
Accurate Prediction of Cancer Prognosis by Exploiting Patient-Specific Cancer Driver Genes


Abstract
:1. Introduction
2. Results
2.1. Data Description
2.2. Model Configuration
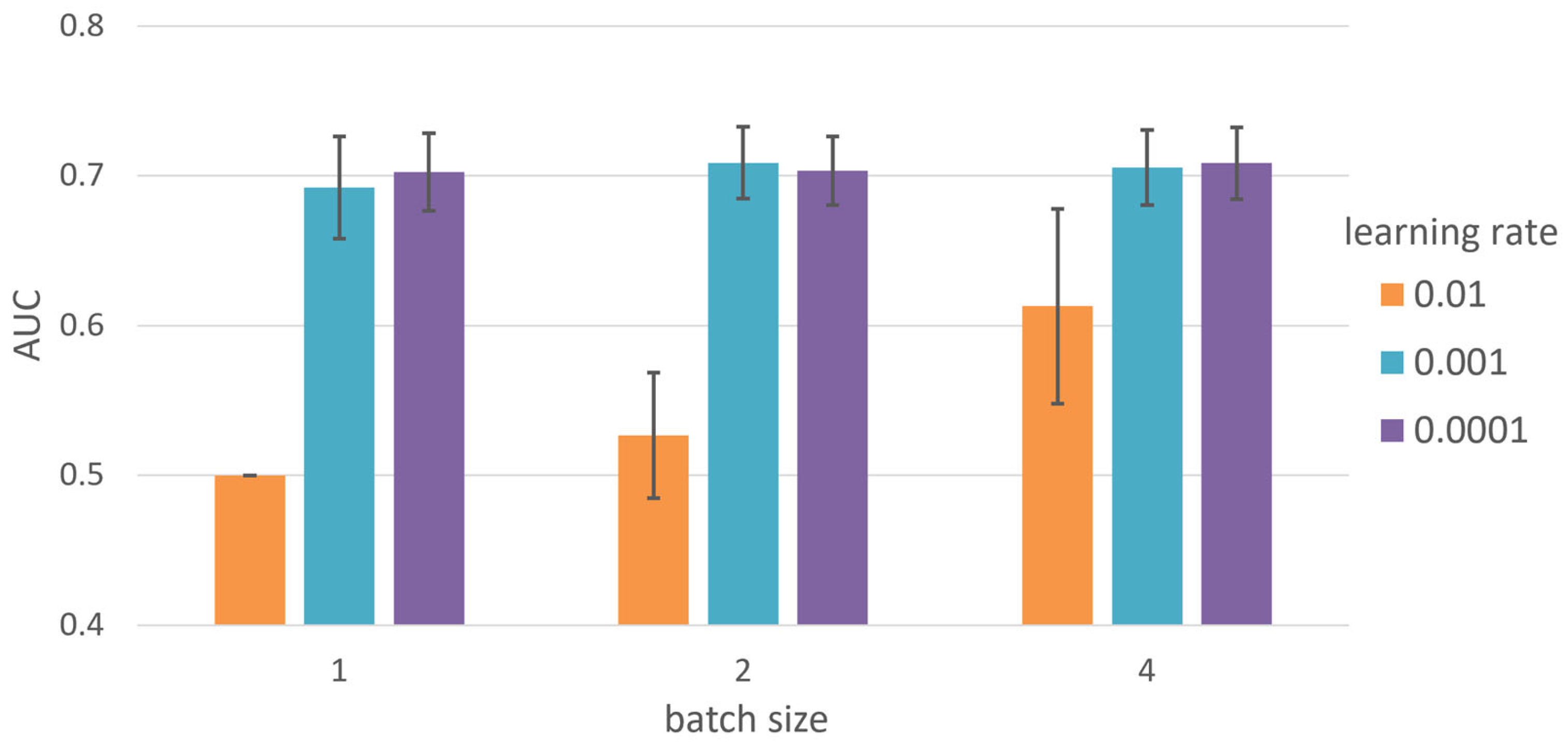
2.3. Hyperparameter Tuning
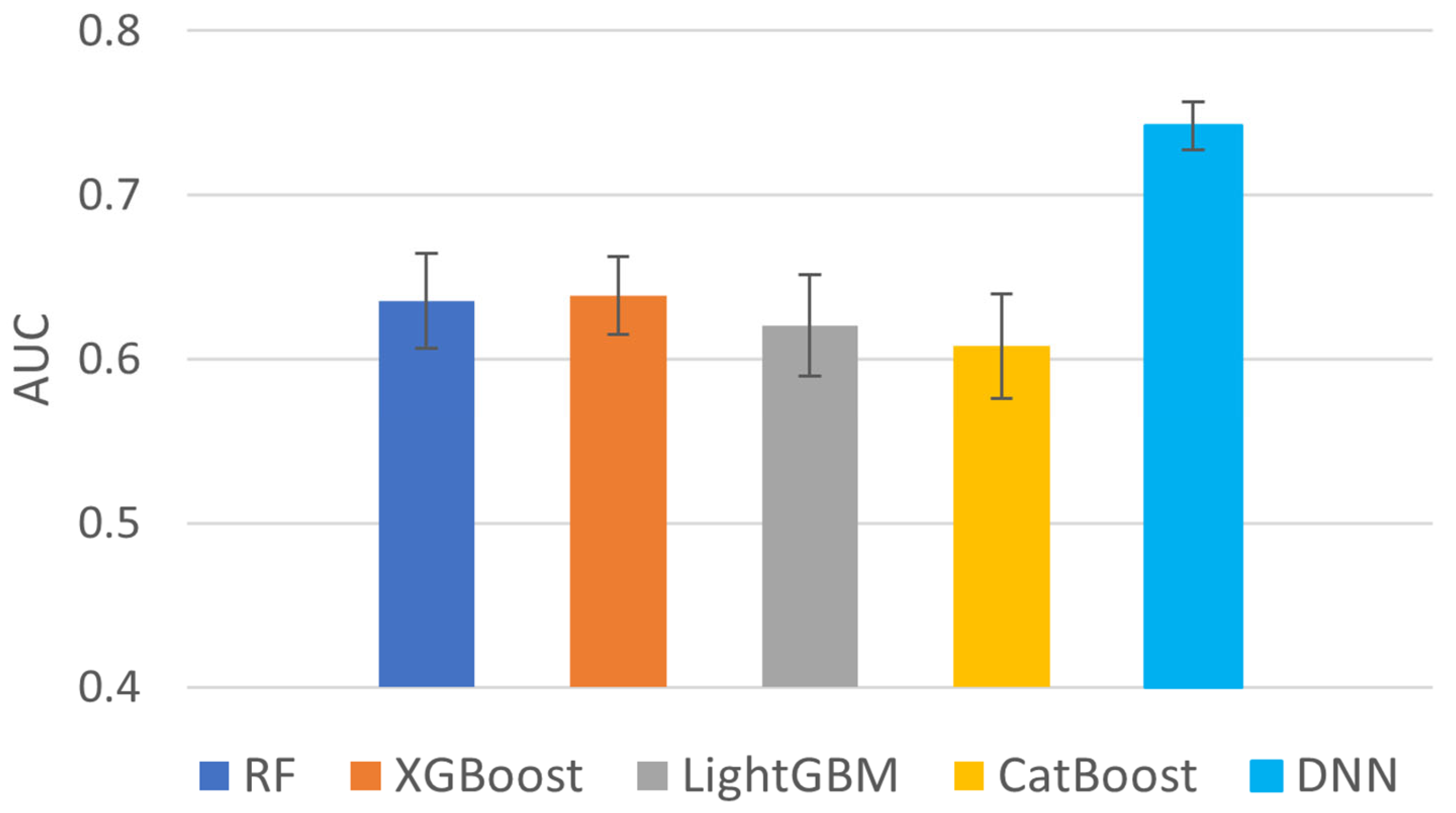
2.4. Comparison on Different Machine Learning Methods
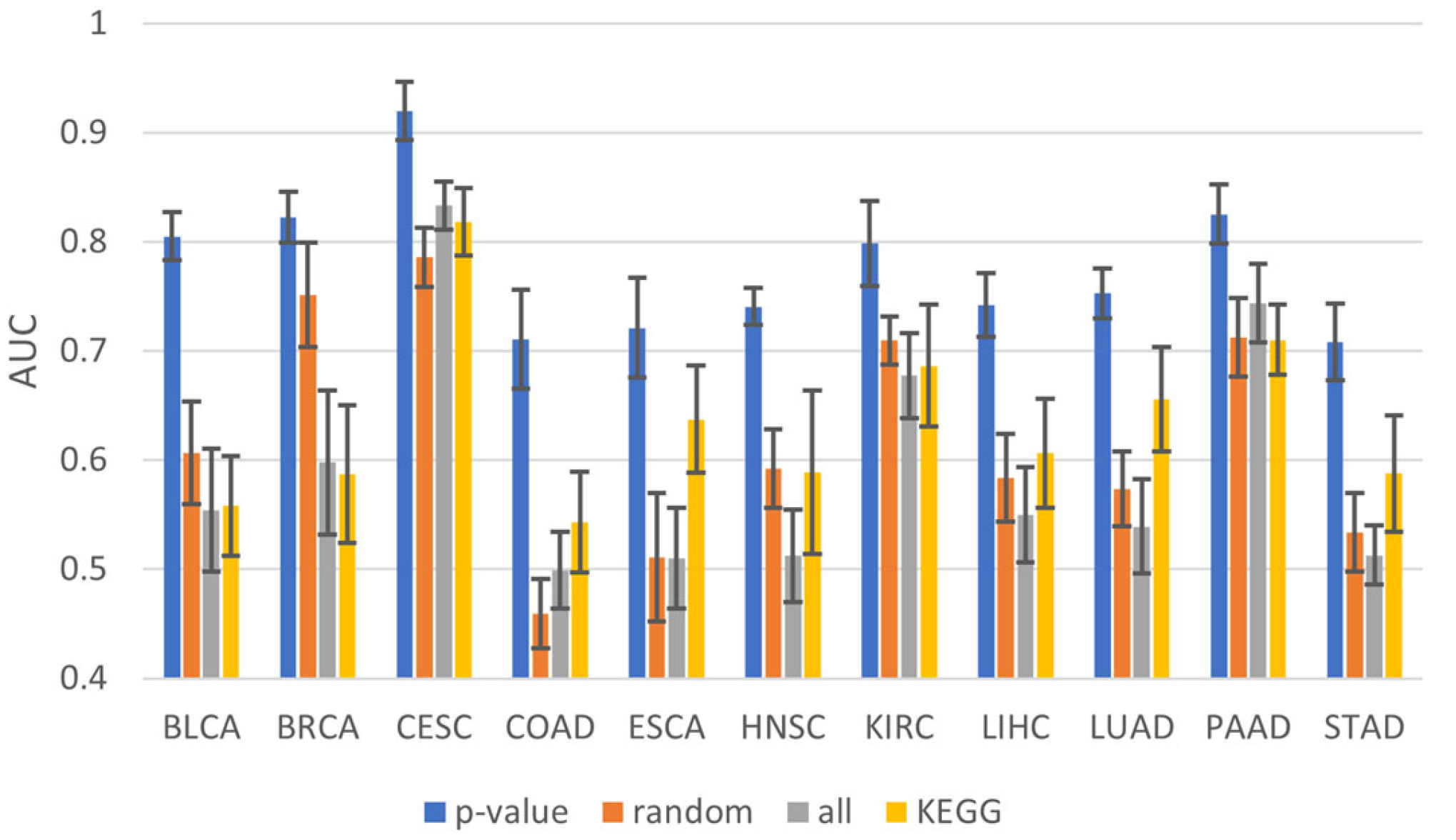
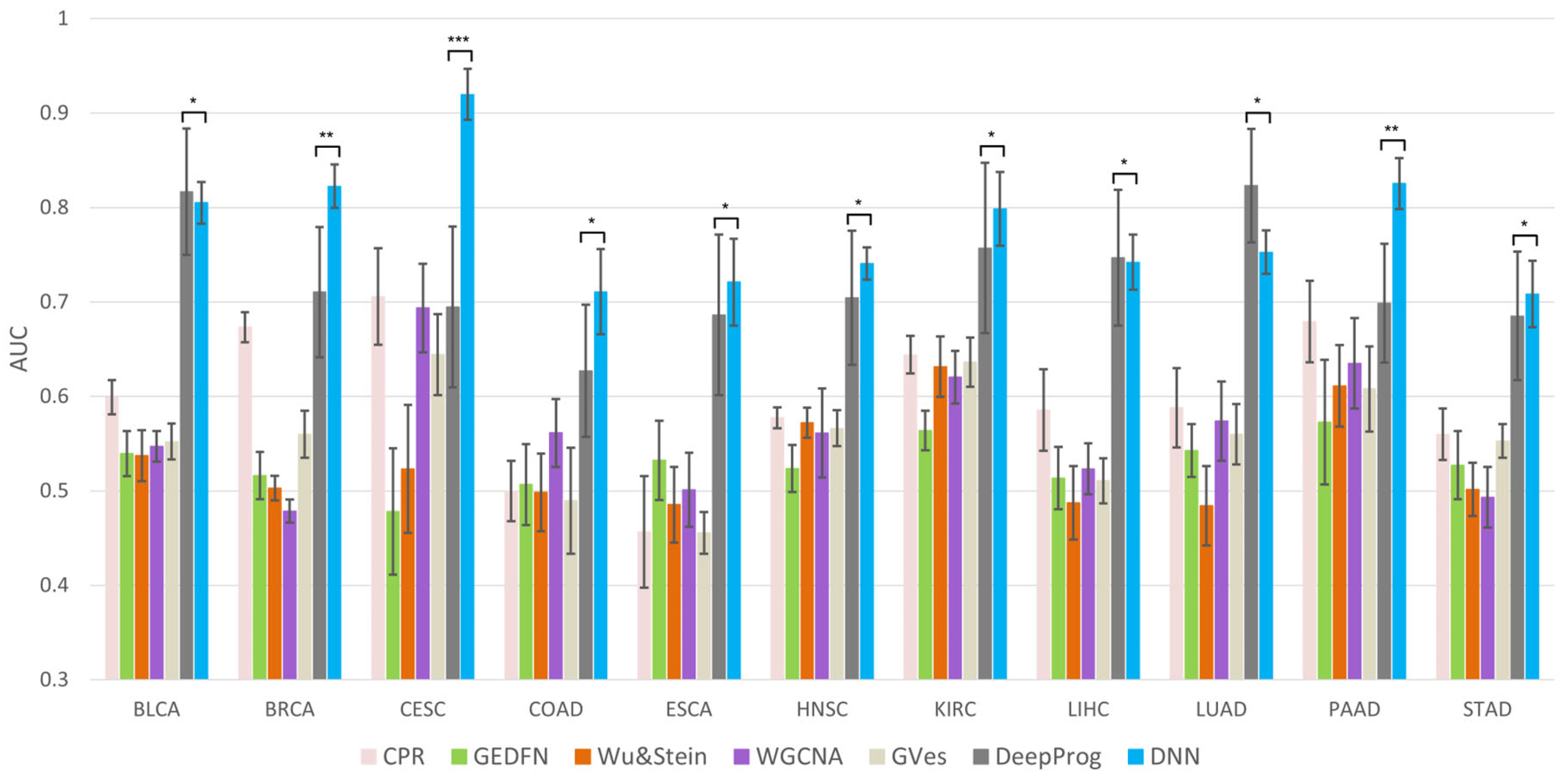
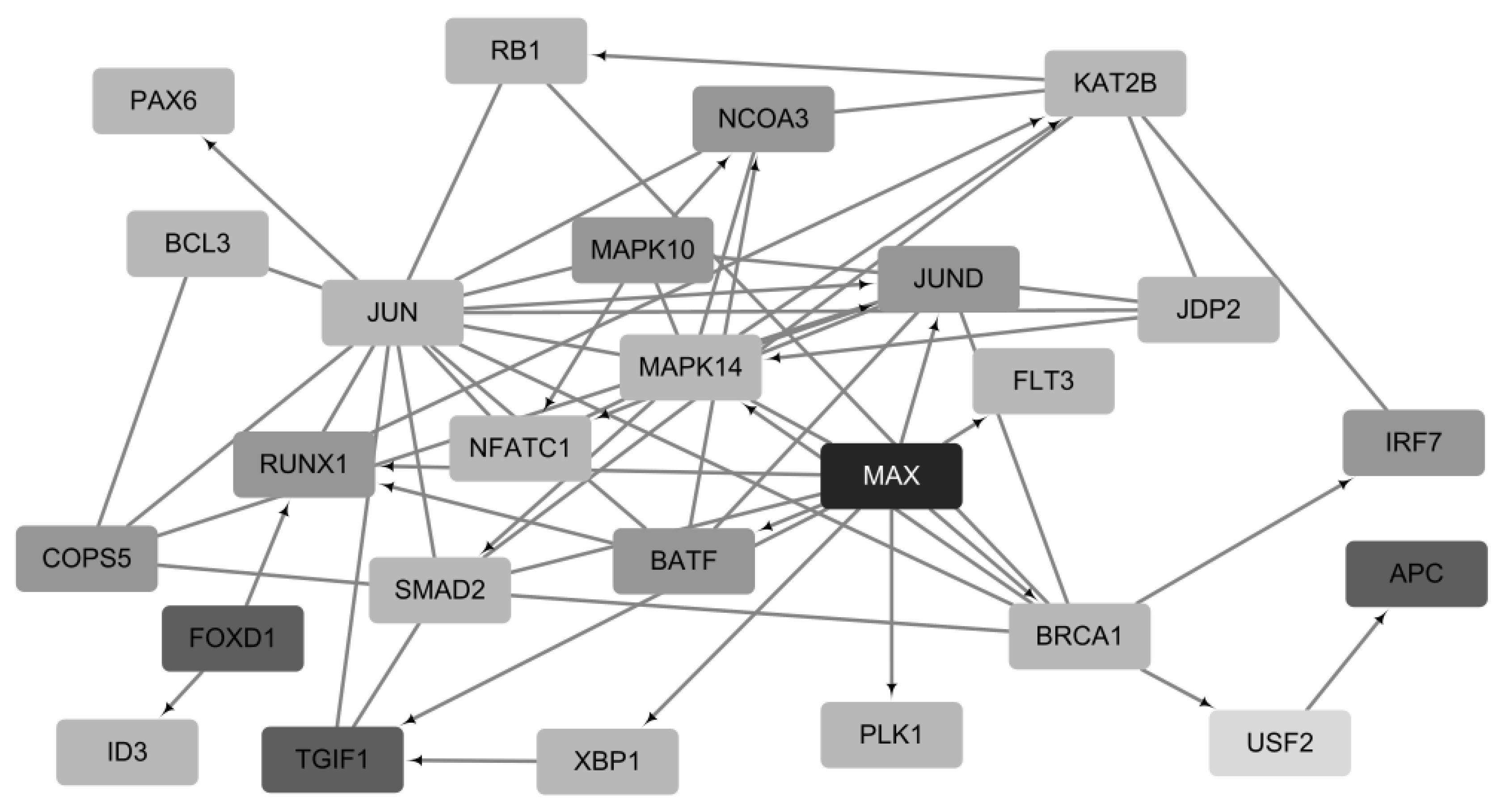
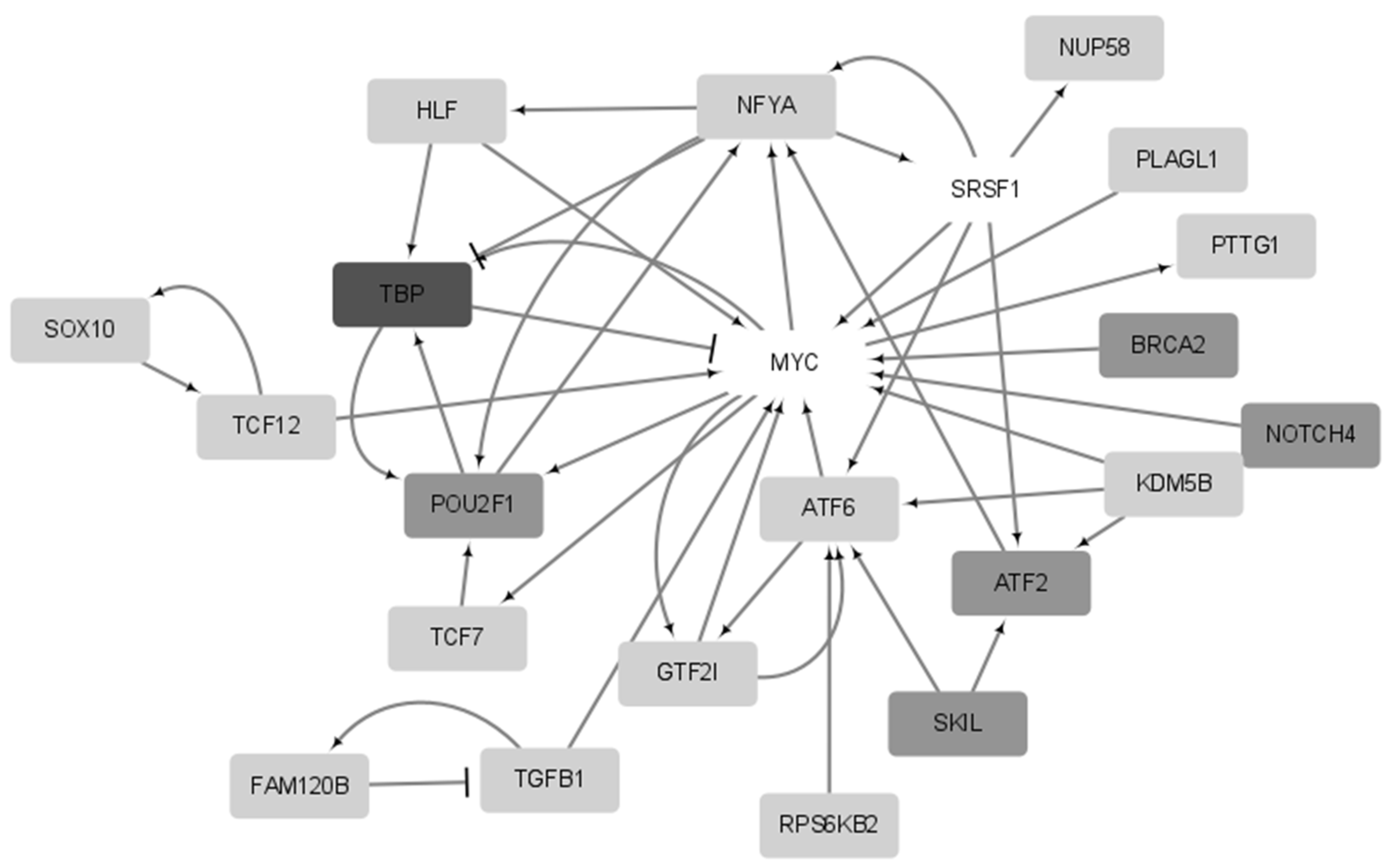
2.5. Functional Analysis of Prognostic Genes
3. Discussion
4. Methods and Materials
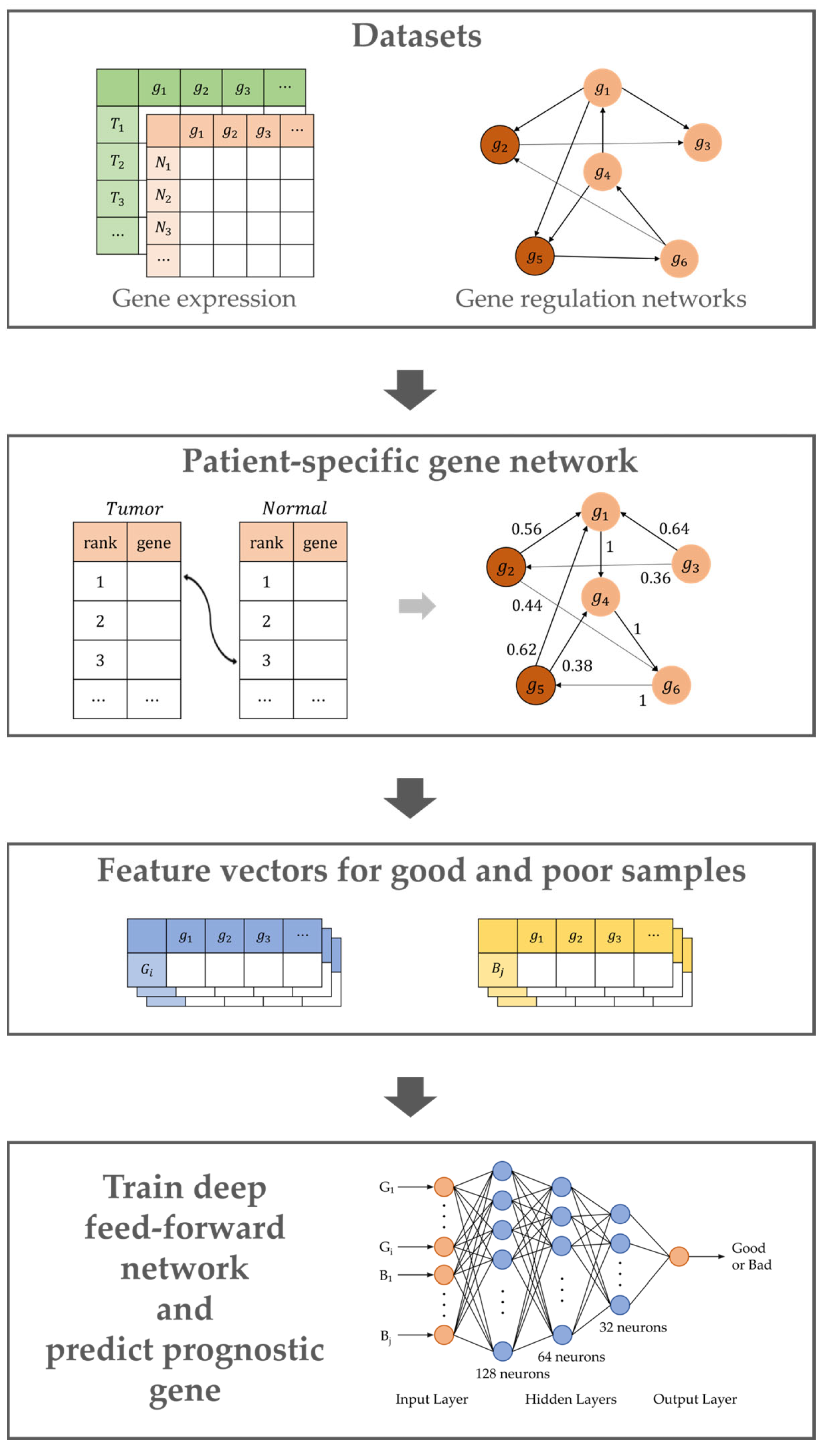
4.1. Overview
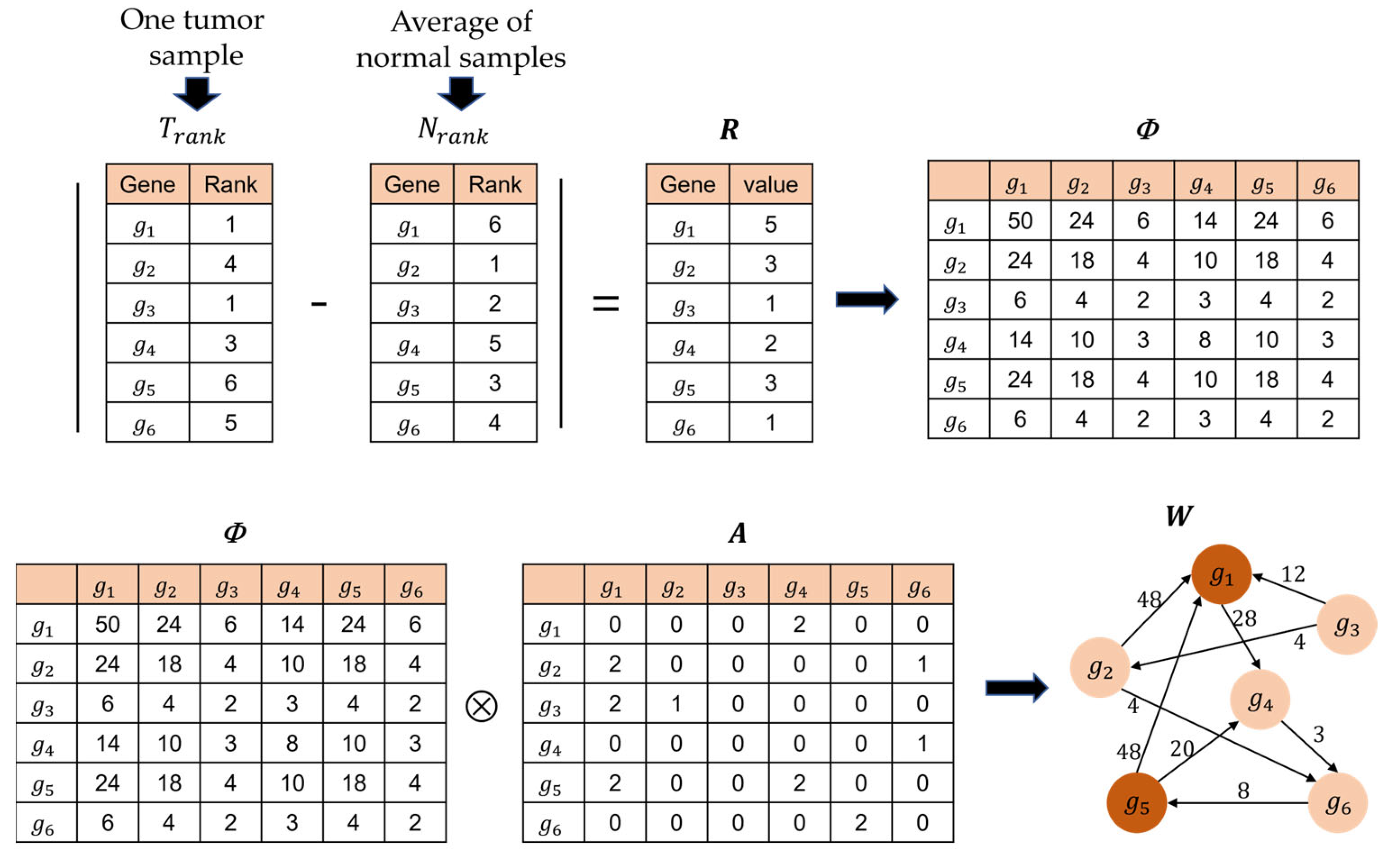
4.2. Building the Patient-Specific Gene Network
4.3. Calculation of Genetic Impact Scores
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jardillier, R.; Chatelain, F.; Guyon, L. Bioinformatics methods to select prognostic biomarker genes from large scale datasets: A review. Biotechnol. J. 2018, 13, 1800103. [Google Scholar] [CrossRef]
