, A. Scikit-Dimension: A Python Package for Intrinsic Dimension Estimation. Entropy 2021, 23, 1368. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Grechuk, B.; Mirkes, E.M.; Stasenko, S.V.; Tyukin, I.Y. High-Dimensional Separability for One- and Few-Shot Learning. Entropy 2021, 23, 1090. [Google Scholar] [CrossRef] [PubMed]
- Jackson, R.D.; Idso, S.B.; Reginato, R.J.; Pinter, P.J. Canopy temperature as a crop water stress indicator. Water Resour. Res. 1981, 17, 1133–1138. [Google Scholar] [CrossRef]
- Lysov, M.; Pukhky, K.; Turlapov, V. Combined processing of hyperspectral and thermal images of plants in soil for the early diagnosis of drought. In Proceedings of the GraphiCon 2021: 31st International Conference on Computer Graphics and Vision, Nizhny Novgorod, Russia, 27–30 September 2021; Volume 3027, pp. 529–541. [Google Scholar] [CrossRef]
- Knipling, E.B. Physical and Physiological Basis for the Reflectance of Visible and Near-Infrared Radiation from Vegetation. Remote Sens. Environ. 1970, 1, 155–159. [Google Scholar] [CrossRef]
- Gitelson, A.; Merzlyak, M. Signature Analysis of Leaf Reflectance Spectra: Algorithm Development for Remote Sensing of Chlorophyll. J. Plant Physiol. 1996, 148, 494–500. [Google Scholar] [CrossRef]
- Vegetation Indices for Chlorophyll (CI–MTCI–NDRE–ND705–ND550–mNDblue). Plant Phenotyping Vegetation Indices for Chlorophyll—Blog Hiphen (hiphen-plant.com). Available online: https://www.hiphen-plant.com/vegetation-indices-chlorophyll/3612/ (accessed on 10 July 2022).







| Key days number | 1 | 3 | 6 | 8 | 12 | 19 | 25 |
| ‘Train’ pots numbers | 5 | 11 | 9 | 5 | 10 | 5 | 10 |
| ‘Test’ pots numbers | 8 | 8 | 8 | 8 | 8 | 4 | 8 |
| Day | Threshold | a,b | Mask, Pix | PLCC | Best Ch., No/nm | RMSE, °C |
|---|---|---|---|---|---|---|
| 1 | 0.4 | 1 | 1274 | 0.616 | 58/566 | 0.159 |
| 1 | 0.5 | 1 | 867 | 0.57 | 144/823 | 0.151 |
| 1 | 0.5 | 0.1 | 483 | 0.827 | 143/820 | 0.056 |
| 3 | 0.4 | 1 | 1134 | 0.325 | 55/557 | 0.207 |
| 3 | 0.5 | 1 | 700 | 0.277 | 52/549 | 0.194 |
| 3 | 0.5 | 0.1 | 349 | 0.48 | 143/820 | 0.067 |
| 6 | 0.4 | 1 | 1232 | 0.464 | 53/551 | 0.212 |
| 6 | 0.5 | 1 | 824 | 0.41 | 118/745 | 0.214 |
| 6 | 0.5 | 0.1 | 337 | 0.685 | 143/820 | 0.058 |
| 8 | 0.4 | 1 | 1376 | 0.596 | 117/742 | 0.212 |
| 8 | 0.5 | 1 | 952 | 0.496 | 117/742 | 0.205 |
| 8 | 0.5 | 0.15 | 590 | 0.774 | 143/820 | 0.085 |
