

Comparison of Multiple NIR Spectrometers for Detecting Low-Concentration Nitrogen-Based Adulteration in Protein Powders


 ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Results
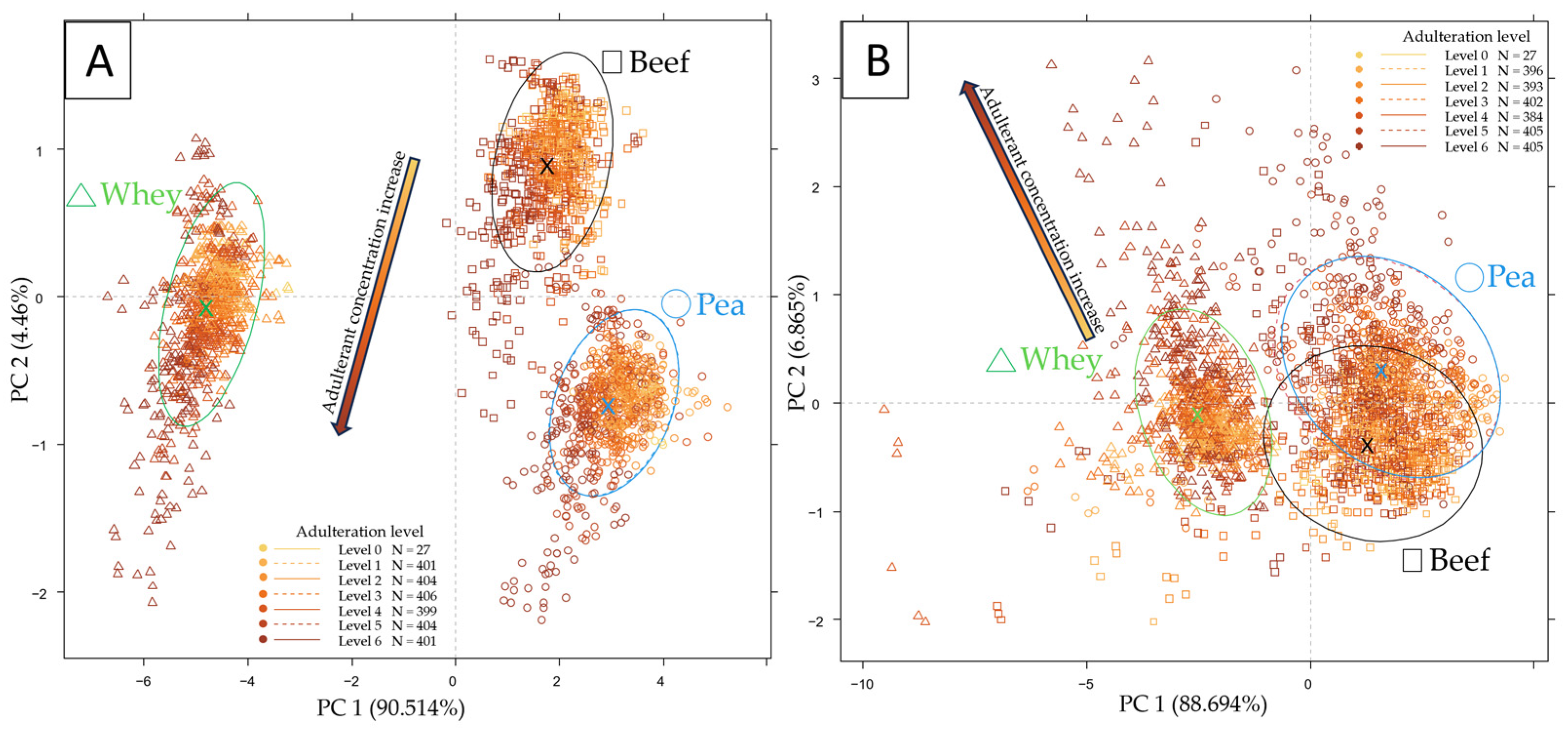
2.1. Exploratory Data Evaluation of the NIR Spectroscopy Results Based on Raw Spectra
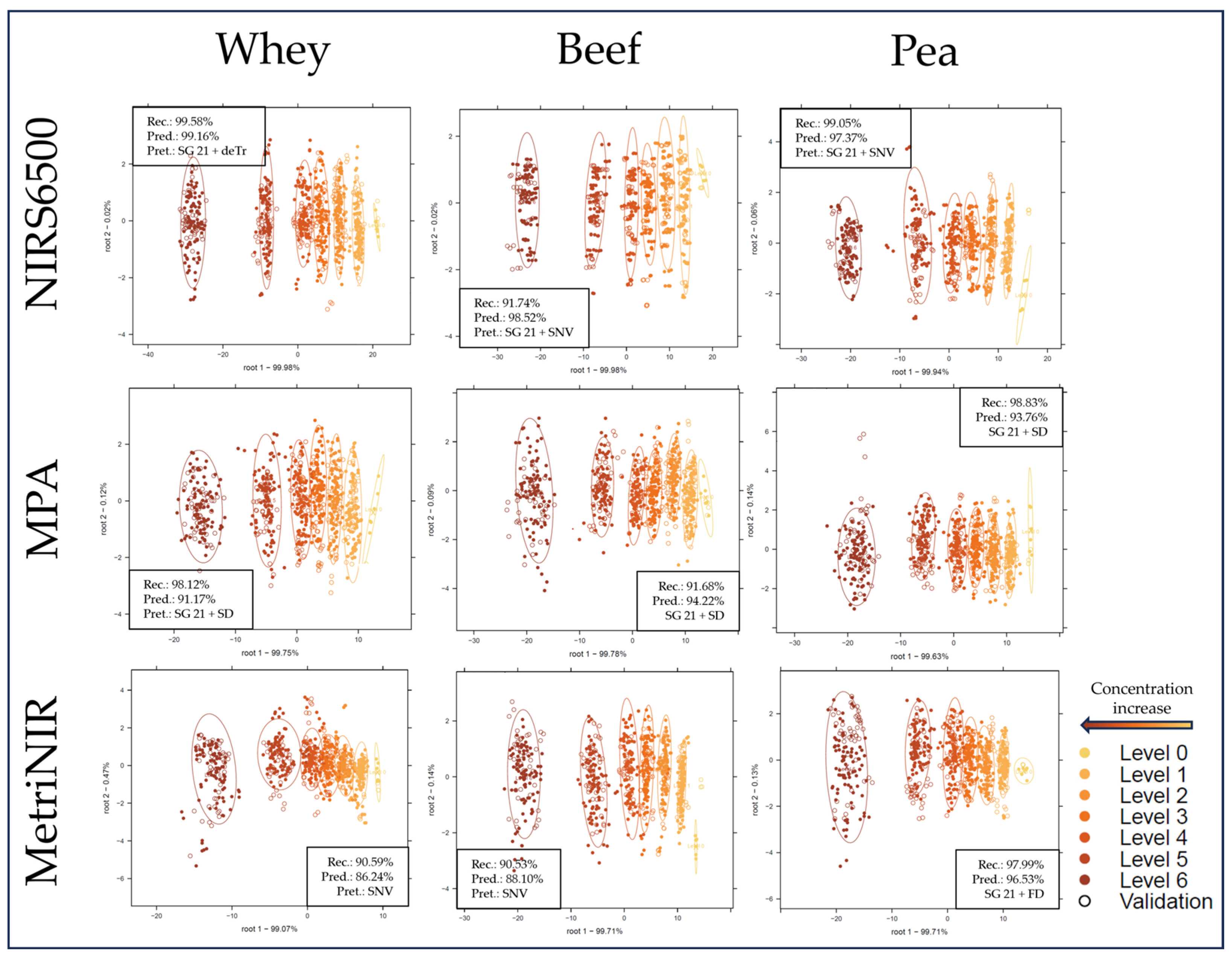
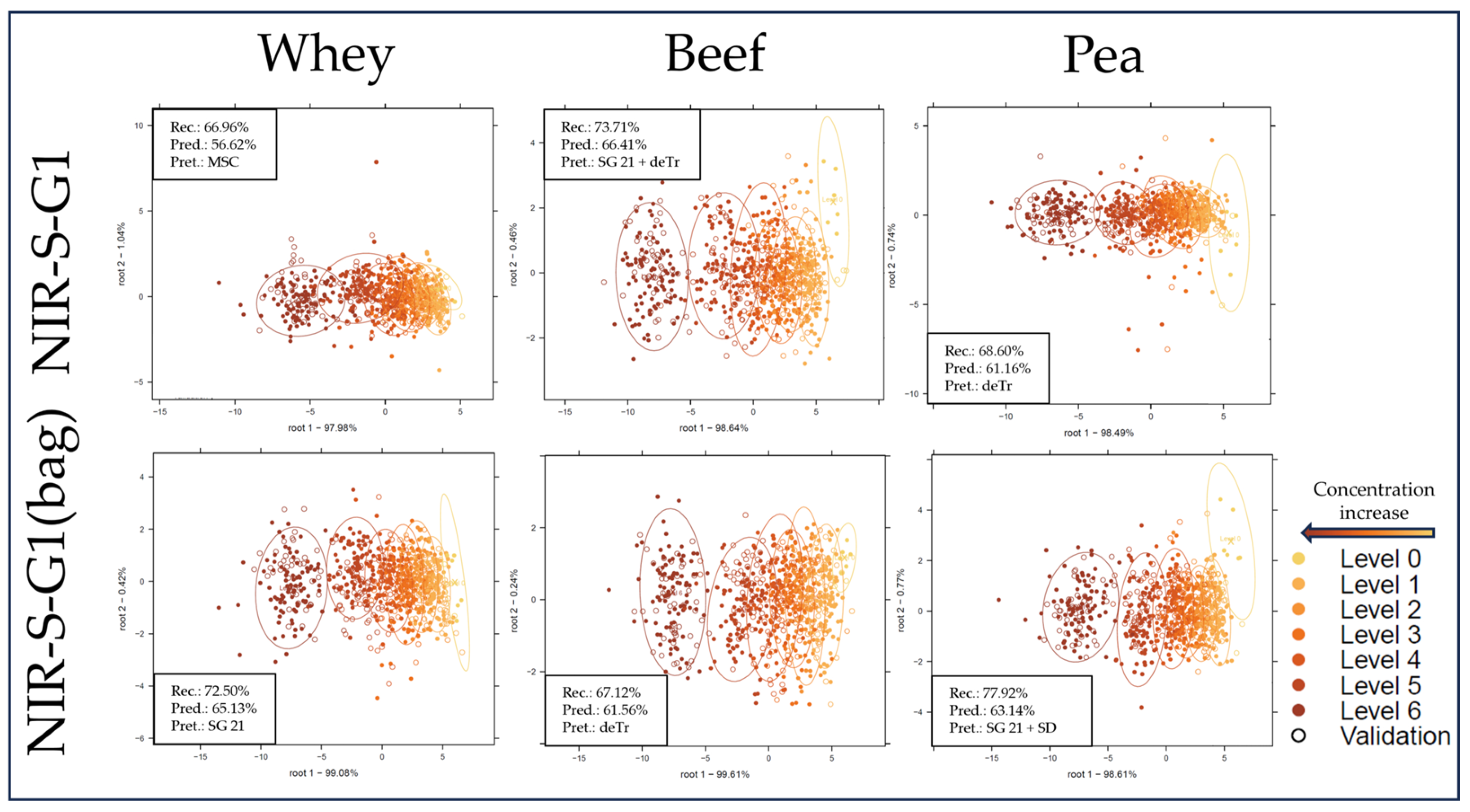
2.2. Supervised Classification of the NIR Spectroscopy Results Based on LDA
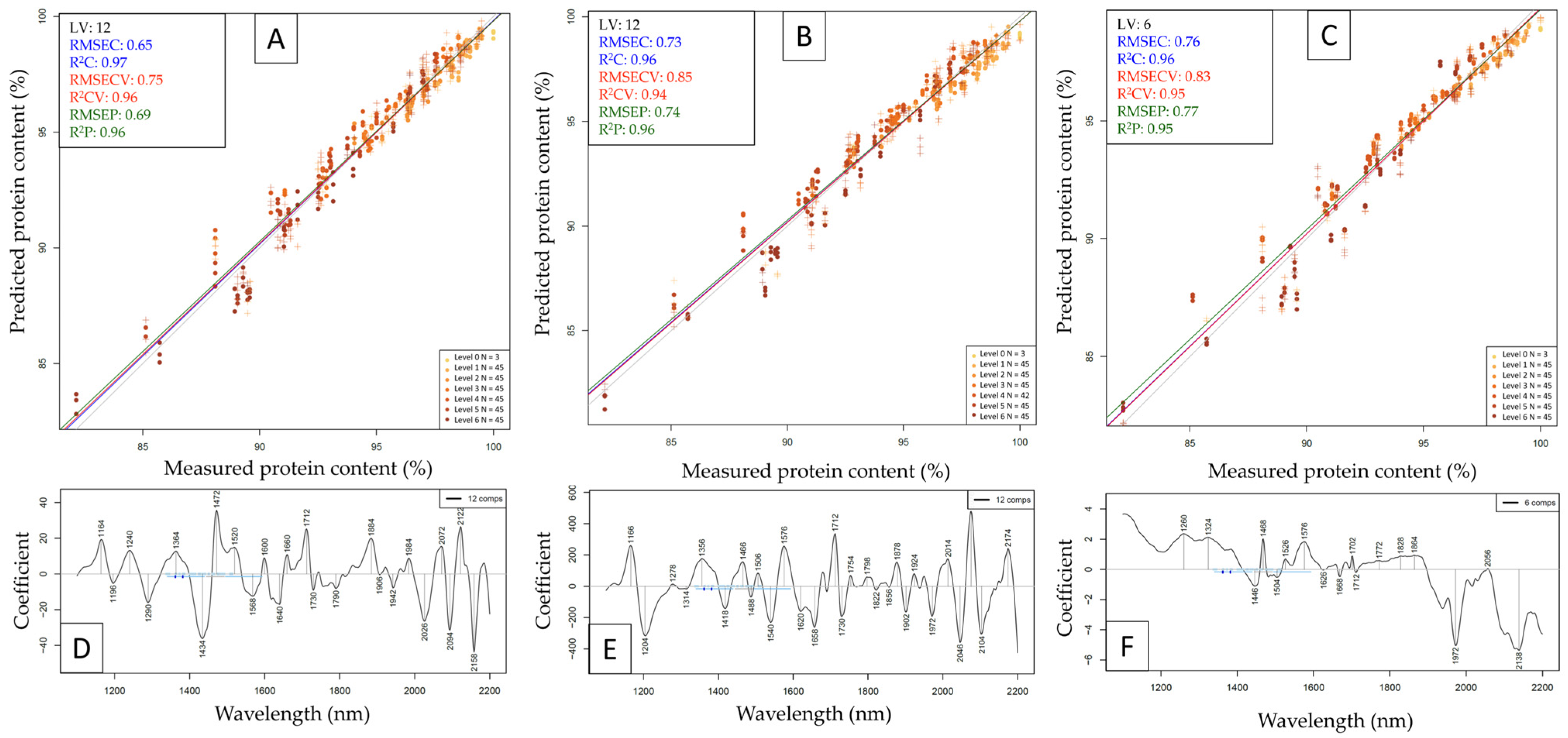
2.3. Building Prediction Models Based on NIR Spectroscopy Results with PLSR
3. Discussion
4. Materials and Methods
4.1. Sample Acquisition
4.2. Sample Preparation
4.3. Near-Infrared Spectroscopy Measurements
4.4. Multivariate Data Analysis of NIRS Spectra
4.4.1. Exploratory Data Analysis
4.4.2. Linear Discriminant Analysis
4.4.3. Partial Least Squares Regression
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zinia Zaukuu, J.-L.; Aouadi, B.; Lukács, M.; Bodor, Z.; Vitális, F.; Gillay, B.; Gillay, Z.; Friedrich, L.; Kovacs, Z. Detecting Low Concentrations of Nitrogen-Based Adulterants in Whey Protein Powder Using Benchtop and Handheld NIR Spectrometers and the Feasibility of Scanning through Plastic Bag. Molecules 2020, 25, 2522. [Google Scholar] [CrossRef]
- Wu, G. Dietary Protein Intake and Human Health. Food Funct. 2016, 7, 1251–1265. [Google Scholar] [CrossRef] [PubMed]
- Andrade, J.; Pereira, C.G.; de Almeida Junior, J.C.; Viana, C.C.R.; de Oliveira Neves, L.N.; da Silva, P.H.F.; Bell, M.J.V.; dos Anjos, V.D.C. FTIR-ATR Determination of Protein Content to Evaluate Whey Protein Concentrate Adulteration. LWT 2019, 99, 166–172. [Google Scholar] [CrossRef]
- Morton, R.W.; Murphy, K.T.; McKellar, S.R.; Schoenfeld, B.J.; Henselmans, M.; Helms, E.; Aragon, A.A.; Devries, M.C.; Banfield, L.; Krieger, J.W.; et al. A Systematic Review, Meta-Analysis and Meta-Regression of the Effect of Protein Supplementation on Resistance Training-Induced Gains in Muscle Mass and Strength in Healthy Adults. Br. J. Sports Med. 2018, 52, 376–384. [Google Scholar] [CrossRef]
- Davies, R.W.; Carson, B.P.; Jakeman, P.M. The Effect of Whey Protein Supplementation on the Temporal Recovery of Muscle Function Following Resistance Training: A Systematic Review and Meta-Analysis. Nutrients 2018, 10, 221. [Google Scholar] [CrossRef]
- Bali, A.; Naik, R. The Impact of a Vegan Diet on Many Aspects of Health: The Overlooked Side of Veganism. Cureus 2023, 15, e35148. [Google Scholar] [CrossRef] [PubMed]
