
Computer-Aided Drug Design towards New Psychotropic and Neurological Drugs

Abstract
:1. Introduction
2. Ligand Based Techniques
2.1. 2D Based Methods
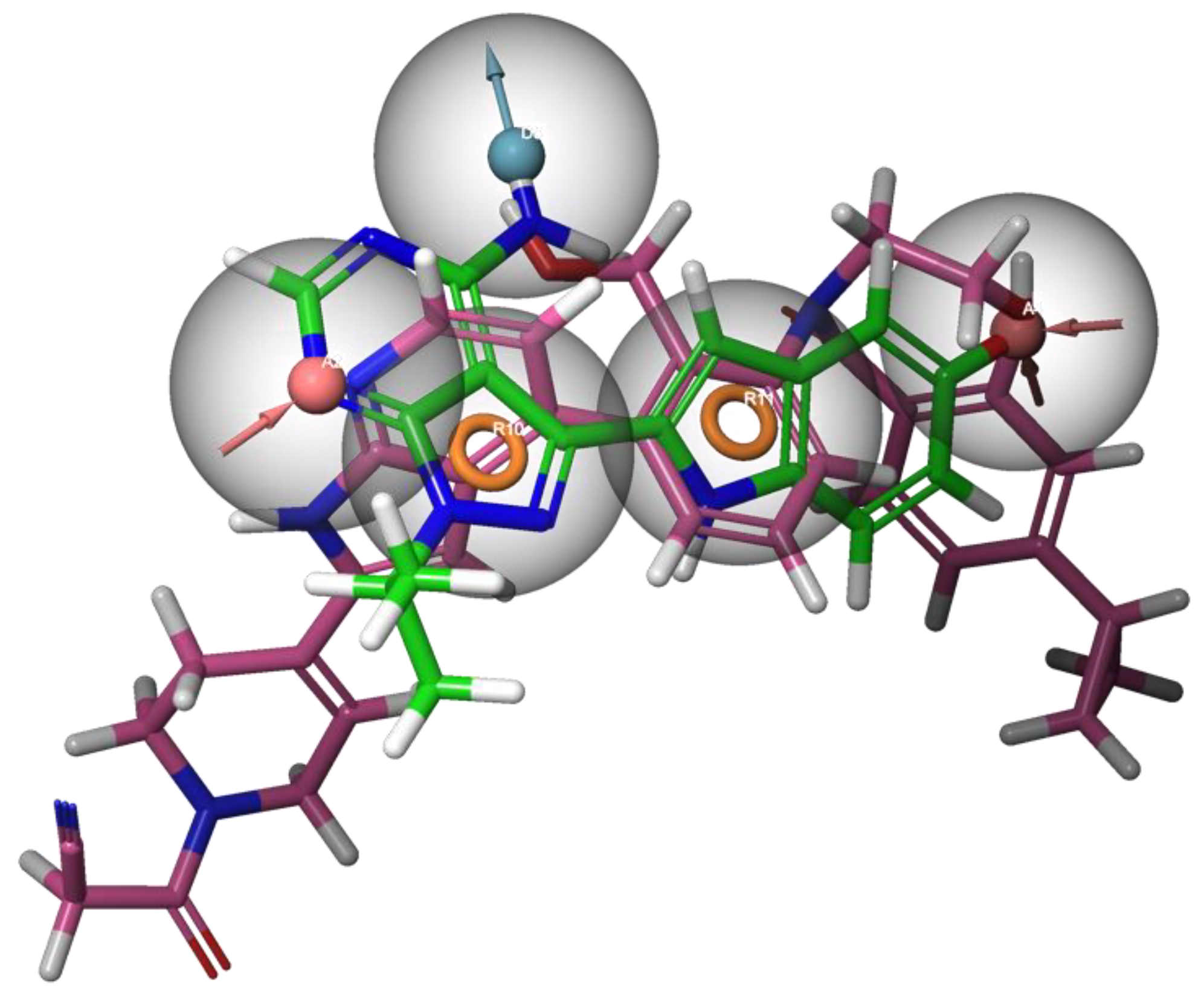
2.2. Pharmacophore Modelling
2.3. QSAR
3. Structure-Based Methods
3.1. Homology Modelling and Molecular Docking
3.2. Molecular Dynamics Studies
4. ADMET Property Prediction
5. The Rise of Deep Learning in Computer-Aided Drug Discovery
6. Applications to Neurological and Psychiatric Conditions
6.1. Alzheimer’s Disease
6.2. Parkinson’s Disease
6.3. Neuropathic Pain
6.4. Schizophrenia

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Drug Target and Methodology | Study Significance | Chemical Structure | Reference |
|---|---|---|---|
| Drug target: Transient receptor potential sub family M4 receptor (TRPM4) Disease target: Multiple sclerosis Software packages: CORINA Methods: xLOS | A ligand-based screening method known as atom category extended ligand overlap score (xLOS) was used to ascertain leads from a library of over 900,000 small molecules. This method was chosen due to a lack of information about the structure and binding pocket of TRPM4. Three reference compounds and the database compounds were converted into 3D structures using CORINA software. xLOS was then used to compare database ligands to the reference compounds, 9-phenanthrol, glibenclamide and flufenamic acid, and rank them. A total of 214 of the top molecules were purchased for biological evaluation. An additional round of xLOS screening on the Princeton database was performed using the top three hits from the first round of biological evaluation. The biological evaluation was conducted on 247 ligands from the second round of screening. The top scoring lead had potency at approximately 1 μM IC50, which is a marked improvement over the initial reference compounds. |  | [142] |
| Drug target: N-methyl-D-aspartate receptor (NDMA) GluN1-GluN2A subunits Disease target: Epilepsy Software packages: Molinspiration Cheminformatics AutoDock 4 Methods: Docking | In silico ADMET assessments and docking studies revealed three compounds with acceptable pharmacological properties, including the ability to traverse the BBB. These compounds demonstrated similar binding interactions to endogenous ligands but with improved binding capacity. The lead compounds resulted in a reduced number of seizures observed in a mouse model of epilepsy without any adverse effects on motor activity. |  | [143] |
| Drug target: Cannabinoid receptor 1 (CB1) Disease target: Substance abuse disorders Software packages: Glide Methods: Docking | A VS study was performed against the CB1 receptor using a natural products subset of the ZINC12 database. Nearly 300,000 small molecules were filtered and docked. The filtering and docking using standard and extra precision settings in Glide indicated 32 top-performing ligands, of which 18 were selected for further in vitro testing through clustering to ensure structural diversity amongst hits. Of the 18 ligands, 7 demonstrated more than 50% displacement in competitive binding at 10uM. Compound 16 had the greatest potency as a selective inverse agonist. Ligands with 80% similarity to compound 16 were screened and assessed for CB1 and CB2 activity. Two ligands were identified that had nanomolar affinity towards CB1. This provided key information for further structural optimization for inverse agonists targeting CB1. |  | [144] |
| Drug target: Caspase-1 Disease target: Febrile seizures Software packages: Glide AMBER 14 Methods: Docking Molecular dynamics | The role of caspase-1 in febrile seizures was initially assessed. Mice with the caspase-1 gene knocked out did not develop febrile seizures, and their wild-type litter mates had an increase in caspase-1 prior to the onset of a febrile seizure. One million compounds from the ChemBridge database were docked against the active site of capase-1. The top 2000 ligands from the extra precision docking stage were filtered to ensure they had suitable drug properties. The remainder were clustered for chemical similarity using the Tanimoto co-efficient. Fifty ligands were purchased for experimental validation of predicted binding affinity. Four compounds had potent inhibitory effects on caspase-1. When compared to diazepam, the top compound, CZL80, showed a capacity to prevent the onset of a second episode of FS, with diazepam not being able to do this. CZL80 also reduced the risk of adult epilepsy when administered after an episode of febrile seizures. |  | [145] |
| Drug target: Phosphoglycerate kinase-1 (PGK1) Disease target: Stroke Software packages: Discovery Studio LibDock Glide Canvas Methods: Docking | More than 73,000 small molecules from the Specs natural compounds and PubChem databases were docked against PGK-1 in search of agonists to protect against brain damage in stroke patients. The initial library was filtered to confirm that the small molecules possessed drug-like properties. The remaining 35,414 ligands underwent HTVS in LibDock and the remaining top 4% were docked using extra precision (XP) in Glide. The highest ranked 20% of ligands from XP docking were clustered to ascertain chemical similarity amongst hits. A total of 19 compounds from the different clusteres were selected for experimental validation. Two ligands, 7979989 and Z112553128, were noted as potential PGK1 activators as demonstrated in a Drosophilia oxidative stress model. |  | [146] |