- Reel, P.S.; Reel, S.; Pearson, E.; Trucco, E.; Jefferson, E. Using machine learning approaches for multi-omics data analysis: A review. Biotechnol. Adv. 2021, 49, 107739. [Google Scholar] [CrossRef]
- Picard, M.; Scott-Boyer, M.-P.; Bodein, A.; Périn, O.; Droit, A. Integration strategies of multi-omics data for machine learning analysis. Comput. Struct. Biotechnol. J. 2021, 19, 3735–3746. [Google Scholar] [CrossRef]
- Zhao, M.; He, W.; Tang, J.; Zou, Q.; Guo, F. A comprehensive overview and critical evaluation of gene regulatory network inference technologies. Brief. Bioinform. 2021, 22, bbab009. [Google Scholar] [CrossRef]
- Delgado, F.M.; Gómez-Vela, F. Computational methods for Gene Regulatory Networks reconstruction and analysis: A review. Artif. Intell. Med. 2019, 95, 133–145. [Google Scholar] [CrossRef]
- Ko, S.; Choi, J.; Ahn, J. GVES: Machine learning model for identification of prognostic genes with a small dataset. Sci. Rep. 2021, 11, 439. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Kong, Y.; Yu, T. A graph-embedded deep feedforward network for disease outcome classification and feature selection using gene expression data. Bioinformatics 2018, 34, 3727–3737. [Google Scholar] [CrossRef]
- Olden, J.D.; Jackson, D.A. Illuminating the “black box”: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002, 154, 135–150. [Google Scholar] [CrossRef]
- Kim, M.; Oh, I.; Ahn, J. An improved method for prediction of cancer prognosis by network learning. Genes 2018, 9, 478. [Google Scholar] [CrossRef]
- Akhavan-Safar, M.; Teimourpour, B. KatzDriver: A network based method to cancer causal genes discovery in gene regulatory network. Biosystems 2021, 201, 104326. [Google