- Mæhre, H.; Dalheim, L.; Edvinsen, G.; Elvevoll, E.; Jensen, I.-J. Protein Determination—Method Matters. Foods 2018, 7, 5. [Google Scholar] [CrossRef]
- Zhang, W.; Xue, J. Economically Motivated Food Fraud and Adulteration in China: An Analysis Based on 1553 Media Reports. Food Control 2016, 67, 192–198. [Google Scholar] [CrossRef]
- Hau, A.K.; Kwan, T.H.; Li, P.K. Melamine Toxicity and the Kidney. J. Am. Soc. Nephrol. 2009, 20, 245–250. [Google Scholar] [CrossRef]
- Tadele, Y.; Amha, N. Use of Different Non Protein Nitrogen Sources in Ruminant Nutrition: A Review. Adv. Life Sci. Technol. 2015, 29, 100–105. [Google Scholar]
- Bock, H.H.-D.; Kowalczyk, J.; Krawielitzki, K.; Völker, T.; Wünsche, J.; Zebrowska, T. Zum Problem Des Harnstoffeinsatzes in Der Schweinefütterung. Arch. Anim. Nutr. 1976, 26, 777–794. [Google Scholar] [CrossRef]
- All About Feed—Swiss Pull False Corn Gluten from Market. Available online: https://www.allaboutfeed.net/animal-feed/feed-additives/swiss-pull-false-corn-gluten-from-market (accessed on 1 February 2024).
- Lukacs, M.; Bazar, G.; Pollner, B.; Henn, R.; Kirchler, C.G.; Huck, C.W.; Kovacs, Z. Near Infrared Spectroscopy as an Alternative Quick Method for Simultaneous Detection of Multiple Adulterants in Whey Protein-Based Sports Supplement. Food Control 2018, 94, 331–340. [Google Scholar] [CrossRef]
- Pustjens, A.M.; Weesepoel, Y.; van Ruth, S.M. Food Fraud and Authenticity. In Innovation and Future Trends in Food Manufacturing and Supply Chain Technologies; Elsevier: Amsterdam, The Netherlands, 2016; pp. 3–20. [Google Scholar]
- Badr, A. Near Infra Red Spectroscopy. In Wide Spectra of Quality Control; InTech: London, UK, 2011. [Google Scholar]
- Heise, H.M.; Burns, D.A.; Ciurczak, E.W. (Eds.) Handbook of Near-Infrared Analysis, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2009; Volume 393, pp. 1387–1389. [Google Scholar] [CrossRef]
- van de Voort, F.R. Fourier Transform Infrared Spectroscopy Applied to Food Analysis. Food Res. Int. 1992, 25, 397–403. [Google Scholar] [CrossRef]
- Gelabert, P.; Pruett, E.; Perrella, G.; Subramanian, S.; Lakshminarayanan, A. DLP NIRscan Nano: An Ultra-Mobile DLP-Based near-Infrared Bluetooth Spectrometer. In Proceedings of the Emerging Digital Micromirror Device Based Systems and Applications VIII, San Francisco, CA, USA, 15 March 2016; Volume 9761, p. 97610B. [Google Scholar]
