1. Introduction
The origin of life and the evolution of life are of widespread interest, but in spite of the efforts aimed at answering these questions, the current knowledge on the subject is limited and there are manifold hypotheses. An indispensable prerequisite for constructing a scenario for the emergence of life via natural processes is the ability to demonstrate a realistic probability for self-assembly of the first simple proto-molecules in the prebiotic world, prior to the existence of any replicative system. The challenge posed by this requirement is self-evident. Even the sequence of a simple ribozyme of 40 mer has 10
24 possible compositions. To represent all of these compositions at least once, and thus to establish a certainty that this simple ribozyme could have materialized, requires 27 kg of RNA chains, which classifies spontaneous emergence as a highly implausible event [
1].
Any scenario describing the emergence of “life as we know it”, i.e., biology based on nucleic-acid and amino-acid polymers, must include a proto-ribosome, which would have catalyzed the formation of a peptide bond between two amino acids and produced simple peptides. This proto-ribosome could have emerged and functioned within an RNA world [
2,
3,
4], where RNA, perhaps with the aid of co-factors, acted as both the catalytic tool and the heredity source. Alternatively, it may have emerged spontaneously, as a stable molecule in the prebiotic chemistry. The ribosome, the contemporary apparatus responsible for catalyzing peptide bond formation during the translation of the genetic code into proteins, may offer a reliable source of extant information on its prebiotic ancestor, because of its universal nature, employing a common mode of action in all life domains. This, alongside with its considerable level of phylogenetic conservation, imply that the essence of the current translation mechanism should have already been present in the Last Universal Common Ancestor (LUCA) and that the vestige of the stand-alone primordial proto-ribosome may still be inferred from its contemporary structure. Owing to the accepted notion that the ribosome