| Drug target: Metabotropic glutamate receptor 5 (mGlu5) Disease target: Fragile X syndrome Depression Software packages: DOCK3.6 Methods: Docking | A total of 6.2 million compounds and fragments from ZINC database were screened to search for negative allosteric modulators (NAMs) of mGlu5. Initially, docking was benchmarked using an initial library of known NAMs and decoys with structural similarities. From this, 59 leads and 59 fragments were identified for experimental validation. In vitro assessments identified 11 identified molecules as NAMs. Compound F1 demonstrated the greatest level in terms of novelty in a pairwise Tanimoto co-efficient assessment with other mGlu5 ligands on the ChEMBL database. F1 also had the greatest affinity, with an Ki of 0.43μM. |  | [147] |
| Drug target: Excitatory amino acid transporter 2 (EAAT2) Disease target: Stroke Brain trauma Neurodegenerative disorders Software packages: MODELLER Desmond Sybyl 8.1 Unity GOLD Methods: Homology modelling Molecular dynamics Hybrid structure-based pharmacophore Docking | MD studies performed on a homology model of the EAAT2 suggested the presence of an allosteric binding site. Five key residues from the allosteric site were identified as key binding residues through site-directed and functional mutagenesis studies. The virtual screening of 3 million small molecules was performed against this pharmacophore. After virtual screening and filtering for favourable ADMET properties and no Lipinski’s violations, 58 ligands were selected for docking against the EAAT2 homology model. The docking studies yielded 10 molecules of interest for further assessment. A SciFinder search confirmed the novelty of these ligands. In vitro testing confirmed four compounds as NAMs, three as PAMs and three as inactive against EAAT2. One of the top performing molecules, GT949, possessed nanomolar potency. |  | [148] |
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Weller, J.; Budson, A. Current understanding of Alzheimer’s disease diagnosis and treatment. F1000Research 2018, 7, F1000 Faculty Rev-1161. [Google Scholar] [CrossRef] [Green Version]
- De Bie, R.M.; Clarke, C.E.; Espay, A.J.; Fox, S.H.; Lang, A.E. Initiation of pharmacological therapy in Parkinson’s disease: When, why, and how. Lancet Neurol. 2020, 19, 452–461. [Google Scholar] [CrossRef] [PubMed]
- De Hert, M.; Detraux, J.; Van Winkel, R.; Yu, W.; Correll, C.U. Metabolic and cardiovascular adverse effects associated with antipsychotic drugs. Nat. Rev. Endocrinol. 2012, 8, 114–126. [Google Scholar] [CrossRef] [PubMed]
- Harrison, R.K. Phase II and phase III failures: 2013–2015. Nat. Rev. Drug Discov. 2016, 15, 817–818. [Google Scholar] [CrossRef] [PubMed]
- Brown, D.G.; Wobst, H.J. A Decade of FDA-Approved Drugs (2010–2019): Trends and Future Directions. J. Med. Chem. 2021, 64, 2312–2338. [Google Scholar] [CrossRef]
- Congressional Budget Office. Research and Development in the Pharmaceutical Industry; Congressional Budget Office: Washington, DC, USA, 2021. [Google Scholar]
- Katritzky, A.R.; Kuanar, M.; Slavov, S.; Hall, C.D.; Karelson, M.; Kahn, I.; Dobchev, D.A. Quantitative Correlation of Physical and Chemical Properties with Chemical Structure: Utility for Prediction. Chem. Rev. 2010, 110, 5714–5789. [Google Scholar] [CrossRef]
- Leo, A.J. Calculating log Poct from structures. Chem. Rev. 1993, 93, 1281–1306. [Google Scholar] [CrossRef]
- Lipinski, C.A.; Lombardo, F.; Dominy, B.W.; Feeney, P.J. Experimental and computational approaches to estimate solubility and permeability in drug discovery and development settings. Adv. Drug Deliv. Rev. 1997, 23, 3–25. [Google Scholar] [CrossRef]
- Clark, D.E. In silico prediction of blood–brain barrier permeation. Drug Discov. Today 2003, 8, 927–933. [Google Scholar] [CrossRef]
- Kearsley, S.K.; Sallamack, S.; Fluder, E.M.; Andose, J.D.; Mosley, R.T.; Sheridan, R.P. Chemical similarity using physiochemical property descriptors. J. Chem. Inf. Comput. Sci. 1996, 36, 118–127. [Google Scholar] [CrossRef]
- Willett, P.; Barnard, J.M.; Downs, G.M. Chemical similarity searching. J. Chem. Inf. Comput. Sci. 1998, 38, 983–996. [Google Scholar] [CrossRef] [Green Version]
- Wermuth, C.; Ganellin, C.; Lindberg, P.; Mitscher, L. Glossary of terms used in medicinal chemistry (IUPAC Recommendations 1998). Pure Appl. Chem. 1998, 70, 1129–1143. [Google Scholar] [CrossRef]
- Zhang, H.; He, X.; Wang, X.; Yu, B.; Zhao, S.; Jiao, P.; Jin, H.; Liu, Z.; Wang, K.; Zhang, L.; et al. Design, synthesis and biological activities of piperidine-spirooxadiazole derivatives as alpha7 nicotinic receptor antagonists. Eur. J. Med. Chem. 2020, 207, 112774. [Google Scholar] [CrossRef]