- Lim, J.; Kim, G.; Mo, C.; Kim, M.S.; Chao, K.; Qin, J.; Fu, X.; Baek, I.; Cho, B.-K. Detection of Melamine in Milk Powders Using Near-Infrared Hyperspectral Imaging Combined with Regression Coefficient of Partial Least Square Regression Model. Talanta 2016, 151, 183–191. [Google Scholar] [CrossRef] [PubMed]
- Khilare, V.; Tiknaik, A.; Prakash, B.; Ughade, B.; Korhale, G.; Nalage, D.; Ahmed, N.; Khedkar, C.; Khedkar, G. Multiple Tests on Saffron Find New Adulterant Materials and Reveal That Ist Grade Saffron Is Rare in the Market. Food Chem. 2019, 272, 635–642. [Google Scholar] [CrossRef]
- Zaukuu, J.Z.; Soós, J.; Bodor, Z.; Felföldi, J.; Magyar, I.; Kovacs, Z. Authentication of Tokaj Wine (Hungaricum) with the Electronic Tongue and Near Infrared Spectroscopy. J. Food Sci. 2019, 84, 3437–3444. [Google Scholar] [CrossRef]
- Barbin, D.F.; de Souza Madureira Felicio, A.L.; Sun, D.-W.; Nixdorf, S.L.; Hirooka, E.Y. Application of Infrared Spectral Techniques on Quality and Compositional Attributes of Coffee: An Overview. Food Res. Int. 2014, 61, 23–32. [Google Scholar] [CrossRef]
- Peng, B.; Ge, N.; Cui, L.; Zhao, H. Monitoring of Alcohol Strength and Titratable Acidity of Apple Wine during Fermentation Using Near-Infrared Spectroscopy. LWT Food Sci. Technol. 2016, 66, 86–92. [Google Scholar] [CrossRef]
- Bodor, Z.; Benedek, C.; Kaszab, T.; Zaukuu, J.-L.Z.; Kertész, I.; Kovacs, Z. Classical and Correlative Analytical Methods for Origin Identification of Hungarian Honeys. Acta Aliment. 2019, 48, 477–487. [Google Scholar] [CrossRef]
- Fodor, M.; Mikola, E.E.; Geösel, A.; Stefanovits-Bányai, É.; Mednyánszky, Z. Application of Near-Infrared Spectroscopy to Investigate Some Endogenic Properties of Pleurotus Ostreatus Cultivars. Sensors 2020, 20, 6632. [Google Scholar] [CrossRef]
- Sohn, S.-I.; Pandian, S.; Zaukuu, J.-L.Z.; Oh, Y.-J.; Lee, Y.-H.; Shin, E.-K.; Thamilarasan, S.K.; Kang, H.-J.; Ryu, T.-H.; Cho, W.-S. Rapid Discrimination of Brassica Napus Varieties Using Visible and Near-Infrared (Vis-NIR) Spectroscopy. J. King Saud Univ. Sci. 2023, 35, 102495. [Google Scholar] [CrossRef]
- Mialon, N.; Roig, B.; Capodanno, E.; Cadiere, A. Untargeted Metabolomic Approaches in Food Authenticity: A Review That Showcases Biomarkers. Food Chem. 2023, 398, 133856. [Google Scholar] [CrossRef]
- Ansari, M.J.; Al-Ghamdi, A.; Khan, K.A.; Adgaba, N.; El-Ahmady, S.H.; Gad, H.A.; Roshan, A.; Meo, S.A.; Kolyali, S. Validation of Botanical Origins and Geographical Sources of Some Saudi Honeys Using Ultraviolet Spectroscopy and Chemometric Analysis. Saudi J. Biol. Sci. 2018, 25, 377–382. [Google Scholar] [CrossRef]