Scholar] [CrossRef]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Poirion, O.B.; Jing, Z.; Chaudhary, K.; Huang, S.; Garmire, L.X. DeepProg: An ensemble of deep-learning and machine-learning models for prognosis prediction using multi-omics data. Genome Med. 2021, 13, 112. [Google Scholar] [CrossRef]
- Hou, J.P.; Ma, J. DawnRank: Discovering personalized driver genes in cancer. Genome Med. 2014, 6, 56. [Google Scholar] [CrossRef]
- Tomczak, K.; Czerwińska, P.; Wiznerowicz, M. Review the Cancer Genome Atlas (TCGA): An Immeasurable Source of Knowledge. Contemp. Oncol./Współczesna Onkol. 2015, 2015, 68–77. [Google Scholar] [CrossRef]
- Croft, D.; O’kelly, G.; Wu, G.; Haw, R.; Gillespie, M.; Matthews, L.; Caudy, M.; Garapati, P.; Gopinath, G.; Jassal, B. Reactome: A database of reactions, pathways and biological processes. Nucleic Acids Res. 2010, 39, D691–D697. [Google Scholar] [CrossRef]
- Liu, Z.-P.; Wu, C.; Miao, H.; Wu, H. RegNetwork: An integrated database of transcriptional and post-transcriptional regulatory networks in human and mouse. Database 2015, 2015, bav095. [Google Scholar] [CrossRef]
- Han, H.; Cho, J.-W.; Lee, S.; Yun, A.; Kim, H.; Bae, D.; Yang, S.; Kim, C.Y.; Lee, M.; Kim, E. TRRUST v2: An expanded reference database of human and mouse transcriptional regulatory interactions. Nucleic Acids Res. 2018, 46, D380–D386. [Google Scholar] [CrossRef]
- Kanehisa, M.; Goto, S. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000, 28, 27–30. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Wu, G.; Stein, L. A network module-based method for identifying cancer prognostic signatures. Genome Biol. 2012, 13, R112. [Google Scholar] [CrossRef]
- Sondka, Z.; Bamford, S.; Cole, C.G.; Ward, S.A.; Dunham, I.; Forbes, S.A. The COSMIC Cancer Gene Census: Describing genetic dysfunction across all human cancers. Nat. Rev. Cancer 2018, 18, 696–705. [Google Scholar] [CrossRef] [PubMed]