| 12 | 0.4 | 1 | 1954 | 0.576 | 142/817 | 0.198 |
| 12 | 0.5 | 1 | 1495 | 0.537 | 141/814 | 0.181 |
| 12 | 0.5 | 0.1 | 662 | 0.836 | 143/820 | 0.06 |
| 19 | 0.4 | 1 | 1124 | −0.465 | 145/826 | 0.306 |
| 19 | 0.5 | 1 | 768 | −0.414 | 145/826 | 0.264 |
| 19 | 0.4 | 0.1 | 482 | −0.795 | 143/820 | 0.18 |
| 25 | 0.4 | 1 | 974 | −0.434 | 128/775 | 0.364 |
| 25 | 0.4 | 0.1 | 398 | −0.815 | 129/778 | 0.184 |
| 25 | 0.4 | 0.05 | 166 | −0.957 | 143/820 | 0.189 |
| 25 | 0.5 | 1 | 588 | −0.384 | 143/820 | 0.371 |
| 25 | 0.5 | 0.1 | 171 | −0.828 | 58/566 | 0.189 |
| Day | Threshold | PLCC a,b = 1 | RMSE a,b = 1, °C | a,b | Mask in, Pix | PLCC in | RMSE in, °C | RMSE out, °C |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.4 | 0.60 | 0.18 | 0.08 | 556 | 0.91 | 0.06 | 0.23 |
| 1 | 0.5 | 0.56 | 0.17 | 0.06 | 316 | 0.92 | 0.05 | 0.2 |
| 3 | 0.4 | 0.18 | 0.29 | 0.05 | 1134 | 0.18 | 0.29 | 0.32 |
| 3 | 0.5 | 0.17 | 0.26 | 0.04 | 700 | 0.17 | 0.26 | 0.29 |
| 6 | 0.4 | 0.35 | 0.31 | 0.05 | 255 | 0.95 | 0.17 | 0.34 |
| 6 | 0.5 | 0.26 | 0.32 | 0.04 | 166 | 0.9 | 0.17 | 0.34 |
| 8 | 0.4 | 0.57 | 0.26 | 0.1 | 1376 | 0.57 | 0.26 | 0.32 |
| 8 | 0.5 | 0.49 | 0.26 | 0.1 | 952 | 0.49 | 0.26 | 0.33 |
| 12 | 0.4 | 0.52 | 0.24 | 0.1 | 1954 | 0.52 | 0.24 | 0.3 |
| 12 | 0.5 | 0.47 | 0.21 | 0.1 | 1495 | 0.47 | 0.21 | 0.27 |
| 19 | 0.4 | −0.43 | 0.27 | 0.05 | 237 | −0.95 | 0.15 | 0.29 |
| 19 | 0.5 | −0.37 | 0.25 | 0.05 | 175 | −0.91 | 0.14 | 0.27 |
| 25 | 0.4 | −0.42 | 0.32 | 0.02 | 49 | −1 | 0.11 | 0.33 |
| 25 | 0.5 | −0.38 | 0.33 | 0.01 | 17 | −1 | 0.11 | 0.33 |
| Threshold | a = b | TrainMask pix | TestMask pix | Train RMSE, °C | Test RMSE, °C | Epoch | Time, Sec |
|---|---|---|---|---|---|---|---|
| 0.1 | 1 | 16,541 | 17,660 | 0.23 | 0.22 | 112 | 44 |
| 0.1 | 0.5 | 16,121 | 17,333 | 0.21 | 0.20 | 97 | 37 |
| 0.1 | 0.1 | 6870 | 7227 | 0.15 | 0.11 | 188 | 31 |
| 0.2 | 1 | 13,636 | 14,861 | 0.26 | 0.21 | 236 | 77 |
| 0.2 | 0.5 | 13,333 | 14,633 | 0.20 | 0.20 | 209 | 68 |
| 0.2 | 0.1 | 5769 | 6207 | 0.15 | 0.11 | 200 | 29 |
| 0.3 | 1 | 11,146 | 12,067 | 0.22 | 0.20 | 146 | 39 |
| 0.3 | 0.5 | 10,938 | 11,920 | 0.21 | 0.19 | 79 | 20 |
| 0.3 | 0.1 | 4740 | 5137 | 0.12 | 0.11 | 113 | 13 |
| 0.4 | 1 | 8581 | 9068 | 0.20 | 0.20 | 221 | 45 |
| 0.4 | 0.5 | 8465 | 8985 | 0.19 | 0.19 | 254 | 52 |
| 0.4 | 0.1 | 3777 | 3938 | 0.09 | 0.10 | 225 | 12 |
| 0.5 | 1 | 6126 | 6194 | 0.19 | 0.19 | 106 | 16 |