- Erasmus, S.W.; van Hasselt, L.; Ebbinge, L.M.; van Ruth, S.M. Real or Fake Yellow in the Vibrant Colour Craze: Rapid Detection of Lead Chromate in Turmeric. Food Control 2021, 121, 107714. [Google Scholar] [CrossRef]
- Fan, W.; Liang, Y.; Yuan, D.; Wang, J. Calibration Model Transfer for Near-Infrared Spectra Based on Canonical Correlation Analysis. Anal. Chim. Acta 2008, 623, 22–29. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Lou, X.; Yang, H.; Yang, H.; Liu, C.; Wu, J.; Bin, J. Improved Calibration Transfer between Near-Infrared (NIR) Spectrometers Using Canonical Correlation Analysis. Anal. Lett. 2019, 52, 2188–2202. [Google Scholar] [CrossRef]
- Bin, J.; Yan, X.; Liu, R.; Kang, C.; Chen, Y. Calibration Transfer for Near-Infrared (NIR) Spectroscopy Based on Local Preserving Projection. Vib. Spectrosc. 2023, 126, 103538. [Google Scholar] [CrossRef]
- Esbensen, K.H.; Geladi, P.; Larsen, A. Myth: Light Travels to and from the Sample in a Fibre-Optic Cable without Problems. NIR News 2014, 25, 25–26. [Google Scholar] [CrossRef]
- Karunathilaka, S.R.; Yakes, B.J.; He, K.; Chung, J.K.; Mossoba, M. Non-Targeted NIR Spectroscopy and SIMCA Classification for Commercial Milk Powder Authentication: A Study Using Eleven Potential Adulterants. Heliyon 2018, 4, e00806. [Google Scholar] [CrossRef]
- Zhang, L.-G.; Zhang, X.; Ni, L.-J.; Xue, Z.-B.; Gu, X.; Huang, S.-X. Rapid Identification of Adulterated Cow Milk by Non-Linear Pattern Recognition Methods Based on near Infrared Spectroscopy. Food Chem. 2014, 145, 342–348. [Google Scholar] [CrossRef]
- Khan, K.M.; Krishna, H.; Majumder, S.K.; Gupta, P.K. Detection of Urea Adulteration in Milk Using Near-Infrared Raman Spectroscopy. Food Anal. Methods 2015, 8, 93–102. [Google Scholar] [CrossRef]
- Mauer, L.J.; Chernyshova, A.A.; Hiatt, A.; Deering, A.; Davis, R. Melamine Detection in Infant Formula Powder Using Near- and Mid-Infrared Spectroscopy. J. Agric. Food Chem. 2009, 57, 3974–3980. [Google Scholar] [CrossRef]
- Jiao, X.; Meng, Y.; Wang, K.; Huang, W.; Li, N.; Liu, T.C.Y. Rapid Detection of Adulterants in Whey Protein Supplement by Raman Spectroscopy Combined with Multivariate Analysis. Molecules 2019, 24, 1889. [Google Scholar] [CrossRef]
- Bishop, C. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2007; ISBN 0387310738. [Google Scholar]
- Balabin, R.M.; Smirnov, S.V. Melamine Detection by Mid- and near-Infrared (MIR/NIR) Spectroscopy: A Quick and Sensitive Method for Dairy Products Analysis Including Liquid Milk, Infant Formula, and Milk Powder. Talanta 2011, 85, 562–568. [Google Scholar] [CrossRef]
