Conformal Prediction Based on K-Nearest Neighbors for Discrimination of Ginsengs by a Home-Made Electronic Nose


Abstract
:1. Introduction
2. Conformal Prediction
2.1. Definition
2.2. Nonconformity Measure
2.3. Prediction in Online Mode
2.4. Prediction in Offline Mode
3. Experiment and Methods
3.1. Sample Preparation
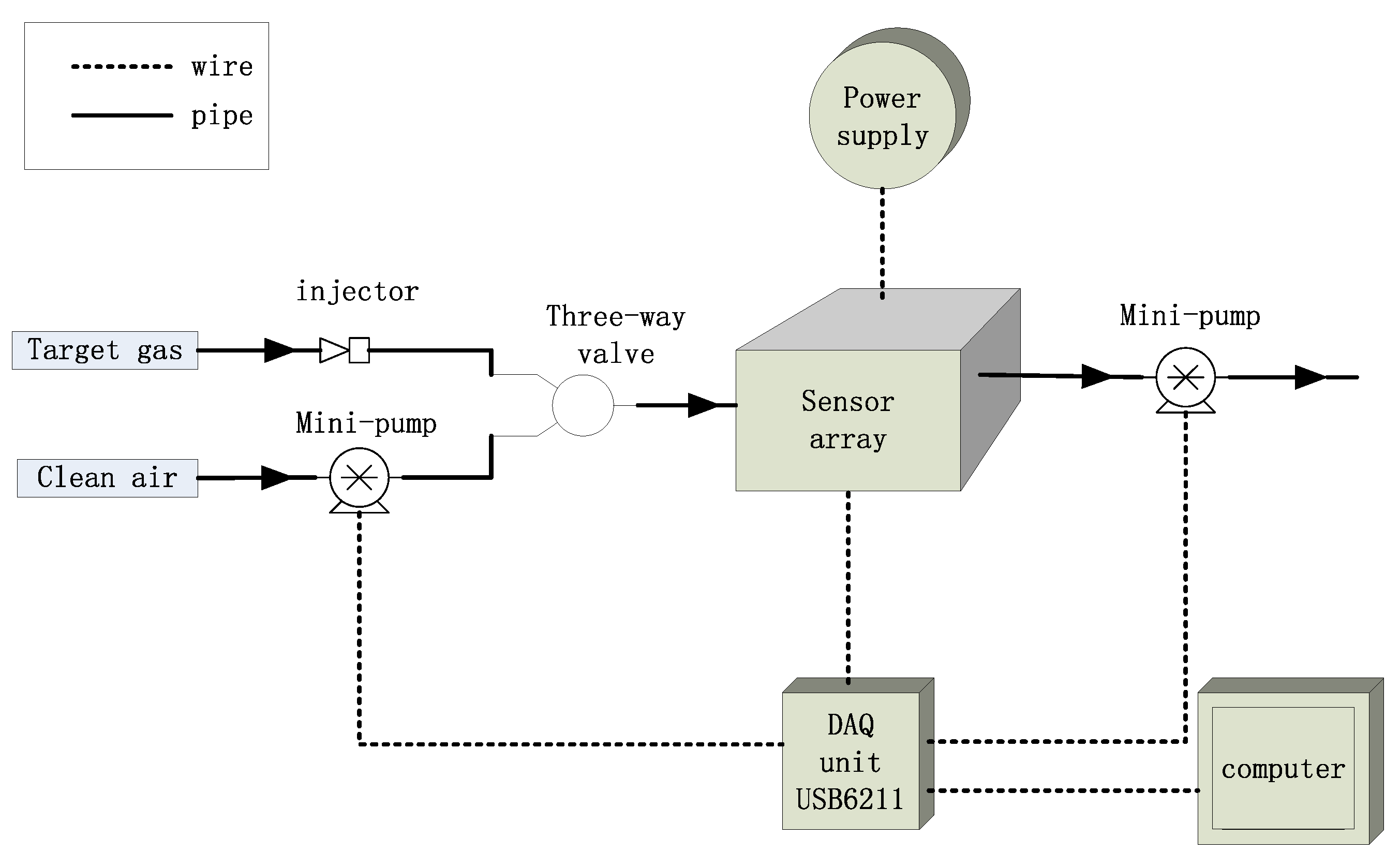
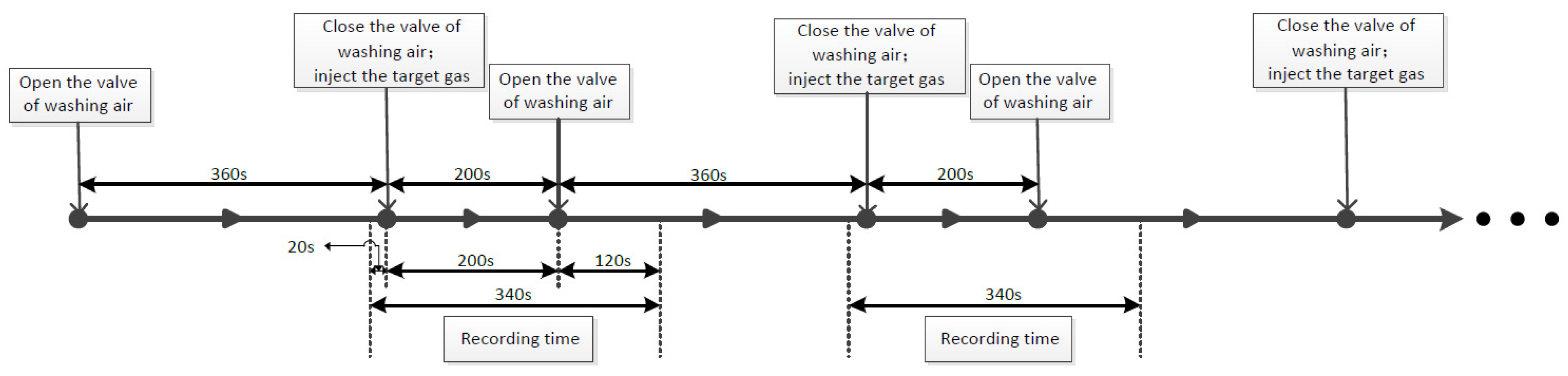
3.2. E-Nose Equipment and Measurement
3.3. Data Preprocessing
- 1.
- The maximal absolute response value, .
- 2.
- The area under the full response curve, , where T is the total measurement time, T = 340 s.
- 3–5.
- Exponential moving average of derivative of R, , . The discretely sampled exponential moving average is defined as with smoothing factors (sampling frequency: 10 Hz). Thus, three different smooth factors “a” give us the last three features.
4. Results and Discussion
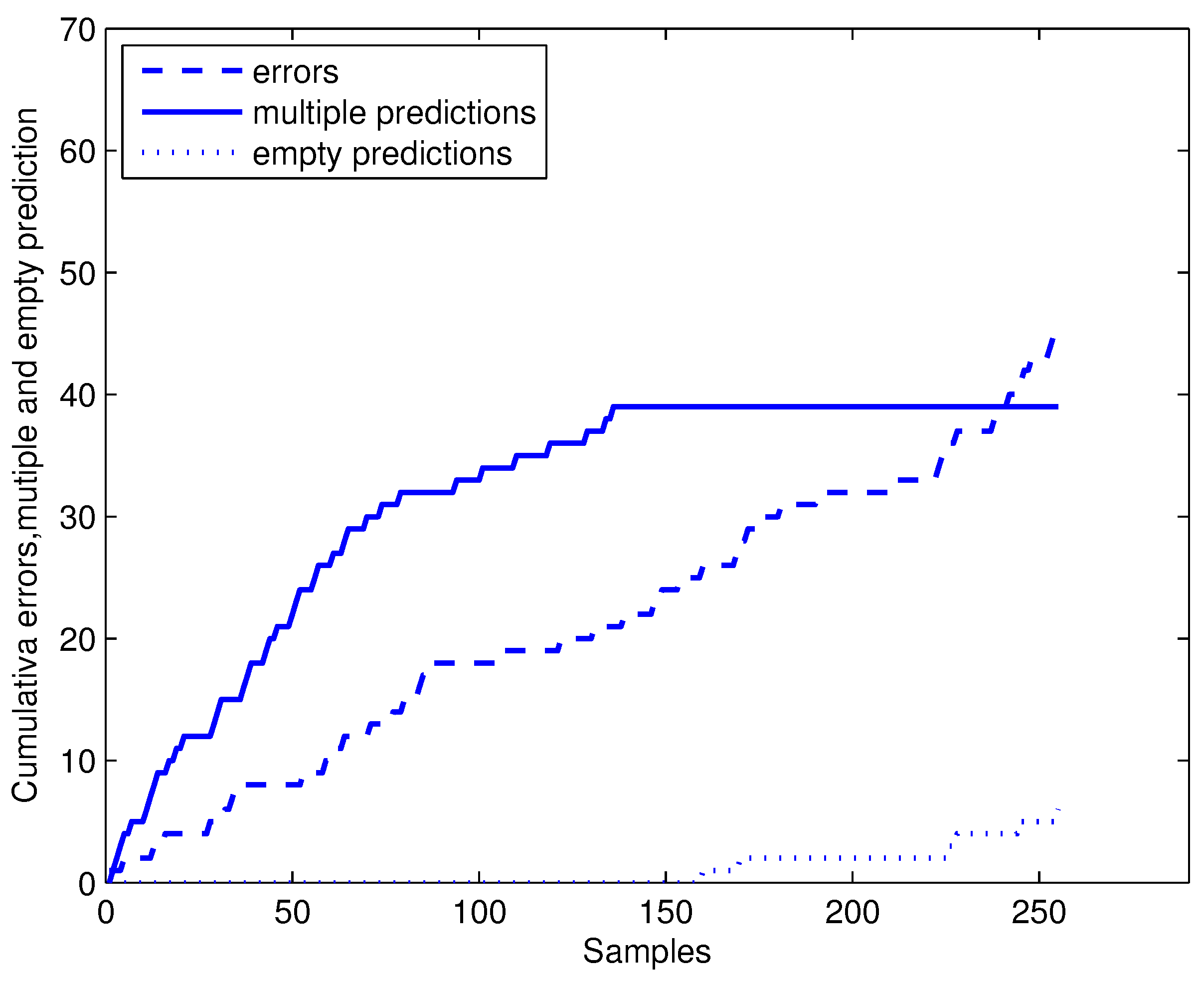
4.1. Comparison of Forced Conformal Prediction with Simple Prediction
4.2. Validity of Online Conformal Prediction
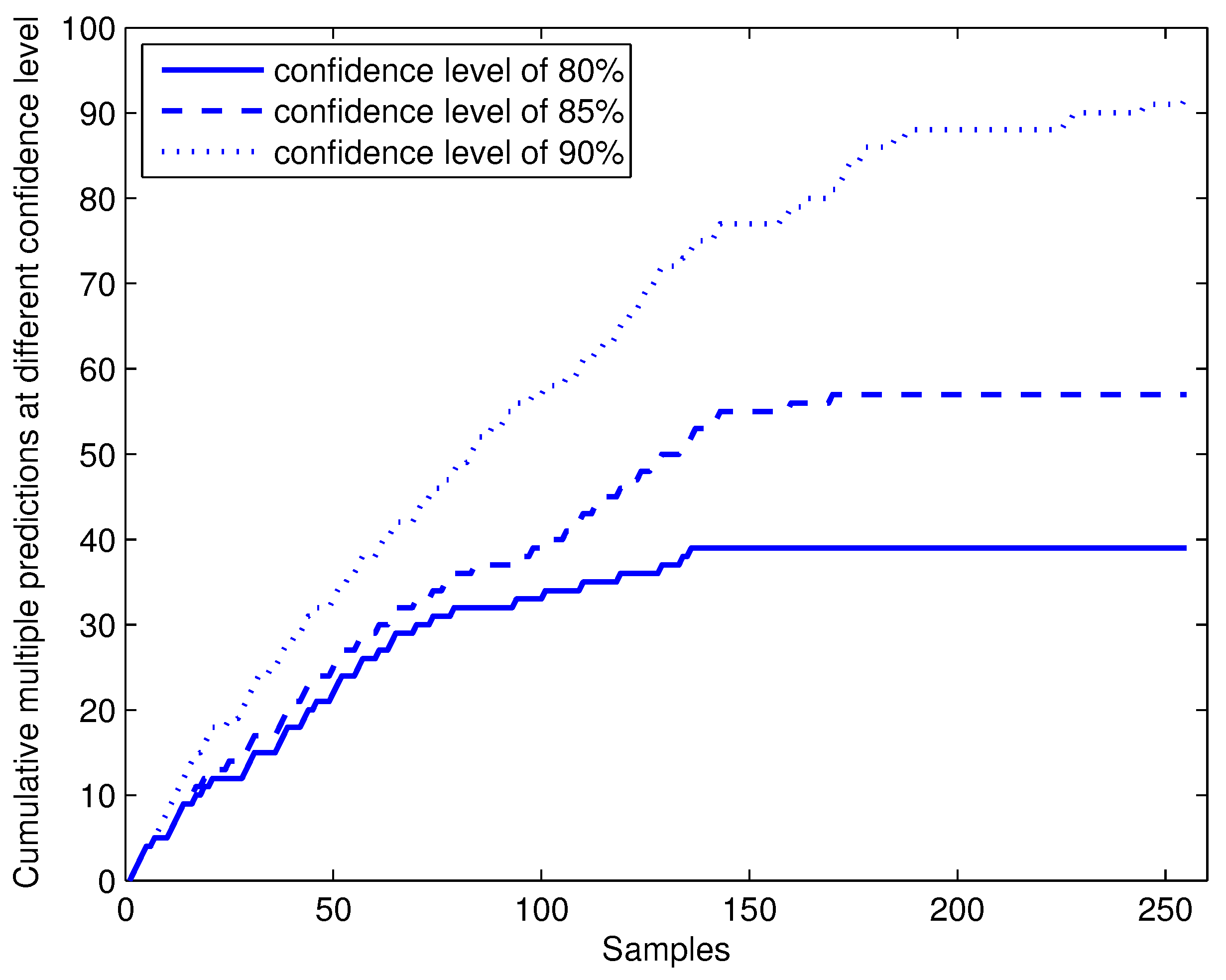
4.3. Efficiency of Online Conformal Prediction
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kaur, R.; Kumar, R.; Gulati, A.; Ghanshyam, C.; Kapur, P.; Bhondekar, A.P. Enhancing electronic nose performance: A novel feature selection approach using dynamic social impact theory and moving window time slicing for classification of Kangra orthodox black tea (Camellia sinensis (L.) O. Kuntze). Sens. Actuators B Chem. 2012, 166, 309–319. [Google Scholar] [CrossRef]