| 0.5 | 0.5 | 6074 | 6164 | 0.20 | 0.18 | 252 | 153 |
| 0.5 | 0.1 | 2762 | 2828 | 0.10 | 0.11 | 266 | 41 |
| Number of Channels | Threshold | a = b | Train Mask, pix | Test Mask, pix | Train RMSE, °C | Test RMSE, °C | Epoch | Time, Sec |
|---|---|---|---|---|---|---|---|---|
| 204 | 0.1 | 0.5 | 16,121 | 17,333 | 0.21 | 0.34 | 48 | 35.35 |
| 204 | 0.1 | 0.1 | 6870 | 7227 | 0.14 | 0.27 | 99 | 34.1 |
| 204 | 0.3 | 0.5 | 10,938 | 11,920 | 0.21 | 0.28 | 61 | 37.64 |
| 204 | 0.3 | 0.1 | 4740 | 5137 | 0.11 | 0.21 | 238 | 61.41 |
| 204 | 0.4 | 0.5 | 8465 | 8985 | 0.17 | 0.27 | 120 | 66.75 |
| 204 | 0.4 | 0.1 | 3777 | 3938 | 0.10 | 0.21 | 316 | 57.65 |
| 204 | 0.5 | 0.5 | 6074 | 6164 | 0.15 | 0.25 | 105 | 48.57 |
| 204 | 0.5 | 0.1 | 2762 | 2828 | 0.08 | 0.24 | 266 | 46.39 |
| 146 (15–160) | 0.5 | 0.5 | 6074 | 6164 | 0.16 | 0.20 | 294 | 98.05 |
| 146 (15–160) | 0.5 | 0.1 | 2762 | 2828 | 0.11 | 0.14 | 278 | 33.17 |
| 32 * | 0.5 | 0.5 | 6074 | 6164 | 0.21 | 0.24 | 132 | 19.19 |
| 32 * | 0.5 | 0.1 | 2762 | 2828 | 0.16 | 0.19 | 207 | 13.84 |
| 8 ** | 0.5 | 0.5 | 6074 | 6164 | 0.24 | 0.27 | 279 | 53.31 |
| 8 ** | 0.5 | 0.1 | 2762 | 2828 | 0.21 | 0.22 | 151 | 13.88 |
| 7 ** | 0.5 | 0.5 | 6074 | 6164 | 0.26 | 0.27 | 214 | 58.12 |
| 7 ** | 0.5 | 0.1 | 2762 | 2828 | 0.22 | 0.22 | 181 | 15.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lysov, M.; Pukhkiy, K.; Vasiliev, E.; Getmanskaya, A.; Turlapov, V. Ensuring Explainability and Dimensionality Reduction in a Multidimensional HSI World for Early XAI-Diagnostics of Plant Stress. Entropy 2023, 25, 801. https://doi.org/10.3390/e25050801
Lysov M, Pukhkiy K, Vasiliev E, Getmanskaya A, Turlapov V. Ensuring Explainability and Dimensionality Reduction in a Multidimensional HSI World for Early XAI-Diagnostics of Plant Stress. Entropy. 2023; 25(5):801. https://doi.org/10.3390/e25050801
Chicago/Turabian StyleLysov, Maxim, Konstantin Pukhkiy, Evgeny Vasiliev, Alexandra Getmanskaya, and Vadim Turlapov. 2023. "Ensuring Explainability and Dimensionality Reduction in a Multidimensional HSI World for Early XAI-Diagnostics of Plant Stress" Entropy 25, no. 5: 801. https://doi.org/10.3390/e25050801
APA StyleLysov, M., Pukhkiy, K., Vasiliev, E., Getmanskaya, A., & Turlapov, V. (2023). Ensuring Explainability and Dimensionality Reduction in a Multidimensional HSI World for Early XAI-Diagnostics of Plant Stress. Entropy, 25(5), 801. https://doi.org/10.3390/e25050801