- Beć, K.B.; Grabska, J.; Siesler, H.W.; Huck, C.W. Handheld Near-Infrared Spectrometers: Where Are We Heading? NIR News 2020, 31, 28–35. [Google Scholar] [CrossRef]
- Bayer, A.; Bachmann, M.; Müller, A.; Kaufmann, H. A Comparison of Feature-Based MLR and PLS Regression Techniques for the Prediction of Three Soil Constituents in a Degraded South African Ecosystem. Appl. Environ. Soil. Sci. 2012, 2012, 971252. [Google Scholar] [CrossRef]
- EFSA Panel on Contaminants in the Food Chain (CONTAM); EFSA Panel on Food Contact Materials, Enzymes, Flavourings and Processing Aids (CEF). Scientific Opinion on Melamine in Food and Feed. EFSA J. 2010, 8, 1573. [Google Scholar] [CrossRef]
- Bhandari, S.D.; Gallegos-Peretz, T.; Wheat, T.; Jaudzems, G.; Kouznetsova, N.; Petrova, K.; Shah, D.; Hengst, D.; Vacha, E.; Lu, W.; et al. Amino Acid Fingerprinting of Authentic Nonfat Dry Milk and Skim Milk Powder and Effects of Spiking with Selected Potential Adulterants. Foods 2022, 11, 2868. [Google Scholar] [CrossRef] [PubMed]
- Næs, T. A User-Friendly Guide to Multivariate Calibration and Classification; NIR Publications: Chichester, UK, 2002; ISBN 0952866625. [Google Scholar]
- Cowe, I.A.; McNicol, J.W. The Use of Principal Components in the Analysis of Near-Infrared Spectra. Appl. Spectrosc. 1985, 39, 257–266. [Google Scholar] [CrossRef]
- Gowen, A.; Downey, G.; Esquerre, C.; O’Donnell, C. Preventing Over-Fitting in PLS Calibration Models of near-Infrared (NIR) Spectroscopy Data Using Regression Coefficients. J. Chemom. 2011, 25, 375–381. [Google Scholar] [CrossRef]
- Allegrini, F.; Olivieri, A.C. IUPAC-Consistent Approach to the Limit of Detection in Partial Least-Squares Calibration. Anal. Chem. 2014, 86, 7858–7866. [Google Scholar] [CrossRef] [PubMed]
- Olivieri, A.C.; Faber, N.M.; Ferré, J.; Boqué, R.; Kalivas, J.H.; Mark, H. Uncertainty Estimation and Figures of Merit for Multivariate Calibration: (IUPAC Technical Report). Pure Appl. Chem. 2006, 78, 633–661. [Google Scholar] [CrossRef]
- Olivieri, A.C. Analytical Figures of Merit: From Univariate to Multiway Calibration. Chem. Rev. 2014, 114, 5358–5378. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Whey | Beef | Pea | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instrument | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) |
| Range (wl) | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 |
