


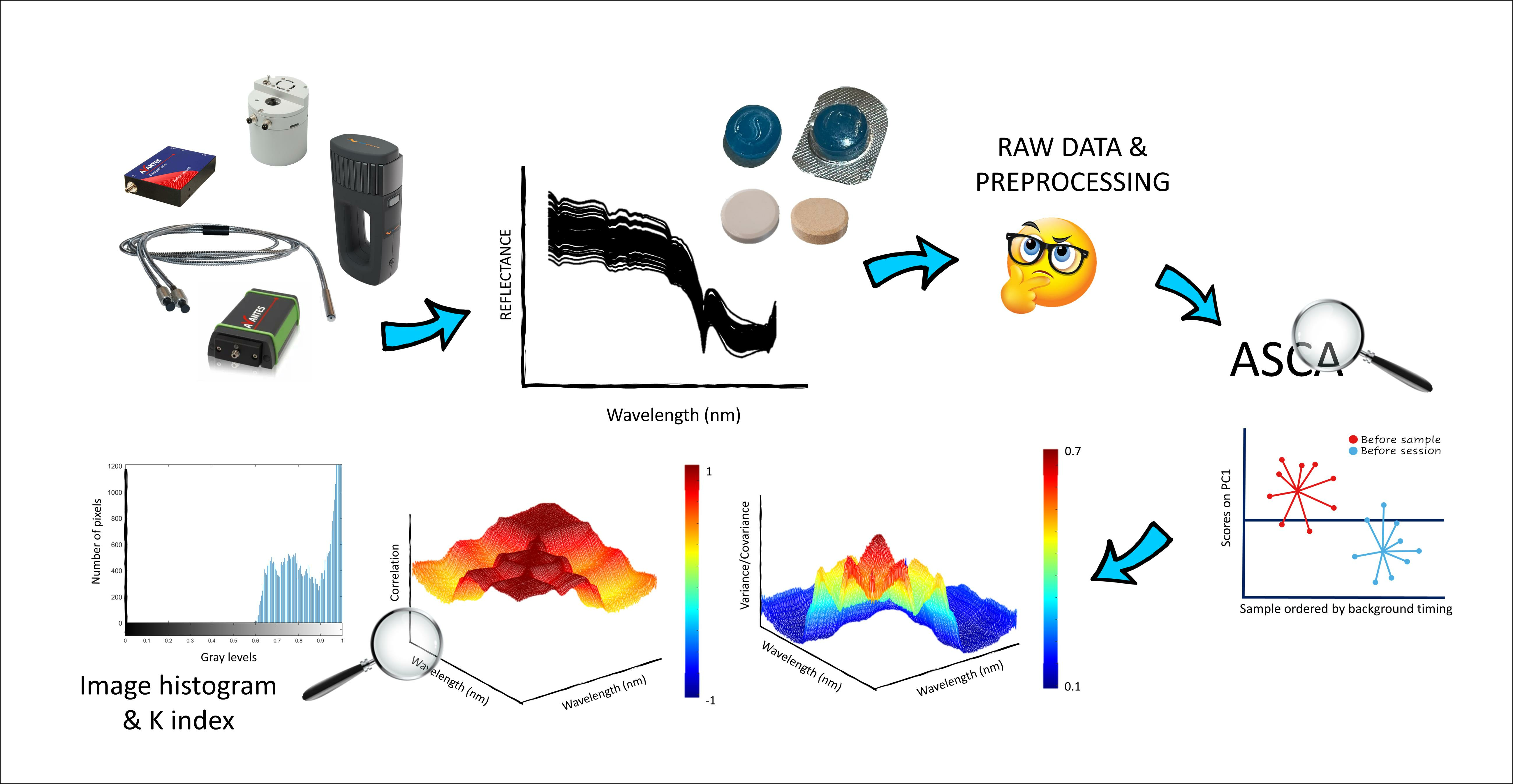
A Multivariate Analysis-Driven Workflow to Tackle Uncertainties in Miniaturized NIR Data




Abstract
:
1. Introduction
2. Results and Discussion
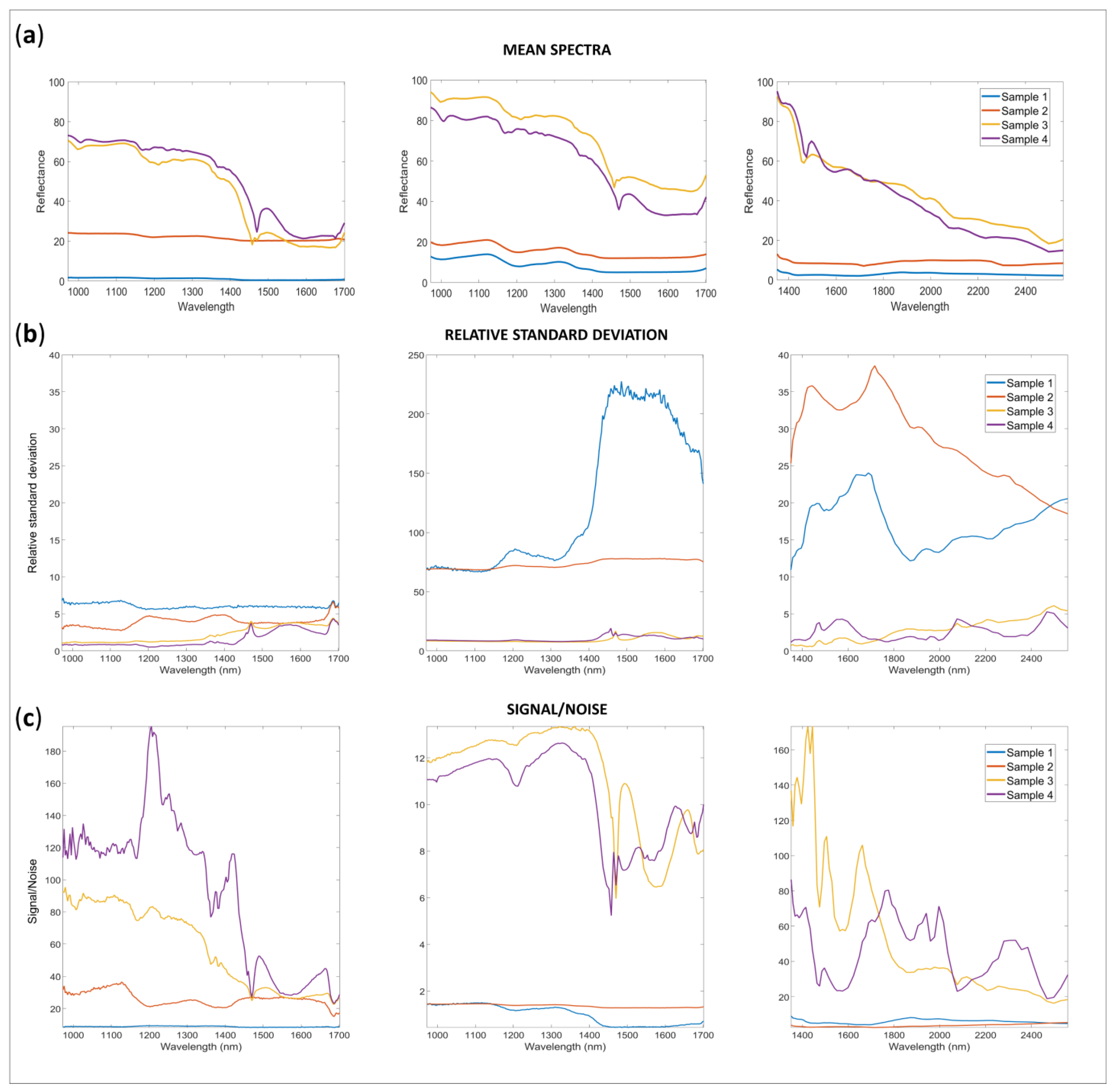
2.1. Spectral Data and Reproducibility
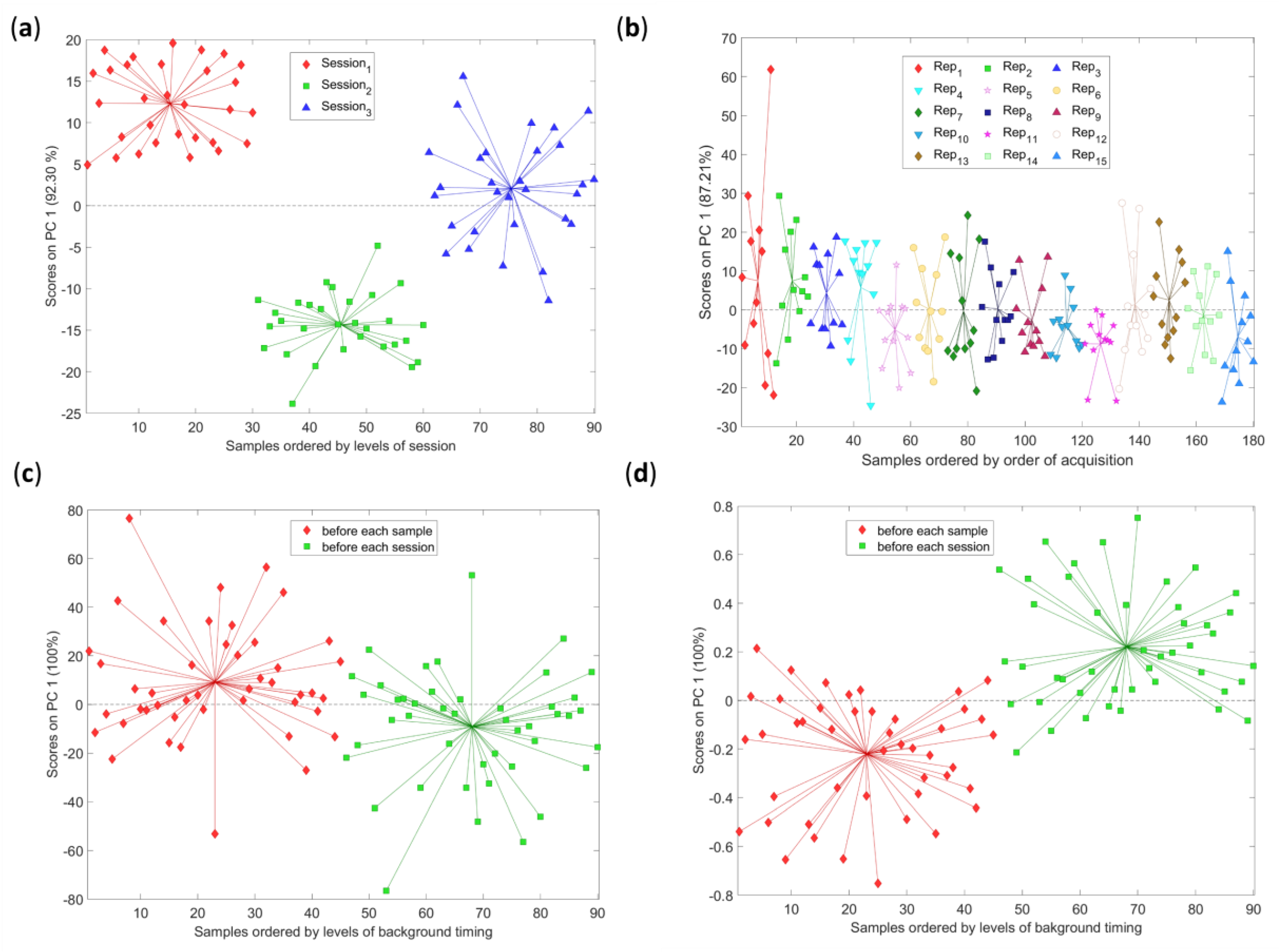
2.2. Study of the Variability Sources in the Data
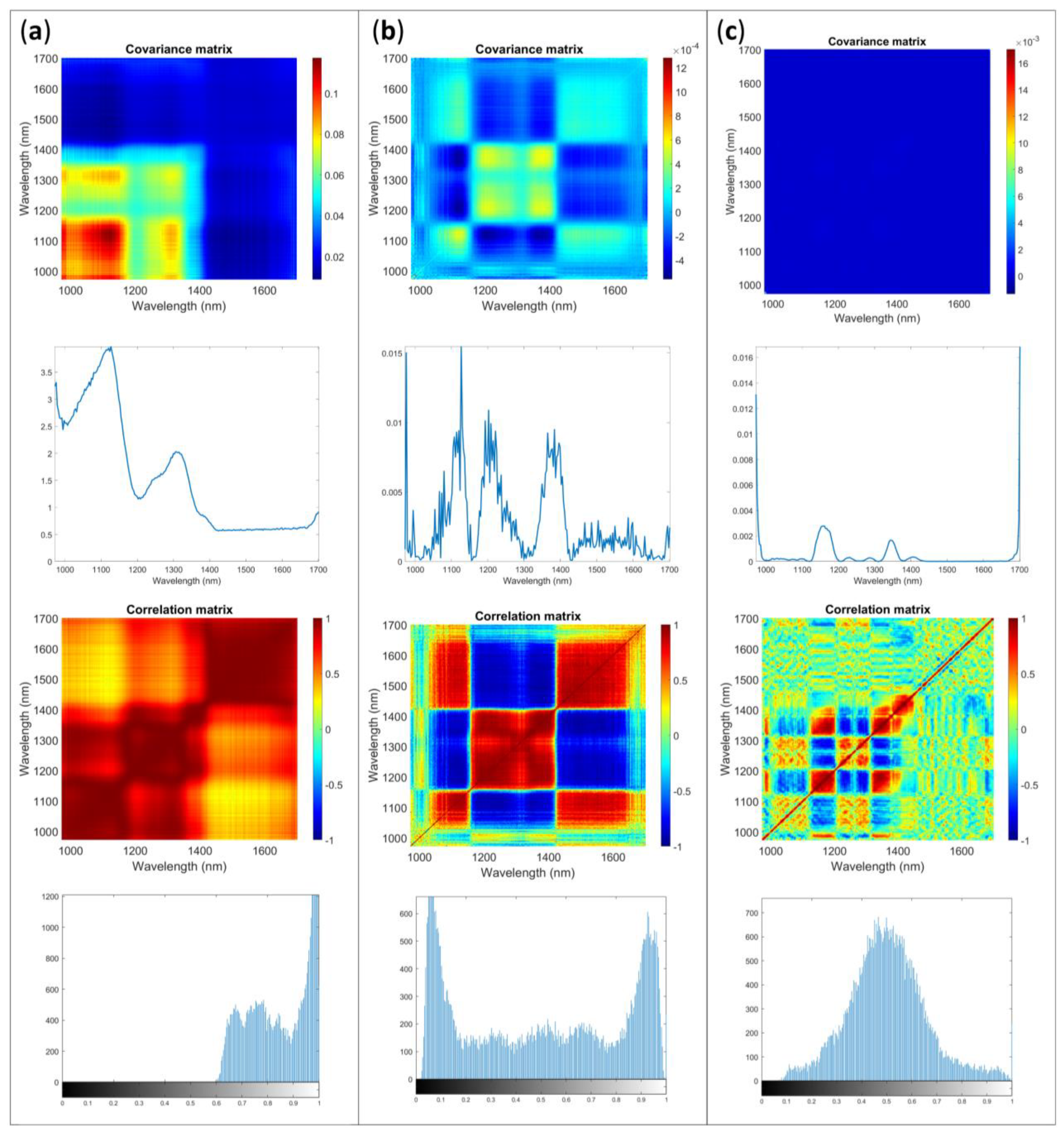
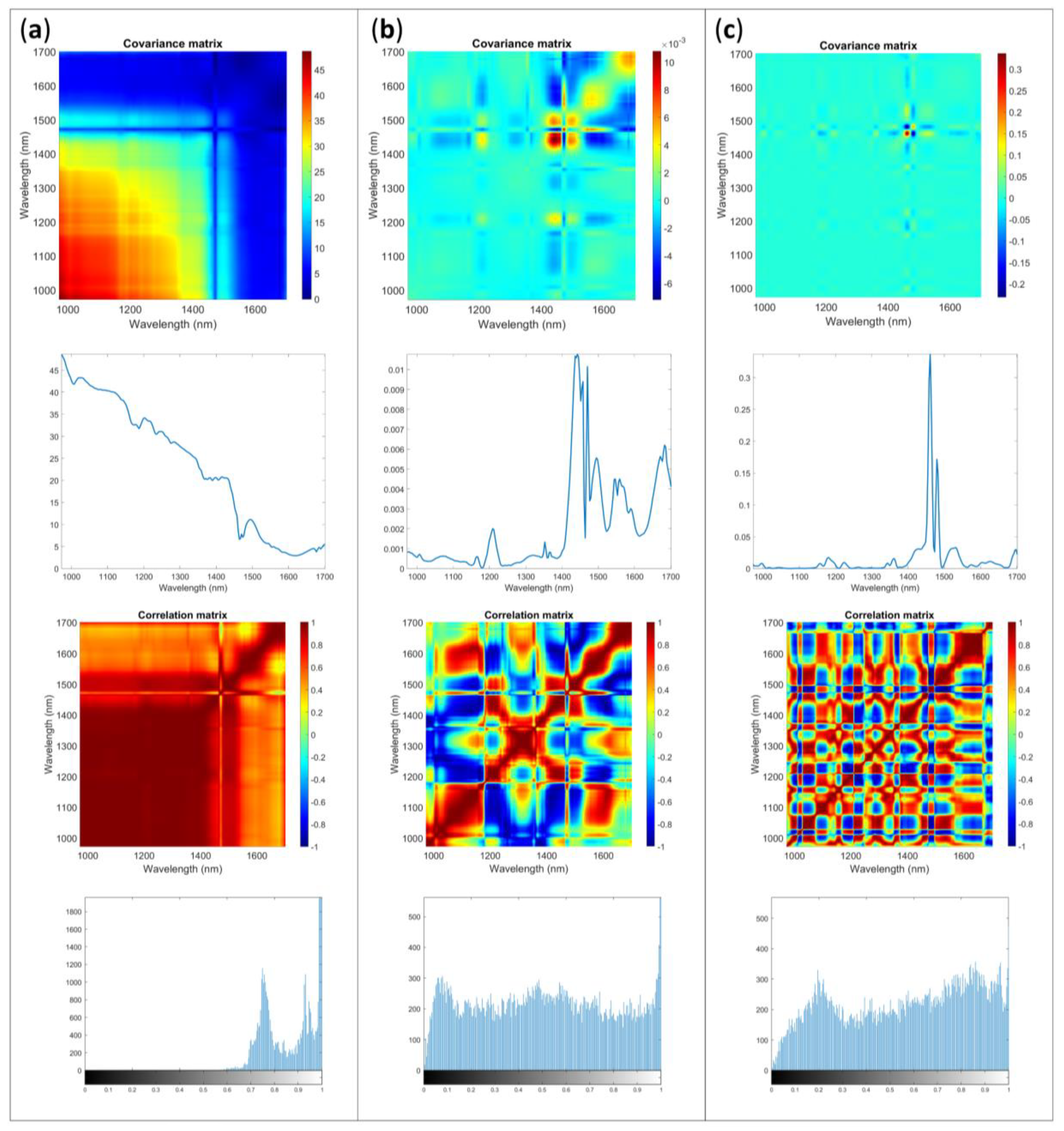
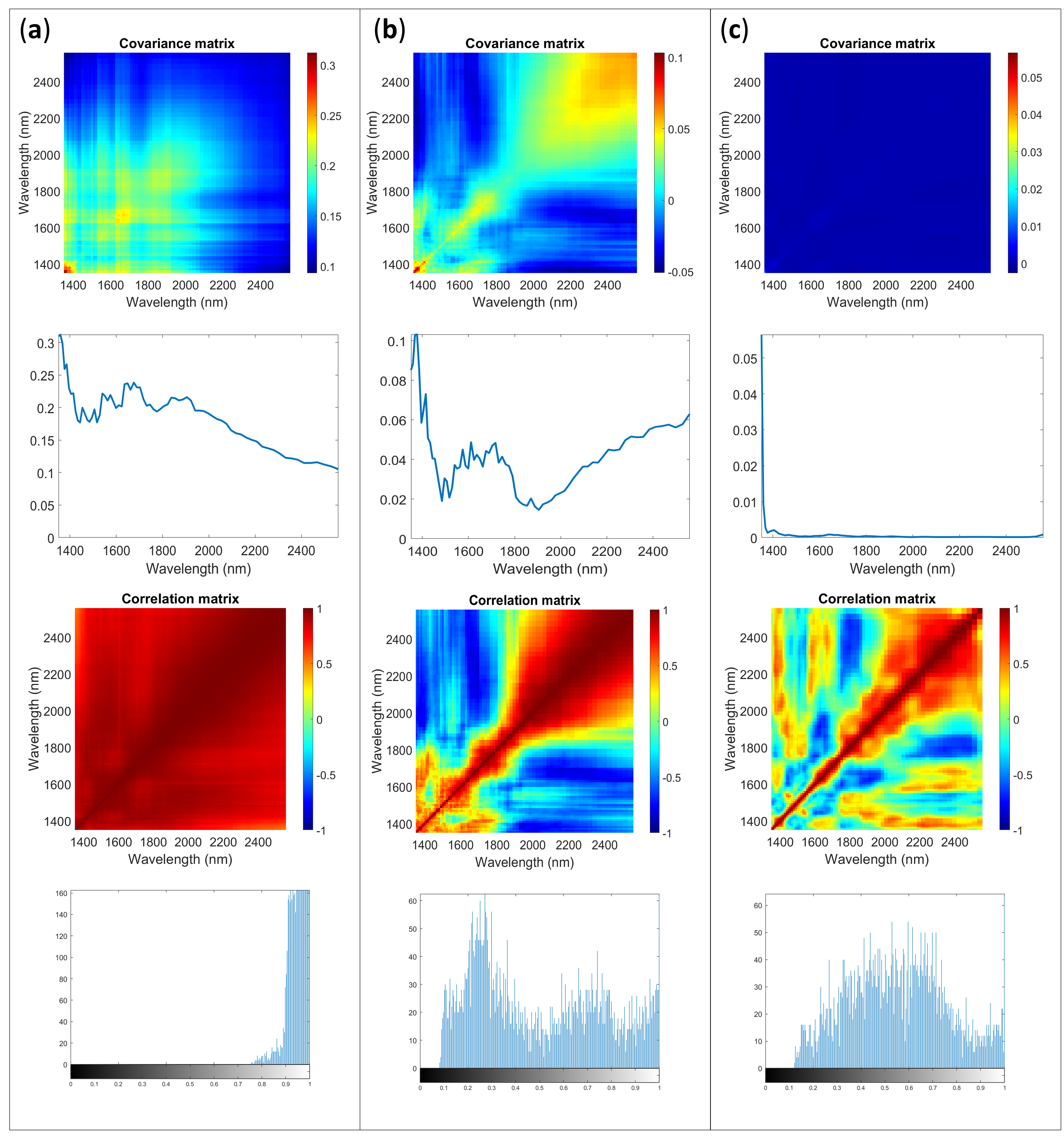
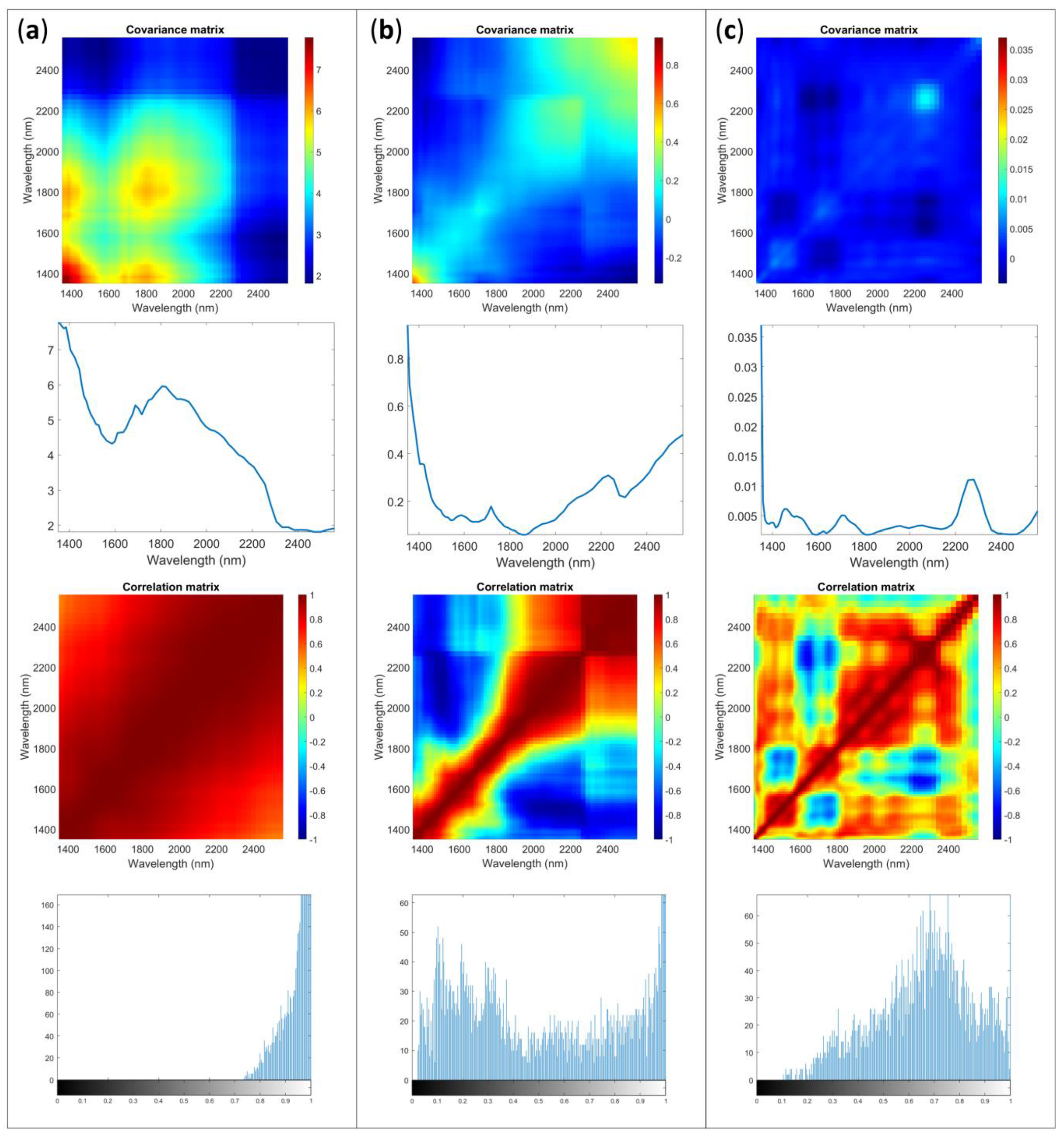
2.3. Uncertainty Characteristics: Multivariate Error
2.3.1. AvaSpec-Mini-NIR
2.3.2. NeoSpectra Scanner
3. Materials and Methods
3.1. Samples
3.2. Spectrometers and Experiments
3.2.1. AvaSpec-Mini-NIR
3.2.2. NeoSpectra Scanner
3.3. Chemometrics Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wentzell, P.D. Measurement Errors in Multivariate Chemical Data. J. Braz. Chem. Soc. 2014, 25, 183–196. [Google Scholar] [CrossRef]
- Wentzell, P.D.; Wicks, C.C.; Braga, J.W.B.; Soares, L.F.; Pastore, T.C.M.; Coradin, V.T.R.; Davrieux, F. Implications of Measurement Error Structure on the Visualization of Multivariate Chemical Data: Hazards and Alternatives. Can. J. Chem. 2018, 96, 738–748. [Google Scholar] [CrossRef]
- Yan, H.; De Gea Neves, M.; Noda, I.; Guedes, G.M.; Silva Ferreira, A.C.; Pfeifer, F.; Chen, X.; Siesler, H.W. Handheld Near-Infrared Spectroscopy: State-of-the-Art Instrumentation and Applications in Material Identification, Food Authentication, and Environmental Investigations. Chemosensors 2023, 11, 272. [Google Scholar] [CrossRef]