- Miao, J.; Zhang, T.; Wang, Y.; Li, G. Optimal sensor selection for classifying a set of ginsengs using metal-oxide sensors. Sensors 2015, 15, 16027–16039. [Google Scholar] [CrossRef] [PubMed]
- Gebicki, J.; Szulczynski, B.; Kaminski, M. Determination of authenticity of brand perfume using electronic nose prototypes. Meas. Sci. Technol. 2015, 26, 125103. [Google Scholar] [CrossRef]
- Gebicki, J.; Dymerski, T.; Namiesnik, J. Investigation of air quality beside a municipal landfill: The fate of malodour compounds as a model VOC. Environments 2017, 4, 7. [Google Scholar] [CrossRef]
- Singh, H.; Raj, V.B.; Kumar, J.; Mittal, U.; Mishra, M.; Nimal, A.T.; Sharma, M.U.; Gupta, V. Metal oxide SAW E-nose employing PCA and ANN for the identification of binary mixture of DMMP and methanol. Sens. Actuators B Chem. 2014, 200, 147–156. [Google Scholar] [CrossRef]
- Longobardi, F.; Casiello, G.; Ventrella, A.; Mazzilli, V.; Nardelli, A.; Sacco, D.; Catucci, L.; Agostiano, A. Electronic nose and isotope ratio mass spectrometry in combination with chemometrics for the characterization of the geographical origin of Italian sweet cherries. Food Chem. 2015, 170, 90–96. [Google Scholar] [CrossRef] [PubMed]
- Green, G.C.; Chan, A.D.C.; Dan, H.H.; Lin, M. Using a metal oxide sensor (MOS)-based electronic nose for discrimination of bacteria based on individual colonies in suspension. Sens. Actuators B Chem. 2011, 152, 21–28. [Google Scholar] [CrossRef]
- Dymerski, T.; Gebicki, J.; Wardencki, W.; Namiesnik, J. Application of an electronic nose instrument to fast classification of polish honey types. Sensors 2014, 14, 10709–10724. [Google Scholar] [CrossRef] [PubMed]