could not have emerged in its present complex form, it must have continuously evolved from a simple ancestor which took part in the emergence of the current mode of life. Its identification within the modern ribosome may therefore enable the examination of the feasibility of spontaneous materialization of a functional ribozyme in the prebiotic era.
In the contemporary ribosome, peptide bond formation, the essential function of the ribosome, takes place at the active site of the large subunit, i.e., at the Peptidyl Transferase Center (PTC), which is composed solely of RNA [
5,
6]. The PTC pocket harbors the universally conserved 3′ end of the Aminoacyl-tRNA substrate, carrying the incoming amino acid and the 3′ end of the Peptidyl-tRNA, bearing the nascent chain synthesized up to that point. The PTC is located at the heart of a region of about 180 nucleotides, possessing an approximate 2-fold rotational symmetry [
7,
8]. The two symmetry-related sub-regions of the symmetrical region (SymR) are termed the A-, P- sub-regions (
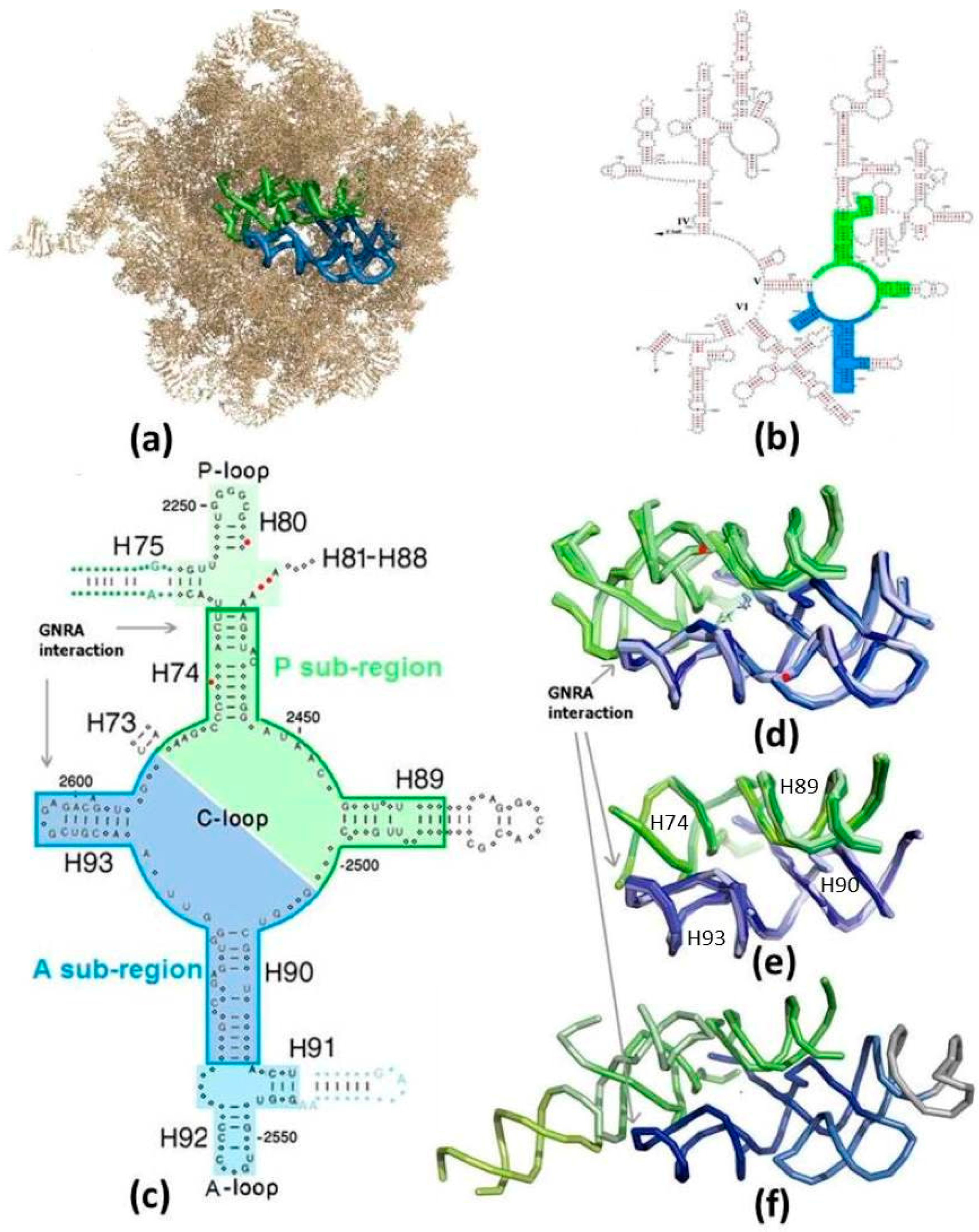
Figure 1), after the A-, P-sites contained in them. The structure of the SymR (
Figure 1a–d) is conserved throughout all of the high resolution structures of the large subunit determined so far, from the three domains of life (
Figure 1d), i.e., in the structures of archaea—
Haloarcula marismortui (H50S) [
9]; bacteria—
Deinoccocus radiodurans (D50S) [
10],
E. coli [
11],
Thermus thermophilus (T50S) [
12]; eukarya—
Saccharomyces cerevisiae (
S. cer) [
13], as well as in mitochondrial ribosomes [
14,
15]. In addition to its 3D structural preservation, this region is highly conserved phylogenetically [
8]. Thus, a version of this symmetrical RNA element, which conforms to the exact stereochemistry of the current PTC, may be conceived as a stand-alone proto-ribosome. Taking advantage of the RNA tendency to form stable dimers spontaneously [
16,
17,
18], such an RNA element can be described as a dimer, whose spontaneous materialization in the prebiotic world would have depended on the aptitude of its monomers to self-assemble correctly from random RNA chains.