- Beć, K.B.; Grabska, J.; Huck, C.W. Principles and Applications of Miniaturized Near-Infrared (NIR) Spectrometers. Chem.A Eur. J. 2021, 27, 1514–1532. [Google Scholar] [CrossRef] [PubMed]
- Giussani, B.; Gorla, G.; Riu, J. Analytical Chemistry Strategies in the Use of Miniaturised NIR Instruments: An Overview. Crit. Rev. Anal. Chem. 2022, 1–33. [Google Scholar] [CrossRef] [PubMed]
- Gorla, G.; Taborelli, P.; Alamprese, C.; Grassi, S.; Giussani, B. On the Importance of Investigating Data Structure in Miniaturized NIR Spectroscopy Measurements of Food: The Case Study of Sugar. Foods 2023, 12, 493. [Google Scholar] [CrossRef] [PubMed]
- Leger, M.N.; Vega-Montoto, L.; Wentzell, P.D. Methods for Systematic Investigation of Measurement Error Covariance Matrices. Chemom. Intell. Lab. Syst. 2005, 77, 181–205. [Google Scholar] [CrossRef]
- Allegrini, F.; Wentzell, P.D.; Olivieri, A.C. Generalized Error-Dependent Prediction Uncertainty in Multivariate Calibration. Anal. Chim. Acta 2016, 903, 51–60. [Google Scholar] [CrossRef]
- Allegrini, F.; Braga, J.W.B.; Moreira, A.C.O.; Olivieri, A.C. Error Covariance Penalized Regression: A Novel Multivariate Model Combining Penalized Regression with Multivariate Error Structure. Anal. Chim. Acta 2018, 1011, 20–27. [Google Scholar] [CrossRef] [PubMed]
- Schoot, M.; Alewijn, M.; Weesepoel, Y.; Mueller-Maatsch, J.; Kapper, C.; Postma, G.; Buydens, L.; Jansen, J. Predicting the Performance of Handheld Near-Infrared Photonic Sensors from a Master Benchtop Device. Anal. Chim. Acta 2022, 1203, 339707. [Google Scholar] [CrossRef]
- Olivieri, A.C.; Faber, N.M.; Ferré, J.; Boqué, R.; Kalivas, J.H.; Mark, H. Uncertainty Estimation and Figures of Merit for Multivariate Calibration: (IUPAC Technical Report). Pure Appl. Chem. 2006, 78, 633–661. [Google Scholar] [CrossRef]