| Pre-treat. | SG 15 + SNV | SG 21 + SC | SG 35 + SNV | SG 21 + SNV | SG 25 + SNV | SG 21 + SC | SG 41 + SNV | SG 35 + SNV | SG 11 + SNV | SG 21 + SNV | SG 5 + SNV | SG 21 + SNV | SG 35 + SNV | SG 19 + SNV | SG 27 + SNV |
| LV | 12 | 4 | 6 | 5 | 7 | 12 | 11 | 5 | 7 | 6 | 6 | 10 | 6 | 10 | 7 |
| RMSEC | 0.65 | 1.05 | 1.09 | 1.52 | 1.22 | 0.71 | 0.86 | 0.97 | 1.21 | 1.24 | 0.76 | 0.74 | 0.90 | 1.16 | 1.22 |
| R2C | 0.97 | 0.92 | 0.91 | 0.82 | 0.89 | 0.96 | 0.94 | 0.93 | 0.89 | 0.88 | 0.96 | 0.96 | 0.94 | 0.90 | 0.89 |
| RMSECV | 0.71 | 1.07 | 1.14 | 1.58 | 1.26 | 0.79 | 0.91 | 1.01 | 1.25 | 1.30 | 0.81 | 0.79 | 0.94 | 1.22 | 1.26 |
| R2CV | 0.96 | 0.91 | 0.90 | 0.81 | 0.88 | 0.95 | 0.94 | 0.92 | 0.88 | 0.87 | 0.95 | 0.95 | 0.93 | 0.89 | 0.88 |
| Whey | Beef | Pea | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instrument | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) |
| Range (wl) | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 |
| Pre-treat. | SG 9 + SNV | SG 21 + 2der | SG 9 + SNV | SG 15 + SNV | SG 11 + SNV | SNV | SG 21 + SC | SG 21 + SNV | SG 11 + SNV | SG 21 + SNV | SNV | SG 31 + SC | SG 5 + SNV | SG 11 + SNV | SG 15 + SNV |
| LV | 4 | 3 | 5 | 8 | 7 | 5 | 6 | 4 | 10 | 8 | 5 | 12 | 4 | 10 | 7 |
| RMSEC | 0.19 | 0.20 | 0.20 | 0.27 | 0.23 | 0.18 | 0.17 | 0.21 | 0.24 | 0.25 | 0.19 | 0.15 | 0.20 | 0.23 | 0.24 |
| C | 0.95 | 0.95 | 0.94 | 0.90 | 0.93 | 0.96 | 0.96 | 0.94 | 0.92 | 0.91 | 0.95 | 0.97 | 0.94 | 0.93 | 0.92 |
| RMSECV | 0.19 | 0.21 | 0.21 | 0.28 | 0.24 | 0.18 | 0.18 | 0.23 | 0.25 | 0.26 | 0.19 | 0.16 | 0.21 | 0.24 | 0.25 |
| R2CV | 0.95 | 0.94 | 0.94 | 0.89 | 0.92 | 0.95 | 0.95 | 0.93 | 0.91 | 0.91 | 0.95 | 0.96 | 0.94 | 0.92 | 0.91 |
| LODmin | 0.08 | 0.14 | 0.09 | 0.27 | 0.25 | 0.04 | 0.06 | 0.20 | 0.26 | 0.46 | 0.04 | 0.08 | 0.16 | 0.26 | 0.30 |
| LODmax | 0.15 | 0.20 | 0.18 | 0.50 | 0.40 | 0.13 | 0.15 | 0.24 | 0.47 | 0.53 | 0.13 | 0.17 | 0.21 | 0.37 | 0.35 |
| LOQmin | 0.24 | 0.43 | 0.26 | 0.82 | 0.75 | 0.13 | 0.17 | 0.60 | 0.77 | 1.37 | 0.13 | 0.25 | 0.48 | 0.78 | 0.90 |
| LOQmax | 0.45 | 0.60 | 0.55 | 1.51 | 1.19 | 0.39 | 0.44 | 0.73 | 1.42 | 1.60 | 0.40 | 0.52 | 0.63 | 1.11 | 1.06 |
| Whey | Beef | Pea | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instrument | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) |
| Range (wl) | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 |
| Pre-treat. | SNV | SG 25 + SNV | SG 21 + SNV | SG 9 + SNV | SG 15 + SNV | SC | SG 21 + SNV | SG 21 + SNV | SG 5 + deTr | SG 11 + SNV | SNV | SG 21 + SNV | SG 21 + SNV | SG 15 + SC | SG 19 + SNV |
| LV | 6 | 6 | 6 | 7 | 7 | 6 | 6 | 6 | 6 | 7 | 4 | 6 | 6 | 10 | 9 |
