Monocular Visual-Inertial SLAM: Continuous Preintegration and Reliable Initialization

Abstract
:1. Introduction
2. Graph Optimization
2.1. IMU Factor with Preintegration
2.1.1. IMU State and Motion Model
2.1.2. Mean Propagation
2.1.3. Error-State Motion Model
- The covariance of can be accurately computed by using the following differential equation:
- The autonomous linear system can guarantee safe and reliable preintegration in the sense of the first-order approximation. Given , we can easily calculate based on the linear system theory for any as the following:where ⊕ is the inverse of the operation ⊖ defined in (5):The matrix can be pre-integrated from the following differential equationwith the initial state . Here we stress that (10) makes hundreds of measurements unnecessary to be stored after preintegration.
2.1.4. IMU Factor
- Connected Nodes: the IMU state at time-step i and the IMU state the IMU state at time-step j.
- Cost function:
- Covariance matrix:
- Measurements: the pre-integrated matrix and the IMU biases used in the preintegration.
2.2. Vision Factor
- Connected Nodes: the IMU state at time-step i and the map point f
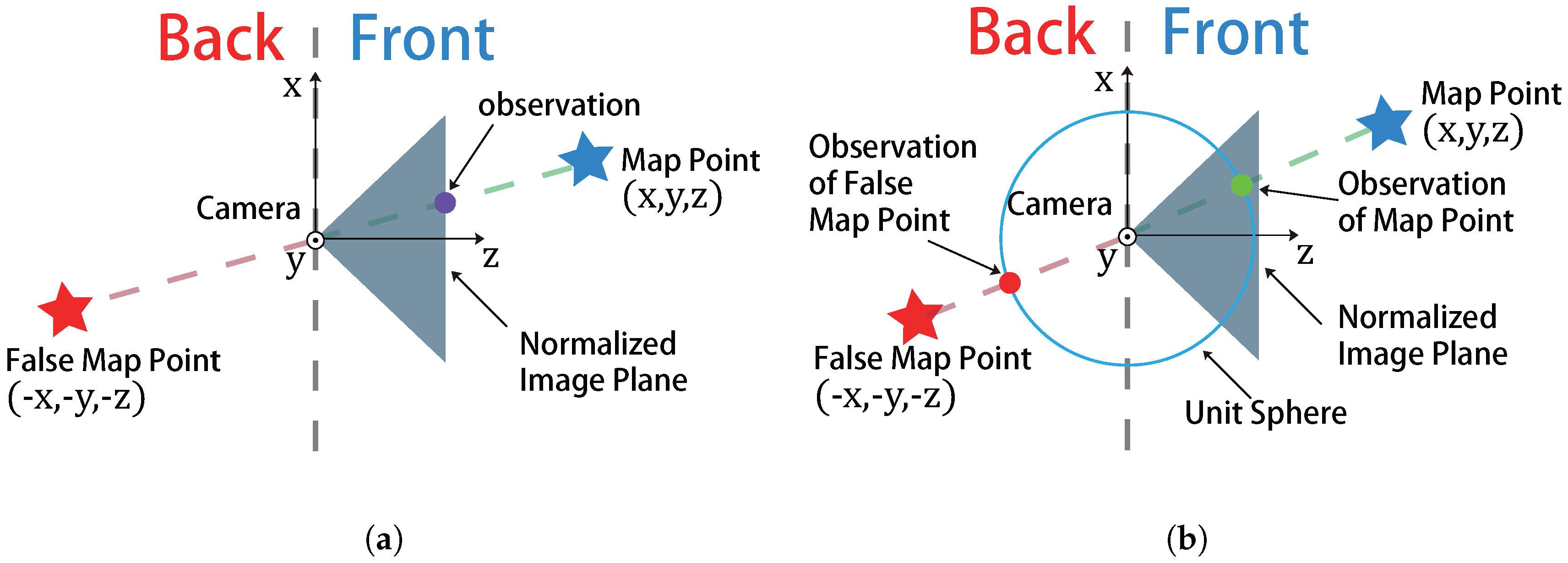
- Cost function:where for and (). Note the directional error can be seen as the normalized vector between map point and camera center, which project the map point into a unit sphere. Thus, unlike the projection error in (18) which is an unbounded factor, the directional error is bounded into the range of , which is friendly to the convergence of the algorithm.