- Andrews, D.T.; Wentzell, P.D. Applications of Maximum Likelihood Principal Component Analysis: Incomplete Data Sets and Calibration Transfer. Anal. Chim. Acta 1997, 350, 341–352. [Google Scholar] [CrossRef]
- Gorla, G.; Taiana, A.; Boqué, R.; Bani, P.; Gachiuta, O.; Giussani, B. Unravelling Error Sources in Miniaturized NIR Spectroscopic Measurements: The Case Study of Forages. Anal. Chim. Acta 2022, 1211, 339900. [Google Scholar] [CrossRef] [PubMed]
- Bertinetto, C.G.; Schoot, M.; Dingemans, M.; Meeuwsen, W.; Buydens, L.M.C.; Jansen, J.J. Influence of Measurement Procedure on the Use of a Handheld NIR Spectrophotometer. Food Res. Int. 2022, 161, 111836. [Google Scholar] [CrossRef]
- Gorla, G.; Taborelli, P.; Ahmed, H.J.; Alamprese, C.; Grassi, S.; Boqué, R.; Riu, J.; Giussani, B. Miniaturized NIR Spectrometers in a Nutshell: Shining Light over Sources of Variance. Chemosensors 2023, 11, 182. [Google Scholar] [CrossRef]
- McVey, C.; Gordon, U.; Haughey, S.A.; Elliott, C.T. Assessment of the Analytical Performance of Three Near-Infrared Spectroscopy Instruments (Benchtop, Handheld and Portable) through the Investigation of Coriander Seed Authenticity. Foods 2021, 10, 956. [Google Scholar] [CrossRef] [PubMed]
- Camacho, J.; Díaz, C.; Sánchez-Rovira, P. Permutation Tests for ASCA in Multivariate Longitudinal Intervention Studies. J. Chemom. 2023, 37, e3398. [Google Scholar] [CrossRef]