| RMSEC | 0.14 | 0.16 | 0.15 | 0.24 | 0.24 | 0.16 | 0.16 | 0.15 | 0.23 | 0.26 | 0.17 | 0.16 | 0.14 | 0.24 | 0.22 |
| R2C | 0.94 | 0.93 | 0.94 | 0.83 | 0.83 | 0.93 | 0.92 | 0.94 | 0.85 | 0.81 | 0.91 | 0.93 | 0.94 | 0.84 | 0.86 |
| RMSECV | 0.15 | 0.16 | 0.16 | 0.25 | 0.26 | 0.17 | 0.17 | 0.16 | 0.23 | 0.27 | 0.18 | 0.17 | 0.15 | 0.24 | 0.23 |
| R2CV | 0.94 | 0.92 | 0.93 | 0.82 | 0.81 | 0.92 | 0.92 | 0.93 | 0.84 | 0.80 | 0.91 | 0.92 | 0.94 | 0.83 | 0.84 |
| LODmin | 0.03 | 0.04 | 0.07 | 0.33 | 0.25 | 0.03 | 0.06 | 0.10 | 0.33 | 0.31 | 0.07 | 0.05 | 0.08 | 0.26 | 0.24 |
| LODmax | 0.13 | 0.21 | 0.21 | 0.55 | 0.40 | 0.12 | 0.15 | 0.18 | 0.55 | 0.45 | 0.15 | 0.15 | 0.17 | 0.37 | 0.29 |
| LOQmin | 0.10 | 0.12 | 0.22 | 1.00 | 0.75 | 0.10 | 0.17 | 0.29 | 1.00 | 0.94 | 0.20 | 0.16 | 0.24 | 0.78 | 0.71 |
| LOQmax | 0.40 | 0.64 | 0.64 | 1.66 | 1.19 | 0.37 | 0.44 | 0.55 | 1.66 | 1.35 | 0.46 | 0.46 | 0.52 | 1.11 | 0.87 |
| Whey | Beef | Pea | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instrument | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) |
| Range (wl) | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 |
| Pre-treat. | SG 21 + SC | SG 31 + SNV | SG 21 + SNV | SG 27 + SNV | SG 15 + SNV | SC | SG 21 + SNV | SG 35 + SNV | SG 11 + SNV | SG 21 + SNV | SNV | SG 21 + SNV | SG 35 + SNV | SG 21 + SNV | SG 15 + SNV |
| LV | 11 | 11 | 6 | 10 | 8 | 4 | 6 | 6 | 8 | 10 | 4 | 6 | 6 | 9 | 8 |
| RMSEC | 0.35 | 0.71 | 0.88 | 1.26 | 1.24 | 0.51 | 0.78 | 0.82 | 1.18 | 1.18 | 0.48 | 0.74 | 0.77 | 1.14 | 1.24 |
| R2C | 0.97 | 0.96 | 0.94 | 0.87 | 0.88 | 0.94 | 0.95 | 0.95 | 0.89 | 0.89 | 0.95 | 0.96 | 0.95 | 0.90 | 0.88 |
| RMSECV | 0.40 | 0.80 | 0.93 | 1.32 | 1.29 | 0.53 | 0.84 | 0.87 | 1.23 | 1.22 | 0.50 | 0.79 | 0.82 | 1.19 | 1.29 |
| R2CV | 0.96 | 0.95 | 0.93 | 0.86 | 0.87 | 0.94 | 0.94 | 0.94 | 0.88 | 0.88 | 0.94 | 0.95 | 0.95 | 0.89 | 0.87 |
| LODmin | 0.06 | 0.03 | 0.07 | 0.23 | 0.24 | 0.08 | 0.06 | 0.10 | 0.23 | 0.30 | 0.07 | 0.06 | 0.08 | 0.30 | 0.31 |
| LODmax | 0.18 | 0.31 | 0.25 | 0.45 | 0.39 | 0.16 | 0.15 | 0.18 | 0.45 | 0.38 | 0.15 | 0.15 | 0.18 | 0.40 | 0.36 |
| LOQmin | 0.18 | 0.10 | 0.22 | 0.70 | 0.71 | 0.23 | 0.18 | 0.29 | 0.70 | 0.91 | 0.20 | 0.17 | 0.24 | 0.89 | 0.93 |
| LOQmax | 0.54 | 0.94 | 0.75 | 1.34 | 1.17 | 0.47 | 0.45 | 0.55 | 1.34 | 1.15 | 0.46 | 0.46 | 0.54 | 1.20 | 1.08 |
| Whey | Beef | Pea | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instrument | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) | NIRS6500 | MPA | MetriNIR | NIR-S-G1 | NIR-S-G1 (Bag) |