The inverse ratio between the length of the ribozyme sequence and the probability of its autonomous formation implies that a dimeric nature of an enzyme increases the feasibility of its random emergence by many orders of magnitude. Three concentric proto-ribosomes of dimeric nature were suggested: The entire SymR of about 180 nucleotides (
Figure 1c,d), whose hub hosts peptide bond formation in the modern ribosome, was linked with the proto-ribosome due to its role, its universality and the high conservation of its structure [
19]. A unique pattern of A-minor interactions [
20] found within the ribosome, constantly pointing from the periphery of the rRNA into the SymR, was interpreted as presenting a mode for adding new structural elements to an existing proto-ribosome [
21]. This observation yielded a proto-ribosome model of 225 nucleotides, composed of the SymR extended by the non-symmetrical parts of H75 and H91 (
Figure 1c,f), denominated here the extended symmetrical region (ext-SymR). A smaller element of about 120 nucleotides, termed the dimeric proto-ribosome (DPR), constituting the core of the SymR (
Figure 1c,e), was concurrently suggested to be the initial proto-ribosome [
22,
23,
24]. Eliminating the vicinity of the A-, P-loops from the SymR structure leaves a dimer of two L-shaped RNA elements, the A-, P-DPR monomers, which are comparable in size and shape to the tRNA molecules [
23,
24]. These three structural entities preserve the stereochemistry of the amino acids’ accommodation at the A- and P-sites of the modern ribosome and could thus have potentially acted as catalysts for the prebiotic peptide bond formation, prior to the advent of mRNA and coding.
The probability that any of the monomers of the three suggested proto-ribosomes could have spontaneously emerged as a building block of the first ribozyme catalyzing non-coded peptide bond formation is hereby assessed. By introducing the notion of "limited specificity” in this context, the feasibility of a spontaneous materialization of the simplest contender, the dimeric proto-ribosome, is demonstrated.
3. Discussion
The preservation of the symmetrical region structure in ribosomes from bacteria, archaea and eukarya (
Figure 1c,d), suggests that this fraction of the ribosome carries structural features older than the differentiation into the life kingdoms. The ancestor of the SymR would have therefore been part of LUCA. As such it would have already been capable of translating a code in a processive manner, implying that beyond applying positional catalysis to the substrates, this molecular machine would have been adapted to some properties of the modern mechanism, such as translocation and substrates conjugated with anticodon loops. This apparatus, whose vestige is suggested to build the modern PTC in the large subunit, should have therefore been an evolved version of the earliest non-coded proto-ribosome, i.e., a proto-ribosome that did not use a code. The primal entity is assumed to have emerged spontaneously as a stable molecule in an era of “chemical evolution”, an epoch which initiated and proceeded in the absence of polymerases, heredity, genetic information, and Darwinian evolution [
31]. This non-coded proto-ribosome would have catalyzed peptide bond formation between random amino acids by exerting positional catalysis on small substrates and enabled simple elongation [
19,
22,
23,
24].
The feasibility of self-assembly of a ribozyme from prebiotic random RNA chains is a question central to the ability to conceive life emerging by natural processes. In the quest for retracing the initial autonomously-formed proto-ribosome, the ensuing coded version conserved in the current ribosomes is used as a model for the non-coded proto-ribosome. The usage of the advanced version is justified because the DPR, representing a vestige of the coded proto-ribosome, was demonstrated to be the smallest possible apparatus of its kind that can preserve the PTC layout [
23,
24]. If the non-coded proto-ribosome could not have been smaller than this coded one, and if, as assumed, it underwent a continuous evolution towards the proto-ribosome present in LUCA, it is reasonable that the initial and evolved versions were similar. Subsequent modifications, which are present in the coded proto-ribosome due to its adaptation to the more complex function, present a challenge to the derivation of the constraints on the nucleotide identity required for obtaining a proper hypothetical sequence of the non-coded proto-ribosome. Additionally, these modifications, combined with the limited information available concerning the nature of the early substrates and the environmental conditions that prevailed on the prebiotic earth, probably impede the attempts to generate a working non-coded proto-ribosome [
32]. Further clarification of these uncertainties may enable the production of a functioning proto-ribosome in the lab.