- Wentzell, P.D.; Cleary, C.S.; Kompany-Zareh, M. Improved Modeling of Multivariate Measurement Errors Based on the Wishart Distribution. Anal. Chim. Acta 2017, 959, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Brown, C.D.; Vega-Montoto, L.; Wentzell, P.D. Derivative Preprocessing and Optimal Corrections for Baseline Drift in Multivariate Calibration. Appl. Spectrosc. 2000, 54, 1055–1068. [Google Scholar] [CrossRef]
- Hadoux, X.; Gorretta, N.; Roger, J.M.; Bendoula, R.; Rabatel, G. Comparison of the Efficacy of Spectral Pre-Treatments for Wheat and Weed Discrimination in Outdoor Conditions. Comput. Electron. Agric. 2014, 108, 242–249. [Google Scholar] [CrossRef]
- Oliveri, P.; Malegori, C.; Simonetti, R.; Casale, M. The Impact of Signal Pre-Processing on the Final Interpretation of Analytical Outcomes—A Tutorial. Anal. Chim. Acta 2019, 1058, 9–17. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Bertinetto, C.; Engel, J.; Jansen, J. ANOVA Simultaneous Component Analysis: A Tutorial Review. Anal. Chim. Acta X 2020, 6, 100061. [Google Scholar] [CrossRef]
- Zwanenburg, G.; Hoefsloot, H.C.J.; Westerhuis, J.A.; Jansen, J.J.; Smilde, A.K. ANOVA–Principal Component Analysis and ANOVA–Simultaneous Component Analysis: A Comparison. J. Chemom. 2011, 25, 561–567. [Google Scholar] [CrossRef]
- Smilde, A.K.; Hoefsloot, H.C.J.; Westerhuis, J.A. The Geometry of ASCA. J. Chemom. 2008, 22, 464–471. [Google Scholar] [CrossRef]
- D’alessandro, A.; Ballestrieri, D.; Strani, L.; Cocchi, M.; Durante, C. Characterization of Basil Volatile Fraction and Study of Its Agronomic Variation by Asca. Molecules 2021, 26, 3842. [Google Scholar] [CrossRef] [PubMed]
- Brereton, R.G.; Jansen, J.; Lopes, J.; Marini, F.; Pomerantsev, A.; Rodionova, O.; Roger, J.M.; Walczak, B.; Tauler, R. Chemometrics in Analytical Chemistry—Part I: History, Experimental Design and Data Analysis Tools. Anal. Bioanal. Chem. 2017, 409, 5891–5899. [Google Scholar] [CrossRef] [PubMed]