- Ghose, A.K.; Wendoloski, J.J. Pharmacophore modelling: Methods, experimental verification and applications. In 3D QSAR in Drug Design; Springer: Berlin/Heidelberg, Germany, 2002; pp. 253–271. [Google Scholar]
- Poptodorov, K.; Luu, T.; Hoffmann, R.D. Pharmacophore model generation software tools. Pharm. Pharm. Searches 2006, 32, 15–47. [Google Scholar]
- Mysinger, M.M.; Carchia, M.; Irwin, J.J.; Shoichet, B.K. Directory of useful decoys, enhanced (DUD-E): Better ligands and decoys for better benchmarking. J. Med. Chem. 2012, 55, 6582–6594. [Google Scholar] [CrossRef]
- Sanders, M.P.; Barbosa, A.J.; Zarzycka, B.; Nicolaes, G.A.; Klomp, J.P.; De Vlieg, J.; Del Rio, A. Comparative analysis of pharmacophore screening tools. J. Chem. Inf. Model. 2012, 52, 1607–1620. [Google Scholar] [CrossRef]
- Wolber, G.; Langer, T. LigandScout: 3-D pharmacophores derived from protein-bound ligands and their use as virtual screening filters. J. Chem. Inf. Model. 2005, 45, 160–169. [Google Scholar] [CrossRef]
- Van Drie, J.H. Generation of three-dimensional pharmacophore models. Wiley Interdiscip. Rev. Comput. Mol. Sci. 2013, 3, 449–464. [Google Scholar] [CrossRef]
- Dixon, S.L.; Smondyrev, A.M.; Knoll, E.H.; Rao, S.N.; Shaw, D.E.; Friesner, R.A. PHASE: A new engine for pharmacophore perception, 3D QSAR model development, and 3D database screening: 1. Methodology and preliminary results. J. Comput. Aided. Mol. Des. 2006, 20, 647–671. [Google Scholar] [CrossRef]
- Vuorinen, A.; Schuster, D. Methods for generating and applying pharmacophore models as virtual screening filters and for bioactivity profiling. Methods 2015, 71, 113–134. [Google Scholar] [CrossRef]
- Giordano, D.; Biancaniello, C.; Argenio, M.A.; Facchiano, A. Drug Design by Pharmacophore and Virtual Screening Approach. Pharmaceuticals 2022, 15, 646. [Google Scholar] [CrossRef] [PubMed]
- Hansch, C.; Maloney, P.P.; Fujita, T.; Muir, R.M. Correlation of Biological Activity of Phenoxyacetic Acids with Hammett Substituent Constants and Partition Coefficients. Nature 1962, 194, 178–180. [Google Scholar] [CrossRef]
- Huang, C.; Zhong, Q.P.; Tang, L.; Wang, H.T.; Xu, J.P.; Zhou, Z.Z. Discovery of 2-(3, 4-dialkoxyphenyl)-2-(substituted pyridazin-3-yl) acetonitriles as phosphodiesterase 4 inhibitors with anti-neuroinflammation potential based on three-dimensional quantitative structure–activity relationship study. Chem. Biol. Drug Des. 2019, 93, 484–502. [Google Scholar] [CrossRef] [PubMed]
- OECD. Guidance Document on the Validation of (Quantitative) Structure-Activity Relationship [(Q)SAR] Models; OECD: Paris, France, 2014. [Google Scholar]
- Golbraikh, A.; Tropsha, A. Beware of q2! J. Mol. Graph. Model. 2002, 20, 269–276. [Google Scholar] [CrossRef]
- Dearden, J.C.; Cronin, M.T.; Kaiser, K.L. How not to develop a quantitative structure-activity or structure-property relationship (QSAR/QSPR). SAR QSAR Environ. Res. 2009, 20, 241–266. [Google Scholar] [CrossRef]
- Netzeva, T.I.; Worth, A.P.; Aldenberg, T.; Benigni, R.; Cronin, M.T.; Gramatica, P.; Jaworska, J.S.; Kahn, S.; Klopman, G.; Marchant, C.A. Current status of methods for defining the applicability domain of (quantitative) structure-activity relationships: The report and recommendations of ecvam workshop 52. Altern. Lab. Anim. 2005, 33, 155–173. [Google Scholar] [CrossRef]
- Manoj, G.D.; Sanjay, N.H.; Firoz, A.K.K.; Devanand, B.S.; Jaiprakash, N.S. Recent advances in multidimensional QSAR (4D-6D): A critical review. Mini Rev. Med. Chem. 2014, 14, 35–55. [Google Scholar]
- Mauri, A.; Consonni, V.; Todeschini, R. Molecular Descriptors. In Handbook of Computational Chemistry; Leszczynski, J., Kaczmarek-Kedziera, A., Puzyn, T.G., Papadopoulos, M., Reis, H., Shukla, K.M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 2065–2093. [Google Scholar]
- Testa, B.; Kier, L.B. The concept of molecular structure in structure–activity relationship studies and drug design. Med. Res. Rev. 1991, 11, 35–48. [Google Scholar] [CrossRef]
- Patel, H.M.; Noolvi, M.N.; Sharma, P.; Jaiswal, V.; Bansal, S.; Lohan, S.; Kumar, S.S.; Abbot, V.; Dhiman, S.; Bhardwaj, V. Quantitative structure–activity relationship (QSAR) studies as strategic approach in drug discovery. Med. Chem. Res. 2014, 23, 4991–5007. [Google Scholar] [CrossRef]
- Wold, S.; Eriksson, L.; Clementi, S. Statistical validation of QSAR results. In Chemometric Methods in Molecular Design; VCH: Weinheim, Germany, 1995; pp. 309–338. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Tropsha, A. Best Practices for QSAR Model Development, Validation, and Exploitation. Mol. Inform. 2010, 29, 476–488. [Google Scholar] [CrossRef]
- Gramatica, P. Principles of QSAR models validation: Internal and external. QSAR Comb. Sci. 2007, 26, 694–701. [Google Scholar] [CrossRef]
- Consonni, V.; Ballabio, D.; Todeschini, R. Evaluation of model predictive ability by external validation techniques. J. Chemom. 2010, 24, 194–201. [Google Scholar] [CrossRef]
