
Detection and Quantification of Alprazolam Added to Long Drinks by Near Infrared Spectroscopy and Chemometrics




Abstract
:1. Introduction
2. Results and Discussion
2.1. Discrimination of Pure and Spiked Drinks by PLS-DA
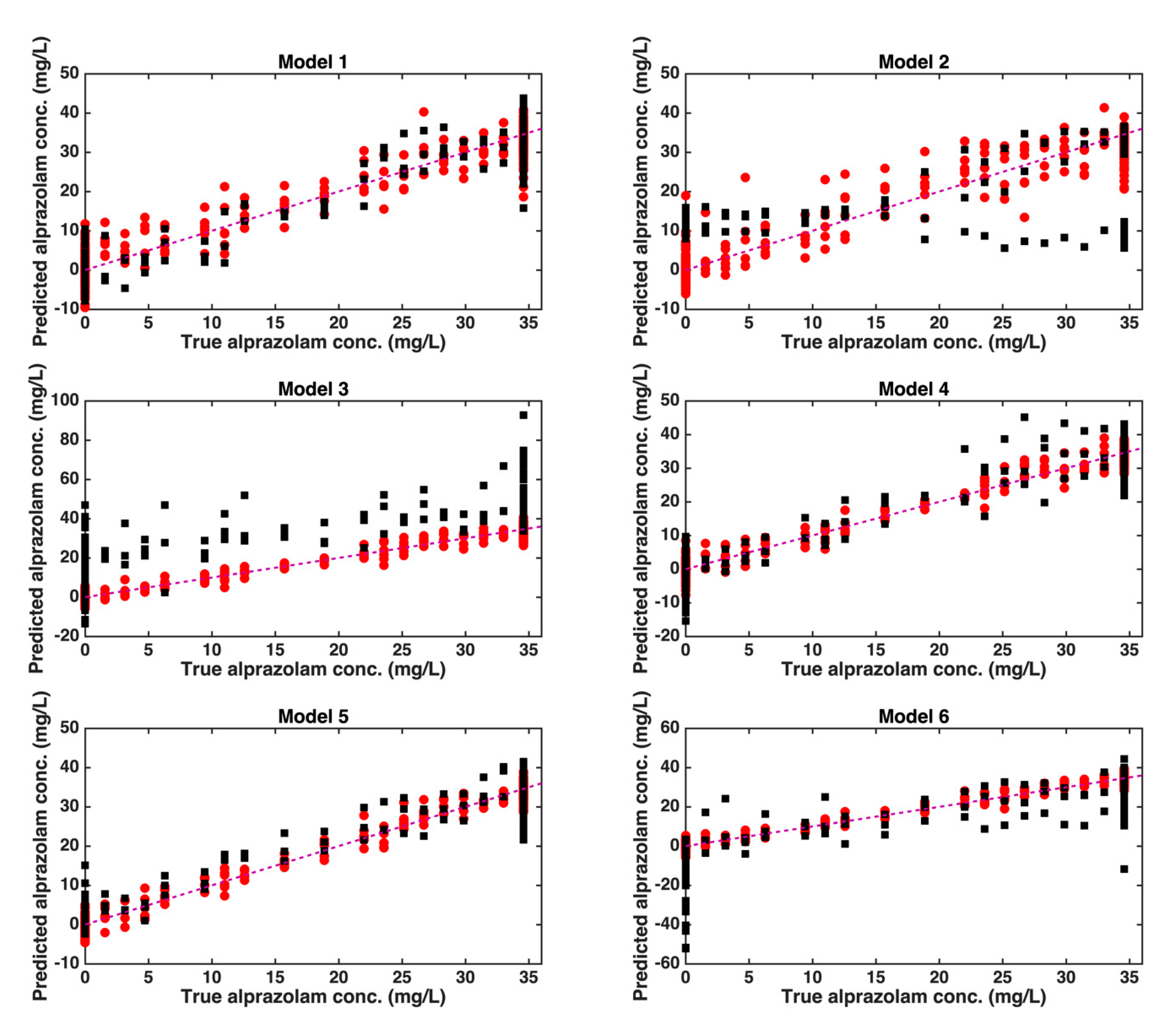
2.2. Quantification of Alprazolam by PLS
3. Materials and Methods
3.1. Sample Preparation
3.2. NIR Spectra Collection
3.3. Chemometric Methods
3.3.1. Partial Least Squares
3.3.2. Partial Least Squares Discriminant Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
References
- Saïas, T.; Gallarda, T. Réactions d’agressivité sous benzodiazépines: Une revue de la littérature. Encephale 2008, 34, 330–336. [Google Scholar] [CrossRef] [PubMed]
- West Virginia Foundation for Rape Information & Services. Drug Facilitated Sexual Assault. Available online: http://www.fris.org/SexualViolence/DrugFacilitated.html (accessed on 9 August 2022).