| Range (wl) | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 | 1100–2200 | 1400–2200 | 950–1650 | 950–1650 | 950–1650 |
| Pre-treat. | SG 21 + SNV | SG 21 + SNV | SG 21 | SG 25 | SG 21 + 2der | SG 15 + SNV | SG 21 + SNV | SG 25 | SG 11 + deTr | SG 21 + SNV | SNV | SG 31 + SNV | SG 31 | SG 21 + SNV | SG 21 + SNV |
| LV | 9 | 5 | 8 | 12 | 9 | 8 | 4 | 8 | 7 | 7 | 6 | 4 | 6 | 10 | 8 |
| RMSEC | 0.63 | 0.50 | 0.63 | 0.90 | 0.81 | 0.67 | 0.65 | 0.61 | 0.71 | 1.01 | 0.69 | 0.53 | 0.50 | 0.83 | 0.96 |
| R2C | 0.97 | 0.94 | 0.91 | 0.82 | 0.86 | 0.96 | 0.91 | 0.92 | 0.89 | 0.77 | 0.96 | 0.94 | 0.94 | 0.85 | 0.79 |
| RMSECV | 0.68 | 0.52 | 0.67 | 0.95 | 0.84 | 0.73 | 0.69 | 0.65 | 0.74 | 1.03 | 0.74 | 0.55 | 0.53 | 0.87 | 1.00 |
| R2CV | 0.96 | 0.94 | 0.90 | 0.80 | 0.84 | 0.96 | 0.89 | 0.90 | 0.88 | 0.76 | 0.96 | 0.93 | 0.94 | 0.83 | 0.78 |
| LODmin | 0.05 | 0.09 | 0.06 | 0.20 | 0.12 | 0.04 | 0.08 | 0.09 | 0.32 | 0.31 | 0.04 | 0.08 | 0.12 | 0.32 | 0.33 |
| LODmax | 0.20 | 0.17 | 0.26 | 0.54 | 0.31 | 0.14 | 0.18 | 0.22 | 0.42 | 0.45 | 0.14 | 0.17 | 0.22 | 0.44 | 0.38 |
| LOQmin | 0.14 | 0.26 | 0.18 | 0.60 | 0.36 | 0.11 | 0.23 | 0.28 | 0.96 | 0.94 | 0.13 | 0.23 | 0.37 | 0.96 | 0.99 |
| LOQmax | 0.59 | 0.51 | 0.77 | 1.62 | 0.93 | 0.41 | 0.53 | 0.67 | 1.25 | 1.35 | 0.43 | 0.50 | 0.65 | 1.31 | 1.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lukacs, M.; Zaukuu, J.-L.Z.; Bazar, G.; Pollner, B.; Fodor, M.; Kovacs, Z. Comparison of Multiple NIR Spectrometers for Detecting Low-Concentration Nitrogen-Based Adulteration in Protein Powders. Molecules 2024, 29, 781. https://doi.org/10.3390/molecules29040781
Lukacs M, Zaukuu J-LZ, Bazar G, Pollner B, Fodor M, Kovacs Z. Comparison of Multiple NIR Spectrometers for Detecting Low-Concentration Nitrogen-Based Adulteration in Protein Powders. Molecules. 2024; 29(4):781. https://doi.org/10.3390/molecules29040781
Chicago/Turabian StyleLukacs, Matyas, John-Lewis Zinia Zaukuu, George Bazar, Bernhard Pollner, Marietta Fodor, and Zoltan Kovacs. 2024. "Comparison of Multiple NIR Spectrometers for Detecting Low-Concentration Nitrogen-Based Adulteration in Protein Powders" Molecules 29, no. 4: 781. https://doi.org/10.3390/molecules29040781
APA StyleLukacs, M., Zaukuu, J. -L. Z., Bazar, G., Pollner, B., Fodor, M., & Kovacs, Z. (2024). Comparison of Multiple NIR Spectrometers for Detecting Low-Concentration Nitrogen-Based Adulteration in Protein Powders. Molecules, 29(4), 781. https://doi.org/10.3390/molecules29040781