- Roy, K.; Das, R.N.; Ambure, P.; Aher, R.B. Be aware of error measures. Further studies on validation of predictive QSAR models. Chemom. Intell. Lab. Syst. 2016, 152, 18–33. [Google Scholar] [CrossRef]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Baek, M.; DiMaio, F.; Anishchenko, I.; Dauparas, J.; Ovchinnikov, S.; Lee, G.R.; Wang, J.; Cong, Q.; Kinch, L.N.; Schaeffer, R.D.; et al. Accurate prediction of protein structures and interactions using a three-track neural network. Science 2021, 373, 871–876. [Google Scholar] [CrossRef]
- Lyu, J.; Wang, S.; Balius, T.E.; Singh, I.; Levit, A.; Moroz, Y.S.; O’Meara, M.J.; Che, T.; Algaa, E.; Tolmachova, K.; et al. Ultra-large library docking for discovering new chemotypes. Nature 2019, 566, 224–229. [Google Scholar] [CrossRef]
- Sussman, J.L.; Lin, D.; Jiang, J.; Manning, N.O.; Prilusky, J.; Ritter, O.; Abola, E.E. Protein Data Bank (PDB): Database of three-dimensional structural information of biological macromolecules. Acta Crystallogr. Sect. D Biol. Crystallogr. 1998, 54, 1078–1084. [Google Scholar] [CrossRef] [Green Version]
- Martí-Renom, M.A.; Stuart, A.C.; Fiser, A.; Sánchez, R.; Melo, F.; Sali, A. Comparative protein structure modeling of genes and genomes. Annu. Rev. Biophys. Biomol. Struct. 2000, 29, 291–325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blundell, T.L.; Sibanda, B.L.; Sternberg, M.J.; Thornton, J.M. Knowledge-based prediction of protein structures and the design of novel molecules. Nature 1987, 326, 347–352. [Google Scholar] [CrossRef]
- Pearson, W.R. An introduction to sequence similarity (“homology”) searching. Curr. Protoc. Bioinform. 2013, 42, 3-1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Consortium, U. UniProt: A hub for protein information. Nucleic Acids Res. 2015, 43, D204–D212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boeckmann, B.; Bairoch, A.; Apweiler, R.; Blatter, M.-C.; Estreicher, A.; Gasteiger, E.; Martin, M.J.; Michoud, K.; O’Donovan, C.; Phan, I. The SWISS-PROT protein knowledgebase and its supplement TrEMBL in 2003. Nucleic Acids Res. 2003, 31, 365–370. [Google Scholar] [CrossRef] [PubMed]
- Notredame, C.; Higgins, D.G.; Heringa, J. T-Coffee: A novel method for fast and accurate multiple sequence alignment. J. Mol. Biol. 2000, 302, 205–217. [Google Scholar] [CrossRef] [Green Version]
- Ye, J.; McGinnis, S.; Madden, T.L. BLAST: Improvements for better sequence analysis. Nucleic Acids Res. 2006, 34, W6–W9. [Google Scholar] [CrossRef] [Green Version]
- Webb, B.; Sali, A. Comparative protein structure modeling using MODELLER. Curr. Protoc. Bioinform. 2016, 54, 5–6. [Google Scholar] [CrossRef] [Green Version]
- Waterhouse, A.; Bertoni, M.; Bienert, S.; Studer, G.; Tauriello, G.; Gumienny, R.; Heer, F.T.; de Beer, T.A.P.; Rempfer, C.; Bordoli, L.; et al. SWISS-MODEL: Homology modelling of protein structures and complexes. Nucleic Acids Res. 2018, 46, W296–W303. [Google Scholar] [CrossRef] [Green Version]
- Jacobson, M.P.; Pincus, D.L.; Rapp, C.S.; Day, T.J.; Honig, B.; Shaw, D.E.; Friesner, R.A. A hierarchical approach to all-atom protein loop prediction. Proteins Struct. Funct. Bioinform. 2004, 55, 351–367. [Google Scholar] [CrossRef] [Green Version]
- Molecular Operating Environment (MOE). Chemical Computing Group ULC; Molecular Operating Environment (MOE): Montreal, QC, Canada, 2022. [Google Scholar]
- Lohning, A.E.; Levonis, S.M.; Williams-Noonan, B.; Schweiker, S.S. A practical guide to molecular docking and homology modelling for medicinal chemists. Curr. Top. Med. Chem. 2017, 17, 2023–2040. [Google Scholar] [CrossRef] [Green Version]
- Pitman, M.R.; Menz, R.I. 2—Methods for Protein Homology Modelling. In Applied Mycology and Biotechnology; Berka, R.M., Singh, G.B., Arora, D.K.., Eds.; Elsevier: Amsterdam, The Netherlands, 2006; Volume 6, pp. 37–59. [Google Scholar]
- Shen, M.Y.; Sali, A. Statistical potential for assessment and prediction of protein structures. Protein Sci. 2006, 15, 2507–2524. [Google Scholar] [CrossRef]
- Benkert, P.; Tosatto, S.C.; Schomburg, D. QMEAN: A comprehensive scoring function for model quality assessment. Proteins 2008, 71, 261–277. [Google Scholar] [CrossRef]
- Djikic, T.; Marti, Y.; Spyrakis, F.; Lau, T.; Benedetti, P.; Davey, G.; Schloss, P.; Yelekci, K. Human dopamine transporter: The first implementation of a combined in silico/in vitro approach revealing the substrate and inhibitor specificities. J. Biomol. Struct. Dyn. 2019, 37, 291–306. [Google Scholar] [CrossRef] [Green Version]
- Kowal, N.M.; Indurthi, D.C.; Ahring, P.K.; Chebib, M.; Olafsdottir, E.S.; Balle, T. Novel Approach for the Search for Chemical Scaffolds with Dual Activity with Acetylcholinesterase and the alpha7 Nicotinic Acetylcholine Receptor-A Perspective for the Treatment of Neurodegenerative Disorders. Molecules 2019, 24, 446. [Google Scholar] [CrossRef] [Green Version]
- Kitchen, D.B.; Decornez, H.; Furr, J.R.; Bajorath, J. Docking and scoring in virtual screening for drug discovery: Methods and applications. Nat. Rev. Drug Discov. 2004, 3, 935–949. [Google Scholar] [CrossRef] [PubMed]