- Brereton, R.G.; Jansen, J.; Lopes, J.; Marini, F.; Pomerantsev, A.; Rodionova, O.; Roger, J.M.; Walczak, B.; Tauler, R. Chemometrics in Analytical Chemistry—Part II: Modeling, Validation, and Applications. Anal. Bioanal. Chem. 2018, 410, 6691–6704. [Google Scholar] [CrossRef] [PubMed]
- Rinnan, Å.; Van Den Berg, F.; Engelsen, S.B. Review of the Most Common Pre-Processing Techniques for near-Infrared Spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Todeschini, R.; Consonni, V.; Maiocchi, A. The K Correlation Index: Theory Development and Its Application in Chemometrics. Chemom. Intell. Lab. Syst. 1999, 46, 13–29. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E.; Eddins, S.L. Digital Image Processing Using Matlab; Education 624; Prentice-Hall, Inc.: Saddle River, NJ, USA, 2003. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Preprocessing | Sample | Integrating Sphere | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Factors | Interactions | Residuals | |||||||
| Order of Replicates | Session | Timing of Background | Order of Replicates × Session | Order of Replicates × Timing of Background | Session × Timing of Background | ||||
| Effect (percentage contribution to the sum of squares) | None | Sample 1 | 16.15 | 2.70 | 4.97 | 25.10 | 15.09 | 2.15 | 33.84 |
| Sample 2 | 13.02 | 15.61 | 4.61 | 30.30 | 9.00 | 7.72 | 19.74 | ||
| Sample 3 | 6.20 | 42.58 | 14.08 | 15.00 | 5.48 | 5.81 | 10.85 | ||
| Sample 4 | 11.61 | 8.17 | 8.33 | 17.24 | 7.18 | 34.5176 | 12.95 | ||