- Covariance matrix:
2.3. Nonlinear Least Squares Form
| Algorithm 1: Solving Equation (21) by Using the Gauss-Newton Algorithm |
 |
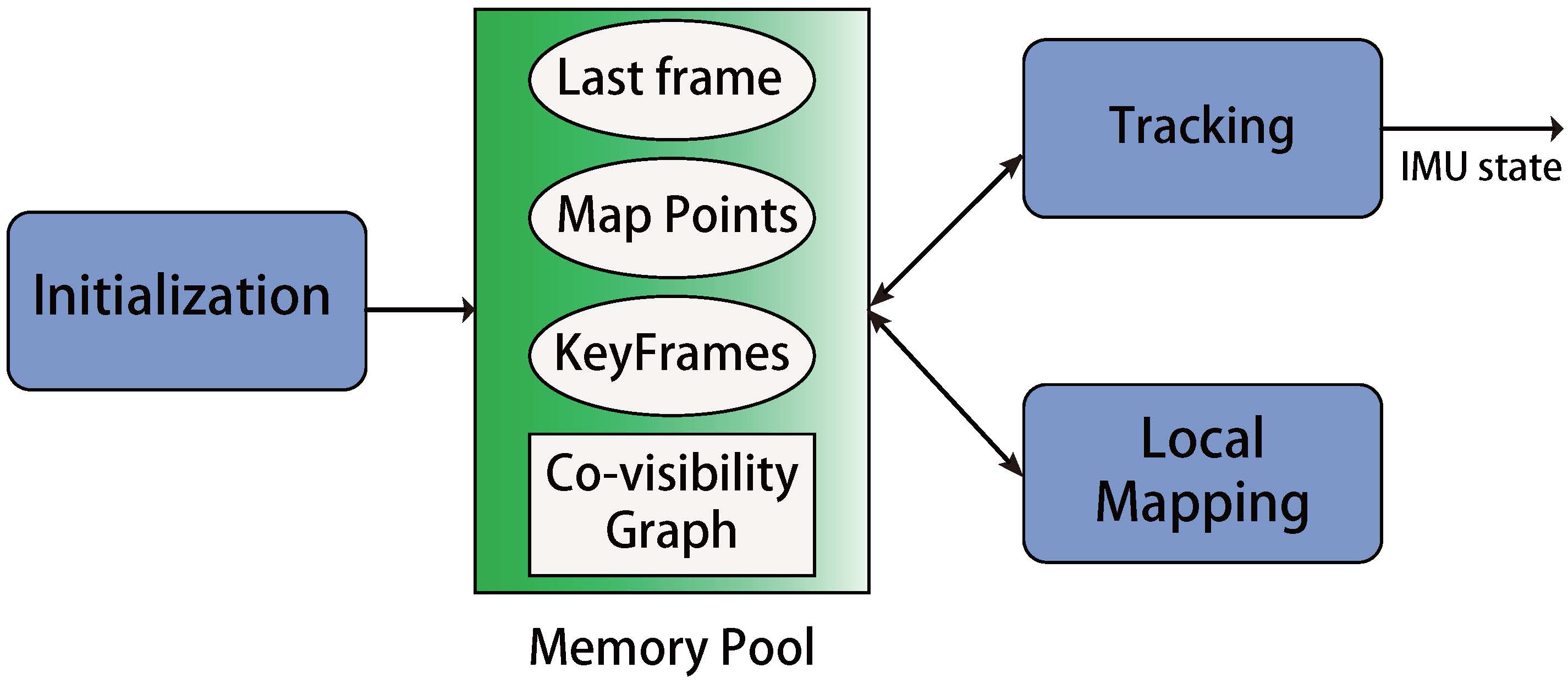
3. Visual Inertial SLAM Algorithm
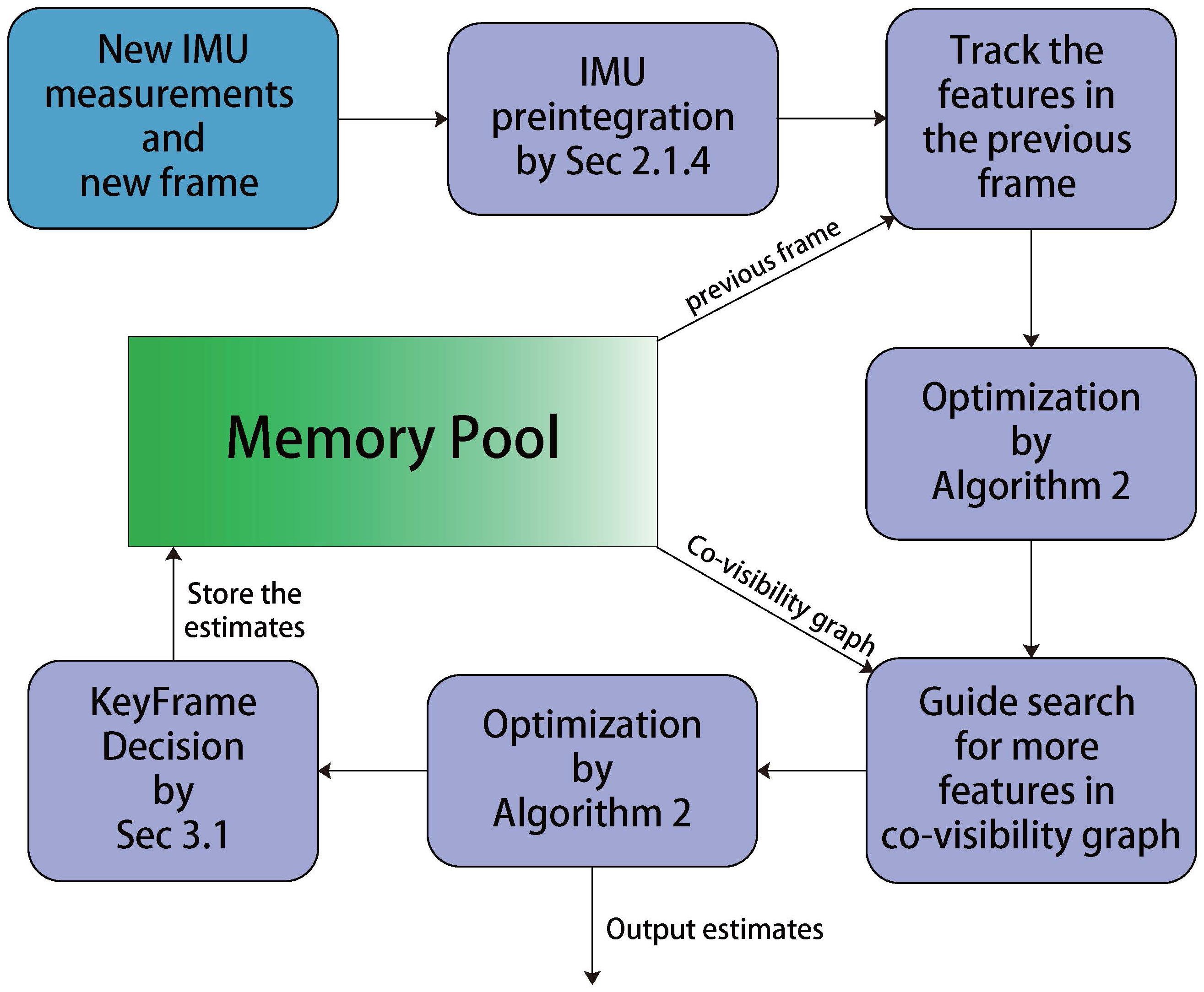
3.1. Tracking
| Algorithm 2: Optimization (24) in Tracking |
 |
3.2. Local Mapping
3.2.1. Creat Map Points
3.2.2. Delete Map Points
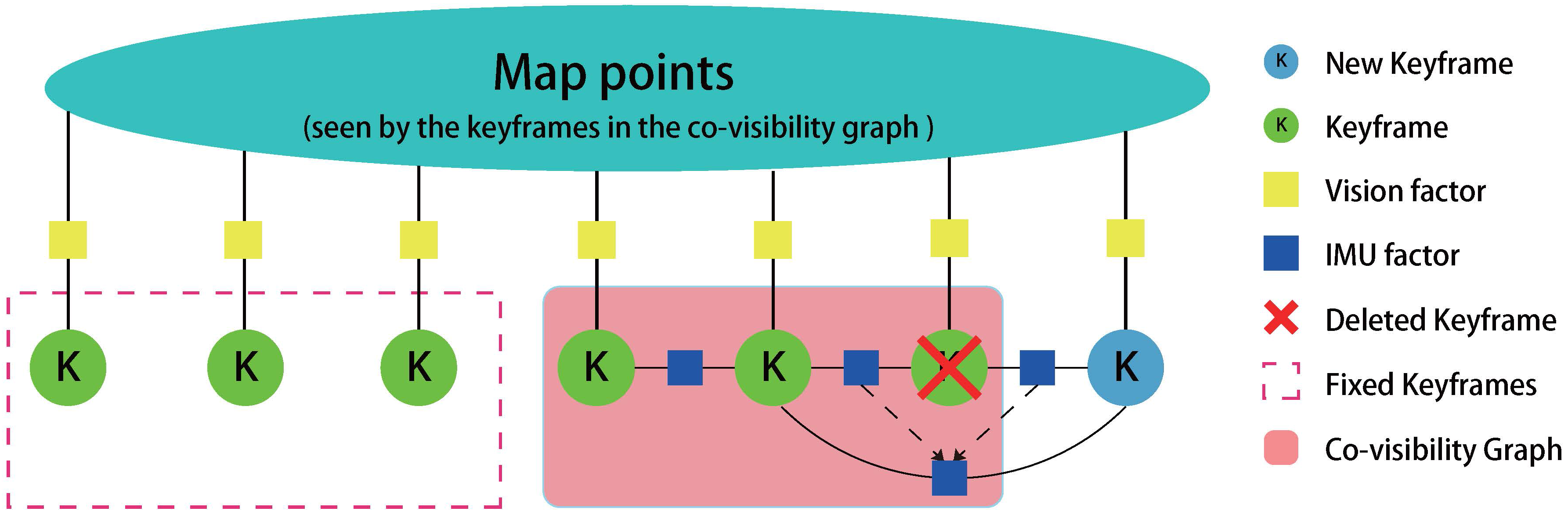
3.2.3. Delete KeyFrames
| Algorithm 3: The Fusion of Two Consequential IMU Factors |
| Input: two consequential IMU factors and Output: IMU factor Process: Connected Nodes: the IMU state and the IMU state the IMU state . Cost function: Measurements: the pre-integrated matrix and the IMU biases . |
3.2.4. Optimization
- (1)
- the latest IMU state and all IMU states in the co-visibility graph (w.r.t. );
- (2)
- all map points observed by in the co-visibility graph (w.r.t. );
- (3)
- all IMU state that observes the map points in (b). Note that these variables are fixed in the optimization.