- Morris, G.M.; Lim-Wilby, M. Molecular docking. In Molecular Modeling of Proteins; Springer: Berlin/Heidelberg, Germany, 2008; pp. 365–382. [Google Scholar]
- Lorber, D.M.; Shoichet, B.K. Flexible ligand docking using conformational ensembles. Protein Sci. 1998, 7, 938–950. [Google Scholar] [CrossRef] [Green Version]
- Sherman, W.; Beard, H.S.; Farid, R. Use of an induced fit receptor structure in virtual screening. Chem. Biol. Drug Des. 2006, 67, 83–84. [Google Scholar] [CrossRef]
- Gurram, P.C.; Satarker, S.; Kumar, G.; Begum, F.; Mehta, C.; Nayak, U.; Mudgal, J.; Arora, D.; Nampoothiri, M. Avanafil mediated dual inhibition of IKKβ and TNFR1 in an experimental paradigm of Alzheimer’s disease: In silico and in vivo approach. J. Biomol. Struct. Dyn. 2022. [Google Scholar] [CrossRef]
- Huang, S.Y.; Grinter, S.Z.; Zou, X. Scoring functions and their evaluation methods for protein-ligand docking: Recent advances and future directions. Phys. Chem. Chem. Phys. 2010, 12, 12899–12908. [Google Scholar] [CrossRef] [PubMed]
- Chandra, S.; Wang, Z.; Tao, X.; Chen, O.; Luo, X.; Ji, R.R.; Bortsov, A.V. Computer-aided Discovery of a New Nav1.7 Inhibitor for Treatment of Pain and Itch. Anesthesiology 2020, 133, 611–627. [Google Scholar] [CrossRef]
- Böhm, H.-J. Prediction of binding constants of protein ligands: A fast method for the prioritization of hits obtained from de novo design or 3D database search programs. J. Comput. Aided Mol. Des. 1998, 12, 309. [Google Scholar] [CrossRef]
- Gehlhaar, D.K.; Verkhivker, G.M.; Rejto, P.A.; Sherman, C.J.; Fogel, D.B.; Fogel, L.J.; Freer, S.T. Molecular recognition of the inhibitor AG-1343 by HIV-1 protease: Conformationally flexible docking by evolutionary programming. Chem. Biol. 1995, 2, 317–324. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Lai, L.; Wang, S. Further development and validation of empirical scoring functions for structure-based binding affinity prediction. J. Comput. Aided Mol. Des. 2002, 16, 11–26. [Google Scholar] [CrossRef]
- Li, X.-L.; Hou, M.-L.; Wang, S.-L. A residual level potential of mean force based approach to predict protein-protein interaction affinity. In Proceedings of the International Conference on Intelligent Computing, Changsha, China, 18–21 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 680–686. [Google Scholar]
- Head, R.D.; Smythe, M.L.; Oprea, T.I.; Waller, C.L.; Green, S.M.; Marshall, G.R. VALIDATE: A new method for the receptor-based prediction of binding affinities of novel ligands. J. Am. Chem. Soc. 1996, 118, 3959–3969. [Google Scholar] [CrossRef]
- Yin, S.; Biedermannova, L.; Vondrasek, J.; Dokholyan, N.V. MedusaScore: An accurate force field-based scoring function for virtual drug screening. J. Chem. Inf. Model. 2008, 48, 1656–1662. [Google Scholar] [CrossRef] [Green Version]
- Hollingsworth, S.A.; Dror, R.O. Molecular dynamics simulation for all. Neuron 2018, 99, 1129–1143. [Google Scholar] [CrossRef] [Green Version]
- Totrov, M.; Abagyan, R. Flexible ligand docking to multiple receptor conformations: A practical alternative. Curr. Opin. Struct. Biol. 2008, 18, 178–184. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.-Y. Comprehensive assessment of flexible-ligand docking algorithms: Current effectiveness and challenges. Brief. Bioinform. 2017, 19, 982–994. [Google Scholar] [CrossRef]
- Tan, S.; Gong, X.; Liu, H.; Yao, X. Virtual Screening and Biological Activity Evaluation of New Potent Inhibitors Targeting LRRK2 Kinase Domain. ACS Chem. Neurosci. 2021, 12, 3214–3224. [Google Scholar] [CrossRef]
- Brooks, B.R.; Bruccoleri, R.E.; Olafson, B.D.; States, D.J.; Swaminathan, S.; Karplus, M. CHARMM: A program for macromolecular energy, minimization, and dynamics calculations. J. Comput. Chem. 1983, 4, 187–217. [Google Scholar] [CrossRef]
- Van Gunsteren, W.F.; Billeter, S.; Eising, A.; Hünenberger, P.; Krüger, P.; Mark, A.; Scott, W.; Tironi, I. Biomolecular Simulation: The GROMOS96 Manual and User Guide; Vdf Hochschulverlag AG an der ETH Zürich: Zürich, Switzerland, 1996; Volume 86, pp. 1–1044. [Google Scholar]
- Wang, J.; Wolf, R.M.; Caldwell, J.W.; Kollman, P.A.; Case, D.A. Development and testing of a general amber force field. J. Comput. Chem. 2004, 25, 1157–1174. [Google Scholar] [CrossRef] [PubMed]
- Jorgensen, W.L.; Maxwell, D.S.; Tirado-Rives, J. Development and Testing of the OPLS All-Atom Force Field on Conformational Energetics and Properties of Organic Liquids. J. Am. Chem. Soc. 1996, 118, 11225–11236. [Google Scholar] [CrossRef]
- Van Der Spoel, D.; Lindahl, E.; Hess, B.; Groenhof, G.; Mark, A.E.; Berendsen, H.J. GROMACS: Fast, flexible, and free. J. Comput. Chem. 2005, 26, 1701–1718. [Google Scholar] [CrossRef]
- Case, D.A.; Aktulga, H.M.; Belfon, K.; Ben-Shalom, I.; Brozell, S.R.; Cerutti, D.S.; Cheatham, T.E., III; Cruzeiro, V.W.D.; Darden, T.A.; Duke, R.E. Amber 2021; University of California: San Francisco, CA, USA, 2021. [Google Scholar]
- Eastman, P.; Swails, J.; Chodera, J.D.; McGibbon, R.T.; Zhao, Y.; Beauchamp, K.A.; Wang, L.-P.; Simmonett, A.C.; Harrigan, M.P.; Stern, C.D. OpenMM 7: Rapid development of high performance algorithms for molecular dynamics. PLoS Comput. Biol. 2017, 13, e1005659. [Google Scholar] [CrossRef] [Green Version]