| SNV | Sample 1 | 6.74 | 10.30 | 8.83 | 22.07 | 19.81 | 6.32 | 25.92 | |
| Sample 2 | 6.12 | 27.68 | 28.29 | 12.16 | 3.23 | 15.84 | 6.69 | ||
| Sample 3 | 2.35 | 35.71 | 6.96 | 5.89 | 2.21 | 41.54 | 5.33 | ||
| Sample 4 | 4.46 | 16.27 | 16.13 | 9.17 | 4.01 | 41.71 | 8.25 | ||
| First derivative | Sample 1 | 11.34 | 10.87 | 15.10 | 20.25 | 11.55 | 8.25 | 22.63 | |
| Sample 2 | 8.81 | 16.59 | 18.60 | 18.87 | 5.19 | 21.83 | 10.11 | ||
| Sample 3 | 4.75 | 27.55 | 4.63 | 10.66 | 4.21 | 40.39 | 7.81 | ||
| Sample 4 | 5.06 | 14.48 | 19.77 | 11.58 | 5.04 | 33.94 | 10.13 | ||
| Preprocessing | Sample | Optical Fiber | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Factors | Interactions | Residuals | |||||||
| Order of Replicates | Session | Timing of Background | Order of Replicates × Session | Order of Replicates × Timing of Background | Session × Timing of Background | ||||
| Effect (percentage contribution to the sum of squares) | None | Sample 1 | 10.07 | 2.94 | 0.56 | 30.43 | 17.44 | 8.28 | 30.28 |
| Sample 2 | 25.73 | 3.41 | 1.65 | 39.52 | 12.83 | 0.78 | 16.08 | ||
| Sample 3 | 12.50 | 13.45 | 21.98 | 19.16 | 10.41 | 3.25 | 19.26 | ||
| Sample 4 | 16.37 | 4.36 | 1.76 | 35.83 | 13.46 | 3.77 | 24.45 | ||
| SNV | Sample 1 | 8.52 | 13.03 | 8.52 | 17.48 | 10.06 | 23.53 | 18.87 | |
| Sample 2 | 25.73 | 3.41 | 1.65 | 39.52 | 12.83 | 0.78 | 16.08 | ||
| Sample 3 | 7.71 | 3.40 | 17.58 | 20.98 | 10.66 | 15.25 | 24.42 | ||
| Sample 4 | 15.76 | 6.64 | 8.44 | 19.68 | 17.02 | 4.05 | 28.41 | ||
| First derivative | Sample 1 | 6.61 | 27.31 | 19.27 | 11.45 | 5.13 | 20.02 | 10.21 | |
| Sample 2 | 25.73 | 3.41 | 1.65 | 39.52 | 12.83 | 0.78 | 16.08 | ||