- Lee, D.; Stout, P.; Egdorf, D. Houston Cocktail: Driving under influence of hydrocodone, alprazolam, and carisoprodol. Forensic Sci. Int. 2021, 323, 110819. [Google Scholar] [CrossRef] [PubMed]
- LeBeau, M.A.; Mozayani, A. Drug Facilitated Sexual Assault—A Forensic Handbook; LeBeau, M.A., Mozayani, A., Eds.; Academic Press: San Diego, CA, USA, 2001. [Google Scholar]
- Hagemann, C.T.; Helland, A.; Spigset, O.; Espnes, K.A.; Ormstad, K.; Schei, B. Ethanol and drug findings in women consulting a Sexual Assault Center-Associations with clinical characteristics and suspicions of drug-facilitated sexual assault. J. Forensic Leg. Med. 2013, 20, 777–784. [Google Scholar] [CrossRef] [PubMed]
- Kintz, P.; Villain, M.; Dumestre-Toulet, V.; Ludes, B. Drug-facilitated sexual assault and analytical toxicology: The role of LC-MS/MS-a case involving zolpidem. J. Clin. Forensic Med. 2016, 12, 36–41. [Google Scholar] [CrossRef] [PubMed]
- United Nations Office on Drugs and Crime (UNO-DC). Guidelines for the Forensic Analysis of Drugs Facilitating Sexual Assault and Other Criminal Acts. Available online: https://www.unodc.org/documents/scientific/forensic_analys_of_drugs_facilitating_sexual_assau_and_other_criminal_acts.pdf.2011 (accessed on 9 August 2022).
- Tseliou, F.; Pappas, P.; Spyrou, K.; Hrbac, J.; Prodromidis, M.I. Lab-on-a-screen-printed electrochemical cell for drop-volume voltammetric screening of flunitrazepam in untreated, undiluted alcoholic and soft drinks. Biosens. Bioelectron. 2019, 132, 136–142. [Google Scholar] [CrossRef] [PubMed]
- Ali, E.M.A.; Edwards, H.G.M. The detection of flunitrazepam in beverages using portable Raman spectroscopy. Drug Test. Anal. 2017, 9, 256–259. [Google Scholar] [CrossRef] [PubMed]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Barker, M.; Rayens, W. Partial least squares for discrimination. J. Chemom. 2003, 17, 166–173. [Google Scholar] [CrossRef]
- Power, A.C.; Jones, J.; NiNeil, C.; Geoghegan, S.; Warren, S.; Currivan, S.; Cozzolino, D. What’s in this drink? Classification and adulterant detection in Irish Whiskey samples using near infrared spectroscopy combined with chemometrics. J. Sci. Food Agric. 2021, 101, 5256–5263. [Google Scholar] [CrossRef] [PubMed]
- Núñez, N.; Saurina, J.; Núñez, O. Authenticity Assessment and Fraud Quantitation of Coffee Adulterated with Chicory, Barley, and Flours by Untargeted HPLC-UV-FLD Fingerprinting and Chemometrics. Foods 2021, 10, 840. [Google Scholar] [CrossRef] [PubMed]
- Wold, S.; Johansson, E.; Cocchi, M. PLS-partial least-squares projections to latent structures. In 3D QSAR Drug Design, Theory, Methods, and Applications, 1st ed.; Kubinyi, H., Ed.; ESCOM Science Publishers: Leiden, The Netherlands, 1993; pp. 523–550. [Google Scholar]
- Makraduli, L.; Makreski, P.; Goracinova, K.; Stefov, S.; Anevska, M.; Geskovski, N. A Comparative Approach to Screen the Capability of Raman and Infrared (Mid- and Near-) Spectroscopy for Quantification of Low-Active Pharmaceutical Ingredient Content Solid Dosage Forms: The Case of Alprazolam. Appl. Spectrosc. 2020, 74, 661–673. [Google Scholar] [CrossRef] [PubMed]
- Allegrini, F.; Olivier, A.C. IUPAC-Consistent Approach to the Limit of Detection in Partial Least-Squares Calibration. Anal. Chem. 2014, 86, 7858–7866. [Google Scholar] [CrossRef] [PubMed]