- Bowers, K.J.; Chow, E.; Xu, H.; Dror, R.O.; Eastwood, M.P.; Gregersen, B.A.; Klepeis, J.L.; Kolossvary, I.; Moraes, M.A.; Sacerdoti, F.D.; et al. Scalable algorithms for molecular dynamics simulations on commodity clusters. In Proceedings of the 2006 ACM/IEEE Conference on Supercomputing, Tampa, FL, USA, 11–17 November 2006; p. 84-es. [Google Scholar]
- Marrink, S.J.; Risselada, H.J.; Yefimov, S.; Tieleman, D.P.; De Vries, A.H. The MARTINI force field: Coarse grained model for biomolecular simulations. J. Phys. Chem. B 2007, 111, 7812–7824. [Google Scholar] [CrossRef] [Green Version]
- Nickolls, J.; Buck, I.; Garland, M.; Skadron, K. Scalable parallel programming with cuda: Is cuda the parallel programming model that application developers have been waiting for? Queue 2008, 6, 40–53. [Google Scholar] [CrossRef] [Green Version]
- Park, H.; Kim, T.; Kim, K.; Jang, A.; Hong, S. Structure-Based Virtual Screening and De Novo Design to Identify Submicromolar Inhibitors of G2019S Mutant of Leucine-Rich Repeat Kinase 2. Int. J. Mol. Sci. 2022, 23, 12825. [Google Scholar] [CrossRef]
- Abbott, N.J.; Patabendige, A.A.; Dolman, D.E.; Yusof, S.R.; Begley, D.J. Structure and function of the blood–brain barrier. Neurobiol. Dis. 2010, 37, 13–25. [Google Scholar] [CrossRef]
- Morgan, P.; Van Der Graaf, P.H.; Arrowsmith, J.; Feltner, D.E.; Drummond, K.S.; Wegner, C.D.; Street, S.D.A. Can the flow of medicines be improved? Fundamental pharmacokinetic and pharmacological principles toward improving Phase II survival. Drug Discov. Today 2012, 17, 419–424. [Google Scholar] [CrossRef]
- Goller, A.H.; Kuhnke, L.; Montanari, F.; Bonin, A.; Schneckener, S.; Ter Laak, A.; Wichard, J.; Lobell, M.; Hillisch, A. Bayer’s in silico ADMET platform: A journey of machine learning over the past two decades. Drug Discov. Today 2020, 25, 1702–1709. [Google Scholar] [CrossRef]
- Bhhatarai, B.; Walters, W.P.; Hop, C.E.C.A.; Lanza, G.; Ekins, S. Opportunities and challenges using artificial intelligence in ADME/Tox. Nat. Mater. 2019, 18, 418–422. [Google Scholar] [CrossRef]
- Vatansever, S.; Schlessinger, A.; Wacker, D.; Kaniskan, H.U.; Jin, J.; Zhou, M.M.; Zhang, B. Artificial intelligence and machine learning-aided drug discovery in central nervous system diseases: State-of-the-arts and future directions. Med. Res. Rev. 2021, 41, 1427–1473. [Google Scholar] [CrossRef]
- Faramarzi, S.; Kim, M.T.; Volpe, D.A.; Cross, K.P.; Chakravarti, S.; Stavitskaya, L. Development of QSAR models to predict blood-brain barrier permeability. Front. Pharmacol. 2022, 13, 4486. [Google Scholar] [CrossRef]
- Gao, Z.; Chen, Y.; Cai, X.; Xu, R. Predict drug permeability to blood-brain-barrier from clinical phenotypes: Drug side effects and drug indications. Bioinformatics 2017, 33, 901–908. [Google Scholar] [CrossRef] [Green Version]
- Miao, R.; Xia, L.Y.; Chen, H.H.; Huang, H.H.; Liang, Y. Improved Classification of Blood-Brain-Barrier Drugs Using Deep Learning. Sci. Rep. 2019, 9, 8802. [Google Scholar] [CrossRef] [Green Version]
- Lingineni, K.; Belekar, V.; Tangadpalliwar, S.R.; Garg, P. The role of multidrug resistance protein (MRP-1) as an active efflux transporter on blood-brain barrier (BBB) permeability. Mol. Divers. 2017, 21, 355–365. [Google Scholar] [CrossRef]
- Garg, P.; Dhakne, R.; Belekar, V. Role of breast cancer resistance protein (BCRP) as active efflux transporter on blood-brain barrier (BBB) permeability. Mol. Divers. 2015, 19, 163–172. [Google Scholar] [CrossRef]
- Tong, X.; Wang, D.; Ding, X.; Tan, X.; Ren, Q.; Chen, G.; Rong, Y.; Xu, T.; Huang, J.; Jiang, H.; et al. Blood-brain barrier penetration prediction enhanced by uncertainty estimation. J. Cheminform. 2022, 14, 44. [Google Scholar] [CrossRef]
- Tang, Q.; Nie, F.; Zhao, Q.; Chen, W. A merged molecular representation deep learning method for blood-brain barrier permeability prediction. Brief Bioinform. 2022, 23, bbac357. [Google Scholar] [CrossRef]
- Ma, J.; Sheridan, R.P.; Liaw, A.; Dahl, G.E.; Svetnik, V. Deep neural nets as a method for quantitative structure–activity relationships. J. Chem. Inf. Model. 2015, 55, 263–274. [Google Scholar] [CrossRef] [PubMed]
- Raina, R.; Madhavan, A.; Ng, A.Y. Large-scale deep unsupervised learning using graphics processors. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 873–880. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Gaulton, A.; Bellis, L.J.; Bento, A.P.; Chambers, J.; Davies, M.; Hersey, A.; Light, Y.; McGlinchey, S.; Michalovich, D.; Al-Lazikani, B. ChEMBL: A large-scale bioactivity database for drug discovery. Nucleic Acids Res. 2012, 40, D1100–D1107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Xiao, J.; Suzek, T.O.; Zhang, J.; Wang, J.; Bryant, S.H. PubChem: A public information system for analyzing bioactivities of small molecules. Nucleic Acids Res. 2009, 37, W623–W633. [Google Scholar] [CrossRef]