- Giungato, P.; Laiola, E.; Nicolardi, V. Evaluation of industrial roasting degree of coffee beans by using an electronic nose and a stepwise backward selection of predictors. Food Anal. Methods 2017. [Google Scholar] [CrossRef]
- Gammerman, A.; Vovk, V. Hedging predictions in machine learning-The second Computer Journal Lecture. Comp. J. 2007, 50, 151–163. [Google Scholar] [CrossRef]
- Nouretdinov, I.; Devetyarov, D.; Vovk, V.; Burford, B.; Camuzeaux, S.; Gentry-Maharaj, A.; Tiss, A.; Smith, C.; Luo, Z.Y.; Chervonenkis, A.; et al. Multiprobabilistic prediction in early medical diagnoses. Ann. Math. Artif. Intell. 2015, 74, 203–222. [Google Scholar] [CrossRef]
- Zhou, C.Z.; Nouretdinov, I.; Luo, Z.Y.; Adamskiy, D.; Randell, L.; Coldham, N.; Gammerman, A. A Comparison of venn machine with platt’s method in probabilistic outputs. Artif. Intell. Appl. Innov. Pt Ii 2011, 364, 483–490. [Google Scholar]
- De Vito, S.; Piga, M.; Martinotto, L.; Di Francia, G. CO, NO(2) and NO(x) urban pollution monitoring with on-field calibrated electronic nose by automatic bayesian regularization. Sens. Actuators B Chem. 2009, 143, 182–191. [Google Scholar] [CrossRef]
- Romain, A.C.; Nicolas, J. Long term stability of metal oxide-based gas sensors for e-nose environmental applications: An overview. Sens. Actuators B Chem. 2010, 146, 502–506. [Google Scholar] [CrossRef]
- Nimsuk, N.; Nakamoto, T. Study on the odor classification in dynamical concentration robust against humidity and temperature changes. Sens. Actuators B Chem. 2008, 134, 252–257. [Google Scholar] [CrossRef]