Three suggested vestiges of the coded proto-ribosome, having a dimeric nature, were derived from the structure of the modern ribosome; the entire symmetrical region—i.e., the SymR [
19], its core—the DPR [
22,
23,
24] and the SymR extended with the non-symmetrical parts of H75 and H91 [
21], namely, the ext-SymR (
Figure 1c–f). The shortest oligomer is required for the formation of the A-DPR monomer—about 60 mer, while the longest is that of the P-ext-SymR monomer, 116 mer. Random RNA polymers of over 100 mer are believed to have existed in the prebiotic environment based on the polymerization of nucleotides on clay [
33], on the elongation of oligonucleotides under temperature gradient [
34] and on the possibility of self-ligation of RNA chains [
35], pointing to the prebiotic existence of oligonucleotides sufficiently long to form each of the monomers.
The probability of random occurrence of a sequence capable of forming a structurally and functionally suitable monomer was tested under the notion of “limited sequence specificity” [
23]. Limited specificity means that just a subset of residues, mainly those involved in functional or structural tasks, have to be restricted to a particular type in order to obtain a working enzyme. This concept is manifested by the A- and the P-sub-regions of the SymR, which in the modern ribosome primarily perform an equivalent role of symmetrically accommodating the reactants of peptide bond formation [
6]. In accordance, the sub-regions exhibit significant 2D and 3D resemblance (
Figure 1c and
Figure 2), while their sequences are hardly related. In
E. coli for instance, only 38% of the symmetry-related nucleotides hold an identical nucleotide type. Nevertheless, the functionally vital nucleotides G2553 from the A-loop and G2251 from the P-loop, which symmetrically accommodate the substrates by forming base-pairs to C75 of the modern A- and P-tRNAs, maintain the same nucleotide type in the two sub-regions. This supports the notion that ribozymes with varying sequences may execute equivalent roles, provided that the functional and structure-determining residues retain the required nucleotide type. Future experimental verification of this notion seems feasible. Mutating the sequence of a well-studied ribozyme, while preserving its secondary structure and the identity of its essential nucleotides, will permit the examination of the limited specificity effect on the function and perhaps result in more efficient ribozymes.
Limiting the requirement for specific nucleotide identity increases the probability of a random occurrence of a functional sequence by many orders of magnitude, compared with that of a fixed-sequence ribozyme of the same size, as demonstrated for the A-DPR monomer, i.e., 10
−18 vs. 10
−36, respectively. This concept may be applied to other specialized enzymes as well. A ≈ 190 mer ribozyme replicase created via directed evolution, with the ability to replicate a 95-nucleotide stretch of RNA [
36], was considered to be far too long a sequence to have arisen through any conceivable process of random assembly [
37]. If, however, the type of the non-catalytic and non-structural residues is permitted to vary, appropriate sequences other than the one obtained in the lab may exist, thus increasing the probability of random occurrence considerably. Additionally, the limited specificity is evolutionary advantageous, since it would have granted the prebiotic apparatus a tolerance to the rather poor copying abilities that any initial replicase would have probably had.
The probability of random occurrence of a proper sequence of the A-DPR-like monomer, i.e., ≈10
−18, which pertains to the A- as well as to the P-DPR monomers, is probably naïve. A random mutation in a loop or bulged nucleotide, permitted here to have a random type, may induce alteration in the base-pairing scheme, decreasing the calculated probability. Still, among the nine A- and P-DPR sequences derived from the current ribosomes (
Table 1) and the ten extensively randomized A-DPR sequences from
E. coli, all of which comply with the full set of constraints on the nucleotides identity defined in
Section 2.1.1, more than half were found to fold into structures analogous to those found within the ribosome (
Figure 3 and
Figure 4). This suggests a reduction of the probability assessed for random occurrence of the non-coded proto-ribosome sequence to 5 × 10
−19.