- Keshavarzi Arshadi, A.; Salem, M.; Firouzbakht, A.; Yuan, J.S. MolData, a molecular benchmark for disease and target based machine learning. J. Cheminform. 2022, 14, 10. [Google Scholar] [CrossRef]
- Smalley, E. AI-powered drug discovery captures pharma interest. Nat. Biotechnol. 2017, 35, 604–606. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Cadieu, C.F.; Hong, H.; Yamins, D.L.; Pinto, N.; Ardila, D.; Solomon, E.A.; Majaj, N.J.; DiCarlo, J.J. Deep neural networks rival the representation of primate IT cortex for core visual object recognition. PLoS Comput. Biol. 2014, 10, e1003963. [Google Scholar] [CrossRef] [Green Version]
- Le Cun, Y.; Boser, B.; Denker, J.; Henderson, D.; Hubbard, W.; Jackel, L. Handwritten Digit Recognition Width a Backpropagation Network. Advances in Neural Information Systems; Morgan Kaufman: San Mateo, CA, USA, 1990; Volume 2. [Google Scholar]
- Grebner, C.; Matter, H.; Kofink, D.; Wenzel, J.; Schmidt, F.; Hessler, G. Application of Deep Neural Network Models in Drug Discovery Programs. ChemMedChem 2021, 16, 3772–3786. [Google Scholar] [CrossRef]
- Francoeur, P.G.; Masuda, T.; Sunseri, J.; Jia, A.; Iovanisci, R.B.; Snyder, I.; Koes, D.R. Three-Dimensional Convolutional Neural Networks and a Cross-Docked Data Set for Structure-Based Drug Design. J. Chem. Inf. Model. 2020, 60, 4200–4215. [Google Scholar] [CrossRef]
- Lim, J.; Ryu, S.; Park, K.; Choe, Y.J.; Ham, J.; Kim, W.Y. Predicting Drug-Target Interaction Using a Novel Graph Neural Network with 3D Structure-Embedded Graph Representation. J. Chem. Inf. Model. 2019, 59, 3981–3988. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Tran, P.T.; Pham, N.Q.A.; Hoang, V.H.; Hiep, D.M.; Ngo, S.T. Identifying Possible AChE Inhibitors from Drug-like Molecules via Machine Learning and Experimental Studies. ACS Omega 2022, 7, 20673–20682. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Yasonik, J. Multiobjective de novo drug design with recurrent neural networks and nondominated sorting. J. Cheminform. 2020, 12, 14. [Google Scholar] [CrossRef] [Green Version]
- Sanchez-Lengeling, B.; Aspuru-Guzik, A. Inverse molecular design using machine learning: Generative models for matter engineering. Science 2018, 361, 360–365. [Google Scholar] [CrossRef] [Green Version]
- Karimi, M.; Wu, D.; Wang, Z.; Shen, Y. DeepAffinity: Interpretable deep learning of compound-protein affinity through unified recurrent and convolutional neural networks. Bioinformatics 2019, 35, 3329–3338. [Google Scholar] [CrossRef] [Green Version]
- Caruana, R. Multitask Learning. In Learning to Learn; Thrun, S., Pratt, L., Eds.; Springer: Boston, MA, USA, 1998; pp. 95–133. [Google Scholar]
- Simões, R.S.; Maltarollo, V.G.; Oliveira, P.R.; Honorio, K.M. Transfer and Multi-task Learning in QSAR Modeling: Advances and Challenges. Front. Pharmacol. 2018, 9, 74. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Qin, J.; Gou, Z.; Zhang, Y.; Yang, Y. Multi-task learning models for predicting active compounds. J. Biomed. Inform. 2020, 108, 103484. [Google Scholar] [CrossRef]
- Lee, K.; Kim, D. In-Silico Molecular Binding Prediction for Human Drug Targets Using Deep Neural Multi-Task Learning. Genes 2019, 10, 906. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Hsieh, C.Y.; Wang, J.; Wang, D.; Weng, G.; Shen, C.; Yao, X.; Bing, Z.; Li, H.; Cao, D.; et al. RELATION: A Deep Generative Model for Structure-Based De Novo Drug Design. J. Med. Chem. 2022, 65, 9478–9492. [Google Scholar] [CrossRef] [PubMed]
- Bung, N.; Krishnan, S.R.; Roy, A. An In Silico Explainable Multiparameter Optimization Approach for De Novo Drug Design against Proteins from the Central Nervous System. J. Chem. Inf. Model. 2022, 62, 2685–2695. [Google Scholar] [CrossRef] [PubMed]
- Maes, M. Precision Nomothetic Medicine in Depression Research: A New Depression Model, and New Endophenotype Classes and Pathway Phenotypes, and A Digital Self. J. Pers. Med. 2022, 12, 403. [Google Scholar] [CrossRef] [PubMed]
- Maes, M.; Anderson, G. False Dogmas in Schizophrenia Research: Toward the Reification of Pathway Phenotypes and Pathway Classes. Front. Psychiatr. 2021, 12, 663985. [Google Scholar] [CrossRef]
- Anastasio, T.J. Predicting the Potency of Anti-Alzheimer’s Drug Combinations Using Machine Learning. Processes 2021, 9, 264. [Google Scholar] [CrossRef]
- Tuladhar, A.; Moore, J.A.; Ismail, Z.; Forkert, N.D. Modeling Neurodegeneration in silico with Deep Learning. Front. Neuroinform. 2021, 15, 56. [Google Scholar] [CrossRef]
- Gauthier, S.; Webster, C.; Servaes, S.; Morais, J.; Rosa-Neto, P. World Alzheimer Report 2022; Alzheimer’s Disease International: London, UK, 2022. [Google Scholar]
- Iida, M.; Iwata, M.; Yamanishi, Y. Network-based characterization of disease–disease relationships in terms of drugs and therapeutic targets. Bioinformatics 2020, 36, i516–i524. [Google Scholar] [CrossRef]
- Ivanova, L.; Karelson, M.; Dobchev, D.A. Multitarget Approach to Drug Candidates against Alzheimer’s Disease Related to AChE, SERT, BACE1 and GSK3beta Protein Targets. Molecules 2020, 25, 1846. [Google Scholar] [CrossRef] [Green Version]