- Greenblatt, D.J.; Wright, C.E. Clinical Pharmacokinetics of Alprazolam. Clin. Pharmacokinet. 1993, 24, 453–471. [Google Scholar] [CrossRef] [PubMed]
- Wold, S.; Martens, H.; Wold, H. The multivariate calibration problem in chemistry solved by the PLS method. In Matrix Pencils. Lecture Notes in Mathematics, 1st ed.; Kågström, B., Ruhe, A., Eds.; Springer: Berlin/Heidelberg, Germany, 1983; pp. 286–293. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Biancolillo, A.; Marini, F.; Ruckebusch, C.; Vitale, R. Chemometric strategies for spectroscopy-based food authentication. Appl. Sci. 2020, 10, 6544. [Google Scholar] [CrossRef]
- Ståhle, L.; Wold, S. Partial least squares analysis with cross-validation for the two-class problem: A Monte Carlo study. J. Chemom. 1987, 1, 185–196. [Google Scholar] [CrossRef]
- Sjöström, M.; Wold, S.; Söderström, B. Partial Least Squares Discriminant Plots. In Pattern Recognition in Practice, Vol. II; Gelsema, E.S., Kanal, L.N., Eds.; Elsevier: Amsterdam, The Netherlands, 1986; pp. 461–470. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Mixtures Used as Test Set | Pre-Treatment * | LVs * | Accuracy (%) | Average % CCR * | Sensitivity (%) | |
|---|---|---|---|---|---|---|---|
| Spiked | Pure | ||||||
| 1 | G3T1 G3T2 G3T3 | MC | 13 | 95.32 | 94.86 | 96.40 | 93.33 |
| 2 | G2T1 G2T2 G2T3 | MC | 10 | 95.32 | 96.40 | 92.79 | 100.00 |
| 3 | G1T1 G1T2 G1T3 | MC | 6 | 78.36 | 71.08 | 95.50 | 46.67 |
| 4 | G1T3 G2T3 G3T3 | D1+MC | 21 | 88.89 | 88.00 | 90.99 | 85.00 |
| 5 | G1T2 G2T2 G3T2 | SNV+MC | 16 | 92.98 | 92.30 | 94.59 | 90.00 |
| 6 | G1T1 G2T1 G3T1 | MC | 3 | 71.35 | 73.72 | 65.77 | 81.67 |
| Model | Mixtures Used as Test Set | Pre-Treatment * | LVs * | Calibration (Training Set) | Validation (Test Set) | ||||
|---|---|---|---|---|---|---|---|---|---|
| RMSEC * | Bias | R2 | RMSEP * | Bias | R2 | ||||
| 1 | G3T1 G3T2 G3T3 | MC | 14 | 4.0 | 0.0 | 0.9321 | 4.9 | 0.5 | 0.9017 |
| 2 | G2T1 G2T2 G2T3 | D2+MC | 14 | 4.2 | 0.0 | 0.9270 | 12.7 | −0.9 | 0.3352 |
| 3 | G1T1 G1T2 G1T3 | MC | 6 | 2.6 | 0.0 | 0.9730 | 19.6 | −15.1 | −0.5879 |
| 4 | G1T3 G2T3 G3T3 | SNV+MC | 24 | 2.5 | 0.0 | 0.9748 | 5.8 | −0.1 | 0.8596 |
| 5 | G1T2 G2T2 G3T2 | SNV+MC | 25 | 2.1 | 0.0 | 0.9810 | 5.1 | −0.7 | 0.8919 |
| 6 | G1T1 G2T1 G3T1 | MC | 22 | 2.1 | 0.0 | 0.9820 | 13.0 | 6.3 | 0.2965 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Scappaticci, C.; Spera, S.; Biancolillo, A.; Marini, F. Detection and Quantification of Alprazolam Added to Long Drinks by Near Infrared Spectroscopy and Chemometrics. Molecules 2022, 27, 6420. https://doi.org/10.3390/molecules27196420
Scappaticci C, Spera S, Biancolillo A, Marini F. Detection and Quantification of Alprazolam Added to Long Drinks by Near Infrared Spectroscopy and Chemometrics. Molecules. 2022; 27(19):6420. https://doi.org/10.3390/molecules27196420
Chicago/Turabian StyleScappaticci, Claudia, Stella Spera, Alessandra Biancolillo, and Federico Marini. 2022. "Detection and Quantification of Alprazolam Added to Long Drinks by Near Infrared Spectroscopy and Chemometrics" Molecules 27, no. 19: 6420. https://doi.org/10.3390/molecules27196420
APA StyleScappaticci, C., Spera, S., Biancolillo, A., & Marini, F. (2022). Detection and Quantification of Alprazolam Added to Long Drinks by Near Infrared Spectroscopy and Chemometrics. Molecules, 27(19), 6420. https://doi.org/10.3390/molecules27196420