- The IMU factors that connects the consecutive IMU states in (a).
- The vision factors that connects the IMU states in (a) or (b) and the map points in (c).
| Algorithm 4: Optimization in Local Mapping |
 |
4. Initialization
4.1. Visual Estimation
4.2. IMU Preintegration
4.3. Visual-Inertial Alignment
4.4. Checking
4.5. Optimization
4.6. IMU Factor Fusion
5. Implementation Details and Results
5.1. Initilization Implementation
- Our method jointly optimizes the scale, gravitational vector, IMU biases, IMU velocity with proper covariance matrix from preintegration.
- Our method subtly uses the knowledge of the magnitude of the gravitational vector such that the ambiguity between the gravitational vector and the accelerometer bias can be avoided.
- We have a criterion to check whether the estimates for initialization is robust or not.
5.2. Preliminary Test on Low-Cost Hardware
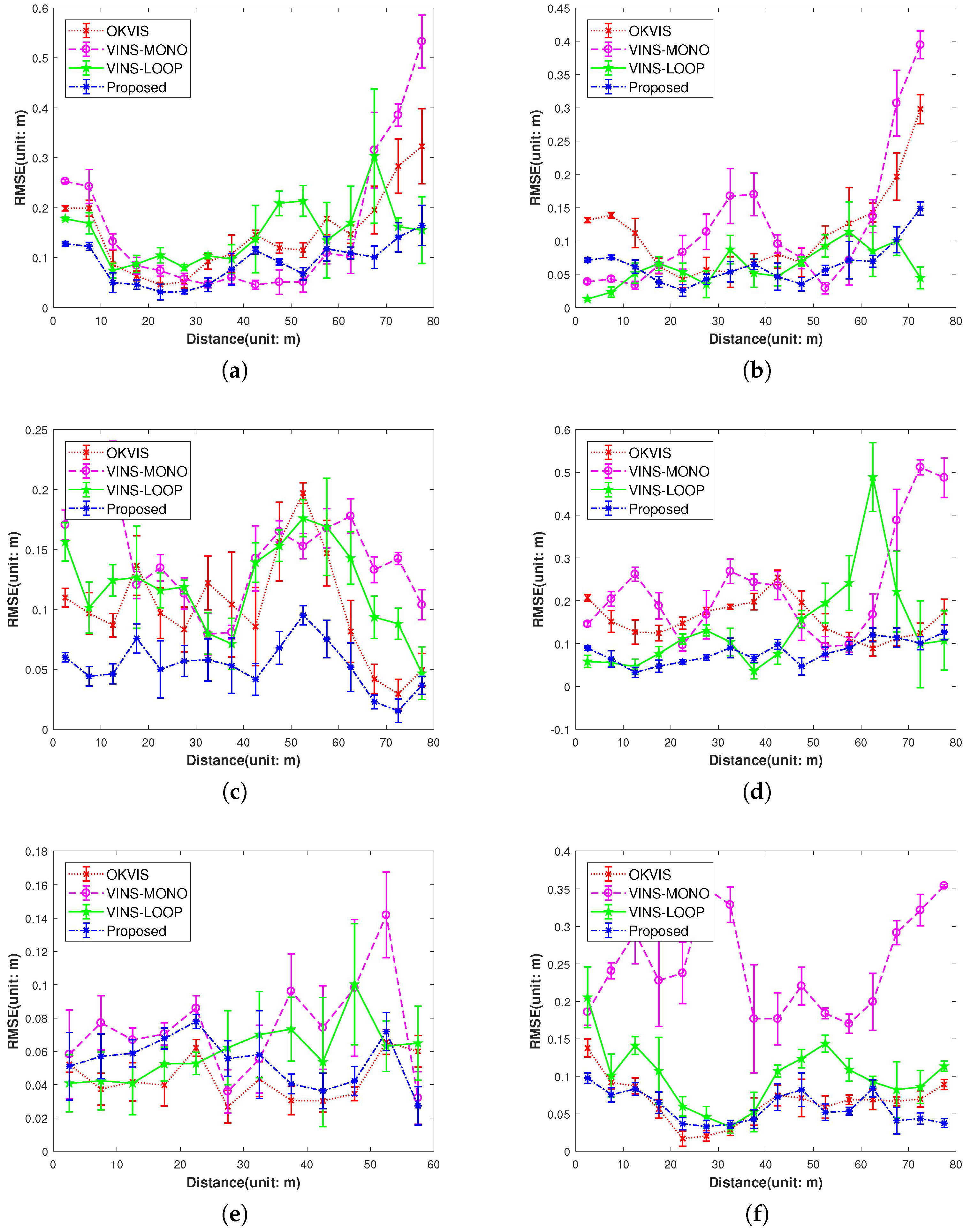
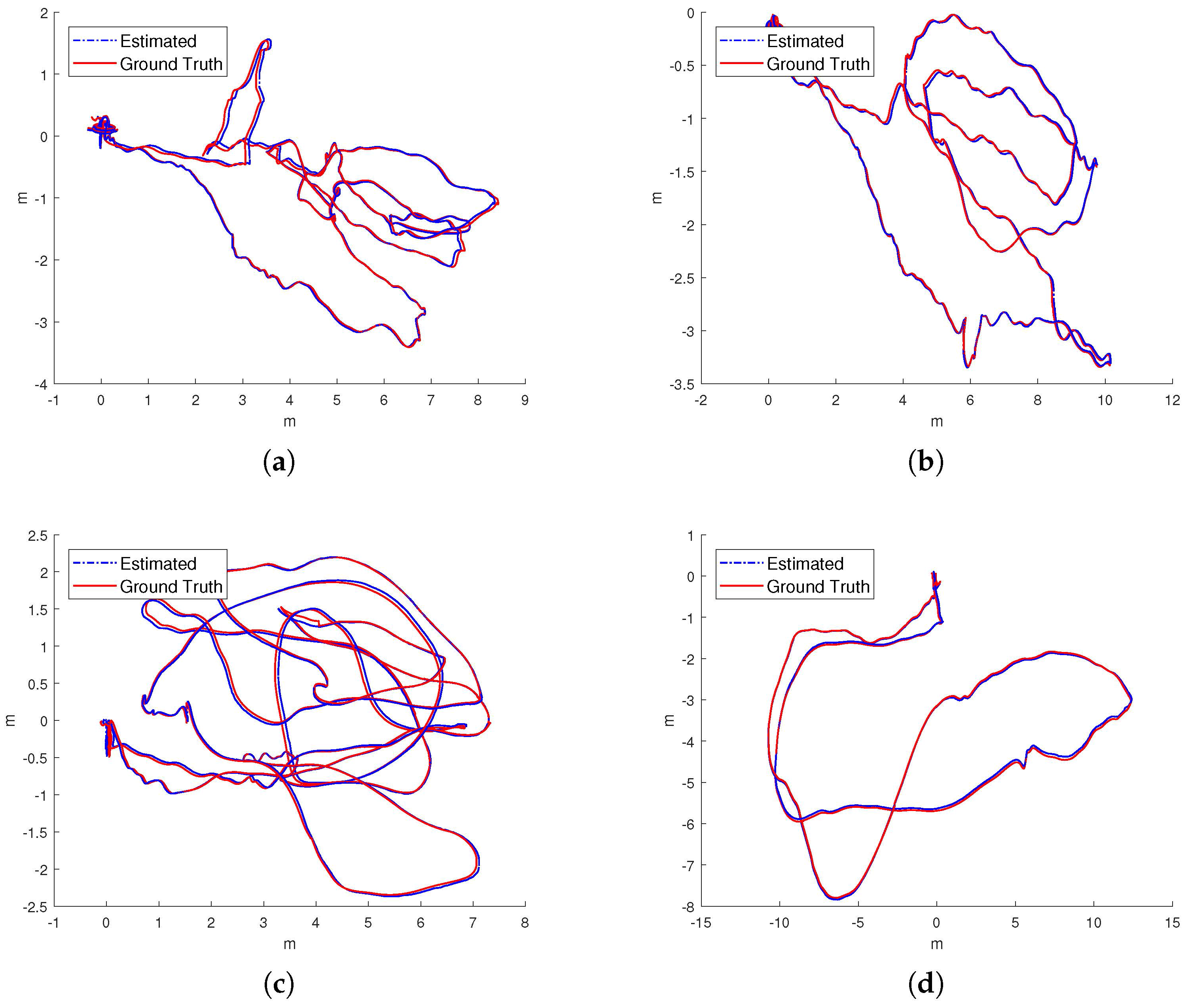
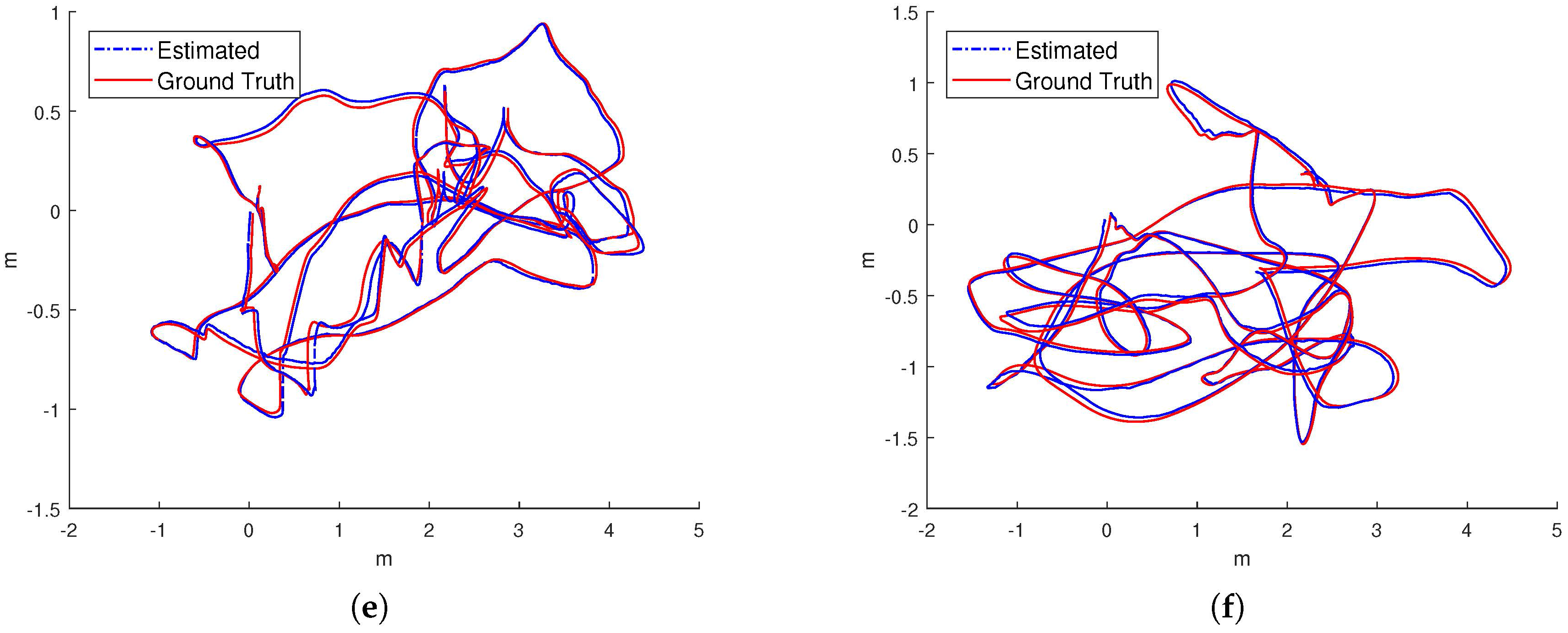
5.3. Evaluation on EuRoC
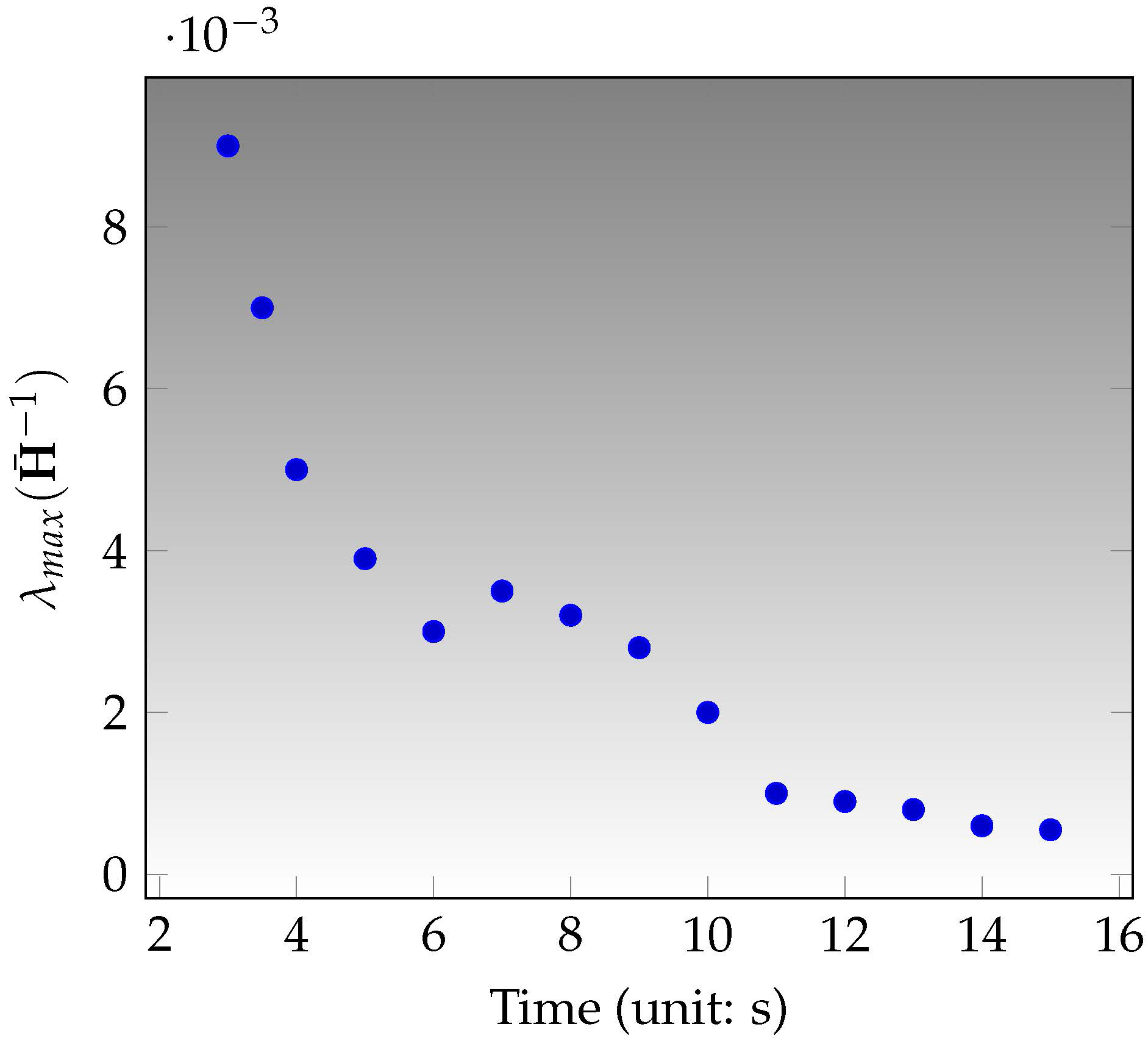
- Our proposed IMU factor is more linear and it does not need reintegration when optimization. The cost function of our proposed IMU factor is more linear in terms of the defined retraction ⊕. The propagated covariance can better reflect the uncertainty of the physical system.