- Sterling, T.; Irwin, J.J. ZINC 15–ligand discovery for everyone. J. Chem. Inf. Model. 2015, 55, 2324–2337. [Google Scholar] [CrossRef]
- Oddsson, S.; Kowal, N.M.; Ahring, P.K.; Olafsdottir, E.S.; Balle, T. Structure-Based Discovery of Dual-Target Hits for Acetylcholinesterase and the alpha7 Nicotinic Acetylcholine Receptors: In Silico Studies and In Vitro Confirmation. Molecules 2020, 25, 2872. [Google Scholar] [CrossRef]
- Liu, J.; Peng, D.; Li, J.; Dai, Z.; Zou, X.; Li, Z. Identification of Potential Parkinson’s Disease Drugs Based on Multi-Source Data Fusion and Convolutional Neural Network. Molecules 2022, 27, 4780. [Google Scholar] [CrossRef]
- Khan, A.; Chandra Kaushik, A.; Ali, S.S.; Ahmad, N.; Wei, D.Q. Deep-learning-based target screening and similarity search for the predicted inhibitors of the pathways in Parkinson’s disease. RSC Adv. 2019, 9, 10326–10339. [Google Scholar] [CrossRef]
- Peng, Y.; Dong, H.; Welsh, W.J. Comprehensive 3D-QSAR Model Predicts Binding Affinity of Structurally Diverse Sigma 1 Receptor Ligands. J. Chem. Inf. Model. 2019, 59, 486–497. [Google Scholar] [CrossRef]
- Kang, K.M.; Lee, I.; Nam, H.; Kim, Y.C. AI-based prediction of new binding site and virtual screening for the discovery of novel P2X3 receptor antagonists. Eur. J. Med. Chem. 2022, 240, 114556. [Google Scholar] [CrossRef]
- Yu, Y.; Dong, H.; Peng, Y.; Welsh, W.J. QSAR-Based Computational Approaches to Accelerate the Discovery of Sigma-2 Receptor (S2R) Ligands as Therapeutic Drugs. Molecules 2021, 26, 5270. [Google Scholar] [CrossRef]
- Ozhathil, L.C.; Delalande, C.; Bianchi, B.; Nemeth, G.; Kappel, S.; Thomet, U.; Ross-Kaschitza, D.; Simonin, C.; Rubin, M.; Gertsch, J.; et al. Identification of potent and selective small molecule inhibitors of the cation channel TRPM4. Br. J. Pharmacol. 2018, 175, 2504–2519. [Google Scholar] [CrossRef] [Green Version]
- Coaviche-Yoval, A.; Trujillo-Ferrara, J.G.; Soriano-Ursua, M.A.; Andrade-Jorge, E.; Sanchez-Labastida, L.A.; Luna, H.; Tovar-Miranda, R. In silico and in vivo neuropharmacological evaluation of two gamma-amino acid isomers derived from 2,3-disubstituted benzofurans, as ligands of GluN1-GluN2A NMDA receptor. Amino Acids 2022, 54, 215–228. [Google Scholar] [CrossRef]
- Pandey, P.; Roy, K.K.; Liu, H.; Ma, G.; Pettaway, S.; Alsharif, W.F.; Gadepalli, R.S.; Rimoldi, J.M.; McCurdy, C.R.; Cutler, S.J.; et al. Structure-Based Identification of Potent Natural Product Chemotypes as Cannabinoid Receptor 1 Inverse Agonists. Molecules 2018, 23, 2630. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Feng, B.; Wang, Y.; Sun, H.; You, Y.; Yu, J.; Chen, B.; Xu, C.; Ruan, Y.; Cui, S.; et al. Structure-based discovery of CZL80, a caspase-1 inhibitor with therapeutic potential for febrile seizures and later enhanced epileptogenic susceptibility. Br. J. Pharmacol. 2020, 177, 3519–3534. [Google Scholar] [CrossRef]
- Qiang, S.J.; Shi, Y.Q.; Wu, T.Y.; Wang, J.Q.; Chen, X.L.; Su, J.; Chen, X.P.; Li, J.Z.; Chen, Z.S. The Discovery of Novel PGK1 Activators as Apoptotic Inhibiting and Neuroprotective Agents. Front. Pharm. 2022, 13, 877706. [Google Scholar] [CrossRef]
- Kampen, S.; Rodriguez, D.; Jorgensen, M.; Kruszyk-Kujawa, M.; Huang, X.; Collins, M., Jr.; Boyle, N.; Maurel, D.; Rudling, A.; Lebon, G.; et al. Structure-Based Discovery of Negative Allosteric Modulators of the Metabotropic Glutamate Receptor 5. ACS Chem. Biol. 2022, 17, 2744–2752. [Google Scholar] [CrossRef] [PubMed]
- Kortagere, S.; Mortensen, O.V.; Xia, J.; Lester, W.; Fang, Y.; Srikanth, Y.; Salvino, J.M.; Fontana, A.C.K. Identification of Novel Allosteric Modulators of Glutamate Transporter EAAT2. ACS Chem. Neurosci. 2018, 9, 522–534. [Google Scholar] [CrossRef] [PubMed]




| Dimension | Definition |
|---|---|
| 0D | Only contains the molecular formula. Thus, the only information is the atom types and numbers of each. |
| 1D | Molecular properties that pertain to the entire chemical structure, such as logP and pKa. It also includes substructural details of molecular fragments. |
| 2D | Topologies are mathematically encoded to represent the connectivity of atoms using a 2D graph. |
| 3D | Details of the spatial arrangement of atoms and non-covalent interaction sites guided by 3D topologies. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dorahy, G.; Chen, J.Z.; Balle, T. Computer-Aided Drug Design towards New Psychotropic and Neurological Drugs. Molecules 2023, 28, 1324. https://doi.org/10.3390/molecules28031324
Dorahy G, Chen JZ, Balle T. Computer-Aided Drug Design towards New Psychotropic and Neurological Drugs. Molecules. 2023; 28(3):1324. https://doi.org/10.3390/molecules28031324
Chicago/Turabian StyleDorahy, Georgia, Jake Zheng Chen, and Thomas Balle. 2023. "Computer-Aided Drug Design towards New Psychotropic and Neurological Drugs" Molecules 28, no. 3: 1324. https://doi.org/10.3390/molecules28031324
APA StyleDorahy, G., Chen, J. Z., & Balle, T. (2023). Computer-Aided Drug Design towards New Psychotropic and Neurological Drugs. Molecules, 28(3), 1324. https://doi.org/10.3390/molecules28031324