Among the secondary structure predictions of the 27 contemporary sequences, performed using energy minimization with Mfold (
Table 1), the eukaryotic sequences of the monomers of all three contenders were predicted to acquire folds different from those found within the ribosome. This result implies that the eukaryotic sequences are not directly related to that of the proto-ribosome and corroborates the notion that eukaryotes are a not direct descendants of LUCA [
38,
39]. The sequences of the prokaryotic SymR monomers were predicted to have multiple alternatives of equally probable folds, mostly incompatible with the suggested proto-ribosome structure. The odds of obtaining an RNA element having the SymR monomer fold from its contemporary sequences are therefore slight. In the case of the prokaryotic ext-SymR monomeric sequences, the most probable fold predictions are compatible with those found in the ribosome only for the bacterial sequences. Moreover, some of the predicted folds are non-unique and the multiple predictions hardly differ in their free energy, thus reducing the chance of spontaneously obtaining the correct secondary structure.
Conversely, if any of the sequences of the DPR monomers found within the contemporary prokaryotic ribosomes existed in the prebiotic world, under environmental conditions which do not differ considerably from the default parameters used by the Mfold program, they would have been compelled to fold into an L-shaped structure matching the one found within the ribosome, in accord with the unique solutions obtained via energy minimization (
Table 1,
Figure 3c,d and
Figure 4a,b). Moreover, half of the extensively randomized sequences of A-DPR from
E. coli were predicted to acquire similar secondary schemes (
Figure 4c). Consequently, sequences of about 60 mer, which conform to the set of constraints on the nucleotides’ identity defined in
Section 2.1.1, can be considered as having a tendency to spontaneously fold into a secondary structure comparable to that found within the ribosome.
The probabilistic criterion, which is equally applied to the three suggested proto-ribosomes, considerably favors the DPR to the larger ones, due to its realistic probability of random occurrence, which is higher by six and ten orders of magnitude relative to the SymR and ext-SymR. Consistently, the energetic criterion points to DPR monomers as having more enhanced propensity to fold correctly. The compatibility of the DPR with the characteristics of the vestige of the non-coded proto-ribosome correlates well with its being structurally the simplest, as is to be expected from a prebiotic apparatus. Additionally, its 3D fold is completely conserved in the modern ribosome (