- Padilla, M.; Perera, A.; Montoliu, I.; Chaudry, A.; Persaud, K.; Marco, S. Drift compensation of gas sensor array data by Orthogonal Signal Correction. Chemom. Intell. Lab. Syst. 2010, 100, 28–35. [Google Scholar] [CrossRef]
- Ziyatdinov, A.; Marco, S.; Chaudry, A.; Persaud, K.; Caminal, P.; Perera, A. Drift compensation of gas sensor array data by common principal component analysis. Sens. Actuators B Chem. 2010, 146, 460–465. [Google Scholar] [CrossRef]
- Marco, S. The need for external validation in machine olfaction: Emphasis on health-related applications. Anal. Bioanal. Chem. 2014, 406, 3941–3956. [Google Scholar] [CrossRef] [PubMed]
- Vovk, V. Conditional validity of inductive conformal predictors. Mach. Learn. 2013, 92, 349–376. [Google Scholar] [CrossRef]
- Vovk, V.; Gammerman, A.; Shafer, G. Algorithm Learning in a Random World; Springer: New York, NY, USA, 2005. [Google Scholar]
- Haddi, Z.; Boughrini, M.; Ihlou, S.; Amari, A.; Mabrouk, S.; Barhoumi, H.; Maaref, A.; Bari, N.E.; Llobet, E.; Jaffrezic-Renault, N.; et al. Geographical classification of Virgin Olive Oils by combining the electronic nose and tongue. Sensors 2012. [Google Scholar] [CrossRef]
- Timsorn, K.; Wongchoosuk, C.; Wattuya, P.; Promdaen, S.; Sittichat, S. Discrimination of chicken freshness using electronic nose combined with PCA and ANN. In Proceedings of the International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Nakhon Ratchasima, Thailand, 14–17 May 2014; pp. 1–4. [Google Scholar]