- Gundem, G.; Perez-Llamas, C.; Jene-Sanz, A.; Kedzierska, A.; Islam, A.; Deu-Pons, J.; Furney, S.J.; Lopez-Bigas, N. IntOGen: Integration and data mining of multidimensional oncogenomic data. Nat. Methods 2010, 7, 92–93. [Google Scholar] [CrossRef] [PubMed]
- Dennis, G.; Sherman, B.T.; Hosack, D.A.; Yang, J.; Gao, W.; Lane, H.C.; Lempicki, R.A. DAVID: Database for annotation, visualization, and integrated discovery. Genome Biol. 2003, 4, R60. [Google Scholar] [CrossRef]
- Lánczky, A.; Győrffy, B. Web-Based Survival Analysis Tool Tailored for Medical Research (KMplot): Development and Implementation. J. Med. Internet Res. 2021, 23, e27633. [Google Scholar] [CrossRef]
- Uhlen, M.; Zhang, C.; Lee, S.; Sjöstedt, E.; Fagerberg, L.; Bidkhori, G.; Benfeitas, R.; Arif, M.; Liu, Z.; Edfors, F.; et al. A pathology atlas of the human cancer transcriptome. Science 2017, 357, 2507. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Fu, J.; Zeng, Z.; Cohen, D.; Li, J.; Chen, Q.; Li, B.; Liu, X.S. TIMER2.0 for analysis of tumor-infiltrating immune cells. Nucleic Acids Res. 2020, 48, W509–W514. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cancer | Criteria for Label | Number of Good Samples | Number of Bad Samples | Number of Normal Samples | Number of Genes |
|---|---|---|---|---|---|
| BLCA | 2 years | 73 | 83 | 19 | 15,779 |
| BRCA | 5 years | 90 | 63 | 113 | 15,557 |
| CESC | 4 years | 25 | 23 | 3 | 15,506 |
| COAD | 3 years | 35 | 32 | 41 | 15,299 |
| ESCA | 1 years | 33 | 30 | 11 | 15,984 |
| HNSC | 2 years | 99 | 120 | 44 | 15,933 |
| KIRC | 4 years | 66 | 51 | 72 | 15,782 |
| LIHC | 2 years | 78 | 55 | 50 | 14,965 |
| LUAD | 2 years | 67 | 64 | 59 | 15,417 |
| PAAD | 1 years | 34 | 27 | 4 | 16,024 |
| STAD | 1 years | 63 | 45 | 35 | 15,638 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Jung, H.; Park, J.; Ahn, J. Accurate Prediction of Cancer Prognosis by Exploiting Patient-Specific Cancer Driver Genes. Int. J. Mol. Sci. 2023, 24, 6445. https://doi.org/10.3390/ijms24076445
Lee S, Jung H, Park J, Ahn J. Accurate Prediction of Cancer Prognosis by Exploiting Patient-Specific Cancer Driver Genes. International Journal of Molecular Sciences. 2023; 24(7):6445. https://doi.org/10.3390/ijms24076445
Chicago/Turabian StyleLee, Suyeon, Heewon Jung, Jiwoo Park, and Jaegyoon Ahn. 2023. "Accurate Prediction of Cancer Prognosis by Exploiting Patient-Specific Cancer Driver Genes" International Journal of Molecular Sciences 24, no. 7: 6445. https://doi.org/10.3390/ijms24076445
APA StyleLee, S., Jung, H., Park, J., & Ahn, J. (2023). Accurate Prediction of Cancer Prognosis by Exploiting Patient-Specific Cancer Driver Genes. International Journal of Molecular Sciences, 24(7), 6445. https://doi.org/10.3390/ijms24076445