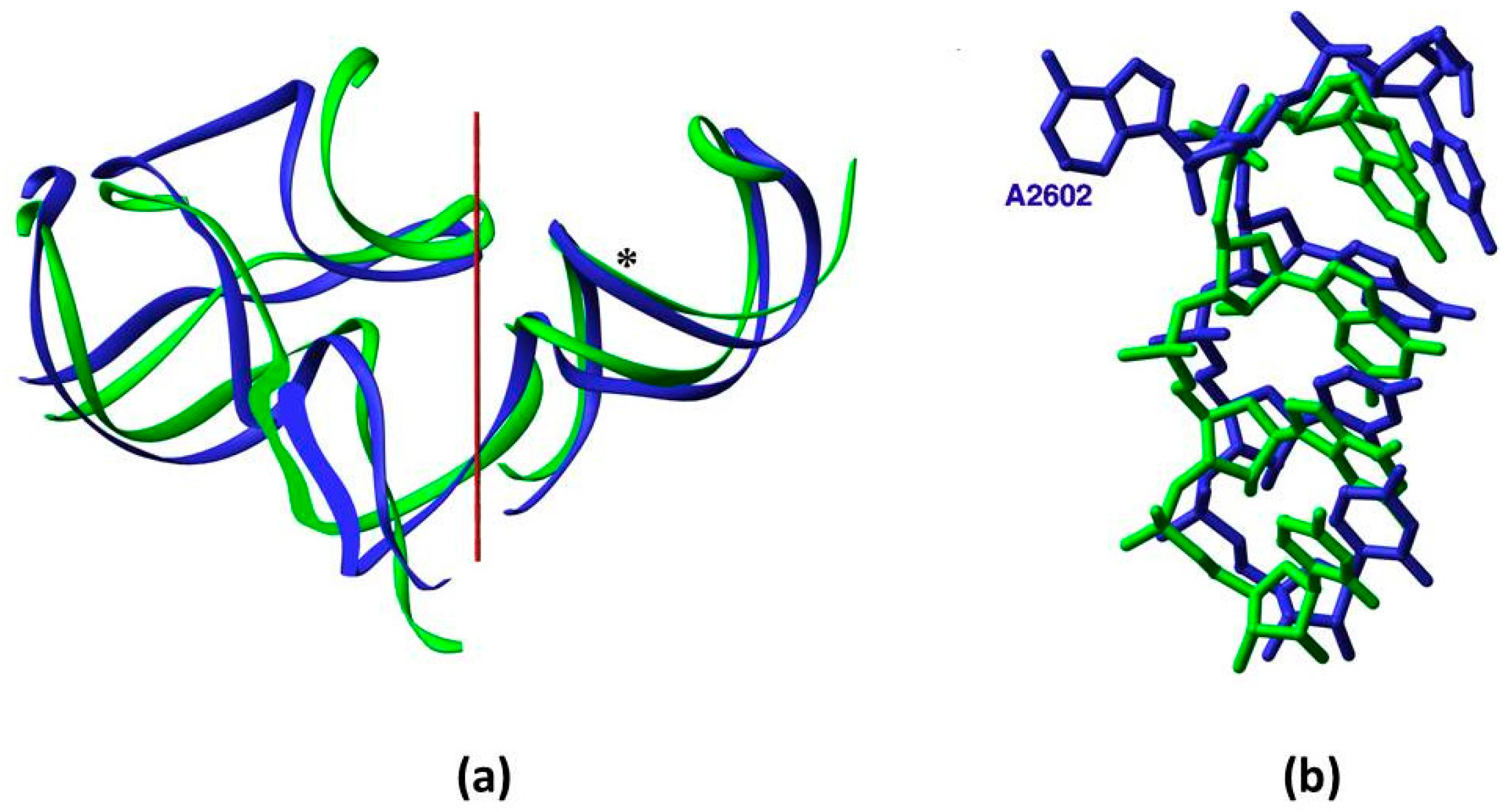
Figure 1c,e), as opposed to the slight deviations found in a peripheral element of the SymR and the ext-SymR in different life domains (
Figure 1d upper left), caused by the indels (
Figure 1c). These arguments and the fact that the DPR building blocks i.e., its two L-shaped monomers, are comparable in size and outline to the L-shaped tRNA [
22,
23,
24] considered to be a molecular fossil [
40], point to the DPR being the most probable vestige of the proto-ribosome.
The tendency of sequences of the prokaryotic A-DPR to fold correctly (
Table 1) and to dimerize [
27,
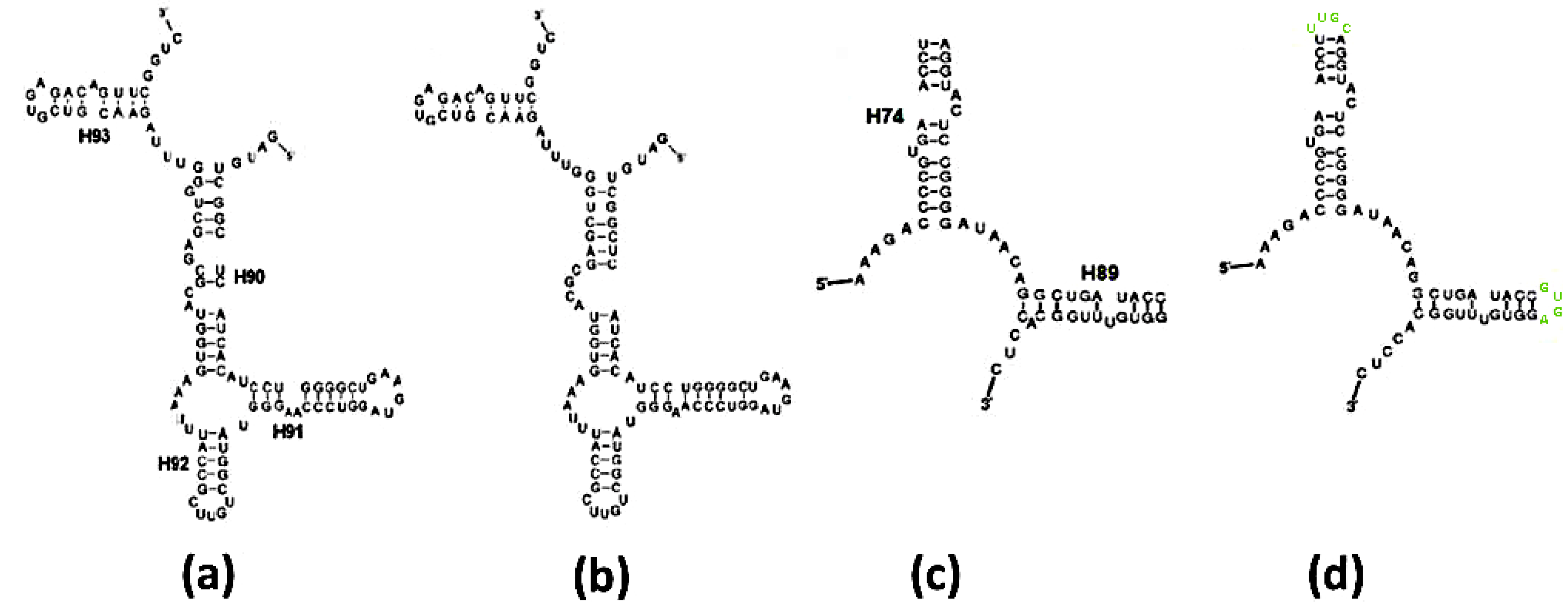
28], suggests that the information embedded in its contemporary sequences may suffice for identifying the determinants for self-assembly into the desired structure. This, however, is not straight forward because the model derived from the modern ribosomes belongs to a more evolved proto-ribosome than the non-coded one. Local deviations between the ribosomal 2D scheme and the fold prediction of the same sequences are inevitable even in the sequences considered as correctly-folded, e.g.,
Figure 3a–d and
Figure 4a,b, because the coded ribosome was adapted to advanced functions at the expense of losing stability. The contemporary structure of H90, for instance, contains a complex network of non-base-paired nucleotides, which is obviously less stable than the predicted one (
Figure 3a,b and
Figure 4a,b). Its spatial organization presumably enables C2573, a 100% conserved nucleotide from the non-base-paired region of H90 (
Figure 4a), to bulge out into the PTC and carry out a role in translocation which is specific to coded proto-ribosomes [
7,
8]. The minimal free-energy structure predicted by Mfold represents the structure of an autonomously folded molecule. Hence, the similarity between the folding predictions and the secondary structure within the ribosome (
Figure 3c,d and
Figure 4a,b), imply that these folds are likely to constitute good approximations of the secondary structure of the non-coded proto-ribosome monomer. These folding results were obtained from sequences that comply with the restrictions on the nucleotide type determined in