- Vovk, V.; Fedorova, V.; Nouretdinov, I.; Gammerman, A. Criteria of efficiency for conformal prediction. In Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Spring: Berlin, Germany, 2016; pp. 23–39. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Ginseng Samples | Places of Production |
|---|---|---|
| 1 | Chinese red ginseng | Ji’an |
| 2 | Chinese red ginseng | Fusong |
| 3 | Korean red ginseng | Ji’an |
| 4 | Chinese white ginseng | Ji’an |
| 5 | Chinese white ginseng | Fusong |
| 6 | American ginseng | Fusong |
| 7 | American ginseng | USA |
| 8 | American ginseng | Canada |
| 9 | American ginseng | Tonghua |
| No. | Sensor Type | Response Characteristic |
|---|---|---|
| 1 | TGS800 | Carbon monoxide, ethanol, methane, hydrogen, ammonia |
| 2 | TGS813 | Carbon monoxide, ethanol, methane, hydrogen, isobutane |
| 3 | TGS813 | Carbon monoxide, ethanol, methane, hydrogen, isobutane |
| 4 | TGS816 | Carbon monoxide, ethanol, methane, hydrogen, isobutane |
| 5 | TGS821 | Carbon monoxide, ethanol, methane, hydrogen |
| 6 | TGS822 | Carbon monoxide, ethanol, methane, acetone, n-Hexane, benzene, isobutane |
| 7 | TGS822 | Carbon monoxide, ethanol, methane, acetone, n-Hexane, benzene, isobutane |
| 8 | TGS826 | Ammonia, trimethyl amine |
| 9 | TGS830 | Ethanol, R-12, R-11, R-22, R-113 |
| 10 | TGS832 | R-134a, R-12 and R-22, ethanol |
| 11 | TGS800 | Carbon monoxide, ethanol, methane, hydrogen, isobutane |
| 12 | TGS2620 | Methane, Carbon monoxide, isobutane, hydrogen |
| 13 | TGS2600 | Carbon monoxide, hydrogen |
| 14 | TGS2602 | Hydrogen, ammonia ethanol, hydrogen sulfide, toluene |
| 15 | TGS2610 | Ethanol, hydrogen, methane, isobutane/propane |