| Sample 3 | 6.66 | 5.13 | 20.35 | 22.60 | 7.99 | 13.01 | 24.26 | ||
| Sample 4 | 16.59 | 7.47 | 3.45 | 19.56 | 18.65 | 2.34 | 31.93 | ||
| Preprocessing | Sample | Factors | Interactions | Residuals | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Order of Replicates | Session | Power Supply | Timing of Background | Order of Replicates × Session | Order of Replicates × Power Supply | Order of Replicates × Timing of Background | Session × Power Supply | Session × Timing of Background | Power Supply × Timing of Background | ||||
| Effect (percentage contribution to the sum of squares) | None | Sample 1 | 6.67 | 9.61 | 0.47 | 0.58 | 14.62 | 6.89 | 6.27 | 1.03 | 3.56 | 3.36 | 46.94 |
| Sample 2 | 4.97 | 1.43 | 0.59 | 10.97 | 12.47 | 3.60 | 6.44 | 6.29 | 6.79 | 14.58 | 31.84 | ||
| Sample 3 | 3.05 | 19.64 | 11.13 | 10.28 | 7.27 | 1.97 | 2.33 | 1.62 | 2.83 | 10.98 | 28.93 | ||
| Sample 4 | 1.07 | 2.31 | 15.76 | 6.60 | 0.85 | 0.76 | 1.25 | 16.56 | 22.75 | 3.12 | 28.98 | ||
| SNV | Sample 1 | 5.22 | 8.91 | 3.17 | 1.54 | 15.07 | 7.93 | 4.74 | 2.39 | 4.67 | 1.19 | 45.17 | |
| Sample 2 | 4.91 | 4.79 | 3.59 | 2.15 | 8.91 | 3.69 | 3.61 | 6.94 | 7.49 | 9.81 | 44.10 | ||
| Sample 3 | 5.31 | 10.99 | 17.67 | 16.42 | 10.99 | 1.44 | 1.93 | 1.74 | 2.51 | 3.39 | 27.59 | ||
| Sample 4 | 0.70 | 2.32 | 6.65 | 4.33 | 1.04 | 0.50 | 0.61 | 19.59 | 22.10 | 4.87 | 37.28 | ||
| First derivative | Sample 1 | 7.13 | 3.23 | 0.72 | 0.40 | 15.99 | 6.30 | 7.51 | 1.89 | 4.63 | 0.48 | 51.72 | |
| Sample 2 | 5.02 | 3.30 | 4.66 | 7.54 | 10.01 | 4.74 | 4.70 | 4.11 | 5.83 | 10.32 | 39.77 | ||
| Sample 3 | 6.02 | 8.33 | 16.21 | 16.48 | 10.48 | 1.93 | 2.88 | 3.54 | 3.87 | 5.30 | 24.97 | ||