Section 2.1.1, thus supporting the constraints applied to the helical portion of the structure.
Another group of constraints pertain to the C-loop nucleotides. These nucleotides build the walls of the active site, and thus include the essential nucleotides involved in accommodating the reactants. The continuity principle would require that the exact mechanism of peptide bond formation is maintained, i.e., that the stereochemistry of the reactants in the active site of the non-coded proto-ribosome and of the modern ribosome must to be identical. In the modern ribosome the reacting amino acids rest upon nucleotides from the C-loop, but the actual accommodation takes place via base-pairing of the tRNA 3’ end with the A- and P-loops. The compact non-coded proto-ribosome that lacked the A, P-loops would have accommodated smaller substrates, whose atomic interactions with the C-loop nucleotides could have been different. The nature of these initial substrates is currently unknown and several options, such as amino-nucleotide conjugates similar to puromycin, or oligo-linked amino acids [
41], as well as single amino acids [
42], were already suggested. The more primitive mechanism implies that only part of the eight C-loop nucleotides essential for the modern function (
Figure 1c), were vital for the non-coded mechanism, and that fewer C-loop nucleotides should be restricted to a particular type, thus increasing the overall calculated probability. On the other hand, extra base-pairs were formed between C-loop nucleotides in all the correctly-folded randomized sequences, a change that would have altered the layout of the PTC completely. To preserve the single stranded nature of the C-loop, additional or different constraints should be applied to the 14 C-loop nucleotides, possibly decreasing the overall calculated probability. The determined probability of the random occurrence of a sequence of the A-DPR-like monomer, 5 × 10
−19, indicates that each liter of 1mM solution of random RNA chains of about 60 mer would have included about 300 oligonucleotides having sequences predisposed to form L-shaped DPR monomers with dimerization affinity and conserved reactant accommodation position. Thus, even a probability lower by two orders of magnitude would still suffice to grant the non-coded proto-ribosome an acceptable probability of self-assembly from random RNA chains.