- The use of the separability trick and the novel vision factor makes convergence faster than the conventional method such that local or global minimum can be reached after few iterations in optimization.
- The use of co-visibility graph in our system can provide edges from current IMU state to the map points observed by the earlier IMU states, Since the data sequences in EuRoC is taken in a single small room, the drone can get the earlier observations easily by turning around, which makes the algorithm with co-visibility graph performs with much better precision.
- The fusion of IMU factors also provides the constraints between two consequential IMU states.
6. Discussion and Future Work
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Math
References
- Bachrach, A.; de Winter, A.; He, R.; Hemann, G.; Prentice, S.; Roy, N. RANGE—Robust autonomous navigation in GPS-denied environments. In Proceedings of the International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 1096–1097. [Google Scholar]
- Grzonka, S.; Grisetti, G.; Burgard, W. A Fully Autonomous Indoor Quadrotor. IEEE Trans. Robot. 2012, 28, 90–100. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pat. Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Civera, J.; Davison, A.J.; Montiel, J.M.M. Inverse Depth Parametrization for Monocular SLAM. IEEE Trans. Robot. 2008, 24, 932–945. [Google Scholar] [CrossRef]
- Eade, E.; Drummond, T. Unified Loop Closing and Recovery for Real Time Monocular SLAM. BMVC 2008, 13, 136. [Google Scholar]
- Eade, E.; Drummond, T. Scalable Monocular SLAM. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 17–22 June 2006; pp. 469–476. [Google Scholar]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Engel, J.; Sturm, J.; Cremers, D. Semi-dense Visual Odometry for a Monocular Camera. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 1449–1456. [Google Scholar]
- Olson, C.F.; Matthies, L.H.; Schoppers, M.; Maimone, M.W. Stereo ego-motion improvements for robust rover navigation. In Proceedings of the IEEE International Conference on Robotics and Automation, Seoul, Korea, 21–26 May 2001; pp. 1099–1104. [Google Scholar]
- Se, S.; Lowe, D.; Little, J. Mobile Robot Localization and Mapping with Uncertainty using Scale-Invariant Visual Landmarks. Int. J. Robot. Res. 2002, 21, 735–758. [Google Scholar] [CrossRef]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D mapping with an RGB-D camera. IEEE Trans. Robot. 2014, 30, 177–187. [Google Scholar] [CrossRef]
- Scaramuzza, D.; Siegwart, R. Appearance-Guided Monocular Omnidirectional Visual Odometry for Outdoor Ground Vehicles. IEEE Trans. Robot. 2008, 24, 1015–1026. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pat. Anal. Mach. Intell. 2017, PP, 1. [Google Scholar] [CrossRef] [PubMed]
- Civera, J.; Davison, A.J.; Montiel, J.M.M. Inverse Depth to Depth Conversion for Monocular SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 2778–2783. [Google Scholar]
- Li, M.; Mourikis, A.I. High-precision, consistent EKF-based visual-inertial odometry. Int. J. Robot. Res. 2013, 32, 690–711. [Google Scholar] [CrossRef]
- Hesch, J.A.; Kottas, D.G.; Bowman, S.L.; Roumeliotis, S.I. Observability-Constrained Vision-Aided Inertial Navigation; Technical Report; University of Minnesota: Minneapolis, MN, USA, 2012. [Google Scholar]
- Lynen, S.; Achtelik, M.W.; Weiss, S.; Chli, M.; Siegwart, R. A robust and modular multi-sensor fusion approach applied to MAV navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 3923–3929. [Google Scholar]
- Jones, E.S.; Soatto, S. Visual-inertial navigation, mapping and localization: A scalable real-time causal approach. Int. J. Robot. Res. 2011, 30, 407–430. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. g2o: A general framework for graph optimization. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]
- Agarwal, S.; Mierle, K. Ceres Solver. Available online: http://ceres-solver.org (accessed on 14 November 2017).