| Sample 4 | 0.88 | 3.36 | 8.19 | 7.35 | 1.71 | 1.00 | 0.88 | 17.62 | 18.30 | 8.40 | 32.32 | ||
| Integrating Sphere | Optical Fiber | |||||
|---|---|---|---|---|---|---|
| Preprocessing | None | SNV | First Derivative | None | SNV | First Derivative |
| Sample 1 | 0.972 | 0.864 | 0.837 | 0.995 | 0.854 | 0.840 |
| Sample 2 | 0.985 | 0.873 | 0.848 | 0.999 | 0.917 | 0.891 |
| Sample 3 | 0.982 | 0.916 | 0.863 | 0.986 | 0.968 | 0.950 |
| Sample 4 | 0.979 | 0.942 | 0.896 | 0.984 | 0.971 | 0.957 |
| NeoSpectra Scanner | |||
|---|---|---|---|
| Preprocessing | None | SNV | First Derivative |
| Sample 1 | 0.94 | 0.94 | 0.82 |
| Sample 2 | 0.97 | 0.94 | 0.88 |
| Sample 3 | 0.90 | 0.86 | 0.88 |
| Sample 4 | 0.89 | 0.83 | 0.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gorla, G.; Taborelli, P.; Giussani, B. A Multivariate Analysis-Driven Workflow to Tackle Uncertainties in Miniaturized NIR Data. Molecules 2023, 28, 7999. https://doi.org/10.3390/molecules28247999
Gorla G, Taborelli P, Giussani B. A Multivariate Analysis-Driven Workflow to Tackle Uncertainties in Miniaturized NIR Data. Molecules. 2023; 28(24):7999. https://doi.org/10.3390/molecules28247999
Chicago/Turabian StyleGorla, Giulia, Paolo Taborelli, and Barbara Giussani. 2023. "A Multivariate Analysis-Driven Workflow to Tackle Uncertainties in Miniaturized NIR Data" Molecules 28, no. 24: 7999. https://doi.org/10.3390/molecules28247999
APA StyleGorla, G., Taborelli, P., & Giussani, B. (2023). A Multivariate Analysis-Driven Workflow to Tackle Uncertainties in Miniaturized NIR Data. Molecules, 28(24), 7999. https://doi.org/10.3390/molecules28247999