| 16 | TGS2611 | Ethanol, hydrogen, isobutane, methane |
| Sample Serial | True Lable | Forced Prediction | Confidence | Credibility | Simple Prediction |
|---|---|---|---|---|---|
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 |
| Predictors | 1NN | 3NN |
|---|---|---|
| Forced conformal predictor | 84.44% | 80.63% |
| Simple predictor | 84.13% | 77.46% |
| Confidence Level | CP-1NN | CP-3NN | ||
|---|---|---|---|---|
| M Criterion | E Criterion | M Criterion | E Criterion | |
| 80% | 15.29% | 1.23 | 23.92% | 1.32 |
| 85% | 22.35% | 1.40 | 32.94% | 1.47 |
| 90% | 36.08% | 1.62 | 45.88% | 1.75 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Sun, X.; Miao, J.; Wang, Y.; Luo, Z.; Li, G. Conformal Prediction Based on K-Nearest Neighbors for Discrimination of Ginsengs by a Home-Made Electronic Nose. Sensors 2017, 17, 1869. https://doi.org/10.3390/s17081869
Wang Z, Sun X, Miao J, Wang Y, Luo Z, Li G. Conformal Prediction Based on K-Nearest Neighbors for Discrimination of Ginsengs by a Home-Made Electronic Nose. Sensors. 2017; 17(8):1869. https://doi.org/10.3390/s17081869
Chicago/Turabian StyleWang, Zhan, Xiyang Sun, Jiacheng Miao, You Wang, Zhiyuan Luo, and Guang Li. 2017. "Conformal Prediction Based on K-Nearest Neighbors for Discrimination of Ginsengs by a Home-Made Electronic Nose" Sensors 17, no. 8: 1869. https://doi.org/10.3390/s17081869
APA StyleWang, Z., Sun, X., Miao, J., Wang, Y., Luo, Z., & Li, G. (2017). Conformal Prediction Based on K-Nearest Neighbors for Discrimination of Ginsengs by a Home-Made Electronic Nose. Sensors, 17(8), 1869. https://doi.org/10.3390/s17081869