- Kaess, M.; Ranganathan, A.; Dellaert, F. iSAM: Incremental Smoothing and Mapping. IEEE Trans. Robot. 2008, 24, 1365–1378. [Google Scholar] [CrossRef]
- Dellaert, F. Factor graphs and GTSAM: A Hands-on Introduction; Technical Report; Georgia Institute of Technology: Atlanta, GA, USA, 2012. [Google Scholar]
- Sibley, G.; Matthies, L.; Sukhatme, G. A sliding window filter for incremental SLAM. In Unifying Perspectives in Computational and Robot Vision; Springer: Berlin, Germany, 2008; pp. 103–112. [Google Scholar]
- Sibley, G.; Matthies, L.; Sukhatme, G. Sliding window filter with application to planetary landing. J. Field Robot. 2010, 27, 587–608. [Google Scholar] [CrossRef]
- Qin, T.; Shen, S. Robust initialization of monocular visual-inertial estimation on aerial robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Weiss, S.; Achtelik, M.W.; Lynen, S.; Achtelik, M.C.; Kneip, L.; Chli, M.; Siegwart, R. Monocular Vision for Long-term Micro Aerial Vehicle State Estimation: A Compendium. J. Field Robot. 2013, 30, 803–831. [Google Scholar] [CrossRef]
- Roumeliotis, S.I.; Burdick, J.W. Stochastic cloning: A generalized framework for processing relative state measurements. In Proceedings of the IEEE International Conference on Robotics and Automation, Washington, DC, USA, 11–15 May 2002; pp. 1788–1795. [Google Scholar]
- Forster, C.; Carlone, L.; Dellaert, F.; Scaramuzza, D. On-Manifold Preintegration for Real-Time Visual–Inertial Odometry. IEEE Trans. Robot. 2017, 33, 1–21. [Google Scholar] [CrossRef]
- Concha, A.; Loianno, G.; Kumar, V.; Civera, J. Visual-inertial direct SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 1331–1338. [Google Scholar]
- Zhang, T.; Wu, K.; Su, D.; Huang, S.; Dissanayake, G. An Invariant-EKF VINS Algorithm for Improving Consistency. arXiv 2017, arXiv:1702.07920. [Google Scholar]
- Hesch, J.A.; Kottas, D.G.; Bowman, S.L.; Roumeliotis, S.I. Consistency Analysis and Improvement of Vision-aided Inertial Navigation. IEEE Trans. Robot. 2014, 30, 158–176. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, K.; Song, J.; Huang, S.; Dissanayake, G. Convergence and Consistency Analysis for a 3-D Invariant-EKF SLAM. IEEE Robot. Autom. Lett. 2017, 2, 733–740. [Google Scholar] [CrossRef]
- Lupton, T.; Sukkarieh, S. Visual-Inertial-Aided Navigation for High-Dynamic Motion in Built Environments Without Initial Conditions. IEEE Trans. Robot. 2012, 28, 61–76. [Google Scholar] [CrossRef]
- Shen, S.; Mulgaonkar, Y.; Michael, N.; Kumar, V. Initialization-free monocular visual-inertial state estimation with application to autonomous MAVs. In Experimental Robotics; Springer International Publishing: Cham, Switzerland, 2016; pp. 211–227. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Visual-Inertial Monocular SLAM With Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Carlone, L.; Karaman, S. Attention and anticipation in fast visual-inertial navigation. In Proceedings of the International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 3886–3893. [Google Scholar]
- Joshi, S.; Boyd, S. Sensor Selection via Convex Optimization. IEEE Trans. Signal Process. 2009, 57, 451–462. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Shi, J.; Tomasi, C. Good features to track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Eigen Is a C++ Template Library for Linear Algebra: Matrices, Vectors, Numerical Solvers, and Related Algorithms. Available online: http://eigen.tuxfamily.org (accessed on 14 November 2017).
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Barfoot, T.D. State Estimation for Robotics; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | RMSE (Unit: m) | Std (Unit: m) |
|---|---|---|
| 0.0542 | 0.0194 | |
| 0.0607 | 0.0246 | |
| X | X | |
| 0.0424 | 0.0145 | |
| 0.0430 | 0.0150 | |
| 0.1010 | 0.0459 | |
| 0.0643 | 0.0294 | |
| 0.0632 | 0.0257 | |
| 0.0921 | 0.0384 | |
| 0.1378 | 0.0348 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Chen, Z.; Zheng, W.; Wang, H.; Liu, J. Monocular Visual-Inertial SLAM: Continuous Preintegration and Reliable Initialization. Sensors 2017, 17, 2613. https://doi.org/10.3390/s17112613
Liu Y, Chen Z, Zheng W, Wang H, Liu J. Monocular Visual-Inertial SLAM: Continuous Preintegration and Reliable Initialization. Sensors. 2017; 17(11):2613. https://doi.org/10.3390/s17112613
Chicago/Turabian StyleLiu, Yi, Zhong Chen, Wenjuan Zheng, Hao Wang, and Jianguo Liu. 2017. "Monocular Visual-Inertial SLAM: Continuous Preintegration and Reliable Initialization" Sensors 17, no. 11: 2613. https://doi.org/10.3390/s17112613
APA StyleLiu, Y., Chen, Z., Zheng, W., Wang, H., & Liu, J. (2017). Monocular Visual-Inertial SLAM: Continuous Preintegration and Reliable Initialization. Sensors, 17(11), 2613. https://doi.org/10.3390/s17112613