The vestige of the compact DPR within the current ribosome is comprised of 121 nucleotides, but as a stand-alone entity it would have had loops capping the currently truncated H74, H89 and H90 (
Figure 1c). If capping by tetra loops is assumed, in accord with the existing H93 stem loop, the overall number of nucleotides in the DPR would have been 133. Hence its autonomous formation would have required two RNA chains of about 70 mer, a length comfortably within the range believed to exist in the prebiotic world [
33,
34,
35]. A tiny fraction of these chains, i.e., those conforming to the constraints on the nucleotide type, would have spontaneously folded into the more stable L-shaped RNA molecules. Two monomers could then spontaneously dimerize around the 2-fold symmetry axis, via GNRA interactions, to form a pocket-like RNA entity (
Figure 1e). Both folding and dimerization are energetically downhill processes, indicating that molecules of the dimeric proto-ribosome could have been readily available in the prebiotic world, catalyzing peptide bond formation at the bottom of the cavity in the same manner that the contemporary ribosome exerts positional catalysis; by accommodating the two reactants in a stereochemistry favorable for peptide bond formation. An efficient apparatus of this kind could have synthesized short peptides with random composition [
22,
23,
24], which would have granted the proto-ribosome an evolutionary advantage of added stabilization, in analogy to the stabilization conferred to the contemporary rRNA by the ribosomal protein tails, which are believed to have a primordial origin [
43,
44,
45].
The entire SymR, or more likely—the ext-SymR, was probably an evolved stage of the dimeric proto-ribosome with the additional RNA helices emanating from the far ends of H74 and H90 (
Figure 1c). It is conceivable that the presence of random peptides, whose formation was catalyzed by the DPR, could have assisted the correct folding and stabilization of these more complex proto-ribosomes and possibly promoted the utilization of larger substrates. Some form of primitive replication would have emerged, either non-enzymatic or by very simple replicators, causing variability via mutations in the copied sequences and allowing for the selection of the fittest proto-ribosome, thus promoting evolution. Following the advent of coding, strings of RNA functioning as mRNA, would be translated by the coded proto-ribosome into the first coded peptides. Additional RNA elements would have later joined the proto-ribosome via different mechanisms [
21,
46] and this, along with the gradual incorporation of proteins serving in stabilizing and supporting roles, could have eventually led to the current complex ribosome.
The most fundamental requirement from a proper initial proto-ribosome model is its capability to autonomously emerge in the prebiotic world with the aptitude to catalyze peptide bond formation. The probability of spontaneous occurrence of the DPR sequence, obtained under the notion of limited sequence specificity, may be too optimistic, but even a significantly lower probability is still acceptable, taking into consideration that the emergence of life is believed to have occurred just once. Given optimal, yet unknown environmental conditions and sufficient time, a small pond with a relatively low concentration of random RNA chains of about 70 mer may have provided feasible likelihood for the materialization of a prebiotic apparatus catalyzing non-coded peptide-bond formation and simple elongation. This dimeric proto-ribosome thus offers a conceivable prebiotic starting point for a natural pathway leading to the complex protein biosynthesis mechanism, shared by all the modern living organisms.







{kind=link}
{kind=link}
{kind=link}
{kind=link}